
Бесплатный фрагмент - Анализ больших данных
Учебное пособие

Электронная книга - Бесплатно
Введение
Инноватика
Инновации, управление инновациями, инновационные процессы, инноватика — звучит как внедрение чего-то «нового». А как на самом деле?
До «инноватики» было «управление инновациями». А ещё есть и сами инновации, с которых всё и начинается. В любом случае неплохо было бы разобраться, что же такое инновации.
Задание. Просмотрите в Википедии статью Инновации.
Образовательный стандарт
Имеет смысл ознакомиться с образовательным стандартом по направлению подготовки. На сегодняшний день этот документ называется ФГОС — Федеральный государственный образовательный стандарт. В этом стандарте описаны основные области профессиональной деятельности выпускников направления «Инноватика». Сюда входят, прежде всего, так называемые наукоемкие отрасли: авиация, ракетостроение, атомная промышленность. Здесь без науки не будет производства. В мире не так много найдётся стран, которые способны строить самолёты, ракеты и атомные реакторы. Остальные могут только покупать готовое.
Если посмотреть список «компетенций» в образовательном стандарте, то есть знаний и умений специалиста, мы обнаруживаем «управление в технических системах», «управление проектами» и «управление производством». Другими словами, здесь упоминаются инженерные и экономические области знания, см. рис.

Задание. Просмотрите ФГОС по направлению «Инноватика» и выясните, какое образование здесь преобладает — инженерное или экономическое.
Кафедры
Если поискать в интернете название кафедр, которые выпускают специалистов по инноватике, можно обнаружить управление инновациями, а также инженерное предпринимательство. В этих названиях мы тоже обнаруживаем технические и экономические знания — в одном пакете.
Задание. Найдите в интернете название кафедр, выпускающих специалистов по инноватике.
Профстандарт
Ещё один тип документов, относящийся к нашему вопросу, это так называемый профессиональный стандарт, или «профстандарт». Это пожелания и требования работодателей, промышленных предприятий. Этот документ составляет министерство труда. По существу, это описание профессии, а не учебной программы. Профстандарт сообщает нам о подготовке менеджеров продуктов и менеджеров проектов, о стратегическом и тактическом планировании, а также про управление производством, в том числе автоматизированное.
Задание. Найдите профессиональный стандарт, имеющий отношение к инновациям. Ознакомьтесь с содержимым профстандарт, обращая внимание на общие направления знаний и название должностей.
Вики
Следующий источник информации (не всегда полный и надёжный, но всегда доступный) — это Википедия, народная энциклопедия. Здесь мы узнаем, что инновации — это коммерциализация результатов научно-технической деятельности. Другое определение инновации — это превращение идей в продукт, то есть в товар или услугу.
Задание. Просмотрите в Википедии статьи на тему инноватика, инновации, управление инновациями, инновационный менеджмент.
Получается, что инноватика — это создание новых товаров услуг, а также управление этим процессом, то есть инновационный деятельностью.
Международные стандарты
Конечно же, не будем забывать и про международные стандарты. На сайте Международной организации по стандартизации ISO можно найти текст стандарта 56000 под названием «Управление инновациями — Основные термины». Английское название: Innovation management — Fundamentals and vocabulary.
Задание. Просмотрите начало стандарта ISO 56000 и найдите определение инновации и виды инноваций. При необходимости используйте автоматический перевод, например, встроенный в браузер в Google Chrome.
Федеральный закон
Картину научной и инновационной деятельности раскрывает Федеральный закон 127-ФЗ о науке. Нас интересует Статья вторая — основные понятия. Очень приблизительно можно описать нашу деятельность как три уровня науки:
— фундаментальная наука
— прикладная наука
— научно-технические разработки / инновации.
Фундаментальная наука называется так неспроста. Чтобы построить дом, сначала нужно заняться фундаментом. Это основание, на котором будет держаться всё здание. Не будет фундамента — дом развалится.
Фундаментальная наука занимается получением новых знаний. Это новые, ранее неизвестные законы природы, см. рис.
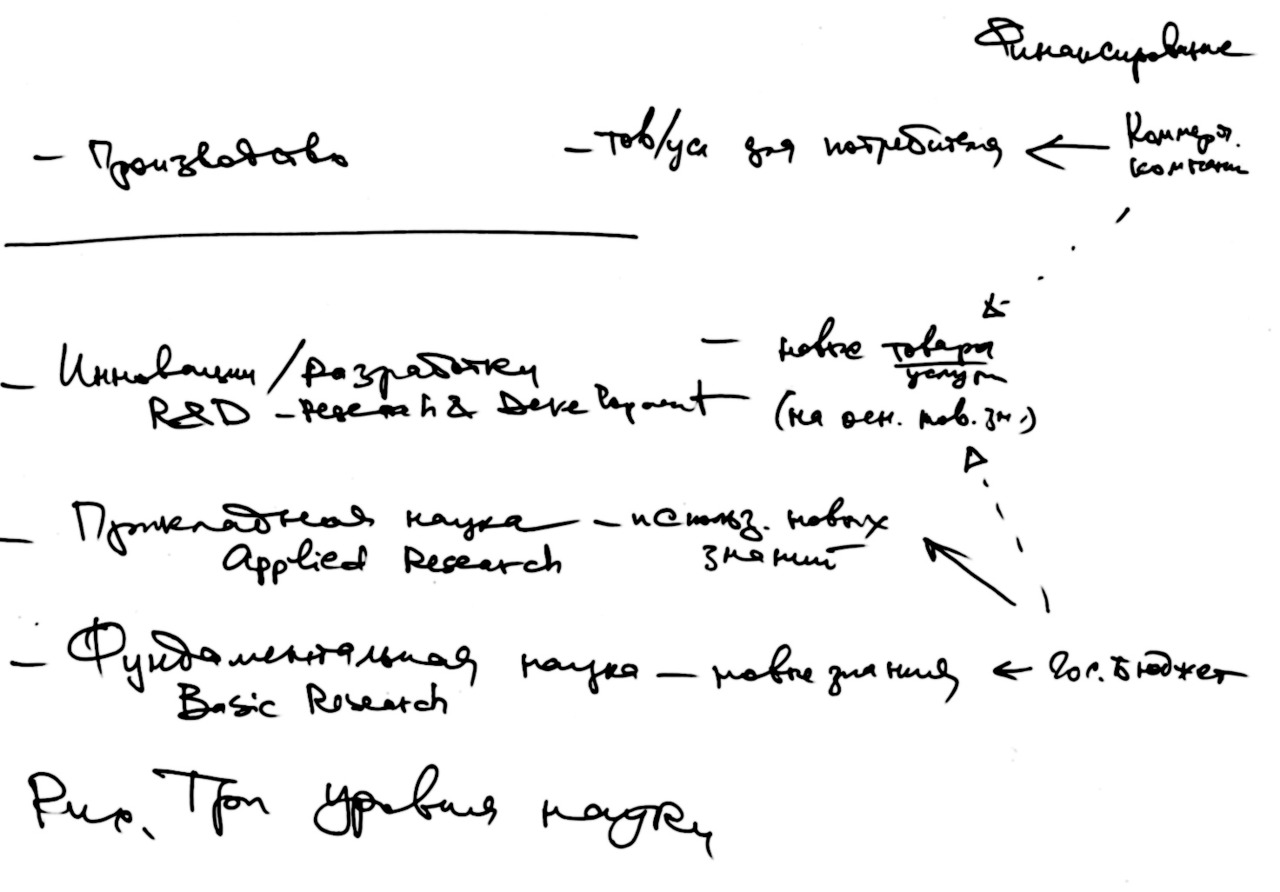
Например, физика и химия изучают вещества, которые состоят из атомов. Атомы организованы в кристаллическую решетку. Между атомами могут перепрыгивать электроны — от одного атома к другому. Изучением таких явлений на уровне атомов молекул и электронов люди занимаются десятилетиями. А научный результат такой работы — это сообщение о научных открытиях. Это статьи и книги.
Понятно, что такой результат невозможно продать какому-нибудь предприятию. И ещё. Не все коммерческие предприятия готовы финансировать такие длительные и «непрактичные» исследования. Поэтому финансированием фундаментальных исследований должно заниматься государство.
По определению государство — это страна и её руководители, цель которых — обеспечить существование своей страны, населения и сохранение территории не просто на ближайшие годы, а на ближайшие столетия. Лучше даже на ближайшие тысячелетия.
Без государственного финансирования фундаментальная наука существовать не может. Это должны понимать те, кто решают вопрос об использовании государственного бюджета — руководители министерств (исполнительная власть) и различные депутаты и парламентарии (законодательная власть).
Второй уровень науки — это прикладные исследования, прикладная наука. Судя по названию, это приложение новых знаний к какой-то реальной задаче, то есть это использование новых знаний. Фундаментальная наука получает новые знания, а прикладная наука начинает их использовать.
В примере изучения атомов и электронов можно продолжить эти исследования и разработать новые материалы. Если к кремнию добавить немножко другого вещества, он приобретает новые свойства. В конечном счёте можно получить так называемый полупроводник. Обычный проводник — это вещество (металл, жидкость или газ, или что-то ещё — типа плазмы), через которое протекает электрический ток в любом направлении. Полупроводник пропускает электрический ток в одном направлении, и не пропускает его в обратном направлении. А ещё некоторые полупроводники начинают светиться при пропускании через них электрического тока.
Это очень интересное явление, но сам полупроводниковый материал всё ещё нельзя продать. Над этим ещё нужно поработать. И такую деятельность тоже, в основном, нужно финансировать из бюджета. Такие работы тоже занимают годы, а то и десятилетия. Не каждая коммерческая компания готова ждать 20 лет до появления нового продукта. Коммерческому инвестору хочется вложить средства и получить отдачу через год, а лучше через полгода. Если дольше — тогда проще вложиться во что-то более «рентабельное».
Третий уровень науки, который основывается на результатах двух предыдущих уровней, это научно-технические разработки и инновации. Именно здесь результаты научных исследований и новые знания превращаются в коммерческий продукт. Это то, что можно продать. Это то, что будет пользоваться спросом у предприятий и у отдельных граждан. Продуктом инновационной деятельности может быть новый товар или новая услуга. С точки зрения предприятий (потребителей инноваций) инновациями может быть новая технология производства товаров или предоставления услуг. Ещё инновациями может быть новое лекарство, новое вещество, новый вид растений или животных.
Инновации строятся на результатах фундаментальных и прикладных исследований. Если не будет фундаментальной и прикладной науки, то ни на чем и не из чего будет строить инновационные продукты. Поэтому в инновационную деятельность вкладывают средства и государство, и коммерческие предприятия.
Чтобы выжить в условиях конкуренции, предприятия стараются опередить своих конкурентов и быстрее предложить потребителям новый товар или услугу.
Продолжим наш пример с атомами, электронами и полупроводниками. Новый товар — это светодиод. Это полупроводниковое устройство, которое излучает свет.
Первые светодиоды появились несколько десятков лет назад. Они используются до сих пор как индикаторы включения какого-нибудь прибора. Свет у них не слишком яркий.
В последние годы на рынке появилось множество совершенно новых, сверхъярких светодиодов. И это действительно инновации. На сегодняшний день они используются вместо фотовспышки в мобильных телефонах.
И, конечно же, у нас появились энергосберегающие светодиодные лампы. Они потребляют на порядок меньше энергии, а выдают света столько же, сколько и лампы накаливания. Прежние поколения ламп накаливания производили световой поток за счёт нагревания металлической нити. При этом большая часть энергии уходит на тепло, а не на освещение. Светодиодные лампы гораздо более экономичные.
Это и будет примером инновационного продукта — нового товара, созданного на основе результатов прикладных исследований, которые в свою очередь основаны на результатах фундаментальных исследований.
В тексте главы второй Федерального закона можем найти именно такие выражения: фундаментальные и прикладные исследования, научно-техническая деятельность, коммерциализации научных и научно-технических результатов, инновационный продукт и инновационный проект.
Задание. Ознакомьтесь с текстом Статьи второй 127-ФЗ о науке и научно-технической деятельности.
Управление
Как мы увидели, инноватика включает понятие управления. Это управление техническими и организационными, социальными системами.
Напомним, что управление — это деятельность по достижению поставленной цели. Одной из первых работ по теории управления является книга Норберта Винера «Кибернетика». Книга написана около 80 лет назад. В ней автор сформулировал основные идеи, касающиеся любого процесса управления. Он указал, что управление — в отличие от производства — является информационным процессом.
При производстве товаров или предоставлении услуг чаще всего работники имеют дело с материальными объектами, с энергией, с клиентами. Управляющий, руководитель, менеджер, а также любая система управления имеют дело с информацией. И эта информация о состоянии объекта управления — то есть того, чем управляют, см. рис.
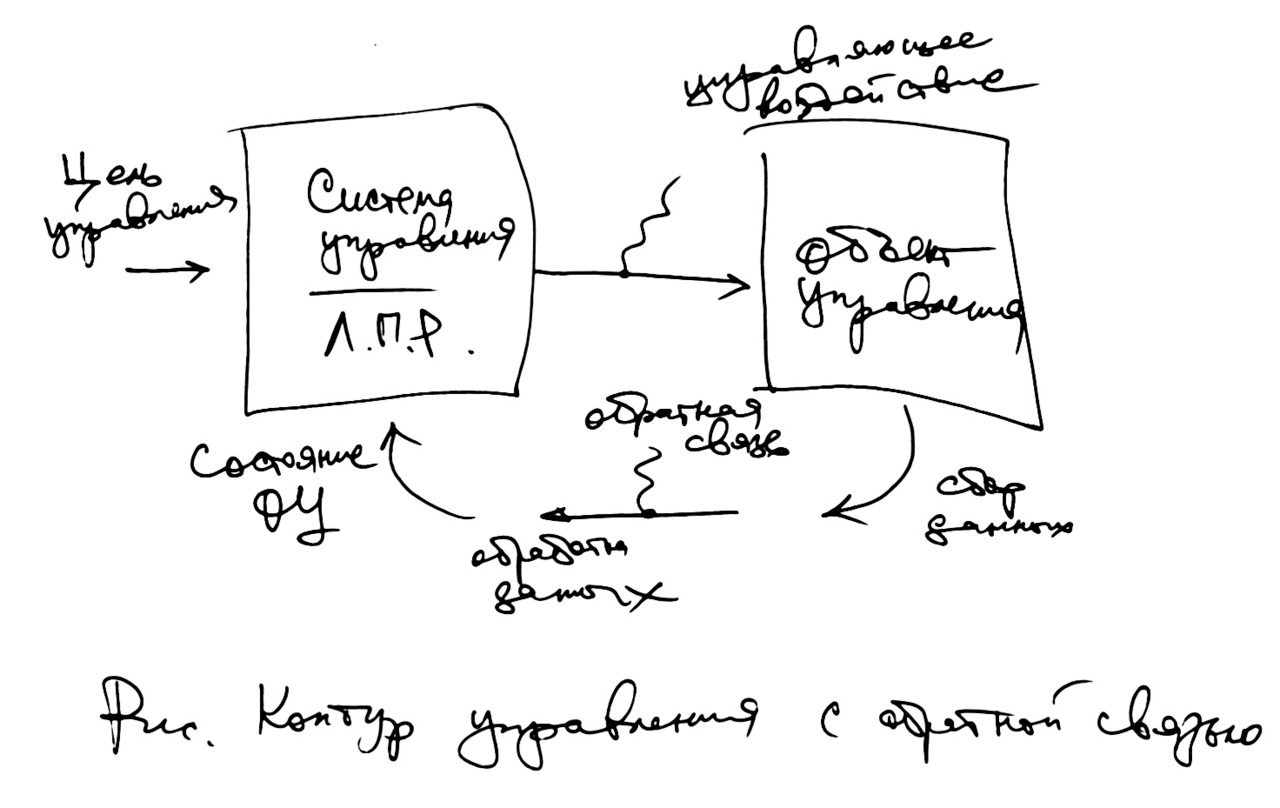
Руководитель и система управления оказывают управляющее воздействие на объект управления. Это передача информации в прямом направлении — от регулятора к объекту. Такую передачу можно назвать «прямая связь».
Но для того, чтобы принимать управленческие решения, чтобы руководить, чтобы рулить, требуется следить за тем, как идут дела. Получение сведений о состоянии объекта управления Винер назвал «обратной связью». Это передача информации в обратном направлении — от объекта к регулятору, руководителю.
В технике система управления может называться словом «регулятор» или «контроллер». В организационном управлении эту функцию выполняет руководитель, администратор, менеджер, супервайзер. Все эти слова означают одно и тоже — «управлять».
Задание. Посмотрите в Вики-словаре определения слов управлять, руководить, менеджер, руководитель, контроллер, регулятор, администратор, супервайзер. Обратите внимание на общие черты, присущие этим понятием.
Кибернетика
В названии своей книги Норберт Винер заложил всю идею теории управления. Полное название книга звучит так: «Кибернетика, или управление и связь в животном и машине».
Общую идею управления с обратной связью можно проиллюстрировать на схеме, см. рис.

