
Бесплатный фрагмент - Подготовка набора данных для обучения и тестирования программного обеспечения на основе технологии искусственного интеллекта
Учебное пособие
ПРИНЯТЫЕ СОКРАЩЕНИЯ И АББРЕВИАТУРЫ
БДТ — базовые диагностические требования
БФТ — базовые функциональные требования
ДЗМ — Департамент здравоохранения города Москва
ЕМИАС — Единая медицинская информационно-аналитическая система
ЕРИС — Единый радиологический информационный сервис
ЗНО — злокачественное новообразование
КТ — компьютерная томография
МИС — медицинская информационная система
МК — медицинская карта
МКБ — Международная классификация болезней
ММГ — маммография
МО — медицинская организация
МРТ — магнитно-резонансная томография
НД — набор данных
ОК — общекультурные компетенции
ОС — операционная система
ОПК — общепрофессиональные компетенции
ПК — персональный компьютер
ПО — программное обеспечение
РГ ОГК — рентгенография органов грудной клетки
РМЖ — рак молочной железы
ТЗ — техническое задание
ТИИ — технологии искусственного интеллекта
УЗИ — ультразвуковое исследование
УИД — уникальный идентификатор
Ф.И.О. — фамилия, имя, отчество
ФИПС — Федеральный институт промышленной собственности
ФС — федеральный справочник
ЭКГ — электрокардиография
ЭНМГ — электронейромиография
ЭЭГ — электроэнцефалография
DICOM — Digital Imaging and Communications in Medicine (медицинский отраслевой стандарт создания, хранения, передачи и визуализации цифровых медицинских изображений и документов обследованных пациентов)
ВВЕДЕНИЕ
Цель данного учебного пособия — приобретение и расширение обучаемыми лицами необходимых компетенций, получение знаний, умений и навыков в области принципов и методологий подготовки набора данных для обучения и тестирования программного обеспечения на основе технологии искусственного интеллекта.
Задачи:
— изучение общетеоретических вопросов, терминологии, значения в системе здравоохранения технологий искусственного интеллекта и необходимых для их развития наборов данных;
— изучение этапов жизненного цикла набора данных в сфере здравоохранения;
— изучение алгоритма создания набора данных;
— изучение мер по профилактике дефектов и ошибок при создании наборов данных;
— обеспечение уровня компетенций и навыков в соответствии с требованиями профессионального стандарта «Специалист в области организации здравоохранения и общественного здоровья»;
— обеспечение уровня компетенций и навыков в соответствии с требованиями профессионального стандарта «Врач-рентгенолог»;
— обеспечение уровня компетенций и навыков в соответствии с требованиями профессионального стандарта «Специалист по тестированию в области информационных технологий».
Требования к входным знаниям, компетенциям и умениям для проведения занятий: теоретические знания и практические навыки в соответствии с федеральными государственными образовательными стандартами высшего образования по специальностям 31.05.01 Лечебное дело, 31.05.02 Педиатрия, 31.05.03 Стоматология, 31.08.09 Рентгенология, 30.05.03 Медицинская кибернетика и 30.05.02 Медицинская биофизика, а также дисциплинам образовательной программы бакалавриата по направлению подготовки 09.03.04 Программная инженерия, специальности 09.04.02 Информационные системы и технологии и 06.004 Специалист по тестированию в области информационных технологий.
Изучение пособия направлено на дальнейшее формирование у обучающихся следующих компетенций:
I. По специальностям 31.05.01 Лечебное дело, 31.05.02 Педиатрия, 31.05.03 Стоматология, 31.08.09 Рентгенология (дисциплина «Общественное здоровье и здравоохранение»):
1. Общекультурных:
— способность к абстрактному мышлению, анализу, синтезу (ОК-1);
— готовность к саморазвитию, самореализации, самообразованию, использованию творческого потенциала (ОК-5).
2. Общепрофессиональных:
— готовность решать стандартные задачи профессиональной деятельности с использованием информационных, библиографических ресурсов, медико-биологической терминологии, информационно-коммуникационных технологий и учетом основных требований информационной безопасности (ОПК-1);
— способность и готовность анализировать результаты собственной деятельности для предотвращения профессиональных ошибок (ОПК-5).
3. Профессиональных:
— способность к применению основных принципов организации и управления в сфере охраны здоровья граждан, в медицинских организациях и их структурных подразделениях (ПК-17);
— готовность к участию во внедрении новых методов и методик, направленных на охрану здоровья граждан (ПК-22).
4. Дополнительно:
— способность организовывать оказание разных видов медицинской помощи с применением допущенных к обращению медицинских изделий на основе технологий искусственного интеллекта;
— способность понимать принципы работы современных информационных технологий, технологий искусственного интеллекта и использовать их для решения задач профессиональной деятельности.
II. По специальности 09.04.02 Информационные системы и технологии:
1. Общекультурных:
— способность совершенствовать и развивать свой интеллектуальный и общекультурный уровень (ОК-1);
— способность к самостоятельному обучению новым методам исследования, к изменению научного и научно-производственного профиля своей профессиональной деятельности (ОК-2);
— использование на практике умений и навыков в организации исследовательских и проектных работ, в управлении коллективом (ОК-4);
— способность к профессиональной эксплуатации современного оборудования и приборов (ОК-7).
2. Общепрофессиональных и профессиональных:
— способность воспринимать математические, естественно-научные, социально-экономические и профессиональные знания, умение самостоятельно приобретать, развивать и применять их для решения нестандартных задач, в том числе в новой или незнакомой среде и в междисциплинарном контексте (ОПК-1);
— владение методами и средствами получения, хранения, переработки и трансляции информации посредством современных компьютерных технологий, в том числе в глобальных компьютерных сетях (ОПК-5);
— умение разрабатывать стратегии проектирования, определять цели проектирования, критерии эффективности, ограничения применимости (ПК-1);
— умение проводить разработку и исследование теоретических и экспериментальных моделей объектов профессиональной деятельности в области медицины (ПК-8).
III. По специальности 09.03.04 Программная инженерия:
1. Универсальных:
— способность осуществлять поиск, критический анализ и синтез информации, применять системный подход для решения поставленных задач (УК-1).
2. Общепрофессиональных:
— способность применять естественно-научные и общеинженерные знания, методы математического анализа и моделирования, теоретического и экспериментального исследования в профессиональной деятельности (ОПК-1);
— способность использовать современные информационные технологии и программные средства, в том числе отечественного производства, при решении задач профессиональной деятельности (ОПК-2);
— способность осуществлять поиск, хранение, обработку и анализ информации из различных источников и баз данных, представлять ее в требуемом формате с использованием информационных, компьютерных и сетевых технологий (ОПК-8).
