
Бесплатный фрагмент - Поисковые алгоритмы ранжирования сайтов
Введение
Представьте, что Google создал свою вселенную. В этой вселенной много стран, городов, и мелких населенных пунктов — это сайты. Как и в любом цивилизованном обществе Google придумал как систематизировать, чтобы жители-пользователи могли в этой вселенной находить нужные им уголки, и совершать желаемые действия: покупать, получать информацию, развлекаться.
Google установил закон, по которому ранжирует сайты, когда что-то ищется пользователем.
Но, как и в любом цивилизованном обществе кроме честных граждан есть и те, которые нарушают установленный закон.
Нужна полиция, которая штрафует нарушителей, и создает благоприятные условия для честных.
Эту полицию принято называть фильтрами, или алгоритмами, по которым и происходит определение качества сайтов и дальнейшее их ранжирование по запросам пользователей.
Сейчас мало создать сайт и наполнить его информацией, сейчас нужно подготовить сайт в 2-х направлениях.
1. Распределить информацию в соответствии с законом (руководствами) Google.
2. Подготовить такой контент (материал), который будет полезен конечному потребителю.
Причем последнему Google неустанно учит оптимизаторов сайтов, как и что должен иметь сайт, чтобы последний понравился пользователям, и получил высокое место в результатах поиска.
Существует три вида SEO оптимизации.
1. Чёрные методы.
Ими пользуются начинающие сеошники, которые ещё не понимают принципов ранжирования, и не знакомы с законом Google. К чёрным методам относятся нарушения, которые Google описал в своих руководствах, и находя их:
· Пессимизирует (понижение позиции сайта в выдаче поисковой системы искусственное снижение релевантности запросу).
· Штрафует см. фильтр «Unnatural Links».
· Удаляет из своего индекса, что случается чрезвычайно редко, и то только с теми сайтами, которые умышленно занимаются обманом, распространяют вредоносное программное обеспечение, и нечестными заработками.
Черная оптимизация делается быстро, не дорого, она не долговечна. Полиция (фильтры) Google их быстро находят, а хозяева таких сайтов несут прямые и косвенные убытки.
2. Серые методы. Включают в себя трудно фиксируемые нарушения, которые чаще всего исходят от фильтров Panda, Penguin, Phantom, и других фильтрах, о которых будем говорить в этой книге.
Серые методы требуют наибольший подготовки, потому что нужно четко представлять,
a. что и в какой мере нарушаешь, чтобы безболезненно обойти. Обычно нарушается то, что по закону не положено делать, но фильтры ещё не научились выявлять эти нарушения. Именно эти нарушители и больше всех шумят, когда их сайты теряют свои высокие позиции.
b. Это самые высокооплачиваемые специалисты экстра-класса, которые как отличные адвокаты выискивают что ещё не запрещено делать, разрабатывают системы, и внедряют их. Например, продажа ссылок — распространённое явление, которое отлично поднимает рейтинг сайта, но доказать, что ссылка куплена — достаточно сложно. Например, гостевые посты на момент написания книги Google приветствовал. Но как доказать, что пост был куплен?
3. Белые методы продвижения сайтов
заключаются в том, чтобы не нарушать закон Google, и делать всё по им установленным правилам. Для сайтов, не нарушающих закон фильтры — это не жандармы, которые рубят все подряд, а добрые полицейские, которые удаляют (пессимизируют) сайты нарушители. Кроме этого Google занимается исследованием поведенческих факторов, и делится своими исследованиями с SEO-специалистами, показывая, как нужно делать, чтобы не только высоко позиционироваться в результатах ответов на запросы пользователей, но и после перехода на сайт посетитель получал максимальное удовлетворение, и совершал желаемое действие.
В большинстве случаем Google не объясняет почему нужно делать так, а не иначе, но выполняющие рекомендации получает преимущество перед другими видами SEO-продвижения. Поясню на одном известном исследовании, направленном на то, как «заставить» человека выбирать желаемое продавцу. В США популярно в кинотеатре перед просмотром фильма покупать попкорн.
Простой эксперимент. Продается попкорн в двух бумажных стаканчиках. Один стаканчик маленький — стоит $4, другой большой — стоит $7. Подавляющее количество посетителей покупали маленький стаканчик. Вторая часть эксперимента. К этим двум стаканчикам добавили третий, средний по размеру по цене $6. И посетители стали покупать большой стаканчик многократно чаще. Средний редко кто брал, иногда брали маленький. Объяснение было простое: «Выгоднее брать большой стакан, чем средний!» Маленький и большой стаканчики остались без изменения, появился только средний стаканчик, который почти никто не брал. Но он (стаканчик) поменял что-то в мышлении. Так и Google в своих руководствах учит нас делать так, чтобы посетитель делал нужный выбор. Одна из частей этого магнетического воздействия на посетителя качественный и полезный контент. Для Google качественный и полезный контент фундаментальные и разные понятия, о который описывается в фильтре Panda.
Google в своих ответах выдачи преследует только одну цель — первым же результатом поиска выдать сайт, который максимально ответит на запрос (ключевую фразу) пользователя. Идеальным считается ответ, если пользователь не вернулся в поисковик, чтобы продолжать поиск ответа на свой вопрос.
Для решения этой задачи требуется:
· понять, чего ищет пользователь — это часть работы фильтров: Possum, Pigeon, Hummingbird;
· среди миллиардов сайтов подобрать лучшие, т.е. выстроить сайты в ответе на запрос пользователя в убывающим порядке — это работа других фильтров.
Есть и большая группа алгоритмов, включенных в Hummingbird, которые развивают идею безкликового поиска. Это когда пользователь в строке поиска Google ввел некоторый вопрос, и в результатах поиска на первом же экране получил ответ на свой вопрос.
Как не вступая в противоречия с руководством Google, и понимая работу фильтров выводить сайт в лидеры посвящена эта книга.
Качественный, полезный и авторитетный контент
Перед тем как начать рассматривать фильтры желательно понимать их основную цель, чтобы правильно оценивать их работу, и пользоваться их благами.
Итак, начнем.
Google стремится к тому, чтобы в результатах поиска первую позицию всегда занимал лучший ответ, а далее по убыванию остальные, которые более-менее соответствуют запросу пользователей.
Для решения этой задачи фундаментом всего поиска Google приняты три кита, на основании которых и строятся все фильтры, или алгоритмы по результатам работы, которых выстраиваются сайты в результатах поиска пользователей на их запросы.
Эти три кита следующие.
Качественный контент
a. оригинальные тексты (копии и рера́йтинг это не качественный контент) и оригинальные изображения (сделанные самостоятельно);
b. тексты без орфографических, синтаксических и других ошибок;
c. хорошо структурированный текст;
d. LSI-терминология см. в следующей главе, и достаточный объем.
Кроме перечисленных пунктов качественного контента к его качеству относится длинна предложения и слов с учетом образованности аудитории, которой предназначается текст. Например, если магазин продает товары, рассчитанные на блондинок (по жизни, а не по способностям), то предложения должны быть короткими, со словами, которые употребляет именно это группа людей. Если же текст рассчитан на людей с высшим образованием, то и предложения, и тексты должны быть более длинными.
Google считает, что текст на сайте должен быть информативен. Большое количество не информативных слов (в, на, весьма, вполне) — понижает вес страницы. У каждого поисковика свой набор не информативных слов и фраз, которые, как и Google они держат в секрете. Эти слова и фразы называют стоп-словами, или шумовыми.
По мнению Google стоп-слова не несут информацию, и раздражают читателя. Но все же небольшое количество для связки должно быть. Мы не говорим, например, «перелез забор», но говорим «перелез через забор».
Чтобы было проще понять смысл слов, которые понижают рейтинг поясню на примере. Девочки, которые прошли курсы по копирайтингу, получают деньги за свою работу из расчета количества напечатанных знаков. У них расчёт простой чем больше, знаков в тексте тем больше они получат. Имея набор ключевых фраз, они умудряются вплетать массу бессмысленного текста.
Например: «Наша быстро развивающаяся компания молодых специалистов с большим опытом работы…». Какая информация, полезная в этой фразе?
Смотрите: «быстро развивающаяся» — ничего не говорящая фраза, читатель видит стандартный штамп, как на других сайтах, и сразу пропускает эту информацию. Нет информации.
Лучше написать: «В прошлом году мы обслужили 150 человек, а в этом 200!». Но эти цифры ничем не подкреплены. Но что значит обслужили? Пришел к ним человек, они ответили на его вопрос, и тот ушел. Можно считать, что они его обслужили. В добавок как проверить? Да в таком варианте есть информация, но как её проверить?
Убедительнее звучит: «В прошлом году мы заплатили 10 000 € налогов, а в этом — 14тыс.». Такая фраза внушает доверие, потому что её можно проверить.
Еще один плюс последний фразы — мы не говорим, что фирма развивается быстро, мы предоставляем возможность читателю самостоятельно сделать вывод, что фирма развивается быстро. Ведь могут оказаться люди, для которых увеличение прибыли на 40% за год не такой уж хороший результат.
Такой вариант, не навязанное мнение для каждого человека — самое ценное его собственное заключение. Более убедительным будет скриншот оплаты налогов за прошлый и текущий год, сделанный с официального сайта, с соответствующей подписью к скриншоту.
Далее «молодых». Вместо молодых лучше написать конкретно: «Возраст работников от 25 до 30 лет». Плюс за мой вариант — для 18—20 летнего заказчика 30 лет — это зрелый возраст. Для 50-ти летнего — это пацаны. Цифры вместо прилагательных для посетителя звучат убедительнее, а значит и полезнее. И Google воспринимает цифры более весомым фактором.
Идеально будет показать фотографии работников, с кратким описанием, возраста, образованием, стажем работы, и дугой информацией, чтобы каждый мог выносить свое суждение.
Фотографии с подписями для Google тоже положительный сигнал, что информация подается разнообразно, ведь мы любим разнообразие.
«Специалистов» — требуется доказать, что работники действительно специалисты. Например, закончил такой-то университет, стажировался там-то. Google уже имеет большой набор штампов, пустых фраз, которые не несут информации? Но снижают вес веб-страницы.
И последнее явное противоречие: «с большим опытом работы». Как у молодого специалиста может быть большой опыт работы?
Специалисты Google утверждают, что они отслеживают достоверность информации, и заметив неправду пессимизируют такие страницы. В качестве примера приводится такая фраза: «Колумб родился в Австралии» как явная ложь. Не берусь утверждать Google уже отлавливает фразы типа «молодых специалистов с большим опытом работы», но уверен, что и такие фразы будут попадать в их черный список.
Наше мировосприятиеустроено так, что если мы видим хоть одно противоречие, уход от четкого ответа, то в нас возникает недоверие ко всему сказанному. Google это знает и снижает вес веб-страниц, которые имеют такие фразы.
Сейчас мы разобрали один небольшой пример, как пример бесполезного текста. Разбирать же все ограничения, которыми пользуется Google нет смысла. Лучше довериться его Руководству, чтобы понять за что может быть наказан сайт. Повторюсь, что не на все уловки Google уже реагирует, но те, кто желает делать качественный, полезный и авторитетный сайт должны уже сегодня стараться избегать запреты, декларированные поисковиком.
Google не любит клише и штампы. Не любит прилагательные, местоимения, наречия, причастные и другие обороты. И наоборот, чем больше существительных и глаголов действия и состояния, числительных тем лучше.
Вспомните А. С. Пушкина
«Буря мглою небо кроет, Вихри снежные крутя; То, как зверь, она завоет, То заплачет, как дитя, То по кровле обветшалой Вдруг соломой зашумит, То, как путник запоздалый, К нам в окошко застучит.»
Посчитайте сколько здесь существительных и глаголов, а сколько прилагательных, и других частей речи.
Уверен, что у многих тексты на сайтах менее качественные по мнению Google.
Полезный контент
это:
· ответы на задранные вопросы (на фразы, которые набирает пользователь) поисковику;
· что комментируют, ставят лайки;
· пишут отзывы.
Полезный контент — это не просто статья на сайте, в блоге, или интернет-магазине, — это ценная информация, которой автор желает поделиться с другими людьми. Ценная информация — это то, что автор отправляет поисковикам, чтобы те помогли поделиться её с другими пользователями.
Так что по мнению Google качественный контент —
· Это то, чем можно поделиться.
· Это реальные ответы пользователю на задранные вопросы поисковику.
· Это то, что люди обсуждают в сети, на работе, в кругу друзей или дома.
· Это то, что цитируют.
Поэтому Google уделяет внимание сколько ссылок сделано на веб-страницу, сколько раз процитировали. Возможно, что, сдирая фрагменты текста с других сайтов Google добавляет вес сайту донору. Но уж точно не увеличивает вес, где замечен плагиат. Однако если фрагмент текста берется в кавычки, и пишется откуда взята цитата, то Google считает, что тема глубоко изучена, а поэтому статья полезная. Конечно, если цитата из авторитетного сайта.
LSI — скрытое (латентное) семантическое индексирование. Методика, разрабатываемая Google, и др. поисковыми системами. Цель — улучшение понимания содержания страниц сайта для более точной сортировки и выдачи соответствующего запросу пользователя.
Если прежде было достаточно ключевую фразу повторить несколько раз на странице сайта, чтобы войти в ТОП 10 при выдаче, то сейчас поисковики считают такое повторение фразы поисковым спамом, и за это понижают рейтинг сайта. Если же поисковый СПАМ — на множестве страниц, то поисковик может исключить этот сайт из поиска.
Сейчас Google проводит семантический анализ страниц сайта, и на основании результатов их ранжировать.
Факторов, влияющих на скрытое семантическое индексирование много, но остановимся на 5-ти наиболее значимых.
1. Направленность сайта
Поисковые машины разделяют сайты по запросам пользователей.
Грубо все сайты делятся на 3 категории.
· У пользователя есть информационные намерение? Информационное намерение — это когда человек ищет информацию по теме. Например, «что такое LSI копирайтинг». Отчасти для таких запросов был создан фильтр Hummingbird.
· Имеют ли человек навигационные цели? Навигационное намерение заключается в том, что поисковик ищет конкретную марку (автомобиля, телевизора, др.), веб-сайт, бизнес или продукт, используя поиск.
· У ищущего есть транзакционные намерения? Транзакционные намерения — это когда человек ищет что-то, потому что хочет это купить. Если предполагаемая покупка не предполагает длительной перевозки, например, пиццы, дивана, садового домика, или покупка услуги, то это геозависимые запросы, то в работу вступают такие фильтры как Pigeon и др. Обо всех пойдет речи далее.
Исходя из намерений страница должна иметь кроме текста и дополнительные атрибуты.
Например, информационный сайт должен иметь поиск, навигацию по разделам, категориям, статьям, чтобы пользователь мог за пару кликов перейти от одного нужного материала к другому. А также комментарии к статьям, и многое другое. Чем больше атрибутов, соответствующих типу сайта, тем сайт имеет больший вес.
Интернет-магазин должен иметь кнопку купить, корзину, цену, описание товара, отзывы на товар, доступную ссылку на доставку. Трудно будет интернет-магазину выбиться в лидеры, если он не имеет всех дополнительных атрибутов, которые есть у лидеров этого запроса.
Например, интернет-магазин, лидер выдачи имеют всё необходимое по требованиям Google. Чтобы иметь шансы обойти лидера другому магазину, нужно иметь все эти же атрибуты, плюс добавить свою изюминку. Если у сайта лидера в магазине нет видео, то новому сайту можно добавить видео-демонстрацию товара. Конечно, у сайта лидера могут быть высокими и другие показатели, но с изюминкой у новичка появляется шанс.
Кроме оценки всего сайта на направленность, и с наличием необходимых атрибутов важную роль играет LSI копирайтинг страниц сайта.
2. Словосочетания
Если Вы в Гугл наберёте слово «Кухня», то Google не поймет, что нужно, и выдаст всего понемногу, по разным темам.
· Кухня смотреть.
· Кухни стран мира.
· Дизайн кухни.
· Кухонная мебель.
· И много другого.
Но если написать «Кухни смотреть», то поисковик поймет, что человек хочет посмотреть сериал, и ему будут выбраны сайты, на которых можно смотреть сериал.
Если же написать «Кухонная мебель», то будут ранжироваться сайты по этой тематике. Стоит добавить слово купить, и поисковик поймет, что человеку нужен интернет-магазин. Причем Google понимает, что по такому запросу нужно выбрать близлежащие магазины, а не магазины из которых доставка будет стоить дороже мебели.
Но это начало. Для поисковика если появилось слово «мебель», и статья посвящена этой теме, то дополнительно Гугл ищет и другие слова, которые часто употребляются со словом «мебель». Например, фото, гарнитура, дерево, стол, стул, и др.
Слову «концерт» сопутствуют слова: билеты, места, аншлаг, премьера, выступление. Если прежде для SEO было достаточно написать на странице слово «Концерт» несколько раз, и выбиться в лидеры, то теперь оценивается полезность по сопутствующим словам.
По технологии скрытого семантического индексирования, если слову «концерт», не будет найдено сопутствующих слов, то такая страница будет расценена как СПАМ. А под такой фильтр уже попало много сайтов.
Сравнивая несколько статей с разных сайтов Гугл позиционирует выше ту статью, в которой было употреблено больше сопутствующих слов. Чем больше сопутствующих слов в статье, тем Google считает тема раскрыта лучше, тем присваивается выше рейтинг статьи. Также учитывается и количество запросов по сопутствующим словам.