Управление по-английски называется control. На сегодняшний день слово control чаще используется как управление в технических системах. Если речь идёт об управлении предприятием, людьми — это менеджмент.
Далее идёт слово связь. В английском оригинале это communication — то есть обмен сообщениями или передачи информации.
Ну и наконец, эти процессы управления внутри животного, живого организма, в технических объектах, в организации, на предприятии и в обществе, в социальных системах — любое управление любым объектом имеет общие закономерности.
В управлении предприятием — в менеджменте — есть свои классики. Приведём пример: «пять функций менеджмента», которые описал Анри Файоль.
Задание. Попробуйте расположить пять функций менеджмента на схеме, как показано на рисунке.
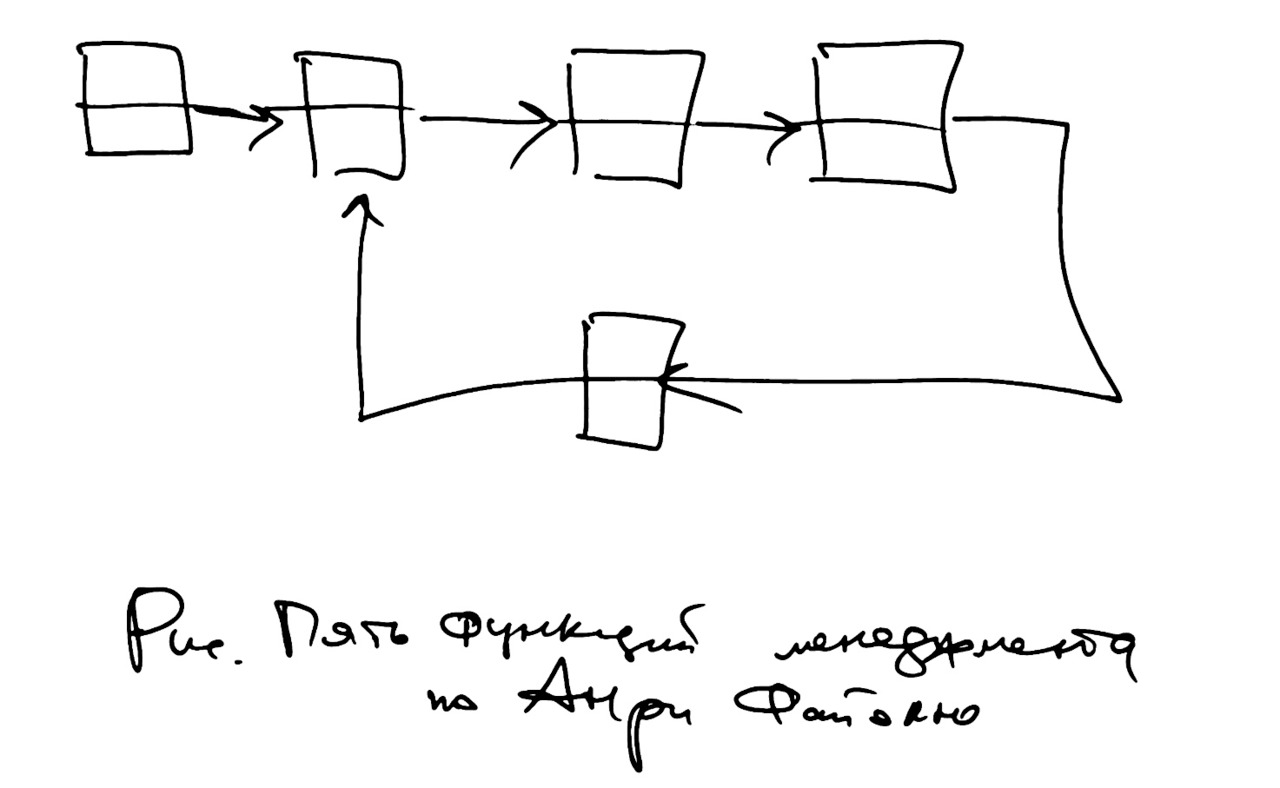
На этой схеме, которую мы описали в самых общих чертах, имеется ОБРАТНАЯ СВЯЗЬ. Здесь производится сбор и обработка данных для того, чтобы оценить состояние объекта управления. Фактически, этим занимается статистика.
Вся схема в целом часто называется «контуром управления». Слово «контур» взято из электроники, и буквально оно означает «цепочка деталей, по которой протекает электрический ток», то есть «электрическая схема».
В переносном смысле контур управления — это последовательность действий, шагов, функций по обработке информации в процессе управления чем-нибудь.
Цель управления
Кроме того, в любом процессе управления должна быть цель — конечная или промежуточная. Что нужно достичь, куда нужно прибыть или попасть.
Поговорим о цели управления. Вообще говоря, цель — это желаемое состояние или пункт назначения, см. рис.
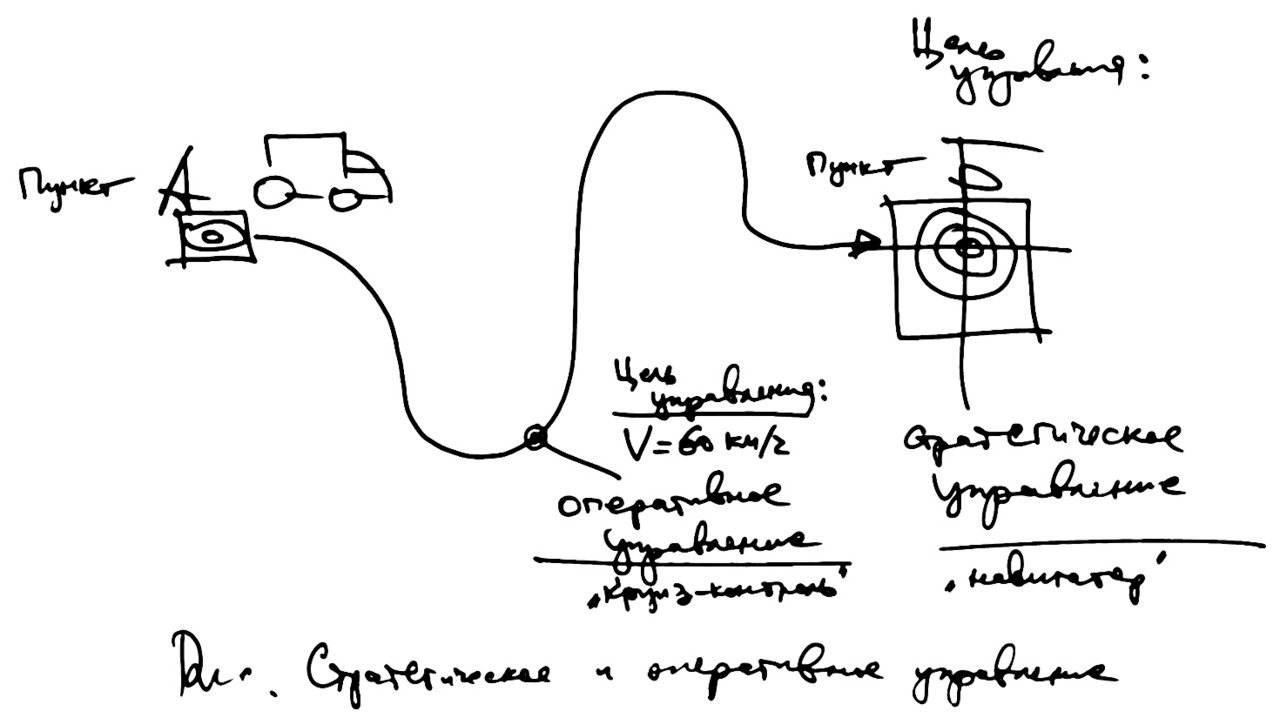
Рассмотрим пример движения автомобиля из пункта А в пункт Б. Конечная цель — это прибытие в пункт Б. Чтобы достичь этой конечной точки, нужно проложить маршрут. На сегодняшний день это делается с помощью навигатора — отдельного устройства либо программы для смартфона. По существу, это можно назвать стратегическим управлением.
С другой стороны, во время всего движение может быть очень желательно поддерживать определённую скорость. Например, нужно ехать со скоростью около 60 километров в час. Это тоже цель управления, но теперь это оперативное управление. Примером такой системы может быть круиз-контроль, то есть система автоматического поддержания заданной скорости движения машины.
И постоянная скорость, и прибытие в конечный пункт — это примеры целей управления.
Статистика
Сбор и обработка данных — анализ данных для решения задач управления — существует столько же времени, сколько существует управление как профессия и как функция.
Можно сказать, что вначале обработкой данных занималась математика. По определению, математика работает с числами и геометрическими фигурами, см. рис.
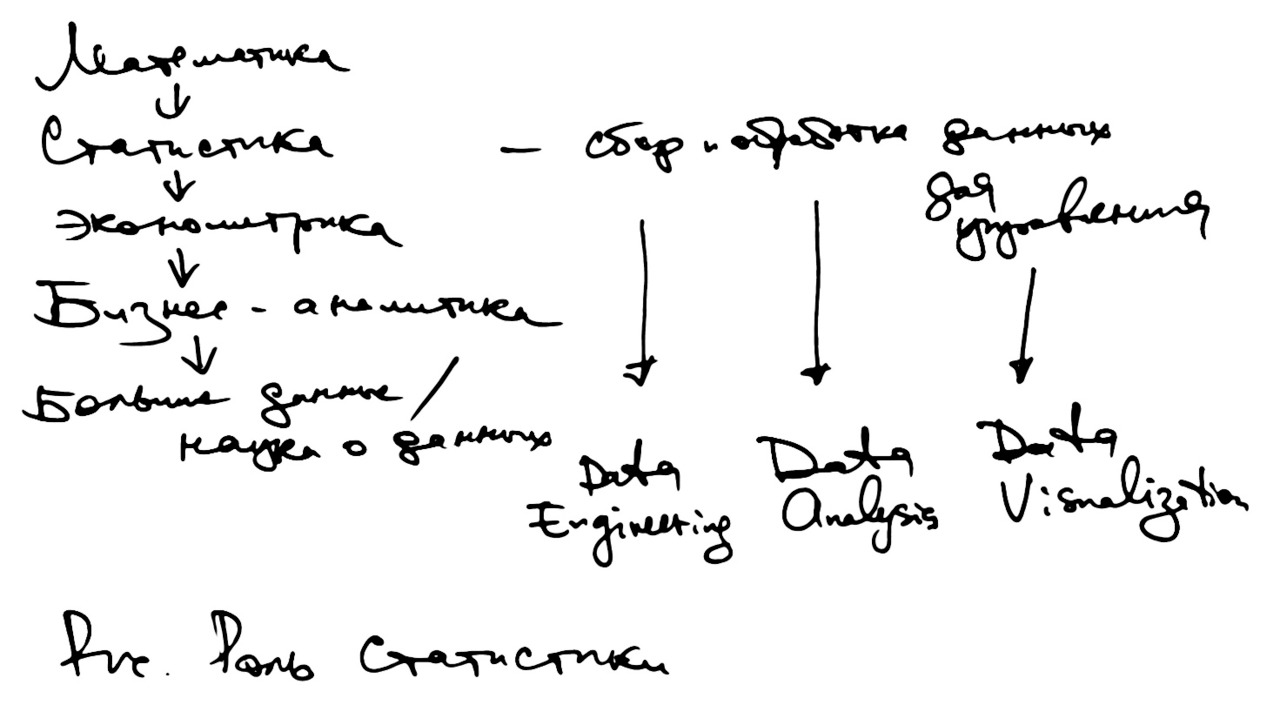
Со временем появилась отдельная дисциплина — статистика.
В ХХ-м веке выделилось отдельное направление статистики на стыке с экономикой под названием эконометрика. Эконометрика занимается построением моделей экономических систем по реальным данным.
Затем появилось новое название для той же самый деятельности по обработке данных — бизнес-аналитика.
В последнее время стали все чаще говорить про Большие данные (Big Data) и про Науку о данных (Data Science).
Если внимательно посмотреть на определения и объяснения, в каждом случае мы находим три основных действия по работе с фактическими данными: сбор данных, обработка данных и представление результатов для человека, принимающего решения.
Если говорить о больших данных, здесь используют красивые английские названия:
— Data Engineering;
— Data Analysis;
— Data Visualization.
Получается, что за каждым красивым названием по-прежнему скрывается сбор и обработка данных, то есть статистика, которой уже несколько сотен лет.
Статистика занимается случайностью, случайными явлениями. Случайность не обязательно является полностью непредсказуемой. Для описания случайных явлений в статистике используется вероятность и распределение вероятностей. Эти понятия мы будем изучать и использовать.
Можно сказать, что в статистике имеется три основных раздела: описательная статистика, аналитическая статистика и методы визуализации — статистические таблицы и графики, см. рис.