IV. По специальности 06.004 Специалист по тестированию в области информационных технологий:
1. Общекультурных:
— способность совершенствовать и развивать свой интеллектуальный и общекультурный уровень (ОК-1);
— способность к самостоятельному обучению новым методам исследований, к изменению научного и научно-производственного профиля своей профессиональной деятельности (ОК-2);
— использование на практике умений и навыков в организации исследовательских и проектных работ, управление коллективом (ОК-4);
— способность к профессиональной эксплуатации современного оборудования и приборов (ОК-7);
2. Общепрофессиональных и профессиональных:
— способность применять естественно-научные и общеинженерные знания, методы математического анализа и моделирования, теоретического и экспериментального исследования в профессиональной деятельности (ОПК-1);
— владение методами и средствами получения, хранения, переработки и трансляции информации посредством современных компьютерных технологий, в том числе в глобальных компьютерных сетях (ОПК-5).
V. По специальности 30.05.03 Медицинская кибернетика и 30.05.02 Медицинская биофизика:
1. Общекультурных:
— способность совершенствовать и развивать свой интеллектуальный и общекультурный уровень (ОК-1);
— способность к самостоятельному обучению новым методам исследований, к изменению научного и научно-производственного профиля своей профессиональной деятельности (ОК-2);
— использование на практике умений и навыков в организации исследовательских и проектных работ, управление коллективом (ОК-4);
— способность к профессиональной эксплуатации современного оборудования и приборов (ОК-7).
2. Общепрофессиональных и профессиональных:
— способность применять естественно-научные и общеинженерные знания, методы математического анализа и моделирования, теоретического и экспериментального исследования в профессиональной деятельности (ОПК-1);
— владение методами и средствами получения, хранения, переработки и трансляции информации посредством современных компьютерных технологий, в том числе в глобальных компьютерных сетях (ОПК-5).
В результате изучения материала обучаемый должен
знать:
— основную терминологию, базовые принципы юридического регулирования, цели и задачи создания и эксплуатации наборов данных в здравоохранении;
— принципы стандартизации процессов создания и эксплуатации наборов данных в здравоохранении;
— принципы классификации, основные требования к структуре, составу, описанию наборов данных;
— подходы к постановке клинической задачи, решаемой с применением конкретного набора данных;
уметь:
— организовывать процесс подготовки набора данных для сферы здравоохранения;
— организовывать процессы контроля и непрерывного повышения качества при подготовке наборов данных;
— обеспечивать защиту персональных данных;
владеть:
— навыками создания технического задания на набор данных;
— отдельными навыками разметки разных типов биомедицинских данных;
— навыками создания описания набора данных для здравоохранения.
Изучение материала пособия рассчитано на 6 академических часов самостоятельной работы, для его успешного освоения рекомендуется использовать открытые библиотеки наборов данных в сфере здравоохранения: https://mosmed.ai/datasets/; https://ai2.rt-eu.ru/. В целях проверки усвоения информации предусмотрены вопросы для самоконтроля. Для повышения уровня эрудированности и вовлеченности обучаемых в изучение учебного курса опционально рекомендуется подготовка рефератов и докладов-презентаций.
Коллектив авторов выражает благодарность за помощь в подготовке учебного пособия В. П. Новику, Е. Ф. Савкиной, Д. В. Козлову, У. А. Сахащик, Ю. С. Бусыгиной, Е. Г. Бахтеевой.
ОБЩИЕ ПОЛОЖЕНИЯ
В последнее время стали популярными такие слова, как искусственный интеллект, машинное обучение, большие данные (big data). Эти термины входят в повседневное употребление и уже встречаются не только в узконаправленных специализированных областях. Не стала исключением и сфера здравоохранения: автоматизированные системы диагностики, системы распознавания медицинских записей и естественного языка, системы анализа и предсказания событий, автоматической классификации и сверки информации, чат-боты поддержки пациентов, электронная медицинская карта и многое другое — результаты масштабной цифровизации в данной сфере,. Столь мощный прогресс цифровых технологий в Российской Федерации поддерживается Национальной стратегией развития искусственного интеллекта на период до 2030 года [1].
Искусственный интеллект (ИИ) — комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая самообучение и поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые, как минимум, с результатами интеллектуальной деятельности человека. Комплекс технологических решений включает в себя информационно-коммуникационную инфраструктуру, программное обеспечение (в том числе в котором используются методы машинного обучения), процессы и сервисы по обработке данных и поиску решений [1].
Технологии искусственного интеллекта (ТИИ) — технологии, основанные на использовании искусственного интеллекта, включая компьютерное зрение, обработку естественного языка, распознавание и синтез речи, интеллектуальную поддержку принятия решений и перспективные методы искусственного интеллекта [1].
В соответствии с Национальной стратегией использование технологий искусственного интеллекта в социальной сфере способствует созданию условий для улучшения уровня жизни населения, в том числе за счет повышения качества услуг в сфере здравоохранения, включая профилактические обследования, диагностику, основанную на анализе изображений, прогнозирование возникновения и развития заболеваний, подбор оптимальных дозировок лекарственных препаратов, сокращение угроз пандемий, автоматизацию и точность хирургических вмешательств.
Основные факторы развития ТИИ — это увеличение объема доступных данных, в том числе данных, прошедших разметку и структурирование, а также постоянное развитие информационно-телекоммуникационной инфраструктуры для обеспечения доступа к наборам таких данных.
С развитием медицины, повышением ее доступности и повсеместного внедрения цифровых технологий в медицинскую практику отмечается высокий рост количества медицинских данных: клинических, лабораторных и инструментальных. Данные — представление информации в формализованном виде, пригодном для передачи, интерпретации и обработки [2].
Большой объем данных способствует оптимальной организации интересующей сферы (в частности, здравоохранения) для достижения наилучших результатов работы. Данные могут быть использованы для прогнозирования текущих тенденций определенных параметров и будущих событий. В последние годы в медицинской практике активно внедряются электронные медицинские карты и медицинские информационные системы, что приводит к необходимости стандартизации медицинской информации.
Например, результаты лабораторных (патоморфологические исследования, клинические анализы, генетические исследования и т.д.), лучевых (КТ, МРТ, ММГ, УЗИ, рентгенография и т.д.) и сигнальных (ЭКГ, ЭЭГ, ЭНМГ и т.д.) исследований максимально стандартизованы и оцифрованы, что способствует росту количества данных по этим направлениям, инструментов для их обработки (программное обеспечение, предназначенное для обработки медицинских данных), передачи и хранения, и, как следствие, развитию ТИИ в этой области.
Внедрение ТИИ в сферу здравоохранения позволяет повысить качество предоставляемых услуг [1], а также снизить нагрузку на врачей. Например, при скрининге рака молочной железы требуется «двойное чтение» результатов маммографических исследований, т.е. каждое исследование должно быть просмотрено двумя специалистами.
