
Бесплатный фрагмент - Искусственный интеллект в лучевой диагностике: Per Aspera Ad Astra
Рецензенты
Нуднов Николай Васильевич — д-р мед. наук, профессор, заместитель директора по научной работе, заведующий НИО комплексной диагностики заболеваний и радиотерапии ФГБУ «Российский научный центр рентгенорадиологии» Минздрава России
Лебедев Георгий Станиславович — д-р техн. наук, профессор, директор Центра цифровой медицины, заведующий кафедрой информационных технологий и обработки медицинских данных ФГАОУ ВО «Первый Московский государственный медицинский университет им. И. М. Сеченова» Минздрава России (Сеченовский Университет)
Научно-исследовательская работа, в рамках которой подготовлена монография
Данная монография подготовлена авторским коллективом в рамках НИР «Научные методологии устойчивого развития технологий искусственного интеллекта в медицинской диагностике» (№ ЕГИСУ: №123031500004—5) в соответствии с приказом Департамента здравоохранения города Москвы от 22.12.2023 г. №1258 «Об утверждении государственных заданий, финансовое обеспечение которых осуществляется за счет средств бюджета города Москвы, государственным бюджетным (автономным) учреждениям, подведомственным Департаменту здравоохранения города Москвы, на 2024 год и плановый период 2025 и 2026 годов».
Источники иллюстраций
1. Управление пресс-службы и информации Президента России. Официальный сайт Президента России.
2. Пресс-служба Мэра и Правительства Москвы.
3. ГБУЗ «НПКЦ ДиТ ДЗМ». Автор: Приходько Алексей Владимирович.
4. ЕРИС ЕМИАС.
ВСТУПЛЕНИЕ
В октябре 2019 г. Указом Президента Российской Федерации утверждена Национальная стратегия развития искусственного интеллекта на период до 2030 года, определяющая цели и основные задачи такого развития, а также меры, направленные на использование искусственного интеллекта в целях обеспечения национальных интересов и реализации стратегических национальных приоритетов, в том числе в области научно-технологического развития.
Национальная стратегия прямо установила, что использование технологий искусственного интеллекта в социальной сфере поспособствует созданию условий для улучшения уровня жизни населения, в том числе за счет повышения качества услуг в области здравоохранения, включая профилактические обследования, диагностику, основанную на анализе изображений, прогнозирование возникновения и развития заболеваний, подбор оптимальных дозировок лекарственных препаратов, сокращение угроз пандемий, автоматизацию и точность хирургических вмешательств.
Спустя месяц после утверждения национальной стратегии Правительство города Москвы издало Постановление о проведении эксперимента по использованию инновационных технологий в области компьютерного зрения для анализа медицинских изображений и дальнейшего применения в системе здравоохранения города Москвы (далее — Московский эксперимент).
De jure целью Московского эксперимента стало «исследование возможности использования в системе здравоохранения города Москвы методов поддержки принятия решений на основе результатов анализа данных с применением передовых инновационных технологий».
De facto основной целью явилось исследование применимости, безопасности и качества технологий искусственного интеллекта (компьютерного зрения) в лучевой диагностике, а дополнительной — создание нового рынка в области цифровых технологий.
Московский эксперимент стал своеобразным «эпицентром», в котором сошлись:
— утверждение стратегической важности сквозного развития и внедрения технологий искусственного интеллекта;
— необходимость системного повышения производительности, доступности и качества лучевых исследований;
— научный подход в соответствии с принципами доказательной медицины, требовавший многоцентрового проспективного клинического исследования неограниченного числа алгоритмов искусственного интеллекта в условиях реального лечебно-диагностического процесса;
— экономическая целесообразность в виде создания новых сегментов рынка;
— необходимость создания условий для эффективного взаимодействия государства, организаций, в том числе научных, и граждан в сфере развития искусственного интеллекта.
Вместе с тем важно отметить, что Московский эксперимент был организован «не на пустом месте». Основанием его проведения стали результаты многолетней комплексной деятельности Научно-практического клинического центра диагностики и телемедицинских технологий Департамента здравоохранения города Москвы (НПКЦ ДиТ ДЗМ) — ведущего учреждения в области лучевой, инструментальной диагностики и цифровизации практической медицины.
Здесь очень важно подчеркнуть историческую преемственность. История развития технологий искусственного интеллекта — как составной части кибернетики, информатики, инженерии, компьютерных и биомедицинских наук — в России насчитывает около двух столетий. Точкой старта этого процесса можно считать издание в 1832 году научного труда Семена Николаевича Корсакова (1787–1853), содержащего описание конструкций пяти «машин, сравнивающих идеи», перфокарт, метода многокритерального поиска с использованием весовых коэффициентов, а также фактически первого способа обработки больших данных. В ХХ веке научное развитие соответствующей предметной области связано с плеядой выдающихся отечественных ученых, среди которых можно особо отметить А. И. Берга, В. М. Глушкова, А. И. Китова, С. А. Лебедева, А. А. Ляпунова, Н. С. Мисюка, И. А. Полетаева. В сфере здравоохранения становление и уникальный прогресс биологической и медицинской кибернетики, автоматизированного анализа биомедицинских данных связан с именами Н. М. Амосова, П. К. Анохина, Н. А. Белова, Н. А. Берштейна, А. А. Богданова, М. Л. Быховского, М. П. Вилянского, А. А. Вишневского, С. А. Гаспаряна, М. С. Гельфанда, М. М. Завадовского, А. С. Кронрода, А. П. Матусовой, Ю. И. Неймарка, Э. Ш. Халфена, Д. С. Чернавского и многих-многих других замечательных врачей, организаторов здравоохранения, инженеров, математиков. Научные знания и практический опыт, обобщенные в трудах этих выдающихся ученых, служат фундаментальной основой современных научных исследований в области технологий искусственного интеллекта в здравоохранении.
Деятельность НПКЦ ДиТ ДЗМ по изучению проблематики искусственного интеллекта (ИИ) в здравоохранении можно условно разделить на два этапа.
I. Научные и аналитические исследования в области искусственного интеллекта. В начале ХХI в. лучевая диагностика окончательно заняла лидирующие позиции среди прочих дисциплин в области цифровизации. В силу революционных преобразований парка диагностических устройств (перехода от «аналоговых» приборов к «цифровым») именно в рентгенологии и радиологии внедрялись самые передовые информационные и телекоммуникационные технологий. Отмечалась высокая готовность соответствующего врачебного сообщества к цифровым инновациям.
Вклад лучевой диагностики в скрининг, диагностику, стадирование, контроль динамики и результативности лечения множества нозологий постоянно и стремительно возрастает. В период 2014–2019 гг. в России отмечался ежегодный прирост абсолютного количества лучевых исследований на 2,5–3,0%, а в 2019–2020 гг. и в период пандемии COVID-19 — на 4,6–8,2%. Столь же интенсивно меняется структура исследований. Постоянно нарастает количество сложных современных методов — компьютерной и магнитно-резонансной томографии — причем во многом за счет исследований, выполняемых в амбулаторных условиях, в первичном звене здравоохранения. Относительно пропорционально сокращается число рентгенологических исследований, однако здесь есть свои особенности.
На востребованность и количество рентген-исследований критично влияет профилактическое направление медицины, ведь именно рентгенография, флюорография и маммография служат основными инструментами скрининга онкологических заболеваний, туберкулеза и иных социально значимых заболеваний. В интересах обеспечения общественного здоровья требуется наращивание объемов их проведения.
Рост количества исследований взаимосвязан с характеристиками парка оборудования. На фоне интенсивного его увеличения и цифровизации во всей стране все более значительным становится вопрос эффективного и одновременно бережливого использования оборудования лучевой диагностики. Хорошо известна проблематика дисбаланса оснащенности аппаратурой, ее загрузки и доступности исследований. В условиях внедрения все большего количества современных аппаратов еще сильнее обостряется вопрос назначения и применения соответствующих современных методов исследований, прежде всего с контрастным усилением.
На основе сказанного следует заключить, что в современном здравоохранении существенным образом изменились условия и требования к работе врачей-рентгенологов. Теперь эти специалисты трудятся с колоссальной и постоянно увеличивающейся нагрузкой, на фоне непрерывно возрастающих требований к качеству и точности, а в контексте массовых профилактических осмотров населения — еще и в условиях высокой рутинности, можно сказать, механистичности. Именно профилактические рентгенография (флюорография) и маммография занимают до 30,0% в структуре всех лучевых исследований — это гигантская цифра. При интерпретации их результатов врачи-рентгенологи сталкиваются с однотипными описаниями преимущественно нормальных состояний. Эта масштабная, стереотипная работа крайне негативно сказывается как на отдельных профессиональных траекториях (то самое пресловутое «выгорание»), так и на доступности сложных диагностических методов для населения (ведь колоссальный кадровый ресурс занят шаблонными описаниями нормальной рентгенологической картины).
С одной стороны, и трудоемкость работы, и риск ошибки у врачей-рентгенологов чрезвычайно высоки, а с другой — все более нарастает дефицит таких специалистов. Отметим, что текущее состояние — рост востребованности, количества исследований и парка оборудования на фоне неустранимого кадрового дефицита — полностью характерно не только для России, но и для всех стран с развитой экономикой. Дело в том, что темпы роста парка оборудования и потребности в лучевых исследованиях (включая профилактические) уже навсегда превзошли все возможные темпы наращивания физического количества врачей-рентгенологов.
Осознание сказанного уже привело к существенным изменениям в привычной (или, точнее сказать, безнадежно устаревшей) организационной модели, в рамках которой у каждого диагностического аппарата обязательно находился врач-рентгенолог. Централизация лучевой диагностики успешно реализована во многих странах мира, в ряде субъектов РФ, в том числе в г. Москве. Благодаря цифровизации и развитию телемедицинских технологий врачей-рентгенологов физически «отделили» от аппаратов и собрали в крупных референс-центрах. Такая новая организационная модель уже убедительно доказала свою значимость и эффективность, минимизировав проблему кадрового дефицита, повысив доступность и качество лучевых исследований. Но в ближайшие 5–10 лет и ее возможности будут исчерпаны.
С точки зрения физической организации кадрового ресурса новые подходы вряд ли появятся. Следовательно, нужно развивать инструментарий врача-рентгенолога. Лучевой диагностике нужен принципиально новый уровень автоматизации процессов анализа, интерпретации и описаний результатов исследований. Здесь на сцену и выходит искусственный интеллект…
В 2015 г. в НПКЦ ДиТ ДЗМ, впервые в Российской Федерации, начались системные научные исследования применения технологий искусственного интеллекта в лучевой диагностике, в том числе по направлениям:
— стандартизация и методология подготовки данных для обучения алгоритмов;
— клинический контекст применения ИИ, в том числе как основа для продуктивной его разработки;
— оценка качества и методология клинических испытаний технологий ИИ.
Был проведен ряд аналитических и научных исследований. Аналитические работы охватывали: систематизацию научных публикаций; мониторинг и анализ рынка; коммуникации с компаниями-разработчиками и врачебным сообществом (включая организацию публичных конкурсов «ИИ-баттл: рентгенологи против искусственного интеллекта»).
Научные изыскания представляли собой эмпирическую разработку методологий создания наборов данных и оценки качества ИИ, а также непосредственную оценку диагностической точности алгоритмов.
В целом изучен и систематизирован международный опыт как отраженный в публикациях, так и представленный в ходе экспертных интервью. Установлены коммуникации с ведущими научными группами и компаниями-разработчиками.
Также были начаты собственные изыскания по проблематике создания наборов данных (датасетов) для обучения и тестирования технологий ИИ. Четыре таких набора получили свидетельство о государственной регистрации базы данных. Для помощи многочисленным разработчикам в 2018 г. (впервые в Российской Федерации) в свободном доступе разместили ограниченный деперсонализированный набор размеченных компьютерных томограмм грудной клетки.
С применением собственных наборов данных проведены оригинальные исследования 18 алгоритмов автоматизированного анализа диагностических изображений и одного алгоритма для распознавания естественного языка и анализа медицинской документации компаний-разработчиков из России, а также Бельгии, Великобритании, Индии, Испании, Китая, Нидерландов, ОАЭ, США, Южной Кореи.
В ходе исследования установлены следующие принципиальные проблемы:
1. Отсутствие в глобальной перспективе общепринятых инструментов научного анализа технологий искусственного интеллекта в медицине.
2. Отсутствие в глобальной перспективе стандартов или хотя бы общепринятых правил разметки данных и создания наборов данных.
3. Широко распространенные типовые проблемы со стороны разработчиков:
— отсутствие клинически обоснованного целеполагания;
— непонимание контекста применения автоматизации в реальных производственных процессах;
— отсутствие или пренебрежение стандартами, применяемыми в практическом здравоохранении;
— отсутствие методического понимания сути автоматизированного анализа медицинских изображений;
— плохая воспроизводимость результатов работы ИИ на новых данных;
— отсутствие стандартов при формировании наборов данных для обучения ИИ;
— игнорирование принципов объяснимости работы искусственного интеллекта;
— отсутствие независимой валидации алгоритмов на новых данных, в том числе в дизайне проспективных мультицентровых исследований;
— незнание или игнорирование принципов доказательной медицины;
— отсутствие внутренней системы менеджмента качества у компаний-разработчиков;
— низкая конверсия перспективных разработок в готовые продукты, сертифицированные в качестве медицинских изделий.
Вместе с тем предыдущий опыт автоматизации в области здравоохранения позволял рассчитывать на значительные положительные эффекты за счет внедрения ИИ и в лучевой диагностике. Более того, удалось объективно выявить ряд конкретных задач для такой автоматизации. Многие тестирования существующих решений на основе ИИ были достаточно успешными, алгоритмы надежно и качественно справлялись с клинически вполне обоснованными задачами. Все сказанное в совокупности вселяло оптимизм и убежденность в необходимости дальнейших научных исследований. При этом разработка методологий создания наборов данных и тестирования ИИ на этапах жизненного цикла определена в качестве одной из ключевых задач собственной программы научных исследований.
II. Создание инфраструктуры. Для применения технологий ИИ в оптимальном масштабе и с высокой эффективностью требуется наличие единого цифрового пространства лучевой диагностики в рамках субъекта РФ: централизованного архива медицинских изображений с подключением до 100% диагностического оборудования и обеспечением доступа к результатам исследований до 100% врачей-рентгенологов.
В городе Москве технологической реализацией сказанного стал Единый радиологический информационный сервис в составе Единой медицинской информационно-аналитической системы города Москвы (ЕРИС ЕМИАС).
ЕРИС ЕМИАС — это информационная система в сфере здравоохранения, которая объединяет рабочие места рентгенолаборантов, врачей-рентгенологов и диагностическую аппаратуру, аккумулирует информацию о каждом исследовании или серии исследований, проведенных на подключенных к нему устройствах.
Создание ЕРИС ЕМИАС — длительный и сложный процесс, реализованный Департаментом здравоохранения Москвы, Департаментом информационных технологий Москвы, Научно-практическим клиническим центром диагностики и телемедицинских технологий ДЗМ (выступавшим в критически значимой и крайне ответственной роли функционального заказчика).
Концептуальные и подготовительные работы в области централизации лучевой диагностики велись примерно в 2011–2014 гг. Первая апробация ЕРИС проведена в течение 2015 г., наращивание числа подключенных медицинских организаций амбулаторно-поликлинического звена интенсивно проводилось в 2016 г. В 2017 г. ЕРИС вышел на рутинный порядок использования. В 2018 г. проведена интеграция ЕРИС и ЕМИАС. В 2019 г. начато подключение к ЕРИС ЕМИАС медицинских организаций стационарного звена. В 2020 г. завершено формирование единого цифрового пространства лучевой диагностики столицы. К централизованному архиву подключено 100% цифрового оборудования для рентгенологических исследований и магнитно-резонансной томографии; обеспечена возможность работы для всех врачей-рентгенологов и рентгенолаборантов медицинских организаций Департамента здравоохранения города Москвы (ДЗМ). В фазе апробации в ЕРИС ЕМИАС было накоплено около 95 тысяч изображений, в фазе рутинного применения в 2020 г. (то есть в момент старта Московского эксперимента) их общее количество превысило 7 миллионов.
На инфраструктурной основе ЕРИС ЕМИАС в 2020 г. внедрена модель организации медицинской помощи в виде централизации лучевой диагностики. На базе НПКЦ ДиТ ДЗМ создан Московский референс-центр лучевой диагностики. Основными его процессами стали первичные описания результатов лучевых исследований, выполняемых в первичном звене здравоохранения в амбулаторных условиях; двойные просмотры результатов профилактических исследований (а в период пандемии и результатов компьютерной томографии пациентов с подозрением на новую коронавирусную инфекцию); экспертные дистанционные консультации; дистанционный контроль качества.
Наличие действительного единого цифрового пространства лучевой диагностики г. Москвы стало предпосылкой для централизованного и стандартизированного внедрения технологий ИИ.
Авторы монографии выражают искреннюю благодарность и глубочайшее профессиональное уважение руководителям и сотрудникам Комплекса социального развития города Москвы, Департамента здравоохранения города Москвы, Департамента информационных технологий города Москвы, медицинских организаций государственной системы здравоохранения города Москвы, всем замечательным коллегам, ученым, врачам и организаторам здравоохранения, инженерам, математикам и кибернетикам, предпринимателям и руководителям, а также всем сотрудникам ГБУЗ «НПКЦ ДиТ ДЗМ» г. Москвы, благодаря кропотливому труду которых за пять лет произошел качественный переход в развитии технологий искусственного интеллекта для лучевой диагностики!
Глава 1. МОСКОВСКИЙ ЭКСПЕРИМЕНТ КАК НАУЧНОЕ ИССЛЕДОВАНИЕ: ПРОБЛЕМЫ КОНТЕКСТА, МЕЖДИСЦИПЛИНАРНОСТЬ, ФОРМАЛЬНОЕ СТРУКТУРИРОВАНИЕ
Имей при себе молоток и гвоздь и воздвигни город.
А. К. Гастев
Быстрый прогресс технологий искусственного интеллекта после 2010 г. связан с развитием вычислительной инфраструктуры, сделавшей использование математических моделей весьма доступным; с эволюцией математических методов, прежде всего нейронных сетей, методик машинного обучения; с накоплением массивов цифровых данных, с одной стороны, пригодных для обучения искусственного интеллекта, а с другой — требовавших обработки и анализа с его помощью.
Указанная ситуация в полной мере наблюдалась и в медицине. Лучевая диагностика, будучи лидером цифровизации, вполне справедливо рассматривалась как наиболее перспективная область для внедрения ИИ. Вместе с тем погоня за самопиаром отдельных «айти-гуру» приводила к одиозным заявлениям о полной замене врачей технологиями ИИ, о необходимости вовсе прекратить подготовку рентгенологов как представителей более неактуальной специальности и прочем. Очевидно, что особое влияние подобные «выкрики» оказывали прежде всего на немедицинскую аудиторию, слабо представляющую реальность медицинской помощи и организации здравоохранения. Впрочем, строго по правилам диалектики, и в этих событиях были положительные результаты — значительное количество математиков, инженеров и ИТ-специалистов заинтересовались разработкой ИИ для медицины и буквально «пришли в отрасль».
Наглядной иллюстрацией этих событий служит всплеск публикационной активности в биомедицинских журналах. Например, по данным библиографической системы Pubmed, в 2010–2015 гг. количество статей об ИИ в рецензируемых медицинских журналах плавно нарастало от 4500 до 6800 в год, а в 2016 г. начался стремительный рост этого показателя с практически удвоением ежегодного числа публикаций в 2019–2020 гг. (порядка 16 400 и 22 600 статей в год соответственно). В 2024 г. на тему ИИ в биомедицинских журналах, индексируемых Pubmed, опубликована почти 51 тысяча статей.
Вместе с тем за истекшие 10 лет «ИИ-революции» в здравоохранении не произошло. Нейросети не заменили врачей, в большинстве экономически развитых стран мира применение технологий ИИ в медицине носит довольно ограниченный характер (во всяком случае принципиально меньший, чем предрекали всяческие «айти-гуру»).
Хайп искусственного интеллекта привел в отрасль здравоохранения новых специалистов и множество больших и малых научных групп, что проявилось колоссальным ростом научной продукции, но минимальным внедрением реально работающих продуктов. В чем же причина такого диссонанса?
Ответ очевиден — низкое качество научных исследований и игнорирование принципов доказательной медицины. Огромный энтузиазм пришедших в отрасль немедицинских специалистов сочетался с игнорированием ими всех устоев медицинской науки. Принцип Noli Nocere! воспринимался исключительно как ретроградный подход «вечно консервативных врачей». Необходимость доказывать безопасность, качество и эффективность предлагаемых инструментов на основе ИИ (по аналогии со всеми иными средствами, применяемыми в медицине) не воспринималась, а нередко и прямо высмеивалась.
Очевидно, что в такой ситуации отношение профессионального медицинского сообщества к технологиям ИИ оставалось настороженным, а пенный поток хайпа только добавлял в это отношение еще и предвзятости. Объективным подтверждением сказанного служат статьи совершенно независимых авторов.
В 2019 г. научная группа из Южной Кореи опубликовала анализ 516 научных статей о применении ИИ для анализа медицинской визуализации (как наиболее перспективной области для внедрения ИИ). Включенные статьи были изданы в 2018 г., фактически — на самой волне ажиотажа под лозунгом «заменим всех рентгенологов на ИИ!».
Проанализировав 516 публикаций в рецензируемых биомедицинских журналах, ученые установили, что 99,0% из них представляют собой доказательства концепции (proof-of-concept study) и технические обоснования (feasibility study). Нелишним будет подчеркнуть, что с позиций доказательности такие публикации представляют для врачебного сообщества фактически нулевую ценность. Только 1,0% статей написан в дизайне диагностического исследования в соответствии с принципами доказательной медицины. Но и здесь были колоссальные проблемы: в 94,0% случаев авторы статей и разрабатывали, и тестировали свои алгоритмы на одних и тех же наборах данных. В свою очередь, 97,0% использованных датасетов формировалось из данных только одной медицинской организации. В целом внешняя валидация ИИ на незнакомых данных была проведена только в 6,0% исследований.
Таким образом, для медицинского сообщества огромный массив публикаций был совершенно неинформативен, а жалкий 1,0% диагностических исследований содержал колоссальные методические недостатки. Более того, воспроизводимость результатов работы ИИ вообще не изучалась. На закономерный и спокойный вопрос врача: «Как ваш ИИ будет работать на данных из другой больницы?» многочисленным «айти-гуру» оставалось только хвастаться инвестициями в свой стартап и ругать консервативных врачей.
В 2020 г. научная группа из Великобритании опубликовала статью с систематическим анализом дизайна, стандартов отчетности, рисков предвзятости, а также доказательности результатов исследований, сравнивающих эффективность и точность алгоритмов ИИ и опытных врачей. Областью применения ИИ вновь стала медицинская визуализация.
В исследование включены 236 статей, опубликованных с 2010 по 2019 гг. и позиционируемых как «клинические исследования». Углубленный анализ показал, что 96,0% из них выполнены в ретроспективном дизайне, то есть представляли собой тестирование алгоритмов на эталонных наборах данных. Действительно, дизайн рандомизированного клинического исследования (ценного и информативного с позиций доказательной медицины) имели всего лишь 4,2% статей. И даже из этого крошечного числа многие работы были выполнены в «экспериментально-лабораторных условиях». Лишь 2,5% статей содержали результаты работы ИИ в реальных условиях практического здравоохранения. Во многих включенных статьях утверждалось преимущество ИИ над врачом, при этом алгоритмы сравнивали в среднем с 4 специалистами (количество включенных врачей колебалось от 2 до 9). Таким образом, и «клинические исследования» точности ИИ были откровенно слабы, а их результаты неубедительны.
Невзирая на бурную публикационную активность, явно ощущаемый потенциал технологий ИИ оставался совершенно нераскрытым для медицины и здравоохранения. Ценность и убедительность доказательств качества и преимуществ ИИ были мизерными. Отдельную проблему составляли манипуляции со статистикой, полностью обесценивавшие публикации об ИИ для врачей. Очевидно, что использование ограниченных наборов данных (авторам этого текста встречалась работа, выполненная на 5 МРТ!) не позволяло получать адекватные показатели точности. Недобросовестные авторы пытались это скрывать путем манипуляций со статистическими показателями, внесением изменений в стандартные формулы чувствительности и специфичности, необоснованным вводом неких новых критериев, совершенно не принятых в биомедицинской статистике. При этом те критерии, которые позволили бы прямо сопоставить заявленную точность с иными опубликованными данными, полностью игнорировались. Пропасть непонимания между врачебным и математическим, ИТ-сообществами нарастала…
В целом, эта ситуация наглядно иллюстрирует описанную К. Боулдингом (K. Boulding; 1910–1993) «глухоту специализации» в научной работе, когда понятийный и методологический аппарат жестко ограничивается рамками строго конкретной научной дисциплины. В современной науке такой подход в принципе безнадежно устарел, и слепое следование ему искусственно и атавистично, тем более, если речь идет о научно обоснованной цифровизации медицины и здравоохранения.
Колоссальный рост интереса со стороны настоящих профессионалов в области математики, компьютерных наук, инженерии к проблематике медицины, обусловленный шумихой вокруг ИИ, нельзя и недопустимо было игнорировать. Как тут не вспомнить слова выдающегося ученого в области научной организации труда, стандартизации и менеджмента Алексея Капитоновича Гастева (1882–1939): «Свой бешеный энтузиазм сохрани, но введи его в график расчета». Требовался системный научный междисциплинарный подход, который позволил бы решить проблемы качества, стандартизации и доступности наборов данных, единства и точности методик оценки ИИ, а также объективно (в том числе сравнительно) оценить точность и воспроизводимость результатов работы ИИ, его безопасность и качество в условиях практического здравоохранения. Ответом на этот запрос науки и практики и стал Московский эксперимент, реализуемый на научных принципах доказательной медицины.
Эксперимент задуман и реализован как исследование со смешанными методами, но ключевой его составляющей является именно проспективное многоцентровое клиническое исследование точности и качества технологий ИИ при анализе результатов пяти основных видов лучевых исследований (рентгенографии, флюорографии, маммографии, компьютерной и магнитно-резонансной томографии).
Московский эксперимент как научное исследование одобрен Независимым этическим комитетом МРО РОРР (протокол 2/2020 от 20.02.2020).
Для представления результатов Московского эксперимента на международном уровне (включая публикации в высокорейтинговых научных изданиях) он зарегистрирован как научное исследование в базе данных Clinical Trials с присвоением идентификационного номера ID Clinical Trials NCT04489992.
Амбициозные цели Московского эксперимента требовали ведения научных изысканий сразу по нескольким направлениям, каждое из которых весьма объемно. В течение 5 лет в рамках каждого направления велись многочисленные исследования. За счет постоянного притока новых знаний появлялись новые гипотезы, требовавшие проверки, соответственно уточнялись и дополнялись конкретные задачи. Общая научная программа отличалась большой динамичностью. Кроме того, появлялись и «ответвления» от основных тематик, из которых зачастую формировались самостоятельные исследования (радиомика, ИИ для контроля качества лучевых исследований, синтетические наборы данных и т.д.).
Сводная научная программа Московского эксперимента за период 2020–2024 гг.:
1. Обосновать клинический контекст, задачи и сценарии применения технологий ИИ в лучевой диагностике.
2. Разработать, внедрить и валидировать методологию создания наборов данных для обучения и тестирования технологий ИИ с учетом этапов жизненного цикла и клинического контекста применения.
3. Разработать, внедрить и валидировать методологию комплексного тестирования и контроля качества технологий ИИ на этапах жизненного цикла.
4. Разработать и реализовать организационно-методические мероприятия по внедрению технологий компьютерного зрения в работу отделений лучевой диагностики.
5. Оценить целесообразность и применимость технологий компьютерного зрения в системе здравоохранения (в том числе с позиций технологического качества).
6. Комплексно изучить качество технологий ИИ при анализе результатов лучевых исследований и при решении организационных задач лучевой диагностики.
7. Изучить влияние технологий ИИ на удовлетворенность и производительность труда врачей-рентгенологов, оценить в динамике отношение врачей к ИИ.
8. Комплексно оценить диагностическую точность ИИ-сервисов при анализе результатов лучевых исследований, в том числе с учетом клинического контекста, сравнительно и в динамике.
9. Оценить возможность применения автоматизированного анализа результатов лучевых исследований для решения задач медицинской профилактики и управления общественным здоровьем.
10. Обосновать подходы к принятию управленческих решений при выборе продукта на основе технологий искусственного интеллекта.
11. Обосновать, внедрить и оценить результативность концепции автономного применения технологий ИИ в лучевой диагностике.
12. Обосновать возможность цифровой трансформации (на основе технологий ИИ) производственных процессов медицинских организаций в аспекте взаимодействия врачей-рентгенологов и врачей клинических специальностей.
13. Изучить медицинскую, социальную и экономическую эффективность технологий искусственного интеллекта (компьютерного зрения) в лучевой диагностике с учетом клинического контекста применения.
14. Обосновать и разработать комплекс стандартов, обеспечивающих единство применения всех компонентов системы обеспечения качества технологий искусственного интеллекта на этапах жизненного цикла.
Формальное структурирование научно-исследовательской работы в рамках Московского эксперимента прошло несколько этапов.
Первоначально сформирован перечень научных и методологических задач с закреплением ответственного исполнителя из числа руководителей научных подразделений и наиболее опытных научных сотрудников. Соответственно ситуативно формировались научные группы. Задачи и ответственные лица были зафиксированы внутренним приказом по учреждению, несколько раз актуализированным.
По итогам 2020 г., то есть первого года эксперимента, сформирован объемный отчет о научно-исследовательской работе, практически полностью опубликованный в виде монографии «Компьютерное зрение в лучевой диагностике: первый этап Московского эксперимента».
В 2021 и 2022 гг. отчеты формировались в сокращенном варианте с обобщением основных годовых результатов и отражением критичных динамических изменений. На этом фоне обширные именно научные результаты содержались в отчете о НИР №3 «Научное обоснование методологии применения и способов оценки качества интеллектуальных технологий („искусственного интеллекта“) в диагностике» (срок выполнения — 2020–2022 гг., финансирование за счет средств государственного задания). Также часть материала в виде отдельных глав, разделов и подразделов входила в отчеты по нескольким иным научно-исследовательским работам, проводимым НПКЦ ДиТ ДЗМ. С одной стороны, представление результатов было несколько «диссеминированным», а с другой — НИР №3 была посвящена не только проблематике Московского эксперимента, что негативно сказывалось на системности формирования ее результатов.
В 2023 г. этот недостаток был устранен: все основные исследования в рамках Московского эксперимента объединены в новой НИР №3 «Научные методологии устойчивого развития технологий искусственного интеллекта в медицинской диагностике», финансируемой за счет средств государственного задания (срок выполнения — 2023–2025 гг.). Подготовка работы по этой теме закреплено за отделом медицинской информатики, радиомики и радиогеномики НПКЦ ДиТ ДЗМ, что также фиксировалось внутренним приказом по учреждению. Вместе с тем подчеркнем, что научная работа в рамках Московского эксперимента ведется сотрудниками всех научных подразделений учреждения на принципах проектного управления. Научные «ответвления» по вопросам искусственного интеллекта теперь входят только в иные НИР. Отметим, что проспективное исследование автономного искусственного интеллекта в 2024 г. проведено в рамках специального Постановления Правительства Москвы, а его результаты оформлены отдельным отчетом о научно-исследовательской работе.
Сквозной характер работ, связанных с Московским экспериментом, а также потребность эффективно и с соблюдением сроков решать не только плановые, но и срочные научные задачи в его рамках обусловили необходимость применения специальных управленческих приемов. Таковым стало проектное управление научной деятельностью, подробно представленное в следующем разделе
Научная проблематика ИИ в медицине чрезвычайно масштабна и многогранна; она действительно «не вмещается ни в одну конкретно-научную дисциплину». Поэтому важной особенностью Московского эксперимента, как неопровержимо лидирующего научного исследования, стал его целенаправленно сформированный междисциплинарный характер.
«Естественная междисциплинарность», по меткому определению Ю. М. Батурина (р. 1949), «может возникать и развиваться как динамическая система, способная к самоорганизации и стремящаяся к экономному решению проблемы, для понимания которой она возникла». Однако в НПКЦ ДиТ ДЗМ междисциплинарный характер научной работы в рамках Московского эксперимента формировался целенаправленно и последовательно, включая реструктуризацию и развитие кадрового состава, создание «экосистемы» научно-исследовательской работы, постоянное повышение требований к качеству и признанию научных результатов, наставничество, нормирование труда как фактор обеспечения преемственности его результатов, переход к проектному управлению.
В 2019–2020 гг. научная группа НПКЦ ДиТ ДЗМ, занимавшаяся соответствующей научно-исследовательской работой, примерно на 90,0% состояла из врачей-рентгенологов. В последующем ситуация изменилась, к 01.01.2025 г. удельный вес рентгенологов сократился до 35,0–40,0% за счет наращивания в коллективе числа специалистов с математическим, инженерным и иным немедицинским образованием. Совершенно особый научный вклад вносят специалисты медицинской кибернетики, био- и медицинской физики, биоинформатики — профессий, изначально находящихся на стыке областей знаний. Отметим, что в 2023–2024 гг. произошло структурное отделение врачей-рентгенологов, обеспечивающих процедуры Московского эксперимента (рутинно проводящих мониторинги, разметку данных), от их коллег, непосредственно участвующих в научно-исследовательской работе. Соответственно, в указанном выше показателе учтены лишь те врачи, которые участвуют именно в научных изысканиях.
Научным исследованиям НПКЦ ДиТ ДЗМ в рамках Московского эксперимента изначально был присущ интегративный тип междисциплинарного взаимодействия (по Э. М. Мирскому; 1935–2012), так как здесь образование новых знаний очевидно происходило за счет «интеграции заимствованных из разных дисциплин представлений и способов исследований».
В учреждении сложилась классическая галисоновская «зона обмена» — социальное и интеллектуальное пространство, в котором связываются воедино прежде разобщенные традиции экспериментирования, теоретизирования и изготовления научных инструментов. Отметим, что ранее в области лучевой диагностики уже фиксировалось и описывалось формирование таких «зон обмена» при взаимодействии инженерного и медицинского персонала в процессе усовершенствования и клинико-экономического обоснования магнитно-резонансной томографии.
Субкультуры теоретиков, экспериментаторов и создателей инструментария, выявленные П. Галисоном (P. Galison, р. 1955), объединены в НПКЦ ДиТ ДЗМ в одном научном коллективе, а в его составе — в ситуативные научные группы. Благодаря созданию общей «экосистемы» научной работы, а также применению определенных управленческих подходов все три субкультуры непрерывно взаимодействуют. Их галисоновские «периоды локальной непрерывности» при этом сдвинуты друг относительно друга совершенно минимально. Тем самым реализована максимальная преемственность, эффективное взаимное дополнение и усиление. Результаты деятельности каждой из субкультур не теряются и не «зависают», а моментально включаются в работу коллег, применяются, уточняются, переосмысливаются и развиваются.
По истечении 5 лет отмечается переход от междисциплинарного характера научных исследований НПКЦ ДиТ ДЗМ к трансдисциплинарному, то есть к формированию у врачей разных специальностей, кибернетиков, математиков, инженеров, физиков, социологов и руководителей (то есть представителей всех включенных во взаимодействие дисциплин) в условиях постоянных коммуникаций «общей системы аксиом». Под этой «системой» мы понимаем совокупность понятий и терминологии, концепций, подходов, методов, материалов в области научного изучения технологий искусственного интеллекта в медицине, лишенных характерных особенностей, присущих каждой из специальности. Таким образом, в научном коллективе НПКЦ ДиТ ДЗМ, занятом проблематикой Московского эксперимента, сформирована новая «научная реальность на основе теорий и методов, утративших свою дисциплинарную определенность». Этим обеспечивается высокая продуктивность научного коллектива НПКЦ ДиТ ДЗМ при проведении Московского эксперимента.