3. LSI-компоненты
Каждая веб-сайт должен иметь соответствующие дополнительные компоненты.
Например, если сайт некоторого доктора, то желательна форма для записи на прием, карта как добраться, сертификаты, и многое другое. Собрать сопутствующие компоненты можно посмотрев на первый десяток сайтов в поисковой выдаче, по соответствующим ключевым фразам. Если дополнительных компонентов на сайте будет недостаточно, то будет трудно рассчитывать па высокие места.
4. Синонимы
Повторение одной и той же фразы много раз на странице сейчас понижает релевантность. Поисковики считают, что такой текст плохо читается, а поэтому не интересен. Теперь пришло время синонимов — слова различные по звучанию, но совпадающие по значению.
Например, синонимы слова «дом»: здание, дворец, изба, хата, хижина, землянка, лачуга, мазанка, палата, хоромы, терем, чертог, усадьба, дача, вилла, загородный дом. Барак, балаган, беседка, будка, караулка, кибитка, куща, намет, палатка, сторожка, шалаш, чум, шатер, юрта.
Чем больше синонимов расстановлено в тексте, тем выше рейтинг статьи.
Синонимы можно брать из словарей синонимов, но латентное семантическое индексирование опирается опять-таки на запросы пользователей, именно на те синонимы, которыми наиболее часто пользуются люди.
Например, синонимами слову «обучение» являются: Подготовка, Образование, Бизнес-обучение, Учеба, Преподавание, и еще несколько десятков.
Задача LSI копирайтера в том, чтобы выбрать самые популярные, и равномерно их расставить по тексту.
5. Стоп-слова или шумовые слова
Прежде к стоп-словам относились союзы, предлоги, причастия, и др. Они считались не информационными, и не учитывались.
Теперь палитра стоп-слов заметно расширилась. К ним добавились некоторые прилагательные (если это информационная статья) и ряд «крылатых» выражений, например, «добро пожаловать на наш сайт», или «индивидуальный подход к каждому клиенту».
Поэтому не стоит писать подобные фразы: «У нас работают профессионалы с большим опытом работы». Это уже бесит не только читателей, но и поисковики.
Пользователь на эту фразу сразу же дает 2-а возражения.
· А у кого работают не профессионалы? И
· А у кого работают профессионалы без опыта?
Да и вообще разве есть профи без опыта?
Для поисковика же эта фраза — поисковый СПАМ.
Чем больше на странице шумовых слов и фраз, тем менее информативна статья. Тем ниже её рейтинг.
6. Легкость чтения
Сейчас у людей преобладает клиповое мышление. Это значит, что люди слабо воспринимают информацию, на изучение сути которой уходит больше времени, чем на просмотр клипа.
А это значит, что тексты должны быть как СМС. Предложения должны быть простыми, не более 160 печатных знака, которые выражают суть.
Л. Толстовские предложения на пол страницы — не годятся. Считается, что лучше писать простыми предложениями по 6—8 слов, потому как если предложение длинное — читатель забудет о том, что говорилось в начале. Тем более если текст сложный в осмыслении.
Чес проще, тем лучше для любой аудитории.
Google для определения читаемости текста возможно пользуется индексом Фога и формулой Флеша.
Во всяком случае что-то подобное Google включил в свои фильтры.
Суть индекса и формулы — просты. Чем меньше слов в предложении, и чем короче слова, тем текст более читаемый, а значит такие статьи получают и больший рейтинг.
Это и понятно. Ведь трудно поверить, что человек, зашедший на веб страницу, не имеет проблем. Невероятно, что у него ни о чем не болит голова, к примеру, его жене, детям, тёще от него ничего не надо…
Сейчас любой заходит на страницу, чтобы по-быстрому получить нужную информацию, и использовать её.
Поисковые системы прекрасно понимают направленность сайта.
Для научного, информационного или сайта-магазина язык подачи информации различен.
Если сайт, к примеру, новостной, то там не должно быть длинных и сложных предложений. Должно быть больше действия, глаголов и минимум превосходной степени. Информация действия!
Если же это литературный сайт, то предложения могут быть длиннее, для простора творческих фантазий. Конечно, если сайт рассчитан на то, чтобы человек просто расслаблялся на нем.
Так SEO оптимизация из набора ключевых фраз превращается в более сложную систему продвижения сайта. А LSI-копирайтинг помогает создавать более приемлемые тексты для читателей, и максимально релевантные для поисковых систем.
Авторитетный контент
Это
e. Что цитируют на других сайтах и в соц. сети.
f. LSI-объекты: сертификаты, галереи работ.
g. Возраст сайта, и другие сигналы, о которых будет рассказано далее.
h. Сертификация безопасности: сертификат SSL.
Продолжу, и укажу на некоторые значительные признаки авторитетности, которые определяются различными фильтрами.
Например, если пользователь ищет характеристики некоторого бренда, то большее доверие вызовет описание с официального сайта, чем с сайта некоторой ремонтной мастерской, а тем более с домашней странички какого-то Васи. Если же Вася захочет по некотором запросу обойти сайт Apple, то это невозможно — никакой ссылочной массы сайту Васи не хватит, чтобы превзойти всемирный бренд.
Наличие политики конфиденциальности указывает Google, что владелец веб-сайта заботится о соблюдении законов и обеспечении безопасности своего веб-сайта.
Контактная информация — ещё один сигнал, который повышает авторитет сайта. А лично вы к какому сайту испытывает большее доверие, на котором один телефон, или возможность связаться с разными людьми по разным номерам. Это говорит о том, что предприятие большое, и может себе позволить, чтобы разные люди отвечали на вопросы по разным темам.
Наличие адреса компании, её филиалов тоже увеличивает авторитет сайта.
Маленькие виджеты из социальных сетей, таких как VK или OK, с фотографиями людей, которым понравился этот конкретный сайт.
Авторитетный веб-сайт — действующий сайт, а это определяется по
· обновлениям, и новостям;
· активности в социальных сетях;
· текущий год в авторском праве.
Если сайт авторитетный, то на него ссылаются другие сайты. Чем выше авторитет ссылаемого сайта, тем выше авторитет сайта, на который ссылаются. Кроме этого, учитывается и схожесть тематики. Авторитета не добавит даже самый крутой сайт рецептов сайту по ремонту компьютеров.
Материал, публикуемый на сайте, должен быть актуальным, убеждать фактами и ссылками, на сайты подтверждающие эти факты.
Пользовательская проверка
После этой предварительной (для Google оценки) наступает пользовательская проверка.
Если посетитель зашел на страницу, пробыл там время необходимое для изучения, изложенного материала, то к рейтингу страницы по этому запросу добавляется дополнительный вес. Если пользователь после изучения страницы не вернулся обратно в поиск, то для Google — эта страница идеально отвечает на запрос. Чем больший процент пользователей не возвращается в поиск, тем ценнее эта страница при ответе на такой запрос пользователей. Google знает, что нет ничего совершенного, поэтому устраивает некоторую ротацию, и посмотреть на реакцию пользователей при изучении других сайтов. Кроме этого, есть и дополнительные фильтры, такие как Hummingbird (Колибри), Pigeon (Голубь), и другие, которые помогают молодым и перспективным сайта оказаться в верхней части первой страницы поиска.
Сейчас ещё в тренде покупать ссылки. Чем вsit ранжируется сайт, тем больше считается вес ссылки. Но это только первое время. Далее Google учитывает ценность этой ссылки количеством пользовательских переходов. Сколько должно быть переходов по ссылке, чтобы считать её качественной, очевидно рассчитывается как CTR (количество переходов по ссылки к количеству показов страницы). Очевидно, учитывается популярность страницы из расчета популярности запроса.
Конечно, ещё алгоритмы далеки от совершенства, и бывает, что Google выдает не понятный результат.
Посмотрите на пример, из которого видно, что Google определил, что в этом запросе для него главное купить в Риге, а не сам товар. Google понял, что ищется, зарядка (блок питания) для ноутбука, но почему-то проигнорировал марку и / или параметры. Заметьте, что Google СЕМЬ раз вывел один и тот же сайт, и ни разу именно ту зарядку, которую я тестировал в поиске, а она есть на сайте.
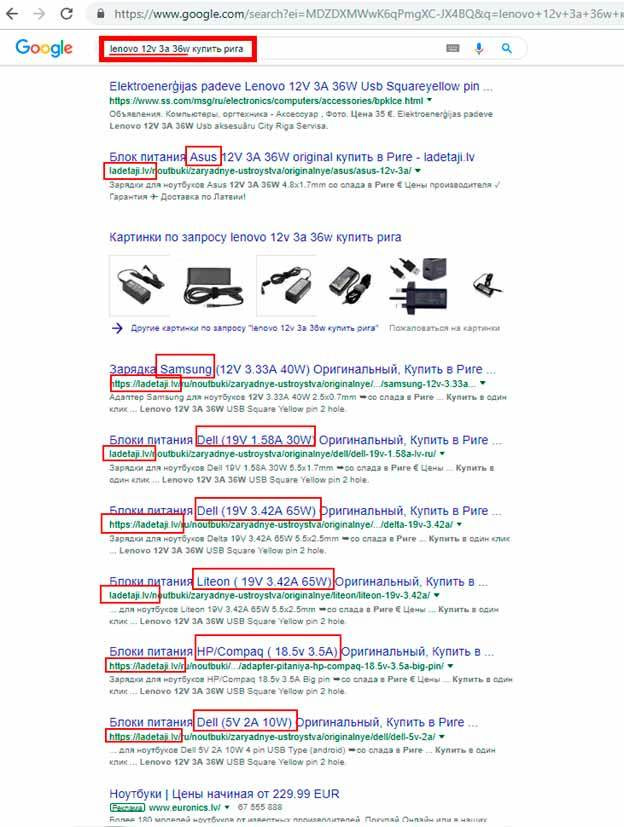
Этот пример говорит о том, что ещё не всё в алгоритмах идеально, и не более того. Google непрерывно работает над усовершенствованием ранжирования, и уже через пару недель ошибка была исправлена.
И хотя я работал над этим сайтом, когда остался один снипет из 7, но тот, который будет отсылать на нужный блок питания, я как оптимизатор доволен, потому что если пользователь ищет зарядку с определенными параметрами, то он не будет переходить на те зарядки, которые ему не нужны.
Другой пример. Обратилась к нам небольшая фирма с просьбой продвинуть их сайт. Бюджет на продвижение у них был весьма ограничен, и мы предложили им для начала на каждой странице проставить Meta Keywords, чтобы знать какую страницу оптимизировать под какую ключевую фразу. Page Title и Meta Description у них уже были прописаны.
Представляете, этого было достаточно, чтобы их сайт через некоторое время оказался в первой десятке. Да все ключевые фразы были низкочастотные, и конкуренция в их отрасли маленькая.
И всё же ключевые слова, на которые Google объявил много лет назад больше не учитываются, оказалось были учтены. Возможно, что ключевые слова не учитываются для определения направленности веб-страницы, но, очевидно влияют на качество и авторитет страницы, ведь тег Meta Keywords никто не отменял, и правила хорошего тона желают, чтобы этот тег был заполнен.
К слову сказать, что мы всегда прописываем ключевые слова для себя, чтобы видеть под какие запросы оптимизировалась страница.
Но вернёмся к идеологии идеального поиска по мнению Google.
Проделаем мысленный эксперимент, представьте, что вы приглашаете к себе в гости людей на банкет.
Что им предложить, если вам дороги эти люди, и желаете показать, что вы заботитесь о них?
Во-первых, то, что они любят. Затем, чтобы продукты были свежими, вкусными и качественными. Если вы заботитесь об их здоровье, то продукты должны быть полезными, без содержания вредных веществ.
Так поступают гостеприимные хозяева.
Тоже самое и с сайтом. Приглашая зайти на сайт, нужно, чтобы предлагаемый материал был качественным и полезным.
Кроме этого, хозяева застолья позаботятся о том, чтобы обслуживающий персонал был авторитетным: еда была вкусно приготовленная и подавалась быстро. Гостей не принято заставлять ждать. Само собой тарелки должны быть чистыми, салфетки свежими, и будут соблюдены ещё тысяча мелочей.
Google формально описал, что должно быть на сайте, подобно нормам хорошего банкета, и с помощью своих фильтров по этим критериям определяет полезность, качественность и авторитетность сайта, и декларировал их в своем Руководстве.
А теперь представьте, что хозяин, который претендует на звание лучшего будет жульничать, обещать одно, а подавать другое, и из недоброкачественных продуктов на грязных тарелках…
Заметьте, что Google из миллионов предложений выбирает лучшее и поднимает их в выдаче. Разве и это не справедливо?
Мне не нравится распространенное слово «пессимизация», т.е. понижение в рейтинге. Мне кажется, что более объективно говорить о повышении в рейтинге хороших сайтов. Почему менее качественные сайты должны быть выше лучших? Многие оптимизаторы воют на весь интернет, когда какой-либо алгоритм «считает», что его сайт хуже других. Но разве алгоритм виноват, что конкурент сделал лучше.
ДА! Уходит время халявы, когда материал на сайте искусственно подстраивался под определенный алгоритм оставался в лидерах надолго. Алгоритмы совершенствуются все быстрее и быстрее. Поэтому становится выгоднее работать на перспективу, следуя Руководству Google, чем пользоваться ещё неучтенными фактами, чтобы получить минутное признание.
Но есть алгоритмы создания высоко ранжируемых сайтов, следуя инструкциям, которых, даже в конкурентных нишах возможно получить хороший результат.
Да не все Пушкины, Шекспиры и Рубенсы, и с этим нужно смериться. Не все способны пробежать стометровку меньше, чем за 12 секунд. Не все способны сделать что-то стоящее, и стать первыми, но многие хотят, поэтому выискиваются лазейки, придумываются уловки, а в результате, как всегда, страдает конечный потребитель.
Вот и получается, аналогичная ситуация: несколько человек приглашают вас на банкет. Google оценивает у кого банкет лучше, туда и направляет посетителей. Тот, кто лучше направляет, к тому и обращается конечный пользователь, поэтому Google заинтересованы в качественном поиске.
Чтобы понять, что значит для Google качественный контент нужно не забывать, что ПОИСК — это бизнес, а продуктом этого бизнеса является результат выдачи. Чем качественнее выдача, тем больше людей пользуются этим поисковиком, а это уже монетизированный продукт. Каждая ключевая фраза, введенная пользователем в строке поиска для Google — это вопрос, на который пользователь хочет найти ответ.
Первая цель поисковика понять какой вопрос был задан. Эта задача как известно из обрывков заявлений Google об организации поиска состоит из двух частей.
Это по этим или подобным запросам подобрать лучшие сайты, которые прежде удовлетворили пользователей. Заметьте, не накрученные сайты, а реальные.
Это и на основании прежних запросов этого пользователя понять, что же заданным вопросом (введенной ключевой фразой) пользователь желает узнать. Например, если прежде человек искал характеристики телевизоров и сравнивал их, а после этого набрал в поисковике «мониторы», то вероятнее всего он желает сравнивать теперь мониторы. Если же, Google заметил, что пользователь купил уже и телевизор, и другое в интернет-магазинах, то вероятнее всего имеет намерение купить монитор. Ни для кого не секрет, что Google отслеживает действия пользователя, знает о его намерениях не хуже, чем сам пользователь, и «подсовывает» ему не только рекламу, но и страницы в рамках пожеланий пользователя.
Для Google постоянный пользователь социальных сетей — это открытая книга. Можно представить какой мощностью обладает Google, если сейчас при приеме на работу работодатели стали обращаться к небольшим формочкам, которые собирают в социальных сетях всю открытую информацию, например с кем дружит, на кого подписан, что комментирует и репостит. Вторая цель — подобрать страницы и вывести их пользователю первыми, чтобы ознакомившись с первой же, посетитель получил ответ на свой вопрос. Согласитесь, что эта задача — искусственного интеллекта, и все больше напоминает разговор людей: один задает вопрос, а другой отвечает. Заметьте Google оценивает и ранжирует разные ответы на поставленный вопрос.
Резюме от Google
Google — имея миллиарды страниц с помощью алгоритмов научился определять какие веб-страницы отвечают на запросы пользователей, а какие имитируют свою полезность.
К наиболее распространенным способам имитации качества полезности и авторитетности Google относит следующие:
· Автоматически сгенерированное содержание:
o Текст, который бесполезен для читателей, но содержит ключевые слова, часто используемые в поиске.
o Текст, который переведен с помощью автоматического инструмента и опубликован без редактирования.
o Текст, созданный с помощью автоматических средств, например, цепей Маркова.
o Текст, созданный автоматически с помощью методов подбора синонимов.
o Текст, сформированный путем копирования контента из фидов Atom/RSS или результатов поиска.
o Контент, скопированный с различных веб-страниц без добавления уникальной информации.
· Участие в схемах обмена ссылками, например,
o Покупка или продажа ссылок, которые учитываются в системе PageRank. К этой категории относится выплата денег за размещение ссылок или сообщений, содержащих ссылки, предоставление товаров или услуг в обмен на публикацию ссылок, а также раздача «бесплатных» товаров с условием размещения отзывов о них со ссылками.
o Чрезмерный обмен ссылками («Сошлись на меня, а я сошлюсь на тебя») и партнерские страницы, служащие исключительно для перекрестного обмена ссылками.
o Масштабная реклама с помощью статей или комментариев с текстовыми ссылками, насыщенными ключевыми словами.
o Использование программ или сервисов для автоматизированного создания ссылок на сайт.
o Требование разместить ту или иную ссылку в соответствии с условиями использования или другим соглашением, если при этом владельцу контента со стороннего ресурса не предоставляется возможность заблокировать PageRank доступ к своей странице, например, с помощью директивы nofollow.