Однако многочисленные исследования показывают, что одно чтение можно доверить ПО на основе ТИИ, при этом качество скрининга не ухудшается. Другой пример успешного применения ПО на основе ТИИ — пандемия COVID-19: в условиях острой нехватки медицинского персонала применение ТИИ позволило уменьшить время обработки заключения КТ, а также осуществить сортировку исследований, благодаря чему исследования пациентов в более тяжелом состоянии обрабатывались в первую очередь [3].
Однако для успешного применения ТИИ необходимо создание релевантных, репрезентативных, корректно размеченных наборов данных (НД).
НД используются не только для разработки и обучения ПО на основе ТИИ, но и их валидации, т.е. проверки качества работы ПО. Благодаря Национальной стратегии развития искусственного интеллекта в Российской Федерации стало возможным активное создание и внедрение в повседневную практику таких НД, а также инструментов их хранения, администрирования и использования.
На первый взгляд может показаться, что создание НД — несложный процесс: ведь ежедневно генерируются терабайты данных медицинской информации, а применение МИС позволяет их хранить, передавать и использовать (например, данные лучевой диагностики медицинских организаций ДЗМ хранятся в Едином радиологическом информационном сервисе — ЕРИС ЕМИАС). Тем не менее процесс создания НД (не стоит забывать о том, что они должны быть релевантными, репрезентативными и корректно размеченными) — очень сложный, имеет множество важных аспектов и вовлекает в себя большое количество специалистов, как медицинских (врачи, лаборанты), так и технических (инженеры, разработчики, аналитики и т.д.), а также смежных направлений (биофизики, кибернетики, биоинформатики).
Кроме того, недостаточно создать НД — необходимо уделить внимание инфраструктуре и инструментам хранения, использования и управления, таким, например, как библиотеки и реестры. Их основными задачами являются аннотация, интеграция и представление НД для контроля качества, удобного и повсеместного использования, в том числе для ПО на основе ТИИ.
Методологии создания наборов данных для сферы здравоохранения продолжают формироваться и в настоящее время, прежде всего — на основе масштабных научных исследований. Так, в основу настоящего учебного пособия положены результаты «Эксперимента по использованию инновационных технологий в области компьютерного зрения для анализа медицинских изображений и дальнейшего применения в системе здравоохранения города Москвы» (mosmed.ai) — крупнейшего в мире проспективного многоцентрового клинического исследования технологий искусственного интеллекта [3].
Глава 1. НАБОРЫ ДАННЫХ И ПРИНЦИПЫ ИХ КЛАССИФИКАЦИИ
1.1. Основные понятия
Медицинские данные подразделяются на несколько подмножеств, каждое из которых является важным компонентом в обучении, оценке качества ПО на основе ТИИ и используется для других прикладных и фундаментальных задач в сфере искусственного интеллекта для здравоохранения. Каждый компонент (подмножество, набор) данных направлен на решение определенной задачи.
Набор данных (НД) — это совокупность данных, прошедших предварительную подготовку (обработку) в соответствии с требованиями законодательства Российской Федерации об информации, информационных технологиях и о защите информации и необходимых для разработки программного обеспечения на основе искусственного интеллекта [1].
Разметка данных — этап обработки структурированных и неструктурированных данных, в процессе которого данным (в том числе текстовым документам, фото- и видеоизображениям) присваиваются идентификаторы, отражающие тип данных (классификация данных), и (или) осуществляется интерпретация данных для решения конкретной задачи, в том числе с использованием методов машинного обучения [1].
В процессе создания, хранения и использования НД необходимо руководствоваться следующими нормативно-правовыми актами, межгосударственными и национальными стандартами:
— Указ Президента Российской Федерации от 10.10.2019 №490 «О развитии искусственного интеллекта в Российской Федерации»;
— ГОСТ 34.602—2020. Информационные технологии. Комплекс стандартов на автоматизированные системы;
— ГОСТ 19.201—78. Единая система программной документации. Техническое задание. требования к содержанию и оформлению;
— ГОСТ 19.101—77. Единая система программной документации. Виды программ и программных документов;
— ГОСТ Р 59921.1-7-2022. Системы искусственного интеллекта в клинической медицине. Алгоритмы анализа медицинских изображений;
— ГОСТ Р 8.736—2011. Государственная система обеспечения единства измерений. Измерения прямые многократные. Методы обработки результатов измерений. Основные положения;
— Федеральный закон «Об информации, информационных технологиях и о защите информации» от 27.07.2006 №149-ФЗ.
Для обучения, внутренней и внешней валидации, клинико-технических и клинических испытаний технологий искусственного интеллекта применяют эталонные наборы данных, под которыми понимают упорядоченную совокупность:
— результатов диагностических исследований одной или нескольких модальностей и/или однотипных медицинских документов;
— сведений о наличии, характере и локализации и т. д. целевых признаков; для текстовых документов — библиотеки ключевых слов, словосочетаний и их критичных сочетаний;
— сведений о верификации (опционально).
Информация о наличии, характере, локализации и т. д. целевых признаков (в том числе в соответствии с Международной классификацией болезней — МКБ) может быть подтверждена объективно — в таком случае набор данных именуется верифицированным.
Размер набора данных (математически — размер выборки) и баланс классов определяются исходя из целей и задач проводимого исследования и требований технического задания на проведение исследований, а также с учетом требований заказчика.
Эталонный набор данных должен быть проверен профильной медицинской научно-исследовательской организацией на предмет полноты и качества содержащейся в нем информации. Рекомендуется при проведении клинических испытаний применять эталонные наборы данных, имеющие государственную регистрацию в качестве базы данных.
Эталонный набор данных для клинических испытаний должен содержать такие сведения (описательного характера) [4]:
— номер свидетельства о государственной регистрации базы данных (рекомендательно);
— характеристика популяции (гендерно-возрастные показатели, этнический состав, регионы проживания и т.д.);
— сведения о медицинских организациях, послуживших источниками для формирования набора данных;
— характеристика исследований: анатомическая область (-и), модальность, проекции;
— целевой признак;
— общее количество клинических случаев, исследований, изображений, документов и их распределение по диагностическим группам (в т.ч. «норма»/«патология»);
— сведения о верификации.
Требования к эталонному набору данных [4]:
1. Структура набора данных должна соответствовать поставленной цели его формирования (решаемой клинической задаче).
2. Планируемый размер эталонного набора данных должен быть обоснован в протоколе исследования, исходя из статистических соображений и желаемой точности оценки основных метрик.
3. Разметка должна быть проведена с использованием стандартизированной терминологии — т.н. тезауруса (кодированной библиотеки типовых формулировок, соответствующих нормативно-правовой документации, клиническим рекомендациям или рекомендациям профессиональных врачебных ассоциаций).
4. Подготовка и разметка должны быть проведены техническими и медицинскими специалистами, имеющими соответствующие навыки и компетенции.
