
Бесплатный фрагмент - 300+ факторов ранжирования в Google
ВВЕДЕНИЕ
Книга 300+ факторов ранжирования в Google — это сборник нескольких тысяч сигналов, которые обрабатывает поисковая система, чтобы выдать пользователю наиболее подходящий ответ на его обращение к поисковику, и наиболее полно отвечающий на его запрос.
Если же вы считаете, что Google — это злой полицейский, и эта книга посвящена тонкостям обхода установленных им ограничений, которые постоянно меняются, то эта книга не для вас.
Книга рассматривает Google как искусственный интеллект, у которого первостепенная задача вывести на первое место поиска самый лучший ответ на вопрос (поисковую фразу) пользователя. И далее ранжирует менее полные, полезные и значимые ответы. Поиск Google — это самообучающий интеллект, алгоритмы (фильтры), которые постоянно совершенствуется, а работа над фильтрами приносит более 500 улучшений ежегодно.
Google щедро делится своими наработками с создателями сайтов, сообщая им как лучше сделать, чтобы конечный пользователь поверил веб-сайту, и совершил желаемое действие, которое задумал хозяин сайта.
Например, для интернет-магазина более значимыми факторами являются: уникальность авторское описание товара, оригинальная картинка (не содранные из интернета), цена, способы доставки, оплаты, отзывы, но не написанные на сайте, которые могут пишут администраторы этого магазина.
Для информационного сайта — уникальность, объем и качество изложенного материала, и другой авторский контент, например, изображения, видео, инфографика, и пр.
Поиск наиболее подходящей веб-страницы на вопрос пользователя подобен конкурсу красоты, в котором Google-алгоритмы являются главными судьями, которые отбирают лучшую по уже известным им критериям, чтобы задавшему вопрос пользователю выдать самое лучшее.
Google как никакая другая организация в мире вкладывает деньги, в свой искусственный интеллект, в двух направлениях.
— Понять, что под несколькими словами, набранными в поисковике, желает увидеть пользователь.
— Подобрать из миллиардов веб-страниц наилучший ответ.
— Алгоритмы, которыми ведётся подбор, постоянно совершенствуются, поэтому менее значимые веб-страницы падают в рейтинге. Но не по причине несправедливых карательных мер, а по причине предоставить пользователям наиболее качественные ответы.
Книга 300+ факторов ранжирования в Google — это 20-ти летний опыт работы по оптимизации сайтов под этот поисковик. По крупицам собранные факторы вошли в эту книгу.
В отличии от других авторов я прежде всего опирался на:
— Материалы, которые предоставляет Google в своих руководствах, рекомендациях, форумах, и других публикаций из открытых источников.
— Открытые выступления действующих и бывших представителей этой организации, таких как Джон Мюллер, Мэтт Каттс, Дэнни Салливан, Уди Манбер, и многих других. (Уверен, что их высказывания более ценны, чем личный опыт местных сеошников.)
— Патенты, которые приобретает Google, и которые включаются в алгоритмы ранжирования по исследованиям мировых лидеров в SEO-индустрии.
— Исследования групп экспертов по SEO из таких компания MOZ, и других мировых лидеров по оптимизации сайтов под поисковые системы.
— Личный опыт, основанный на вышеупомянутых материалах.
Я не против исследований российских SEO-специалистов, но, к сожалению, у них нет таких огромных финансовых ресурсов для исследований, как у западных компаний. Но в сети основная часть «умников», которые прочитали пару книг, и на их основании излагают свою интерпретацию, которая, порой, сильно отличается от прямых пожеланий Google по многим вопросам.
К основному недостатку моего подхода можно отнести то, что Google разрабатывает свои алгоритмы ранжирования на английском языке, а потом их вводит на других языках. Это значит, что некоторые факторы, при вашем прочтении этой книги могут быть ещё не включены в алгоритм ранжирования на русском или другом языке. Есть и большая группа уже введённых изменений расчёта веса веб-сайта, которая затрагивает связи с другими внешними ресурсами, которые влияют на вес первого сайта, и пересчёт происходит относительно долго.
Но это и преимущество перед конкурентами, которые добиваются сиюминутной выгоды, а потом поднимают шум по поводу того, что их сайт просел в поисковой выдаче.
Следующее преимущество моего описания в том, что в своих руководствах и рекомендациях показывается, как лучше оформлять контент на веб-сайтах, чтобы как можно дольше удерживать внимание пользователя, чтобы посетитель совершил действие, желаемое хозяином сайта.
Google, как никто другая в мире ведёт работу в этом направлении, и оказывает веб-мастерам неоценимую помощь. Поэтому в этой книге я рассматриваю Google, как экзаменатора, у которого оценкой является место на каком находится материал, в поисковой выдаче по каждой ключевой фразе.