· Публикация страниц с некачественным или скопированным контентом, например,
o автоматически созданное содержание;
o бесполезные партнерские страницы;
o плагиат, например, скопированное содержание или некачественные публикации в блоге;
· Маскировка, например,
o Предоставление поисковым системам страницы с HTML-текстом, а пользователям — страницы с картинками или Flash.
o Добавление на страницу текста или ключевых слов только в ответ на запрос этой страницы агентом пользователя, связанным с поисковой системой.
· Скрытая переадресация, например,
o Поисковый сканер анализирует одну страницу, а пользователям показывается совершенно другая.
o Пользователи компьютеров видят обычную страницу, в то время как пользователи смартфонов перенаправляются хакерами на совершенно другой домен.
· Скрытый текст и скрытые ссылки, например,
o Использовать текст белого цвета на белом фоне
o Поместить изображение поверх текста
o Поместить текст за пределами экрана с помощью CSS
o Установить для размера шрифта значение 0
o Скрыть ссылку, используя в качестве текста ссылки один незаметный символ (например, дефис в середине абзаца)
· Дорвеи, например,
o Несколько доменных имен или страниц с таргетингом на отдельные регионы или города для переадресации пользователей на одну и ту же страницу.
o Страницы, единственной целью которых является перенаправление пользователей в определенный раздел сайта.
o Практически одинаковые страницы, которые скорее соответствуют возможным результатам поиска, чем выстроены в четкую иерархию.
· Скопированное содержание, например,
o Сайты, размещающие контент из других источников без дополнительной обработки.
o Сайты, на которых публикуется скопированное содержание с незначительными изменениями (например, слова заменены синонимами или используются автоматические методы обработки).
o Сайты, транслирующие с других ресурсов фиды, без собственных функций для работы с ними.
o Сайты, содержащие только встраиваемый контент, например, видео, изображения и прочие мультимедийные материалы, с других сайтов без дополнительной значимой информации.
· Участие в партнерских программах, если вы не создаете контент самостоятельно, например,
o Страницы со ссылками на товары, на которых размещены только описания и отзывы, скопированные с сайта продавца, и отсутствует какой-либо уникальный контент.
o Бесполезные страницы, которые содержат преимущественно материалы из других ресурсов и минимум оригинального контента.
· Загрузка страниц с нерелевантными ключевыми словами, например,
o Список телефонных номеров без дополнительной информации
o Текстовые блоки с перечнем городов и областей, по запросам которых веб-мастер пытается повысить рейтинг страницы
o Многократное повторение слова или фразы, из-за чего текст не воспринимается как естественный.
· Создание вредоносных страниц для фишинга и установки вирусов, троянов или другого нежелательного ПО, например,
o Манипулирование контентом таким образом, что при нажатии пользователем на конкретную ссылку или кнопку фактически происходит нажатие на другой элемент страницы.
o Внедрение на страницы новых объявлений или всплывающих окон, или замена существующих объявлений другими, а также реклама или установка программного обеспечения, которое выполняет эти действия.
o Добавление нежелательных файлов при загрузке содержания, запрошенного пользователем.
o Установка вредоносного ПО, троянских программ, шпионского ПО, рекламы или вирусов на компьютер пользователя.
o Изменение домашней страницы в браузере или настроек поиска без ведома и согласия пользователя.
· Некорректное использование разметки для расширенных описаний веб-страниц.
· Автоматические запросы в Google.
Заметьте, что начинающему вэб-мастеру нужно неистово «стараться» для того, чтобы его сайт попал под бан поисковой системы.
Google редко применяет репрессивные меры, исключая из индекса сайты, ограничиваясь пессимизацией — искусственным понижением в позиции поисковой выдачи.
Для этого специалисты интернет гиганта предусмотрели несколько основных алгоритмов.
Фильтры
Если человек на машине, нарушает правила дорожного движения, мешает другому транспорту, создавая опасную ситуацию на дороге, то это считается очень плохо. Если такого нарушителя останавливает полиция, штрафует его, ставя нарушителя тем самым на место, то это считается нормой.
Если же Google ставит нарушителя правил на место, то это почему-то называется пессимизацией. Мне кажется, что все-таки более правильно называть действия Google определение более точного положения сайта в рейтинге.
Реально Google редко кого штрафует, и это происходит после ручной проверки. Понижение же в рейтинге — это усовершенствование алгоритма, который прежде не точно оцени истинное значение сайта.
Есть и искусственное понижение, настоящая пессимизация, когда Google не доверяет ещё не известному, или мало известному сайту, что в общем-то похоже на поведение человека, который вступает в общение с незнакомцем.
1 — Domain Name Age (возраст доменного имени)
Представьте, что к вам на улице подходит незнакомый человек, и начинает вам что-то рассказывать. Поверите ли вы ему? Уверен, что нет! Но в сети верят, потому что соприкосновение идет постоянно с сотнями неизвестных пользователю сайтов. Если культура поведения в быту диктует одни нормы поведения, то в сети бдительность утрачивается. Появляются сайты, которые направлены, чтобы обмануть человека.
Google пытается защитить доверчивых пользователей, и берет на себя некоторую ответственность, не доверяя молодым сайтам и понижает их рейтинг.
Google имеет доступ к регистрационным данным всех доменов, знает когда появился сайт, и как любой человек не доверяет новичкам. Сайт должен сначала зарекомендовать себя. Так Google борется с сайтами однодневками, которые приходят в сеть не с целью донести полезную информацию, или продать достойный товар конечному пользователю.
Первым фильтром, под который попадают все новые сайты, точнее доменные имена — это «Возраст доменного имени» (Domain Name Age). Этим фильтром Google ПЕРЕСТРАХОВЫВАЕТСЯ, и в течение года следит за новым сайтом.
Незначительно можно сократить действие этого фильтра, если покупать доменное имя не на год, а на пять лет. Это для Google хороший сигнал, что сайт не однодневка.
По оценкам разных компаний в 2018 году ежедневно создавалось от миллиона до полутора миллионов сайтов. И как показывает практика более 80% из них исчезают в течении первого же года. Ещё 10—15% из них не имеют развития.
В эти 95% сайтов входят:
· спамерские сайты, которые создаются для увеличения рейтинга основного сайта;
· мошеннические сайты, которые под благовидными предлогами выманивают деньги у пользователей;
· фишинг сайты;
· другие вредные, или бесполезные для пользователя сайты;
· сайты начинающих веб-мастеров, которые не приносят результат и закрываются через год по окончанию срока действия домена.
Именно поэтому Google, и не присваивает сайту на молодом домене высокий ранг. Соответственно и статьи на сайте, как ответы на вопросы пользователей имеют понижающий коэффициент рейтинга.
Покупка существующего несколько лет доменного имени увеличит вес веб-сайта и страниц при соблюдении определенных Google (м) формальностей.
2 — SandBox (песочница)
Даже если куплено доменное имя, но по мнению Google, сайт претерпел серьёзные изменения, особенно в тематике, то его ждет фильтр «Песочница».
«Барахтаться» в «Песочнице» можно от 3 месяцев до 1–2 лет.
Если же хозяин сайта решил поменять тематику сайта, или внес существенные изменения в структуру и подачу материала, кардинально поменял контент, то такому сайту также не избежать «Песочницы».
Чем менее популярен запрос, тем меньший коэффициент понижения веса страницы применяется.
Если же запросы высокочастотные, то понижающий коэффициент тем выше, чем популярнее запрос.
Как и с новым сайтом требуется провести внутреннюю оптимизацию сайта, связав страницы тематическими ссылками, заполнить уникальным и полезным материалом.
Выйти из песочницы помогает контекстная реклама в Google, если поисковик видит, что, кликая по рекламе, пользователь получает желаемый ответ на свой вопрос. Только так можно «внушить» Google, что веб-сайт качественный.
Google не индексирует все страницы сайта за один заход. Как утверждают эксперты, Google «просматривает» сайт определенное алгоритмом количество времени, и забирает на индексацию столько страниц, сколько успеет. Поэтому скорость загрузки страниц сайта существенно влияет на количество индексируемых страниц новому сайту. (А далее время, уделяемое на индексацию сайта, зависит от периодичности и объема добавления новой информации.)
Когда все страницы сайта проиндексированы, он Google анализирует весь сайт на качество и полезность. Не уникальные тексты, картинки, тексты ссылок, и пр. — факторы для понижения рейтинга сайта.
3 — Оver Оptimization (чрезмерная оптимизация)
К этим фильтру нужно быть особенно внимательно начинающим SEO-оптимизаторам, по неопытности думающим, что чем больше ключевых фраз в тексте — тем лучше.
Ещё с древних времен считается, что чем больше раз поисковая ключевая фраза будет записана на странице, тем лучше.
Начинающие копирайтеры и оптимизаторы пишут примерно так:
«Наши пластиковые окна самые лучшие из всех пластиковых окон, которые продаются на рынке пластиковых окон у нас в городе. Покупайте у нас пластиковые окна, и убедитесь, что мы лучшие поставщики пластиковых окон, потому что наши пластиковые окна будут служить дольше, чем любые другие пластиковые окна, купленные в нашем городе.»
Google видит, что такие тексты не естественные, и такой текст не понравится пользователям, а значит не вызовет доверия, а значит у такого продавца никто не станет покупать.
Зачем показывать первым такой сайт, если есть сайты, написанные более человеку понятному языком. Естественно, такой текст Google считает не качественным и не авторитетным.
Как и везде при написании текстов нужна мера.
Просмотрев миллионы сайтов было определено, что нормальное количество поисковых клещевых фраз в качественном тексте составляет 3—5% от общего количества слов на страницы. Тексты в тегах, в заголовке и описании страницы, ALT и TITLE учитываются при расчете.
Это значит, на сто слов текста ключевое слово должно быть 1 раз
· в заголовке странице,
· в заголовке текста на странице,
· в начале статьи,
· в подписи к картинке,
· и еще, например, в подписи гиперссылки.
Все, что сверх этого — пере оптимизированный текст. С одним словом — просто, но когда в страница оптимизируется под ключевую фразу, состоящую из несколько слов, или даже оптимизация делается под несколько ключевых фраз (а такие страницы имеют больший вес в Google), то произвести точный подсчет не так просто.
SEO-специалисты разработали несколько вариантов методик подсчета, например подсчитать количество знаков в ключевой фразе, и сравнить с общим количеством знаков в тексте.
Google не раскрывает по каким правилам поисковик определяет этот злополучный процент.
Также не известно при таком подсчете Google учитывает или нет стоп, или шумовые слова. Поэтому лучше не заморачиваться на подсчетах, чтобы подогнать результат, а писать простым, человеческим языком, уделяя тому, чтобы статья была интересна, легко читаемая и полезная.
Лучшего результата можно добиться как должна быть оптимизирована страница, и какие LSI фразы следует использовать — посмотреть ТОП 5 конкурентов по выдачи, по этой фразе.
Любителям же математической статистики считать вручную плотность ключей в тексте не нужно, ведь для этого есть масса бесплатных программ.
И не забывайте о LSI словах, и других окружающих элементах, которые очень важны.
4 — Сocitation linking filter (плохое соседство)
В жизни формируют мнение о человеке не только по внешнему виду, но и по его окружению: по друзьям, и по другим людям, с которыми он постоянно общается.
Также и Google ориентируется на окружение сайта: на какой сайт ведут ссылки с этого сайта, и кто на него ссылается.
Это один из критериев определения авторитетности сайта.
Фильтр CO-citation Linking накладывается на сайт, если ресурс содержит ссылки на:
— низкокачественные сайты, по мнению Google,
— сайты начинающих веб-мастеров,
— сайты с неодобренным содержанием, например, порно сайты,
— спамерские сайты, которые создаются для увеличения рейтинга основного сайта;
— мошеннические сайты, которые под благовидными предлогами выманивают деньги у пользователей;
— фишинг сайты;
— другие вредные, или бесполезные для пользователя сайты;
— сайты с информацией о самодельных взрывных устройствах, наркотиках и т. п.
Поэтому, обращайте внимание не только на сайты своей тематики, но и убедитесь, что на сайт, на который вы ссылаетесь — доброкачественный, и чем он более авторитетный, тем лучше.
Сайт акцептор в этом случае не страдает санкциями от Google.
5 — Too Many Links At Once Filter (Ссылочный Взрыв, Свечка)
Часто молодые хозяева сайтов любители получить все за один день могут посетить несколько десятков сайтов, на которых что-либо написать, и поставить ссылки на свой сайт.
Горячие оптимизаторы, могут закупить на сайт несколько десятков или даже сотен ссылок, за короткий промежуток времени.
Все это вредно для сайта, особенно молодого, потому что Google считает, что естественным путем так быстро не может расти ссылочная масса. Еще более не правдоподобно для Google, когда в один день, или короткий промежуток времени ссылки добавлялись десятками или сотнями на разных сайтах, а потом наступило затишье.
Исследуя миллионы сайтов в разных отраслях, Google уже определил как быстро и в какой тематике набирается и теряется ссылочная масса.
Основная функция фильтра — фиксирование скорости увеличения или уменьшения ссылок (так называемых волн), приводящих на сайт. Быстрое, а значит не естественное увеличение ссылочной массы, фиксирует фильтр Too Many Links at Once Filter.
Если фильтр замечает волновое увеличение ссылочной массы, то перестает учитывать приводящие на сайт ссылки. По-моему, справедливо отдавать предпочтение сайтам, которые работают над качеством контента, а не сайтам, которые гонятся за наращивание ссылочной массы.
Искусственно наращивать ссылочную массу очень быстрый и дорогой вид продвижения, который отслеживает этот фильтр, и борется с нечестностью.
Борьба с покупными ссылками приоритетное направление у всех поисковиков, поэтому часто значительно проседают сайты, у которых основной вид продвижения — покупные ссылки.
Наращивание ссылочной массы таким путем имеет и оборотную сторону. Если средства у владельца сайта заканчиваются, или по какой-либо другой причине, он не в состояния больше оплачивать дорогие ссылки, то это также хороший сигнал для Too Many Links at Once Filter, чтобы пессимизировать сайт.
Также нужно медленно и отказываться от покупных ссылок, чтобы этот процесс выглядел как бы естественным. Быстрое снижение ссылочной массы также отрицательно влияет на рейтинг сайта.
Для Google в первые месяцы нового сайта естественным приростом внешних ссылок не должно превышать количества уникальных и качественных страниц на сайте.
В дальнейшем естественный прирост ссылочной массы не может превышать 10%.
Это значит, что, если на сайте 20 страниц за первые месяцы его существования максимально может появиться 15—20 ссылок с других сайтов. А далее по 1—2 ссылки в месяц. Причем в 20 страниц не входят страницы «Контактов», «О нас», «Наши сертификаты», «Партнеры» и подобные.
Google считает, что вышеперечисленные страницы нужны и поднимают авторитет сайту, но ссылки на такие страницы не имеют веса. Кроме этого не имеют веса коммерческие, спонсорские и подобные ссылки, ведущие в интернет магазин, или другую продажу.
Количество ссылок, ведущих на сайт при естественном приросте, не может быть скачкообразным волновым. Естественно увеличение или уменьшение количества ссылок не может быть равномерной: в один период их будет чуть больше, в другой — чуть меньше. Поэтому Google рассчитывает среднестатистическую погрешность, даже авторитетных и крупных сайтов.
Фильтр Too Many Links at Once Filter постоянно совершенствуется, всё лучше и лучше учится находить покупные ссылки, и уже делает их бесполезными, они не получают вес.
А для перестраховки (но не наказания) отключает вес даже тех ссылок, которые были получены естественным путем.
Фильтр проводит пессимизацию не только при не естественном приросте, но и при неестественном уменьшении.
Фильтр «Ссылочный взрыв» прекрасно понимает, что резкое уменьшение ссылок происходит, когда было закуплено много ссылок, но у хозяина сайта произошло ограничение бюджета, и он перестает закупать ссылки.
Вывести сайта из-под этого фильтра — наиболее сложная задача, чем вывод из-под других фильтров.
6 — Bombing (бомбардировка)
Если на сайт ведет много внешних ссылок с одинаковыми ALT и / или TITLE, и / или одинаковым текстом описания ссылки, то фильтр Bombing не учитывает эти ссылки, и не добавляет вес страницы. Из-за этого вес страницы может, обнуляются. Даже если несколько друзей решило сделать вам подарок, и проставили одну и ту же ссылку на вашу страницу со своих сайтов.
Google считает такие ссылки не естественными, и пессимизирует только те страницы, на которые ведут эти внешние ссылки. Поисковик понимает, что такие ссылки получаются при бездумном или автоматическом добавлении, а значит и не могут быть естественными.
Даже если автор вручную копирует и вставляет ссылку на разных сайтах, то это не меняет отношение Google. Для поисковика каждая ссылка должна быть уникальная, продуманная и быть связующим звено материала на сайте донора и акцептора.
Повторюсь, что поисковики желают видеть уникальный текст и помогать решить определенную задачу. Ссылка же должна вести на уточнение, на расширение понятия, описываемого в тексте. Поэтому и все атрибуты ссылки должны быть уникальными. Только тогда они имеют ценность для пользователя.