Наборы данных для обучения и тестирования алгоритмов искусственного интеллекта можно классифицировать различными способами. Например, выделяют наборы со структурированными, частично структурированными и неструктурированными данными; либо разделяют их по источникам формирования, условиям использования, типам биомедицинских и клинических данных, по временным характеристикам, файловой структуре, наконец, по видам задач, для решения которых наборы сформированы и т. д.
Рекомендуется использовать две классификации: по диагностической ценности (подробнее см. параграф 1.2 «Классификация разметки и наборов данных») и по целевому назначению (подробнее см. параграф 3.1 «Этап инициирования создания набора данных»).
Контрольные вопросы
1. Дайте определение понятию «Набор данных».
2. Дайте определение понятию «Разметка данных».
3. Перечислите нормативно-правовые акты, регулирующие создание набора данных.
4. Что такое эталонный набор данных?
5. Перечислите основные требования к эталонному набору данных.
1.2. Классификация разметки и наборов данных
Под разметкой в контексте классификации медицинских наборов данных понимается установка категориального или визуального признака в данных, выполненная медицинским персоналом и/или врачом-экспертом.
Класс разметки варьируется в зависимости от задачи, поставленной ПО на основе ТИИ, и основывается на методах верификации данных. В таблице 1 представлены принципы классификации методов верификации, разработанные на основе собственного опыта, а также рекомендаций Управления по санитарному надзору за качеством пищевых продуктов и медикаментов (Food and Drug Administration, FDA [5]). Под верификацией понимают проверку данных на достоверность, правильность и точность. На рисунке 1 изображены методы верификации данных по возрастанию их ценности.

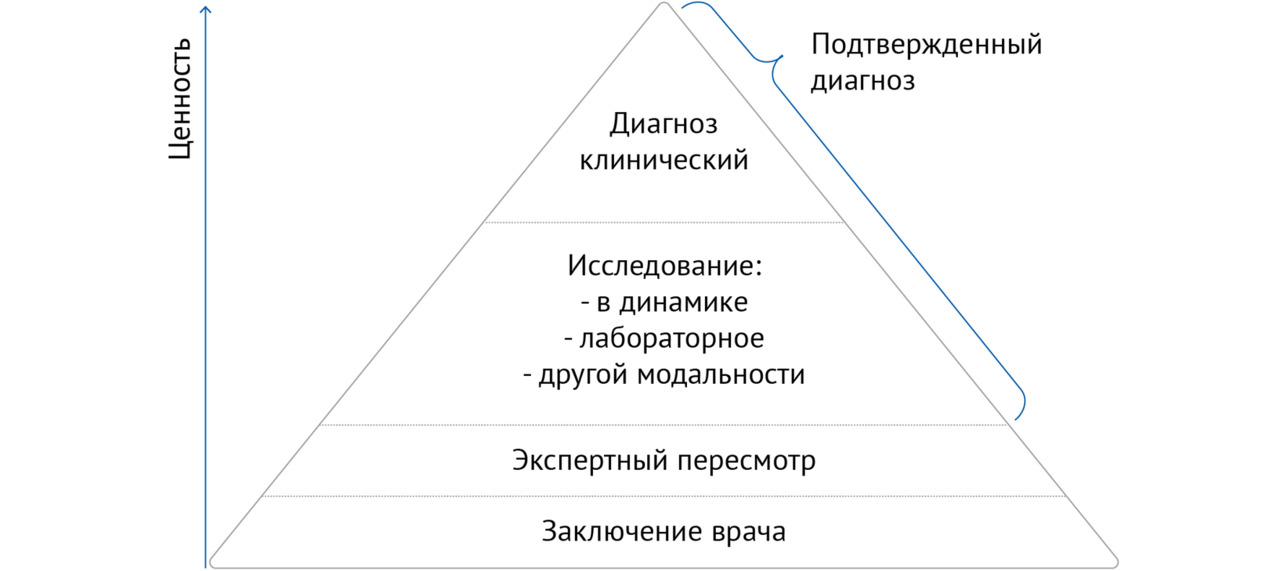
Наименьшей ценностью обладает верификация по заключению врача, т.е. вывод о наличии или отсутствии патологии делается на основании заключения врача, описывавшего исследование. Как правило, такой способ разметки используется на первых этапах отбора данных и может быть осуществлен с помощью алгоритмов автоматического анализа текстовых протоколов, например MedLabel. Следующим по ценности методом верификации является экспертный пересмотр: слепой анализ исследований врачами-экспертами с достижением заданного уровня согласованности их решений (подробно описан в подпараграфе 3.3.2 «Разметка данных»). Следующие две группы методов являются наиболее достоверными, и их можно условно назвать «подтвержденный диагноз»: исследование той же модальности в динамике, исследование другой модальности, лабораторное исследование, которые в совокупности с остальными данными медицинской карты дают клинический диагноз. Стоит отметить, что для верификации каждой патологии существует свой метод «золотого стандарта», который позволяет подтвердить диагноз.
На рисунке 2 представлена классификация видов разметки на примере рака молочной железы (РМЖ) с учетом ценности разметки.