1.1. Краткая история, прогресс и результаты Московского эксперимента
Подготовка и начало работ (2019–2020 гг.). Московский эксперимент по использованию инновационных технологий в области компьютерного зрения для анализа медицинских изображений и дальнейшего применения в системе здравоохранения города Москвы — научное клиническое исследование. В нем принимают участие юридические лица — резиденты Российской Федерации, разработавшие или имеющие права на предоставление сервисов на базе технологий компьютерного зрения для анализа медицинских изображений (в дальнейшем они именуются ИИ-сервисами). Использование термина «сервис» было целенаправленным, так как концептуально решения на основе ИИ должны были предоставлять конечному пользователю стандартизированные результаты своей работы, будучи при этом бесшовно интегрированными не только в профессиональные информационные системы в сфере здравоохранения, но и в производственные процессы лучевой диагностики.
Организационная, научная и методическая работа в эксперименте осуществляется Департаментом здравоохранения города Москвы и конкретным уполномоченным учреждением — Научно-практическим клиническим центром диагностики и телемедицинских технологий ДЗМ. Технологическая составляющая обеспечивается Департаментом информационных технологий города Москвы. Для поддержки и мотивации юридических лиц, представляющих ИИ-сервисы, Правительство города Москвы осуществляет выделение грантов.
Нормативно-правовое обеспечение Московского эксперимента представлено постановлениями Правительства Москвы и приказами Департамента здравоохранения города Москвы.
Положения о начале Московского эксперимента, основные требования к участникам-разработчикам ИИ, порядки предоставления и рассмотрения заявок на получение грантов, механизмы расчета объемов и условия соответствующих выплат приведены в Постановлении Правительства Москвы от 21 ноября 2019 г. №1543-ПП.
Во исполнение Постановления в IV квартале 2019 года коллективом научных подразделений (дирекции «Наука») НПКЦ ДиТ ДЗМ под патронатом Департамента здравоохранения города Москвы и при участии отдельных сотрудников Департамента информационных технологий города Москвы разработаны:
— проект приказа ДЗМ с детальным описанием всех аспектов эксперимента;
— основные производственные процессы;
— методологии обеспечивающих процедур.
Приказ Департамента здравоохранения города Москвы от 19.02.2020 №142 «Об утверждении Порядка и условий проведения эксперимента на использованию инновационных технологий в области компьютерного зрения для анализа медицинских изображений и дальнейшего применения в системе здравоохранения города Москвы» устанавливал конкретные цели и задачи эксперимента; регламентировал процессы (в том числе работу комиссии, рассматривающей организационно-финансовые вопросы) и применяемые методологии, устанавливал пороговые значения диагностической точности ИИ; распределял зоны ответственности, права и обязанности всех участвующих сторон; также определял формы заявки на участие в эксперименте и соответствующее типовое соглашение.
За период 2020–2024 гг. было издано несколько сменявших друг друга версий постановлений Правительства Москвы и приказов ДЗМ, последовательно отражающих преобразование и качественное развитие самого Московского эксперимента как уникальной научной платформы.
Организационное обеспечение. Организацию проведения и сопровождение Московского эксперимента осуществляет Научно-практический клинический центр диагностики и телемедицинских технологий Департамента здравоохранения города Москвы.
В 2019–2020 гг. НПКЦ ДиТ ДЗМ выполнена комплексная организационно-методическая подготовка к проведению Московского эксперимента, которая включила в себя:
1. Разработку нормативно-правового обеспечения.
2. Участие в организации и проведении комплекса работ по технологической интеграции ИИ-сервисов в ЕРИС ЕМИАС (включая разработку детальной концепции и технического задания, выполнение обязанностей функционального заказчика).
3. Методическую разработку, организацию и проведение процедур отбора, оценки, включения, мониторинга ИИ-сервисов — участников Эксперимента, а также выплаты предусмотренных грантов.
4. Организацию информирования и вовлечения компаний-разработчиков ИИ-сервисов в эксперимент.
5. Организацию информирования, обучения и вовлечения врачей-рентгенологов.
6. Разработку специальных методологий и процедур (как для операционных, так и для научных задач эксперимента).
7. Обеспечение эффективной системы коммуникаций со всеми участниками Московского эксперимента; информирование профессиональной аудитории и широкой общественности о его ходе.
В 2019–2020 гг. силами сотрудников научных подразделений (дирекция «Наука») НПКЦ ДиТ ДЗМ организована бесперебойная работа по организации и проведению процедур привлечения, информирования, получения и обработки заявок, отбора и оценки, входного тестирования, включения, регулярного мониторинга, поддержки, научного анализа участников Московского эксперимента. Также организационно-технически была обеспечена работа комиссии Департамента здравоохранения города Москвы, ведение соответствующего документооборота, в том числе для выплаты предусмотренных грантов. Все перечисленные работы были сопряжены с выстраиванием и формальным структурированием целого ряда новых производственных процессов. Причем некоторые из них были новыми лишь для данного учреждения (например, деятельность по выдачи грантов), а другие — были принципиально новыми и не имели прямых аналогов (например, ежемесячный мониторинг технического и медицинского качества ИИ-сервисов).
Налажена эффективная система коммуникаций со всеми сторонами, вовлеченными в эксперимент, включая списки рассылок, выделенные телефонные номера, тематические чаты и группы в интернет-мессенджерах, а также разработан и запущен официальный веб-сайт Эксперимента www.mosmed.ai и электронный почтовый ящик.
Интенсивность коммуникаций наглядно иллюстрирует следующий факт. Ежедневно на официальный электронный адрес эксперимента поступало от 30 до 50 обращений. В результате анализа коммуникации с компаниями было выявлено 120 типовых вопросов, подготовлены и опубликованы на сайте www.mosmed.ai стандартные справочные ответы.
Для информирования профессиональной аудитории и широкой общественности о ходе Эксперимента осуществлялся план публикаций в средствах массовой информации и социальных медиа. Примечательно, что в 2020 г. суммарно было выпущено 2742 тематических материала новостного, научно-популярного и публицистического характера о Московском эксперименте, что составило 57,0% от общего объема публикаций в масс-медиа по проблематике ИИ и смежным темам. Ряд публикаций и сообщений были сделаны ТАСС и РИА Новости. Общий охват превысил 110 миллионов аудитории.
Для развития у врачей-рентгенологов Московского референс-центра лучевой диагностики, а также иных медицинских организаций ДЗМ компетенций по применению ИИ-сервисов разработано учебно-методическое обеспечение и реализована трехэтапная схема обучения. На первом этапе в формате вебинаров проведены 6 дистанционных лекций общей длительностью 10 академических часов. На втором этапе врачам предоставлен свободный доступ к 21 оригинальному видеоуроку, содержание которых в последствие неоднократно актуализировалось и дополнялось. Также для врачей была подготовлена короткая визуальная инструкция по использованию результатов работы ИИ-сервисов. На третьем этапе проведены 2 очные рабочие встречи при участии наиболее активных и заинтересованных врачей. На основании накопленных материалов научного, учебно-методического и практического характера в конце 2020 г. сформирована программа дополнительного профессионального образования, рассчитанная на 18 академических часов.
Особым направлением работы было широкое информирование и вовлечение компаний-разработчиков: в ходе информационной кампании обеспечен охват потенциального рынка в 100,0% в РФ и 65,0% на международном уровне.
Для мониторинга общего процесса и основных метрик Московского эксперимента разработан отдельный дашборд (онлайн-табло).
Технологическое обеспечение. Технологической средой для проведения Московского эксперимента, как было сказано выше, стал ЕРИС (централизованный архив медицинских изображений) ЕМИАС (государственная информационная система в сфере здравоохранения субъекта РФ).
Сервисы на основе искусственного интеллекта, включенные в эксперимент, проходили процедуру интеграции с ЕРИС ЕМИАС для обеспечения бесшовных производственных процессов отделений лучевой диагностики. Методически для этого процесса были разработаны стандартизированные минимальные технические условия — базовые функциональные требования для ИИ-сервисов (подробнее о них будет сказано далее).
Для проведения интеграции в составе ЕРИС была специально разработана подсистема «Продукт управления моделями (ПУМ)» — «точка входа» для ИИ-сервисов. В ЕМИАС применялась подсистема «Единая система уведомлений для внешних взаимодействий (ЕСУВВ)», построенная на продукте Apache Kafka (распределенный программный брокер сообщений).
В составе ЕРИС была сформирована тестовая среда — так называемый тестовый программно-аппаратный комплекс (ТПАК). Это «точка» первоначального подключения ИИ-сервисов для выполнения инженерно-технических работ, настройки, функционального и калибровочного тестирования. Фактически в тестовом контуре ИИ-сервис «адаптируется» к работе в государственной информационной системе в сфере здравоохранения субъекта РФ, причем в условиях бесшовной интеграции.
Для непосредственной работы с потоком результатов лучевых исследований в составе ЕРИС сформирован так называемый продуктивный программно-аппаратный комплекс (ППАК). Из ТПАК в ППАК ИИ-сервис «переключается» по факту успешного завершения тестовых процедур.
Интеграция и работа ИИ-сервисов в ЕРИС ЕМИАС осуществляется в строгом соответствии с действующим законодательством в сфере государственных информационных систем, информационной безопасности, защиты персональных данных.
Организацию и проведение комплекса работ по интеграции ИИ-сервисов, технической поддержке и сопровождению разработчиков, обеспечению информационной безопасности на высоком профессиональном уровне выполняет коллектив Департамента информационных технологий города Москвы.
Научно-методологическое обеспечение. Систематизация общемирового и собственного практического опыта продемонстрировала необходимость научной разработки ряда оригинальных, специфических методологий и процедур, предназначенных для обеспечения контроля и мониторинга безопасности и качества ИИ-сервисов на этапах жизненного цикла. Чрезвычайно важно отметить, что по состоянию на 2019–2020 гг. большинства требуемых методик не существовало, а значит их следовало изобрести, создать «с нуля». Лишь по отдельным аспектам (например, разметке данных) имелось некое количество разрозненных, неунифицированных способов и приемов, как минимум требовавших вдумчивой научной систематизации и приведения к единообразию.
Исходя из сказанного, в рамках Московского эксперимента сотрудниками научных, медицинских и иных подразделений НПКЦ ДиТ ДЗМ были разработаны:
1. Принципы клинического целеполагания при разработке ИИ-сервисов.
2. Стандартизированные базовые функциональные и диагностические требования к ИИ-сервисам.
3. Методология создания наборов данных (в том числе схема жизненного цикла; унифицированные требования к структуре наборов; классификации самих наборов, а также способов разметки данных; стандарты описания датасета, технического задания; формализованные производственные процессы).
4. Методологии и процедуры тестирования ИИ-сервисов на этапах интеграции в тестовом контуре ЕРИС ЕМИАС для определения качества, точности и возможности работы в условиях реальной информационной системы в сфере здравоохранения:
— функционального (проверка технологического качества интеграции ИИ-сервиса);
— калибровочного (проверка диагностической точности ИИ-сервиса на эталонных наборах данных, сравнение результатов с метриками точности, заявленными разработчиком);
— контрольно-технического (проверка корректности маршрутизации и обмена данными между каждым диагностическим устройством и ИИ-сервисом).
5. Методологии и процедуры мониторинга ИИ-сервисов в процессе их работы в условиях реального потока результатов лучевых исследований в промышленном контуре ЕРИС ЕМИАС:
— технологического (проспективный контроль с оценкой в динамике сроков обработки данных, технической надежности путем проверки результатов работы ИИ-сервиса на наличие категоризированных технологических дефектов);
— клинического (проспективная проверка диагностической точности ИИ-сервисов с оценкой в динамике).
6. Методология оценки зрелости технологий ИИ для здравоохранения (интегральная оценка технологического и медицинского качества ИИ-сервисов в динамике).
7. Рекомендации по проведению испытаний ИИ-сервисов на этапах жизненного цикла с описанием конкретных методологий, инструментов и процедур:
— самостоятельного тестирования разработчиком;
— предварительных клинико-технических испытаний;
— клинических испытаний.
Ряд методик, процедур и процессов были разработаны в 2019 — начале 2020 гг., непосредственно к старту Московского эксперимента. Иные были созданы позже, исходя из полученных новых знаний о работе технологий искусственного интеллекта в практическом здравоохранении, а также на фоне развития требований к ИИ-сервисам. Детальнее об этом будет сказано далее; также в последующих главах будут представлены сами методологии.
В рамках Московского эксперимента сотрудниками НПКЦ ДиТ ДЗМ научно разработана и внедрена система обеспечения качества технологий искусственного интеллекта на этапах жизненного цикла.
Процесс Московского эксперимента. Общий ход эксперимента в 2020 г. представлен на рисунке 1.1. В последующие годы логическая структура и последовательность процедур в целом не изменились; развивались и дополнялись методологии контроля и мониторинга, эволюционировали подходы маршрутизации, общему менеджменту, решались новые актуальные научные задачи.
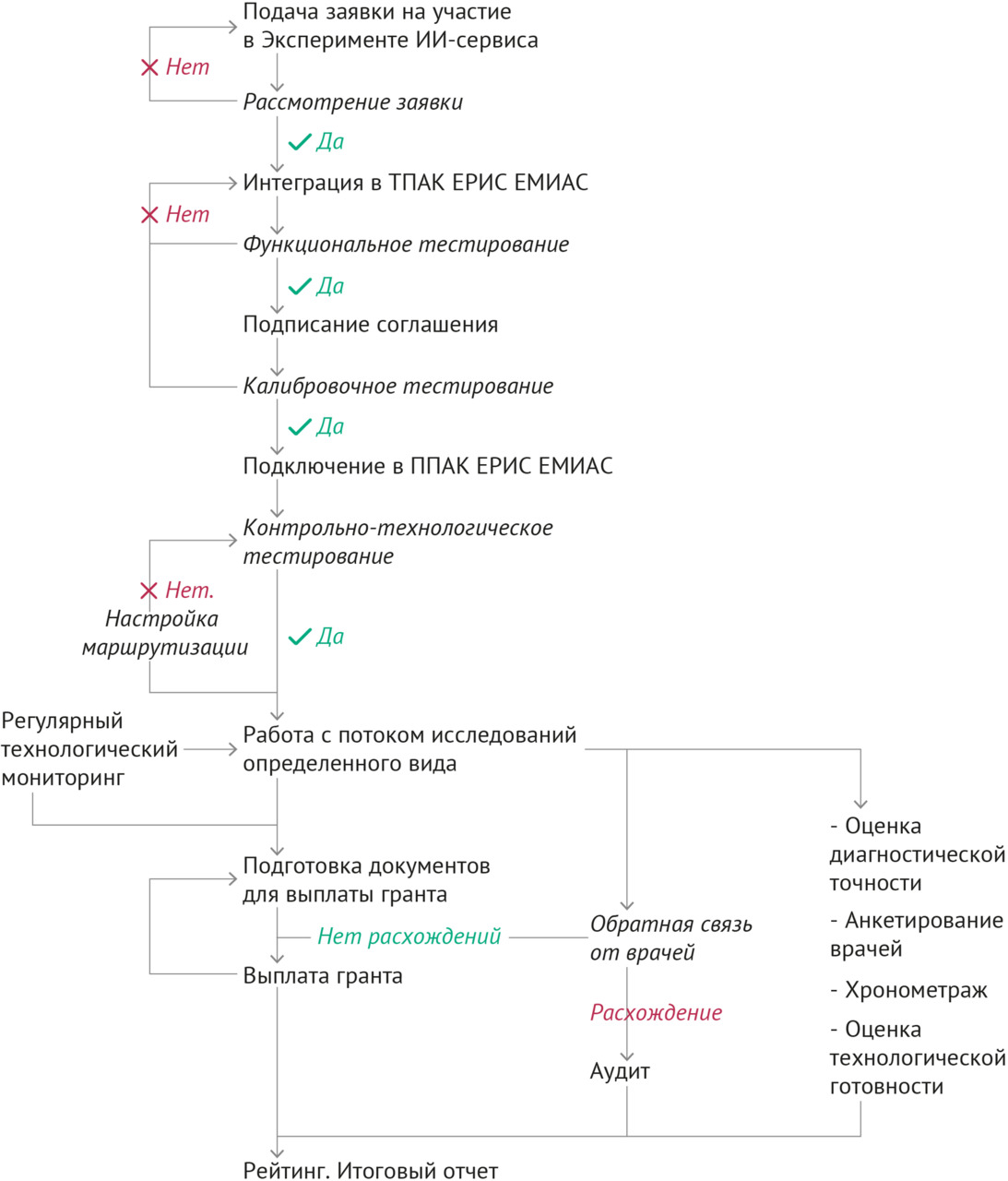
Нормативное обеспечение и методика Московского эксперимента предусматривали наличие строго установленных клинических задач, которые должны были решать ИИ-сервисы в рамках процесса анализа, интерпретации и описания результатов лучевых исследований врачом-рентгенологом. Изначально описание клинических задач включало: модальность (вид исследования), анатомическую область, целевую патологию (рентгенологический признак, синдром или нозологию в соответствии с МКБ-10). Позднее к этому перечню добавились стандартизированные базовые диагностические требования к результатам работы ИИ-сервисов при решении данной задачи. В рамках Московского эксперимента клинические задачи для ИИ именуются «направлениями Эксперимента».
Первоначально в 2019 г. были определены 3 направления Московского эксперимента:
1. Компьютерная томография и низкодозная компьютерная томография (КТ/НДКТ) органов грудной клетки с целью выявления рака легких.
2. Маммография (ММГ) с целью выявления рака молочных желез.
3. Рентгенография (РГ) /флюорография (ФЛГ) легких с целью определения наиболее распространенных патологий.
Несмотря на наличие на потенциальном рынке определенного количества решений на основе ИИ по данным направлениям, их разработчики не спешили принимать участие в Эксперименте. Во многом это объясняется субъективными причинами — страхом и опасениями, связанными с публичным представлением своего продукта и независимым контролем его качества; иногда встречалось и необоснованное оспаривание стандартизированных требований к результатам работы ИИ-сервисов. Среди объективных причин со стороны разработчиков часто фигурировала техническая неготовность к интеграции с реальной информационной системой в сфере здравоохранения, к работе с данными в форматах и стандартах, принятыми в лучевой диагностике. Надо особо отметить, что по итогам 2020 г. только 46,0% из общего числа начавших интеграцию ИИ-сервисов смогли успешно ее завершить. Это прямое свидетельство низкого уровня готовности компаний-разработчиков технологий ИИ к работе с реальными информационными системами в сфере здравоохранения. К счастью, в последующие годы эта ситуация принципиальным образом изменилась в лучшую сторону; случаи критичных проблем технической интеграции в ЕРИС ЕМИАС стали единичными.
11 марта 2020 года Всемирная организация здравоохранения объявила вспышку нового типа коронавируса 2019-nCoV (COVID-19) пандемией. Последовавшие за этим события нанесли колоссальный вред в социально-экономическом, медицинском, а также демографическом аспектах. Наглядным доказательством сказанного служит следующий факт: на протяжении десятилетий стандартной «триадой» основных причин смертности населения всегда были злокачественные новообразования, болезни системы кровообращения и травмы. В период пандемии травмы были вытеснены COVID-19, уверенно занявшим третье место в структуре смертности от всех причин.
Оценка итогов пандемии с позиций диалектики указывает на наличие и положительных сторон. Одной из таковых, несомненно, является принципиальное изменение отношения к цифровым технологиям в здравоохранении, особенно к телемедицине. В Московском эксперименте пандемия стала своеобразным триггером:
— в число направлений были включены КТ/НДКТ и рентгенография органов грудной клетки с целью выявления признаков коронавирусной инфекции (COVID-19);
— сотрудниками НПКЦ ДиТ ДЗМ был подготовлен и выложен в открытый доступ набор данных КТ органов грудной клетки, в котором были представлены результаты поражения легких COVID-19 с классификацией тяжести поражения по шкале «КТ0—4»;
— сразу несколько компаний в очень короткие сроки подготовили ИИ-сервисы для указанного выше направления;
— необходимость сортировки и маршрутизации пациентов в условиях массового поступления буквально вынудила взглянуть на технологии ИИ и Московский эксперимент не только как на отвлеченное научное изыскание, но и на прикладной инструмент, востребованный «прямо сейчас».
В результате в июне 2020 г. процесс входа новых продуктов в Московский эксперимент кардинальным образом интенсифицировался. Один за другим ИИ-сервисы интегрировались в тестовый контур, проходили входное тестирование и начинали работу с потоком исследований в промышленном контуре ЕРИС ЕМИАС. Соответственно, стартовали и выплаты Правительством Москвы грантов за обработанные исследования.
Пример первых успешных участников оказался мощным стимулом для многих разработчиков: в Эксперимент начали входить ИИ-сервисы и по другим направлениям.
Организационное обеспечение. С учетом высокого уровня ответственности, сложности и комплексности перечисленных процессов с IV кв. 2020 г. начался переход на новую форму их организации на принципах проектного управления. В структуре НПКЦ ДиТ ДЗМ создан проектный офис как структура, непосредственно ответственная за проведение Московского эксперимента. Улучшено структурирование задач и соответствующих им процессов; в частности, более четко обозначены административные, научно-исследовательские, технические, образовательные, вспомогательные процессы. Из состава сотрудников всех подразделений учреждения сформированы соответствующие рабочие группы. Задачи и зоны ответственности установлены локальными нормативными актами.
Итоги первого года Московского эксперимента были противоречивы. С одной стороны, реализованы процессы масштабного научного исследования, впервые в масштабе мегаполиса технологии компьютерного зрения внедрены в практическое здравоохранения. С другой стороны — качество и ценность для врача первых ИИ-сервисов были откровенно низкими. Именно поэтому итогам этого первого периода, опубликованным в виде монографии, предшествовал эпиграф в виде высказывания К. Э. Циолковского: «Чем грандиознее идея и ее польза, тем слабее бывает первое исполнение. Причина понятна. Это — трудность ее реализации».
На пути истинной науки крайне редко встречается быстрая победа. Результат дают вера, упорство и скрупулезный, системный труд. Подтверждением этого тезиса служат положительная динамика, успешность и общественное признание научных достижений Московского эксперимента в последующие годы.
Динамика эксперимента (2020–2024 гг.). В 2020 г. в Московском эксперименте приняли участие 39 ИИ-сервисов от 21 компании-разработчика; 18 продуктов успешно интегрировались в ППАК ЕРИС ЕМИАС и работали в условиях реального потока результатов лучевых исследований.
На анализ направлялись результаты исследований по четырем модальностям, проведенные в медицинских организациях Департамента здравоохранения Москвы, оказывающих медицинскую помощь взрослому населению.
Для ИИ-сервисов были определены 4 направления (клинических задачи), в том числе внепланово установленное, имеющее целью выявление признаков и определение объема поражения легких при COVID-19.
Всего ИИ-сервисами проанализированы результаты 1 468 872 лучевых исследований, в том числе результаты КТ и НДКТ – 56,0% (818 296), ММГ – 4,0% (61 497), РГ – 18,0% (270 965), ФЛГ – 22,0% (318 114).
Впервые разработаны и введены базовые функциональные и диагностические требования.
Маршрутизация результатов исследований на ИИ-сервисы осуществлялась двумя способами: первоначально – весь поток исследований данного направления на каждый из ИИ-сервисов по данному направлению; позднее введена «шахматная маршрутизация» с формированием отдельных потоков для каждого ИИ-сервиса данного направления и периодическим «переключением» потоков между собой (благодаря этому каждый ИИ-сервис мог поработать с результатами исследований от всех диагностических устройств).
В 2021 г. успешно прошли входное тестирование и работали в промышленном контуре ЕРИС ЕМИАС 23 ИИ-сервиса от 21 компании-разработчика.
Количество направлений эксперимента (клинических задач для ИИ-сервисов) возросло до 9.
Всего ИИ-сервисами проанализированы результаты 2 917 095 лучевых исследований, в том числе результаты КТ и НДКТ – 31,0% (902 002), ММГ – 9,0% (257 065), РГ – 24,0% (713 882), ФЛГ – 36,0% (1 044 146).
Произошло развитие принципов маршрутизации результатов исследований на ИИ-сервисы:
1. Процесс работы ИИ-сервиса в ППАК разделен на два этапа — апробации и опытной эксплуатации. Апробация — ограниченная по времени поочередная работа ИИ-сервиса со всеми медицинскими организациями (диагностическими устройствами по данному направлению) ДЗМ. Опытная эксплуатация — неограниченная по времени работа с медицинскими организациями, которые самостоятельно (по результатам ежеквартального опроса) выбрали данный ИИ-сервис.
2. Появление так называемого «маркетплейса» — каталога ИИ-сервисов и функции отправки результатов лучевого исследования на дополнительный автоматизированный анализ. «Маркетплейс» доступен на рабочем месте каждого врача-рентгенолога и может быть использован, исходя из предпочтений и по усмотрению специалиста, проводящего описание результатов данного исследования.
Наиболее важными достижениями 2021 г. стали:
— выполнение научных исследований по определению объема выборки для ежемесячного технического мониторинга качества работы ИИ-сервисов;
— создание открытой библиотеки наборов данных (https://mosmed.ai/datasets/);
— организация и проведение постоянных семинаров между разработчиками и врачами-рентгенологами;
— привлечение компаний-разработчиков к процессу формирования тарифов на анализ исследований, что повысило прозрачность процессов Московского эксперимента и объективность предоставляемых грантов;
— включение НПКЦ ДиТ ДЗМ в единый реестр уполномоченных организаций, имеющих право проводить исследования (испытания) медицинских изделий, благодаря чему в стенах Центра также в 2021 г. начались официальные технические и клинические испытания программного обеспечения на основе технологий искусственного интеллекта (https://telemedai.ru/uslugi/ispytaniya-medicinskih-programmnyh-produktov).
В 2022 г. успешно прошли входное тестирование и работали в промышленном контуре ЕРИС ЕМИАС 43 ИИ-сервиса от 20 компаний-разработчиков.
Количество направлений эксперимента вновь возросло до 16, в том числе появились задачи для автоматизированного анализа результатов магнитно-резонансной томографии. Параллельно начался процесс создания «комплексных ИИ-сервисов» путем объединения отдельных задач для данного вида исследований. Прежде всего, были объединены в комплексный ИИ-сервис отдельные задачи для анализа результатов исследований органов грудной клетки.
Всего ИИ-сервисами проанализированы результаты 4 104 505 лучевых исследований, в том числе результаты КТ и НДКТ – 24,4% (1 001 051), ММГ – 12,2% (501 051), МРТ – 0,1% (4164), РГ – 29,0% (1 188 908), ФЛГ – 34,3% (1 409 331).
Наиболее важные достижения 2022 г.:
— научная разработка методологии и внедрение ежемесячного клинического мониторинга (теперь регулярно оценивалась не только техническая надежность, но и диагностическая точность, медицинское качество ИИ-сервисов);
— масштабирование Московского эксперимента в виде подключения медицинских организаций Ямало-Ненецкого автономного округа;
— развитие базовых диагностических требований по маммографии в виде перехода на шкалу BI-RADS из пяти степеней.
В 2023 г. успешно прошли входное тестирование и работали в промышленном контуре ЕРИС ЕМИАС 57 ИИ-сервисов от 24 компаний-разработчиков.
Количество направлений эксперимента продолжило увеличиваться и составило 29.
Всего ИИ-сервисами проанализированы результаты 3 246 277 лучевых исследований, в том числе результаты КТ и НДКТ – 24,0% (778 937), ММГ – 10,0% (316 236), МРТ – 1,0% (37 015), РГ – 37,0% (1 189 980), ФЛГ – 28,0% (924 109).
Наиболее важные достижения 2023 г.:
— научная разработка и внедрение методологии интегральной оценки качества ИИ-сервисов — матрицы зрелости;
— полноценное внедрение научных результатов Московского эксперимента в практическое здравоохранение — введение в системе здравоохранения г. Москвы медицинской услуги, оказываемой с применением медицинских изделий на основе технологий искусственного интеллекта и финансируемой за счет средств обязательного медицинского страхования;
— научная разработка и первичная проверка гипотезы о возможности автономной сортировки результатов лучевых исследований ИИ-сервисами, настроенными на максимальную чувствительность;
— совместные проекты с врачами клинических специальностей.
В 2024 г. успешно прошли входное тестирование и работали в промышленном контуре ЕРИС ЕМИАС 59 ИИ-сервисов от 26 компаний-разработчиков.
Количество направлений эксперимента уменьшилось до 12 за счет объединения отдельных задач в комплексные (соответствующее развитие комплексных ИИ-сервисов для анализа результатов КТ органов грудной клетки, головного мозга).
Всего ИИ-сервисами проанализированы результаты 2 603 669 лучевых исследований, в том числе результаты КТ и НДКТ – 34,0% (890 145), ММГ – 8,0% (213 528), МРТ – 5,0% (120 713), РГ – 49,0% (1 264 614), ФЛГ – 4,0% (114 669).
Наиболее важные достижения 2024 г.:
— масштабирование возможностей Московского эксперимента на общегосударственном уровне; создание и запуск платформы «МосМедИИ» для обеспечения работы всех медицинских организаций Российской Федерации с лучшими и постоянно контролируемыми ИИ-сервисами;
— организация и проведение проспективного научного исследования медицинской и экономической эффективности автономного искусственного интеллекта;
— научное развитие методологий матрицы зрелости, формирования выборок для регулярных контрольных мероприятий, клинического мониторинга;
— закрытие входа в Эксперимент для моносервисов по направлениям, где на опытной эксплуатации есть три и более комплексных ИИ-сервиса.
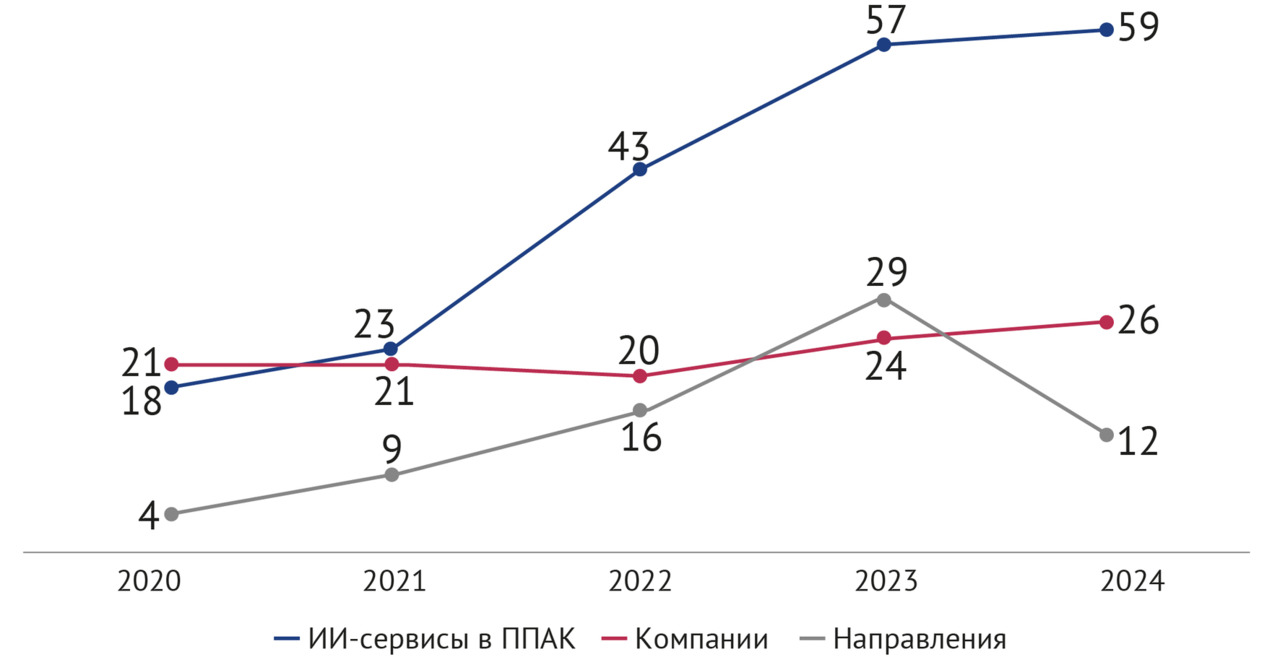
Всего за период 2020–2024 гг. в Московском эксперименте приняли участие 39 компаний, представившие 204 ИИ-сервиса. Подавляющее большинство продуктов (77,5%) были созданы разработчиками из Российской Федерации. Зарубежные ИИ-сервисы, в соответствии с нормативно-правовым обеспечением Московского эксперимента, участвовали через своих официальных представителей в РФ; за 5 лет 10 компаний из Австрии, Республики Беларусь, Израиля, Индии, Китая, Франции, Южной Кореи представили для участия в Московском эксперименте 46 ИИ-сервисов по разным направлениям.
За период 2020–2024 гг. из 204 ИИ-сервисов 57,0% (116) работали в промышленном контуре ЕРИС ЕМИАС, то есть осуществляли анализ потока результатов лучевых исследований в условиях практического здравоохранения.
По состоянию на 01.01.2025 г. статистика ИИ-сервисов выглядит следующим образом:
— работают в промышленном контуре ЕРИС ЕМИАС — 52 (26,0%);
— проходят входное тестирование в тестовом контуре ЕРИС ЕМИАС — 43 (21,0%);
— приостановлено участие — 5 (2,0%);
— полностью прекратили участие — 72 (35,0%);
— прекратили участие как отдельный продукт (включены в состав комплексных ИИ-сервисов) — 32 (16,0%).
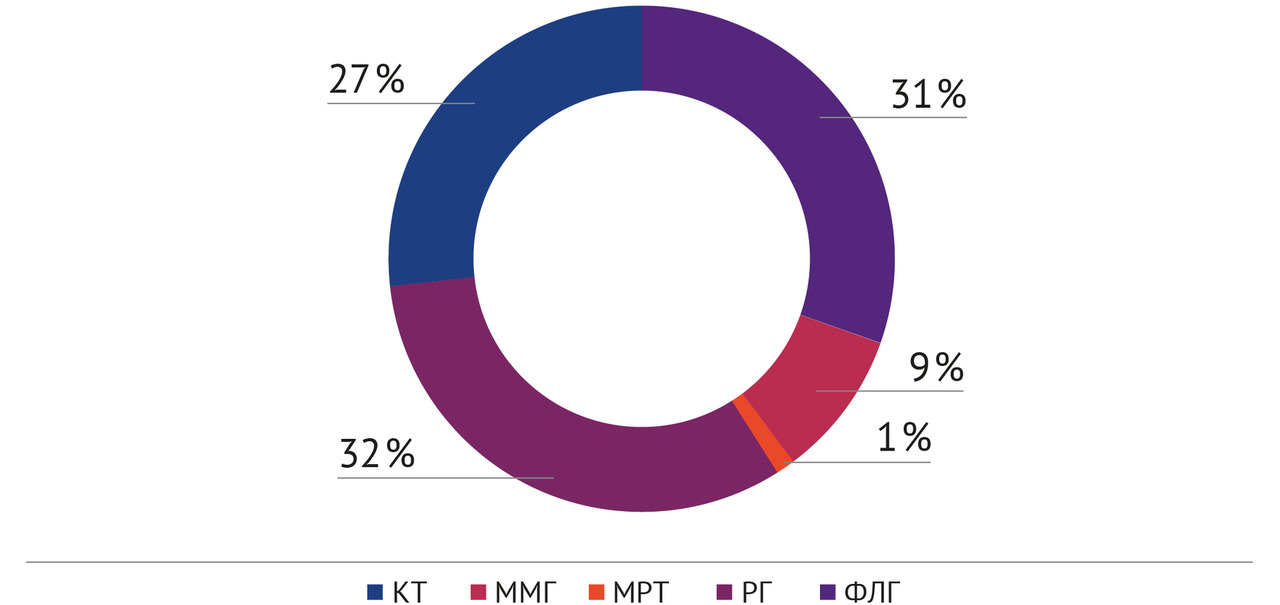
За период 2020–2024 гг. ИИ-сервисами в рамках Московского эксперимента обработаны результаты 14 228 378 лучевых исследований (рисунок 1.3). По состоянию на 01.01.2025 г. эта самая крупная в мире выборка клинических случаев с результатами работы технологий искусственного интеллекта. В структуре модальностей лучевых исследований преобладали рентгенография — 32,0%, компьютерная томография — 31,0% и флюорография — 27,0%.