Как вы уже знаете, не Google, и ни какой другой поисковик придумал эти правила, а потребители контента так рассуждают, а поисковые системы формализовали этот факт в виде фильтра.
Удаление не качественных ссылок возвращает веб-страницы на прежние позиции в результатах поиска. Но это требуется делать разумно, планомерно и не спеша.
Быстрое же удаление ссылок приводит в действие другой фильтр — Too Many Links at Once Filter, который в этой книге расположен перед этим фильтром.
7 — Broken links (битые ссылки)
Этот фильтр — один из многих, который определяет качество сайта.
Любой развивающийся сайт, со временем претерпевает некоторые изменения. Некоторые страницы добавляются, некоторые изменяются, удаляются или переносятся. Страницы же сайта, как правило, связаны ссылками, и при переносе или удалении даже одной страницы случается так, что несколько или несколько десятков страниц сайта имеют ссылки на удаленную, или перемещенную страницу.
Поэтому получается, что несколько ссылок ведут на несуществующую страницу.
Бывает и так, что при создании сайта недодумано, могут генерироваться страницы с ошибкой 404.
Самый простой и распространенный пример. Программист устанавливает календарь событий компании, на котором пользователь может выбрать любую дату, месяц и год, чтобы посмотреть новость компании этого дня.
Но забывает закрыть доступ к тем датам, когда компания ещё и не существовала. Так пользователь может открыть любой год, например, 1001, или 11, и естественно получить страницу с ошибкой 404.
Разумному человеку вряд ли придет в голову посмотреть события компании в начале первого тысячелетия, но алгоритм, без эмоций выполняет свою работу.
У поисковика алгоритм — обойти все ссылки. Робот и обходит все, а для нашего примера это
2022 х 365 +505= 738 535 не рабочих ссылок, которые ведут на несуществующие страницы.
Ссылка, которая ведет на несуществующую страницу, называют битой. Обычно пользователю в этом случае выдается страница с кодом ошибки 404.
Ошибка 404 или Not Found («не найдено») — стандартный код ответа HTTP о том, запрашиваемая страница не найдена. (Ошибку 404 не следует путать с ошибкой «Сервер не найден» или иными ошибками, указывающими на ограничение доступа к серверу.)
Если сайт с таким календарем имеет несколько десятков страниц, то не сложно подсчитать отношение «хороших» и «плохих» страниц, а это хороший прирост к отрицательному определению качества сайта.
Кроме этого робот-паук должен обойти все страницы сайта, и если он «застрянет» на таком календаре, то хорошие страницы будут еще долго не индексированы.
Другая распространенная причина получения битых ссылок — перенос материала из одной категории в другую. Этим обычно страдают интернет-магазины.
Если битых ссылок на сайте много (величина или процент, который определяет, что битых ссылок много — коммерческая тайна Google), то Google считает этот сайт низкого качества, а поэтому его не стоит показывать пользователям, и пессимизирует его.
Перед запуском сайта нужно убедиться, что на веб-страницах нет битых ссылок, т.е. ссылок, которые никуда не ведут.
8 — Links (обмен ссылками)
Ранее среди веб-мастеров и хозяев сайтов было модно обмениваться ссылками, т.е. размещать ссылки на своем сайте на другой сайт, а тот в сою очередь делает то же самое.
Поисковики такой вариант увеличения ссылочной массы считают искусственным, и перестали учитывать такие ссылки. Если обмен ссылками был с большим количеством сайтов, то можно дополнительно получить наказание в виде понижения в рейтинге выдачи.
Links — применяется также к сайтам, содержащим страницы обмена ссылок с другими ресурсами. Такие страницы обычно называют полезными страницами, что на первый взгляд кажется правильным.
Но представьте такой вариант. У меня туристическая фирма, и я продаю путевки в разные страны и города. Для удобства пользователя на сайте создаю страницы для каждого курорта, где прописываю полезную информацию по этому месту отдыха. Например, даю ссылки на сайты: где заказать машину, экскурсовода, музеи, места, где вкусно готовят, и многое еще чего, что может пригодиться в незнакомой местности. В ответ, в качестве благодарности, все эти сайты делают ссылки на мой сайт.
Вся предоставляемая мной информация — полезна пользователям? Безусловно! Но поисковики считают такие страницы спамными. Кроме этого, чтобы не попасть под этот фильтр, если ссылка ведет на прайс-лист, или другое финансовое предложение, то Google разработал специальные атрибуты для гиперссылки, который указывает, что это коммерческая или спонсорская ссылка. Ссылки с такими атрибутами не учитываются, поэтому не учитываются и не могут навредить сайты. Их и требуется устанавливать в таких случаях.
Противоречиво, не справедливо, но это — объективная реальность на данный момент.
Под этот фильтр попадает обмен ссылками с доморощенными каталогами, которые предлагают за установку баннера их каталога размещать у себя ссылки на сайт.
Теперь если же на одной страницы сайта появляется 4 или более ссылок на сайты «партнеров», то велика вероятность попасть под пессимизацию фильтра Links.
Но если вы пишете хорошую статью, и в статье ссылаетесь на выводы нескольких авторитетных сайтов, то в этом случае сайт не попадает под этот фильтр, а наоборот — увеличивает свой вес.
Google считает, что одним из признаков авторитетности статьи — ссылки на первоисточники. В этом случае, если на странице 4 и более ссылок на авторитетные издания, то Google добавляет вес к авторитету сайта. Такой шаг Google считает, что ссылка помогает углубить изучение вопроса, в котором заинтересован пользователь.
Подчеркну, что Google не учитывает обмен ссылками. Лучше сослаться на авторитетный сайт самому, чем искать, с кем можно обменяться ссылками.
9 — Page load time (время загрузки страницы)
Фильтр Page load time проверяет, как быстро загружается сайт на различных гаджетах.
Если сайт долго загружается, то есть вероятность, что пользователь не дождется окончательной загрузки, то для этого фильтра — это сигнал, чтобы понизить рейтинг сайта на таком устройстве.
В самом деле, зачем пользователю показывать сайт, который на его устройстве будет грузиться долго, в то время как сотни подобных сайтов загружаются быстро. Особо щепетильно Google относится к загрузке страниц сайтов на мобильные устройства.
Каждый разработчик после того как собрал сайт, если желает, чтобы сайт высоко позиционировался в Google проверит скорость загрузки своего творения на тестирующие Google — PageSpeed Insights, чтобы убедиться, что скорость загрузки его шедевра удовлетворяет требованиям поисковика. Если же скорость загрузки низкая, то требуется выполнить там же предлагаемые рекомендации.
Заметьте, что Google никого и ничего не заставляет делать, он принимает всех, только выстраивает в рейтинге как считает нужным. Но Google дает рекомендации, которые не сам придумывает, чтобы усложнить жизнь разработчикам.
Его рекомендации — это плод его исследований, и собираемой статистики. Google бесплатно делится ими, чтобы помочь нам сделать свой веб-проект как можно более полезным конечному потребителю.
Но вернёмся к скорости загрузки веб-сайта.
Кроме медленной скорости работы сервера (что сейчас редко встречается), может быть очень большой объем загружаемой информации.
Это может быть километровые CSS файлы, скрипты, которые лучше подгружать позже, или скрипты в основном несущие только дизайнерскую «красоту» и эффекты, а также огромные картинки, которые в своем объеме практически не нужны. На все, что может снизить время загрузки, на исследуемом сайте Google сразу же указывает в своих рекомендациях, поэтому разработчик сайта обязан устранить все указанные недочеты…
Но скудные знания многих «программистов», тех, которые разрабатывают сайты на известных системах управления сайтами, не позволяют сделать это… А скорость загрузки сайта — один из приоритетных факторов при ранжировании сайтов.
Здесь и большая вина заказчиков сайтов. Они, как правило, желают по максимумы получить навороченный сайт. Но все навороты сводятся к усложнению дизайна: всякие всплывающие, динамические элементы, большие графические вставки существенно увеличивают время загрузки веб-страницы.
Возможно, провести сравнение крысы и белки. Белка — тюнингованная крыса, а заказчик желает получить белку, на которой дополнительно надеты наряды.
Google еще не понимает, хорош или плох дизайн, пользователю приятнее смотреть на белку. Поэтому мастерство разработчика сайта должно найти золотую средину между белкой и крысой.
Ведь, если пользователь пытается просмотреть сайт на своем мобильном устройстве, при оплате за трафик, для него тяжелые сайты — расточительны, поэтому тяжелая версия сайтов в Google считается недопустима. Так Google заботится о своих пользователях.
Если скорость загрузки страницы сайта больше 2—3 сек., то сайт может иметь существенную пессимизацию.
Здесь действует принцип — чем быстрее открывается веб-страница, тем лучше. Статистика показывает, что пользователи не готовы ждать открытия страницы более 2—3 сек. Пользователи смартфонов ещё более не терпеливы.
10 — Omitted results (упущенные результаты)
Если на сайте:
— много дублей страниц;
— мало уникального контента;
— много похожих фрагментов на разных страницах;
— мало ссылок на другие страницы сайта;
— нет внешних ссылок на авторитетные сайты;
То велика вероятность попасть под Фильтр Omitted results.
Честно говоря, мне не нравится стандартный оборот: «попасть под фильтр», мне кажется, что слово «выбраковывается» более точно подходит.
Дубли страниц часто возникают в системах управления сайтом (СМС), когда добраться до одного материала можно несколькими способами.
Например, до статьи можно добраться через раздел «Последние статьи», и через раздел, к которому приписана эта же статья. В интернет-магазинах один товар можно открыть в нескольких категория. И в каждом случае прописываются разные адреса одной веб-страницы.
Более подробно о дублях страниц, и как их избегать будет рассказано в другой части книги.
Малое количество уникального контента, т.е. основная часть текстов скопирована с других сайтов. Здесь не имеет значение, копирован текст с одного сайта, или была солянка фрагментов с разных сайтов.
Много похожих фрагментов на разных страницах, когда на веб-странице вместо гиперссылки на другую страницу сайта дублируется текст. Это распространено в интернет-магазинах, когда схожие товары имеют одно описание.
Этим грешат и компании, у которых несколько филиалов. Чтобы набрать больше страниц, они для каждого филиала создают отдельные страницы с длинными, или не очень длинными текстами. И вся разница в том, что в текстах меняется только адреса, телефоны, да время работы.
Так же плохо, когда дублируется текст на нескольких страницах.
Не желательно копировать фрагменты текстов с разных источников, которые в этом случае идут в минус. Для этого нужно пользоваться тегами цитаты.
Для Google хороший сигнал качества, когда в тексте он видит тег <blockquote> для длинных фрагментов текста, и тег <q> для коротких цитат, с указанием первоисточника.
Google считает, что пользователям удобнее прослеживать одну мысль от начала до конца на одной странице. Если же требуется расширить изложение в подтверждении фактов, или развить тему с уводом излагаемого в сторону, то нужно делать гиперссылку на все разъяснения и отклонения. Не желательно валить всё в одну кучу, у себя на веб-странице.
Например, в биографии знаменитости, в описании, где учился, может быть достаточно, указать только название университета со ссылкой на описание истории этого университета, а не валить все в кучу.
Так пользователь быстро получает ответ на свой вопрос, а дополнительные разъяснения — это ответ на другой вопрос, а значит должна быть и другая страница.
Или другой пример. На запрос пользователя: «Где учился Лермонтов» пользователь вероятнее всего хочет получить информацию о наиболее значимом учебном заведении поэта.
В большинстве случаев пользователю будет достаточно написать «Московский государственный университет имени М. В. Ломоносова». Но для расширения ответа перечислить другие места его образования, поставить внешние ссылки на действующие сайты, и сделать внутренние ссылки на страницы описания учебных заведений, которых уже нет.
Чем больше в тексте гиперссылок на авторитетные сайты, тем больше сигналов для Google, что контент — качественный.
Если в статье излагается полезная информация — факты, то наилучшим подтверждением справедливости написанного текста будет ссылка на авторитетный сайт, который подтверждает это, чем самому дублировать качественный контент.
Например, то, что Колумб родился в Австралии, возможно можно найти на каком-нибудь сайте с нулевым авторитетом. Google считает, что такой «факт» не заслуживает доверия. Но если в статье написано, что Генуя, Италия — место рождения Колумба, и море авторитетных сайтов утверждают это, то ссылка на один из таких сайтов увеличит рейтинг веб-страницы.
Какому заключению вы доверите больше: заключению бабушки, студенту, или практикующему специалисту?
Google как обычный человек доверяет тому больше, у кого выше авторитет.
Действие этого фильтра можно увидеть, если сайт отсутствует в результатах основного поиска, но виден в расширенном поиске.
11 — Фильтр —30
Фильтр — 30 накладывается на сайты за черные методы продвижения.
К ним относится: скрытый редирект, клоакинг, дорвеи, тексты, написанные цветом фона, и многие другие устаревшие уловки. Об этом более подробно написано выше, в этой главе.
Под этот фильтр попадают любые действия для повышения рейтинга, без повышения ценности страницы утверждает Google.
«Обратите внимание, что согласно нашему определению, все типы действий, предназначенных для повышения рейтинга (релевантности, важности или того и другого), без повышения истинной ценности страницы, считаются спамом».
(Таксономия веб-спама от Zoltán Gyöngyi & Гектор Гарсия-Молина)
Если не делать имитацию полезности, тем самым не нарушать правила, то этот фильтр не страшен.
12 — Additional Results (или Дополнительные результаты)
Этот фильтр Google пессимизирует страницы сайта, если считает их незначимыми для пользователя.
Значимость текста, как писал ранее — это в основном объемное и уникальное содержание с наличием LSI факторов.
В результатах выдачи страницы, которые Google посчитал не значительными ранжируются ниже, чем значимые, по мнению робота.
Самый распространенный метод поднятия рейтинга таких страниц добавить — входящих ссылок, с авторитетных сайтов. Но не забывайте, что ссылка с авторитетного сайта — это не гарантия увеличения ссылочной массы. Гарантией будет то, что люди переходят по этой ссылки, и получают ожидаемую пользу.
Но представьте, что на авторитетном сайте стоит ссылка в статье, которая утверждает, что на странице Васи Пупкина об этом рассказано более подробно. Google в этой ситуации верит людям, которые голосуют (кликают), или не голосуют (не кликают) за авторитетность этой ссылки.
13 — Page Layout Algorithm
(или количество рекламы)
Алгоритм, который определяет общее количество размещенной рекламы на сайте, и при её избыточности понижает рейтинг всего сайта.
Google заметил, что если рекламы раздражительно много на сайте, то люди покидают такие сайты даже с хорошим содержанием, не дочитывая тексты до конца.
Особенно этот фильтр отрицательно реагирует на рекламу, расположенную в верхней части страниц, которая по большей степени закрывает весь первый экран.
Google считает, что, открывая страницу сайта, пользователь сразу же хочет увидеть ответ на свой вопрос, заданный поисковику, а не рекламу.
Убийственно для пользователей открыть страницу с, казалось бы, ответом на свой вопрос, и увидеть, что весь первый экран забит рекламой, и требуется пользоваться полосой прокрутки, чтобы добраться до цели посещения этой страницы.
Пользователям проще считать, что Google тупит, не выдает качественные сайты, и перейти на другой результат поиска. Посетители отказываются искать ответ между рекламными площадками, им проще открыть другой сайт.
Ни для кого не секрет, что многие сайты создаются только для зарабатывания денег на рекламе, Google способствует этому, создав AdSense. Но считает, что для посетителя первична полезная информация, за которой пришел пользователь, а потом реклама, но обязательно по теме веб-страницы, на которой она стоит. Реклама должна быть как дополнительное расширения, как пояснение на его интересующую тему.
Например, человек зашел посмотреть как по симптомам, им указанным, лечить своего питомца. Пользователю не будет интересна реклама ремонта телефонов, или продажа женских сумочек. Но пользователя может заинтересовать реклама ветеринарной клиники.
У последней рекламы будет и больший отклик, и сам сайт пользователю покажется более полезным, что в конечном итоге оценит Google.
Так Google защищает пользователей от избыточной и не целевой рекламы.
14 — Pirate Algorithm (Пиратство)
Как уже говорилось не раз, Google отрицательно относится к копированию статей с других сайтов, он также отрицательно относится и к рерайту. По её мнению пользователям полезна только авторитетная и уникальная информация.
Можно даже уже видеть заявления, в котором говорится, что Google определяет, когда в тексте были переставлены, слова, слова заменены синонимами, и другие косметические изменения в тексте.
Кроме этого, Google прямо пишет в своем руководстве, что он распознает переведенные тексты с других языков, с использованием translate.google.com, и литературно не обработанный. И такой текст так же воспринимает как рерайт.
Не уверен, что по поводу синонимов, перестановки слов и переводов уже работает на все 100%, но уверен, что Google идет в этом направлении, и точность определения рерайта будет высочайшей, а поэтому не стоит пытаться зарабатывать дивиденды на чужом труде, даже если это ещё не полностью работает.
Более жестко Google относится, когда авторский текст, без изменения воруется с сайта, и перепечатывается на другом.
Google понимает, что на молодом сайте может появиться полезная статья, но быть проиндексированной на этом сайте позже, чем на другом, который уже приобрёл некоторый авторитет.
Если в этой ситуации применять правило: «Кто первый встал того и тапки», то значит, что поисковик поощряет пиратство, и молодым и перспективным сайтам никогда не пробиться в лидеры. Google же заинтересован, чтобы постоянно «вливалась новая кровь», чтобы поиск становился всё лучше и полезнее.