Задание. Изучите оглавление любого учебника по теории статистики и обратите внимание на три перечисленные направления.
Бизнес-аналитика
Что касается бизнес-аналитики или по-английски Business Intelligence (BI), здесь имеется некоторая игра слов. Если в названии товара и услуги присутствует слово «бизнес», можно ожидать более высокой цены. Сравните: «обед» и «бизнес-ланч». Сравните: «тренер», «консультант» и «бизнес-коуч».
На самом деле слово «бизнес» не обязательно означает «зарабатывание денег» или «экономическую деятельность с целью получения прибыли».
Другое значение слова «бизнес» — это предприятия, компании, организации. Таким образом, бизнес-аналитика — это анализ работы предприятия. Можно перечислить десятки разных названий для этой деятельности, например, экономический анализ, см. рис.

На сегодняшний день существует ряд программных продуктов, которые реализует технологии бизнес-аналитики.
Показатели
Результаты статистической обработки данных — это обобщенные показатели, то есть числа, которые ПОКАЗЫВАЮТ, как идут дела, показывают нам состояние объекта управления.
Могут быть и другие названия для обобщенных показателей: индикаторы, индексы, меры, метрики, агрегаты. Все эти слова означают одно и то же: «показатель», см. рис.

В последнее время у больших руководителей стало модно говорить про ключевые показатели — KPI — Key Performance Indicators. Это выражение можно перевести как ключевые показатели эффективности, результативности, работы, функционирования.
Однако, следует иметь в виду одну неприятную сторону показателей. Они только ПОКАЗЫВАЮТ состояние дел. Они не являются продуктом, результатом работы предприятия.
Не имеет никакого смысла требовать достижения показателей. Сам показатель не является целью управления. Как мы уже говорили, цель управления — это попасть в нужную точку или поддерживать нужное состояние.
Разберём простой пример. Чтобы оценить состояние организма пациента, врач измеряет температуру тела и давление крови. Можно ли требовать достижения заданной температуры?
Можно ли ставить целью лечения достижение температуры 36,6?
Если цель лечения — это температура, достаточно дать пациенту таблетку от повышенной температуры — жаропонижающее. Затем можно выписать пациента и на следующий день он может отправиться в реанимацию или в морг.
Мы не работали с причиной повышенной температуры или пониженного давления. А причиной болезненного состояния могла быть инфекция, воспаление, перелом костей, разрыв сосудов, язва желудка и прочие неприятности. Если не искать причину, а бороться только за показатели, это очень плохо закончится.
На самом деле показатели только говорят нам о том, что дела идут не так, как должны. После этого необходимо выяснить причину ухудшения ситуации. Или даже причину улучшения ситуации. А затем нужно работать именно с причиной. Тогда можно добиться стабильного улучшения показателей.
Задание. Просмотрите в Википедии статью Ключевые показатели эффективности.
Детализация
Для поиска настоящих причин может использоваться процедура погружения в данные. Английское название Drill-Down. Это выражение может переводиться как «провалиться в данные», «опуститься в данные» или как «детализация», см. рис.
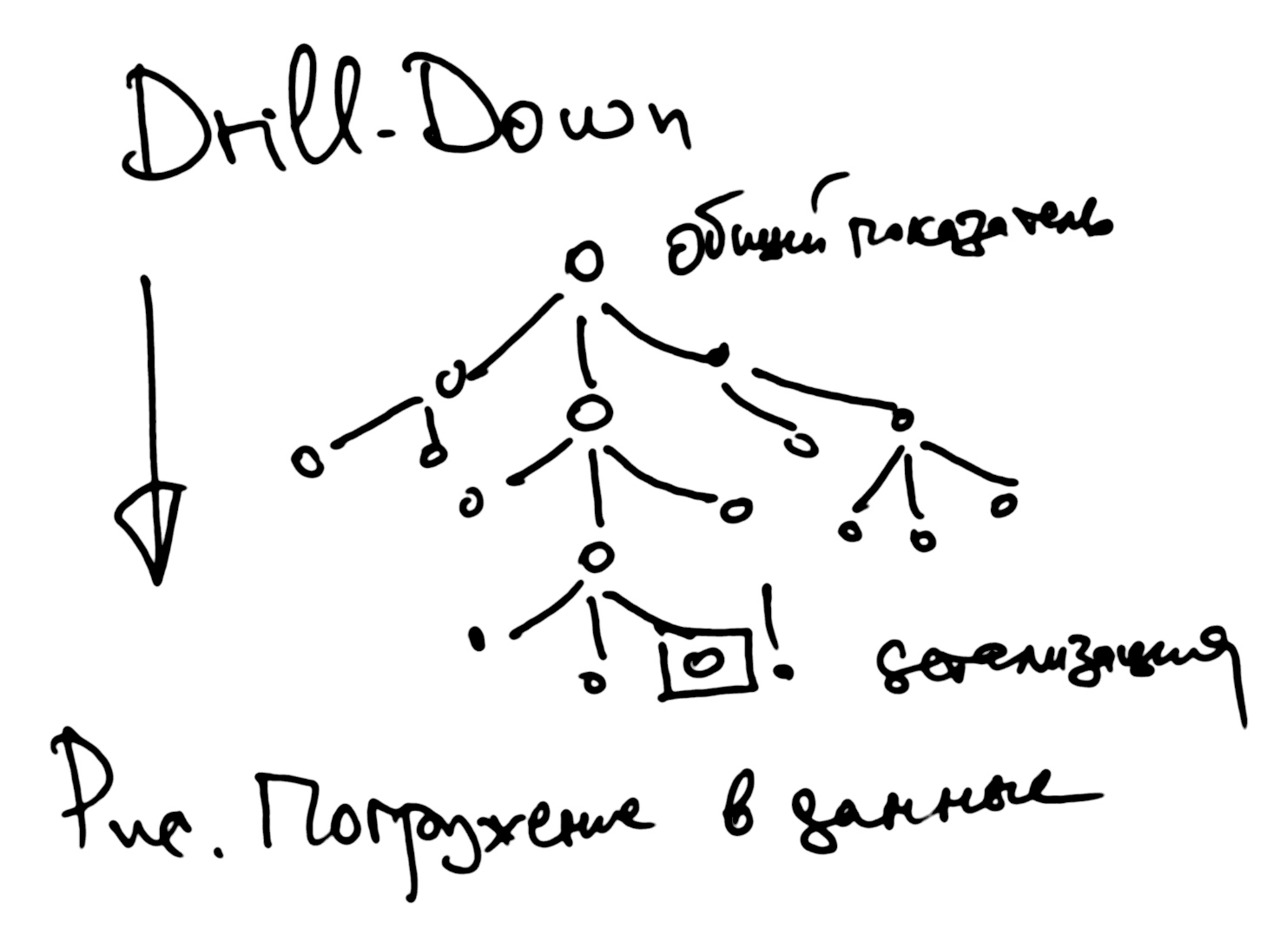
Мы опускаемся с общего показателя, с уровня предприятия в целом до конкретного подразделения, до конкретного исполнителя.
Задание. Просмотрите в Википедии англоязычную статью Data drilling.
Визуализация
Обобщенные показатели — это несколько чисел, описывающих состояние объекта управления. Очень часто обобщенные показатели выводится на один экран виде приборов, похожих на измерительные приборы. Такая информационная панель или панель показателей называется словом дашборд, дэшборд, Dashbord. Буквально это слово переводится как «приборная доска автомобиля» или «приборная панель».
Водителю автомобиля приходится следить, прежде всего, за текущей скоростью движения. Поэтому прибор, показывающий скорость — спидометр — самый большой по размеру, см. рис.
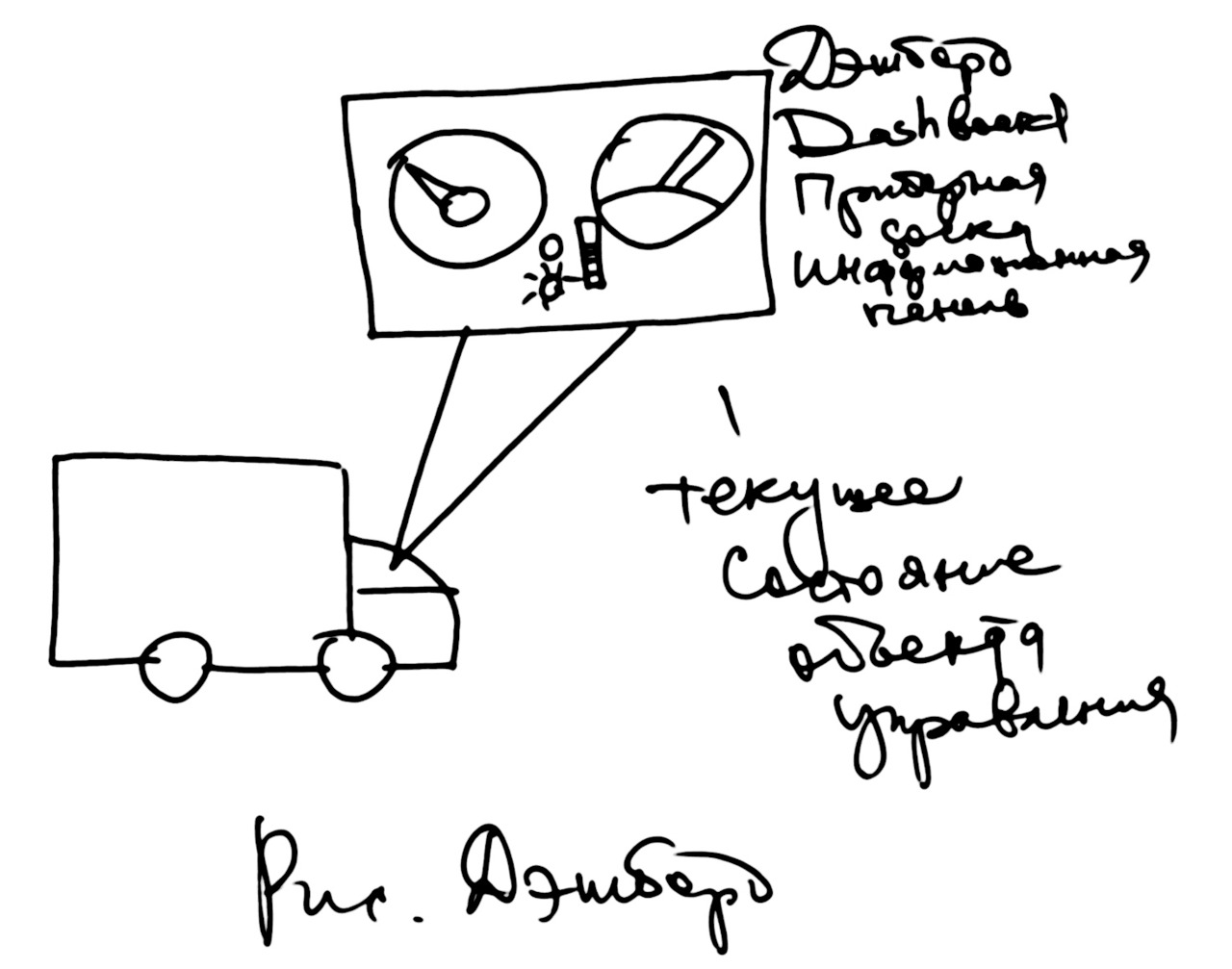
Обычно рядом такого же размера прибор показывает состояние двигателя. Это тахометр, который показывает частоту вращения, или обороты двигателя. Это второй по важности показатель.
Есть и другие важные параметры, на которые водителю приходится посматривать: количество бензина в баке, температура двигателя, положение ручного тормоза и так далее.
Современные программные средства визуализации позволяют создать программную имитацию такой приборной панели. Очень часто Dashboard руководителя сравнивают с приборной доской водителя автомобиля. В обоих случаях это обратная связь от объекта управления, это состояние объекта управления.
Статистика и инноватика
Статистика и её современная реализация — Большие данные –могут найти применение в управлении инновациями, см. рис.

С одной стороны, статистика играет роль обратной связи в процессе управления. Другими словами, статистика — это инструмент управления, менеджмента.
Кроме того, методы анализа данных позволяют создавать новые, инновационные продукты — товары и услуги, использующие анализ больших данных. Это могут быть инструменты маркетинга, продвижения товаров или просто новый метод поиска информации, или новая рекомендательная система.
Профессии в больших данных
Очень условно можно выделить три функции, три направления или три профессии в области работы с большими данными, см. рис.

Исследователь данных или Data Scientist — это специалист, который разрабатывает методы анализа больших данных. По большому счёту, его нельзя назвать учёным. Это, скорее, исследователь на уровне прикладной науки.
Второй вид специалистов — это инженер по подготовке данных. Английское название: Data Engineer. Он занимается сбором данных и их подготовкой для анализа. Это колоссальная работа.
Есть на эту тему известная шутка. Специалисты по большим данным 80% времени тратят на подготовку данных и 20% времени на жалобы о том, что они тратят 80% времени на подготовку данных.
Третья профессия — это аналитик данных — Data Analyst. Аналитик данных занимается анализом данных. Он использует данные, которые подготовил инженер по данным, и применяет к ним методы анализа данных, разработанные или предложенные исследователем данных.
Так что все эти три профессии взаимосвязаны. Если предприятие небольшое, то все три функции выполняет один специалист. На большом предприятии может быть три, или десять, или сто человек, занимающихся анализом данных.
Виды аналитики
В настоящее время выделяют четыре уровня, или вида аналитики, см. рис.