По состоянию на 01.01.2025 в РФ допущены к обращению 39 медицинских изделий на основе технологий ИИ, среди них 18 ИИ-сервисов – участников Московского эксперимента. Подчеркнем, что среди всех медицинских изделий этой категории, предназначенных для лучевой диагностики (n=22), удельный вес участников Московского эксперимента составляет 82,0%.
В 2020 г. рынок медицинских изделий и услуг, связанных с применением технологий искусственного интеллекта в здравоохранении, в России отсутствовал. Спустя 5 лет в Программе государственных гарантий бесплатного оказания гражданам медицинской помощи на 2025 год и на плановый период 2026 и 2027 годов (утверждена Постановлением Правительства РФ от 27.12.2024 № 1940) «средние нормативы финансовых затрат на единицу объема медицинской помощи за счет средств обязательного медицинского страхования установлены с учетом в том числе расходов, связанных с использованием систем поддержки принятия врачебных решений (медицинских изделий с применением искусственного интеллекта, зарегистрированных в установленном порядке) (при проведении маммографии, рентгенографии или флюорографии грудной клетки, компьютерной томографии органов грудной клетки)». Таким образом, можно констатировать успешное выполнение одной из целей Московского эксперимента, состоящей в создании нового рынка в области искусственного интеллекта.
14 февраля 2024 г. Научно-практический клинический центр диагностики и телемедицинских технологий ДЗМ посетил Президент Российской Федерации Владимир Владимирович Путин, где ознакомился с работой референс-центра лучевой диагностики и опытом применения технологий искусственного интеллекта. Результаты Московского эксперимента получили признание на общегосударственном уровне и были масштабированы на всю систему здравоохранения Российской Федерации.

Глава 2. ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ В ПРАКТИЧЕСКОЙ МЕДИЦИНЕ: ОБЩИЕ ПРИНЦИПЫ И ФУНДАМЕНТАЛЬНЫЕ МЕТОДОЛОГИИ
Венец всякой науки есть раскрытие закономерностей. Там, где чистый эмпирик видит разрозненные факты, эмпирик-философ усматривает отражение закона.
В. Я. Пропп
2.1. Внедрение систем искусственного интеллекта: принципы, этапы, стандартизация требований к результатам работы
Национальная стратегия развития искусственного интеллекта на период до 2030 года предусматривает следующее определение: искусственный интеллект — комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые с результатами интеллектуальной деятельности человека или превосходящие их. Комплекс технологических решений включает в себя информационно-коммуникационную инфраструктуру, программное обеспечение (в том числе то, в котором используются методы машинного обучения), процессы и сервисы по обработке данных и поиску решений.
В здравоохранении «искусственный интеллект» целесообразно рассматривать как очередное поколение инструментов автоматизации трудовых операций и производственных процессов. Только такой материалистический взгляд позволяет трезво и рационально подойти к внедрению и применению соответствующих технологий. В действительности, автоматизация в отдельных медицинских отраслях чрезвычайно высока и давно стала рутиной. Машинный анализ данных с оценкой физиологических и морфологических показателей, определением патологических проявлений уже на протяжении десятилетий является составной частью многих медицинских приборов. Самый «древний» пример — это электрокардиография, более «современный» — лабораторная диагностика.
Безусловно, актуальные технологии («компьютерное зрение, обработка естественного языка, распознавание и синтез речи, интеллектуальная поддержка принятия решений и перспективные методы искусственного интеллекта») открывают принципиально новые возможности, по сравнению с уже реализованными решениями. Однако принципы их изучения и внедрения в практическое здравоохранение остаются прежними: системный научный подход, Noli Nocere, методология доказательной медицины.
Искусственный интеллект — это инструменты автоматизации трудовых операций и производственных процессов в здравоохранении, применение которых осуществляется в определенном клиническом контексте, на принципах материализма, доказательности, эффективности, осознанности, объяснимости, прозрачности.
Клинический контекст — единый дискретный комплекс информации о цели, задачах, конкретных процессах и операциях, нозологиях, видах биомедицинских и иных данных, функциях медицинского персонала и технических устройств, связанных с организацией и оказанием медицинской помощи.
Принцип материализма — отказ от гуманизации технологий искусственного интеллекта в здравоохранении, отказ от стереотипов и предубеждений, связанных с отождествлением разума человека и математического аппарата электронно-вычислительной машины.
Принцип доказательности — разработка, апробация, внедрение и применение технологий искусственного интеллекта осуществляются только на научной основе, с использованием подходов и методик доказательной медицины. Носит сквозной характер, так как все элементы и этапы проектирования, разработки, применения, оценки эффектов и проч. технологий ИИ в здравоохранении базируются исключительно на научном подходе — хайпу нет места в медицине.
Принцип эффективности — применение технологий искусственного интеллекта для достижения конкретной измеримой цели; научное обоснование результативности такого применения.
Принцип осознанности — адаптация применения технологий искусственного интеллекта к конкретному клиническому контексту, понимание возможностей и ограничений таких технологий, научное формирование показаний и противопоказаний к их применению.
Принцип объяснимости — функциональная возможность программного обеспечения на основе ИИ объяснить человеку свое решение, процесс его достижения и степень уверенности в нем.
Принцип прозрачности — недискриминационный доступ пользователей продуктов, которые созданы с использованием технологий искусственного интеллекта, к информации о применяемых в этих продуктах алгоритмах работы искусственного интеллекта.
Отдельно выводить принцип безопасности и качества не имеет смысла, так как любое медицинское изделие или применяемое в медицине средство должно ему соответствовать. Каких-либо особенностей и исключения для ИИ здесь нет. В этом контексте попытки этически ограничить «автономность» технологий искусственного интеллекта выглядят довольно натянуто, так как, например, при объективном рассмотрении довольно трудно проследить грани автономности и неавтономности при проведении клинико-лабораторных исследований в современной автоматизированной лаборатории.
Клинический контекст представляет собой комплекс специфической базовой информации, необходимой для эффективного применения искусственного интеллекта в практическом здравоохранении на основе перечисленных принципов.
Другим критичным аспектом является адекватное, обоснованное целеполагание в соответствии с принципами осознанности и эффективности.
В период подготовки Московского эксперимента в 2019 г. были осуществлены действия для целеполагания.
На первом этапе изучены запросы системы здравоохранения Российской Федерации с позиций того, что перспективное становление технологий искусственного интеллекта должно быть согласовано с общим направлением развития отечественной системы охраны здоровья, целями и задачами национальных проектов в данной области. При этом учтены также эпидемиологический и социальные аспекты в плане борьбы с социально значимыми заболеваниями, состояния и проблематики массовых профилактических осмотров, основных проблем служб лучевой диагностики и т. д. Также с социологической точки зрения изучены ожидания врачебного сообщества от внедрения технологий ИИ. Определены наиболее перспективные направления для масштабного внедрения искусственного интеллекта:
— анализ результатов массовых профилактических осмотров лучевыми методами;
— выявление признаков онкологических заболеваний, особенно — на ранних стадиях;
— поддержка врачебных решений по оптимальной, предписанной маршрутизации пациентов;
— оппортунистический поиск предикторов или проявлений особо значимых патологий;
— влияние на производительность труда врача-рентгенолога путем автоматизированного формирования проектов описаний с использованием стандартизированных систем протоколирования и классификаций.
Установлено требование по точности и сбалансированности технологий искусственного интеллекта; категорической недопустимости создания дополнительной необоснованной нагрузки на систему здравоохранения (за счет избыточной генерации ложноположительных или клинически нецелесообразных результатов).
Подробно эти материалы изложены в монографии о результатах первого года Эксперимента.
На втором этапе стандартизирован, описан и проанализирован основной производственный процесс службы лучевой диагностики, включающий взаимодействие лечащего врача, пациента, рентгенолаборанта, врачей-рентгенологов, экспертов посредством общей информационной системы. Выявлены ключевые проблемы и риски процесса; соответственно установлены конкретные трудовые операции в его составе, автоматизация которых потенциально позволит снизить риски дефектов и ошибок, повысить производительность труда, увеличить скорость постановки диагноза и начала специального лечения.
Детально проработан актуальный на момент начала Московского эксперимента (2019–2020 гг.) клинический контекст, в котором осуществляется основной производственный процесс.
На третьем этапе введено понятие «направление», по сути, представляющее собой конкретную клинико-диагностическую задачу — выявление на результатах определенного вида лучевого исследования рентгенологических признаков, ассоциируемых с конкретным синдромом или заболеванием, с учетом клинического контекста. Среди критичных факторов клинического контекста, прежде всего, выделяли вид, форму и условия оказания медицинской помощи, а также характер исследования — профилактическое или диагностическое. Очевидно, что таких задач может быть множество, поэтому была осуществлена приоритизация по следующему алгоритму:
1. Анализ частоты выполнения исследований в сети медицинских организаций государственной системы здравоохранения г. Москвы за год.
2. Определение наиболее часто выполняемых видов исследований (как модальностей, так и конкретных медицинских услуг).
3. Определение наиболее часто выявляемых патологий на результатах этих исследований.
4. Исключение патологий с нетипичной (неспецифичной) рентгенологической картиной и/или не имеющих четких клинических рекомендаций по дальнейшей маршрутизации пациента.
5. Формирование клинико-диагностической задачи — конкретного направления Московского эксперимента.
По этому принципу первыми направлениями стали выполняемые в амбулаторных условиях диагностическая компьютерная томография органов грудной клетки для выявления признаков пневмонии (в том числе вирусной), злокачественных новообразований; профилактическая рентгенография (флюорография) органов грудной клетки для выявления туберкулеза, воспалительной и онкологической патологии и т. д. Именно массовость и социально значимый характер этих и ряда иных исследований обусловили их лидерство среди направления Московского эксперимента, тем самым технологиям ИИ были «гарантированы» не только медицинская результативность, но и масштабность применения (таким образом заложены еще и основы нового сегмента рынка).
Из клинического контекста проистекают стандартизированные требования к способам применения конкретной технологии искусственного интеллекта, видам и формам представления результатов ее работы, измеримым метрикам качества.
Поэтому на четвертом этапе концептуально определено, что программное обеспечение на основе технологий ИИ при обработке результатов лучевых исследований должно осуществлять 3 основные функции:
1. Приоритизировать в рабочем списке врача-рентгенолога результаты исследований, содержащих признаки патологии.
2. Маркировать патологические находки на диагностическом изображении, предоставленном в виде дополнительной серии (не изменяя и не влияя при этом на исходное изображение).
3. Предоставлять проект текстового описания результатов исследования и обнаруженных патологических проявлений.
Для развития этих концептуальных положений на пятом этапе разработаны базовые диагностические требования (БДТ) — стандартизированные требования к результатам работы ИИ при решении данной клинико-диагностической задачи (то есть при работе по конкретному направлению Московского эксперимента). Требования включают:
1) вид лучевого исследования (модальность, анатомическая область, проекция и т.д.);
2) клиническую задачу для ИИ (целевой синдром или заболевание);
3) рентгенологические признаки целевого патологического состояния, для которых ожидается положительный и/или отрицательный ответ ИИ;
4) содержание ответа ИИ — форма (терминология, классификации, системы репортировния, единицы измерений и т.д.) и структура (обязательные и опциональные компоненты);
5) формат ответа (каждому элементу содержания ответа соответствует определенный формат: число, контур/маска, текст и т.д.);
6) техническая форма ответа (Apache Kafka Message, DICOM, DICOM SR и т.д.).
Подчеркнем, что БДТ прямо проистекают из клинического контекста: ИИ должен предоставить врачу-рентгенологу тот результат, которые необходим именно в конкретной ситуации. Например, при интерпретации профилактического рентгеновского исследования молочных желез (маммографии) результат работы ИИ должен представлять собой не абстрактную тепловую карту или дифференциальную диагностику выявленных образований, а классификацию по стандартизированной системе BI-RADS.
В основе БДТ лежат клинические рекомендации Министерства здравоохранения Российской Федерации, а также иные научные и методические материалы с высоким уровнем достоверности и убедительности. Ссылки на использованные при подготовке документы и публикации обязательно размещаются в БДТ по каждому направлению Московского эксперимента.
Разработка и периодическая актуализация базовых диагностических требований ведется группой врачей-экспертов с последующим их утверждением научно-проблемной комиссией НПКЦ ДиТ ДЗМ. БДТ публикуются на сайте Московского эксперимента (https://mosmed.ai/ai/docs/) и периодически издаются в формате методических рекомендаций, утвержденных Департаментом здравоохранения Москвы.
Для медицинского работника — непосредственного пользователя технологий искусственного интеллекта — именно благодаря базовым диагностическим требованиям реализуется принцип объяснимости ИИ.
Также на данном этапе установлены единые требования к скорости машинной обработки данных. Определено и включено в правила Московского эксперимента максимальное время, которое ИИ-сервис может затратить на прием, анализ и обратную передачу результатов. Методически требовалось, чтобы результат работы ИИ-сервиса оказывался в ЕРИС ЕМИАС до того, как врач начнет работу с данным исследованием. Очевидно, что выполнение требований к скорости описаний зависит не только от характеристик и возможностей серверного обеспечения ИИ-сервиса, но и от каналов связи. Однако предоставление результатов от СИИ во время или, тем более, после описания исходного изображения снижает шансы их использования врачом-рентгенологом до нуля. Поэтому требования были установлены достаточно жесткие, впрочем, как показала дальнейшая практика, они оказались полностью выполнимыми. Более того, длительность обработки стала одним из параметров технологического мониторинга (см. параграф 2.6). Стандартизация длительности обработки данных СИИ предотвратила как изменения временных норм по оказанию медицинских услуг, так и негативное влияние на упорядоченные рабочие процессы врача-рентгенолога.
Шестой этап был связан с решением технических задач. При изучении запросов системы здравоохранения Российской Федерации было установлено, что в соответствии с действующим законодательством программное обеспечение на основе технологий ИИ должно быть интегрировано с информационными системами в сфере здравоохранения субъектов РФ и/или медицинскими информационными системами. Поэтому в рамках Московского эксперимента была изначально предусмотрена бесшовная интеграция искусственного интеллекта. Это означает, что соответствующее программное обеспечение должно быть интегрировано с государственной информационной системой в сфере здравоохранения субъекта РФ, вести обмен данными с централизованным архивом медицинских изображений, получать и направлять данные в электронную карту пациента. Медицинский работник при этом должен работать с одним, привычным интерфейсом медицинской информационной системы. Для реализации сказанного проводится интеграция программного обеспечения на основе технологий искусственного интеллекта с Единым радиологическим информационным сервисом автоматизированной информационной системы города Москвы «Единая медицинская информационно-аналитическая система города Москвы» (ЕРИС ЕМИАС). Соответствующие технические положения и стандарты обобщены в базовых функциональных требованиях (БФТ). Они содержат унифицированную терминологию, технические требования к передаваемым данным (прежде всего — к ответу с результатами работы ИИ), к документированию, форматам и содержанию сообщений, маркировки изображений, описания тегов, положения по стандартизации и управлению рисками. БФТ также доступны на официальном сайте Московского эксперимента (https://mosmed.ai/ai/docs/).
Отдельным важнейшим аспектом технической и методической подготовки, тесно связанным с предыдущими этапами, стала стандартизация настроек диагностических устройств. В тесном взаимодействии с производителями оборудования унифицированы номенклатура, протоколы, заполнение DICOM-тегов. Тем самым обеспечен единый стандарт лучевых исследований в сети медицинских организаций ДЗМ.
Первые версии БФТ и БДТ опубликованы в монографии с обобщением результатов первого года Московского эксперимента.
Таким образом, основным методологическим подходом при внедрении ИИ в практическое здравоохранение служит триада стандартизированных документов:
1. Перечень обоснованных клинико-диагностических задач (направлений), решаемых в рамках стандартизированного производственного процесса в актуальном клиническом контексте.
2. Базовые диагностические требования.
3. Базовые функциональные требования.
Надо подчеркнуть, что решение каждой клинико-диагностической задачи представляет собой автоматизацию определенной трудовой операции в рамках стандартизированного производственного процесса, а также дает измеримый результат, пригодный для интегральной оценки результативности и эффективности внедрения технологий искусственного интеллекта.
Процесс практического использования ИИ должен сопровождаться тестированием и мониторингом безопасности и качества; подробно эти вопросы изложены далее, в параграфе 2.4.
2.2. Методология создания наборов данных
2.2.1. Определения и общие положения
Набор данных — состав данных, которые структурированы или сгруппированы по определенным признакам, соответствуют требованиям законодательства Российской Федерации и необходимы для разработки программ для электронных вычислительных машин на основе искусственного интеллекта.
Разметка данных — этап обработки структурированных и неструктурированных данных, в процессе которого данным (в том числе текстовым документам, фото- и видеоизображениям) присваиваются идентификаторы, отражающие тип данных (классификация данных), и (или) осуществляется интерпретация данных для решения конкретной задачи, в том числе с использованием методов машинного обучения.
Наборы данных (НД) — основа функционирования искусственного интеллекта. Они необходимы при создании моделей (обучение, тестирование, дообучение), на этапе использования (клинические испытания, внешняя валидация, первичные и повторные тестирования), а также в научных исследованиях. В Национальной стратегии развития искусственного интеллекта на период до 2030 года наборам данных уделено особое внимание:
— формирование НД определено одним из направлений повышения доступности инфраструктуры для СИИ;
— регламенты работы с наборами данных выбраны одними из основных направлений внедрения доверенных технологий искусственного интеллекта в органах публичной власти и организациях;
— законодательное обеспечение возможности доступа разработчиков технологий искусственного интеллекта к различным видам данных указано одним из основных направлений создания комплексной системы нормативно-правового регулирования общественных отношений, связанных с развитием и использованием технологий искусственного интеллекта, и обеспечения безопасности применения таких технологий;
— создание библиотек наборов данных входит в основные направления оказания поддержки организациям — разработчикам технологий искусственного интеллекта, а также в основные направления укрепления международного сотрудничества в области использования ТИИ.
С 2015 г. в НПКЦ ДиТ ДЗМ начаты системные научные исследования в области создания и применения наборов данных для обучения и тестирования искусственного интеллекта. Для научного тестирования СИИ эмпирически сформирован и размечен ряд наборов данных, четыре из которых получили официальное свидетельство о государственной регистрации базы данных. К 2018 г. научно обоснован оригинальный метод разметки очагов в легких сферическими кластерами; созданы алгоритмическая основа и программный комплекс, позволяющие проводить разметку компьютерных томограмм ОГК; подготовлен набор данных деперсонализированных размеченных компьютерных томограмм органов грудной клетки CTLungCa-500. Для помощи многочисленным разработчикам этот набор данных впервые в Российской Федерации размещен в свободном доступе. Он был скачан несколько десятков раз и использован для самотестирования и обучения несколькими научными группами разработчиков и компаниями.
В ходе подготовки и реализации Московского эксперимента потребовалось создание большого количества эталонных (валидированных) наборов данных, поэтому был организован непрерывный процесс их формирования (рисунок 2.1), в первую очередь для тестирования ИИ-сервисов, а также для научных исследований, нацеленных на изучение качества работы и потенциала развития СИИ, поиск новых направлений их применения.
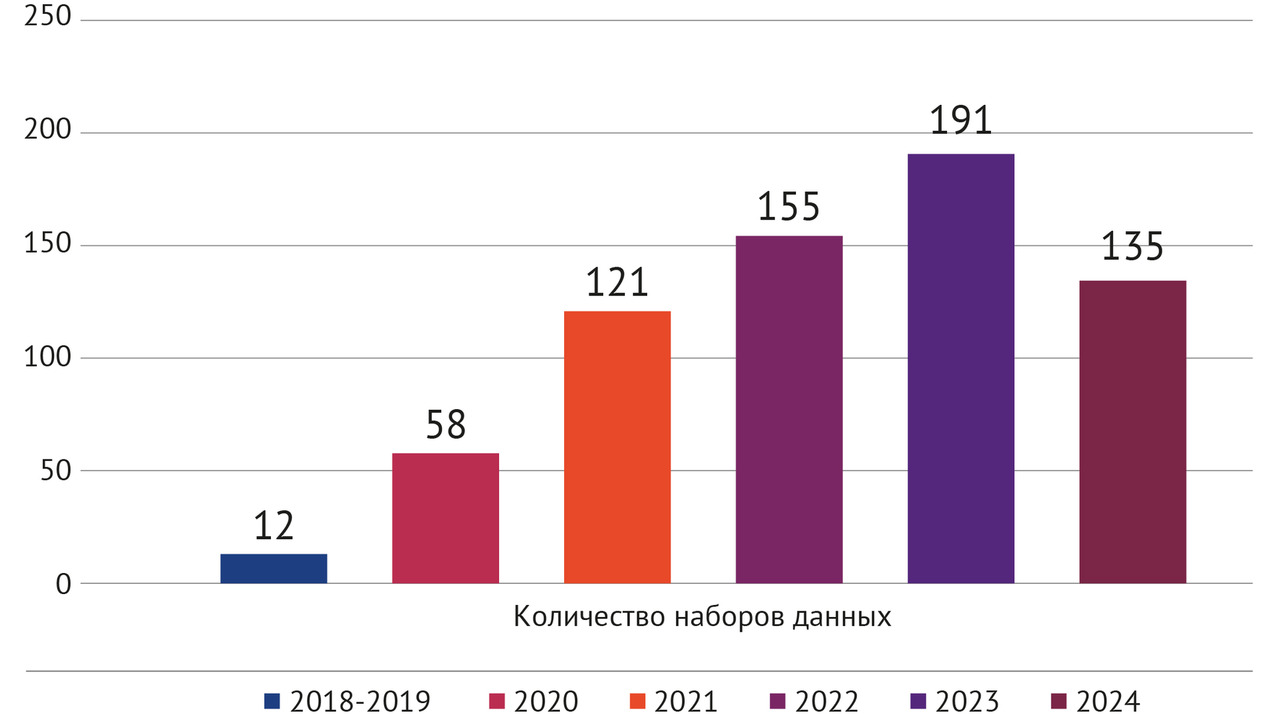
В процессе накопления опыта возникали новые задачи, и наборы данных создавались уже для обучения собственных моделей ИИ. Так были созданы инструменты контроля качества рентгенографии органов грудной клетки, анализа результатов компьютерной томографии печени CT HepatoScan Наличие богатого опыта формирования НД позволило сделать их самих объектом научного интереса и сформировать методологию их создания, принципы организации и инструменты работы с данными.
Путем систематизации эмпирического опыта и результатов экспериментально-лабораторной работы научно обоснованы и реализованы на практике:
— унифицированные основные характеристики наборов данных для разработки и тестирования СИИ в здравоохранении;
— понятие и требования к эталонным наборам данных;
— практико- и клинически ориентированная классификация наборов данных;
— обобщенная методология формирования наборов данных;
— мероприятия по организации разметки и контролю ее качества;
— формализованный производственный процесс создания наборов данных.
Все перечисленные разработки носят универсальный характер и могут применяться в разных клинических направлениях.
Научно-практическая ценность методологии описания, сбора и разметки данных, разработанной коллективом авторов, была подтверждена оценке независимыми группами исследователей. В первую волну пандемии COVID-19 по оригинальной методологии создан крупнейший в мире набор данных результатов компьютерной томографии органов грудной клетки у пациентов с ПЦР-подтвержденной новой коронавирусной инфекцией («MosMedData: результаты исследований компьютерной томографии органов грудной клетки с признаками COVID-19» (MosMedData-CT-COVID19-type VII-v 2)). Этот набор был размещен в открытом доступе, благодаря чему использован для обучения и тестирования алгоритмов ИИ учеными из разных стран мира. Данное утверждение подтверждается 11 статьями, индексируемыми системой Pubmed (в т.ч. авторских коллективов из Китая — 3, США — 2, Ирана — 1, международных групп ученых — 5).
Благодаря Московскому эксперименту впервые в Российской Федерации реализована библиотека наборов данных для сферы здравоохранения (https://mosmed.ai/datasets/). В библиотеке размещены свыше 250 наборов данных, по состоянию на 01.01.2025 зафиксировано 4709 скачиваний и десятки тысяч просмотров конкретных наборов. В пятерке лидеров по используемости — «MosMedData-CT-COVID19-type VII-v 2» (1093 скачиваний), «MosMedData-CT_XR_MMG-MULTI-type II» (481 скачивание), «MosMedData-CT-HEMORRHAGE-type VIII» (364 скачивания), «MosMedData-ECG-MULTI-type VII» (311 скачиваний), «MosMedData-MRI-MS-type II» (284 скачивания). Разработанные методологии целеполагания, стандартизации, работы с данными используются при создании технологий искусственного интеллекта, а также стали основой национальных стандартов.
2.2.2. Принципы классификации и организации наборов данных в лучевой диагностике
В лучевой диагностике набор данных представляет собой упорядоченную совокупность:
— диагностических изображений одной модальности и/или однотипных медицинских документов (например, протоколов описаний результатов исследований);
— сведений о наличии, характере и локализации патологических изменений на изображениях; для текстовых документов — библиотеки ключевых слов, словосочетаний и их критичных сочетаний;
— сведений о верификации диагноза (опционально).
В ходе Московского эксперимента установлено, что набор данных должен содержать следующие сведения описательного характера:
1) номер свидетельства о государственной регистрации базы данных в качестве результата интеллектуальной деятельности (рекомендательно);
2) характеристику популяции (возрастно-половые показатели, этнический состав, регионы проживания и т.д.); сведения о деидентификации; сведения о медицинских организациях, послуживших источниками для формирования базы данных; сведения о факторах риска;
3) характеристику диагностических исследований: анатомическая область (и), модальность, проекции, типы медицинских изделий — диагностических приборов, виды и характеристики протоколов исследования;
4) целевую патологию согласно Международной классификации болезней 10 версии (либо наименование феноменов в соответствии с клиническими рекомендациями, национальными стандартами, рекомендациями профильных ассоциаций врачей-специалистов);
5) общее количество клинических случаев, исследований, изображений, документов и их распределение по диагностическим группам;
6) соотношение случаев «норма»/«патология» (случаи «патология» могут быть разделены на несколько подклассов);
7) сведения о верификации (патогистологическом или ином окончательном диагнозе);
8) методологию разметки.
На международном уровне сформирован рекомендательный список метаданных для верифицированного набора медицинских изображений:
1. Тип изображения: вид исследования (компьютерная томография, рентгеновское исследование и т.п.); разрешение; общее число изображений и по сериям.
2. Число исследований.
3. Источники исследований: оборудование; типы оборудования; медицинская организация.
4. Параметры сканирования изображений.
5. Параметры хранения изображений: формат данных; уровень и тип сжатия данных.
6. Аннотация (разметка): тип; что и как описано; привлеченная экспертная группа.
7. Контекст.
8. Как определена истинная разметка и промаркирована.
9. Связанные данные: демографические; клинические; лабораторные; геномные; временные; принимаемые медикаментозные средства; другие.
10. Временной диапазон сбора изображений: дата и время исследования.
11. Использование данных: какое программное обеспечение использовать для просмотра данных.
12. Кому принадлежат данные.
13. Кто ответственен за данные.
14. Допустимое использование.
15. Назначение набора данных.
16. Информация об одобрении комитета по этике.
17. Информация о деидентификации набора данных.
18. Информация о проведенном контроле качества набора данных.
19. Параметры доступа: доступность; цена и лицензионные соглашения.
20. Распределение случаев (если применимо): процент «норма/патология» (код МКБ-10); данные патологии: число исследований с каждой патологией.
Уже на первых этапах Московского эксперимента сформирован общетеоретический подход к классификации, состоящий в выделении трех видов наборов данных, определяемых процессом выполнения разметки (рисунок 2.2). Классификация цитируется по ГОСТ Р 59921.5–2022:
1. Набор данных по ретроспективной разметке. Такая разметка подразумевает сбор данных в соответствии с указанными метаданными, перечень которых выбирают в соответствии с поставленной целью формирования НД. Она выполняется путем выгрузки данных из медицинской информационной системы. Ретроспективная разметка не предполагает выполнение манипуляций или какой-либо обработки элементов. Для каждого элемента НД лишь устанавливают соответствие с медицинской информацией (диагноз, результаты лабораторного тестирования и т.п.). Такой способ разметки не требует участия врача, он может быть реализован на основе технического задания техническим специалистом, который имеет опыт работы с НД.
2. Набор данных по проспективной разметке. Такая разметка подразумевает сбор данных в соответствии с поставленной целью формирования НД, а также проведение дополнительных манипуляций с элементами (например, путем постановки метки начала и окончания события, меток обнаружения признаков, обозначений патологий и т.п.). Такую разметку проводят с участием обученного медицинского персонала путем ручного аннотирования содержания данных или их частей, которое может быть выполнено в графической или текстовой форме, либо в их комбинации.
3. Верифицированный набор данных. Разметка в таком случае подразумевает включение верифицированной (то есть подтвержденной объективными свидетельствами) медицинской информации. Такой НД формируют путем дополнения результатов проспективной разметки данными из медицинской документации. Для верификации можно применять метод «золотого стандарта» для целевой патологии, информацию об окончательном и/или патологоанатомическом диагнозе, повторное исследование пациента через определенное время, результаты патогистологических, иммунологических исследований и др. Отдельным методом верификации служит слепой анализ набора данных экспертами с достижением заданного уровня согласованности их решений.
Сформированы следующие критерии отнесения НД к верифицированному:
— данные получены из реальной практики (не допускается получение синтезированных данных);
— данные получены в «сыром виде» — без применения фильтров и математических средств постобработки;
— структура НД соответствует поставленной цели его формирования (обучение, тестирование, клинические испытания и проч.);
— количество наблюдений (исследований) достаточно для достижения статистической значимости результата;
— разметка и/или аннотирование проведены экспертной группой, соответствующей определенным критериям (см. далее);
— разметка и/или аннотирование проведены с использованием тезауруса (кодированной библиотеки типовых формулировок, соответствующих клиническим рекомендациям, национальным стандартам, рекомендациям ассоциаций специалистов в данной области).
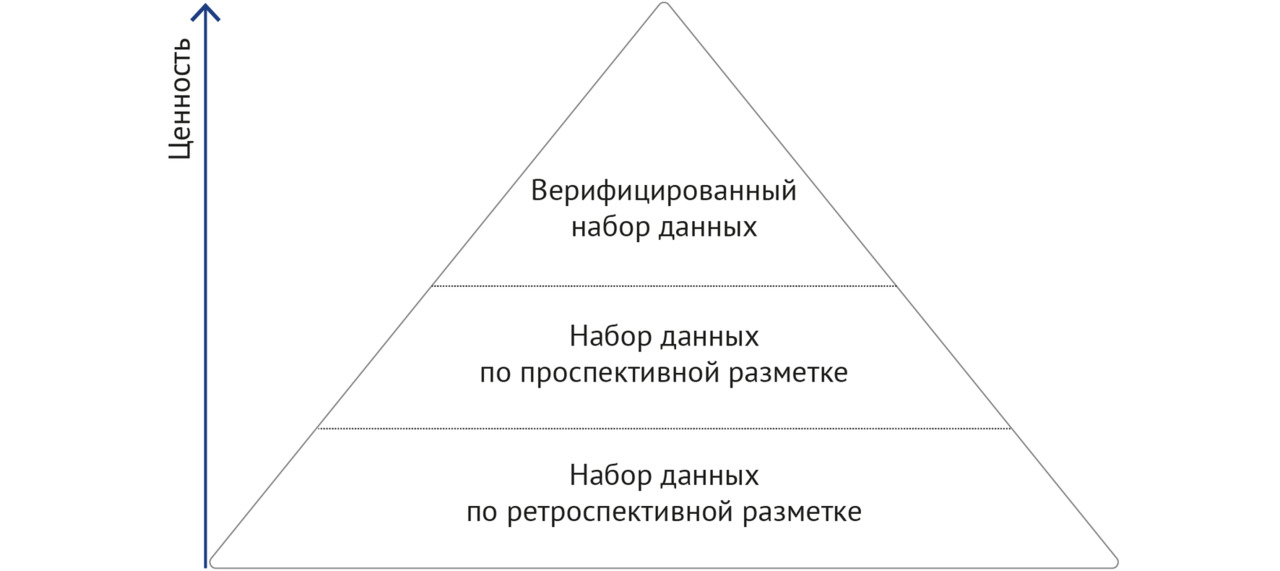
Приведенный подход включен в национальный стандарт ГОСТ Р 59921.5–2022 как основополагающий. В дальнейшем, по мере накопления практического опыта и научных знаний, были разработаны более специализированные классификации наборов данных лучевой диагностики по диагностической ценности (рисунок 2.3) и по целевому назначению (таблица 2.1). Также в дальнейшем были классифицированы методы верификации (рисунок 2.4).
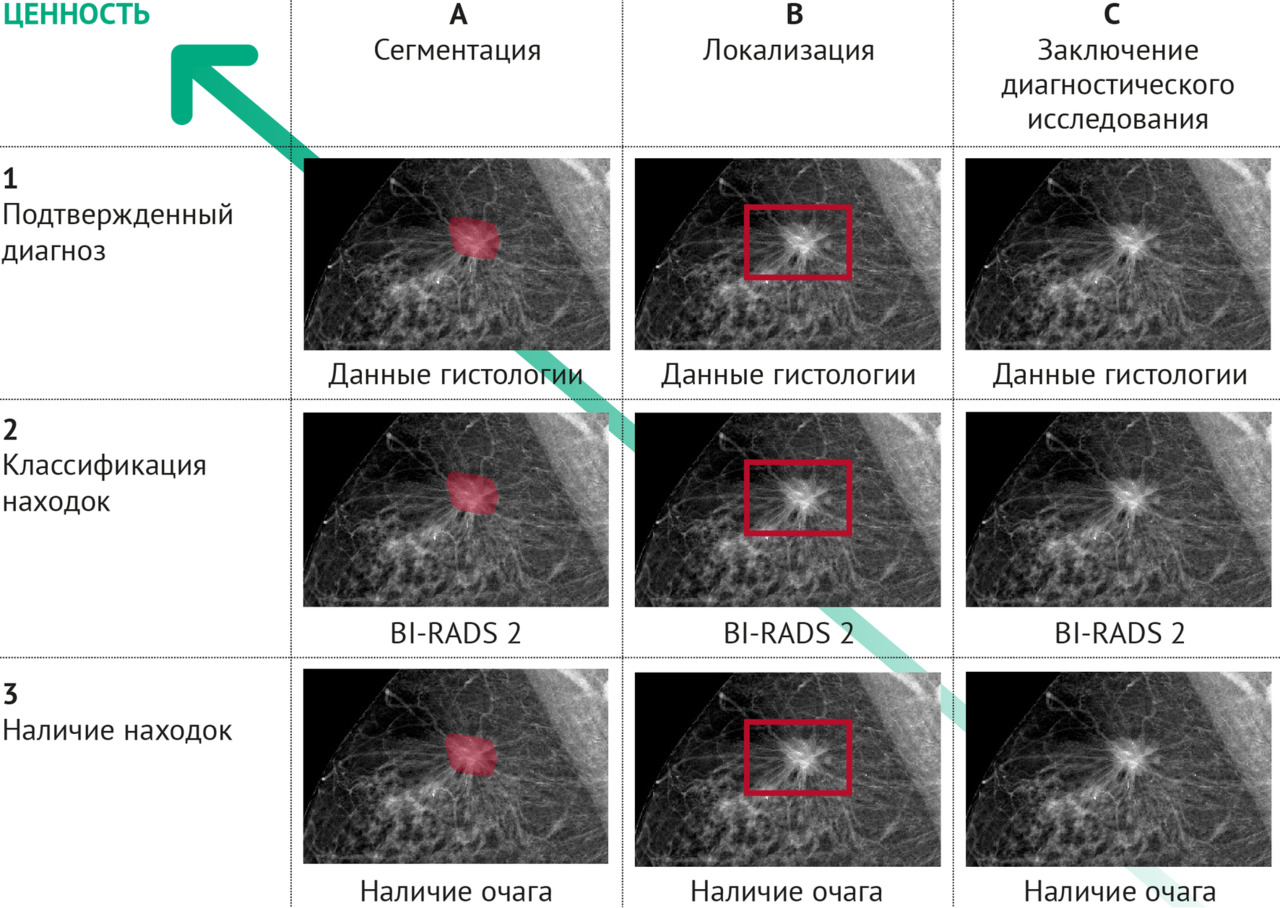
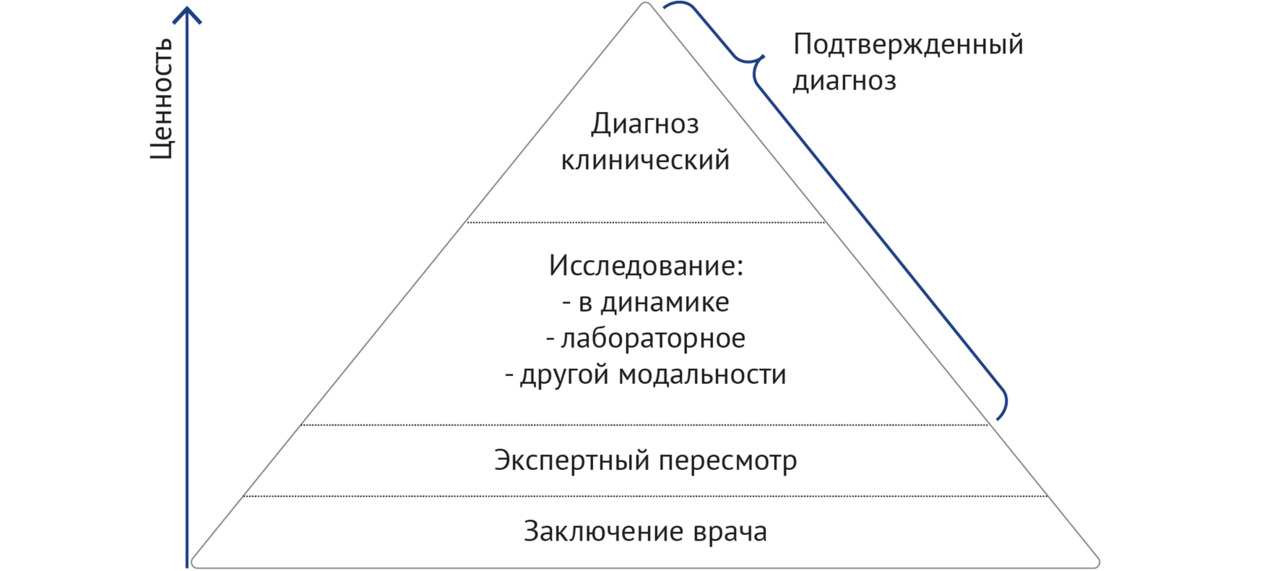
Классификация по диагностической ценности предполагает разделение наборов данных на три вида (1, 2, 3) и три класса (A, B, C). Вид подразумевает типовой способ верификации:. Бинарная оценка факта наличия или отсутствия целевой патологии.