Фильтр Pirate Algorithm пессимизирует сайты, которые нарушают авторские права.
Google предлагает заявлять на контент свои авторские права через Google+, первоначально публикуя материал там. Но закрытие этой сети для физических лиц для многих авторов усложняет задачу закрепления авторских прав.
Остается один вариант — размещать статьи в социальных сетях, в надежде, что Google её там проиндексирует быстрее, чем на сайте конкурентов.
У Яндекса есть специальная форма для закрепления авторских прав.
У Google остается пока только одна форма, через которую правообладатель может подать жалобу. Но, как понимаете, подать жалобу и получить ответ, и получить положительный результат — это разные вещи.
Как говорится — обещать жениться и жениться — разные вещи.
15 — Gluing (Склеивание)
Google отслеживает не только авторский текст, но следит и за тем, что написано в анкорах (тексты ссылок, которые располагается между открывающимся тегом <a> и закрывающим тегом </a>), а так же к подписям к изображениям и видео.
Обычно рассылается ссылка с анкором в разные источники: своим «партнерам», друзьям или подготавливается автоматическая, или ручная рассылка по разным каталогам.
Фильтр Gluing обладает алгоритмами определяющего, как ссылка ставилась осмысленно или просто размножалась.
Сайты же акцепторы на которых плодятся бездомные ссылки сами по себе выпадают из первых строк или страниц поиска.
Кроме этого фильтр Gluing не любит «безжизненные» анкоры-фразы типа «Смотри здесь», «Перейдите по ссылки» и пр.
Если просите друга поместить ссылку на страницу своего сайта, то используйте ключевые или LSI фразы, которые передают смысл, как бы ответ на вопрос, который мог бы заинтересовать пользователя.
16 — Link Washer (Линкопомойка)
Под действием этого фильтра оказываются сайты, на страницах которых содержится чрезмерное количество исходящих ссылок на посторонние ресурсы.
Вероятность, что к сайту будут применены санкции, резко возрастает, если на страницах имеется свыше 20 внешних ссылок. Google считает, что никакая, даже научная статья не может ссылаться на 20 и более авторитетных изданий.
Фильтр «Линкопомойка» может быть применён к отдельным страницам. Если таких страниц несколько, так понижению рейтинга может быть подвержен и весь сайт в целом. Это зависит от степени заспамлености.
Правильнее говорить, что не поисковик наказывает, а поисковик освобождает место для более достойных сайтов.
Google понимает, что не за все нарушения нужно безапелляционно наказывать сайты, и если хозяева сайтов удаляют не тематические ссылки, то после последующей индексации сайт переносится на соответствующее место в результатах органического поиска.
Для того, чтобы не попасть или выйти из-под этого фильтра:
1. Проведите технический аудит, составьте полный список ссылок, исходящих со страниц на посторонние и малозначимые ресурсы. Помните, что, ссылаясь не по теме и / или на неавторитетный ресурс, одним этим происходит снижение веса страницы.
2. Составьте список ссылок, имеющих наименьшую значимость для пользователей и поисковой системы.
3. Удалите наименее значимые ссылки так, чтобы на каждой странице осталось не более 5—7 внешних ссылок, при условии, что текст статьи не менее 8—10 тыс. печатных знака.
После того, как источник проблемы устранён, сайт после очередной переиндексации будет освобожден от фильтра в течение периода от 2 недель до 2 месяцев, в зависимости от того, как Google считает нужным повторно переиндексировать ваш сайт.
Частота же посещения сайта для переиндексации зависит от частоты обновления сайта и его авторитета. Если обновления сайта не происходит долгое время, то и поисковик заходит на сайт редко.
Если же сайт обновляется ежедневно, а пользователи подолгу изучают контент, то переиндексация сайта может происходить ежедневно.
Популярные же новостные каналы могут посещаться поисковиком по несколько раз в сутки, и индексировать все страницы.
17 — Sociating (Социтирование)
Как говорилось не раз, Google отслеживает, чтобы ссылки были качественными.
Под качественными ссылками следует понимать, что сайты из одной тематики, рассматривают одни и те же вопросы, а ссылка — это некоторое расширение ответа на возможный вопрос пользователя.
Например, ссылка получает дополнительный вес, если в статье рассказывается об установки пластиковых окнах, а ссылка отправляет пользователя на сайт производителя этих окон, на статью, в которой рассказывается, из какого пластика изготовляются эти окна. Если сайт производителя окон авторитетный, то статья установщиков получает дополнительный вес. Если сайт не имеет авторитета, и мнимого производителя, то такая ссылка бессмысленна.
Плохой вариант ссылки, которая попадает под Фильтр Sociating, например такой.
Интернет-магазин бытовой техники ссылается на сайт местного, хоть и авторитетного поэта.
Вес таких ссылок не учитывается напрямую, но Google видит нарушение или неправомерное расширение тематики сайта, и понижает рейтинг интернет магазина при тематических запросах.
Хороший вариант сайту бытовой техники ставить ссылки на сайты производителей брендов. Например, в разделе «Зарядки для ноутбуков Asus» поставить ссылку на официальный сайт Asus, на страницу.
И не просто на главную страницу сайта, а на страницу, на которой показаны модели ноутбуков. Ссылку (анкор) можно подписать: «Документация зарядок моделей ноутбуков Asus».
18 — Bowling (боулинг, козни конкурентов)
Особый фильтр — фильтр жалоб. Действие, этого фильтра могут спровоцировать конкуренты.
Например, что вы украли контент с их сайта.
И жалоба будет вполне обоснована, если сайт конкурента пере индексируется чаще чем ваш.
Происходит так. Вы размещаете свою авторскую статью, конкурент её копирует, и размещает на своем сайте. После чего пишет жалобу в Google о том, что вы украли у него статью. Если Google первым проиндексировал копию конкурента, то вы уже точно потеряли статью, а ваш сайт получит пессимизацию.
Чтобы избежать такой ситуации перед публикацией статьи на сайте опубликуйте её часть в нескольких социальных сетях, со ссылкой на продолжение статьи на своем сайте.
Для этого хорошо подходит Дзен.
Но с дзеном — беда. Яндекс воспринимает, как будто оригинал находится на Дзене, и ее высоко позиционирует, а статья на сайте проваливается в результатах поиска.
Для закрепления авторства контента молодому сайту в Google, самым надежным способом, при публикации статьи, дать в Google контекстную рекламу на веб-страницу, на которой размещен этот материал.
Так вы хотя бы по дате публикации сможете доказать своё авторское право.
Другой вариант: написать статью в гостевом блоге, или каталоге, у которого высокая частота переиндексации, и в этой статье поставить ссылку на свою новую статью. Если выбрали правильную, часто индексируемую площадку, то авторское право будет закреплено за вами.
Более рискованно сразу после публикации статьи сразу купить ссылку на эту статью.
Ни один из перечисленных способов не гарантирует на 100% закрепление авторства за вами, но лучше что-то делать, чтобы увеличивать свои шансы.
Другой способ подгадить чужому сайту — писать на него отрицательные отзывы интернет-площадках.
Работают отрицательные отзывы, написанные и на других ресурсах, и величина пессимизации зависит от авторитетности площадки, на которой был написан отзыв.
В этом случае пара отрицательных отзывав не сделают погоды, но успокаивают жалобщика. А вот сотня негативных отзывав может существенно испортить репутацию.
Конкуренты могут писать отрицательные комментарии на вашем сайте, делать посты, не относящиеся к теме сайта, и ещё многое другое.
Мелким компаниям не следует этого бояться, но знать о том, что конкуренты могут повлиять на ваш веб-ресурс подлым образом. Но это нужно знать обязательно, чтобы отслеживать и вовремя пресекать происки конкурентов.
Постоянно надо отслеживать статистику сайта, и немедленно реагировать, обращаясь в поддержку Google.
19 — Supplemental Results (дополнительные результаты)
Робот Google индексирует все, что найдет на сайте, и все данные передает на анализ в фильтр Supplemental results. Этот фильтр разделяет проиндексированные страницы сайта на хорошие и плохие.
Страницы, которые Google считает хорошими, попадают в основной индекс.
Страницы же, которые Google посчитал плохими, попадают в дополнительные результаты.
Страницы сайта, не прошедшие через сито Supplemental results никогда не попадают в органический поиск. Google никогда ранее признанную страницу плохой не меняет своего мнения.
Если плохих страниц на сайте много, то Google считает сайт бесполезным пользователю, и никогда его не показывает. В этой ситуации не стоит пытаться улучшать что-либо. Единственный выход — закрывать сайт, и учитывая ошибки создавать новый.
В дополнительные результаты попадают:
В первую очередь, дубли страниц сайта.
О дублях страниц более подробно читайте в «Дубли или копии страниц на сайте».
Во-вторых, не корректное, или полное игнорирование основных тегов страницы (Title, Description). Если проигнорированы Title, Description и на страницы нет заголовка Н1, то это гарантия того, что сайт попадает под Supplemental results.
В дополнение замечу, что, хотя Google объявил, что перестал учитывать ключевые слова, но стоило нам на одном из сайтов, написать ключевые фразы, чтобы определиться со стратегией, как этот сайт вышел на первую страницу. Повторюсь, добавили только ключевые слова в мета–тег keywords, и всё. Возможно это совпадение, с каким-либо другим событием, или пришло время сойтись звездам. Но не стоит лениться, и поэтому заполняйте все имеющиеся мета-теги. Уж точно — хуже не будет, а плюсы — повысится качество сайта.
В-третьих, не достаточный вес у страницы. Если сайт содержит сотни или тысячи страниц, расположенные на 4-5-6 и т. д. уровнях и к ним добраться с 4-5-6 и т. д. клика, то будьте уварены, что такие страницы попадут в дополнительные результаты, потому что даже хозяин сайта считает их малополезными.
А для поисковика — чем выше уровень размещения статьи, тем он более значимый. Все же материалы ниже третьего уровня, для поиска считаются малозначимыми.
В-четвертых, если страница сайта не имеет обратных ссылок, нет качественного контента, то и такая страница может быть отнесена к дополнительным результатам.
Чем больше страниц сайта в дополнительных результатах, тем ниже авторитетность сайта, и тем ниже рейтинг всего сайта в результатах поисковой выдачи., что отрицательно влияет и на хорошие веб-страницы.
Поисковые роботы Google посещают страницы дополнительного индекса значительно реже, чем уже занесенные в индекс и поиск новых, поэтому лучше избегать попадания под действие фильтра Supplemental results, чем улучшать, или удалять «плохие» страницы, с надеждой, что скоро улучшенные страницы получат больший вес.
Дешевле сразу продумать интуитивно понятную структуру с пунктами меню, которые соответствуют запросам пользователей, чем после попадания в дополнительный индекс пытаться выводить сайт.
Обычному разработчику всё равно за что получать деньги, а вот хозяину сайта придётся платить дважды, если заблаговременно не позаботится о правильной структуре.
20 — Possum (Оппосум. Территориальное ранжирование)
Представьте распространенную ситуацию, когда в одном бизнес-центре находится 6 юридических контор, которые, судя по их сайтам, оказывают одни и те же услуги.
Если прежде все 6 компаний отображались в локальном поиске, то после введения Оссумума Google может показать в местном поиске только одну, или, возможно, две, юридические конторы вместо всех шести.
Для человека из 6 фирм выбрать одну, лучшую, практически не реально. Человек по природе своей в состоянии выбрать только из двух. Если ему приходится выбирать из трех, то выбор происходит следующим образом. Сначала сравниваются первые два, выбирается лучший, а затем выбранный и следующий. Уж так устроен наш мозг.
Гугл понимая это не совершенство мозга, создал свой искусственный интеллект, в помощь пользователю, оставив 2-е на выбор.
Только увеличив масштаб карты, или выбрав пользовательские фильтры, такие как «Лучшие», другие юридические конторы вновь появятся на прежних высоких местах в местном поисковике.
Но последнее кто будет делать?
В одном из примеров своего исследования MOZ отметил, что бизнес, расположенный слегка удаленно от географического скопления, подскочил с №21 до №10 в результатах локального поиска.
Это примечательно, поскольку в локальном поиске в SEO уже давно наблюдается, что компании, находящиеся за пределами района или города, имеют мало шансов, получить высокий локальный рейтинг по запросам, исходящих из этих районов или городов и содержащих названия этих городов.
В местном SEO было выдвинуто несколько дополнительных теорий о влиянии Опоссума. К ним относится увеличение чувствительности близости поисковика — расположения между физическим местоположением пользователя и предприятиями, которые Google показывает в результатах своих локальных пакетов.
Кроме того, есть мнение, что локальный фильтр Google работает более независимо от их органического фильтра после Опоссума, так как компании получают высокие рейтинги за списки, указывающие на страницы веб-сайтов с низким или «отфильтрованным» органическим рейтингом.
Помните, что Google всегда стремится показать наиболее релевантный веб-сайт конечному пользователю.
Улучшение общего локального SEO (включая полномочия домена, ссылки, контент, точность и распространение ваших ссылок, а также количество ваших собственных обзоров Google) может помочь «убедить» Google, что, если они собираются показывать только один бизнес в вашей категории и районе, он должен быть вашим.
Опоссум предоставляет хорошую возможность провести аудит конкурента, который не отфильтрован этим фильтром, чтобы увидеть, достигли ли они определенных показателей, которые делают их наиболее актуальным ответом Google.
Поскольку одним из триггеров для Опоссума является присутствие нескольких однотипных компаний географически близко расположенных друг от друга (например, кафе, или сувенирные магазины в исторической части города) и в одном месте, вы можете поэкспериментировать с изменением основной категории в Google Мой бизнес. (Сокращенное руководство по «Google Мой бизнес» см. в приложении. А полную версию этого руководства читайте в книге «50 руководств по SEO-оптимизации»).
Например, если ваша текущая основная категория — «Бар», и вы отфильтровываетесь, потому что эта категория также используется более сильным конкурентом около вас, вы можете протестировать переключение на «Пивной бар», если около вас нет ничего подобного.
Имейте в виду, что изменение категорий может привести к значительному снижению ранжирования, существенным колебаниям трафика и должно осуществляться только с четким пониманием потенциальных негативных воздействий и «Рекомендаций по представлению вашего бизнеса в Google».
Если же трафик уже упал до нуля из-за фильтрации, эксперименты могут оказаться единственным действующим средством для поднятия сайта в Google.
Поскольку Опоссум заложил основу для фильтрации списков на основе их общей принадлежности, это ставит под сомнение целесообразность составления списков для врачей и юристов, агентств недвижимости и аналогичных бизнес-моделей.
Учитывая влияние фильтрации, местной индустрии SEO необходимо продолжать изучать риски и преимущества списков, состоящих из нескольких специалистов, в том числе то, как диверсификация категорий Google может повлиять на результаты после Опоссума.
21 — Panda (Панда. Качество контента)
Фильтр Panda — один из самых известных фильтров, который анализирует качество контента. Этот фильтр может влиять на весь сайт, а иногда и на один раздел, такой как новостной блог на сайте.
Панда не склонна влиять только на отдельные страницы сайта. Если у вас есть сайт с хорошим контентом, но на нем есть страницы с небольшими текстами, или есть текст (фрагменты текста), которые дублируется на разных страницах, то фильтр Panda может вызвать проблемы с ранжированием всего сайта, а не только, по мнению фильтра на «плохие» страницы.
Конечно, Google не раскрывает действительные сигналы ранжирования, используемые в своих алгоритмах, потому что не желает, чтобы SEO-специалисты забывали о качестве выдаваемого материала на сайте и занимались играми в ублажения алгоритмов.
Кроме этого, алгоритмы постоянно усовершенствуются, как программистами, так и уже действующим искусственным интеллектом, и может возникнуть ситуация, что идеально оптимизированная статья под один набор алгоритмов через некоторое время окажется не уделом после ввода других, более тонких подстроек, и дополнений других фильтров.
Поэтому для личного определения качества созданного контента Google рекомендует ответить для себя на следующие вопросы. (Это мой вольный перевод с комментариями.)
— Доверили бы вы информации, представленной в этой статье?
— Эта статья написана экспертом или энтузиастом, который хорошо знает эту тему, или она более поверхностна?
— Есть ли на сайте повторяющиеся, перекрывающиеся или избыточные статьи на одинаковые или похожие темы с немного отличающимися вариантами ключевых слов?
— Будет ли доверительно пользователю предоставлять информацию о своей кредитной карте на этом сайте?
— Есть ли в этой статье орфографические, стилистические или ошибки в изложении фактов? Под фактическими ошибками подразумевается ошибки в изложении фактов. Существует в интернете общепризнанное, экспертное мнение, на которое следует опираться: все, что расходится с этими общепринятыми фактами, является ложью.
Например, ложным фактом является сообщение, что Великая Отечественная война началась в 1956году.
— Подходят ли темы к подлинным интересам читателей сайта, или сайт генерирует контент, пытаясь угадать, чтобы занять хорошее место в поисковых системах?
— Предоставляет ли статья оригинальное содержание или информацию, оригинальную отчетность, оригинальное исследование или оригинальный анализ?
Надергав обрывки статей с других сайтов, не стоит надеяться, что таким образом созданная статья получит высокий рейтинг.
— Предоставляет ли информация на странице существенную ценность по сравнению с другими страницами в результатах поиска?