Описательная аналитика просто описывает то, что происходит сейчас, или то, что происходило в прошлом. Описательная аналитика отвечает на вопрос: «Что случилось, что произошло?»
Диагностическая аналитика — это ответ на вопрос: «Почему это произошло?» Врач ставит диагноз и находит причину болезни. Менеджер находит причину желательных или нежелательных изменений.
Третий вид аналитики — предсказательная, прогнозная или предиктивная. Это ответ на вопрос: «Что будет?» Это прогноз развития событий на будущее.
Наконец, четвёртый вид аналитики — это предписывающая аналитика. Это ответ на вопрос: «Что нужно сделать, чтобы улучшить ситуацию или не допустить ухудшения ситуации?» Можно сказать, что это своеобразный «рецепт» или метод лечения. Это рекомендации.
Беременная школьница
Несколько лет назад в американских газетах журналисты с удовольствием смаковали подробности конфликта между сетью супермаркетов и одной американской семьей.
Родители пожаловались на рекламу товаров для беременных и новорождённых. Сеть магазинов прислала рекламу на адрес школьницы. Руководителям отдела рекламы пришлось принести извинения.
А через пару недель извинения принесли уже родители школьницы. Как оказалось уроки сексуального просвещения принесли свои плоды, и школьники начали практически применять полученные знания — в меру своего понимания.
Таким образом, сеть магазинов узнала о состоянии организма девушки раньше, чем её семья.
Следующая волна статей объясняла, как магазин узнал о грядущем прибавлении семейства. Это технологии больших данных.
Каждый покупатель использует дисконтную карту для получения небольшой скидки при регулярных покупках. Это означает, что в базе данных супермаркета хранится вся история покупок каждого клиента. Если провести анализ всей этой базы данных, выяснится некоторая закономерность. Если клиент изменяет состав покупаемых товаров определённым образом, то в среднем через девять месяцев этот покупатель начинает приобретать товары для новорождённых. Это статистика, это поведение в среднем для данной категории покупателей.
Следующая волна статей выражала озабоченность клиентов магазина использованием их персональных данных. Это вмешательство в личную жизнь.
Наконец, было найдено решение. Теперь в подобной ситуации рекламу по-прежнему целевым образом присылают каждому клиенту. Но товары для новорождённых соседствуют с газонокосилкой, мебелью и кухонными принадлежностями — всё на одной странице. Формально уже нет повода для жалобы. Но, по существу, это таргетированная реклама, основанная на анализе, прогнозе, предсказаниях и рекомендациях.
Задание. Выясните название сети магазинов, о которой писали в вышеописанных статьях. Добавьте это название в поисковый запрос и просмотрите найденные статьи.
Регрессия
Продолжим обсуждать материал, касающийся регрессии. В прошлый раз мы с ним немного познакомились.
Постановка задачи
Напомним, в чём состоит идея. Наши исходные данные — это множество каких-то иксов и игреков — в простейшем случае, см. рис.
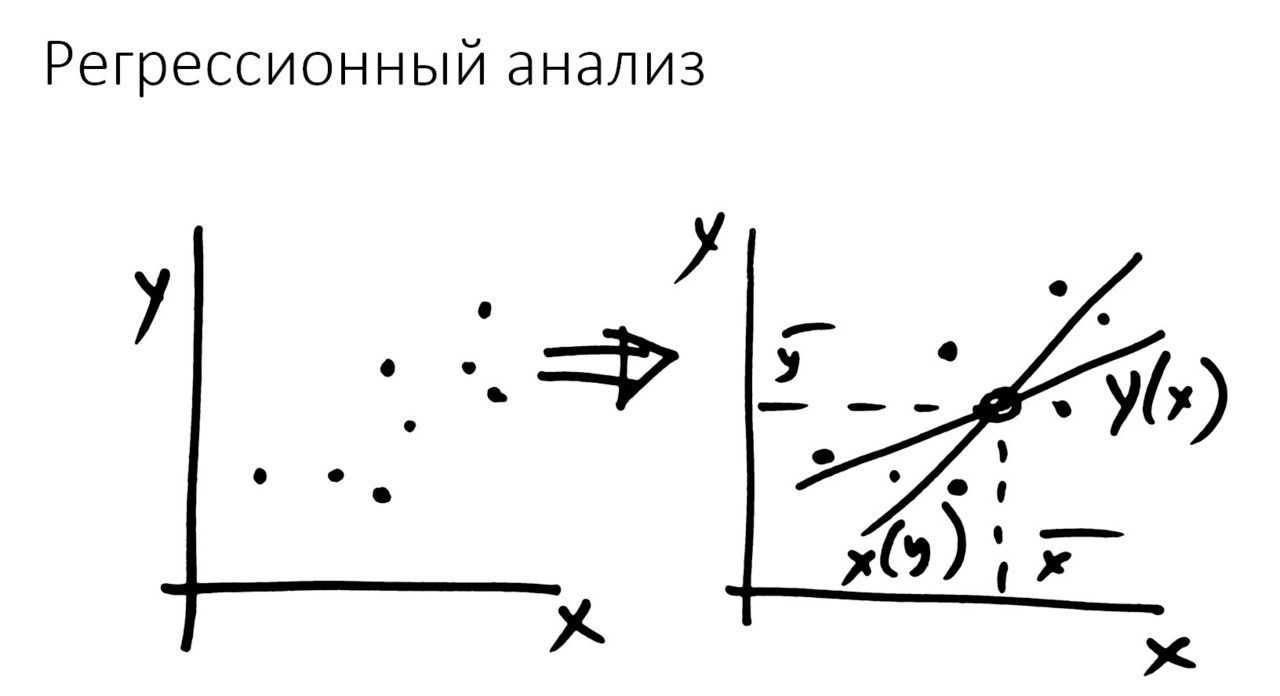
Задача ставится так: нужно выяснить, есть ли хоть какая-то связь между ними. Связь может проявляться как прямая или кривая линия. В результате регрессионного анализа мы получаем уравнение и линию на графике. Эта линия должна проходить как-то «в среднем» по этим самым точкам.