2. Классификация целевой патологии в соответствии с клиническими рекомендациями, стандартизованными клинико-рентгенологическими классификациями, шкалами, системами описания.
3. Наличие данных о верификации природы целевой патологии.
Класс подразумевает типовой способ отображения патологической находки в результатах лучевого исследования — информация о наличии/отсутствии целевой патологии:
1. Содержится в метаданных, сопроводительных файлах (таблицах), отсутствует на изображении.
2. Представлена в виде координат. Может помещаться в метаданные (аннотация, сводный табличный сопроводительный файл) и/или присутствовать на изображении в виде отметки области расположения простой геометрической фигурой.
3. Представлена на изображении в виде пиксельной маски (оконтуренной области изображения), дополнительно может содержаться в метаданных (в аннотации).
Классификация может применяться в отношении наборов данных для любых задач лучевой диагностики. Она не зависит от типов (модальности) диагностических данных, но вместе с тем четко отображает взаимосвязь между собой:
— объемов и качества исходных данных;
— трудозатрат на подготовку;
— методик разметки и работы с первичными данными;
— диагностической ценности в контексте той или иной медицинской задачи.
Классификация по цели использования с появлением новых задач претерпела значительные изменения и в итоговом варианте содержит 10 типов НД (таблица 2.1).
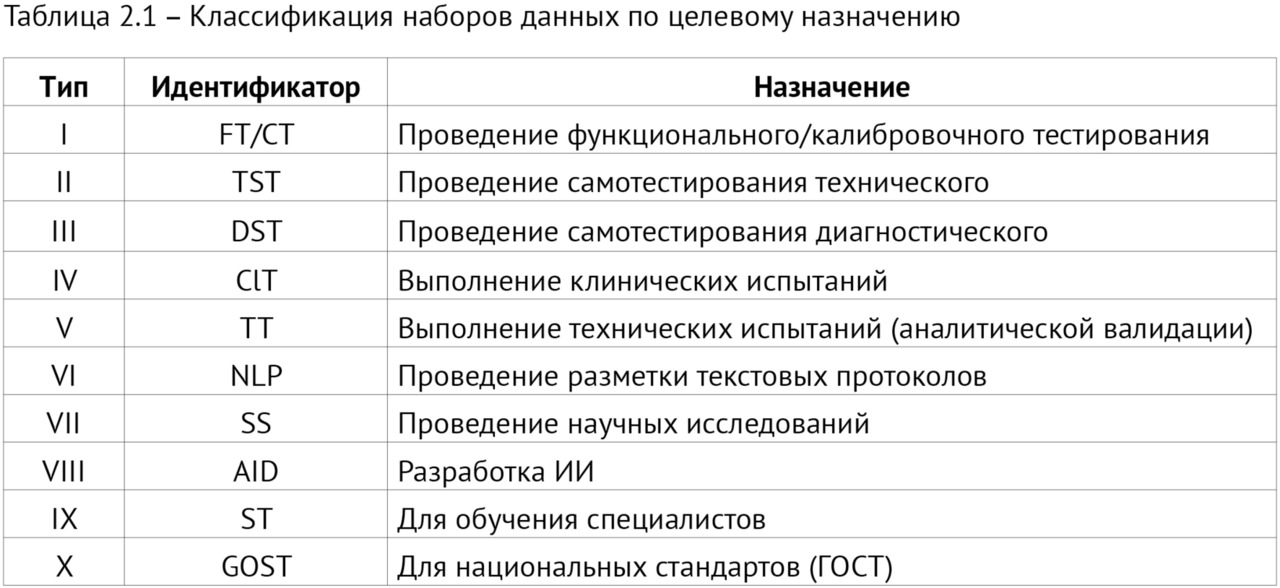
Исторически самым первым и самым разнообразным типом являются наборы данных для научных исследований (VII). Опыт их создания послужил основой для всех остальных типов и для формирования методологии, в процессе которой определился VI тип. На первых этапах исследования НД собирались исключительно вручную на потоке (просматривались все исследования целевой модальности на предмет наличия патологии), однако централизованное хранение всех лучевых исследований в ЕРИС ЕМИАС, включая текстовые протоколы описания и заключения, позволили в дальнейшем автоматизировать этот процесс. Было положено начало направлению работы с медицинскими текстами, которое потребовало создания специальных наборов данных (VI). Большинство наборов данных принадлежит к I типу (минимум 4 НД на каждое направление), так как предназначены для валидационных тестирований ИИ-сервисов в Московском эксперименте, а также к III и IV типу — для самотестирования (самостоятельной проверки корректности диагностической оценки ИИ-сервисами и их работоспособности на разных диагностических устройствах). Отдельные типы (IV и V) НД созданы для клинических испытаний. На более поздних этапах при разработке собственных ИИ-сервисов потребовались наборы данных для обучения (VIII). Накопленный научный и практический опыт позволил разрабатывать национальные стандарты, в рамках которых также требовались эталонные НД (тип X). Деятельность ГБУЗ «НПКЦ ДиТ ДЗМ» включает самые разные направления, например, образовательную работу, в рамках которой создаются НД для обучения и тестирования врачей (тип IX). По-видимому, список типов наборов данных в дальнейшем также будет претерпевать изменения с еще большим расширением возможностей и появлением новых задач.
Также опыт показал, что количество исследований (единиц НД) не определяется типом набора. Расчет объема выборки является нетривиальной задачей и зависит от множества факторов (подробнее см. 2.3.1).
Одной из первых задач, которую решали ИИ-сервисы в Московском эксперименте, стало определение на результатах лучевого исследования наличия признаков, характерных для целевой патологии. В рамках данной задачи валидационные НД (те, которые использовались при тестировании ИИ-сервисов) преимущественно относились к С-классу разметки (рисунок 2.3); при разметке в этом случае прежде всего требовалось отнести исследование к верному классу (как правило, с наличием/отсутствием патологии, реже — ее классификация по степени тяжести). В дальнейшем, в ходе анализа результатов работы ИИ-сервисов, возникали новые задачи, требующие более сложных НД. Так, отмечалась некорректная работа ИИ-сервисов в исследованиях с артефактами, дефектами укладки или некорректно заполненной метаинформацией. В результате были созданы соответствующие НД и впервые разработан ИИ-сервис для определения их качества.
С развитием Московского эксперимента расширялись требования к результатам работы ИИ-сервисов, в ходе накопления практического опыта и при проведении научных исследований возникали новые задачи и стратегии применения СИИ в медицине. Так, появилось новое направление — автоматизация рутинных измерений (морфометрия) и соответствующие ему наборы данных. В дальнейшем обозначилась потребность в динамических НД, а также в наборах изображений, обогащенных клинической информацией. Поэтому возникла новая классификация наборов данных по решаемой задаче:
1. Диагностические (оценка качественных признаков: наличие/отсутствие, степень выраженности, классификация признака).
2. Морфометрические (оценка количественных признаков: измерение линейных размеров, площадей, углов, объемов, коэффициентов).
3. Для контроля качества (с артефактами и дефектами укладки, ошибками DICOM-тегов и т.д.).
4. Динамические (оценка исследований в динамике, прогностические задачи).
5. Обогащенные клинической информацией (НД с дополнительной клинической информацией для разработки СППВР и прогностических задач).
6. Комбинированные (сочетающие в себе вышеперечисленные данные).
Отдельное внимание заслуживают синтетические НД (см. параграф 2.2.5). Такое обилие классификаций обусловлено большим количеством наборов данных, созданных в ГБУЗ «НПКЦ ДиТ ДЗМ» за 5 лет (более 600!) и разнообразием решаемых задач, в том числе перспективных. Все разработанные принципы классификации и организации метаданных реализованы в виде реестра НД.
Реестр наборов данных — это перечень всех созданных в учреждении НД, содержащий структурированную информацию о них. Потребность в таком инструменте возникла с первых дней Московского эксперимента, в частности, для выбора НД при проведении функциональных и калибровочных тестирований. Первоначально это был простой список названий НД, однако с увеличением количества направлений возникла потребность в дополнении списка различными параметрами, а также в унификации названий и создании идентификаторов, кодирующих базовую метаинформацию. Примеры структуры названия и идентификатора приведены на рисунках 2.5 и 2.6.

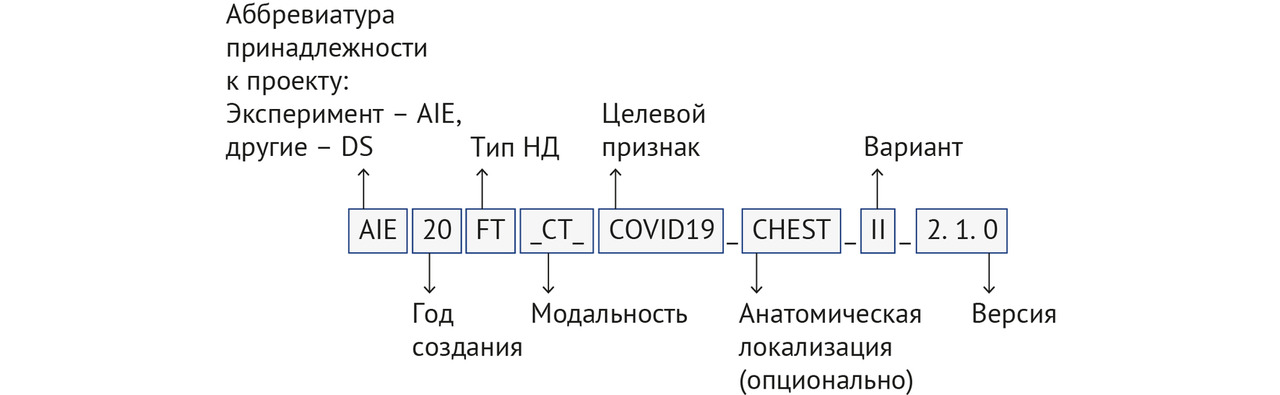
К сожалению, с появлением новых задач, разработанные правила наименования не всегда позволяют создавать релевантные названия, однако при этом структура названия гибкая и может меняться (дополняться) в зависимости от требуемых для внесения параметров. Полная форма названия чаще используется для регистрации результатов интеллектуальной деятельности или упоминания НД в публикациях, документах и в устной речи. Идентификатор необходим для наименования файла, так как длина названия ограничена, а также в нем зашифрованы дополнительные данные, необходимые в контексте выполняемых задач. Например, на рисунке 2.6 идентификатор читается как: «Набор данных для Эксперимента, созданный в 2020 году, для функционального тестирования по направлению ″компьютерная томография органов грудной клетки″ с наличием и отсутствием признаков коронавирусной инфекции COVID-19, вариант 2, версия 2.1.0». Вариативность создана с целью тестирования ИИ-сервисов на разных НД с одинаковой спецификацией, а версионность разрешает отслеживать изменения, вносимые в набор. Идентификатор позволяет однозначно определить НД, который отправлялся ИИ-сервису для тестирования, для дальнейшей корректной (в т.ч. автоматизированной) оценки результатов обработки и обеспечения прозрачности процесса тестирования.
Реестр наборов данных как полноценный инструмент был сформирован в 2022 году и содержал в себе порядка 100 полей. Их количество и названия незначительно колебались в процессе совершенствования инструмента, однако принципы организации оставались общими:
1. НД имеют унифицированные названия и идентификаторы.
2. Метаинформация структурирована и классифицирована согласно российским и международным медицинским справочникам (ФСИДИ, Международная классификация болезней 10-й версии, справочник ЕРИС ЕМИАС, справочник анатомических локализаций, RadLex, LOINC), а также разработанным классификациям (классы разметки, методы верификации, характер и уровень разметки, источник данных, направление Московского эксперимента и т.д.).
3. Реестр имеет разделы, синхронизированные с жизненным циклом набора данных. Его заполнение происходит на каждом этапе, включая использование, и продолжается до момента утилизации НД (если такой наступает).
4. Описательная информация (карточка НД) составлена с учетом как собственного опыта использования метаинформации, так и чек-листов описания НД и СИИ в научных публикациях в мировых рецензируемых изданиях. Она организована по разделам: клинические, популяционные, технические параметры, назначение, параметры разметки.
Благодаря всему перечисленному реестр выполняет следующие функции:
1. Обеспечение процессов управления: контроль сроков и порядка выполнения работ по созданию НД, оценка результативности использования, оптимизация ресурсов (повторное использование данных).
2. Доступ к данным: единое место хранения всей информации, включая ссылки на хранение, указание ответственных за НД, удобное формирование библиотеки.
3. Контроль качества данных: проверка параметров НД на соответствие техническому заданию, базовым диагностическим требованиям, отслеживание внесения изменений (смена версионности).
4. Автоматизация процессов создания НД: генератор readme-файла, автоматическая проверка данных на соответствие техническому заданию.
Реестр представляет собой практическое внедрение научно обоснованного стандарта набора данных для лучевой диагностики.
2.2.3. Жизненный цикл и алгоритм создания набора данных
Важнейшим результатом, полученным в ходе создания и использования наборов данных, стала описанная методология, включающая в себя жизненный цикл НД (рисунок 2.7) и непосредственно алгоритм его создания (рисунок 2.8).
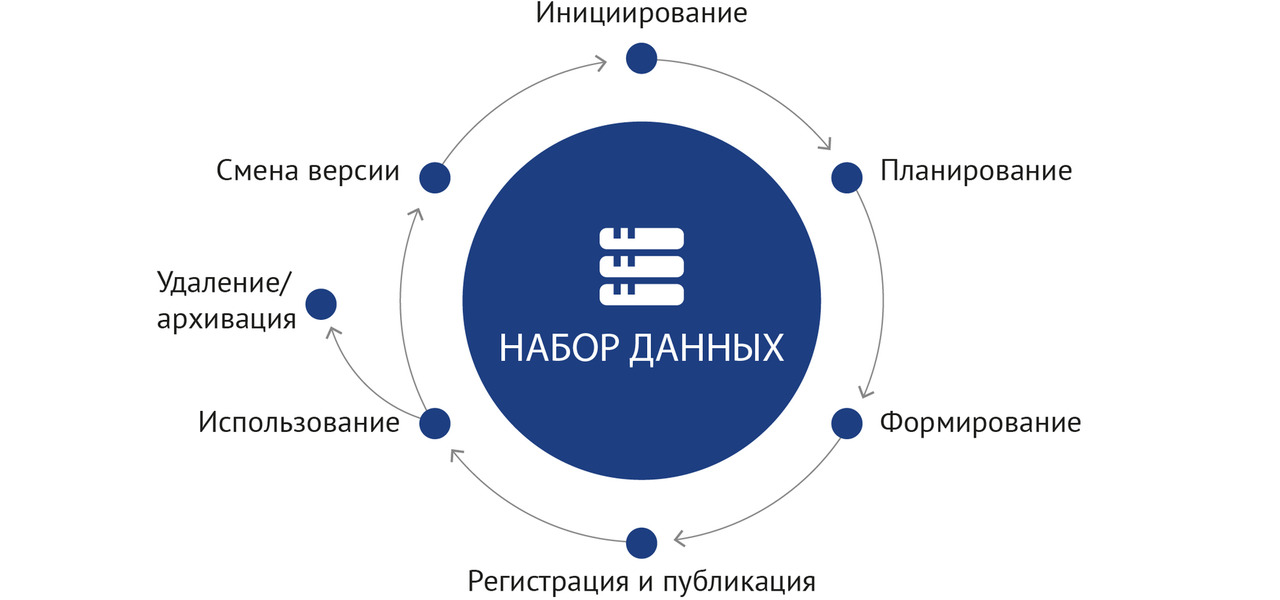
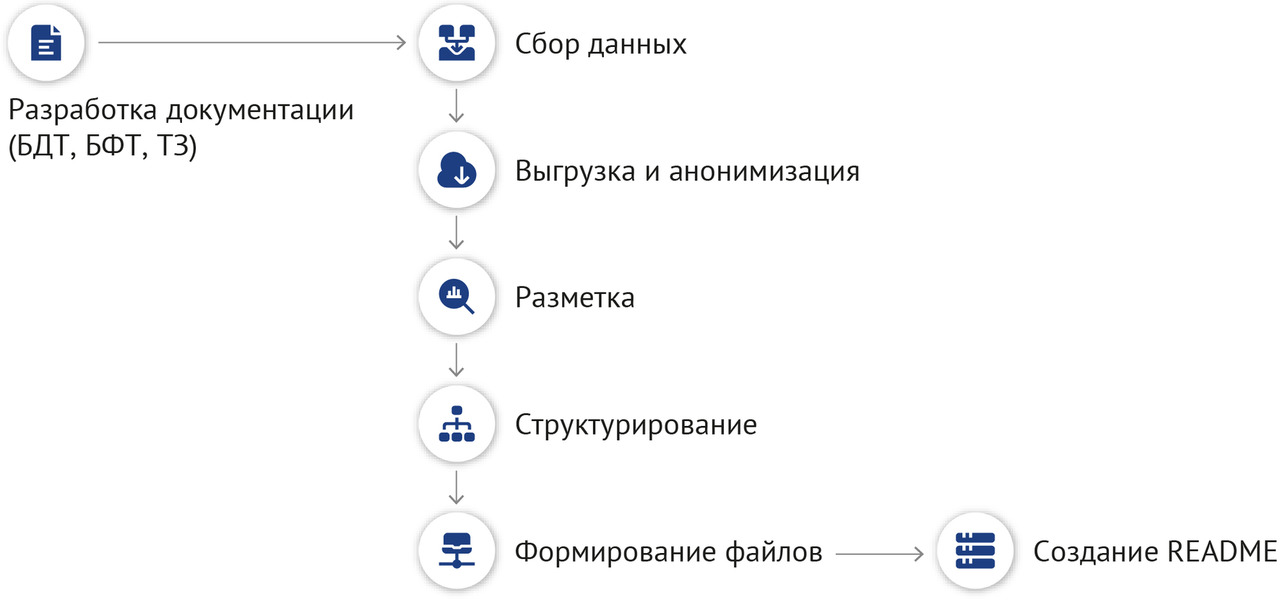
Сформированная методология позволяет регламентировать все процессы, связанные с наборами данных, описывает все действия, которые необходимо совершить разработчику или исследователю, начиная от идеи/потребности создания НД, заканчивая его использованием, сменой версии и утилизацией. Это позволяет наладить четкие процессы выполнения работ, а также не упустить важные аспекты, в т.ч. связанные с безопасностью данных и регламентированные законодательством, что в свою очередь минимизирует вероятность возникновения ошибок, повышает качество и снижает сроки создания наборов.
Кроме того, сформулированная этапность всех действий позволила автоматизировать эти процессы. На первых этапах Московского эксперимента, когда методика только начинала формироваться, большая часть работ выполнялась вручную. В дальнейшем внедрялась автоматизация отдельных процессов: как правило, это были разрозненные программы, не имеющие интерфейса. Для их использования требовалась помощь разработчика и/или научного сотрудника, который адаптировал код под конкретную задачу и запускал процесс обработки данных. Для оформления сопроводительной документации также разрабатывались специальные шаблоны для заполнения. Объединить весь накопленный опыт удалось в оригинальном программном продукте «Платформа подготовки наборов данных». Он имеет удобный интерфейс и модульную структуру, при этом модули можно использовать последовательно, согласно алгоритму создания НД, или изолированно. Далее описаны этапы жизненного цикла и алгоритма создания НД от первых шагов до единой платформы подготовки.
Подготовка набора данных в общем виде состоит из набора процедур, выполнение которых позволяет достигнуть цели обучения и тестирования системы искусственного интеллекта (СИИ) с обеспечением качества набора данных.
Инициирование. Первый этап жизненного цикла наступает с момента появления идеи создания конкретного НД и определения его цели. Формирование цели НД включает оценку того, является ли доступ к данным или другая деятельность по их обработке допустимыми:
— какие данные допустимо собирать;
— как их следует использовать (применительно к каким задачам);
— кому их следует раскрывать (доступ третьим лицам);
— в течение какого времени они должны быть доступны.
Цели формирования НД разнообразны, наиболее типичны следующие:
— разработка СИИ, включающая этап обучения алгоритма искусственного интеллекта и выполнение внутреннего тестирования;
— научная независимая оценка СИИ;
— выполнение аналитической или клинической валидации СИИ, в том числе в рамках клинических испытаний.
Как оформленный этап инициирования появился при внедрении в работу реестра наборов данных? До этого момента, информация о них хранилась разрозненно и не структурированно, иногда не фиксировалась вовсе. С появлением реестра возникла возможность вносить информацию о НД еще на этапе идеи, что позволило эти идеи организовать, отслеживать и развивать. На платформе для инициирования необходимо заполнить ключевую информацию (предварительное название, Ф. И. О. ответственного, ключевая информация в свободной форме), после чего НД появится в реестре и будет доступен для дальнейших манипуляций (рисунок 2.9).
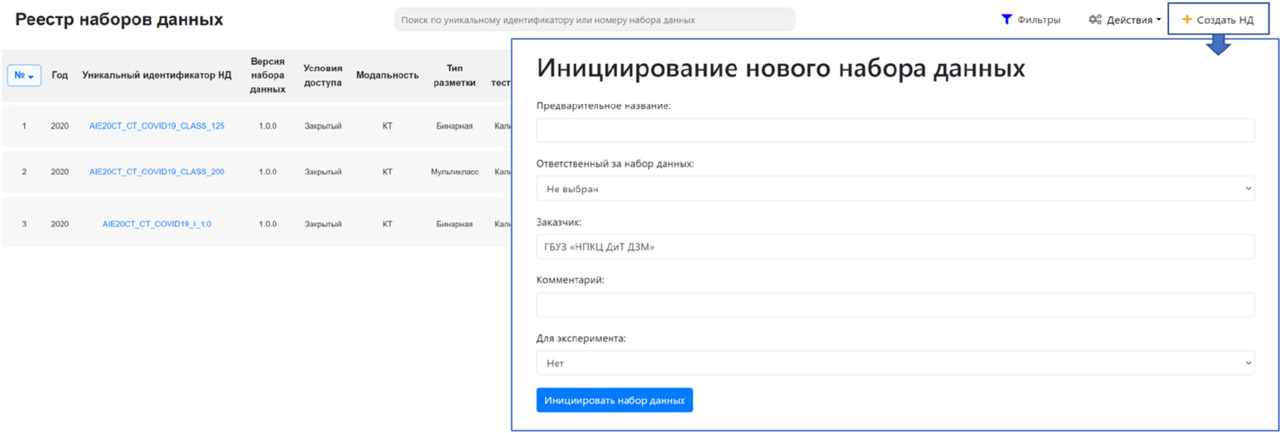
Планирование. Этап предполагает детальную проработку сформулированной ранее идеи.
На этом этапе осуществляется постановка задачи подготовки НД, включающая определение предметной области и выбор методов обработки. Задача должна быть определена проблемой, на решение которой направлено создание СИИ, ее классом, задачей или целью проведения тестирования.
Исходя из задачи определяются:
1. Размер набора данных (размер выборки для его формирования). Подробнее этот вопрос рассмотрен в подпараграфе 2.3.1.
2. Баланс данных и распределение классов. Сбалансированный набор данных должен содержать одинаковое количество примеров различных категорий (классов) объектов интереса, включая примеры нормы. При условии бинарной классификации это может соответствовать распределению 50/50 для случаев «патология»/«норма».
Вся информация о будущем НД фиксируется в техническом задании (ТЗ), которое составляется, в том числе с учетом базовых диагностических и функциональных требований Московского эксперимента.
Изначально ТЗ формулировалось в свободной форме, со временем был разработан структурированный шаблон и, наконец, в составе платформы ТЗ реализовано в виде структурированной формы для заполнения. Для удобства часть полей предварительно заполнена, подгружены используемые справочники, настроены связи между ними, реализовано автоматическое формирование названия НД согласно описанным выше правилам, имеются справочные вкладки, поясняющие, какую информацию необходимо внести. Это позволяет тщательно продумать все аспекты будущего НД и, возможно, обратить внимание исследователя на те моменты, которые на первый взгляд могли показаться неважными. Фактически платформа осуществляет обучение процессу создания НД. На основании введенной информации генерируется таблица разметки, если это необходимо.
После утверждения ТЗ вся информация выносится в карточку НД, где она структурирована по разделам: клинические, популяционные, технические параметры, назначение, параметры разметки, ответственные (рисунок 2.10г). В дальнейшем на этапах регистрации и использования эта информация дополняется.
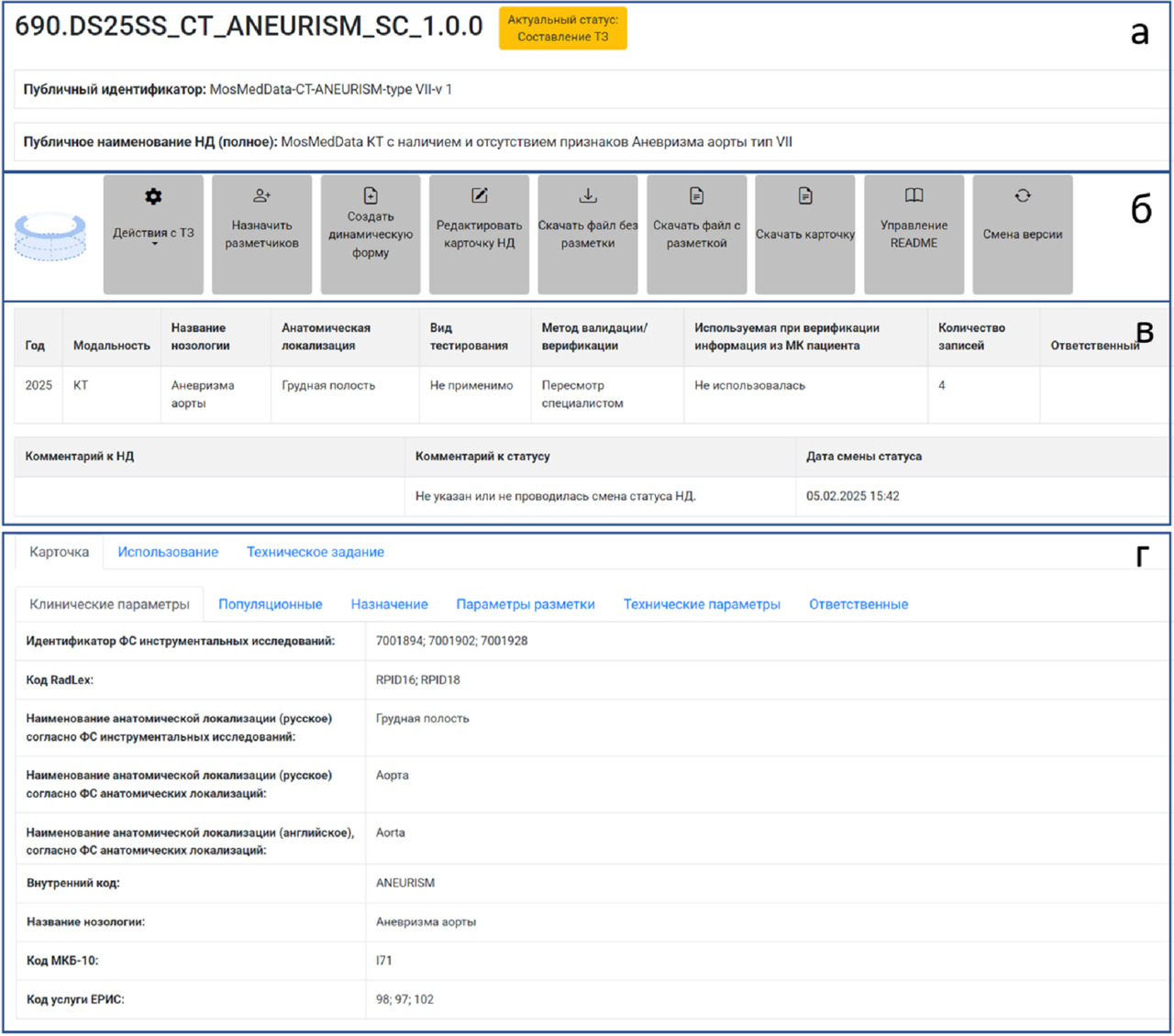
Формирование. Сбор данных. Первым шагом является непосредственно работа с данными, которая начинается с их поиска и отбора.
Здесь возможны два подхода — для НД представление медицинских данных (феноменов, синдромов, заболеваний, исходов) происходит:
1) с отражением максимальной вариативности (то есть и частые, и редкие случаи представлены в одинаковом объеме);
2) согласно их частоте встречаемости, предтестовой вероятности, заболеваемости, распространенности в популяции.
Первый подход должен применяться при подготовке НД аналитической валидации СИИ, второй — для клинической (см. подпараграф 2.9.2).
Для тестирования и оценки эксплуатационных характеристик СИИ в набор данных целесообразно добавлять тест-случаи (контрольные тесты), соответствующие ситуациям, сложным для классификации экспертами: данные с высоким уровнем шума либо с ухудшенными характеристиками (например, в результате сбоя оборудования), изображения с недостаточной видимостью целевых объектов, изображения нерелевантных анатомических областей или видов исследований. Включение таких данных позволит проверить устойчивость СИИ в дополнение к заявленным эксплуатационным характеристикам.
Принципы сбора данных для аналитической валидации:
1. НД пригоден для определения следующих характеристик: производительность (например, время, затрачиваемое на обработку СИИ медицинского исследования при наличии функции автоматического расчета времени и т.д.), точность интерпретации исследований с учетом функциональных возможностей СИИ, повторяемость, воспроизводимость.
2. НД может включать элементы с нарушением технологии (внешние помехи, артефакты, неверное наложение электродов/датчиков, нарушение последовательности регистрации, укладки пациента и т.п.). При этом такие элементы должны быть помечены должным образом (например, посредством меток в метаданных).
3. При формировании использованы данные из разных медицинских организаций и разных моделей/производителей оборудования, обработку данных с которых изготовитель СИИ включает в функциональное назначение.
Принципы сбора данных для клинической валидации:
1. НД должен быть верифицированным.
2. Сбор данных проводится с учетом следующих аспектов:
— соотношение «норма»/«патология» или разные заболевания в НД определяют областью применения СИИ;
— используют данные из разных медицинских организаций и разных моделей/производителя оборудования;
— демографические, социально-экономические характеристики и основные показатели здоровья пациентов (репрезентативная выборка) должны соответствовать усредненным характеристикам популяции территории, на которой планируется использование СИИ;
— планируемый размер набора данных должен быть обоснован в документации испытаний, исходя из статистических соображений и желаемой точности оценки основных метрик (подробнее см. подпараграф 2.3.1).
NB! Принцип многоцентрового сбора данных особо важен для снижения систематической ошибки, так как невключение в НД элементов, получаемых на некой модели оборудования, может привести к разнообразным ограничениям и рискам. Возможно использовать данные из разных медицинских организаций, но обладающие одинаковой структурой и полученные в результате применения оборудования с одинаковым процессом работы (одинаковая модель/производитель).
На первых этапах Московского эксперимента сбор данных производился вручную «на потоке»: врач-рентгенолог при просмотре исследований в ЕРИС ЕМИАС фиксировал номера подходящих исследований, а в дальнейшем они отправлялись на разметку. Далее это процесс был оптимизирован путем автоматизации работы с текстовыми протоколами заключений; для этого был разработан инструмент MedLabel. Из ЕРИС ЕМИАС выгружались анонимизированные текстовые протоколы заключений, далее проводилась предразметка с помощью MedLabel (формировалась таблица, включающая номер исследования, протокол, разметку), после чего врач-рентгенолог пересматривал заключения и корректировал разметку на основании текста. Это позволило существенно ускорить процесс сбора данных, однако применение разработанного программного обеспечения требовало привлечения дополнительного технического специалиста, а в дальнейшем, при расширении направлений Московского эксперимента, Medlabel потребовал доработки. Тогда был реализован более простой метод отбора исследований по «ключевым словам» и «стоп-конструкциям»: специальный алгоритм анализировал наличие слов, характерных для целевой патологии, а также слов, говорящих об отсутствии патологии (например, «не выявлено», «отсутствуют», «без признаков»), и на основании этого присваивал значение разметки. Этот принцип лег в основу разработки инструмента поиска исследований (рисунок 2.11). Он имеет интуитивно понятный интерфейс и позволяет отбирать исследования путем фильтрации по его модальности, процедуре, датам проведения, возрасту пациента, среди которых происходит поиск целевых патологий по текстовым протоколам (рисунок 2.11а). В результате формируется таблица с номерами исследований, текстовыми протоколами и предварительной разметкой. Далее исследования, если требуется, пересматриваются врачом-рентгенологом в подмодуле пересмотра, в основу которого положен инструмент с открытым кодом LabelStudio (рисунок 2.11б). Результат работы модуля — сформированный список идентификаторов исследований с разметкой по текстовым протоколам.