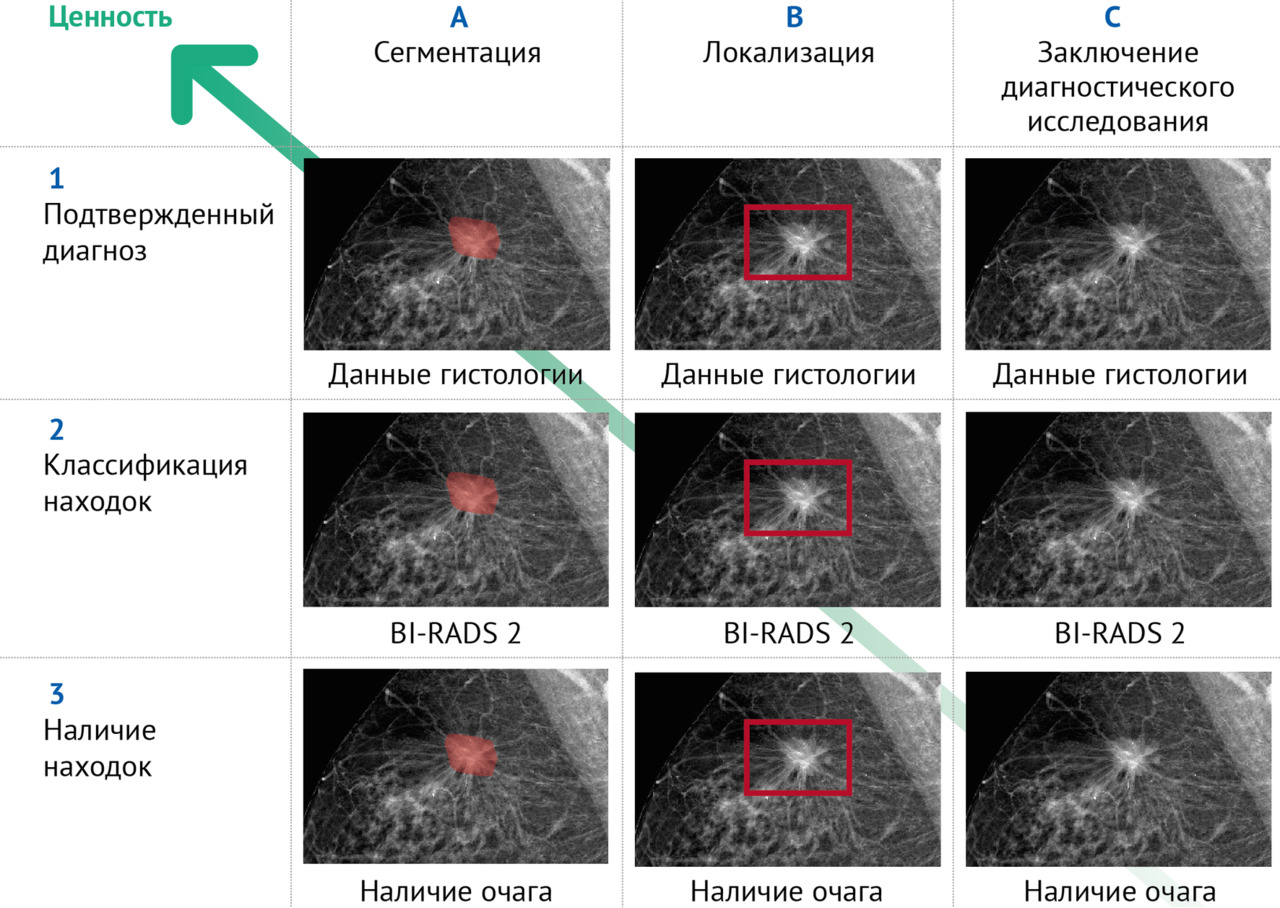
В наиболее общем виде разметка данных может проводиться на основании:
А. Информации об имеющейся целевой патологической находке, представленной на изображении в виде пиксельной маски (оконтуренной области изображения). Дополнительно может содержаться в метаданных (аннотации).
B. Информации об имеющейся целевой патологической находке, представленной в виде координат. Может помещаться в метаданных (в аннотации, в сводном табличном сопроводительном файле) и/или присутствовать на изображении в виде отметки области расположения простой геометрической фигурой.
С. Информации о наличии/отсутствии целевой патологической находки, содержащейся в метаданных (то есть в аннотации — сопроводительных файлах) и отсутствующей на изображении.
Классификация A, B, C для уровня 3 (обнаружение находки) предполагает вовлечение врачей-экспертов с целью поиска (наличие/отсутствие — С), локализации (В) и сегментации (А).
В случае локализации врачу необходимо обозначить координаты области интереса простой геометрической фигурой, в случае сегментации — обвести контур области интереса, т.е. создать пиксельную маску. Для уровня 2 (классификация находки) необходимо классифицировать находку, используя общепринятые шкалы (например, BI-RADS, ASPECTS). Для уровня 1 (подтвержденный диагноз) необходимы данные медицинской карты, позволяющие поставить диагноз.
Классификация отображает взаимосвязь:
— объемов и качества исходных данных;
— трудозатрат на подготовку;
— методик разметки и работы с первичными данными;
— диагностической ценности.
Стоит отметить, что данная классификация применима в случае поиска патологических находок. Для некоторых НД, например, при задаче сегментации анатомической структуры, подтверждение диагноза неприменимо, соответственно данную классификацию использовать нельзя.
Также разметку данных можно разделить на проспективную и ретроспективную, т.е. по времени их получения.
Проспективная разметка аналогично ретроспективной разметке представляет собой сбор элементов в соответствии с поставленной целью, при этом обязательным условием является проведение дополнительных манипуляций с элементами (например, постановка метки начала и окончания события, меток обнаружения признаков, обозначений патологий и т.п.). Этот вид разметки проводят с участием обученного медицинского персонала (зачастую квалифицированного врача в субспециализации размечаемого набора данных) путем ручного аннотирования содержания данных или их частей.
Ретроспективная разметка данных представляет собой сбор элементов в соответствии с метаданными, которые отбираются по поставленной цели. Такую разметку проводят путем минимальных трудозатрат: выгрузка данных происходит из медицинской информационной системы, которую может провести инженер (аналитик) без участия врача. При этом для каждого элемента (изображение, сигнальные данные и т.д.) набора данных устанавливают соответствие с медицинской информацией (диагноз, результаты лабораторного тестирования и т.п.).
Также разметка характеризуется следующими параметрами:
1. Уровень разметки: пациент, серия, набор изображений, изображение.
Примеры:
— на уровне пациента: у пациентки с диагнозом злокачественного новообразования (ЗНО) молочной железы разметка проводится на основании маммографии и гистологического исследования;
— на уровне серии (у той же пациентки): маммография, прямая и боковая проекции;
— на уровне изображения: прямая проекция правой молочной железы.
2. Тип разметки: бинарная, мультикласс, мультилейбл.
Примеры:
— бинарная разметка: норма/патология;
— мультиклассовая разметка: норма/патология/технический дефект;
— мультилейбл разметка: лейбл «Признаки эмфиземы легкого», лейбл «Процент поражения легкого».
3. Характер разметки: бинарная, категориальная, регрессионная.
Примеры:
— бинарная: наличие признаков патологии/отсутствие признаков патологии;
— категориальная: категория BI-RADS для маммографии;
— регрессионная: процент поражения легкого при COVID-19.
Контрольные вопросы
1. Какие бывают методы верификации данных?
2. Какие бывают виды разметки данных по диагностической ценности?
3. Как классифицируется разметка данных в зависимости от времени получения данных?
4. Перечислите параметры разметки.
5. Какие бывают уровни разметки данных? Приведите примеры.
Глава 2. ЖИЗНЕННЫЙ ЦИКЛ НАБОРОВ МЕДИЦИНСКИХ ДАННЫХ
Жизненный цикл — развитие системы, продукции, услуги, проекта или другой создаваемой изготовителем сущности — от замысла до вывода из эксплуатации.
Жизненный цикл данных — последовательность этапов, которую конкретная порция данных проходит от начального этапа создания или получения до момента архивации или удаления [6].