Так что первоначально мы имеем просто множество точек, см. рис.
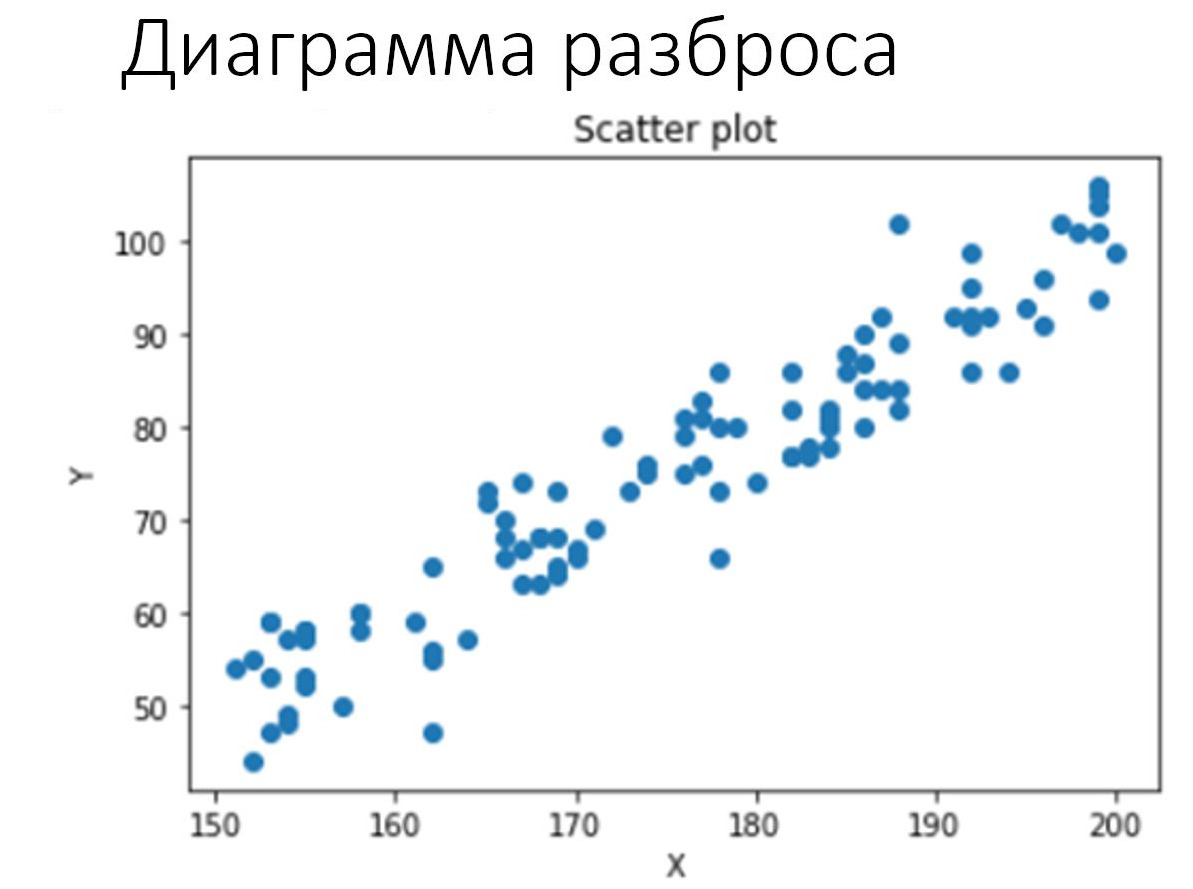
Если по этим точкам просматривается какая-то закономерность, тогда эту закономерность пытаются выразить с помощью формул и графиков.
Естественно, перед тем, как этим заниматься, кто-то должен поставить такую задачу. Например, нам нужна математическая модель, по которой мы сможем предсказывать — хотя бы приблизительно, в среднем –сколько будет стоить квартира. Для этого мы берем все данные, которые у нас в открытом доступе имеются. Это могут быть тысячи или даже миллионы объектов недвижимости.
По такому набору данных нам в конечном счете предстоит какую-то линию провести и получить какое-то уравнение, см. рис.
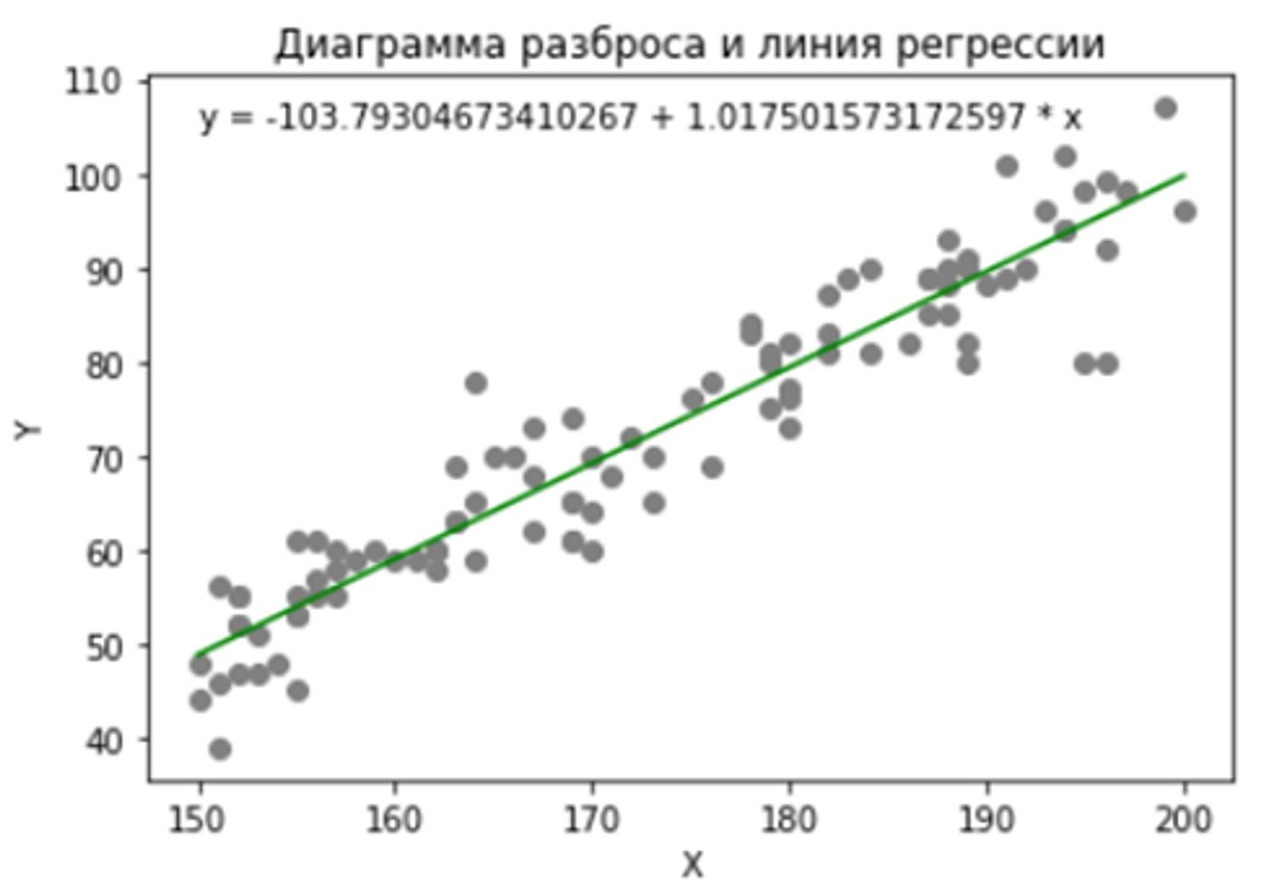
Вот в общих чертах то, чем занимается так называемая «регрессия». Само слово «регрессия» в нашем случае означает просто «линия, которая в среднем проходит по точкам».
Для этого чаще всего используется так называемый метод наименьших квадратов, сокращённо — МНК, см. рис.
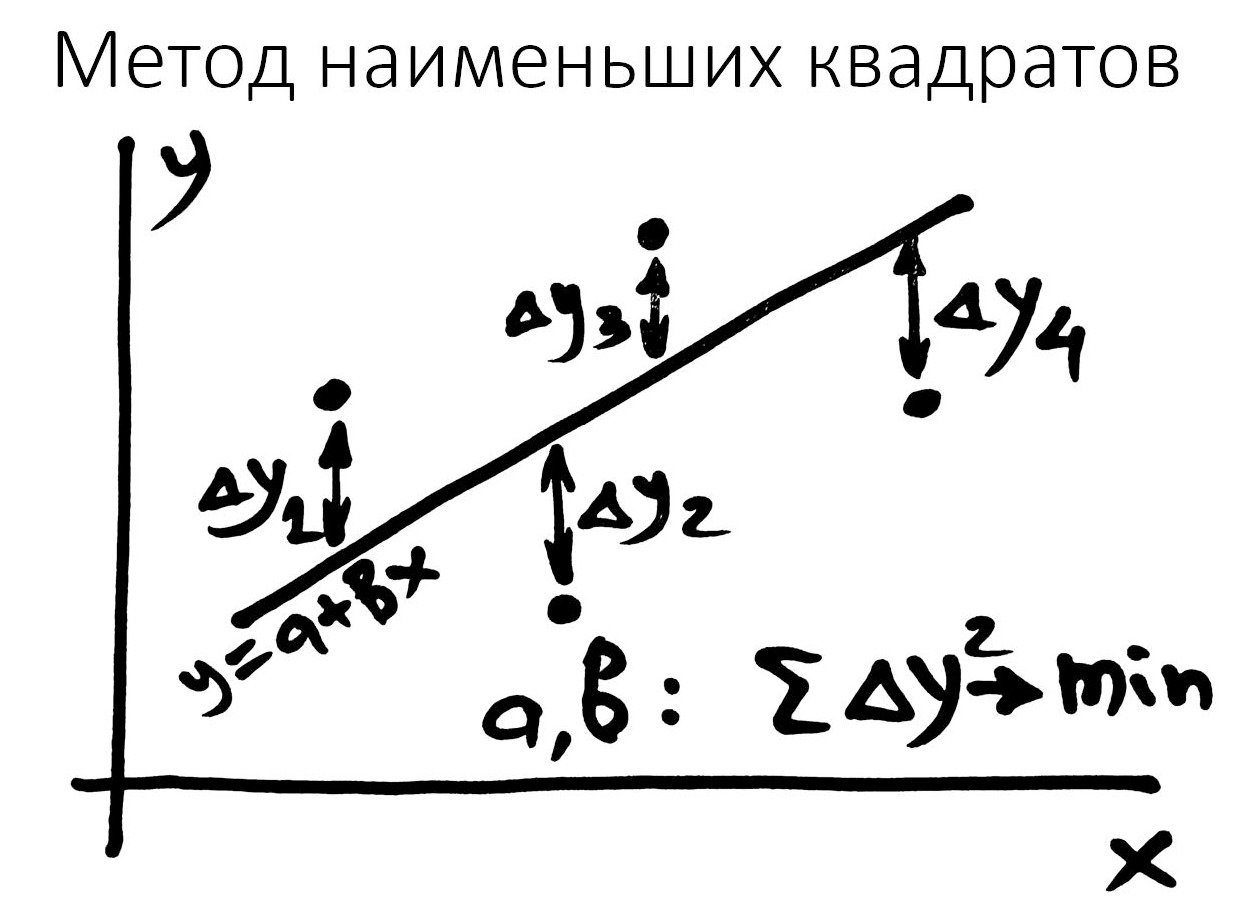
Идея МНК сводится к тому, что нужно найти коэффициенты уравнения:
y = a + bx.
Эти коэффициенты должны удовлетворять определенным требованиям. Вот наши условия: минимальная сумма квадратов отклонений, то есть расстояний от каждой точки до будущей линии. Так мы можем расшифровать название: «метод наименьших квадратов».
Особенность МНК в том, что здесь расстояние от точки до линия измеряется по вертикали. Это разность по игрекам. В этом есть определённый смысл. Когда мы оцениваем качество наших прогнозов, мы говорим: вот фактическая стоимость квартиры, а вот то, что предсказала наша модель. На сколько рублей они отличаются? Это и есть «разница по игрекам».
Дальше выясняется: неважно, каким способом решается задача. Полученная линия пройдёт примерно в одном и том же месте.
Для решения задачи регрессии можно использовать решение системы нормальных уравнений, или какие-нибудь решающие деревья, или какие-нибудь нейронные сети — всё, что угодно. Всё это называется «математические модели».
Если говорить о более сложных вещах, то это уже так называемые методы искусственного интеллекта.
Конечно, есть отдельный предмет, учебная дисциплина под названием «Искусственный интеллект». Обычно в этом курсе рассказывают про нейронные сети и про то, что с их помощью можно делать — распознавать речь или заниматься классификацией. Есть самые разные задачи, которые этот искусственный интеллект может решать. Например, в нашем вузе студент идёт по коридору и может видеть себя на большом экране. Подходит ближе к камере, и система распознаёт лицо, обводит в рамочку. Заодно фиксируется лицо человека, определяется личность и наличие маски. Можно просто распознавать, в какой части кадра находится лицо. Можно по лицу ещё и личность человека определить, если его фотографии уже есть в базе данных. Здесь решается масса задач.
Вернёмся к нашей проблеме — как провести линию в среднем по точкам и как предсказать цену квартиры. Здесь тоже может использоваться нейронная сеть. На входе будет площадь в квадратных метрах, на выходе — цена в тысячах рублей.
Самый простой вариант регрессионной модели — это парная линейная регрессия, см. рис.