Google стандарт «YMYL» (который так же рассматривается в этой книге), это первоначальный сбор информации людьми, которые анализируют страницы сайта вручную, по установленным Google параметрам, и выставляют оценку качества предоставляемой информации. Поэтому только на основании руководства Quality Raters Google уже можно сделать высоко ранжируемый сайт. Это 150 страничное руководство, которое также постоянно усовершенствуется. Его последнюю версию желающий всегда может найти в интернете.
В книге описывается 300+ факторов ранжирования, которые включают в себя несколько тысяч сигналов. Сигналы сгруппированы по факторам. Факторы рассматриваем как молекулы, а сигналы — атомы из которых собираются молекулы.
Сигналы как единицы информации для ранжирования достаточно мелки и в них можно запутаться, но группируя их в факторы легко понять принципы работы алгоритмов.
Например, при рассмотрении фактора «Начертания шрифтов» рассматриваются теги <b> <strong>.
Напомню, что первый тег рекомендовано применять для лучшего прочтения текста (как дизайнерское выделение), а вторым тегом (<strong>) выделять ключевые фразы. При просмотре веб-страницы оба тега выводят одинаковое начертание, но Google воспринимает это как два различных сигнала.
Это — два сигнала. Третьим положительным сигналом считается употребление в одном тексте обоих тегов.
Далее можно рассматривать как сигналы отсутствие этих тегов в документе, или применение только одного из этих тегов.
Тоже самое и с тегами <em> и <i>.
Сочетание на одной страницы всех четырёх тегов — это дополнительный сигнал. Отсутствие в разных сочетаниях — другие дополнительные сигналы.
Т.е. чем больше тегов используется на веб-страницы, тем больше положительных сигналов получает она.
Как видите такое дробление на уровне сигналов только увеличивает объем книги, заполняя её малозначимой информацией, только запутывает всех, и снижает уровень понимания основных факторов.
Ведущий инженер Google — Сингхал как раз и занимался разработкой системы ранжирования страниц, которая включает в себя более 2000 видов информации, или то, что Google называет «сигналами».
PageRank — это всего лишь один сигнал.
Некоторые сигналы находятся на веб-страницах — например, слова, ссылки, изображения и так далее.
Некоторые взяты из истории того, как страницы менялись со временем. Некоторые сигналы — это паттерны данных, обнаруженные в триллионах поисковых запросов, которые Google обрабатывал на протяжении многих лет.
«Данные, которые мы имеем, продвигают современное состояние», — говорит г-н Сингхал.
«Мы видим, что все ссылки ведут на страницу, как содержание меняется на странице с течением времени».
Google все чаще использует сигналы, поступающие из истории того, что отдельные пользователи искали в прошлом, чтобы предлагать результаты, которые отражают интересы каждого человека.
Например, поиск «дельфинов» будет давать разные результаты для пользователя.
Человека, который прежде посещал сайты с футбольной тематикой, Google воспринимает как футбольного фаната клуба Дельфинов, и выдаст один результат.
А для пользователя, который является морским биологом — другой. Это работает только для пользователей, которые входят в одну из служб Google, например, Gmail.
Если же Google не может определить человека, то он выдаёт оба варианта.
Как только Google отправляет свои бесчисленные сигналы, они подают в их формулы, которые Google называет классификаторами (факторами), которые пытаются вывести полезную информацию о типе поиска, чтобы отправить пользователя на самые полезные для него страницы. Классификаторы могут, например, сказать, ищет ли кто-то продукт для покупки или информацию о месте, компании или человеке.
Google недавно разработала новый классификатор для определения имён людей, которые не известны. Другой внедрённый классификатор идентифицирует торговые марки.
Эти сигналы / классификаторы определяем, как факторы ранжирования. Они рассчитывают несколько ключевых показателей релевантности страницы, в том числе тот, который называется «актуальность» — показатель того, как тема страницы относится к широкой категории запроса пользователя. Например, страница с речью президента России в Кировограде в Кремле имела бы высокую актуальность для Кировоградчан, в меньшей степени для самого президента, и ещё меньше для Кремлёвских чиновников. Google объединяет все эти факторы в итоговую оценку релевантности.
Сайты с 10-ю наивысшими баллами получают желанные места на первой странице поиска, если только итоговая проверка не показывает, что в результатах недостаточно «разнообразия».
«Если у вас много разных точек зрения на одной странице, часто это более полезно, чем если бы на странице доминировала одна точка зрения», — говорит г-н Каттс.
«Если кто-то из пользователей печатает название продукта, это может быть, например, ему нужен его обзор в блоге, или страница производителя, или интернет-магазин для покупки этого продукта, или сайт для сравнения цен…», — продолжает г-н Каттс.
Кромке факторов и сигналов в книге рассматриваются и фантомы.
К фантомам относим сигналы и факторы, которые:
— устарели и Google их уже не использует,
— сигналы, на которые ещё ведётся разработка алгоритмов, и
— факторы, придуманные сео-специалистами, которых никогда не было и не будет.