Выгрузка и деидентификация (анонимизация) исследований. Эти два процесса неразрывно связаны между собой, т.к. выгрузка без анонимизации повышает риск утечки персональных данных и нарушает принципы информационной безопасности. В начале Московского эксперимента этот этап следовал после разметки, т.е. разметчики просматривали исследования в ЕРИС ЕМИАС, а процесс выгрузки и анонимизации завершал формирование НД. Выгрузка производилась с помощью специально разработанного кода. На «Платформе подготовки наборов данных» данный функционал реализован в виде специального модуля: загружается таблица из модуля поиска, настраивается ряд параметров (диапазон дат, модальность, кластер) и производятся выгрузка и анонимизация исследований (можно выбрать отдельные серии или исследования из списка) (рисунок 2.12).
Относительно деидентификации необходимо указать, что в целом элементы НД не должны содержать какую-либо персональную информацию согласно действующим нормативно-правовым актам; любая персональная информация должна быть удалена как из метаданных, так и из исходных данных. Также должны быть удалены любые иные идентификаторы, с помощью которых потенциально возможно установить личность пациента. Деидентификация данных должна быть произведена в МО, в которой было проведено медицинское исследование, при условии наличия согласия пациента на обработку его персональных данных, включая деидентификацию (обезличивание).
Деидентификация метаданных и изображений в формате DICOM проводится в соответствии с ГОСТ Р 71674—2024.
Разметка (аннотация).
В глобальной перспективе существуют два условно стандартизированных подхода к разметке (аннотированию) медицинских данных:
1. «Аннотация и разметка изображений» (англ. annotation and image markup (AIM)). Использует три базовых концепта:
1) визуальные наблюдения («масса», «поражение», «очаг»);
2) анатомические объекты («затылочная доля», «теменная доля», «медиальный сегмент средней доли правого легкого»);
3) интерференция (нарушение) (поражение речевого центра», «плевральный выпот», «пневмония»).
Визуальным наблюдениям и анатомическим объектам задают характеристики. Например, характеристики наблюдений — «предполагаемый», «кистозный», объектов — «расширенный», «разорванный». После задания характеристик наблюдений и объектов проводят их количественную оценку. Ее допустимо выражать в терминах «присутствует», «отсутствует», «не применимо» либо квартиль/процентиль, либо в произвольной шкале и др. Проводят совмещение этой описательной информации с графическими символами, располагаемыми экспертами на самом изображении, в единый тип данных.
2. «Состояние представления DICOM» (англ. DICOM Presentation State (PS)). Независимый экземпляр класса типовой инструкции DICOM, который содержит информацию о том, как должно отображаться конкретное изображение с использованием всех возможных параметров и визуальных элементов, определенных в стандарте DICOM. Позволяет без потерь вернуться к оригинальному изображению, поскольку никак не модифицирует пиксельные данные.
В рамках Московского эксперимента были выделены и применялись как основные два иных подхода:
1. Полуструктурированное текстовое описание визуальных наблюдений с указанием содержащих их анатомических объектов и типов нарушений. В лучевой диагностике вариативность терминологии и структуры описаний результатов исследований, а также ориентировочный характер локализации наблюдений делает крайне сложными и малоэффективными автоматический поиск по таким аннотациям и их применение для обучения или тестирования СИИ.
2. Структурированная аннотация, которая должна использовать согласованный набор терминов для снижения вариабельности интерпретаций визуальных наблюдений. В лучевой диагностике такая аннотация может быть сопровождена конкретизированной информацией о локализации наблюдений, которую могут выполнять с разным уровнем точности и детализации:
— с грубой локализацией — приблизительное обозначение координат объектов интереса, посредством задания ограничивающего параллелепипеда или эллипсоида;
— с полной сегментацией на основе маски минимальных элементов, обозначающей положение объекта интереса на фоне остальной части данных.
В лучевой диагностике целесообразно придерживаться следующей типизации видов разметки:
1. Классификация (общий анализ) — отнесение результатов лучевого исследования к одной из категорий, например, «норма» или «наличие целевой патологии».
2. Детекция или локализация — кластерная разметка, ограничение целевых областей изображения прямоугольниками или иными геометрическими фигурами.
3. Сегментация — выделение целевых областей изображения попиксельной маской.
В целом процесс разметки разделяется на два этапа:
1. Первичная разметка. В ее процессе выполняются отметка и характеризация всех целевых структур в подготовленном НД с формированием структурированной аннотации, шаблон которой определен техническим заданием на набор данных.
Предварительная разметка выполняется врачами, которые соответствуют следующим критериям:
— компетентность в области конкретных типов данных: изображения, текстовые данные или сигнальные (ЭКГ, ЭЭГ, спирометрия и т.д.), количественные данные (ЧСС, артериальное давление, спирометрия и др.), бинарные данные (например, да/нет);
— наличие знаний и навыков, соответствующих уровню сложности планируемой разметки и/или аннотирования: первичная разметка (сегментирование) или экспертная; детализация на уровне классов или подклассов, установление связи с метаданными, определение вероятных исходов (прогнозирования);
— успешное прохождение предварительного тестирования.
1. Экспертная валидация. Выполняется с привлечением экспертной группы врачей-специалистов в целях проверки и корректировки результатов первичной разметки. Выделяют две группы экспертных оценок:
1) индивидуальные оценки, основанные на использовании мнения отдельных экспертов, независимых друг от друга;
2) коллективные оценки, основанные на использовании коллективного мнения экспертов.
Основные этапы обработки экспертных оценок:
— определение компетенции экспертов;
— определение обобщенной оценки;
— построение обобщенной ранжировки объектов в случае нескольких оцениваемых объектов или альтернатив;
— определение зависимостей между ранжировками;
— оценка согласованности мнений экспертов (при отсутствии значимой согласованности экспертов необходимо выявить причины несогласованности (наличие групп) и признать отсутствие согласованного мнения (ничтожные результаты));
— оценка ошибки исследования;
— построение модели свойств объекта (объектов) на основе ответов экспертов (для аналитической экспертизы);
— подготовка отчета (с указанием цели исследования, состава экспертов, полученной оценки и анализа результатов).
В экспертную группу должны входить врачи-специалисты с большим опытом работы с определенным типом наборов данных (видом медицинской информации). Как правило, предъявляют требование к опыту работы от трех лет. Эксперты должны обладать опытом в областях, соответствующих решаемым задачам. При подборе экспертов следует учитывать наличие конфликтов интересов, которые могут стать существенным препятствием для получения объективного суждения.
В рамках Московского эксперимента процесс разметки изначально происходил следующим образом: врач-разметчик просматривал исследование в ЕРИС ЕМИАС и вносил данные в таблицу разметки, используя внешний редактор электронных таблиц. Однако с ростом количества размечаемых показателей этот процесс стал крайне трудозатратным и часто приводил к появлению ошибок ввода. Кроме того, каждое исследование просматривалось 2-мя врачами-разметчиками и валидировались экспертом, что также довольно неудобно при работе с обычными электронными таблицами. Эта проблема решена на «Платформе подготовки наборов данных» путем объединения DICOM-просмотровщика, формы разметки и назначением ролей врача и эксперта (рисунок 2.13).
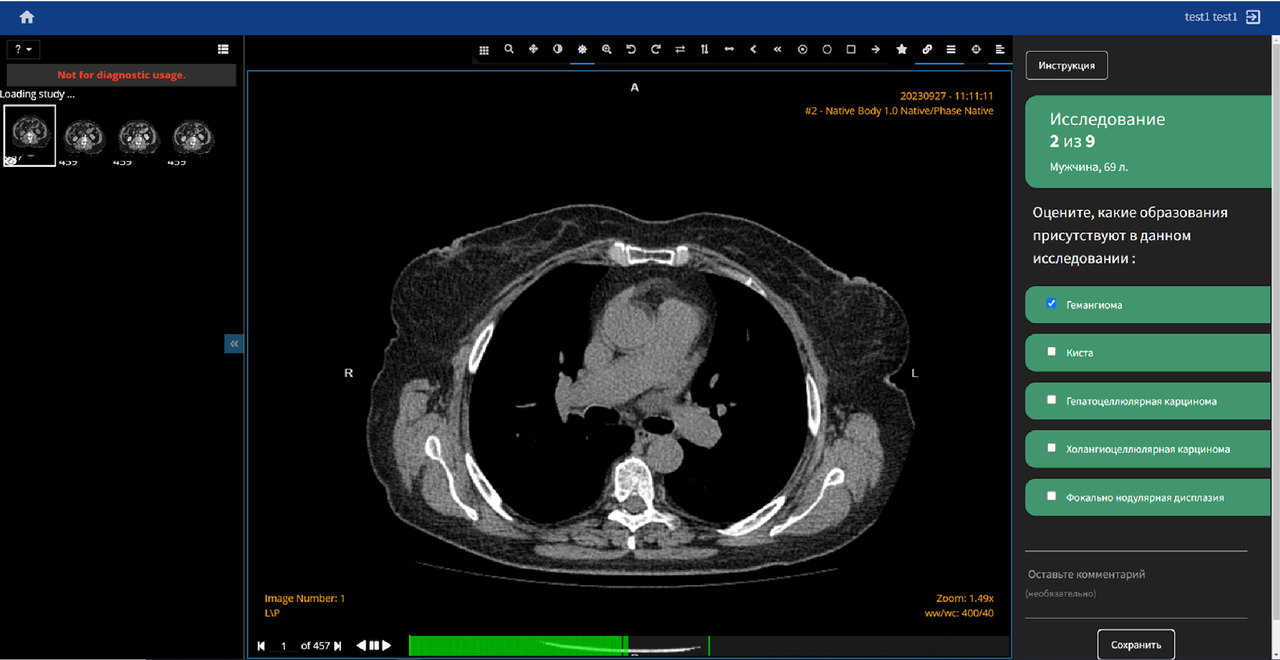
Форма разметки находится в одном окне с просмотровщиком, автоматически переключается при переходе к новому исследованию и имеет гибкие возможности настройки полей и ролей, что способствует снижению ошибок ввода данных и ускорению процесса разметки. Форма создается с помощью специального конструктора (рисунок 2.14), где возможны настройка связей между полями, вид полей (поле для ввода, поля с множественным и единичным выбором), формат данных. Простейший пример так называемой динамической формы — это настройка связи при наличии брака: при выставлении галочки в поле «Брак» дальнейшая часть формы не отображается. Это также дает возможность избежать ряда ошибок и повышает качество создаваемого набора данных. Кроме того, назначение роли «Эксперт» позволяет визуализировать форму с данными разметки от врачей-разметчиков для обеспечения удобной валидации.
Необходимо отметить, что вопросу качества НД уделено максимально внимание, и все создаваемые инструменты этому способствуют. Так был разработан модуль контроля качества для результатов рентгенографии органов грудной клетки. В автоматическом режиме он анализирует DICOM-исследования на предмет нарушений качества проведения исследований (обрезка, ротация, нарушения экспозиции дозы) и заполнения DICOM-тегов.
Структурирование данных. Включает в себя проверку таблиц разметки, балансировку классов и формирование итоговых таблиц разметки. Изначально этот этап проводился аналитиком в полуавтоматическом режиме, однако теперь на «Платформе подготовки наборов данных» основную часть этого этапа, а именно проверку таблиц разметки и формирование итоговых таблиц, «взял на себя» модуль разметки. Теперь правильно сформированная форма разметки делает возможным в автоматическом режиме проводить проверку непосредственно в процессе разметки, не позволяя вводить некорректную информацию.
Формирование файлов с DICOM-изображениями и с разметкой производилось вручную. В таблицах разметки указывалась краткая информация о ее содержимом (название, целевая патология, авторы, год создания, назначение и т.д.). На «Платформе подготовки наборов данных» реализован инструмент, позволяющий формировать и структурировать файлы для тестирований в Московском эксперименте в полуавтоматическом режиме (рисунок 2.15).
Детальная информация об инструментах разметки и их сравнение представлены далее.
Регистрация и публикация. В завершение всех процессов непосредственно по формированию набора данных необходимо обозначить этот момент, а также подготовить сопровождающий readme-файл, который содержит основную информацию о НД и будет храниться вместе с ним. Изначально для readme-файла был разработан специальный шаблон, куда вносилась нужная информация. Однако с учетом того, что readme хранится на двух языках (русском и английском) и в двух форматах (PDF и md), его заполнение занимало много времени. Поэтому был разработан специальный программный код, который формировал документ путем извлечения данных из реестра. Код включен в «Платформу подготовки наборов данных» в виде генератора readme на странице НД (рисунок 2.10б). Он позволяет автоматически сформировать документ на двух языках и визуализирует его в корректируемом виде: можно исправить и сохранить все параметры, которые не соответствуют стандартному шаблону. Этап регистрации заключается во внесении всей информации о наборе в реестр и фиксации статуса «Готов».
Публикация НД осуществляется на закрытых или открытых ресурсах. Закрытые наборы данных НПКЦ ДиТ ДЗМ доступны только сотрудникам, задействованным в Московском эксперименте и научных исследованиях; открытые — опубликованы в библиотеке https://mosmed.ai/datasets/ и доступны всем желающим. Данная библиотека разработана в рамках нормативно-правового регулирования общественных отношений, связанных с развитием и использованием технологий искусственного интеллекта, и обеспечения безопасности применения таких технологий, предусмотренных Национальной стратегией развития искусственного интеллекта до 2030 года. В частности, речь идет об установлении правил создания и предоставления наборов данных, основой которых являются обезличенные медицинские данные, а также создании механизмов их распространения, объединения и обмена для выполнения научных исследований в области искусственного интеллекта. Кроме того, распространение наборов данных соответствует принципу бережливости Национальной стратегии и принципам FAIR (от англ. Findable, Accessible, Interoperable, Reusable — доступные для поиска, доступные к использованию, совместимые, пригодные для повторного использования научные данные).
Библиотека mosmed.ai содержит каталог НД с различными фильтрами для удобного поиска (рисунок 2.16).
Карточка НД также имеет структурированный вид для оптимального поиска исследователем или разработчиком необходимых параметров (рисунок 2.17). При скачивании загружается архив, содержащий медицинские изображения, файл (ы) разметки и readme на двух языках.
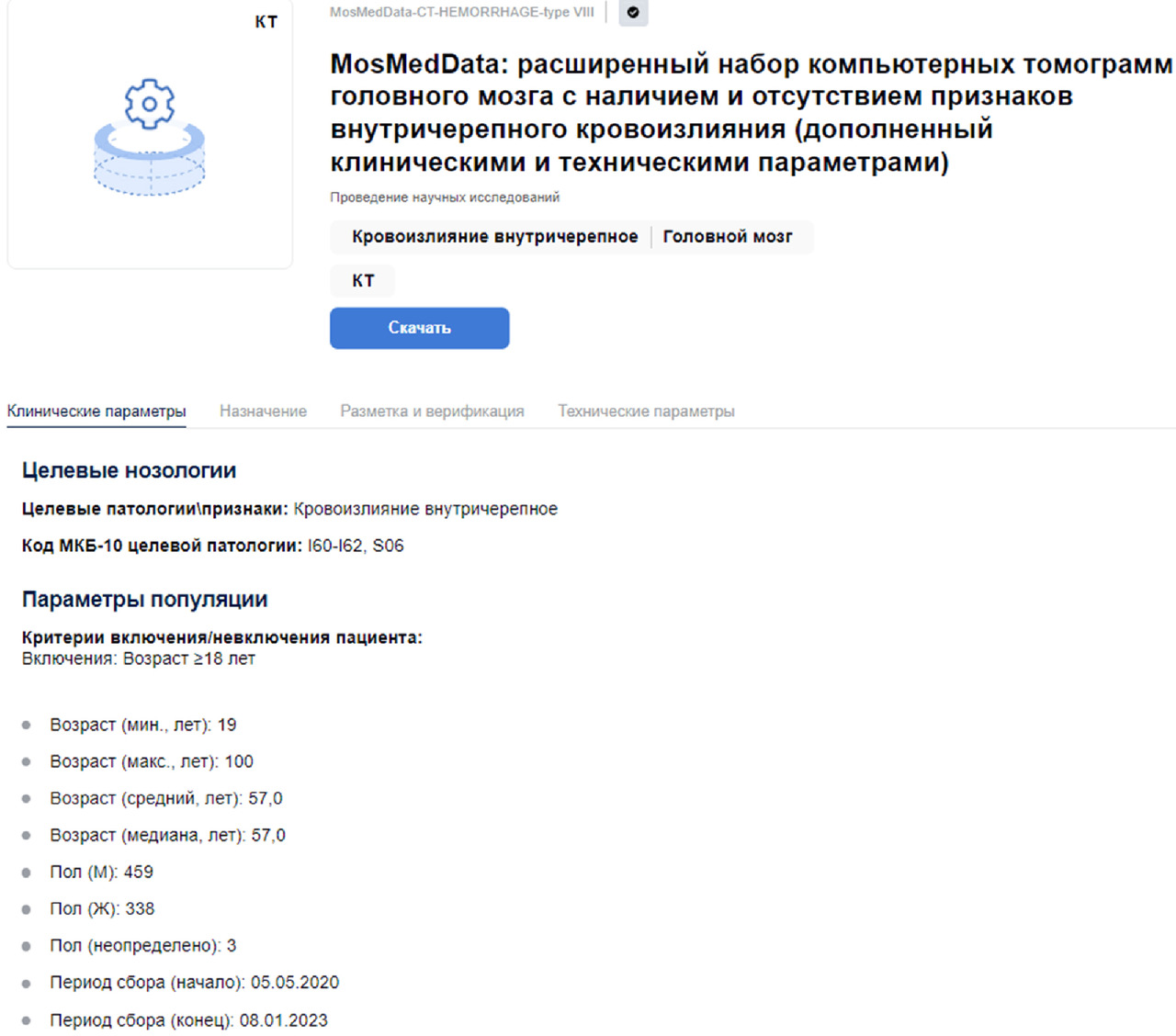
Библиотека содержит различные категории НД, однако наиболее широко в ней представлены «селф-тесты диагностические», то есть наборы данных для самотестирования ИИ-сервисов. Они активно используются в Московском эксперименте, содержат небольшое количество исследований (от 4 до 10) и предназначены для предварительного самостоятельного тестирования разработчиками своих продуктов. Это позволяет выявить и устранить ошибки до момента подачи заявки на участие в Московском эксперименте. Также для самостоятельной оценки функционирования СИИ на различных диагностических устройствах в библиотеке имеются «селф-тесты технические». Научные исследования представлены в библиотеке несколькими наборами данных разных модальностей (КТ, РГ, УЗИ, ММГ, ЭКГ), в частности, имеются 2 набора данных, обогащенных клинической информацией.
Использование. После размещения НД в хранилище и внесении в реестр можно приступать к процессу использования. При этом информацию об использовании также необходимо фиксировать, особенно с учетом большого количества НД, создаваемых в НПКЦ ДиТ ДЗМ, а также их всестороннего использования в соответствии с принципом разумной бережливости (принцип повторного использования). Информация об использовании также хранится в реестре в одноименном разделе. В соответствии с задачами были выделены следующие разделы:
— ссылка на хранение НД;
— актуальная версия для Московского эксперимента;
— научное сотрудничество;
— научная статья;
— доступ для разработчиков;
— ссылка для цитирования;
— статус регистрации РИД.
Кроме того, ввиду проведения большого количества тестирований эта информация также фиксируется в специальном журнале на платформе оценки диагностической точности. Ведение такого рода журналов и реестра позволяет отслеживать процессы использования, возвращаться к данным и протоколам при возникновении вопросов, избегать публикации калибровочных наборов данных в публичном пространстве и, наоборот, открывать доступ к НД, которые уже не используются в тестированиях. Это позволяет оценивать и повышать результативность применения наборов данных (следовательно, ресурсов на их создание) и принимать управленческие решения.
Контроль качества при подготовке набора данных (по ГОСТ Р 59921.5–2022).
Под качеством набора данных понимается его структурированность, однородность, репрезентативность, сбалансированность по классам, отсутствие выпадающих значений, наличие разметки, которая соответствует поставленной задаче, наличие описания модели данных и документации.
В процессе разработки НД целесообразно применять систему менеджмента качества — организационную структуру, функции, процедуры, процессы и ресурсы, необходимые для скоординированной деятельности по руководству и управлению организацией применительно к качеству. Формирование НД должно быть спланировано и подвержено мониторингу и управлению для обеспечения соответствия качества.
Работой группы может руководить сотрудник, назначенный ответственным, который не принимает участие в разметке и/или аннотировании, но будет регулировать срочность, очередность и объем работы между экспертами. Обязанностью данного ответственного также является формирование рабочей группы для обеспечения объективности и достоверности результата.
Должны быть применены методы оценки качества набора данных, по которому будет производиться разметка:
— проверка отсутствия пропусков элементов в наборе данных;
— проверка отсутствия некорректных элементов для решения поставленных задач;
— проверка качества элементов набора данных рекомендованным критериям профессионального медицинского сообщества.
Должны быть подготовлены и внедрены стандартные процедуры применения наборов данных в рамках системы менеджмента качества. Необходимо указать и требования по организации доступа к наборам данных, в том числе реестр лиц, которые получили к нему доступ.
После создания и регистрации набора данных может возникнуть необходимость внести изменения — например, в результате обнаружения ошибок или добавления новых данных. При внесении любых корректировок необходимо документировать изменение версии НД. Эта документация должна быть приложена к набору данных.
2.2.4. Инструменты разметки и работы с данными
В процессе создания сотен наборов данных для решения задач Московского эксперимента, клинических испытаний, собственной разработки ИИ-сервисов и научных задач в НПКЦ ДиТ ДЗМ накоплен практический опыт, позволивший сформировать требования к базовой функциональности программного обеспечения (ПО) для разметки результатов лучевых исследований:
1. Общие характеристики:
— возможность установки ПО на локальных серверах;
— возможность распределенной работы нескольких экспертов над одним набором данных;
— возможность формирования задач экспертам, отслеживания статусов готовности;
— расширяемость ПО, возможность добавления новых модулей.
2. Загрузка и сохранение. Поддерживаемые форматы:
— поддержка основных форматов медицинских изображений;
— возможность загрузки иерархической структуры папок DICOM, загрузки нескольких файлов с сегментациями и исходными изображениями, одновременной работы с несколькими сегментациями;
— возможность просматривать теги DICOM;
— сохранение векторных данных при ручной разметке полилиниями, полигонами и другими фигурами и возможность их дальнейшего изменения.
3. Возможности визуализации медицинских изображений:
— наличие 3D-визуализации исходного изображения и сегментации;
— наличие стандартных окон преобразования из HU-интенсивностей в интенсивность цвета;
— возможность менять расположение окон просмотра;
— возможность менять направления осей проекции;
— возможность управления контрастом (по области, на основе гистограммы интенсивности);
— отображение информации о номере среза, HU-плотности, позиции курсора;
— наличие крестового курсора для ориентации в нескольких проекциях.
4. Ручные и дополнительные инструменты:
— стандартные ручные инструменты, наличие ручных инструментов редактирования в 3D-окне;
— логические операции со слоями сегментации;
— возможность отменить последнее действие;
— определение диапазона интенсивностей по области;
— работа с областью сегментации как с графом (удаление/выделение компоненты/главной компоненты, удаление определенных по размеру компонент);
— сглаживание полученной области (удаление полостей, выпуклостей и др.);
— расширение/сужение области на определенную величину.
5. Полуавтоматические инструменты:
— наиболее эффективные методы — Thresholds, SurfaceCut, Fill between slices, Region Growing 2D, Intelligent Scissors и RITM Interactive.
Существуют три основных подхода к техническому обеспечению разметки результатов лучевых исследований:
1. Применение стандартного DICOM-просмотровщика и электронных таблиц из пакета офисных программ.
2. Применение специального разработанного оригинального программного обеспечения.
3. Применение программного обеспечения с открытым исходным кодом.
Первый подход максимально широко доступен, вместе с тем он имеет ряд принципиальных ограничений:
— позволяет выполнять только самые простые виды разметки (например, фиксировать в таблице координаты очагов или некие размеры);
— возможна только ручная разметка;
— крайне сложно организовать и управлять работой команды врачей-разметчиков.
Второй подход оптимален с точки зрения обеспечения максимально релевантной функциональности. Подобные программные продукты обычно содержат модули собственно разметки с различными инструментами работы с изображениями (измерений, оконтуривания и проч.), управления работой команды (так называемые «оркестраторы»), а также единую базу данных. Возможно проведение как ручной, так и полуавтоматической или автоматической разметки. К ограничениям подхода можно отнести высокие финансовые затраты на разработку собственного решения, сложность масштабирования в силу лицензионных ограничений и изначального создания программного обеспечения для решения узких задач конкретной группы разработчиков СИИ.
Третий подход оптимален с точки зрения баланса сильных и слабых сторон. В настоящее время он приобрел значительную популярность. В силу активного конкурентного развития бесплатное программное обеспечение с открытым исходным кодом зачастую не уступает коммерческому или проприетарному.
Далее приводится описание и специально проведенное сравнение программного обеспечения для разметки результатов лучевых исследований с открытым исходным кодом, впервые опубликованное в статье «Обзор современных средств разметки цифровых диагностических изображений».
Свод характеристик, включенных в обзор программных решений представлен в таблице 2.2.
3D Slicer. Модульный продукт широкого профиля, позволяющий обрабатывать многомерные изображения и обладающий наиболее обширным функционалом, по сравнению с аналогами, в области сегментации, регистрации, фильтрации и других областях обработки медицинских и других биологических изображений.
ITK-SNAP. Программный продукт, специализирующийся на сегментации структур в многомерных диагностических изображениях.
MITK. Программный продукт на основе библиотеки c открытым исходным кодом Medical Imaging Interaction Toolkit.
Medseg. Программный продукт с базовой функциональностью и инструментами ручной разметки. Содержит ряд автоматических и полуавтоматических методов на основе нейронных сетей для сегментации различных органов и некоторых видов патологии.
CVAT. Веб-платформа с открытым исходным кодом для ручной и полуавтоматической разметки изображений и видео. Требует преобразования медицинских изображений в графические форматы.
Supervisely. Коммерческая веб-платформа для осуществления всех этапов обучения моделей компьютерного зрения, включая задачи организации, разметки (аннотации) и аугментации данных, обучения моделей, обеспечения качества и многие другие. Добавлена в обзор для наглядности сравнения (непосредственно в НПКЦ ДиТ ДЗМ данный продукт не применяется).
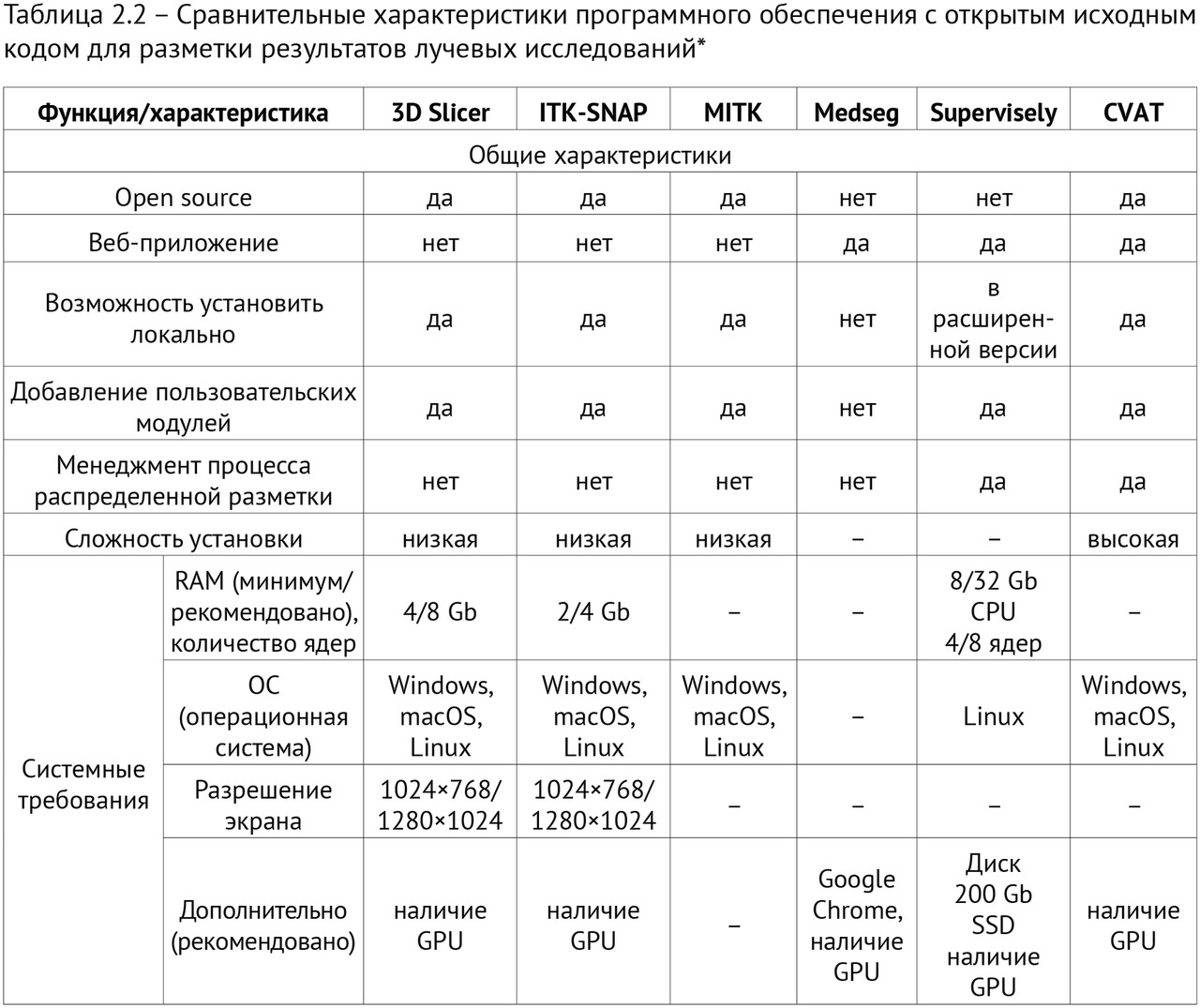
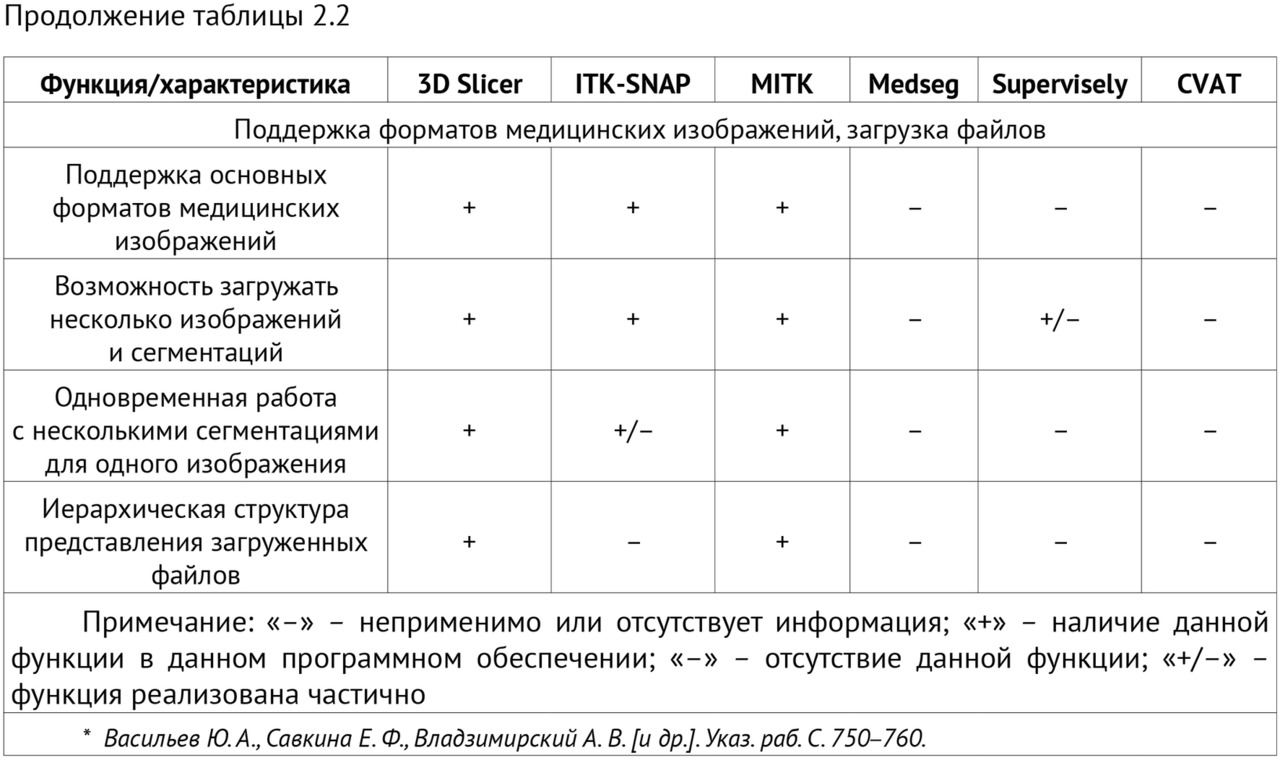
Функционал организации и управления процессом разметки имеется только у CVAT и Supervisely. В частности, CVAT позволяет хранить изображения на локальном сервере и осуществлять распределенную работу нескольких экспертов. У Supervisely присутствует обширная функциональность по управлению, включая экзамены для экспертов по разметке, онлайн-проверки разметки одних экспертов другими, расчет метрик согласованности разметки и др.
Возможностью расширять функциональность и добавлять новые пользовательские модули обладают 3D Slicer, MITK, Supervisely, CVAT; все перечисленные решения снабжены развернутым руководством для программирования и сопроводительной документацией.
В последних версиях ITK-SNAP появилась возможность удаленного подключения к дополнительным сервисам обработки изображений (DDS) и создания собственного сервиса.
Наибольшее разнообразие форматов обрабатываемых исходных изображений и форматов областей сегментации имеется у 3D Slicer. Основные форматы (DICOM, NRRD, NIfTI) и некоторые другие поддерживаются MITK, ITK-SNAP. Supervisely работает только с форматами DICOM, NRRD; Medseg — c форматом NIfTI, DICOM.
На этом фоне CVAT «не умеет» работать с медицинскими изображениями в традиционных форматах, необходимо предварительно конвертировать изображения в графические форматы с помощью поставляемой разработчиками утилиты. Следует отметить, что конвертация медицинских изображений влечет за собой риск неверной интерпретации данных. Например, при преобразовании КТ-изображений в графические форматы происходит потеря точности из-за более узкого диапазона дискретных значений интенсивностей цвета по сравнению с исходным диапазоном, теряется информация о параметрах протокола сканирования и т. д.
Наиболее удобная загрузка файлов реализована в 3D Slicer. Этот модуль поддерживает загрузку нескольких сегментаций и изображений в различных форматах, а также изображений формата DICOM из иерархической структуры папок. В MITK и 3D Slicer загруженные файлы представлены в виде иерархической структуры, отображающей связь между сегментациями и исходными изображениями.
Можно гибко менять видимость различных изображений и сегментаций в окне просмотра, сравнивать несколько сегментаций между собой. Дополнительно в 3D Slicer существует возможность просматривать и синхронизировать несколько серий изображений одновременно.
Относительно представления и сохранения данных сегментации следует сказать, что у MITK, 3D Slicer и Medseg каждая сегментация представлена слоями для каждого класса разметки. В CVAT и Supervisely принципиально другое представление разметки — в виде объектов: полигонов, прямоугольников, растровых объектов и др. В CVAT объекты сгруппированы по изображениям, к которым они относятся. В Supervisely формируются классы разметки на основе различных типов (прямоугольник, полигон, маска, любая форма). Создаются объекты на основе классов разметки, включающие фигуры только указанного типа. Благодаря такой структуре в CVAT и Supervisely полигоны и другие векторные фигуры можно редактировать после создания.
Сохранение разметки удобно реализовано в 3D Slicer. Можно выборочно сохранять произвольные наборы исходных изображений и областей сегментации в отличие от другого ПО (MITK, ITK-SNAP), где можно сохранить или все рабочее пространство, или каждую сегментацию по отдельности. В Supervisely и СVAT присутствует возможность сохранения векторных объектов в векторном виде для последующей коррекции, что делает данное ПО объектом выбора, когда разметка требует сохранения векторной информации для полигонов, прямоугольников, например, в случае аннотаций прямоугольниками для задачи детекции.