Слово «линейная» означает, что это прямая линия на графике или уравнение, где икс участвует в первой степени.
Слово «парная» использовано потому, что у нас в уравнении имеется только ПАРА переменных — один икс и один игрек. Эти переменные называют по-разному. В настоящее время их называют словом «признаки», или по-английски FEATURES.
«Статистические признаки» — это СВОЙСТВА объектов, которые выражаются числами. И эти признаки участвуют в нашем уравнении, в нашей модели.
Вернёмся к исходным данным. У нас не просто прямая линия. Эти точки имеют некоторый разброс вокруг прямой линии. Поэтому в модели так или иначе присутствует случайность. Она обозначена буквой е, что означает случайность — от слова ERROR, то есть «ошибка». А ошибка обычно бывает случайной, непредсказуемой. Поэтому в наших прогнозах обязательно будут некоторые ошибки, неопределённость.
Интерпретация
Далее выясняется, что это уравнение — это модель «чего-нибудь», какого-то объекта, системы, явления, процесса. Например, можно подсчитать, сколько тратят на разные статьи расходов — в среднем — люди с разными доходами или семьи с разными доходами.
Это традиционный пример из эконометрики, см. рис.

Что-то они тратят на предметы долгосрочного пользования. Что-то они тратят на продукты питания — это расходы на потребление. Что-то они откладывают на будущее — это уже накопления.
Можно провести опрос, собрать такие сведения, а потом построить модель по этим данным:
y = 50 +0,5 x.
В переводе на русский язык это будет означать: при увеличении дохода на 1000 рублей человек в среднем будет тратить на 500 рублей больше. Естественно, это просто придуманный, «игрушечный» пример.
Коэффициент при иксе может оказаться и больше единицы. Человек начинает больше зарабатывает и на радостях начинает брать кредиты. Тогда он тратит больше, чем зарабатывает. Естественно, это долго продолжаться не будет.
Тем не менее, по реальным данным строится модель того, что происходит на самом деле.
Это то, что называется «интерпретация», то есть «перевод с математического языка формул на русский язык».
Погрешность оценок
Вообще говоря, если взять любой программный продукт, выясняется, что после регрессионного анализа мы получаем не только уравнение — само по себе, см. рис.

Это можно наблюдать и в пакете типа Excel или Libre Office Calc. В любом пакете типа «электронные таблицы» есть такая функция или надстройка, которая занимается регрессией.
В нашем случае в первой колонке у нас полученные значения коэффициентов уравнения регрессии: –108 и 1,05.
По ним можно написать уравнение:
y = — 108 +1,05 x
Но кроме этих коэффициентов, у нас есть погрешности для каждого коэффициента, результата. Если у нас используется метод наименьших квадратов, то погрешности определяются почти автоматически. Excel сразу выводит их в одной таблице.
Полученные погрешности можно представить таким образом. У нас есть коэффициент а — и для него имеется сигма а. Есть коэффициент b — для него имеется сигма b.
Напомним, что сигма — это стандартное отклонение, или среднеквадратичное отклонение. Это подробно изучается в курсе «Статистика». Если нужно, посмотрите эти материалы и освежите основные идеи в памяти.
В конце данного пособия вы найдёте ссылки на видеозаписи лекций по статистике и эконометрике — чтобы было общее представление, что за этими цифрами стоит.
Самое главное: в любой модели будут коэффициенты. Это будет какое-то уравнение. Для каждого коэффициента будет его неопределенность, или погрешность, или возможная ошибка.
Это будет означать что у нас коэффициент –108 плюс минус погрешность, то есть имеем на самом деле некоторый интервал, диапазон значений.
Так вот, их соотношение — сама величина коэффициента и его возможная ошибка — это очень важный момент.
На сегодняшний день традиционные нейронные сети этого не делают. Скорее всего, вам про это даже не будут рассказывать. Только самые свежие разработки в области многослойных (глубоких) нейронных сетей подходят к пониманию проблемы. Это называется Evidential Deep Learning — «доказательное глубокое обучение». Имеется в виду обучение многослойных нейронных сетей с учётом количества и качества исходных данных.
Надо просто иметь в виду, что кроме числа в результате любых расчетов должна быть его «дельта», неопределенность. Каждый раз мы говорим: мы получили такой результат
y = 1000
Но при этом мы обязательно добавляем: плюс-минус 100.
Если не уточнять, с какой погрешностью были сделаны расчеты, то это будет неполное объяснение.
Ошибки
Если мы рассматриваем традиционный метод наименьших квадратов, то в нём есть готовые формулы. Они позволяют оценить, какая у нас будет погрешность для каждого коэффициента, см. рис.

Здесь есть оценки — сигма для коэффициента b и сигма для коэффициентов а. В этих формулах скрывается кое-какая полезная информация, которую мы попробуем извлечь.
На следующем рисунке у нас показан пример того, как проводится регрессионный анализ в пакете Python — он же Питон.
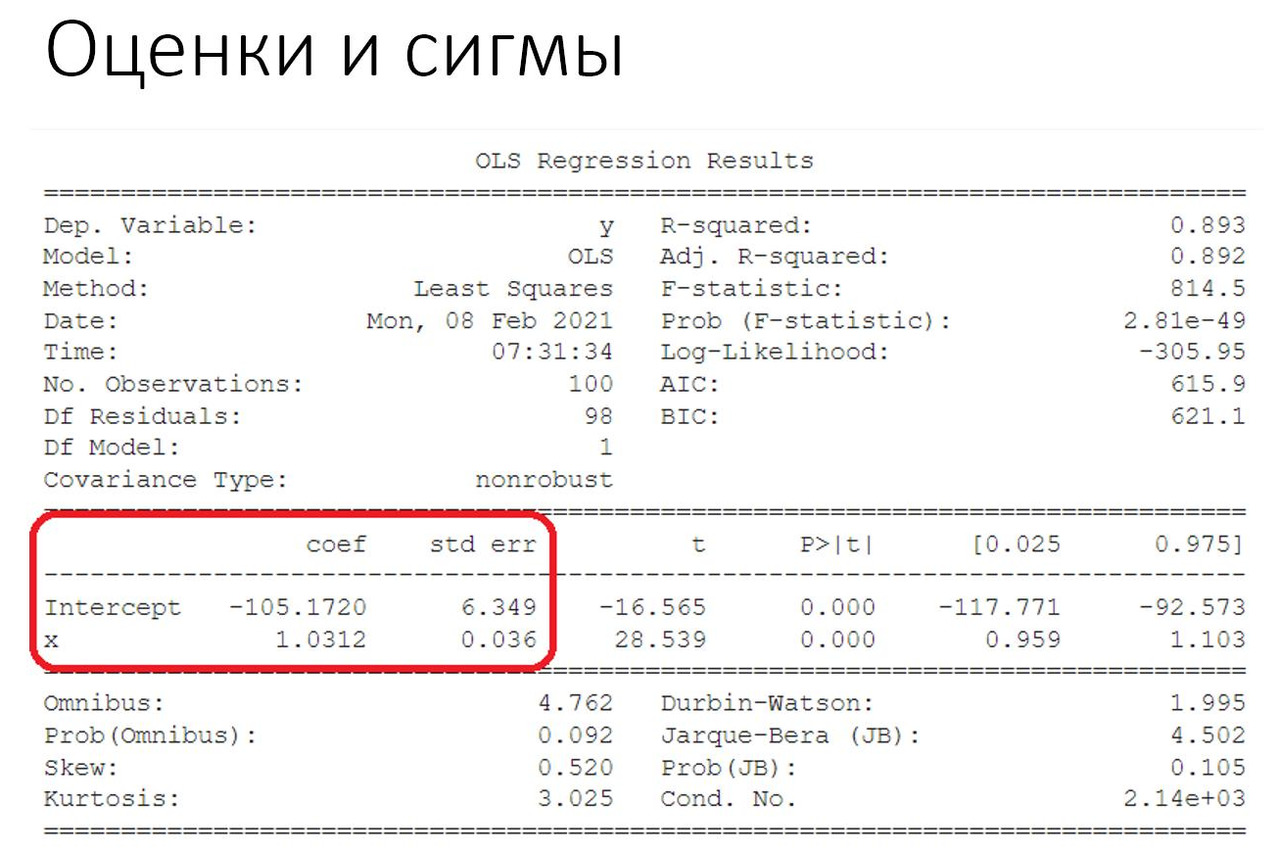
Здесь в заголовке написано OLS — Ordinary Least Squares. Это самый обыкновенный метод наименьших квадратов. Как видим, после расчетов появляется огромная таблица. В первом приближении мы берем буквально два числа — значения коэффициентов. Если чуть подробнее разбираться, для каждого коэффициента будет своя сигма. Это вторая колонка — std err — Standard Error, то есть стандартная ошибка, или проще говоря СИГМА.
Плюс к этому, есть еще масса дополнительных сведений, которые тоже нам что-то сообщают.
Имитационное моделирование
Возьмём разные наборы исходных данных. Или смоделируем разные наборы исходных данных — в цикле, см. рис.