Не поленитесь, прочитайте статьи ваших конкурентов статьи из первой пятерки поиска по ключевой фразе, по которой написана ваша статья, и убедитесь, что вы выдаете информацию более интересно и освещаете другие факты. Считайте, что место, на которое поставил Google вашу статью — это оценка качества, как со стороны поисковика, так и возможного пользовательского интереса.
Не забывайте о поведенческих факторах, которые скорректируют место в поисковой выдачи, в ответах на запросы пользователей.
— Какой контроль качества делается конкурентами, что вам сделать лучше?
— Описывает ли статья все стороны заданного вопроса лучше, чем это сделали конкуренты?
— Будет ли статья увеличивать авторитет всего сайта, и что уже сделано, чтобы сайт стал признанным авторитетом в своей теме?
— Является ли контент массовым производством, или подобный материал распространяется по различным сайтам, чтобы его отдельные страницы получали больший вес?
— Правильно ли отредактирована и отформатирована статья, или она выглядит неаккуратной или поспешной?
— Если бы вы интересовались вопросами, например, связанным со здоровьем, доверили бы вы информации с этого сайта?
— Признаете ли вы этот сайт в качестве авторитетного источника, когда его упоминают по имени?
— Предоставляет ли статья на сайте полное или исчерпывающее описание темы?
— Содержит ли эта статья глубокий анализ или интересную информацию, которая за гранью очевидности?
— Вы хотите добавить эту страницу в закладки, поделиться с другом или порекомендовать её людям интересующихся этой темой?
— Есть ли в этой статье слишком много рекламы, которая отвлекает или мешает основному содержанию?
— Возможно, ли будет увидеть эту статью в печатном журнале, энциклопедии или книге, или цитаты из неё?
— Являются ли статья короткой, несущественной или не имеющей полезной информации?
— Страницы создаются с большой осторожностью и вниманием к деталям, а не с вниманием к восприятию её алгоритмом Panda или другими фильтрами?
— Будут ли пользователи жаловаться, или ругаться при просмотре этой страницы?
— Получит ли пользователь, исчерпывающий ответ на свой вопрос, или ему придется искать уточнения?
Все статьи из первой пятерки положительно отвечают на эти вопросы. Если нет, что сейчас бывает очень редко, то у вас большие шансы стать первым в результатах поиска по этому вопросу. Чтобы быть выше в результатах поиска, нужно иметь более качественный контент. Это обязательное, но не гарантированное условие, потому как учитываются и другие факторы.
Написание алгоритма для оценки качества страницы или сайта является гораздо более сложной задачей, которая не ограничивается одним фильтром.
Надеюсь, что приведенные выше вопросы помогут понять, как Google подходит к оценке качества контента, и на этом основании пытается написать алгоритмы, которые отличают сайты более высокого качества от сайтов низкого качества.
Задумайтесь, что первостепенная цель Google размещать лучшее в первых ответах поиска, а, чтобы худшее случайно не пробилось вверх — Google сдвигает вниз ответы на запросы пользователей плохие материалы.
К счастью, только разработчики алгоритмов знают, где заканчивается работа одного фильтра, а где начинается работа другого, поэтому не стоит углубляться в названия алгоритмов. Лучше ответить себе на вышеописанные вопросы.
«Panda одно из примерно 500 улучшений поиска, которые мы разместили в этом году. Фактически, с тех пор как мы запустили Panda, мы развернули более десятка дополнительных настроек наших алгоритмов ранжирования, и некоторые SEO-оптимизаторы ошибочно предположили, что изменения в их рейтингах были связаны с Panda. Поиск — это сложное и развивающееся искусство и наука, поэтому вместо того, чтобы фокусироваться на конкретных алгоритмических настройках, мы рекомендуем вам сосредоточиться на предоставлении пользователям наилучшего материала.»
Амит Сингхал, сотрудник Google
А теперь рассмотрим доступные пользователям факторы, которые включены в алгоритм Panda.
Мало текста
Страницы считаются слабыми, если описание релевантного запроса на странице содержит не достаточно, мало текста.
Например, набор страниц, описывающих различные болезни, тех, которые часто запрашивают пользователи, но описание содержит по несколько предложений.
Чем более популярен запрос, тем Panda считает, что должно быть более развернутое описание.
Желаете, чтобы ваш сайт, по популярному запросу, был выше конкурентов в выдаче? Анализируйте контент этих конкурентов, и делайте свои описания более качественным.
Глупо надеяться, что Google в ответах на запрос пользователей поставит менее полезный материал выше, чем те, которые уже завоевавших авторитет.
Panda считает контент низкокачественным, поскольку контенту на веб-странице не хватает подробной информации.
Например, страница рассказывает о высокой надежности входной двери в квартиру, но в тексте нет слов, которые описывали бы надежность, таких как материал изготовления, толщина стального листа двери, замки, конструкция, покрытие, уплотнения, и т. д.
Если у конкурента на сайте, в ответе на запрос стоит текст длинной в 10 тысяч печатных знаков (Лонгри́д — букв. «долгое чтение» — формат подачи журналистских материалов в интернете), то никакой текст с несколькими сотнями печатных знаков не будет в ответах на конкретный запрос позиционироваться выше, даже если тысячи страниц ссылается на короткий текст.
Полный список функций, которые выполняет фильтр Panda — это закрытая информация. Кроме этого, не обнародуется специфика действий и других фильтров, поэтому возникают некоторые пересечения в действиях различных фильтров.
Например, об анализе на дубли или копии страниц говорится в нескольких фильтрах, но в открытом доступе нет информации о том, где заканчивается действие одного фильтра, а где начинается действие другого фильтра. Возможно, некоторые фильтры со временем утрачивают свою актуальность, пишутся другие алгоритмы, и включаются в новые фильтры.
Очевиден и тот факт, что созданные фильтры и саморазвивающийся искусственный интеллект — далеко не совершенны, и дают сбои, которые тщательно вуалируются их создателями. Это и понятно, какой производитель будет рассказывать отрицательные стороны своего продукта.
Уверен, что для оптимизации сайта такие тонкости особо не имеют принципиального значения.
Больше того они могут быть и вредны, потому что фильтры — это не стоячая вода, а бурно развивающиеся анализаторы, это наука, которую сейчас принято называть искусственным интеллектом. А как в любой науке есть свои теории, которые не всегда соответствуют истинному положению вещей.
Зачем обременять SEO-специалистов знаниями, которые каждый день изменяются, усовершенствуются? Может получиться, что казалось справедливым вчера, завтра окажется уже устаревшим.
Итак, продолжаем, на что Panda обращает внимание.
Дублированный контент
Скопированный контент, считается дублированным, если появляется в Интернете более чем в одном месте. Обычно поисковики считают, что оригиналом является тот текст, который ими был проиндексирован раньше.
Проблемы с копиями страниц также могут возникать на собственном веб-сайте, когда есть несколько страниц с одинаковым текстом, практически без изменений.
Например, компания, занимающаяся уборкой помещений в разных городах страны, может создать 10 страниц, по одной для каждого города. Очень здорово с точки зрения геозависимого поиска. Но содержание веб-страниц идентично для всех городов. Отличие страниц только в названии города, интервал времени прибытия для уборки и тарифы.
Низкокачественный контент
Если на странице отсутствует подробная информация, разъяснения термина, явления, и подобного, то такие страницы Google считает, не представляют ценности читателю. Опять-таки возвращаемся к сопутствующим словам, которые есть в текстах на уже зарекомендовавших себя сайтах.
Например, если вы описываете номера в своей гостиницы, то для полного понимания, насколько хорош номер, требуется описание всех предметов, которые находятся в номере, чтобы пользователь понимал какой комфорт, ему предлагается.
Или другой пример. Кулинарный рецепт трудно представить без описания, какие продукты туда входят, времени и методики их приготовления. Рецепт будет считаться более полным, если в него добавить калорийность, аллергены, дополнительные фотографии, или видео.
Недостаток авторитета достоверности
Контент, созданный со ссылками на источники, которые Google не считает авторитетными, не увеличивают вес страницы.
Представители Google неоднократно заявляют в различных изданиях, что сайты, нацеленные на то, чтобы избежать влияния Panda, попадают в черный список, и должны работать, чтобы стать признанными авторитетами в своей теме и отрасли. И не делать попытки обмануть этот фильтр.
Чтобы стать авторитетным сайтом пользователь на этом сайте должен чувствовать себя комфортно, чувствовать надежность и, если требуется предоставлять информацию о себе и своей кредитной карте.
Именно поэтому Google считает, что ссылки на неавторитетные сайты делает и сайт донор не авторитетным.
То же самое, когда не авторитетный сайт ссылается на более авторитетный сайт, то авторитетный сайт делится своим авторитетом, но это уже действие другого фильтра CO-citation Linking Filter.
Более подробно об определения авторитета сайта читайте в книге «5000+ сигналов ранжирования в поисковиках».
Большое количество некачественных страниц
Здесь под некачественными страницами имеется ввиду, что материал собран с различных не авторитетных сайтов слабо подготовленным копирайтером.
В результате получается большой набор маленьких не авторитетных статей с низкой ценностью для читателей, которые в общей сумме являются понижающим фактором веса всего сайта.
В этом случае Google считает, что страницы создавались, чтобы охватить, как можно больше ключевых фраз с целью получить высокий рейтинг по многим запросам.
Google считает, что если страницу можно показывать по различным пользовательским запросам, то — это качественная страница.
Чем на большее количество вопросов отвечает веб-страница, тем она более качественная, и её нужно выше ранжировать.
НИЗКОКАЧЕСТВЕННЫЙ ПОЛЬЗОВАТЕЛЬСКИЙ КОНТЕНТ (UGC)
UGC (User-generated content или пользователями сгенерированный контент — совращение, введенное Google) — это оригинальный контент, который создается большим количеством наемных авторов, для продвижения какого-либо бренда.
Этим контентом может быть все, что угодно это материал, размещенный на сайте или в социальных сетях для продвижения своего бренда. Часто UGC контент оказывает намного большей эффективностью, чем обычный. Справедливо и обратное, — плохой пользовательский контент оказывает отрицательное влияние на вес страницы.
Основные виды UGC контент.
— Посетители могут оставлять свои сообщения под новостями, статьями, изображениями и т. п.
— Актуальны для интернет-магазинов отзывы, рейтинги. После покупки товара клиент может оставить запись о нем. Более 60% покупателей сначала читают отзывы, а уже потом покупают товар.
— Обзоры. Отзывы, содержащие фото или видео-доказательную базу.
— Контент, появляющийся на конкурсах. Довольно интересен такой пользовательский контент, если вы проводите конкурс фотографий, стихов, произведений и т. п.
— Фотографии и видео. Многие люди желают поделиться фото своего ребенка на детском сайте или видео отчетом о путешествии на туристическом ресурсе.
— Форумы. Посетители сайта общаются друг с другом под надзором модераторов.
Примером низкокачественного пользовательского контента может служить блог, в котором публикуются короткие записи гостевого блога, полные орфографических и грамматических ошибок и не имеющие достоверной информации.
Под фильтр низкокачественного пользовательского контента попадают и покупные отзывы, если, конечно, их «заметила» Panda. Покупными отзывами могут считаться разноплановые отзывы одного человека на работу или продукты в разных регионах. Например, человек в разных фирмах покупает холодильники для домашнего пользования. Или в Омске покупает телевизор, в Новгороде — стиральную машину, а в Подольске — грузоподъемник для склада.
Знаком случай, когда сайт, продаваемый квартиры в новостройке, потерял сильно в рейтинге после публикации нескольких десятков отзывов на одном и том же сайте.
Причем эти отзывы писал человек, который покупал диваны, холодильники, и др. бытовую технику в разных городах России.
Много рекламы
Очень часто создаются сайты для получения большого трафика, или создания иллюзии большого трафика, а затем набирается большое количество рекламы других сайтов.
Panda без труда определяет рекламные блоки на сайте, насколько они соответствуют тематике сайта. Если алгоритм считает, что рекламы много и вдобавок из другой тематики — вводит понижающий коэффициент рейтингу сайта. Чем больше рекламы на сайте, тем больше уменьшается вес страницы.
Panda не любит многократные врезки в текст, что отвлекает пользователя от чтения ответа на свой вопрос, и постоянно сбивает его от главной мысли.
Точное процентное соотношение рекламы к тексту — коммерческая тайна Google, но известен принцип — чем меньше, тем лучше.
Да, Google коммерческая организация, которая зарабатывает на рекламе, и можно считать, что любая реклама, не исходящая от Google вредна веб-сайтам с позиции Google.
Впрочем, известны случаи, когда Google наказывал за чрезмерное размещение рекламы от Google AdSense.
Для Google в приоритете, чтобы пользователь, перешедший из его поиска на сайт, получил ответ на вопрос, который задал поисковику, а не кликал по рекламе.
Некачественный контент вокруг партнерских ссылок
Panda относится подозрительно к ссылкам партнерских программ.
Плохими считаются ссылки, которые имеют не точную формулировку, или не соответствие текста ссылки и веб-страницы, куда делается переход. Это чаще всего несоответствие тематик сайта донора и акцептора. Такие ссылки не учитываются.
Отвлеченный текст ссылки от содержания, указывающих на платные партнерские программы, отличный сигнал, для Panda, что ссылка куплена, вес ее не учитывается, а страница получает понижение веса.
Однако по наблюдениям установление партнерской программы Google AdSense в некоторых случаях увеличивает ранг сайта.
Сайты, заблокированные пользователями
Google предложил пользователям Chrome, самостоятельно отфильтровать поисковый спам, установив специальное расширение в обозреватель. Так поисковый гигант предлагает своим пользователям понижать в рейтинге не качественные сайты и контент-фермы (сайты, которые используют для своего наполнения другие сайты интернета).
Мэтт Каттс и Амит Сингхал пишут в официальном блоге Google о том, что делает последнее изменение алгоритма Panda.
«Это обновление предназначено для снижения рейтинга низкокачественных сайтов с низкой информационностью для пользователей, копирования контента с других сайтов, которые просто не очень полезны. В то же время, он обеспечит лучший рейтинг для высококачественных сайтов с оригинальным контентом и информацией, такой как исследования, подробные отчеты, вдумчивый анализ и так далее.»
Поисковик Google ввел функцию в своих результатах поиска и когда вы нажимаете на результат поиска, а затем нажимаете кнопку «назад», чтобы вернуться в Google, вы можете увидеть новую ссылку рядом с кнопкой «кеш», которая позволит вам заблокировать этот домен от дальнейших поисков.
После следующего поиска вы больше не увидите заблокированные сайты, и результаты поиска должны быть немного более высокого качества. Конечно, вы всегда можете разблокировать сайт, прокрутив вниз до результатов поиска и нажав на ссылку, чтобы просмотреть заблокированные сайты.
Это и хорошее дополнение, если нет конкурентной борьбы. Но если у вашего бизнеса в интернете есть серьезные конкуренты, которые могут организовать блокировку вашего сайта с сотни, или более компьютеров, то организация падения рейтинга сайта гарантирована.
И против этой нечестной конкурентной борьбы трудно придумать противоядие.
Содержание не соответствует поисковому запросу
Бывает, что создатель страницы в названии, её описании, а также в заголовке контента, и других тегах и атрибутах как бы продекларировал одни ключевые фразы, а текст написал не относящийся к этим ключевым словам.
Этот фактор отличается от «некачественного контента» тем, что умышленно создаются страницы, которые обещают посетителю невероятную выгоду при переходе на их сайт.
Например, обещание 50% скидки, или купон на приобретение, или др. Когда же человек заходит на страницу это оказывается рекламная страница, или только текст по теме, что обычно приводит к разочарованию посетителя.
22 — Fred (дополнение к фильтру Panda)
Fred — это крупный бонус честным авторам, которые добросовестно дают полезную информацию своим читателям.
Fred пессимизирует сайты, которые нарушают правила для веб-мастеров.
Под действия этого фильтра попадают, прежде всего, новостные сайты и блоги, которые плодят некачественные публикации, размещают много рекламы, а цель таких сайтов получение дохода, но не предоставление полезной информации.
Под действие этого фильтра попадают сайты
· с небольшими статьями, статьи, состоящие из 300 слов (примерно двух тысяч символов),
· с правильными SEO-текстами,
· предельно отшлифованные,
· но лишенные какой-либо полезности.
Полезность можно определить по поведенческому фактору. Если статья открывается, а на её ознакомление уходит времени гораздо меньше, чем требуется среднестатистическому человеку на её прочтение, а затем пользователь возвращается к странице поиска, то это самые веские аргументы, по которым поисковик определяет, что статья низкого качества.
Хуан Гонсалес из Sistrix проанализировал 300 веб-сайтов из Германии, Испании, Великобритании и Соединенных Штатах, в поиске Google, которые сильно потеряли в рейтинге результатов поиска.
Хуан сказал, что
«Почти все ушедшие с первых страниц сайты имели очень много рекламы, особенно баннерной. Многие, из которых были кампаниями AdSense. Еще одна вещь, которую мы часто замечали, заключалась в том, что на этих сайтах содержалось мало контента или он был некачественный, который не имел никакой ценности для читателя».
Этим фильтром Google показал, что он готов предоставлять свою рекламу только сайтам, имеющим полезную информацию для конечного пользователя, и не желает зарабатывать на своей рекламе, размещая на низкопробных сайтах, понижая свой авторитет.
23 — Phantom (продолжает ориентировку на контент)
Phantom разделяет некоторые общие черты с Panda, поскольку он ориентирован на контент.
Пессимизация сайтов, попавших под этот фильтр, происходит по следующим причинам.