Отдельный вопрос — возможности визуализации медицинских изображений в программном обеспечении для разметки. Для определения минимальной функциональности проведен специальный опрос врачей-рентгенологов, участвующих в разметке наборов данных, и трех специалистов по подготовке наборов данных НПКЦ ДиТ ДЗМ. Решение о включении каждой из функций в анализ принимали на основании большинства голосов опрошенных экспертов (таблица 2.3).

CVAT не обладает средствами визуализации медицинских изображений, так как работает уже с графическими форматами. Возможность 3D-отображения исходного изображения есть только в MITK, ITK-SNAP и 3D Slicer. Наличие настраиваемых и стандартных окон преобразования HU-интенсивностей в интенсивности цвета есть в большинстве программ, кроме ITK-SNAP, где контрастность и окно преобразования настраиваются по гистограмме HU-интенсивности. В 3D Slicer доступна автонастройка контраста по выбираемому региону.
Инструменты ручной сегментации и дополнительные возможности корректировки области сегментации в целом идентичны в различных программах. В CVAT, Supervisely доступна посткоррекция вручную созданных векторных объектов. В 3D Slicer есть удобная возможность редактировать области сегментации в 3D-окне, а также инструмент «Ножницы», позволяющий вырезать подпространства, ограниченные цилиндрической поверхностью в срезах и в 3D-окне.
В 3D Slicer, а также в MITK существует множество дополнительных инструментов для коррекции сформированной области сегментации: логические операции со слоями, расширение/сужение области сегментации на некоторую величину, работа с областями как с элементами графа (выделение главной компоненты, удаление маленьких по размеру компонент, выделение/удаление выбранной компоненты), сглаживание различными методами (заливка полостей, удаление выпуклостей и др.).
Инструменты полуавтоматической сегментации. Полуавтоматическая сегментация служит одной из самых важных частей ПО для разметки. Она предполагает ввод определенных данных человеком, например, области интереса или ключевых точек, либо требует дополнительной ручной настройки параметров. Алгоритмы, лежащие в основе полуавтоматических методов, способны реализовать различные подходы. Это могут быть классические подходы или же подходы на основе методов машинного обучения (нейронные сети, классические алгоритмы машинного обучения).
Автоматическая сегментация. Только небольшая часть рассмотренного ПО (3D Slicer, Medseg) содержит готовые модули для автоматической сегментации. Большинство модулей являются моделями глубокого обучения и связаны с сегментацией различных органов. Так, например, в 3D Slicer есть плагины по сегментации височной кости, дыхательных путей, опухолей молочной железы, печени и ее сосудов, других сосудов, мозга, сердца и других структур по КТ/МРТ-изображениям. В программе Medseg есть модели, сегментирующие легкие, печень, почки, поджелудочную железу и другие органы, и виды патологии по КТ/МРТ-снимкам. Недостаток Medseg, ограничивающий возможность применения моделей, — невозможность локальной установки.
Проведенный обзор может быть использован при принятии решений относительно выбора программного обеспечения с открытым исходным кодом для разметки результатов лучевых исследований.
2.2.5. Специальные и перспективные наборы данных
Сложные наборы данных. Любому практикующему врачу знакомо выражение «студенческий случай», означающее проявление данного заболевания в максимальном соответствии классическому его описанию. В этой ситуации семиотика и симптоматика настолько типичны, что требуются лишь элементарные знания в предметной области для точной диагностики. Вместе с тем в реальной медицинской практике такие случаи не слишком распространены, чаще всего врач вынужден проводить сложный аналитический процесс и глубокую дифференциальную диагностику. Подавляющее большинство современных медицинских СИИ обучают именно на «студенческих случаях». С одной стороны, это представляет собой закономерный этап развития, с другой — создает значительные ограничения для масштабирования применения соответствующих технологий. Требуется создание наборов данных, содержащих клинические случаи со сложными, нетипичными, неочевидными проявлениями патологического процесса. В НПКЦ ДиТ ДЗМ ведутся соответствующие научные исследования.
Морфометрические наборы данных. В контексте расширения возможностей СИИ и использования их не только в качестве классификаторов важнейшую роль играет морфометрия (автоматизация рутинных измерений). Будучи весьма перспективным, это направление одновременно является и одним из наименее изученных: в мировой практике крайне мало опыта по применению таких технологий, а обоснованные методики подготовки НД и тестирования ИИ-сервисов вовсе отсутствуют. Тем более сложной и вместе с тем интересной становится задача подготовки морфометрических наборов данных. Среди нерешенных вопросов — оценка выбросов в измерениях, обоснование количества разметчиков и стратегии разметки данных, стандартизация методик измерений, стратегии применения морфометрии. Данное направление появилось в Московском эксперименте в конце 2023 года, и на сегодняшний день немногие ИИ-сервисы смогли решить отдельные задачи измерения анатомических структур. Методологии создания морфометрических наборов данных и оценки качества соответствующих ИИ-сервисов — предмет текущих научных исследований НПКЦ ДиТ ДЗМ.
Обогащенные наборы данных. Обогащенные клинической информацией наборы данных — одно из перспективных направлений развития СИИ, потенциально реализующих типичный именно для практического здравоохранения комплексный подход к диагностике заболеваний. Объединение максимально возможного количества данных из медицинской документации пациента может не только расширить возможности диагностики и прогнозирования течения заболевания, но и позволит искать новые зависимости, совершать открытия в области медицины и развивать профилактическое направление. Основные препятствия при создании обогащенных НД: неструктурированное представление информации в медицинской документации; ограничение доступа к документации, сформированной в разных медицинских организациях; отсутствие единых стандартов, в том числе в части терминологии, величин измерений и т. д. Благодаря наличию и возможностям ЕРИС ЕМИАС перечисленные препятствия медленно, но верно преодолеваются. Разработаны стратегии (создание НД «с нуля» или обогащение уже готового набора изображений) и подходы к определению объема выборки, уточнены особенности работы с литературой и медицинской информационной системой при выборе и внесении клинических параметров. Научно-практическая работа в данном направлении активно продолжается. Обеспечивается автоматизация процессов работы с клиническими данными, ведется совершенствование алгоритмов работы с неструктурированными данными, разработка методик сбора и обработки данных и т. д.
Динамические наборы данных. Оценка динамических изменений в состоянии здоровья пациента по результатам серии лучевых исследований — актуальная и весьма распространенная практическая задача. Для ее решения с помощью СИИ требуются специальные динамические НД, отражающие, например, рост новообразований, прогрессирование демиелинизации, течение репаративных процессов и т. д. Практическое развитие соответствующих ИИ-сервисов сталкивается с проблемами технического характера на этапе организации их работы с действующими информационными системами в сфере здравоохранения. Эти проблемы еще предстоит решить. В рамках решения методологических задач в НПКЦ ДиТ ДЗМ ведутся научные исследования по анализу ошибок в динамическом ряду изображений, а также осуществляется доработка программы «Платформа подготовки наборов данных» для поиска и сбора данных в динамике. Представляет значительный интерес комбинация динамических и обогащенных наборов данных.
Наборы данных для оценки технического качества. Автоматизация оценки качества результатов лучевых исследований актуальна для двух направлений:
1. Непрерывное повышение качества работы рентгенолаборантов (в том числе путем выявления типичных ошибок при выполнении исследования, определения и устранения их причин), устранение необходимости повторных исследований одного и того же пациента с соответствующим снижением затрат и недопущением конфликтных ситуаций.
2. Снижение числа ложных срабатываний СИИ путем предварительной оценки и исключения из анализа результатов исследований, выполненных с технологическими дефектами. К нарушениям технического качества относятся некорректные DICOM-теги, нарушения укладки, инородные тела, нарушения экспозиции дозы, «обрезка» областей изображения, артефакты различного происхождения и проч. Перспективно формирование соответствующих наборов данных по видам исследований и анатомическим областям.
«Умение» ИИ-сервисов обнаруживать исследования с дефектами и исключать их из анализа обязательно проверяется в рамках Московского эксперимента. Случаи с техническими дефектами обязательно входят в наборы данных, применяемые для функционального тестирования (см. параграф 2.6). В НПКЦ ДиТ ДЗМ разработан оригинальный ИИ-сервис для анализа технологического качества результатов рентгенографии органов грудной клетки. Очевидно, что создание и тестирование этого инструмента потребовало формирования соответствующего набора данных. ИИ-сервис интегрирован в программу «Платформа подготовки наборов данных» для внутреннего контроля качества создаваемых НД, а также тестируется в рамках пилотного проекта в медицинских организациях г. Москвы.
Синтетические наборы данных. В настоящее время генеративный ИИ рассматривается как универсальное средство синтеза необходимых визуальных данных.
Большие генеративные модели — модели искусственного интеллекта, способные интерпретировать (предоставлять информацию на основании запросов, например, об объектах на изображении или о проанализированном тексте) и создавать мультимодальные данные (тексты, изображения, видеоматериалы и тому подобное) на уровне, сопоставимом с результатами интеллектуальной деятельности человека или превосходящем их.
В глобальной перспективе методы и инструменты синтеза результатов лучевых исследований и связанных с ними данных потенциально позволяют:
— генерировать новые изображения для обогащения наборов данных;
— создавать дополнительные изображения других модальностей: КТ из МРТ, ПЭТ из МРТ, контрастно-усиленные исследования из бесконтрастных;
— улучшить качество изображений путем шумоподавления, удаления артефактов и реконструкции изображений;
— предсказывать динамику патологии.
Проблематика синтетических наборов данных в текущий момент времени рассматривается преимущественно в рамках сугубо научных исследований. В подавляющем большинстве таковых в качестве визуальной генеративной модели применяются генеративно-состязательные сети — GAN (от англ. Generative adversarial network). GAN состоят из двух противоборствующих сверточных сетей: генератора, который пытается сгенерировать реалистичные изображения, и дискриминатора, который определяет, является ли изображение реальным или синтетическим. Именно данный подход применяется в указанных выше научных исследованиях. Вместе с тем известны общие недостатки GAN-подхода. Во-первых, для GAN, как и для ИИ в целом, характерна зависимость результата от качества и объема обучающих данных. Во-вторых, для GAN-моделей актуальна проблема сходимости и коллапса модели, вызывающих появление одного и того же результата при различных входных данных. В рамках проведения научно-исследовательских и опытно-конструкторских работ научным коллективом НПКЦ ДиТ ДЗМ был разработан подход к синтезу бесконтрастных КТ-изображений сосудов из контрастно-усиленной фазы КТ-ангиографического исследования. В качестве решения предложен альтернативный подход к преобразованию размеченных контрастированных КТ-изображений в бесконтрастные с сохранением корректной экспертной разметки. Разработанное для данных целей программное обеспечение не использует машинное обучение и основано на специально разработанном математическом алгоритме подавления контрастирования. Разработанный подход позволяет подавлять контраст-индуцированную детерминированную компоненту сигнала рентгеновской плотности в области брюшного отдела аорты на КТ-изображениях; получать КТ-изображения брюшного отдела аорты, статистически значимо не отличающегося от окружающих мышечных тканей по величине рентгеновской плотности. Главным отличием предложенного подхода от существующих решений является то, что предложенный подход не использует методы синтетической генерации и машинного обучения. Разработанный алгоритм основан на математическом анализе исходных данных, используемая модель позволяет выделить детерминированную компоненту сигнала рентгеновской плотности, что дает возможность получать исходные данные бесконтрастной фазы вместо их синтетической генерации. Таким образом, создание бесконтрастных изображений происходит автоматически и лишено характерных для GAN-подхода недостатков.
Синтетические наборы данных, несомненно, относятся к перспективным и требуют дальнейшего научного изучения. Многие аспекты их создания и применения при обучении СИИ сталкиваются с серьезными ограничениями, включающими вопросы качества и правдоподобия, этики, безопасности, применимости. В последнее время особое значение приобретает возможность генерировать новые изображения для обогащения наборов данных. По мере развития СИИ в задачи для автоматизированного анализа включается выявление патологии с низкой и крайне низкой распространенностью в популяции. Даже на фоне существования колоссальных централизованных архивов медицинских изображений, как, например, московский ЕРИС ЕМИАС, формирование набора данных из сотен и тысяч случаев конкретного редкого заболевания представляет собой трудноразрешимую задачу. Также крайне проблематично сформировать сбалансированный, например, по полу и возрасту, набор данных из случаев редкого патологического состояния. Дальнейшее научно-практическое развитие синтетических наборов данных потенциально позволит устранить этот барьер.
2.3. Математические и статистические методы при оценке качества систем искусственного интеллекта: проблемные вопросы, унификация подходов
2.3.1. Определение размера выборки при формировании набора данных
Наборы данных формируют для обучения и тестирования СИИ на этапах жизненного цикла. В процессе разработки обычно используют один или несколько наборов данных, которые делят на обучающую, тестовую и в некоторых случаях проверочную выборки. Важно, чтобы тестирование СИИ проводилось на наборе данных, не использовавшемся для обучения. Это позволяет исключить явление переобучения, при котором в итоге тестирования получается смещенная оценка. Обучающая и тестовая выборки должны быть независимы для получения несмещенной оценки при тестировании СИИ. В некоторых случаях используют проверочный набор данных для выбора оптимальной модели в процессе разработки СИИ.
В общем виде под обучающей выборкой понимают такую, по которой производится настройка (оптимизация) параметров СИИ; под проверочной — предназначенную для проверки применимости параметров системы искусственного интеллекта для отличных от обучающей выборки наборов данных. Тестовая или контрольная выборка — это полностью уникальная выборка, на которой проводят объективную оценку качества параметров обученной системы искусственного интеллекта.
Известный афоризм гласит, что данные — это топливо для искусственного интеллекта. Однако объемы этого топлива отнюдь не безграничны. В реальной практике разработки, тестирования и эксплуатации СИИ необходимы обоснованные подходы для оценки размеров наборов данных.
Согласно ГОСТ Р 59921.5–2022 размер выборки для обучения или тестирования СИИ определяется целью его применения и зависит от следующих факторов:
— требуемое качество решений СИИ;
— тип и архитектура алгоритма СИИ;
— количество параметров алгоритма СИИ;
— качество данных, включая качество аннотаций, распределение метрик и уровень шума в наборе данных.
В данном контексте необходимо упомянуть такую характеристику набора данных, как размерность. Под ней понимают количество атрибутов, которые имеют объекты в НД (например, диаметр магистрального сосуда, объем кровоизлияния, значение артериального давления и др.). Высокая размерность выдвигает повышенные требования к алгоритмам СИИ, допустимому размеру НД, а также к вычислительным ресурсам для их обработки. В ряде случаев допустимо обоснованное снижение размерности НД, в частности за счет кластеризации данных либо группировки взаимосвязанных по какому-либо признаку атрибутов в объединенные категории.
Длительное время обоснования оценки необходимого и достаточного размера набора данных (НД) для обучения и тестирования СИИ находились на стадии разработки. Применялись автоматизированные средства расчета на основе ширины 95% доверительного интервала и допустимой ширины определения метрик. Известен эмпирический метод, согласно которому размер набора данных должен в несколько раз превышать количество параметров алгоритма СИИ либо соответствовать другим обоснованным критериям. Такая ситуация не соответствовала уровню качества научных исследований, установленному для Московского эксперимента, поэтому были проведены оригинальные изыскания для обоснования и создания объективных методов определения размера набора данных.
2.3.2. Статистические подходы для известной доли значений качественного признака (цитируется по оригинальной статье авторов)
Первые предложенные в рамках Московского эксперимента подходы к формированию выборки применялись к НД, используемым для мониторинга (ретроспективного контроля качества результатов работы ИИ-сервисов). Они соответствовали принципам математической статистики и основывались на известной вероятности технологического дефекта в генеральной совокупности, равной 10%. Объем генеральной совокупности при этом принимался в пределах от 1000 до 100 000 исследований.
В рамках следующих подходов проводилась серийная бесповторная выборка, которая характеризовалась тем, что выбранная единица отбиралась из всего объема генеральной совокупности и не возвращалась обратно.
1. Подход, основанный на точечной статистической оценке. Данный подход учитывает отклонение результатов выборочного исследования от генеральных значений (2.1):
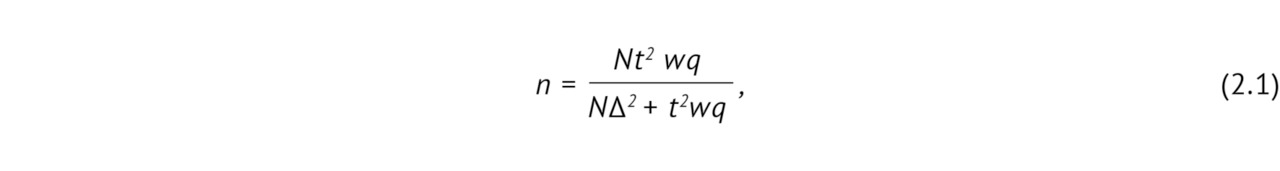
где n — объем выборки; N — объем генеральной совокупности; t — коэффициент, показывающий, с какой вероятностью (надежностью) можно гарантировать достоверность полученного результата или критическое значение критерия Стьюдента при соответствующем уровне значимости (для уровня значимости 0,05 коэффициент); Δ — предельная ошибка показателя; w — доля изучаемого признака; q = (1 — w) — доля, где изучаемый признак отсутствует.
Таким образом, при доле изучаемого признака (w) 0,9, уровне статистической значимости 0,95 и предельно допустимой ошибке (Δ) 0,05 был получен объем выборки (n), равный 138.
2. Подход, основанный на проверке статистических гипотез (вариант 1). Подход предполагает проверку статистической гипотезы H0 (исследования формируемого НД удовлетворяют предъявляемым требованиям) при наличии альтернативной гипотезы H1 (исследования формируемого НД не соответствуют предъявляемым требованиям). Если среди исследований число дефектных (m) не превышает приемочное число (m ≤ с) (максимально допустимое количество технических дефектов среди выборки), то НД принимается; в противном случае — бракуется. Для выбора плана контроля (определения выборки) используется формула (2.2):
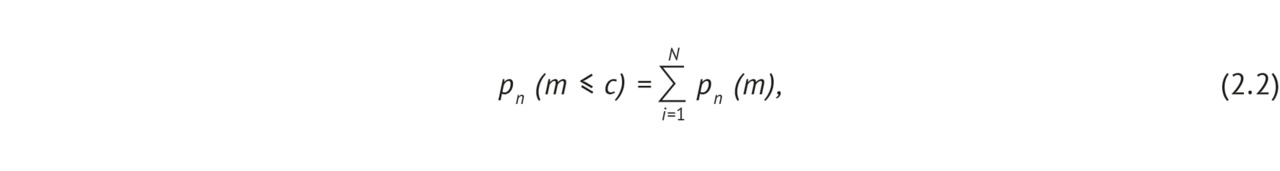
где m — число дефектных единиц продукции в выборке n; pn (m) — вероятность появления дефектных единиц продукции m в выборке n; c — приемочное число.
Так как в рамках Московского эксперимента объем генеральной совокупности превышал объем выборки более чем на 10%, то оперативные характеристики определяли по формуле (2.3):
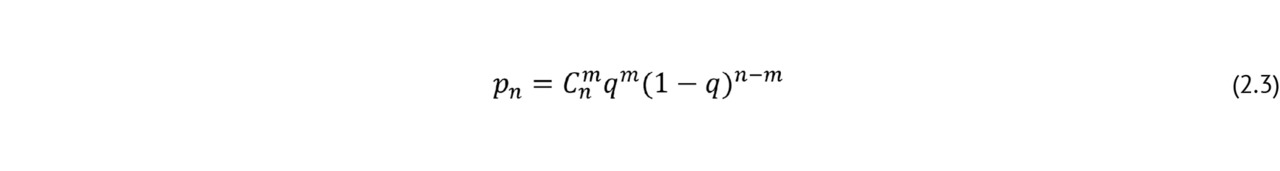
где Cnm — количество сочетаний появления дефектных единиц продукции m в выборке n (2.4):
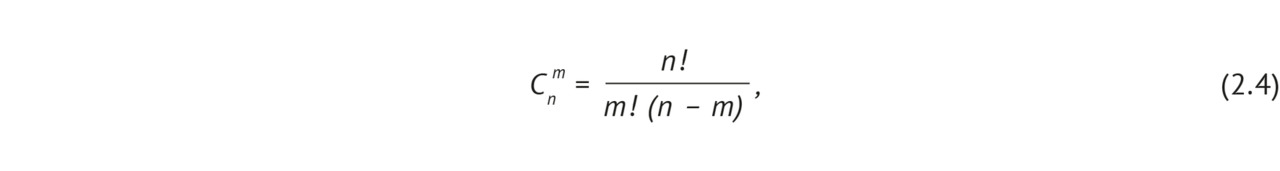
На примере Московского эксперимента было использовано приемочное число, равное двум единицам продукции, произведены расчеты и построены кривые для выборок в 30, 50, 80, 138 единиц продукции. На рисунке 2.18 обозначены следующие риски:
— вероятность отклонить генеральную совокупность исследований при ее хорошем качестве (т.е. в генеральной совокупности удельный вес дефектных единиц продукции менее 10%) — учитывая долю заявленных дефектных исследований от ИИ-сервиса, риск принимаем равным 1%;
— вероятность принять генеральную совокупность при ее низком качестве — учитывая долю дефектных изделий, определенных валидатором ПО с ТИИ (в данном случае — валидатором является ГБУЗ НПКЦ ДиТ ДЗМ), риск принимаем равным 10%.
Анализируя данные таблицы 2.5 и учитывая описанные выше риски на уровне не более 10% и не более 5% соответственно, установили, что объем выборки, равный 80, удовлетворяет требованиям как со стороны ИИ-сервиса, так и валидатора.
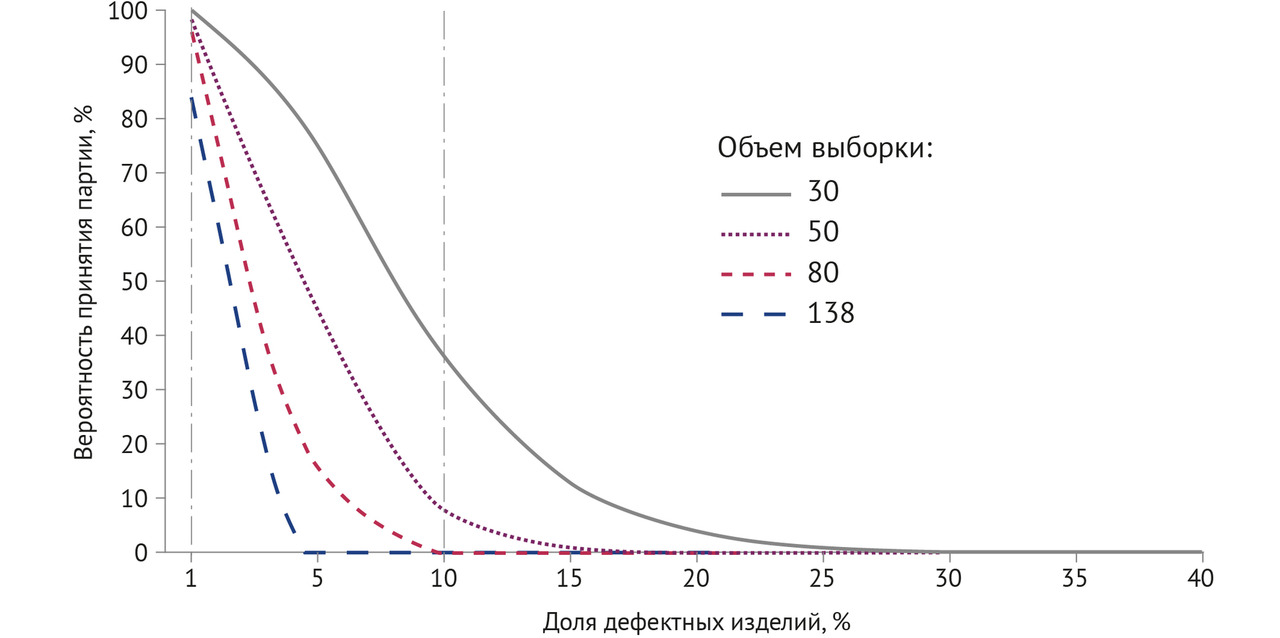
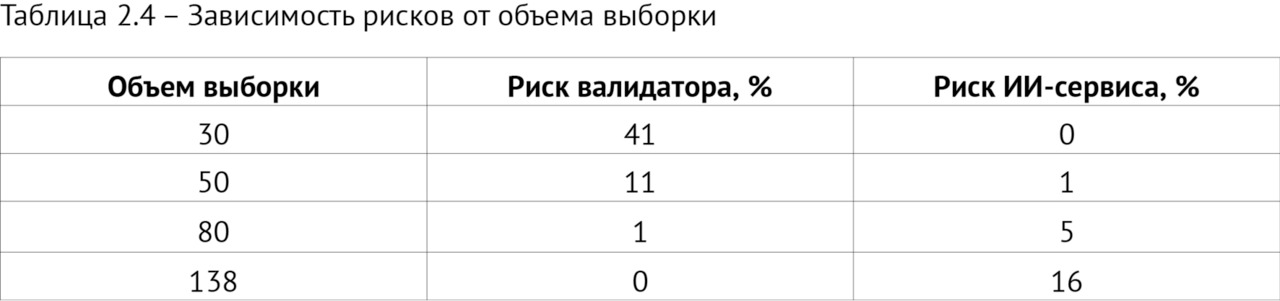
3. Подход, основанный на проверке статистических гипотез (вариант 2). Данный подход базируется на принципах вероятности отклонения нулевой гипотезы; учитывает риски обеих сторон. Нулевая гипотеза H0 предполагает, что если в генеральной совокупности содержится более 10% дефектных исследований, то генеральная совокупность за отчетный период содержит более 10% исследований с технологическими дефектами. Соответственно, при альтернативной гипотезе H1 — менее 10% исследований с технологическими дефектами. Вероятность отклонения нулевой гипотезы — не менее 80%.
Выполнены расчеты (таблица 2.5) для выборок в 30, 50, 80, 120 исследований с приемочным числом от нуля до четырех (приемочное число ограничивалось превышением рисков валидатора более 10% или ИИ-сервиса — более 5%).
Анализируя данные таблицы 2.6 и учитывая заданные риски, а также долю заявленных дефектных исследований от ИИ-сервиса (1%) и долю дефектных исследований, определенных валидатором (10%), установили, что объем выборки, равный 30, 50, 80 и 120 единиц продукции, удовлетворяет требованиям обеих сторон при приемочном числе, равном нулю. С учетом доли дефектных исследований при приемочных числах больше нуля наиболее подходящие объемы выборок равнялись 80 или 120 единицам.
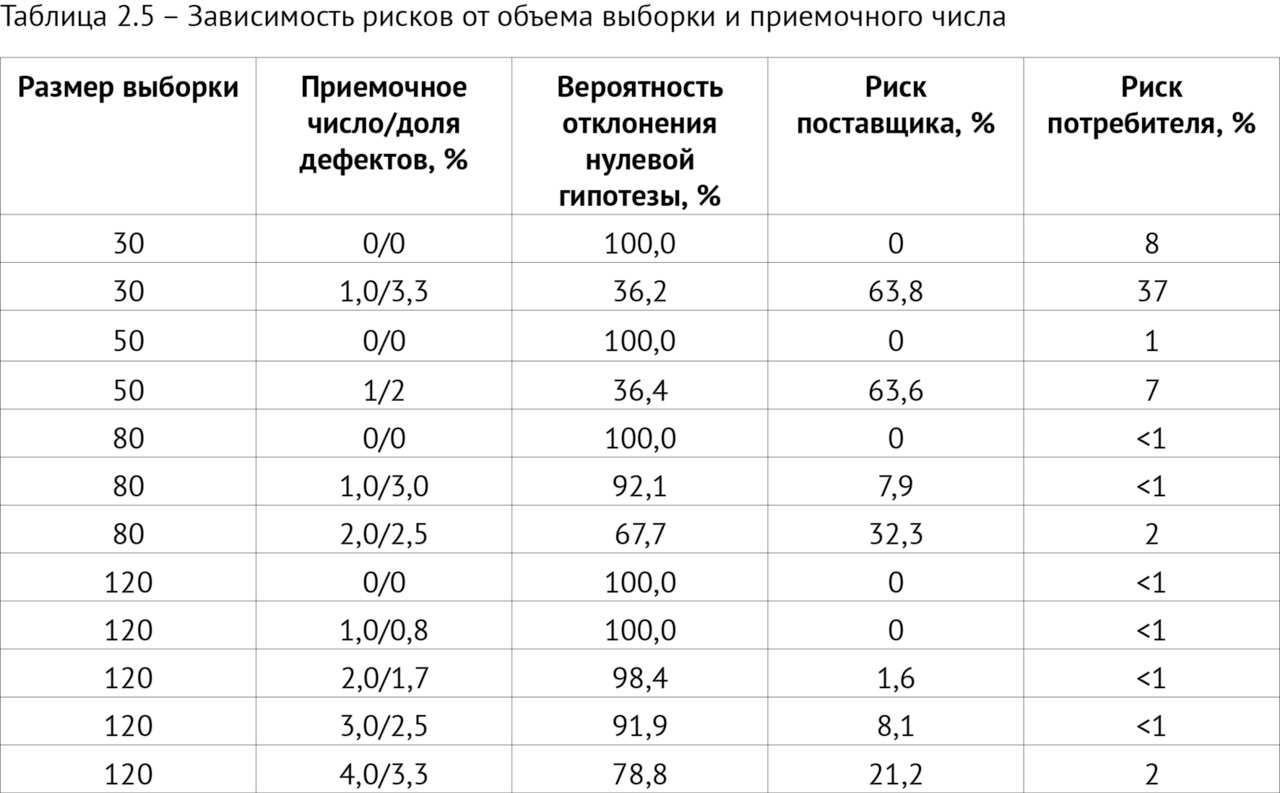
4. Подход, основанный на применении ГОСТ Р ИСО 2859-1-2007. ГОСТ Р ИСО 2859-1-2007 «Статистические методы, процедуры выборочного контроля по альтернативному признаку» устанавливает процедуру выборочного контроля по альтернативному признаку для штучной продукции на основе приемлемого уровня качества. Приемлемый уровень качества выражается в проценте несоответствующих единиц продукции или числе несоответствий на сто единиц продукции. Было рассмотрено несколько вариантов формирования объемов выборок. Сначала была использована таблица «Коды объема выборки» из указанного ГОСТ Р. В рассматриваемом случае общий уровень контроля равен II, специальный уровень контроля не используется. Так как объемы генеральной совокупности (партии в контексте ГОСТ Р) находились в пределах от 1000 до 100 000, то интерес представляли следующие коды: J, K, L, M. В то же время план не имел многоступенчатости и не подразумевал переход на ослабленный или усиленный контроль. В связи с этим были использованы данные из таблицы «Одноступенчатые планы при нормальном контроле (основная таблица)»: для приемлемого уровня качества потребителя в 10% (для партий объемом от 501 до 10 000 исследований) объем выборки для контроля качества будет равен 125 единицам продукции с приемочным числом партии, равным нулю; для партий объемом от 10 001 до 150 000 объем выборки для контроля качества будет равен 500 единицам продукции с приемочным числом партии, равным единице. При обращении к таблице «Риск изготовителя при нормальном контроле (процент непринятых партий для одноступенчатых планов)» были получены риски поставщика 11,8% для выборки в 125 единиц продукции; 9,02% — для выборки в 500 единиц.
В таблице 2.6 приведена сводная информация о сильных и слабых сторонах рассматриваемых подходов.
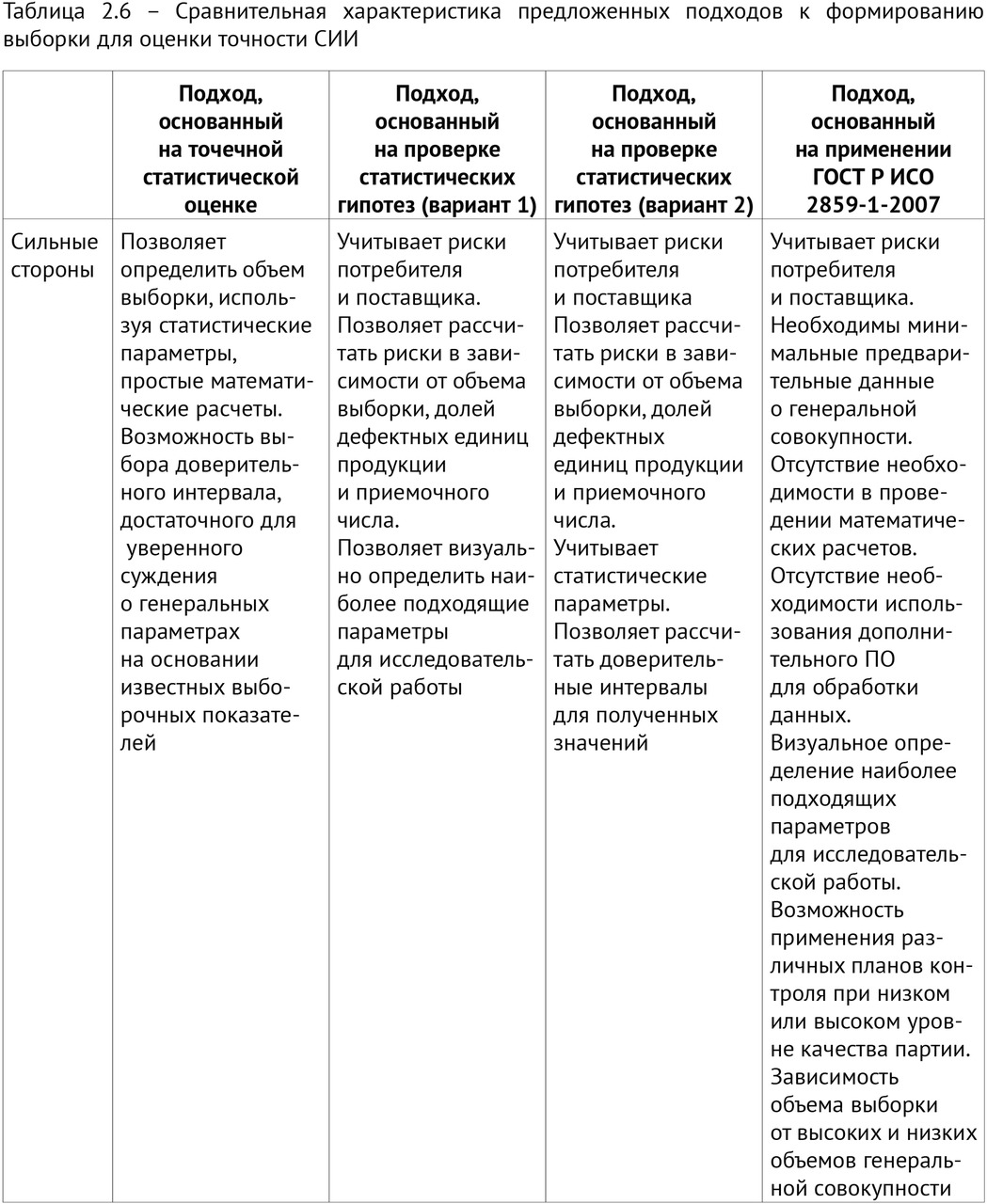
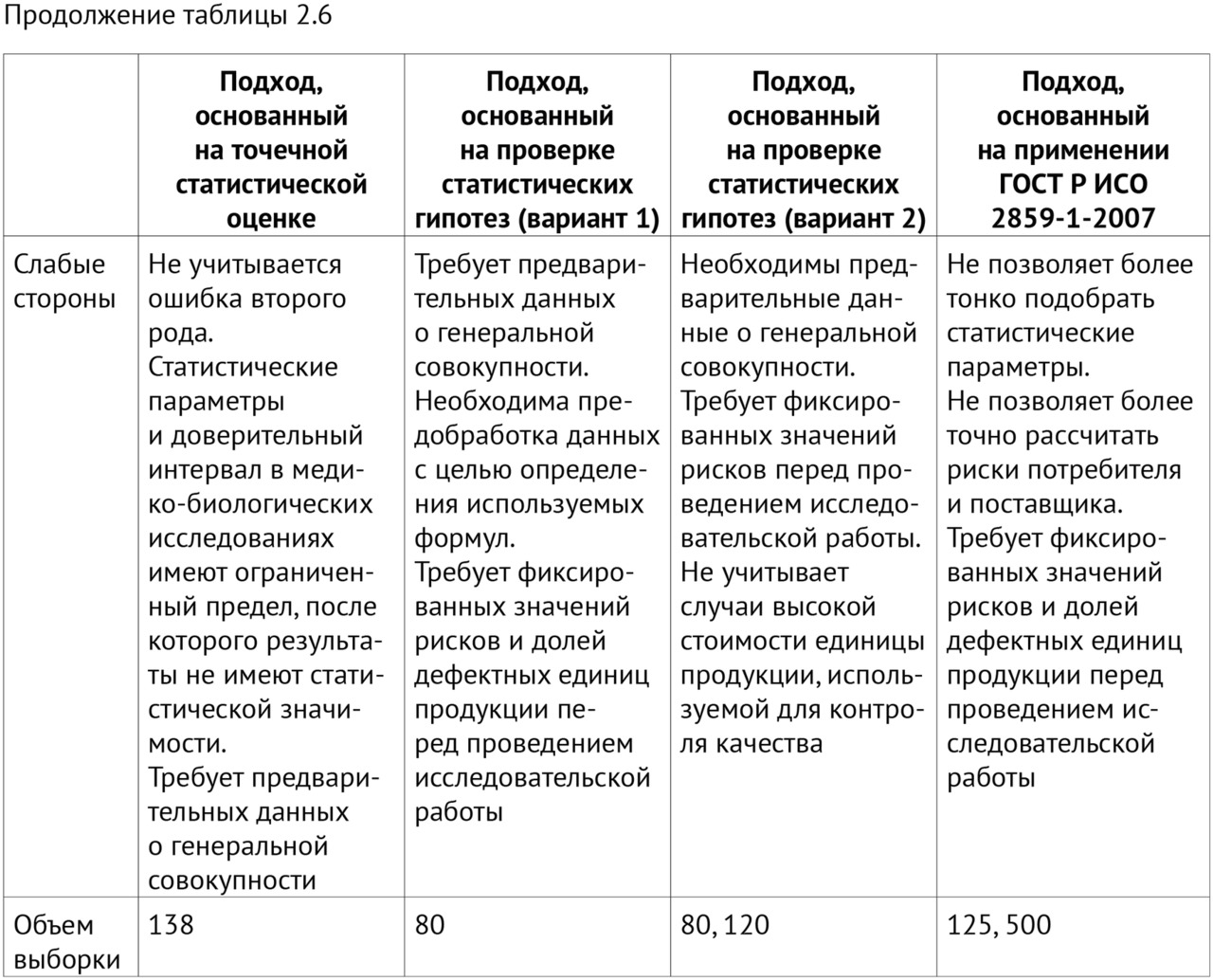
Таким образом, на данном этапе были разработаны несколько подходов для определения достаточной мощности НД для проведения мониторинга ПО с ТИИ. Использование точечной статистической оценки и подхода, основанного на проверке статистических гипотез, позволяет наиболее гибко рассчитать объемы выборки в зависимости от входных параметров проводимого исследования. Применение ГОСТ Р ИСО 2859-1-2007 для формирования выборки является приоритетным, если эксперимент затрагивает взаимодействие исследователя и сторонней организации; позволяет учитывать риски и ошибки для обеих сторон, вовлеченных в процесс.