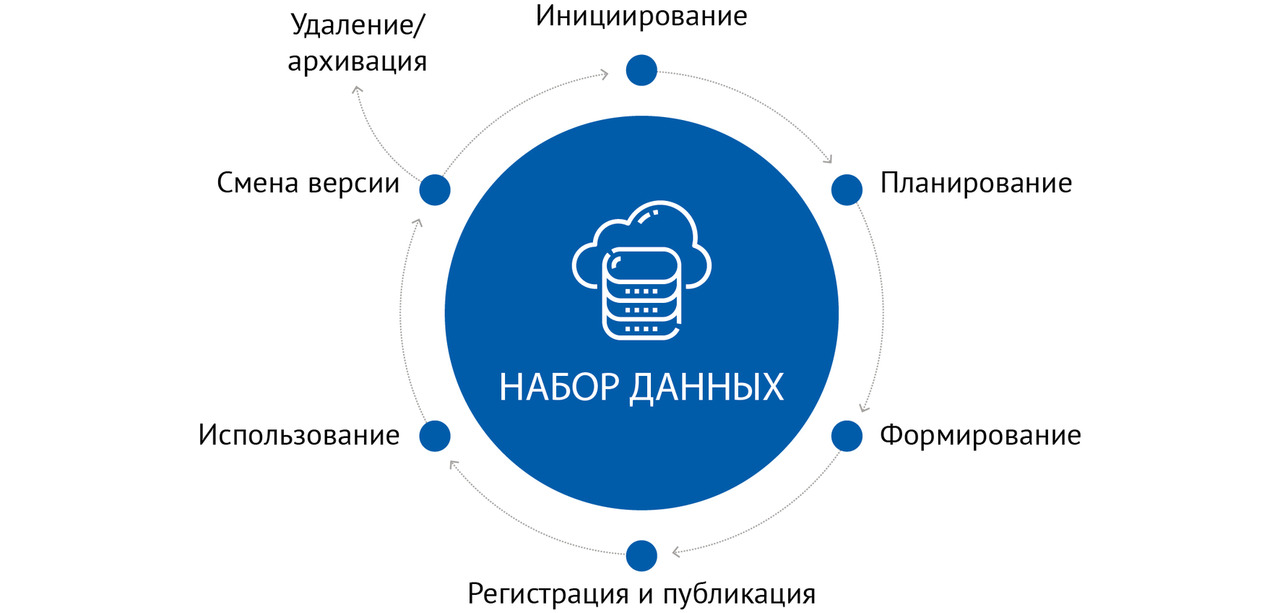
Жизненный цикл наборов данных состоит из следующих этапов:
— инициирования;
— планирования;
— формирования;
— этап регистрации и публикации;
— использования;
— смены версии;
— удаления и архивации.
Последовательность и взаимосвязь этих этапов представлена на рисунке 3.
Этап инициирования
Данный этап начинается с момента возникновения потребности или идеи создания НД, поэтому первое, с чем необходимо определиться — это цель их создания. На основании цели создания НД разработана классификация по типам:
I. Проведение тестирований для оценки функционала (функциональное тестирование) и оценки метрик диагностической точности, настройки ПО на основе ТИИ (калибровочное тестирование) [7].
II. «Самотестирование техническое» — проведение самостоятельной проверки разработчиками способности ПО на основе ТИИ обрабатывать исследования с диагностических устройств разных производителей и моделей [8].
III. «Самотестирование диагностическое» — проведение самостоятельной проверки корректности клинической интерпретации исследований ПО на основе ТИИ [9].
IV. Выполнение клинических испытаний — оценка безопасности и эффективности медицинского изделия [4,10].
V. Выполнение технических испытаний — оценка соответствия характеристик ПО на основе ТИИ требованиям нормативно-правовой, технической и эксплуатационной документации[11].
VI. Проведение разметки текстовых протоколов с помощью программ автоматизированного анализа текстов.
VII. Проведение научных исследований [12].
VIII. Разработка ПО на основе ТИИ: обучение и дообучение [13].
После определения цели создания НД формируются или используются ранее подготовленные базовые диагностические требования (БДТ) и базовые функциональные требования (БФТ) [14]. БДТ — это требования к содержащейся в информации НД, необходимой для решения поставленных задач и достижения цели (модальность исследования, целевая патология, критерии отнесения исследований к классам и т.д.). Процесс создания БДТ описан в главе 3, подпараграф 3.1.1. БФТ — это описание технических особенностей отображения результатов клинических исследований (серия изображений, толщина срезов, окно визуализации и т.д.). Процесс создания БФТ описан в главе 3, подпараграф 3.1.2.
БДТ и БФТ — основные документы для формирования технического задания (ТЗ), которое в свою очередь является основным документом, регламентирующим и структурирующим разработку НД. Процесс создания ТЗ описан в главе 3, подпараграф 3.1.3.
Этап планирования
На этапе планирования определяются сроки подготовки НД, финансовые и людские ресурсы (назначаются исполнители, а именно врачи-разметчики, специалисты, ответственные за сборку НД и формирование сопровождающей документации, руководитель проекта), необходимые для подготовки НД, определяются риски (технические, административные и т.д.), которые могут повлиять на выполнение работы. При определении содержания работ, осуществляемых конкретным специалистом, проводится декомпозиция ТЗ на создание НД и уточняются требования к составу, количеству исследований, типам и способам разметки для каждого из задействованных специалистов (если это необходимо для выполнения работы).
Этап формирования
На данном этапе происходит непосредственно процесс создания НД: сбор данных, их разметка, структурирование, анонимизация, формирование файлов данных, разметки и сопроводительного текстового файла (readme-файла). Все файлы помещаются в хранилище данных. Подробный алгоритм формирования НД описан в главе 3 (параграф 3.3 «Этап формирования набора данных»).
Этап регистрации и публикации
На этапе регистрации вся информация о НД вносится в реестр. Полностью формируется так называемая карточка НД, где указываются все клинические, популяционные, технические параметры, параметры разметки, область применения, а также сформированные название и идентификатор НД.
Завершающим этапом процесса создания НД является его публикация — помещение структурированного набора файлов в отдельную директорию хранилища с регламентированным уровнем доступа.
По уровню доступа НД разделяются на общедоступные (открытые), ограниченного доступа (закрытые) и закрытые с общедоступными примерами. Общедоступные НД размещаются в открытом доступе (так называемые библиотеки НД) и предназначены для использования разработчиками ПО на основе ТИИ для проведения обучения, тестирования и/или валидации своей разработки.
Наборы данных, имеющие ограниченный доступ, предназначены для проведения внутренних исследований или для предоставления третьим лицам на особых условиях.
Регламент предоставления доступа к закрытым НД определяется политикой информационной безопасности и законодательством Российской Федерации.
Этап использования
На данном этапе происходит непосредственное использование НД согласно целям, обозначенным на этапе инициирования.
Этап смены версии
В процессе подготовки набора данных необходимо определить следующие шаги по его сопровождению:
— изменение уровня доступа третьим лицам;
— частота обновления;
— срок поддержки;
— способ утилизации.