— Низкое качество содержания материала на сайте.
— Мало контента на небольшом количестве страниц, на сайте.
— Статьи партнеров сайта.
— Статьи как приманка для перехода на желаемую страницу сайта.
— Много рекламы, забивающий основной материал.
— Всплывающие окна, появляющиеся сразу при открытии, или по прохождении некоторого времени, или при желании покинуть страницу.
— Длинные видео. Оптимальной считается длина видео 3—5 мин.
— На веб-странице трудно ориентироваться пользователю.
Это обновление пессимизирует больше, чем какой-либо другой фильтр сайты с некачественным контентом. Наказываются целые домены только за небольшую часть некачественного контента.
Под фильтр Phantom попадают сайты:
— Большое количество ссылок на другие сайты без использования параметра nofollow. Причем пессимизация происходит не только спам-сайтов, но заслуживших в Google большой авторитет.
— Штрафуются сайты, ссылающиеся друг на друга с использованием точных якорных текстовых ссылок.
— В анкорах употребляются одни и те же тексты. Одинаковые анкоры чаще всего получаются при автоматическом распространении ссылок.
— Сайты, которые под подозрением принадлежат одному хозяину или компании. Например, когда у владельца несколько доменов и когда между сайтами создаются перекрёстные ссылки, используя один и тот же якорный текст в ссылках. Теперь эта, ранее популярная стратегия не работает. Google имеет доступ к whois (см. Фильтр Google Trust Rank), поэтому определить владельца нескольких сайтов — не сложно.
— Много перекрёстных ссылок между двумя сайтами. Вот только, количество много Google не уточняет, так же, как и сам расчёт.
— Заимствование контента. Phantom находит фрагменты текстов, помеченных как цитата, со ссылкой на первоисточник. Если страницы сайта злоупотребляют этим приемом — штрафуются. Этот фильтр пессимизирует и сайты, где большие фрагменты текста сдублированы, но источник не указан.
Заметьте, что теги цитат нужно употреблять только по назначению. Например, тег <q> предназначен для выделения коротких цитат в предложениях.
Тег <blockquote> предназначен для выделения длинных цитат, которые могут состоять из нескольких абзацев. Если эти теги употреблять не по назначению, без указания источника, а как дизайнерские элементы оформления текста, то это сигнал, что контент некачественный.
— Страницы списка ссылок, которые нужно прокручивать и прокручивать. Наверняка вы видели такие веб-страницы, и не смогли увидеть на них ничего полезного. Это понимает и Phantom.
— Не качественный дизайн сайта. Google не может сказать дизайн сайта хорош, или плох. Даже дизайнеры не могут перечислить критерии, по которым они оценивают качество других сайтов. Но Google провел масштабное исследование и определил критерии, по которым можно определить качество дизайна. К самым простым из них Google считает: мелкий шрифт, контраст шрифта и фона, трудность отличить рекламу от искомого содержания, и многое другое.
— Устаревшие и не относящиеся к теме комментарии. Часто бывает, что статья спустя некоторое время переделывается несколько раз, а устаревшие комментарии остаются. Статьи с такими комментариями Phantom штрафует.
— Оптимизация страниц сайта под известные бренды. Если прежде высоко ранжировались сайты, и получали большой трафик за счет оптимизации по известным брендам, то Phantom теперь лишил этой возможности. Google понимает, что если пользователь вводит название бренда, то он желает попасть именно на сайт бренда.
Выдача в ответах ложных страниц раздражает пользователей, и Google их пессимизирует. Теперь не обязательно писать «официальный сайт…». Теперь, например, маленькому интернет-магазину, продающему китайский Apple по китайским ценам невозможно обойти сайт Apple по запросу «продукция Apple». Справедливо это? Уверен, что честные работяги довольны этому. Ведь ещё встречаются случаи, когда один работает, не поднимая головы, а его трудом пользуются изворотливые дельцы.
— Множество страниц, ведущих на страницу с 404 ошибкой.
Phantom не пессимизирует весь сайт, а санкциям подвергаются отдельные страницы.
Многие считают, что Phantom это самый злостный карающий фильтр, от которого пострадало много сайтов. Однако, не забывайте — страдают одни, те кто тиражирует некачественные материалы, но выигрывают качественные сайты.
Phantom «заставляет» делать более качественные страницы, чтобы страница отвечала на запрос пользователя четко и без воды.
Например, если пользователь в строке поиска набирает «LED монитор» или «Какой LED монитор лучше», то он желает получить ответ на конкретно заданный вопрос. Ему нужно описание, характеристики, поэтому должно быть описание характеристик.
А контента должно быть достаточно, чтобы ответить на этот вопрос.
Если же пользователь набирает «Купить монитор Philips», то ему нужен интернет-магазин, и Google выводит пользователю список интернет-магазинов, в которых человек может приобрести нужный ему монитор. Причем, как помните, вначале выстраивает лучшие предложения, а затем в убывающем порядке.
Если какой-то интернет магазин «провалился» в поиске, то вина в этом не Google.
«На зеркало нечего пенять, коли рожа крива.»
(эпиграф и сюжет комедии Н. В. Гоголя «Ревизор». )
24 — Pirate Update (нарушение авторских прав)
Google Pirate Update — это фильтр, призванный помешать сайтам с большим количеством жалоб о нарушении авторских прав, которые подаются через систему DMCA Google, и которые занимают высокие позиции в ответах на запросы пользователей в Google.
Эти жалобы являются одним из факторов удаления контента из индекса Google. Но любой может написать жалобу. Это ещё не доказательство нарушения авторских прав. Это просто обвинение, и оно может быть оспорено.
Google оценивает каждую жалобу, и, если считает нарушение действительным, контент удаляется из индекса.
Чтобы избегать ложных обвинений в нарушении авторских прав можно каждую статью публиковать в социальных сетях, с размещением ссылки на страницу веб-сайта, где размещён оригинал статьи.
Это конечно не 100% гарантия (хакеры могут взломать правительственные сайты), но практически это хорошая защита, потому что цена защищенности информации намного выше цены взлома.
Если же считаете, ценность своей статьи превышает цену взлома, то у вас 2 пути: либо не размещать в сети, либо закреплять авторские права у нотариуса.
Чтобы не попасть под Google Pirate Update — не воруйте чужие материалы.
Если же разместили чужой контент, и уже попали под этот фильтр, то лучше всего удалит плагиат. Фильтр периодически повторно проверяет веб-сайты. Когда это происходит, ранее попавшие под этот фильтр сайты могут вернуть свои позиции, если сделаны правильные улучшения.
25 — Cassandra
Cassandra был одним из первых фильтров Google, который разрабатывался специально для фильтрации ссылочного спама.
Это были трудные времена для веб-сайтов, которые создавали ссылки с доменов, находящихся в совместном владении, и скрывали ссылки и текст, чтобы манипулировать своим рейтингом.
От Кассандры также сильно пострадали скрытые тексты и скрытые ссылки.
Хотя сейчас ни один серьёзный сеошник не занимается такими глупостями, но некоторые «умники» ещё пытаются таким образом обмануть поисковики.
26 — Penguin (Пингвин. Оценка качества ссылок)
Эта группа алгоритмов занимается определением качества ссылок: спам или нерелевантные ссылки, ссылки с чрезмерно оптимизированным якорным текстом, и др.
Цель Google Penguin максимально поощрять высококачественные веб-сайты и уменьшать присутствие на странице результатов поисковой системы (SERP) веб-сайтов, которые используют схемы манипуляторных ссылок и заполнение их ключевыми словами.
В отличие от фильтра Panda, Пингвин работает в режиме реального времени.
Пингвин создавался для выявления двух определенных факторов.
Первый. Схемы ссылок
Схемы ссылок — это разработка, приобретение или покупка обратных ссылок. Ссылки могут быть с некачественных или с качественных сайтов, но с сайтов другой тематики.
Это создает искусственную картину актуальности и авторитетности сайта, чтобы поисковики устанавливали больший вес сайту, и выше его позиционировали, отодвигая реально хорошие сайты, не имеющие такого большого количества ссылок.
Например, некоторый бухгалтер может на множестве интернет-форумах писать спам-комментарии со ссылками на свой сайт как «самый лучший и надежный бухгалтер в городе», набирая, таким образом, ссылочную массу неестественными ссылками.
Другой вариант, когда этот же бухгалтер может заплатить, чтобы его ссылка «самый лучший и надежный бухгалтер в городе» появилась в статье о красивой и модной одежде.
Третий вариант, когда ссылки покупаются на отличных схожих по теме сайтах, в статьях, в которых рассказывается о хороших бухгалтерах.
Многие веб-мастера воют, что не справедливо понижать рейтинг их сайтов за наращивание ссылочной массы. Они забывают, что ведут не честную игру перед сайтами, над которыми люди действительно трудятся. Покупатели ссылок почему-то считают, что воровать — не хорошо, и вор должен сидеть в тюрьме, и в это же время воруют рейтинг у отличных сайтов.
Любые ссылки, предназначенные для манипулирования PageRank или рейтингом сайта в результатах поиска Google, могут рассматриваться как часть схемы ссылок и нарушением Google Руководства для веб-мастеров.
Сложность работы фильтра Penguin в том, что невозможно доподлинно установить какая ссылка хорошая, а какая — манипуляторная.
Google в своем Руководстве для веб-мастеров определил, что любые ссылки, предназначенные для манипулирования рейтингом сайта в результатах поиска Google, могут рассматриваться, как часть схемы ссылок являются нарушением.
Заметьте, что Google указал фактор, которые он принял, для разработчиков сайтов являются законом в её поисковой системе, нарушая который, веб-мастера подвергают свои творения получить штраф.
Это как правила дорожного движения: должен принять, чтобы выезжать на дорогу, в противном случае — штраф, если поймают. Не согласен с правилами — не выезжай.
Google –предоставляет свои правила, в которых говорит за какие «лихачества» он будет наказывать если поймает.
Ещё не все «нарушения» может отлавливать Google Penguin, но механизм усовершенствования работает. Если верить публичным высказываниям Google разработчиков, то только за 2021 год было создано и доработано более 500 обновлений.
Это ежедневно почти по два обновления вносятся в фильтры ранжирования сайтов. Не забывайте, что искусственный интеллект корректируется, и развивается самостоятельно.
Если вчера вы прочитали статью авторитетного блоггера о некотором приеме обхода Penguin, то это не значит, что уже сегодня Google не нашел как выявлять, фиксировать эти нарушения, и наказывать за них.
И не думайте, что про «красивый» обход Penguinа прочитали только вы. Google сканирует интернет, находит (намного лучше нас с вами) предлагаемые приёмы, и разрабатывает алгоритмы выявления и борьбы с этими «нарушениями».
Так, что, возможно прочитав для вас новую уловку, для Google эта уловка уже обработана и найдено для её противоядия. Понимаете, что любой поисковик работает не только над улучшением поиска, но она ищет и бесплатных «тестировщиков», которые ищут дыры, ускоряя совершенствования фильтров.
Но вернемся к списку.
Подчеркну, что как утверждает Google это не список основных схем ссылок, а закон, за нарушение которого веб сайты будут наказываться. Поэтому изучите его основательно, и прочитайте разъяснения и комментарии.
Итак, список основных схем ссылок, которые могут негативно повлиять на рейтинг сайта в результатах поиска (написаны курсивом). Обычным шрифтом читайте комментарии специалистов из Google, независимых экспертов и мои скромные добавления.
Покупка или продажа ссылок, которые увеличивают рейтинг сайта:
— Обмен денег на ссылки или сообщения, содержащие ссылки.
Но что, если ваша компания сделала пожертвование, например, детскому дому. Они поблагодарили вас и поставили ссылку на своем сайте на ваш сайт. Если у вас есть пара таких ссылок, вероятно, Google посчитает, что все в порядке.
Но сколько можно поставить таких ссылок? С какого количества таких ссылок это становится вопросом мотива негативного влияния на сайт.
Но, если вы начнете использовать это как тактику связывания, и пожертвуйте во многих местах, которые, как известно, связываются со своими спонсорами, тогда вы можете столкнуться с проблемами.
На данный момент алгоритм Пингвина вряд ли повлияет на ссылки, подобные этим.
Но если вы когда-нибудь получите ручную проверку от члена команды веб-спама, большое количество таких ссылок может привести к наказанию за ссылки, как утверждает MOZ.
— Обменивать товары или услуги на ссылки.
Например, хозяйки салона понравился раскрученный блог какой-то модницы. Хозяйка пригласила модницу пройти некоторую процедуру, а за это та должна написать, как хорошо блоггершу обслужили в салоне, и сделать несколько ссылок в статье на салон.
Но если хозяйка салона пригласила не одну, а 10—20 блогершь, и те сразу разместили статьи со ссылками в своих блогах, то для Penguin — это прямой сигнал, что произошло не естественное наращивание ссылочной массы.
Другой вариант. У хозяйки салона большой юбилей, и благодарные блогерши и посетители салона решили поздравить её положительными отзывами, разместили статьи в своих блогах, и …. Сайт салона провалится от неестественного увеличения ссылочной массы.
К сожалению, Google не разработал грамотной концепции по борьбе с покупными ссылками, а хозяевам сайтов следует внимательно прочитать ещё раз список основных схем ссылок, которые могут негативно повлиять на рейтинг сайта в результатах поиска, чтобы не получилось, что благими намерениями выкладывается дорога вниз рейтинга.
— Отправка кому-либо «бесплатного» продукта в обмен на то,
чтобы получатель напишет об этом в своем блоге и включает ссылку на сайт продавца. Если компания отправила свой продукт двумстам блогерам, попросила их протестировать и описать свои ощущения в своем блоге, то это также попадает под санкции Penguin.
— Чрезмерный обмен ссылками.
Или «Сошлись на меня, и я буду ссылаться на тебя», или партнерские страницы исключительно ради перекрестных ссылок.
Допустим, я агент по недвижимости в некотором городе и у меня есть страница на моем сайте, где я рекомендую юристов по недвижимости, ипотечных брокеров и тому подобное. Некоторые из этих профессионалов, по доброй воли, также включили меня в свой список полезных ресурсов.
Это противоречит руководству по качеству? Возможно, и нет. Но, скажем, я вижу, что этот тип ссылки относительно легко получить. Далее, я решил добавить раздел на своем сайте, который рекомендует риэлторов по всему миру, и я обращаюсь к сотням риэлторов для обмена ссылками. Я включаю их в свою страницу ресурсов, и они также включают меня в свои веб-страницы.
И, возможно, я также обмениваюсь ссылками с как можно большим количеством сайтов, которые хоть немного связаны с недвижимостью. Теперь это похоже на схему связывания, и поэтому уже явно попадает под санкции. Т.е. я не могу себя широко рекламировать, если не хочу попасть под санкции.
Здесь я понимаю, что должен выбирать между партнерскими отношениями с другими компаниями, или котироваться в поисковике.
— Крупномасштабные кампании по маркетингу статей
или публикации гостевых постов с помощью якорных текстовых ссылок, так же подвергается наказанию.
— Гостевая публикация,
также известная как гостевой блоггинг, — это метод, при котором владелец сайта или его SEO-специалист напишет статью, опубликует ее на другом веб-сайте и разместит ссылку на свой сайт.
— По словам Мэтта Каттса, главы отдела по борьбе с веб-спамом в Google
«Проблема в том, что, если мы посмотрим на общий объем гостевых публикаций, мы увидим большое количество людей, которые предлагают гостевые блоги или статьи гостевых блогов, где они публикуют одну и ту же статью, производят несколько ее копий и отправляют электронные письма на разные сайты. Такой размноженный текст будут создавать те же самые низкокачественные типы статей, которые люди использовали для размещения статей в каталогах статей, или на сайтах банков статей. Если люди просто уходят от создания банков статей, каталогов статей или маркетинга статей к гостевым блогам, и они не повышают свои пороги качества для контента, то это может вызвать проблемы. С одной стороны, это возможность. С другой стороны, мы не хотим, чтобы люди думали, что гостевой блоггинг — это панацея, которая решит все их проблемы.»
Означает ли это высказывание, что качественное размещение гостевых постов не попадет под санкции Penguin? Рекомендации по качеству не делают различий между высоким и низким качеством размещения гостевых постов. Они просто говорят, что ссылки, при крупномасштабной публикации гостевых сообщений с привязанным к одной и той же, или нескольким подобным ключевым фразам в якорном тексте, можно считать неестественными.
Если вы периодически публикуете статьи на сайте другого человека, и эти статьи является информативными и полезными для читателя, вы, вероятно, не собираетесь гневить Google Penguin.
Однако очевидный вопрос: «Сколько это слишком много?». Когда Penguin начинает рассматривать, что эти гостевые посты крупномасштабная тактика создания ссылок?
Я не знаю, что кто-либо за пределами Google имеет хоть приблизительный ответ на этот вопрос.
— Использование автоматизированных программ или сервисов для создания ссылок на ваш сайт.
Обычная ситуация для начинающих: заплатить за размещение нескольких отдельных материалов, тому кто пообещал создать сотни ссылок на сайт заказчика, содержащих его основные ключевые фразы в качестве основного текста.
Большинство из этих распространителей будут использовать автоматизированное программное обеспечение, которое находит сайты, на которых они могут создавать ссылки, делая такие вещи, как написание спам-комментариев или создание поддельных профилей на форуме.