Запускаем генератор случайных чисел и получаем набор иксов от 150 до 200.
Затем получаем массив игреков:
y = x — 100.
Это уравнение прямой линии.
К этим значениям прибавляем 5 умножить на е. Это случайный разброс. В данной формуле у нас случайный разброс, у которого стандартное отклонение 5 единиц.
Мы сформировали набор исходных данных.
Затем в последних трех строчках нашей программы происходит обучение модели. В Питоне обучение модели — это функция fit. Она сама всё вычисляет, находит коэффициенты уравнения. Но, к сожалению, нам не сообщается, какую погрешность для этих коэффициентов мы получили.
Мы можем сделать оценку погрешности косвенным образом. В данном примере цикл for позволяет нам много раз — в данном случае N = 1000 — тысячу раз cгенерировать набор исходных данных. По нему вычисляем коэффициенты. Наши коэффициенты уравнения а и b — это a [0] и a [1].
В цикле эта история повторяется, и мы получим 1000 разных значениях для коэффициента а и для коэффициента b.
Теперь мы можем построить распределение, см. рис.
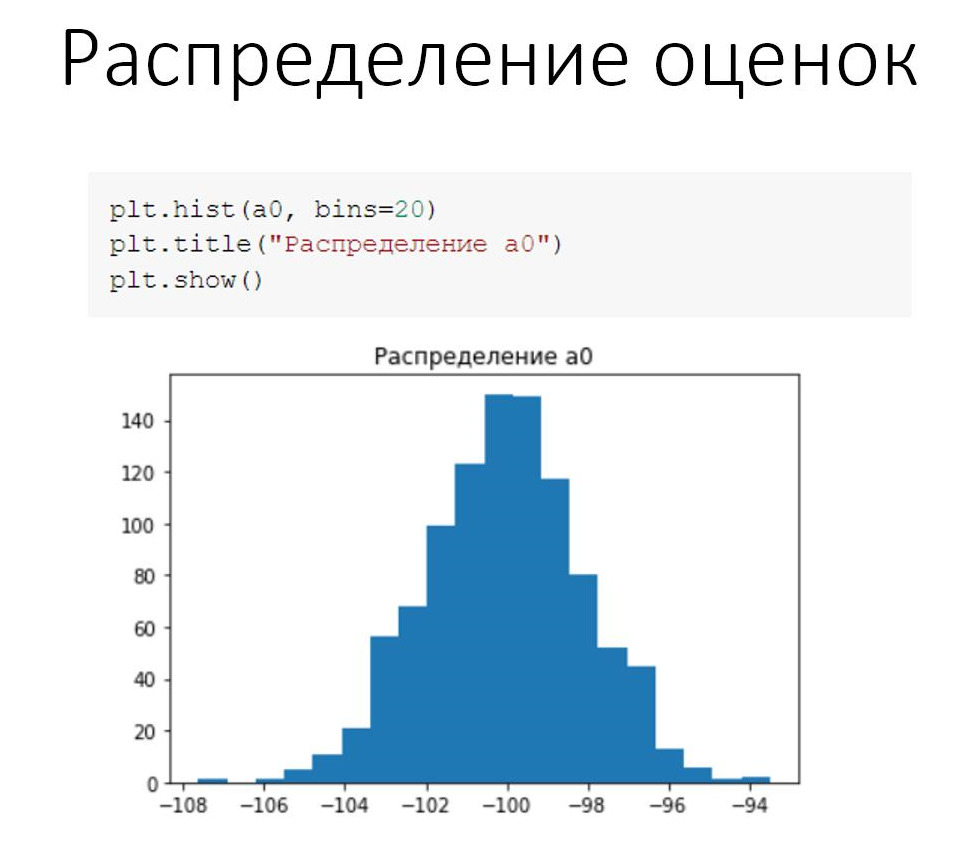
В одних и тех же условиях, для разных наборов данных наш коэффициент а0 (свободный член уравнения) оказался в диапазоне от –108 до –94.
В исходной модели мы задавали коэффициент ровно –100, а после каждого прогона мы получали плюс-минус 4, или 6, или 10.
Это самое «плюс-минус», этот самый случайный разброс присутствует и в наших исходных данных, и он же переходит на результаты расчетов. Это самая главная неприятность при обработке данных. Надо понимать, что любой результат будет содержать внутри себя некоторую погрешность.
То, что мы видим на экране, — это гистограмма. Она показывает форму распределения. В нашем случае эта форма очень похожа на то, что называется «нормальное распределение».
Управление погрешностью
Теперь поговорим по поводу погрешности.
Перед нами формула — сигма для коэффициента b, см. рис.
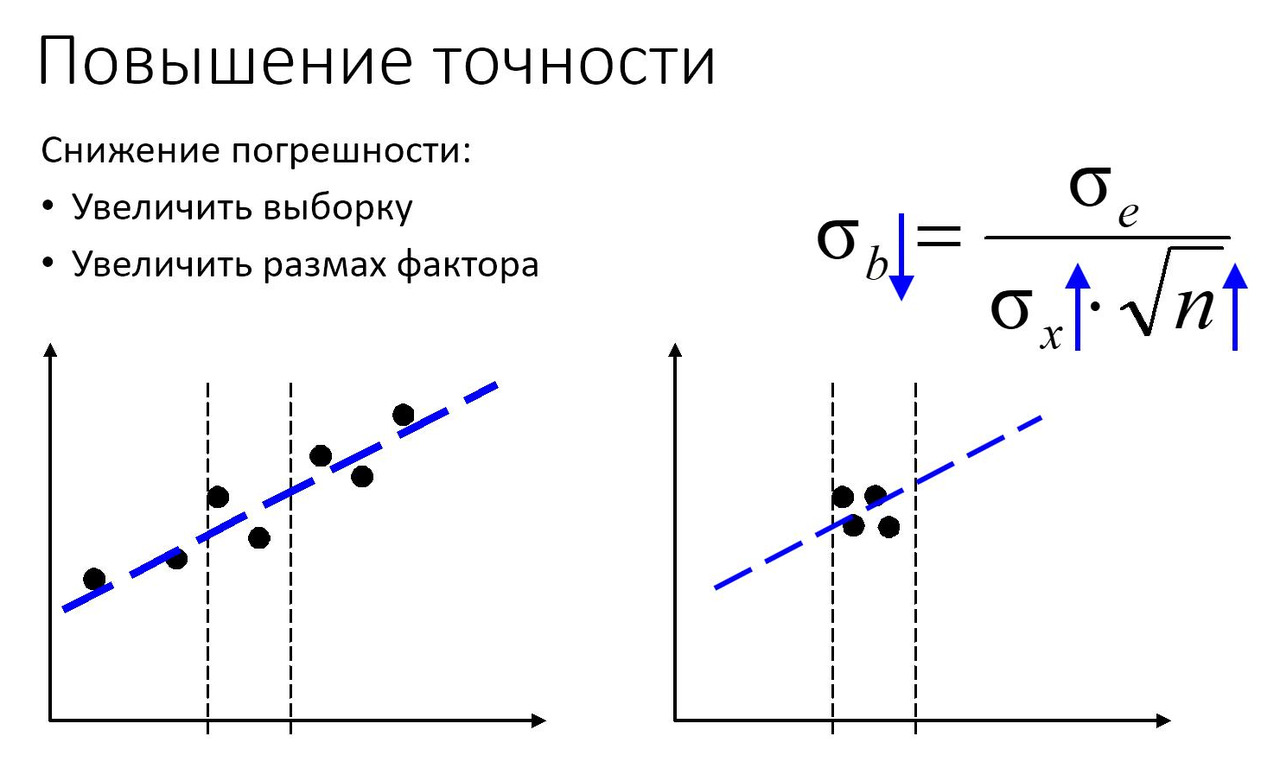
b — это коэффициент наклона, коэффициент при иксе, коэффициент регрессии. В нашем уравнении y = а + b x.
Естественно, мы хотим, чтобы ошибка этого коэффициента была поменьше. В нашей формуле есть числитель и знаменатель. Чтобы уменьшить эту ошибку — это отношение — нужно либо уменьшить числитель, либо увеличить знаменатель. В числителе находится случайный разброс, который присутствует в исходных данных. е — это случайный разброс вокруг будущей линии. Этим разбросом мы управлять никак не можем. Мы просто берём набор исходных данных. А вот то, что находится в знаменателе, — на это уже можно как-то повлиять. Что же мы видим в знаменателе? У нас имеется сигма для икса. По сути это разброс значений икса. И это то, что мы можем изменить. Если мы собираем исходные данные, мы можем сразу сказать: нам нужно получить побольше самых разных значений икса.
На рисунке внизу два графика. На графике слева большой диапазон значений икса, и по ним можно уверенно провести линию — в среднем. А вот на графике справа у нас небольшой диапазон значений икса, и они все собрались в небольшой области. Через такие точки тоже можно провести прямую линию — под любым наклоном. То есть при этом у нас погрешность возрастает — очень существенно.
Так вот, когда мы подбираем исходные данные для своих моделей, за этим приходится следить. Нам приходится выбирать эти самые иксы — как можно более разнообразные. И мы будем это делать в рамках лабораторных работ.
Вторая составная часть знаменателя — это квадратный корень из объёма выборки n. Это количество наших исходных точек на графике. Причём это количество идёт под корнем. Это означает, что если мы хотим увеличить точность в 10 раз, из-за этого корня нам придется взять данных не в 10 раз больше, а в 100 раз больше. Если мы захотим улучшить точность в 100 раз, то нам придётся увеличить объём исходных данных — 100 в квадрате — в 10 тысяч раз!
Выясняется такая интересная закономерность: цена точности, цена качества. В результате приходится заранее решать: на какое качество и на кие расходы мы согласны. Что нас устроит для решения нашей практической проблемы типа прогноза цены квартиры. Какого качества прогнозов мы можем в принципе достичь при таких исходных данных? И от этой самой неопределенности оценок нам никуда не деться.
Неопределённость прогноза
Итак, мы получили — неважно каким способом — мы получили модель, в которой скрывается неопределенность коэффициентов а и b. На что это повлияет? В конечном счёте нас интересует прогноз для игрека, см. рис.