Оптимальное количество исследований при проведении контроля качества работы изучаемых нами ТИИ для анализа медицинских изображений составляет 80 единиц. Это удовлетворяет требованиям репрезентативности, баланса рисков потребителя и поставщика услуг ТИИ, а также оптимизации трудозатрат сотрудников, вовлеченных в процесс контроля качества результатов работы ТИИ.
2.3.3. Аналитический подход с использованием ROC-анализа (цитируется по оригинальной статье авторов)
В ходе Московского эксперимента проведено исследование подходов к определению количества исследований, необходимых и достаточных для НД, который предназначен для проведения внешней валидации ИИ-сервисов (калибровочного тестирования) с учетом баланса классов «норма»/«патология».
Для этого использовались анонимизированные уникальные результаты 123 301 маммографии, полученные из ЕРИС ЕМИАС. Исследования классифицировались по наличию и отсутствию злокачественного новообразования (ЗНО) молочной железы. Анализировались выставленные значения по шкале Bi-RADS: 0 — в случае определения врачом 1-го или 2-го класса BI-RADS («норма») и 1 — в случае классов BI-RADS 3, 4, 5 («патология»). Изначально баланс классов составлял: «норма» — 89,3%/ «патология» — 10,7%.
Производилась оценка результатов работы СИИ, в качестве которого выступал один из сервисов искусственного интеллекта по направлению «маммография», участвующий в эксперименте. Валидация проходила в несколько этапов. На первом этапе данные были разделены на две группы — «норма» и «патология». Из разделенных данных случайным образом формировались выборки с балансом классов «норма»/«патология», содержащие «патологию» в количестве 50%, 40%, 30%, 20%, 10%. Минимальная выборка, сформированная случайным образом, содержала 30 исследований, далее размер выборки увеличивался с шагом 10, с учетом сохранения доли «патологии». Максимальный возможный объем изучаемой выборки составлял 26 386 (количество исследований с патологией, умноженное на 2) исследований и обусловлен ограничением вычислительных мощностей.
Для каждого баланса классов и объема случайным образом формировались подвыборки 10 000 раз с возвращением, для них рассчитывалась площадь под характеристической кривой (AUROC). По результатам работы CИИ рассчитаны средние значения AUROC для различных случайных наборов исследований с одинаковым балансом классов (рисунок 2.19).
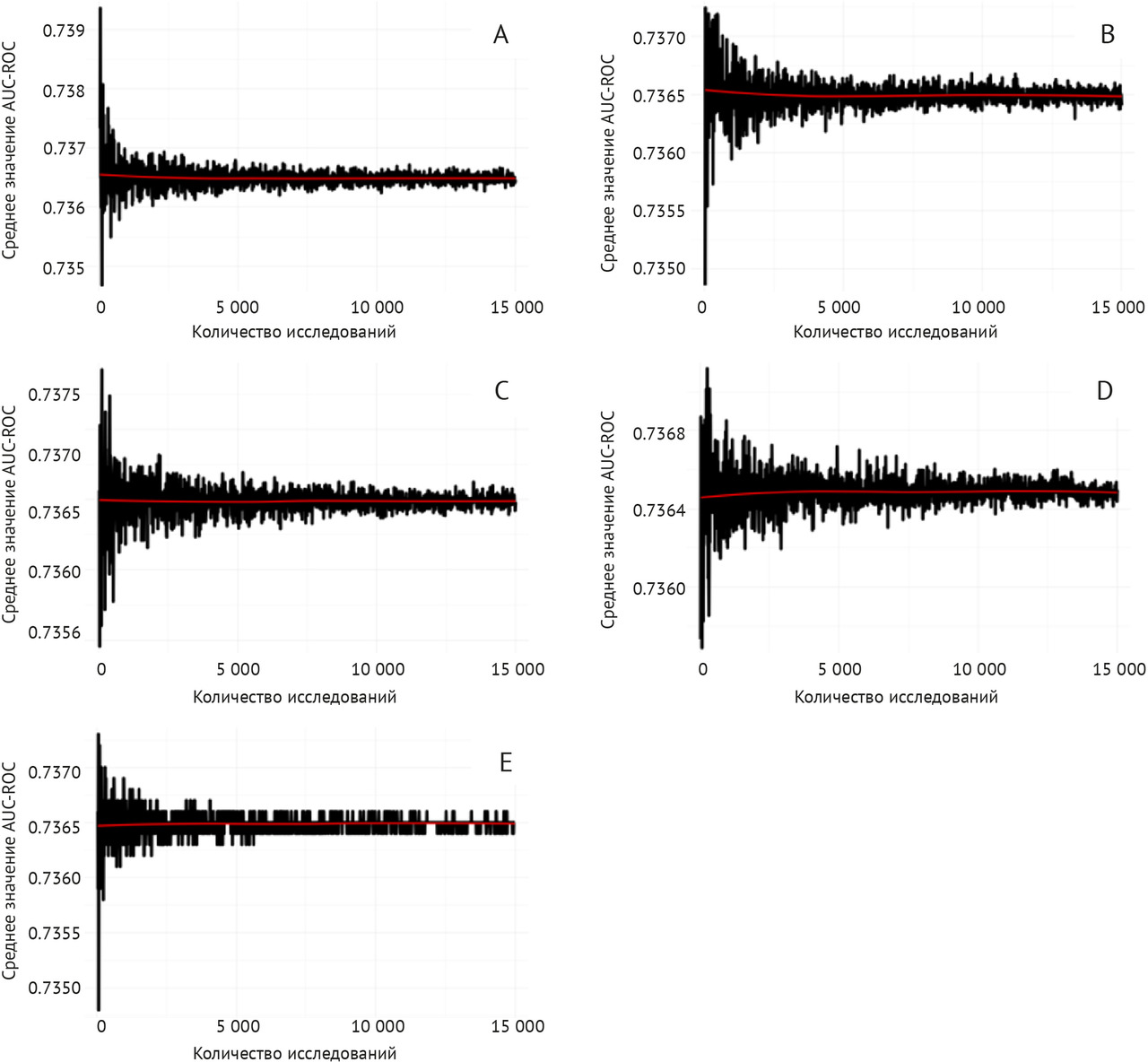
Следующим шагом средние значения AUCROC были подвергнуты трем типам анализа:
1. Фурье-анализ значений AUROC в зависимости от количества данных. Применение преобразования Фурье к колебаниям значений AUROC позволило выявить точку перехода, что является своеобразной границей между двумя различными распределениями. Эта граница соответствует значению 11 940 исследований. При использовании меньшего или равного количества исследований значения AUCROC для всех изученных долей «патологии» в балансе классов «норма»/«патология» распределяются по закону, близкому к распределению Коши. Причем если количество исследований превышало 11 940, то AUCROC имели нормальное распределение для 10% и 20% долей «патологии», логистическое — для 30% и 50% долей «патологии» и логарифмически нормальное — для 40% долей «патологии».
2. Анализ наиболее близкого теоретического распределения значений AUROC посредством применения информационных критериев Акаике и Байеса. Чтобы найти максимальное отклонение от линии тренда (рисунок 2.9) среднего показателя точности диагностики слева и справа от точки перехода (11 940 исследований), был определен ближайший тип простого распределения по минимуму критериев Акаике и Байеса. В таблице 2.7 представлены результаты сравнения распределения значений AUROC слева и справа от точки перехода для десяти различных распределений.
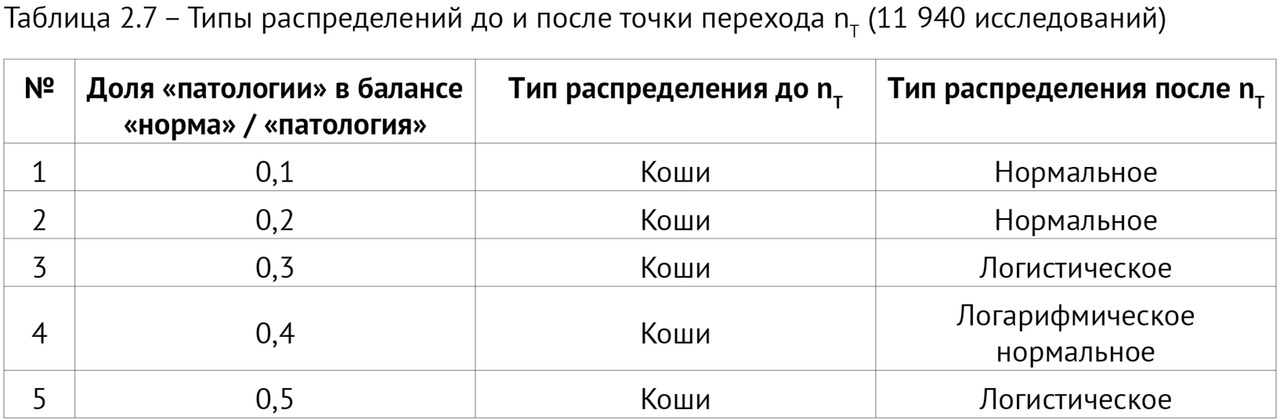
Из результатов анализа поведения аргумента спектральной функции AUROC и анализа ближайшего теоретического распределения следует, что до точки перехода для всех балансов классов сохраняется один и тот же тип распределения — распределение Коши. После точки перехода тип распределения меняется. Нормальное распределение наблюдается при 10% и 20% «патологии», логистическое — при 30% и 50% «патологии», а логнормальное распределение значений AUROC — при 40% «патологии».
3. Анализ коэффициента вариации в зависимости от количества исследований для установленного наиболее близкого типа распределения AUROC. Для оценки однородности значений AUROC был проведен анализ коэффициента вариации в зависимости от количества исследований (до 11 940 исследований). В случае распределения Коши коэффициент вариации рассчитывался по уравнению (2.5):
где Υ — масштабный параметр в распределении Коши; x0 — параметр сдвига в распределении Коши.
На рисунке 2.20 представлены результаты расчета зависимости коэффициента вариации распределения значений AUROC от количества исследований для пяти долей «патология» в балансе классов «норма»/«патология».
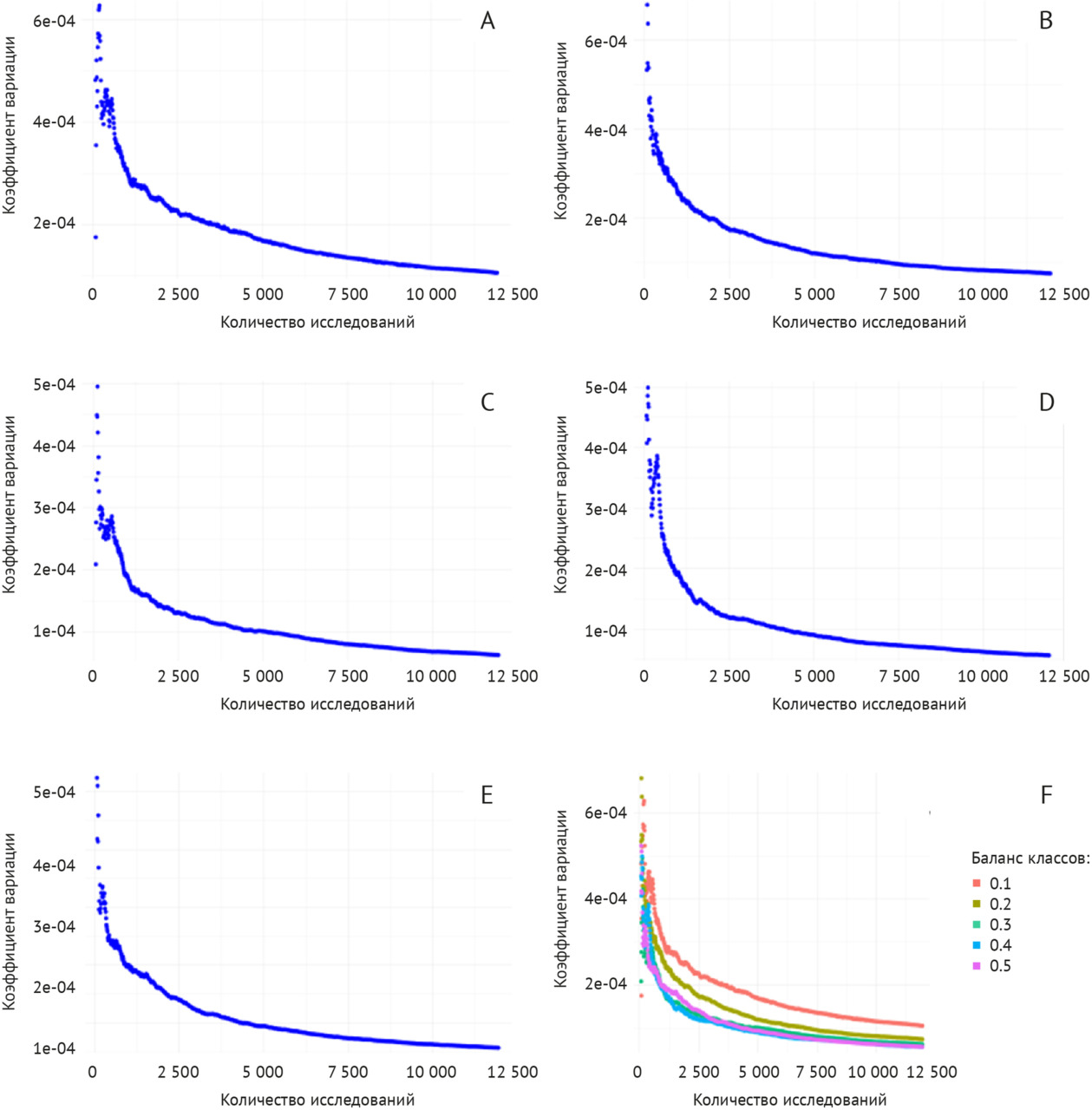
Максимальное значение коэффициента вариации значений AUROC для 10% доли «патологии» достигается при количестве исследований, равном 190; для 20% доли — 80 исследований; для 30% доли — 120 исследований, для 40% доли — 110 исследований, а для 50% доли — 70 исследований.
Таким образом, была сформирована гипотеза о возможности следующего применения полученных результатов:
1. Определение AUROC на наборе данных с заданным балансом классов и соответствующим объемом выборки.
2. Определение доверительного интервала для AUROC с помощью метода бутстреппинга.
3. Использование нижней границы доверительного интервала в качестве порогового значения для принятия решения о допуске СИИ AUROC.
Результаты, полученные с помощью данного подхода, сопоставимы с результатами одного из предыдущих подходов, описанных выше. Частота встречаемости признака в популяции известна не всегда, может варьировать с течением времени и в разных популяциях, может быть очень низкой для редко встречающихся патологий. На основании вышеизложенного логичным решением является задавать баланс классов как постоянную величину и выбирать объем необходимых для валидации данных для заданного баланса классов.
Также следует отметить, что отклонение среднего значения AUROC от линии тренда с увеличением количества исследований уменьшается, что свидетельствует о том, что при использовании СИИ в клинической практике могут демонстрироваться показатели диагностической точности, отличные от полученных при валидационном тестировании. По этой причине на этапе валидации СИИ необходимо определить максимальные пределы изменения показателей диагностической точности и в дальнейшем проводить регулярный мониторинг его работы.
2.3.4. Эмпирический подход с использованием ROC-анализа (цитируется по оригинальной статье авторов)
Предложенный в 2023 г. оригинальный подход включает в себя поиск порогового значения размера выборки, минимального и достаточного для получения объективного значения AUROC, и рассматривает исследования с бинарной классификацией «норма»/«патология».
После разделения генеральной исходной выборки на подвыборки в соответствии с классами назначаются баланс классов k в диапазоне от 10 до 90% и размер выборки для тестирования ИИ-алгоритма n в диапазоне от 30 до 25 000 с шагом в 10. Вычисления первого этапа содержат две последовательные операции:
1. Для выбранной комбинации k и n из базовых подвыборок случайным образом отбирается по k × n исследований класса «патология» и (1 — k) × n исследований класса «норма». Операция повторяется 100 раз, в результате чего формируются 100 подвыборок размера n, в каждой из которых содержится k % исследований класса «патология», что соответствует 100-кратному повторению эксперимента для заданной комбинации n и k.
2. На каждой из 100 подвыборок проводятся тестирование ИИ-алгоритма и регистрация метрик — чувствительность (Se), специфичность (Sp) и AUROC. В результате выполнения расчетов получается матрица размером 100 × 3, т. е. по 100 значений каждой метрики, полученных на выборке размером n с долей патологических случаев k.
Действия по п. 1 и п. 2 повторяют для каждой из возможных комбинаций n и k.
Для практической апробации настоящего подхода были использованы результаты тестирования трех различных алгоритмов ИИ, участвующих в Московском эксперименте. Результаты расчета nкр были сопоставлены между тремя алгоритмами ИИ.
При разработке подхода были использованы следующие наборы данных (НД):
1. Результаты профилактической маммографии классифицировались по наличию («патология») и отсутствию («норма») признаков злокачественных новообразований молочной железы аналогично предыдущему описанному подходу:
1.1 НД, содержащий 143 710 исследований с результатами ИИ-алгоритма «А1», полученными за период с 01.02.2022 по 31.10.2022.
1.2 НД, содержащий 123 301 исследование с результатами работы ИИ-алгоритма «A2», полученными за период с 01.09.2021 по 27.12.2021.
2. Результаты рентгенографии органов грудной клетки классифицировались по наличию («патология») и отсутствию («норма») хотя бы одного из следующих признаков: плевральный выпот, пневмоторакс, очаг затемнения, инфильтрация, консолидация, диссеминация, полость, ателектаз, кальцинат, расширение средостения, кардиомегалия, нарушение целостности кортикального слоя. НД, содержащий 62 142 исследования с результатами работы ИИ-алгоритма «A3», полученными за период с 25.10.2023 по 21.11.2023.
Первично была проанализирована зависимость выборочных средних и медианных значений каждой из трех метрик AUROC, Se и Sp от доли патологических исследований в выборке. Для всех трех алгоритмов наблюдается совпадение этих значений (рисунок 2.21а). Общий вид зависимости упомянутых метрик, а также их дисперсии от размера выборки представлены на рисунке 2.21б на примере данных алгоритма A1. Зависимость для всех трех метрик имеет сходный вид симметричного затухающего колебания: с ростом n амплитуда разброса значений уменьшается, достигая некоторого условно стабильного диапазона. Вид зависимости дисперсии от n (рисунок 2.21б, нижний ряд) подтверждает целесообразность учета дисперсии подвыборок при сравнении средних. Согласно полученным данным, ожидаемое среднее значение AUROC для ИИ-алгоритмов А1 и А2 составляет 57%, и 70% для А3.
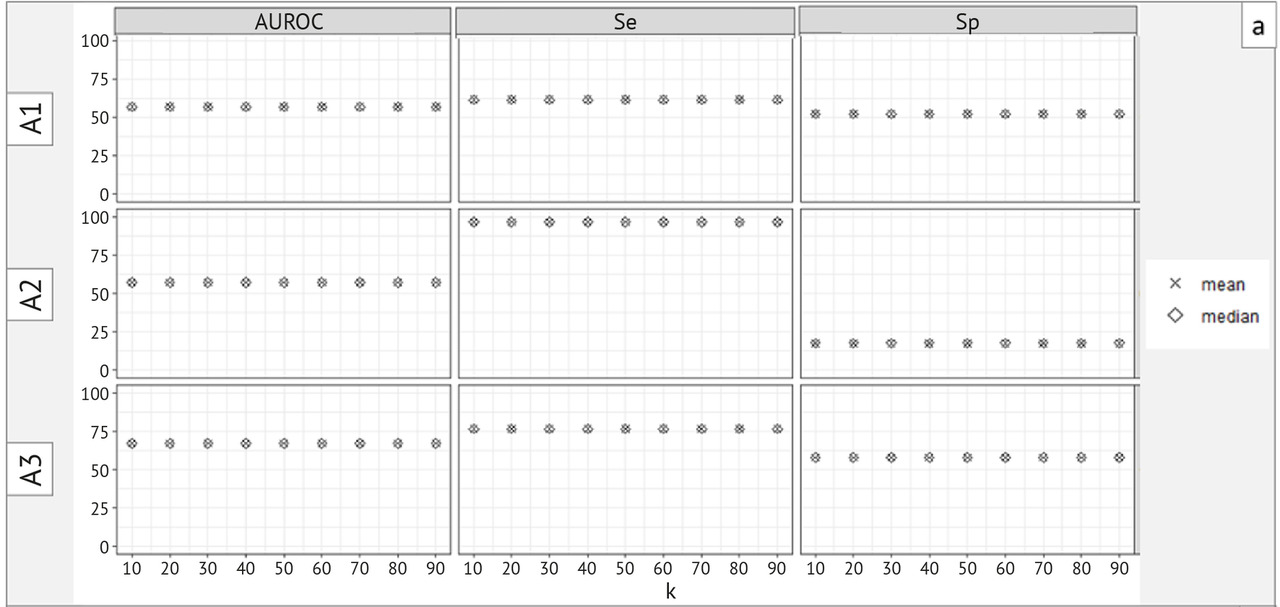
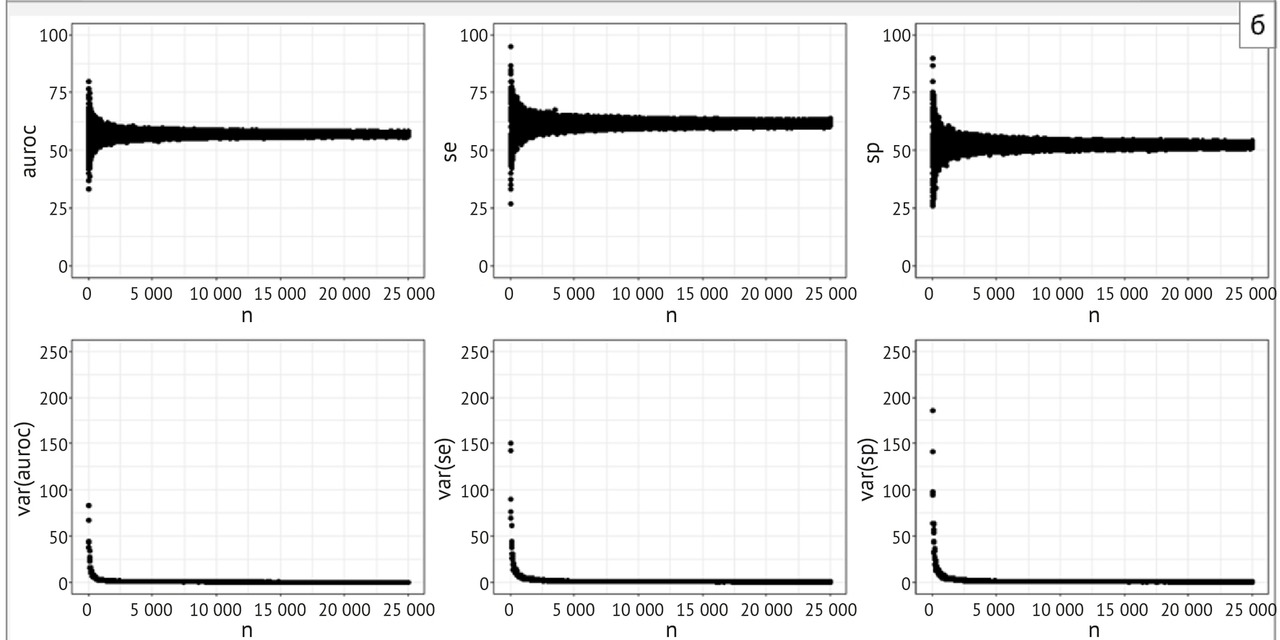
На рисунке 2.22 представлены результаты сглаживающей аппроксимации для всех k всех трех метрик по каждому ИИ-алгоритму. Показана зависимость числа «избыточных соседей» x от размера выборки n. Также показана линия отсечки, по которой определено nкр для каждого класса. Число x по критерию одновременного сопоставления средних и дисперсии метрики увеличивается с ростом размера выборки, на котором получена данная метрика.
Кривые имеют сходный вид вне зависимости от баланса классов: линейно подобно нарастающий участок плавно переходит в область малых колебаний вблизи плато. Линия отсечки, соответствующая 10 «избыточным соседям» x, пересекает графики на условно линейном участке.
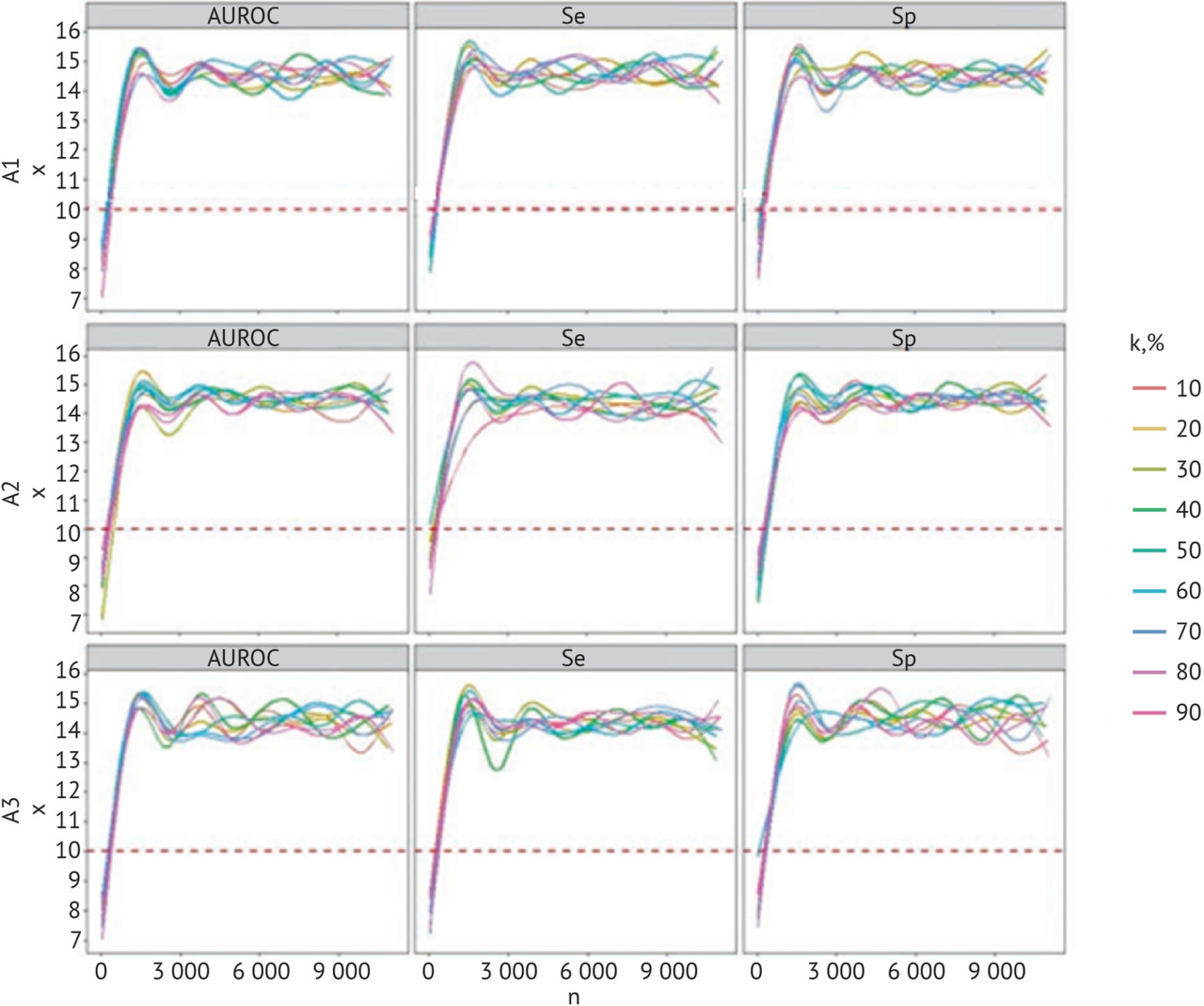
Теоретическая оценка размера выборки для алгоритмов А1 и A2 (ожидаемое значение AUCROC — 57%) имеет сходный вид для обоих методов расчета: U-образная кривая с минимальным значением для баланса классов 1:1. Для алгоритма A3 (ожидаемое значение AUROC — 70%) вид зависимости существенно разнится для первого и второго методов расчета. Эмпирическая зависимость размера выборки от баланса классов демонстрирует отсутствие явной зависимости от k.
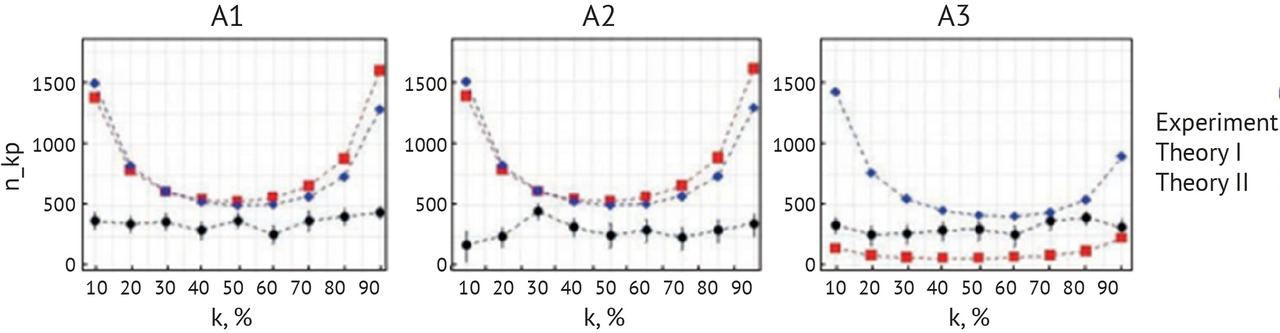
Как видно из графиков на рисунке 2.23, теоретически рассчитанные значения nкр превышают эмпирические для всех k у первых двух ИИ-алгоритмов. Для третьего алгоритма данное условие не соблюдается при использовании расчета по критерию оценки размера эффекта: т. к. ожидаемое значение AUROC (70%) ощутимо превышает значение для нулевой гипотезы (50%), минимально достаточные размеры выборок оказались малыми.
Для определения вида зависимости nкр от баланса классов был дополнительно проведен анализ результатов в области, включающей все значения 95% доверительных интервалов (ДИ) nкр для всех балансов классов: были отобраны все значения метрики, полученные при n ∈ [min nкр; max nкр]. Использован параметрический критерий Пирсона либо непараметрический — Спирмена, и проведено статистическое сопоставление групп, соответствующих различному k для каждого из трех алгоритмов по методу ANOVA или Краскелла–Уоллиса с апостериорным тестом Тюки либо Данна соответственно, с целью выявления отличающихся групп. Для объективизации результатов подгрупповой анализ проводился с поправкой Бонферрони на множественность сравнений.
Межгрупповой анализ выборок числа соседей при анализе AUROC между тремя алгоритмами для всех балансов классов дает следующий результат: p = 0,8 (тест Краскелла–Уоллиса), что соответствует отсутствию статистически значимых отличий и позволяет унифицировать 95% ДИ для nкр до (245; 398) при среднем значении 322. Целесообразно оценить граничный размер по верхней границе интервала, округляя до ближайшего значения, удобного при составлении выборок при различном балансе классов: 400 исследований.
Сравнение значений AUROC, полученных при n = 400, и n = N =25 000 для всех трех ИИ-алгоритмов, демонстрирует отсутствие статистически значимых различий при любом k (минимальное значение p = 0,08). Это означает, что AUROC, полученная при эмпирическом размере выборки в 400 исследований, статистически значимо не отличается от значения, полученного при размере выборки в 25 000 исследований вне зависимости от доли содержания патологии (от 10 до 90%), ИИ-алгоритма (А1, A2 или A3), а также типа лучевого исследования (ММГ или РГ). Применительно к абсолютным значениям речь идет об изменении усредненной AUROC между сопоставляемыми группами (n = 400 и n = 25 000) в третьем знаке после запятой, что, помимо показанного отсутствия статистической значимости, не обладает и практической.
Таким образом, оценка минимального размера выборки эмпирическим путем дает результаты, существенно отличающиеся от теоретических, причем не только по абсолютной величине, но и по зависимости от входных данных.