Если вы создали ссылки с помощью автоматизированного программного обеспечения или если вы приобрели какой-либо пакет, например, 100 постов в каталогах за 50 евро, то у вас есть неестественные ссылки, которые Google Penguin в лучшем случае не учтет, а в худшем пессимизирует ваш сайт.
— Требование ссылки в рамках Условий обслуживания,
контракта или аналогичного соглашения без предоставления стороннему владельцу контента возможности выбора использования nofollow или другого метода блокировки PageRank, если они того пожелают.
— Текстовая реклама, которая повышает рейтинг веб сайта.
Google Penguin может посчитать, что это проплаченная реклама, и принять соответствующие меры. Если вы приобрели рекламу на сайте, следуя рекомендациям по качеству, по которым к этой ссылки должна быть прикреплена метка nofollow, чтобы эта публикация не увеличивала вес станицы, на которую ведет ссылка.
— Advertorials или нативная реклама, где оплата получена за статьи, которые содержат ссылки на веб-сайт и повышают его рейтинг.
— Естественная (нативная) реклама (англ. native advertising) — способ, которым рекламодатель привлекает к себе внимание в контексте площадки и пользовательских интересов. В оригинале она воспринимается как часть просматриваемого сайта, учитывает особенности площадки, не идентифицируется как реклама, и не вызывает у аудитории отторжения.
— Рекламные ссылки
обычно хорошо работают по сей день, и улучшают рейтинг сайта.
Нередко рекламные ссылки размещаются на новостных сайтах с высоким пиаром за некоторую сумму денег. Если у вас много подобных ссылок, и они существенно увеличивают рейтинг, то они по требованиям Google должны быть либо удалены, если вы хотите оставаться в рамках рекомендаций Google по качеству.
— Ссылки с оптимизированным якорным текстом в статьях или пресс-релизах, распространяемых на других сайтах. Например, «на рынке много обручальных колец». «Если вы хотите провести свадьбу, вам нужно будет выбрать лучшее кольцо». «Вам также нужно будет купить цветы и свадебное платье», «Кольца, цветы и свадебные платья можно купить в лучшем магазине города».
— Некачественные ссылки на каталог или закладку сайта.
— — Где Google проводит границу между низкокачественными и высококачественными каталогами (и любыми другими сайтами) достаточно объемный и трудоёмкий процесс, который подробно описан в книге «5000+ сигналов ранжирования в поисковиках»
— — Большинство людей, которые проводят аудит ссылок, согласятся с тем, что ссылка на dmoz.org — это отличная ссылка, потому что Dmoz известен как каталог с высокими рангом.
— — Ссылка на каталог «Желтых страниц» местного интернет-издания, скорее всего, тоже подойдет.
— — Наиболее рациональным подходом для оптимизатора можно принять положительные ответы для себя на следующие вопросы.
— — — Эта ссылка будет сделана, даже если бы поисковых систем не существовало?
— — — Может ли эта ссылка привлечь трафик на сайт?
— — — Является ли эта ссылка полезной для реальных людей?
— — Если вы можете честно сказать, что это ссылка, которая не была сделана с целью увеличения вашего PR, тогда, вероятно, это нормальная ссылка.
— — Часто приходится видеть, как веб-мастера обосновывают неестественные ссылки, говоря, что каталог имеет высокий PR и, следовательно, является высококачественным.
Или что каталог не был проиндексирован, поэтому Google должен думать, что это нормально.
Google никому и ничего не должен. Нет умения делать великолепный материал, и соблюдать правила Google, делайте так, и не участвуйте в ранжировании Google. Google как фейс контроль, сам определяет, кого следует пускать в свой клуб, а кто будет только мешаться тем, кого он отобрал, и считает авторитетным.
— Богатые ключевыми словами, скрытые или некачественные ссылки, встроенные в виджеты, которые распространяются по разным сайтам.
Если создадите, кредитный калькулятор он понравится риэлторам, и они начнут встраивать его на своих сайтах вместе со ссылкой «Ипотечный калькулятор, предоставленный example.com».
— Google не уточняет в своих рекомендациях по качеству, можно ли считать некоторые ссылки из встроенных виджетов естественными. Вот что об этом говорит Джон Мюллер, о встраиваемых ссылках виджетов.
«Если вы предоставляете действительно полезные виджеты и стоит ссылка на ваш веб-сайт таким образом, что веб-мастер может выбрать ссылаться или нет на ваш ресурс, то это отличный сервис для этих веб-мастеров и может быть ценным для других веб-сайтов.»
Если вы пользуетесь «бесплатным калькулятором подсчета калорий» или «бесплатном калькулятором расчета…», то сайты, которые имеют хороший рейтинг, получают его благодаря весу ссылок, содержащих эти ключевые слова во встраиваемых виджетах.
Мой личный опыт подсказывает, что Google считает эти ссылки приемлемыми, поскольку они на самом деле связаны со счетчиком калорий или каким-либо другим подсчетам. Конечно, если эти виджеты связаны с использованием ключевых слов.
— Сссылки в нижних колонтитулах или шаблонах различных сайтов — широко распространены.
Например, веб-студия на созданном ими сайте размещает ссылку на свой сайт.
Google четко не говорит в своем руководстве, допустимо ли размещать в нижних колонтитулах ссылку, содержащую ваш адрес сайта разработчикам этого сайта.
Тем не менее, Джон Мюллер по этому поводу говорил.
— а) «Это то, что действительно ясно — веб-мастер нарочно ссылается на этот сайт. А это то, что требуется делать. Один из способов состоит в том, что, если вы говорите, что этот сайт был разработан www.marketsharewebdesign.com или что-то в этом роде, то мы обычно говорим, что это нормально.»
— б) Затем он немного отступает и говорит, что, если вы хотите быть абсолютно уверенным, что не нарушаете руководящих принципов качества, вы можете использовать тег nofollow.
— в) В этой же беседе он отмечает, что этот тип ссылки может выглядеть как ссылка в обмен на продукт (веб-сайт), который не соответствует рекомендациям по качеству.
Вот и решайте сами, какой из трёх вариантов изберет Google Penguin, когда будет ранжировать вашу ссылку.
У нас в компании не принято ставить свою ссылку на изготовляемый сайт.
По-настоящему,
· ссылка с нового сайта не имеет никакого веса в обозримом будущем, т.к. сайт молодой.
· ссылка даже уже с уже авторитетного сайта имеет вес, если она помогает пользователю разобраться более глубоко в рассматриваемом вопросе. Сайты должны быть из одной отрасли, и рассматривать одну тему с разных сторон, чтобы ссылка позволяла глубже разобраться в рассматриваемом вопросе, тогда эта ссылка получает некоторый вес.
· И самое главное, лично для меня, поставив ссылку на свой сайт, мне кажется, что пользователи воспринимают её, как фразу: «Ну возьмите меня…». Если кто-то захочет перейти на наш сайт, то он может скопировать название сайта, и вставить его в адресную строку обозревателя. Такой подход можно рассматривать как тест на допуск к сайту. Если человек не заинтересован, то ему и ссылка не нужна. А заинтересованный всегда найдет путь как добраться.
— Комментарии на форуме с оптимизированными ссылками в сообщении или подписи,
например,
«Спасибо, это отличная информация! — пицца Илоны в Риге Лучшая пицца в Риге.
Обратите внимание, что рекламные ссылки с оплатой за клик, которые не увеличивают ранг сайта покупателю рекламы, не нарушают правила Google. Для этого нужно заблокировать передачу веса ссылки несколькими способами, такими как:
· Добавление атрибута rel = «nofollow» так <a href="signin.php» rel=«nofollow»> войдите </a>
· Перенаправление ссылок на промежуточную страницу, заблокированную поисковыми системами с помощью файла robots. txt.
Познакомившись со списком неестественных ссылок, возникает вопрос: «Если все эти ссылки неестественны, то какие ссылки можно использовать, чтобы полностью соответствовать рекомендациям Google»?
Ответ на этот вопрос заключается в том, чтобы сосредоточиться на том, чтобы делать вещи, которые действительно зарабатывают ссылки, а не строить их самостоятельно.
Однако это нелегкая задача. Прямо сейчас, в некоторых нишах, невозможно конкурировать без какой-либо формы неестественных ссылок.
Сайты, которые ранжируются в высоко конкурентных нишах, часто являются сайтами, которые нарушают рекомендации по качеству. Но делают это способами, которые в данный момент Google не может обнаружить.
Google недавно запустил обновление, которое было специально разработано для снижения эффективности неестественных ссылок в высокодоходных нишах. Они постоянно работают над улучшением алгоритмов, в частности алгоритма Пингвин, с целью полного снижения эффективности неестественных ссылок.
Прошли те времена, когда можно было легко ранжировать сайт, создавая большое количество ссылок на разных сайтах, ведущих на свой сайт.
Уверен, что в ближайшие несколько лет мы увидим кардинальные изменения в борьбе с неестественными ссылками. По мере того как Google становится еще лучше в обеспечении соблюдения рекомендаций по качеству, SEO специалисты, обладающие интеллектом и креативным мышлением, (чтобы найти способы естественного продвижения сайта), будет пользоваться повышенным спросом.
Конечно, список запретов, которые выставляет Google больше говорит о том, что так Google борется с конкурентами за то, чтобы все рекламные денежные потоки шли по большей степени к нему, чем о возможностях реализовать эти ограничения.
И не забывайте, что Google создает алгоритмы для отслеживания, чтобы сократить свои потери за рекламу.
Многое из запретов не реально и отследить. Например, хозяйки салона понравился блог какой-то модницы. Хозяйка пригласила модницу пройти некоторую процедуру, а за это та должна написать, как хорошо блоггершу обслужили в салоне, и сделать несколько ссылок в статье на салон. Как в этой ситуации доказать, что делалось всё по велению сердца, а не с сетью наживы?
Как Google Penguin сможет доказать, что вначале блоггерша получила процедуру, а затем написала статью, и было это не наоборот?
Или ещё сложнее. Модница ходит по салонам. Ей что-то делают в салонах, а она от чистого сердца, описывает, как хорошо её обслужили.
Но Google Penguin никому и ничего не будет доказывать, это хозяин сайта может попытаться, что-то доказать.
А на этот случай у Google предусмотрен вариант — не учитывать ссылки, не понижая рейтинг. И здесь тёмное пятно: мы не можем узнать, учитывался ли вес ссылки или нет.
Но если хозяйка салона пригласила не одну, а 10—20 блоггершь, и те сразу разместили статьи со ссылками в своих блогах, то для Penguin — это прямой сигнал, что произошло не естественное наращивание ссылочной массы.
Компания Google не признает рекламных акций, если они могут положительно воздействовать на рейтинг сайта.
К сожалению, Google не разработал грамотной концепции, или, во всяком случае, не объявил её, по борьбе с покупными ссылками, а хозяевам сайтов следует внимательно прочитать ещё раз список основных схем ссылок, которые могут негативно повлиять на рейтинг сайта в результатах поиска.
По мнению Google, нельзя вступать в личные отношения с хозяевами других сайтов. Можно только создавать превосходный контент, который будет востребован, и другие сайты с удовольствием будут ссылаться на материал вашего веб-ресурса.
Но здесь замкнутый круг. Как о моей статье узнают другие, если меня никто не знает, и в органическом поиске эта прекрасная статья позиционируется не на первой странице результатов?
Google предполагает, что создатели нужного пользователям контента будут давать рекламу, и кто-то увидит, и будет ссылаться на этот материал…
Google считает, что создание хорошего контента окупается: ссылки — это, как правило, выбор редакции, и чем больше у вас полезного контента, тем больше шансов, что кто-то найдет этот контент ценным для своих читателей и даст ссылку на него.
Возможно, в англоязычном интернете практикуется устанавливать ссылки на другие сайты, но чтобы безвозмездно в русскоязычном интернете это делалось, и массово, мне трудно представить.
Хотя по исследованиям психологов установлено, что в глазах читателя авторитет статьи резко возрастает, если автор подкрепляет свои рассуждения авторитетными источниками. Поэтому сейчас в тренде начинать с фраз: «Британские ученые доказали…».
И это сразу увеличивает доверие к далее написанному, хотя практически никто не проверяет реальность источника.
Второй. Заполнение ключевыми словами
Заполнение веб-страницы большим количеством ключевых слов или повторений ключевых слов в попытке манипулировать ранжированием путем повышения релевантности для определенных поисковых фраз отрицательно воспринимается поисковиками.
Примеры заполнения ключевых слов включают в себя:
— Списки телефонных номеров, или другими мало полезными, или вообще бесполезными данными для увеличения объема текста.
— Блоки текстового списка стран и городов, на которых веб-страница пытается получить рейтинг, также увеличивая объем текста.
— Повторение одних и тех же слов или фраз настолько часто, что это звучит неестественно.
Например, «Мы продаем пластиковые окна. Наши пластиковые окна изготовлены вручную. Если вы думаете о покупке пластиковых окон, пожалуйста, свяжитесь с нашими специалистами по продаже пластиковых окон, в Москве, по телефону…». И эта фраза повторяется для каждого города.
Итак, под Google Penguin легко попадают сайты имеющие:
— большое количество скрытых ссылок,
— активного наращивания или уменьшения ссылочной массы, а также
— наличие точных ключевых фраз в анкорах, с частым употреблением этих ключевых фраз.
Уверен, что если вы не будите пользоваться массовыми действиями «оптимизаторов», а будите всё делать вручную, то никакой пингвин вам не страшен.
27 — Google Caffeine
Сростом популярности собственной поисковой системы Google также пришлось признать, что многие установленные процессы больше не работают достаточно хорошо.
Ведь идея алгоритма и поискового индекса родилась в то время, когда всего было несколько миллионов сайтов. Однако самое позднее в 2010 году каждый день добавлялись миллионы веб-страниц.
Обновление Google Caffeine было разработано, чтобы отдать дань уважения изменениям в Интернете. Это было одно из крупнейших обновлений инфраструктуры поисковой системы, которое изменило дизайн поисковой выдачи таким образом, что его можно увидеть и сегодня.
До обновления инфраструктуры поисковый индекс Google состоял из нескольких слоев. Чтобы обновить изменения, нужно было проанализировать всю сеть, что занимало достаточно долгое время. Таким образом, между временем обнаружения страницы и ее появлением в индексе значительная значительная задержка.
В 2000 году индекс обновлялся только каждые 4 месяца. В конце 2001 года частота индексации была увеличена до одного раза в месяц.
Новый поисковый индекс Caffeine включает пошаговый и непрерывный процесс сканирования и индексирования. Теперь каждый веб-сайт можно сканировать отдельно и включать в индекс вскоре после публикации.
Google Caffeine — самое важное обновление инфраструктуры
Большинство названных обновлений Google в той или иной форме касались алгоритма. Будь то Флорида, Панда, Пингвин, Колибри или обновление Фреда — все они, так или иначе, задают условия для ранжирования.
Таким образом, Google Caffeine вписывается в ряд этих имен лишь в ограниченной степени. Это было полное изменение внутренних процессов и обработки, которое в конечном итоге привело к индексации. Для этого было много причин.
Во-первых, Google должен был определить для себя, насколько быстро преобразуется Интернет и как меняется его контент.
С другой стороны, сам рост развивался гораздо быстрее, чем предполагала сама поисковая система.
Обновление Google Caffeine было необходимо главным образом потому, что основная динамика сети изменилась в 2019 и 2020 годах. Вместо статических веб-сайтов, которые редко менялись, новый контент появлялся каждый день, каждый час и каждую минуту.
Живые обновления и динамический контент стали популярными и предоставили пользователям новую информацию. На тот момент процесс индексирования был разработан таким образом, чтобы страницы в интернете менялись только через длительные интервалы времени, если вообще менялись.
Как работал Google до и после обновления Google Caffeine?
До применения Google Caffeine Update индекс состоял из нескольких слоев. Были некоторые смены, которые обновлялись чаще, чем другие.
Чтобы один из этих слоев или уровней обновился, был необходим полный поиск сохраненных страниц в слое. В результате веб-страницы иногда довольно долго хранились в одном из слоев, но не переносились в поисковый индекс, если соответствующий слой не был запланирован для переноса в поисковую выдачу.
Вначале интервалы для такого обновления составляли четыре месяца, но со временем Google уже сократила время до одного месяца. Однако, поскольку каждый день по-прежнему добавлялись и индексировались тысячи новых веб-сайтов, иногда случалось, что они появлялись в поисковой выдаче только через несколько недель. Это также относилось к динамическому контенту, созданному на уже проиндексированных веб-сайтах.
Цель состояла в том, чтобы стимулировать и активизировать поисковый индекс на основе названия Google Caffeine Update. В будущем все центры обработки данных должны обеспечивать одновременные результаты.
При этом было важно, чтобы актуальный контент был приоритетным в поисковых системах. Это стало особенно очевидным, когда поисковик не смог предоставить поисковику самую свежую информацию в случае текущих событий. Обновление Google Caffeine полностью изменило способ индексации веб-сайтов и по-прежнему активно в этой форме.
Гибкий индекс с вниманием к новостям и социальным сетям
После обновления Google Caffeine пользователи смогли наблюдать несколько интересных нововведений. С одной стороны, веб-сайты, которые были относительно новыми и хотели только позиционировать себя, теперь также можно было найти в результатах поиска.
Вам не нужно было ждать недели или даже месяцы, чтобы увидеть первые результаты поисковой оптимизации. Однако, прежде всего стало ясно, что важную роль играет динамичное и новое содержание. Обновление Google Caffeine послужило основой для Новостей Google и отображения текущего контента в обычном поиске.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.