Так вот, у нашего игрека при заданном иксе будет своя ошибка — своя сигма игрека. В этой формуле тоже участвуют разные сигми, иксы и прочее. Получается, что если мы строим прогноз, то мы тоже должны сказать: «игрек равно столько плюс-минус столько».
Если это прогноз стоимости квартиры, мы говорим: «Вот квартира площадью 60 квадратных метров, в таком-то районе города, на таком-то этаже, дом построен из кирпича или бетона, есть лифт, а расстояние до остановки 200 метров». После этого мы пропускаем наши параметры через обученную модель, делаем прогноз и говорим: «В среднем такие квартиры, в этом районе обычно стоят шесть половиной миллионов рублей». Но затем мы сразу же должны сделать оговорку: «Наш прогноз будет плюс-минус 300 тысяч». Здесь мы исходим из того какой разброс в реальных данных присутствует.
Если мы просто мы дадим свою оценку (без погрешности) — этого будет недостаточно.
Если посмотреть на общую формулу для сигмы игрека — здесь участвует сигма икса. Это разброс значений вокруг нашей линии. Чем больше разброс в исходных данных, тем хуже будет точность наших прогнозов.
В этой формуле нас подстерегает ещё одна неприятность. Здесь участвует «икс минус среднее значение», к тому же в квадрате. Это означает, что чем дальше мы от среднего значения находимся, чем ближе мы к правому или левому краю, тем хуже будет точность наших прогнозов.
Вот такая особенность имеется при построении моделей и при построении прогнозов.
Наша задача — найти точки с как можно большим разбросом. Тогда наши прогнозы будут более уверенными, более точными. Но после этого мы всё равно получим какие-то границы, причём по краям эти границы будут расширяться.
А там, где мы чего-то не знаем, этот разброс будет очень большим. Например, если мы построили прогноз для однокомнатных квартир, а потом взялись по той же модели работать с трёхкомнатными, — тут у нас качество наших прогнозов будет похуже, см. рис.
Теперь мы посмотрим, как выглядят исходные данные для первой лабораторной работы. Заходим на сайт Яндекс Недвижимость, см. рис.
Выбираем условия поиска:
— Купить
— Квартиру
— 1 комната
— Район Кировский
Видим около 600 разных объявлений только по одному району. Переходим к просмотру объявлений, см. рис.
Как видим, здесь есть новостройки и «вторичка» — рынок вторичного жилья. Выбираем вторичку — то есть квартиры, которые уже были в собственности. Скорее всего, там кто-то уже проживал.
Единичка в поле «Район» говорит о том, что мы уже выбрали один пункт из большого списка районов города.
Рассмотрим первое объявление:
Площадь — 39 кв. м.
Цена 4 млн. руб.
Стрелка рядом с ценой говорит о том, что цена уже менялась.
Дополнительные статистические признаки — цифры, которые могут пойти в нашу модель:
— номер этажа — 7
— общее количество этажей — 14
В объявлении указан адрес. Его тоже можно привязать к модели.
Другие параметры: расстояние до остановки общественного транспорта и до железнодорожной станции.
Дальше имеется словесное описание. Это текст, в котором могут быть полезные сведения и подробности.
При этом мы не видим описание самого дома:
— когда он был построен
— когда в нем был капитальный ремонт
Для поиска таких сведений приходится использовать другие источники. Добавление данных из других источников называется «обогащение данных» — Data enrichment. При этом наши данные становятся более ценными, более полезными, более информативными для анализа.
Есть ещё один аспект использования дополнительных источников. Это достоверность данных. Правда ли, что этот дом кирпичный? И что он построен именно в 1972, а не в 1962 году? Как говорится, «доверяй, но проверяй».
Мы открываем выбранное объявление и получаем некоторые подробности, см. рис. Если мы получим одинаковые или очень похожие сведения из нескольких разных источников, то доверие к ним может немного возрасти.
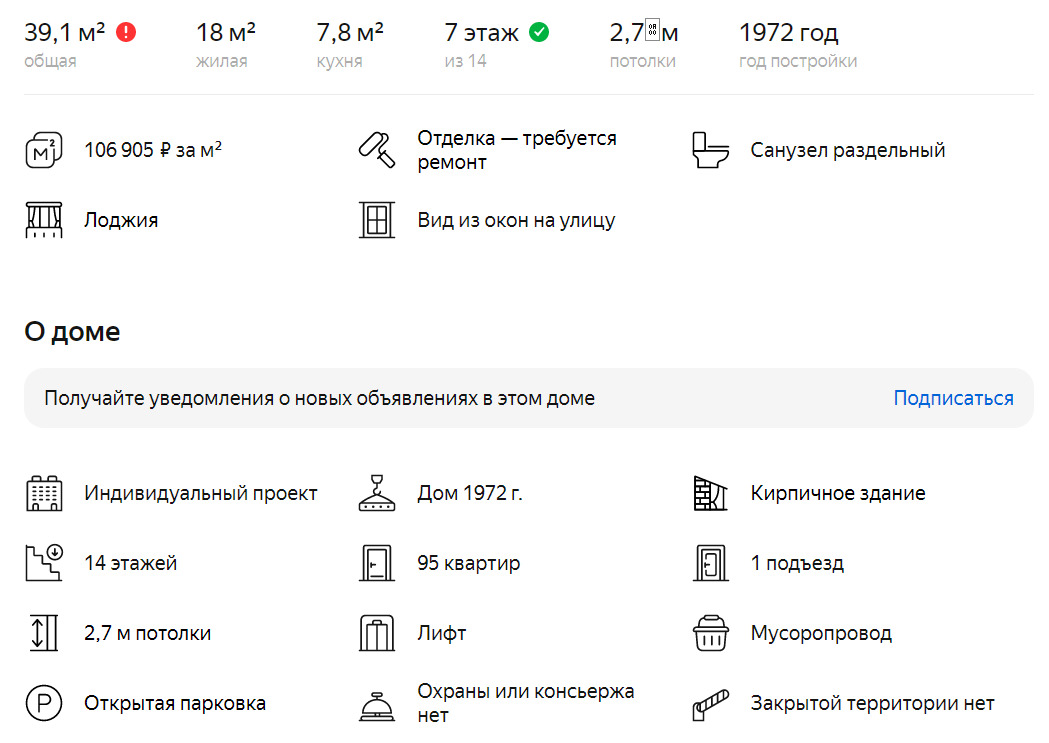
Вот наши исходные данные для анализа. Мы можем вручную «вынимать» эти сведения. Но если речь идет о сотнях или тысячах записей, естественно, нужна специальная программа для извлечения информации из базы данных или сайта. Или хотя бы для «разбора» страниц сайта с результатами поиска. В конечном счёте нам нужна табличка, где признаки организованы по колонкам, а объекты — по строкам. И в этой таблице должны быть заголовки по столбцам. Это будут названия наших переменных в модели.
Итак, мы можем собрать такие сведения — разного размера квартиры, площадь, цену, количество комнат и так далее.
Здесь участвует большое количество параметров. У нас есть цифры, которые можно сразу вставить в уравнении. А ещё есть характеристики, которые выражаются словами:
— ремонт: косметический, дизайнерский или требуется
— санузел
То, что выражается словами, тоже можно учитывать в уравнении, но уже более хитрым образом. Это называется «фиктивные переменные», и мы с ними поработаем на практике.
Возвращаемся к теории. Погрешность для прогноза по уравнению регрессии, см. рис.

По краям диапазон возможная ошибка, разброс значений расширяется. За границами известных значений прогноз становится очень «неопределенным» и очень «неизвестным». Совсем не обязательно, что это линия дальше пойдет именно как продолжение имеющейся прямой. Возможно, она изогнётся. Возможно, вообще, в принципе, таких квартир не бывает — однокомнатной квартиры площадью 5 квадратных метров. Или двадцати-комнатная квартира площадью 500 квадратных метров. Можно ли такие найти? Причём в этом районе города…
Так что здесь всегда есть ряд ограничений, которые ещё немножко эту задачу усложняют.
Значимость коэффициентов
В регрессионном анализе мы определили значения коэффициентов и их так называемые сигмы — стандартные отклонения. Теперь проверяют, насколько это существенно — влияние каждого входного параметра (икса) на выходной параметр (игрек), см. рис.

Проводится сравнение. Величина коэффициента — в данном случае 20 — и его сигма 3,3.
Фактически, мы отвечаем на вопрос: сколько сигм составляет значение коэффициента?
Эта процедура называется проверка статистической значимости. Мы делим коэффициент на его сигму и получаем какое-то число. Если это число больше 3, то можно сказать, что это значение важно, существенно — на фоне возможных случайных ошибок. То есть значение 20 гораздо больше, чем его случайные погрешности.
Во втором примере значение коэффициента регрессии составляет 1,5, а его сигма составляет 30 единиц. Сама по себе величина коэффициента вроде бы не равна нулю. Но она очень маленькая на фоне возможных случайных ошибок.
В статистике «большое» или «маленькое» считается по сравнению с возможной погрешностью. В последнем примере 1,5 даже меньше, чем одна сигма. Это отношение, которое меньше единицы, является несущественным, неважным и незначительным. Случайность гораздо больше, чем сама величина.
Получается, что этот самый икс в этом уравнении мало чего добавляет к нашей модели. В таких ситуациях этого икса просто исключают из модели. Эта технология называется «проверка значимости».
Чем сложнее модель, тем сложнее проводить такие проверки.
Если у нас два коэффициента, мы это можем очень легко расписать. А если в сложной модели таких коэффициентов пара сотен или тысяч… всё становится уже гораздо сложнее. Требуются другие технологии для того, чтобы как-то с этим справляться.
Коэффициент детерминации
Наконец, есть общая характеристика качества уравнения. Её обычно называют «эр-квадрат», см. рис.

R-квадрат означает, что это R во второй степени, причём «эр» большое — заглавная буква.
R2 — это число, которое принимает значение от нуля до единицы. И называется этот показатель коэффициент детерминации. Он определяет, насколько хорошо наше уравнение описывает наши исходные, реальные данные. Другими словами, насколько наши прогнозы будут близки к истинному значению.
В случае линейной модели и для одного факторного признака — то есть для парной линейной регрессии — этот коэффициент детерминации R2 будет равен квадрату коэффициента линейной корреляции r2. Видимо, поэтому и было выбрано такое странное обозначение. Ну а большая буква R говорит, что это что-то большее, чем просто r. Если у нас будет нелинейная модель и много факторов (иксов), то здесь уже идея корреляции проявляется более опосредованно.
На все эти моменты мы с вами будем смотреть на примерах обработки реальных данных.
Сложные модели
Теперь надо сделать замечание по поводу более сложных моделей. В настоящей модели для реальных данных приходится учитывать большое количество самых разных иксов. Как мы видели на примере оценки стоимости квартиры, кроме площади нужно учитывать еще с десяток разных параметров. После этого в нашей модели появляется соответствующее количество иксов и их коэффициентов, см. рис.

Такая модель называется множественная или многофакторная регрессия.
И здесь для каждого коэффициента снова появляется своя сигма. И потом снова надо провести проверку значимости –для каждого коэффициента по отдельности и для уравнения регрессии в целом.
Когда в уравнении участвует несколько разных иксов, их называют «факторы», или «факторные признаки», или просто «признаки», или features. А ещё их называют «регрессоры». Соответственно, наше уравнение называется «многофакторная регрессия», или «множественная регрессия». То есть участвует «множество» иксов.
Рассмотрим пример. Здесь в уравнении участвует два фактора, два признака. Один признак обозначен через X, другой — через Z, см. рис.
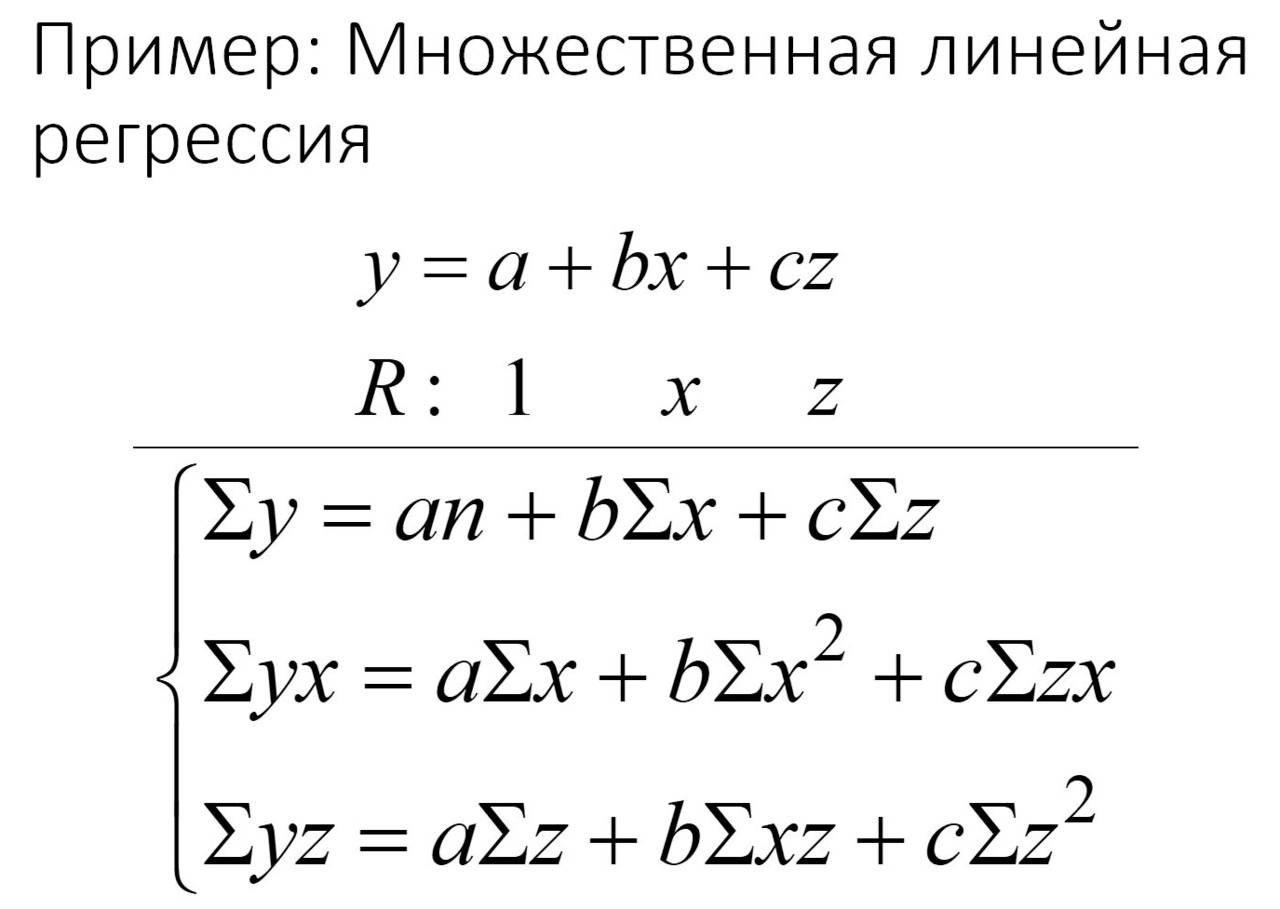
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.