Во-первых, эмпирический минимальный объем выборки инвариантен к размеру эффекта, т. е. отличию ожидаемого значения AUROC от условной границы «случайного ответа» (AUROC = 0,5). Это позволяет определить размер выборки, не задавая предварительно значение метрики, на получение которой и направлена процедура тестирования. Согласно теоретическим расчетам, чем выше желаемое значение AUROC, тем меньше размер выборки потребуется, однако именно для выборок малого размера отмечается высокий риск внесения систематической ошибки. Это подтверждается результатами анализа реальных данных: для выборок малого размера характерен больший разброс, следовательно, для выборки формально достаточного размера можно получить необоснованно завышенные или заниженные результаты.
Во-вторых, эмпирический минимальный объем выборки инвариантен к содержанию патологии в ней. На первый взгляд данный тезис содержит логическое противоречие, т. к. известно, что несбалансированность классов в выборке может приводить к неоправданному завышению чувствительности или специфичности. При этом долю патологии (т. н. prevalence) обычно назначают, исходя из данных популяционных исследований для достижения репрезентативности выборки, т. е. ее максимального правдоподобия по отношению к генеральной совокупности. Это подтверждается результатом сравнения средних значений выборок AUROC, полученных для разных балансов классов.
Наконец эмпирический минимальный объем выборки может быть определен вне зависимости от модальности исследований и алгоритма ИИ. Получены три значения для минимально необходимого объема выборки: 365 (95% ДИ 324; 407), 297 (95% ДИ 235; 358) и 312 (95% ДИ 274; 350) для А1, A2 и A3. Проведенный межгрупповой анализ показал отсутствие статистически значимых различий, что позволяет объединить результаты и обозначить единый порог для тестирования алгоритма ИИ как верхнюю границу 95% ДИ, округленную до 400 исследований.
На основании этого можно заключить, что для получения стабильного значения метрик при тестировании сервисов ИИ с бинарным исходом достаточно 400 исследований, причем минимальная доля любого из классов должна составлять всего 10%. Дальнейшее увеличение размера выборки, равно как и изменение баланса классов, не будет вносить статистически значимых изменений в значение данной метрики. Полученное значение не зависит от баланса классов, типа обработанных исследований и самого ИИ-сервиса, а результаты воспроизводимы для всех основных диагностических метрик — чувствительности, специфичности и AUROC. При этом в данном случае, в отличие от описанного выше, не требуется дополнительных манипуляций с данными (бутстреппинг, определение границ доверительного интервала), а оценивается точечное значение AUROC, полученное на 400 исследованиях. Дальнейший рост размера выборки не даст статистически значимого вклада в значение диагностической метрики точности работы алгоритма.
Подходы к определению мощности наборов данных, разработанные в ходе Московского эксперимента, охватывают важнейшие процессы разработки и успешного внедрения технологий искусственного интеллекта. Все подходы, освещенные в данном разделе, применимы как к задачам калибровки, так и к задачам мониторинга, и демонстрируют пошаговое развитие методик, применяемых при оценке СИИ. Имея сопоставимые результаты по необходимому и достаточному количеству исследований в наборах данных, подходы остаются достаточно гибкими и универсальными для использования в большинстве медико-биологических задач.
2.3.5. Точность измерений при оценке диагностического качества систем искусственного интеллекта
Внедрение систем искусственного интеллекта в практическое здравоохранение — сложный многоэтапный процесс, в котором нужно отметить следующие ключевые компоненты:
1. Технические и клинические испытания. Без этих этапов невозможен ввод в эксплуатацию медицинского изделия с ИИ, так как они необходимы для оценки эффективности и безопасности продукта при его применении. Технические испытания фокусируются на функциональных характеристиках СИИ, в то время как клинические испытания оценивают ее влияние на пациентов и способность выявлять заданную патологию.
2. Государственная регистрация. После успешного прохождения технических и клинических испытаний СИИ регистрируют в качестве медицинского изделия, что в дальнейшем допускает ее использование в качестве самостоятельного медицинского изделия или в составе другого медицинского изделия в медицинских организациях. Этап государственной регистрации, фактически, является валидирующим.
Оценка технических характеристик СИИ как медицинского изделия неизбежно приводит к необходимости обращения специалистов к фундаментальным концепциям метрологии. Одним из ключевых понятий в этой области является «точность измерений».
Точность измерений определяется как близость измеренного значения к истинному значению измеряемой величины. Этот термин тесно связан с понятием «точность результата измерений», которое отражает степень приближения полученного результата к действительному значению измеряемой характеристики. Любая же измеренная техническая характеристика отражает истинное значение измеряемой величины лишь с определенной погрешностью. Эта погрешность является неотъемлемым элементом процесса измерения и должна учитываться при интерпретации результатов. Поэтому в контексте применения СИИ в здравоохранении представление результатов измерений (точность их представлений) и их округление приобретают особую важность, ведь они влияют непосредственно на здоровье пациента (на основе этих данных может быть принято решение — направить его на дальнейшее обследование или нет).
Среди технических характеристик, относящихся к СИИ в здравоохранении (в том числе в лучевой диагностике), выделяются следующие метрики диагностической точности: чувствительность, специфичность, точность, площадь под характеристической кривой (AUROC — от англ. area under receiver operating characteristic curve), индекс Дайса–Сёренсена и др. Исходя из вышесказанного возникает вопрос о представлении результатов измерений со стороны разработчиков СИИ и способах их округления до приемлемых значений и представлении регулятору. От точности измерения и представления основных технических характеристик СИИ зависят:
1. Обеспечение безопасности и качества медицинской помощи.
2. Обоснование клинической значимости применяемых технологий ИИ.
3. Удобство представления результатов измерений (в контексте технических и клинических испытаний) регулятору в сфере здравоохранения и другим заинтересованным сторонам.
4. Единообразие форм оформления документации и протоколов испытаний.
5. Соблюдение требований стандартов (например, ГОСТ Р 8.736—2011).
В соответствии со ст. 38 Федерального закона от 21.11.2011 №323-ФЗ «Об основах охраны здоровья граждан в Российской Федерации» в Государственный реестр медицинских изделий и организаций, осуществляющих производство и изготовление медицинских изделий, должны вноситься сведения о взаимозаменяемых медицинских изделиях. При этом медицинские изделия считаются взаимозаменяемыми в том случае, если они «сравнимы по функциональному назначению, качественным и техническим характеристикам и способны заменить друг друга». В этом контексте метрики диагностической точности, описанные выше, приобретают статус основных технических характеристик для СИИ. Таким образом, без их тщательного анализа и четкой структуры представления невозможно принять решение об их взаимозаменяемости.
В связи с вышесказанным и в контексте активно развивающейся стандартизации ИИ в здравоохранении возникла острая необходимость в разработке четких стандартов представления метрик диагностической точности. Их отсутствие на данном этапе приводит к ряду проблем как для медицинского сообщества, так и для сообщества разработчиков.
В настоящий момент существует подход вольного представления метрик диагностической точности разработчиков в регуляторные органы, а также их частичное или полное утаивание от медицинского сообщества. Это способствует возникновению риска допуска к использованию в здравоохранении СИИ низкого качества, что несет потенциальную угрозу здоровью пациентов. Кроме того, подобный подход препятствует сравнительному анализу взаимозаменяемости медицинских изделий с технологией ИИ, что противоречит ст. 38 Федерального закона №323-ФЗ.
Примечательно, что, по зарубежным данным, манипуляции компаний-разработчиков с данными о точности СИИ, предоставляемыми регулятору и демонстрируемыми медицинскому сообществу, выявлены в 19,2% случаев.
Проведен комплексный анализ доступной информации разработчиков об их медицинских изделиях с СИИ с использованием официальных ресурсов регулирующих органов Российской Федерации (Росздравнадзор (РЗН)) и для сравнения — США (Food and Drug Administration (FDA)). Дополнительно были изучены научные публикации в научных базах данных и официальные веб-ресурсы разработчиков СИИ. Найдены заявления о государственной регистрации СИИ, публикации, в которых были представлены метрики диагностической точности таких медицинских изделий. На основе этой информации был проведен сравнительный анализ, направленный на выявление различий и сходств в представлении метрик диагностической точности между различными медицинскими СИИ. На основе этого было принято решение о создании классификации программного обеспечения с технологиями ИИ в области лучевой диагностики. Это стало необходимым, так как выделились определенные области применения подобного программного обеспечения, внутри которых можно говорить о взаимозаменяемости подобных медицинских изделий.
Анализ подтвердил, что наблюдается проблема недостаточной прозрачности представления метрик диагностической точности со стороны разработчиков программного обеспечения с СИИ. Была выявлена склонность к преимущественно маркетинговому описанию медицинских изделий на их веб-платформах. Научные труды на эту тему редко публикуются, отсутствует доступ к данным с описанием диагностической точности, используемым при подаче заявок на регистрацию медицинских изделий в регуляторные органы.
Примеры указания метрик диагностической точности со стороны разработчиков программного обеспечения с СИИ, зарегистрированных в качестве медицинских изделий в Росздравнадзоре и FDA, представлены в таблице 2.8.
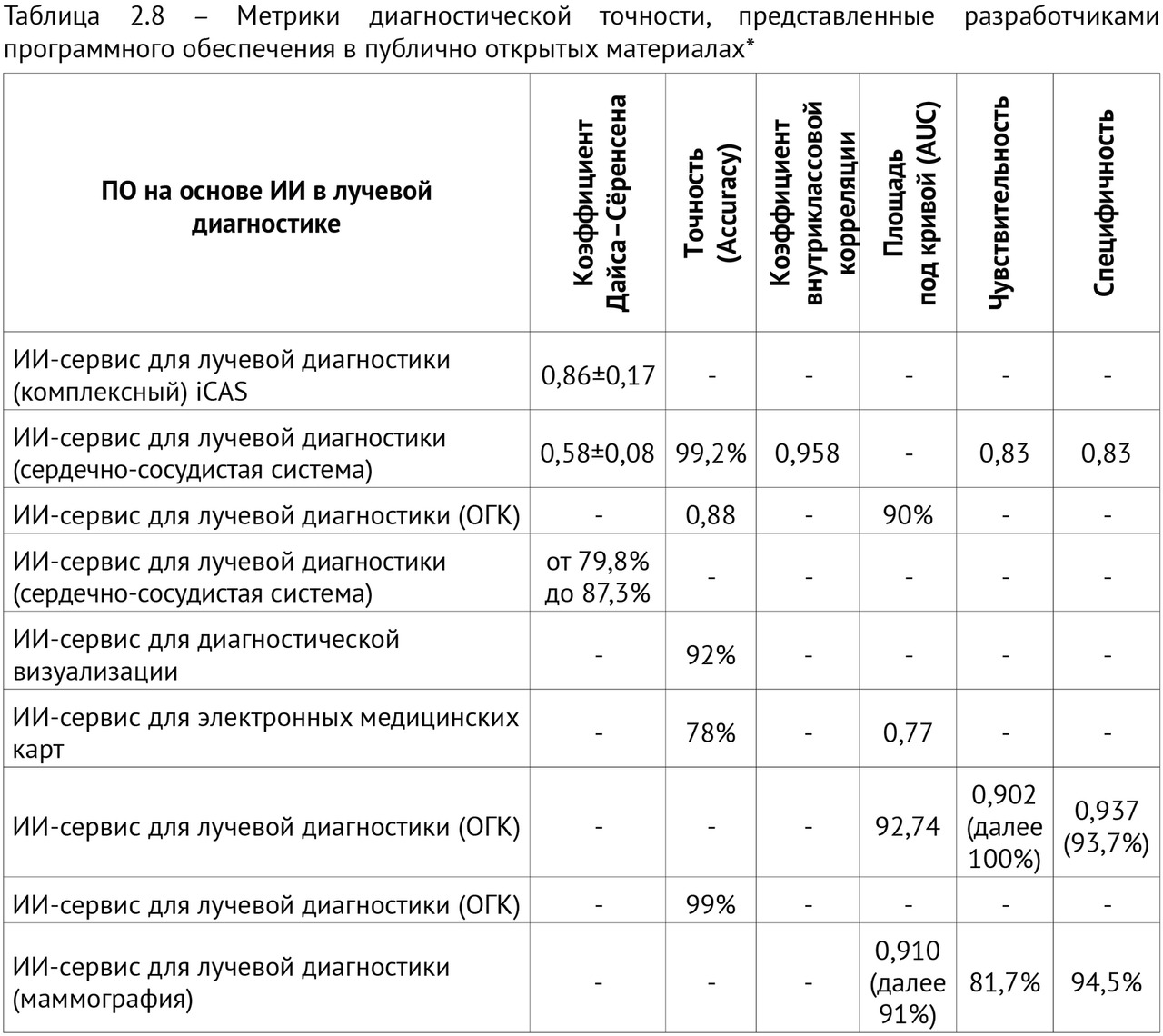
Из предложенной таблицы можно увидеть определенные тенденции представления метрик диагностической точности различными разработчиками ИИ-систем. Например, один из разработчиков в общедоступных источниках (общий текст публикации) указывает значение чувствительности как 100%. Однако в таблице в той же самой публикации отмечено среднее значение чувствительности на тестовых данных не в округленном виде и равняется 0,902, то есть, на самом деле, на тестовых данных не было достигнуто чувствительности, равной 1,0, но разработчик указал ее именно в формате 100%. Фактически (с точки зрения математических операций с округлением чисел) он имел на это право. Со стороны другого разработчика ИИ-системы диагностические метрики — чувствительность и специфичность, наоборот, были указаны с точностью до третьего знака после запятой. Подобная ситуация наблюдается и у других разработчиков с различными метриками, отражающими диагностическую точность ИИ-системы. Таким образом, наблюдается разобщенность как между разработчиками программного обеспечения с ТИИ, так и регуляторными органами.
Рассмотрим следующую ситуацию: медицинская организация (МО) внедряет программное обеспечение с ИИ в службу лучевой диагностики. МО не хочет работать с ИИ-сервисами с AUROC ниже 0,81. Как определить, какой ИИ-сервис может быть использован в этой МО, а какой — нет? Предположим, что при тестировании фактически достигнутая AUROC у одного из разработчиков сервиса ИИ составила 0,807. В случае округления до двух знаков после запятой данная система-ИИ может быть допущена к использованию в этой МО, так как в этом случае их AUROC будет равна 0,81. Однако, если бы исходное значение AUROC не было округлено, то разработчик со своей ТИИ не соответствовал бы требованиям МО.
Во время анализа литературы, доступных сайтов и публикаций о метриках диагностической точности и их представления со стороны разработчиков стало понятно, что необходима определенная классификация ИИ-сервисов. Не все сервисы выполняют одинаковую функцию, также они предназначены для выявления различных типов патологий, которые имеют неодинаковую опасность для здоровья пациентов. Таким образом, стало понятно, что эта классификация будет направлена на обеспечение единого подхода к представлению данных о диагностической точности различных ИИ-сервисов с точки зрения их клинического использования. Классификация будет способствовать повышению прозрачности и сравнимости информации о различных программных продуктах на основе ИИ, таким образом обеспечив взаимозаменяемость этих продуктов, зарегистрированных в качестве медицинских изделий.
В результате анализа, литературного поиска и опыта применения различных СИИ в медицине была разработана классификация, представленная на рисунке 2.24. Данная классификация масштабируема не только на лучевую диагностику, но и на другие области здравоохранения, например, системы мониторинга, системы поддержки принятия врачебных решений и другие.

Не для всех СИИ необходима высокая детализация указания метрик диагностической точности. Приведем несколько примеров расчета для пояснения. По данным Всемирной организации здравоохранения (ВОЗ), туберкулез считается заболеванием с высоким уровнем смертности. По данным Федеральной службы государственной статистики, впервые в жизни активный туберкулез в 2022 году у взрослого населения Российской Федерации был выявлен у 45,6 тысяч человек. Посчитаем количество больных, которых ИИ-сервис для выявления очагов туберкулеза в легких признает ошибочно здоровыми в случае указания метрики диагностической точности «чувствительность» до двух десятых вместо трех десятых в случае массовых диагностических исследований (т.е. в случае округления метрики в большую сторону). Результаты расчета представлены в виде таблицы 2.9.

Таким образом, в случае округления разработчиком значения метрики диагностической точности (чувствительность) вместо 0,836 до 0,84 — происходит недооценка реального количества больных таким социально значимым заболеванием, как туберкулез. Если у системы ИИ чувствительность — 0,836, то будет пропущено на 4 человека с туберкулезом больше, чем при чувствительности системы ИИ, равной 0,84.
Возник логичный вопрос — почему же тогда не указывать значение метрик диагностической точности с еще большой точностью? В целом, этот вопрос до сих пор обсуждается, однако, на данном этапе развития СИИ предлагается остановиться на максимальных трех знаках после запятой или менее. Тем не менее, как обсуждалось выше — вопрос представления метрик диагностической точности зависит от того, какое предназначение имеет медицинское изделие с СИИ, в какой области оно применяется, какие экономические затраты появятся в связи с недообследованными или пропущенными пациентами, а также другими факторами.
Очевидно, что высокая точность указания метрик важна для СИИ, используемых в целях оказания экстренной (неотложной) помощи пациентам. Например, использование ИИ-сервисов в палатах интенсивной терапии или для быстрой сортировки пациентов в МО, оказывающих неотложную помощь.
Указание уровня диагностической метрики «специфичность» дает понимание того, насколько вообще можно доверять такое ИИ-системе (таблица 2.10).

При указании разработчиком у медицинского изделия с ИИ всего двух знаков после запятой наблюдается та же ситуация, что и у чувствительности. Одновременно с этим один знак после запятой — сильно занижает реальную пользу СИИ и уровень доверия к ней в пересчете на пропущенных пациентов.
В продолжение рассуждения о том, сколько знаков после запятой необходимо указывать, рассмотрим пример использования ИИ-сервисов для морфометрических исследований. Для таких СИИ в лучевой диагностике указание двух знаков после запятой, например, в индексе Дайса–Сёренсена является достаточным и предпочтительным. Это решение основано на анализе ошибок, которые допускают врачи-рентгенологи при проведении исследований, а также на основе погрешности измерений, которую дает медицинское оборудование. Двух знаков после запятой вполне достаточно, чтобы показать реальную способность ИИ-сервиса измерять органы и ткани, без необходимости абсолютной точности. Учитывая вариативность ошибок измерения даже среди профессиональных медицинских работников, подобное представление метрик диагностической точности у ИИ-сервисов, не относящихся к медицинским изделиям для неотложной помощи, обеспечивает баланс между техническими характеристиками СИИ и ее практической применимостью.
Таким образом, разработанная клиническая классификация для программного обеспечения с ИИ в лучевой диагностике помогает понять, насколько важна точность передачи значения метрик диагностической точности со стороны разработчика как в регуляторные органы, так и для конечного пользователя. Данная классификация может быть масштабируема на другие виды медицинских изделий с ИИ. Она также может быть использована для определения взаимозаменяемости соответствующих медицинских изделий.
Рекомендуемая классификация должна быть использована для разработки и внедрения программного обеспечения на основе ИИ в области лучевой диагностики и в смежных областях, а также для совершенствования системы регулирования и контроля качества подобного рода медицинских изделий.
2.3.6. Основные показатели для оценки качества системы искусственного интеллекта
Диагностическая точность. Исследования диагностической точности СИИ проводят в дизайне диагностического исследования в соответствии с методологией STARD-2015 (см. подпараграф 2.10.3). Проведение такого исследования подразумевает наличие некоего эталона (так называемого золотого стандарта) — референс-теста, с которым сравнивают точность нового инструмента — индекс-теста.
Для оценки точности СИИ обеспечивают наличие размеченного и верифицированного набора данных; его и считают референс-тестом. Далее, посредством изучаемой СИИ, выполняется автоматизированный анализ этого набора данных; полученные в итоге результаты и считают индекс-тестом.
Для сопоставления результатов индекс- и референс-теста составляют четырехпольную таблицу для целевой патологии и определяют абсолютное значение для каждого вида результатов (таблица 2.11). Следующим шагом производят выбор и расчет релевантных показателей с определением достоверности в рамках 95% доверительного интервала (ДИ).
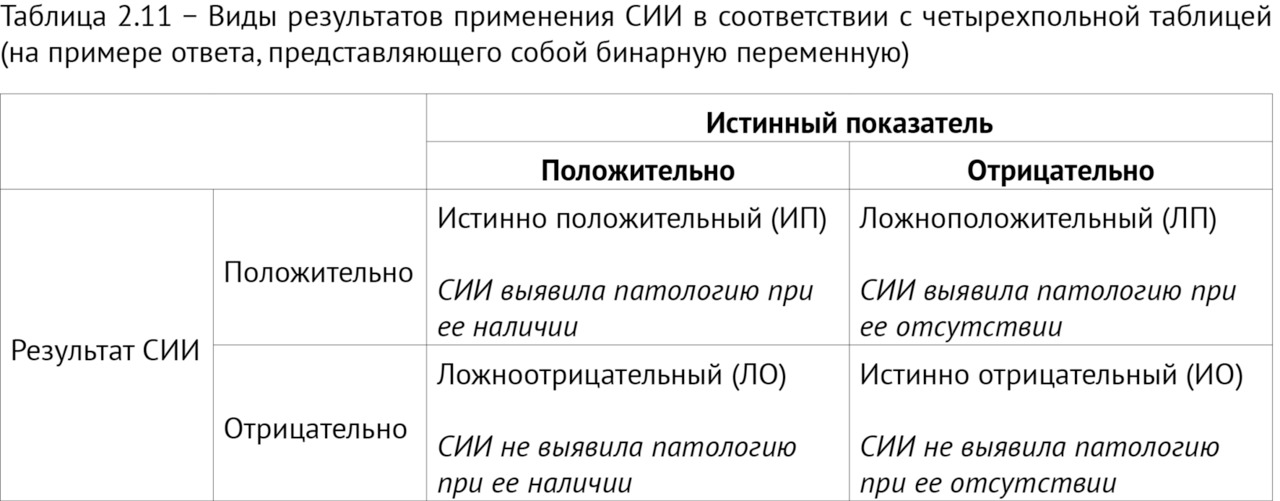
На основе четырехпольной таблицы рассчитывают необходимые показатели, в том числе чувствительность и специфичность (см. далее), на основе которых строят характеристическую кривую (ROC-кривую).
Характеристическая кривая (ROC — от англ. receiver operating characteristic curve) — отображение соотношения между долями объектов от общего количества носителей признака, верно классифицированными как несущие признак (то есть чувствительностью), и долями объектов от общего количества объектов, не несущих признака, ошибочно классифицированных как несущие признак (то есть специфичностью) при варьировании порога активации. Метрика диагностической ценности: площадь под кривой (AUC — от англ. area under curve) — площадь, ограниченная ROC-кривой и абсциссой.
Классическая ROC-кривая представляет собой график зависимости чувствительности от 1-специфичности (по оси абсцисс — 1-специфичность, по оси ординат — чувствительность).
При анализе ROC-кривой необходимо воспользоваться пороговым значением, указанным в документации производителя, или определить оптимальные значения порога активации (так называемого cut-off). Переопределение порогового значения возможно тогда, когда это подтверждено производителем и отражено в итоговой документации клинических испытаний. В отдельных случаях переопределение порогового значения может привести к изменению качества работы СИИ, например, когда СИИ состоит из ансамбля алгоритмов. В случае, если производителем допускается переопределение пороговых значений, то для этого могут быть использованы различные методики. В качестве примера (но не обязательного требования) можно привести следующие:
— минимальное расстояние от верхнего левого угла до ROC-кривой (минимум d);
— индекс Юдена (Youden index), который отображает максимальное расстояние от диагональной линии до ROC-кривой (рисунок 2.25).
Приоритет той или иной методике определения порога активации должен отдаваться в зависимости от целей испытания.
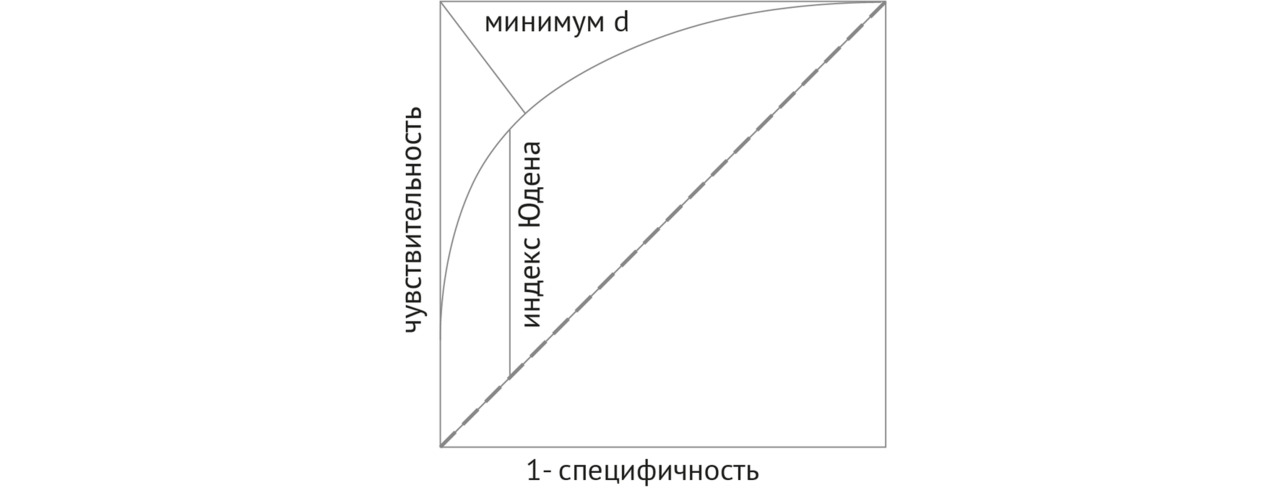
Для оценки диагностической точности СИИ вычисляют показатель — площадь под характеристической кривой (как часть координатной плоскости под графиком ROC-кривой).
Иногда используют разновидность ROC-кривой — так называемую PR-кривую (от англ. precision-recall), которая строится как зависимость прогностической ценности положительного результата по оси ординат и чувствительности по оси абсцисс. Критерием качества СИИ при использовании данной метрики является площадь под PR-кривой (AUC-PR).
Согласованность (конкордантность) — математическое отображение согласованности классификации двух экспертов относительно одного явления. Показатель согласованности определяется по формуле Коэна (каппа Коэна) (2.6):
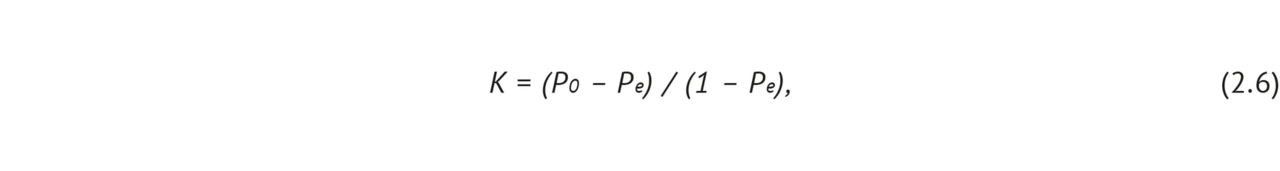
где Р0 — доля случаев, когда измерения совпадали, и Ре — ожидаемая доля случаев случайного совпадения.
Порядок расчета коэффициента соответствия классификации приведен в таблице 2.12.
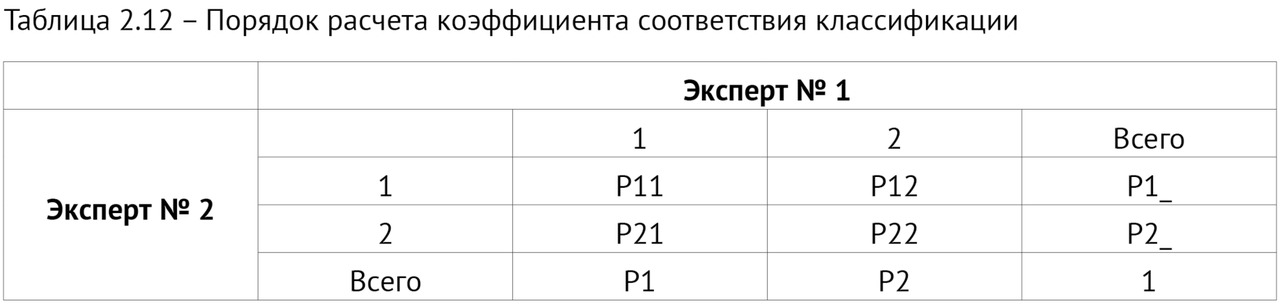
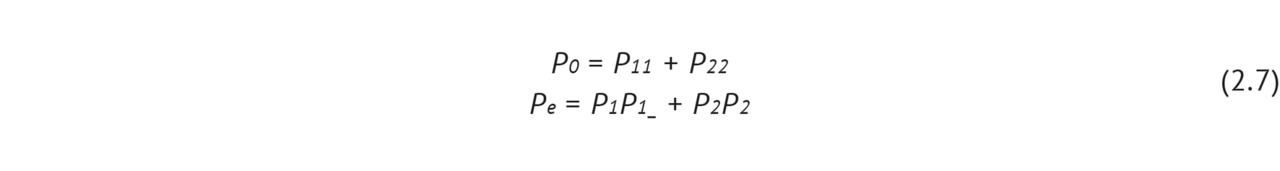
где P11, P12, P22, P21 — доля случаев, когда мнения экспертов совпали; P1, P2, P1, P2 — доля случаев случайного совпадения.
В таблице 2.13 представлен свод классических показателей диагностической точности, используемых на всех этапах жизненного цикла СИИ: от внутреннего тестирования в процессе разработки до клинических испытаний и пострегистрационного мониторинга.

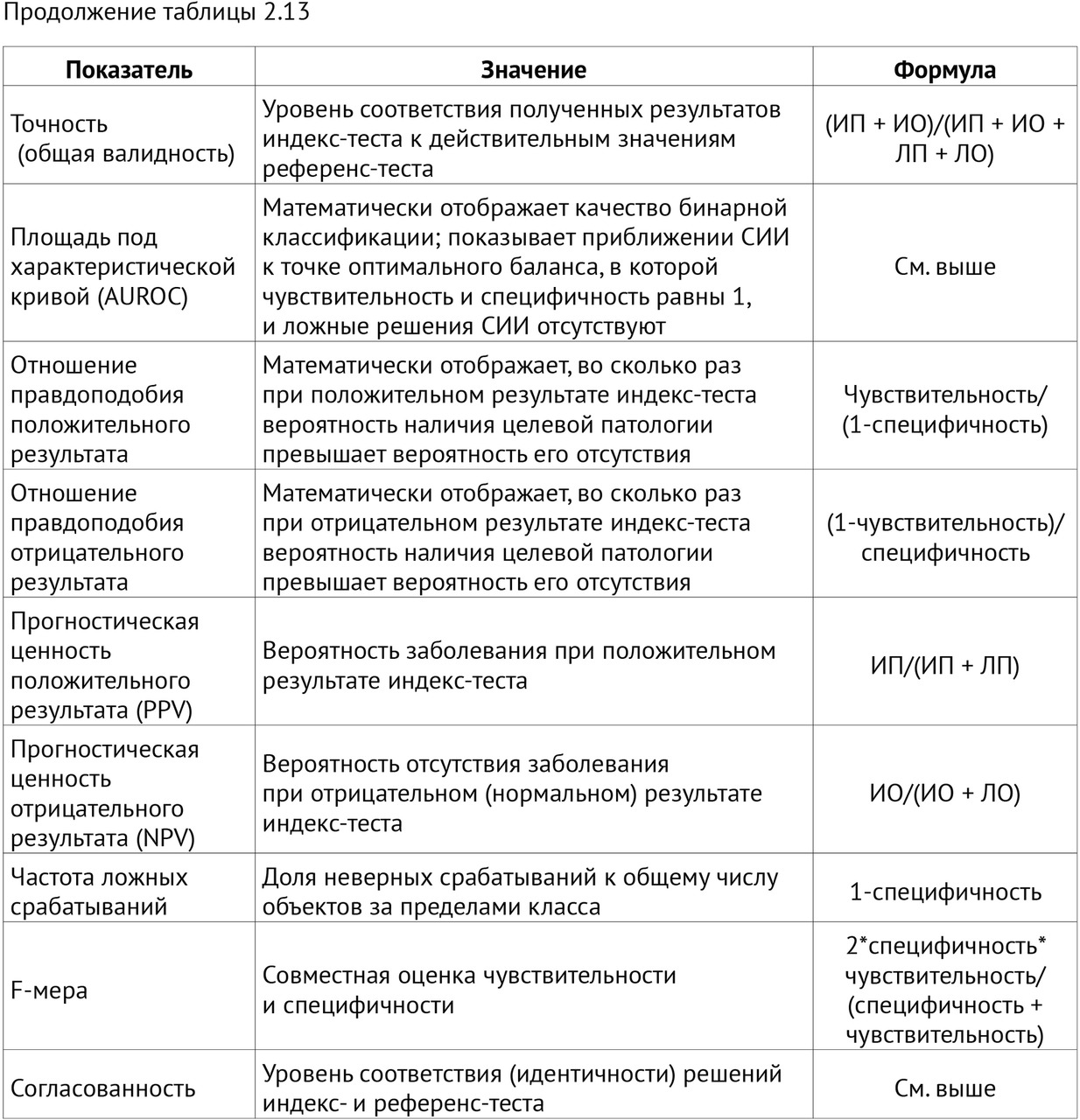
Все метрики, кроме отношения правдоподобия, оцениваются в диапазоне 0−1 или в процентах от 0 до 1 (или 100%). Интерпретация значений показателей диагностической точности: менее 0,7 — неприемлемое, 0,7–0,8 — приемлемое, 0,81–0,9 — хорошее, более 0,9 — высокое качество.
Отношение правдоподобия положительного результата должно быть как можно выше, тогда как отношение правдоподобия отрицательного результата — как можно ниже.
В зависимости от решаемой научно-методической задачи могут применяться различные сочетания показателей. Например, анализ характеристической кривой и/или определение коэффициента согласованности классификаций и т. д.
Дополнительные метрики оценки точности сегментации медицинских данных. Стандартная метрика кросс-энтропии — или логарифмическая функция потерь log-loss. Кросс-энтропия измеряет расхождение между двумя вероятностными распределениями. Если кросс-энтропия велика, это означает, что разница между двумя распределениями велика, а если кросс-энтропия мала, то распределения похожи друг на друга. На рисунке 2.26 приведена схема обозначений для расчета метрик: на медицинских данных (I) выполнена эталонная сегментация экспертом (G), а также сегментация с использованием СИИ (М). В таблице 2.14 приведен соответствующий перечень метрик, которые применяют для оценки точности сегментации медицинских данных.
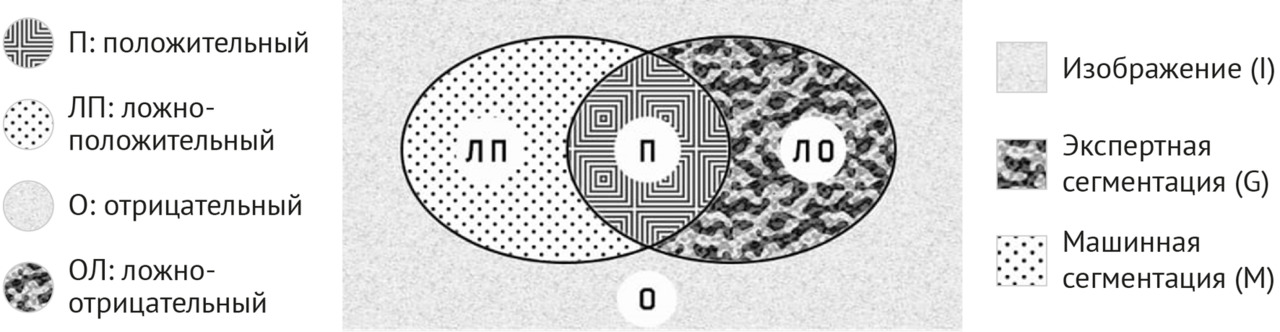
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.