Некоторые категории наборов данных подлежат регулярным обновлениям. Изменения могут вноситься как в сопроводительную информацию (например, при появлении исследований в динамике для верификации), так и касаться самих единиц наборов данных (например, добавление новых случаев в особых эпидемиологических условиях). В этих случаях следует отдельно описать принципы получения новых данных, внесения изменений, в том числе в номер версии. Частота обновления данных оговаривается в ТЗ на подготовку набора данных.
Версия набора данных позволяет оценить вносимые изменения с течением времени. Изменения (включая любую смену версии) должны быть задокументированы, а документация — приложена к набору данных.
При смене версии предлагается использовать обозначения формата А.Б.В, где А — мажорная версия, Б — минорная версия, В — патч-версия:
— мажорная версия увеличивается при изменении значимых параметров набора данных, связанных с клинической задачей, целью, принципами разметки и верификации данных;
— минорная версия увеличивается при замене, добавлении и удалении единиц данных (изображений, текстовых или сигнальных данных и др.) без изменений значимых параметров набора данных (минорная версия Б = 0 при выпуске новой мажорной версии);
— патч-версия увеличивается при внесении корректировок в сопроводительную документацию, исправлении опечаток или ошибок в файлах разметки и верификации, при этом не меняется ни количество, ни качество входных данных (патч-версия В = 0 при выпуске новой минорной или мажорной версии).
Новый набор данных создается при условии полного изменения назначения, цели создания и клинических задач. При внесении изменений в НД ему присваивается новый идентификатор, и он проходит весь жизненный цикл заново.
Сроки поддержки НД определяются ТЗ и/или государственным контрактом на выполнение работ.
Этап удаления/архивации
По мере использования НД может оказаться более неактуальным и может быть скрыт из доступа, заархивирован в длительное хранение без возможности быстрого восстановления. Однако бесследное удаление НД не рекомендуется, так как в будущем может появиться необходимость восстановить источник «потерянных» исследований.
Контрольные вопросы
1. Опишите основные этапы жизненного цикла данных.
2. В чем заключается самотестирование техническое, самотестирование диагностическое?
3. В чем заключается выполнение технических испытаний?
4. Какие документы готовятся на этапе инициирования создания набора данных?
5. Опишите этап планирования. Какие основные факторы необходимо учитывать при планировании работ по созданию НД?
Глава 3. АЛГОРИТМ СОЗДАНИЯ НАБОРА ДАННЫХ
3.1. Этап инициирования создания набора данных
3.1.1. Базовые диагностические требования
Основным содержанием БДТ являются требования к результатам работы ПО на основе ТИИ [14]; они включают следующую информацию:
— тип исследования;
— клиническая задача, решаемая ПО на основе ТИИ;
— критерии классификации исследования;
— содержание ответа ПО на основе ТИИ;
— формат представления ответа ПО на основе ТИИ.
Раздел «тип исследования» включает в себя данные о модальности исследования и области сканирования. Данная информация представлена в клинических рекомендациях по лечению соответствующей патологии.
Раздел «клиническая задача, решаемая ПО на основе ТИИ» определяет целевое назначение НД.
При постановке клинической задачи необходимо учитывать, что ПО на основе ТИИ решает те задачи или часть задач, которые решает врач при описании исследования по данному направлению. Например, при описании ММГ врач-рентгенолог должен оценить:
— техническое качество выполнения исследования (PGMI);
— плотность молочной железы по шкале ACR;
— изменения в ткани молочной железы по шкале BI-RADS (выявить и классифицировать).
Соответственно, при постановке клинической задачи для ПО на основе ТИИ может быть решена как отдельно третья задача, так и все три. В зависимости от поставленной задачи для ПО будут формироваться требования для НД. Таким образом, НД может состоять из исследований, классифицированных только по шкале BI-RADS, или может быть дополнен значениями по шкале ACR и PGMI.
Однозначность и точность формулировки клинической задачи позволяет определить, в частности, является ли выбранный метод диагностики «золотым стандартом» в отношении выбранной патологии либо требуется дополнительная верификация. Так, например, для злокачественных новообразований легкого корректная формулировка клинической задачи звучит следующим образом: «Выявление компьютерно-томографических признаков, коррелирующих с наличием злокачественных новообразований в легких», так как диагноз «ЗНО легкого» не может быть выставлен только по данным компьютерной томографии (КТ). В то же время для диагностики дилатации брюшной аорты необходимо и достаточно данных КТ, поэтому клиническая задача формулируется более конкретно: «Определение расширения брюшного отдела аорты».
Раздел «критерии классификации исследования» определяет тип классификации (бинарная либо мультиклассовая) и постулирует критерии отнесения исследования к каждому из классов. Необходимо указать однозначные и непересекающиеся критерии включения в каждый класс, поэтому стоит остановиться на некоторых аспектах терминологии.
Класс — это множество всех объектов с заданным значением метки. В медицинских данных чаще всего встречаются классы «наличие патологии / отсутствие патологии» в случае бинарной классификации или, в случае мультиклассовой классификации, шкалы степени тяжести заболевания (КТ-COVID, BI-RADS, ASPECTS и т.д.). Еще одним примером мультиклассовой классификации является разделение исследований на группы: наличие патологии / отсутствие патологии / технический дефект. Лейбл (от англ. label — ярлык, этикетка) — название патологического (или нормального) состояния, которое подвергается классификации. Например, в НД компьютерной томографии грудной клетки может быть 2 лейбла: «признаки рака легких» и «признаки коронавирусной инфекции».
Критерии включения могут быть пороговыми, в тех случаях, когда диагностический признак патологии имеет явное численное определение (например, размеры объекта или его рентгеновская плотность), или неявными (например, паттерны поражения легочной ткани, характерные для пациентов с COVID-19). Стоит учесть, что для некоторых патологий диапазоны численных значений диагностических признаков могут перекрываться или быть относительными (например, гиподенсное образование печени — область, рентгеновская плотность которой ниже средней плотности неизменной ткани печени). В этих случаях следует отдельно рассмотреть возможность явного определения класса патологии как совокупности отдельных признаков. При формулировке критериев особое внимание надо уделить доступности их восприятия: определения должны быть лаконичными и не содержать большой объем узкоспециальной терминологии, численные диапазоны величин необходимо сопровождать ссылками на литературные источники.
Формулировка критериев должна проводиться строго в рамках выбранной клинической задачи. При наличии у искомой патологии (иного) верификационного диагностического метода, его можно указать опционально (в разделе дополнительной информации).
В случае если первичной задачей при подготовке НД является не классификация исследований, а их сегментация или детекция, данный раздел формируется исходя из критериев отнесения объектов к целевой области интереса (перечисляют не диагностические, а сегментационные признаки объекта).
Раздел «содержание ответа ПО на основе ТИИ» должен отражать обязательные и опциональные требования к результатам работы ИИ. При формировании содержания раздела необходимо учесть целевое назначение ПО и его объективный потенциал. Важно в каждом конкретном случае разграничить задачи врача и ПО на основе ТИИ, учитывая, что общей задачей внедрения ТИИ в диагностику является автоматизация рутинных процессов. Целевое назначение конкретного ПО определяется исходя из клинического сценария диагностики соответствующей патологии.
Пример
Диагностика лимфаденопатии проводится на основании измерения лимфоузлов, следовательно, от ПО на основе ТИИ требуется измерение всех лимфоузлов выбранной области и выделение тех, чьи размеры превышают диагностический порог патологии.
К обязательным требованиям относят представление всех признаков, которые необходимы для однозначной классификации исследования в рамках поставленной клинической задачи. К опциональным требованиям относят функционал ПО, определяющий его потенциал в отношении удобства использования врачом-оператором.
При заполнении данного раздела стоит учитывать, что обе категории требований (обязательные и опциональные) к содержанию ответа ПО на основе ТИИ должны однозначно соответствовать разметке НД. Следовательно, НД должен быть подготовлен так, чтобы любой из указанных в данном разделе пунктов можно было бы верифицировать или оценить.
Необходимо отметить класс диагностических задач, который предполагает косвенный расчет параметров. К таким задачам относят использование различных шкал или индексов (таких как Genant или Agastson) и других метрик, предполагающих применение специальных формул расчета или таблиц. В этих случаях результаты полуавтоматического анализа изображения обычно слабо коррелируют с субъективной оценкой врача. Например, процент поражения легочной ткани при эмфиземе может быть диффузным (распределенным) в объеме легких, что затрудняет постановку диагноза при визуальной оценке изображения, однако не влияет на результат автоматического анализа области. При формировании НД для подобных задач стоит заранее определить инструментарий создания достоверной разметки (например, использовать инструменты полуавтоматической сегментации).
Раздел «формат предоставления ответа ПО на основе ТИИ» кратко обобщает формат и вид представления каждого из ответов ПО на основе ТИИ. Результаты его работы могут быть в виде одного либо комбинации следующих типов:
— численное значение конкретного диагностического признака (например, размер объекта) либо вероятности отнесения к классу;
— контур либо маска, однозначно определяющая локализацию объекта;
— текст для категориальных величин.
Формирование раздела определяется способом постобработки результатов ПО на основе ТИИ. БДТ содержит общую информацию о формате данных, детализация процедуры обмена данными отражена в базовых функциональных требованиях.
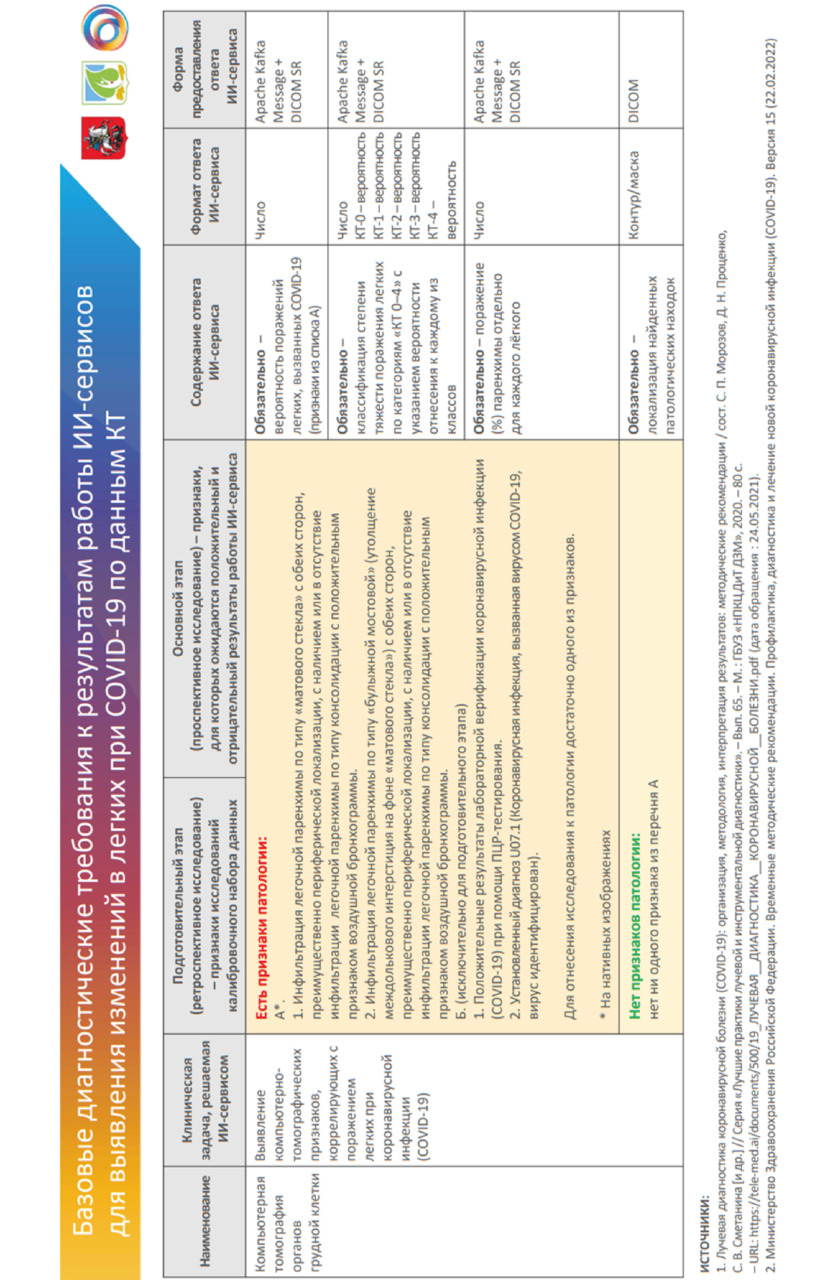
Для специалиста, создающего НД, ключевое значение в БДТ имеют наименование, клиническая задача и содержание подготовительного этапа. Главный этап относится к ПО на основе ТИИ на этапе практического использования. Пример заполнения БДТ представлен на рисунке 4.
3.1.2. Базовые функциональные требования
Основное содержание БФТ представляет собой обязательный набор требований к работе ПО на основе ТИИ для использования в деятельности практикующих врачей-рентгенологов. Документ содержит детализированную информацию по следующим пунктам:
— параметры исследования: серия, толщина срезов, окно визуализации;
— подробное описание и требования к формату представления, структуре и содержанию результатов работы ПО на основе ТИИ;
— подробное описание процедуры обработки данных ПО на основе ТИИ: порядок предоставления, защиты, хранения и удаления данных, обработки исключений (например, формирование сообщений об ошибках работы);
— словарь ключевых терминов для формирования машиночитаемых отчетов о работе ПО на основе ТИИ.
Раздел «параметры» содержит в себе указание серии исследований, требуемых для анализа целевой патологии.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.