Но начнём всё по порядку.
КЛЮЧЕВЫЕ СЛОВА
В широком понимании ключевыми словами или keywords называют фразы, по которым люди ищут в поисковиках товары, услуги или другие ответы на свои вопросы.
Сеошники те, кто занимается оптимизацией и продвижением сайтов, в поисковых системах, ключевыми словами называют фразы на страницах сайта, по которым должны появляться страницы в результатах поиска в поисковиках.
Оптимизацией, или поисковой оптимизацией сайта называют комплекс работ, которые позволяют сайту поднять сайт в выдаче поисковых систем по определённым запросам как можно выше.
Продвижением сайтов в широком понимании включают оптимизацию. В узком понимании продвижением сайтов называют публикацию контента или другой информации на различны сторонних сайтах, таких как каталоги, или социальные сети, со ссылками на свой сайт с целью привлечения посетителей.
Основным понятием в строительстве сайтов были, есть и будут ключевые слова или фразы. Если прежде поиск поисковиками осуществлялся выбором соответствия фразы, введённой пользователем с наличием этой фразы на страницах сайтов, то сейчас концепция изменилась.
Как писал в первой части книги (36 фильтров Google) в Google существует специальный фильтр, который введённую пользователем фразу рассматривает как вопрос, на который пользователь желает найти ответ на каком-либо сайте.
Если, к примеру, пользователь в строке поиска введёт «купить летнюю обувь», то поисковик не понимает, что конкретно желает купить пользователь, и предложит разные варианты, например, «модные мужские туфли», «красивые босоножки», и тому подобное.
Google «понимает» вопрос, и предлагает различные варианты, которые могут не содержать именно те слова, которые ввёл пользователь, но, которые подразумевают показать ответ на поставленный вопрос.
Поэтому ключевые слова теперь с одной стороны — это вопросы пользователей, а с другой — возможность дать ответ на этот вопрос пусть и, другими словами. Ключевые слова — это ориентир, который помогает лучше ориентироваться на странице.
Да Google неоднократно заявлял, что он более не ориентируется на ключевые слова, но наша практика показывает, что он всё же учитывает заполнение этого тега, если не напрямую, то учитывает, как фактор, того, что страница качественно подготовлена и более авторитетна.
Маленький пример. Как-то к нам обратилась компания с желанием, чтобы в поисковике их сайт ранжировался выше. У них оптимизация была выполнена формально, не хуже, чем у других. Но тег ключевых слов не был заполнен. Чтобы разобраться с оптимизацией их страниц, и начать с ними работать мы попросили их заполнить тег ключевых слов. Так мы желали разобраться под какие фразы нам необходимо оптимизировать страницы их сайта.
После того как были заполнены эти теги, Google с 3-5-х страниц ответов на запросы пользователей повысил рейтинг этих страниц до 1-2-й страницы.
Невозможно точно определить прямые или косвенные факторы повлияли на увеличение рейтинга, но однозначно: заполнение этого тега на странице увеличивает её рейтинг, пусть и не так существенно, как прежде.
Однако, если статья большая (более 20 тыс. печатных знаков) и затрагивает много ключевых фраз, на которые отвечает эта страница, то заполнение этого тега может получить обратный эффект.
1 фактор. Заполнение тега ключевых слов
Ключевые фразы страницы записывают в специальном теге, называемом keywords, который размещается между тегами <head> и </head>
Формат записи тега keywords.
<meta name=«keywords» content=«Создание сайтов, оптимизация сайтов, продвижение сайтов» />
Каждая ключевая фраза записывается через запятую.
Прежде Google писал, что чем больше в этом теге указано ключевых слов, тем меньше их вес, потому как вес делится на количество записанных фраз. А в другой рекомендации декларировалось, что лучший вариант — одна фраза на одну веб-страницу. Сейчас эта рекомендация осталась в контекстной рекламе.
Ещё один фактор за этот тег keywords: он не исключён из спецификации.
Он нужен:
— создателям, для грамотного построения структуры сайта;
— оптимизаторам, потому как по нему показана под какие фразы оптимизирована страница сайта;
— хозяевам сайтов, чтобы просмотреть выполнение работ;
— аудиторам для определения качества проведённых работ;
— тем, кто в последствии будет улучшать положение сайта в поисковиках.
Ключевые фразы были и остаются камнями фундамента всего сайта. С их набора и начинается создание сайтов.
Да, можно набрать ключевые фразы, которые нравятся заказчику сайта, но они могут и не быть в обиходе у пользователей.
Например, продавец знает, что у него хорошо покупают моторное масло Castrol Edge Titanium FST 0W-30. Продавец желает, чтобы была страница оптимизирована под запрос «моторное масло Castrol Edge Titanium FST 0W-30», и считает, что кто знает это масло — тот купит. Для веб-мастера вывести на первое место страницу сайта по этому запросу — легко.
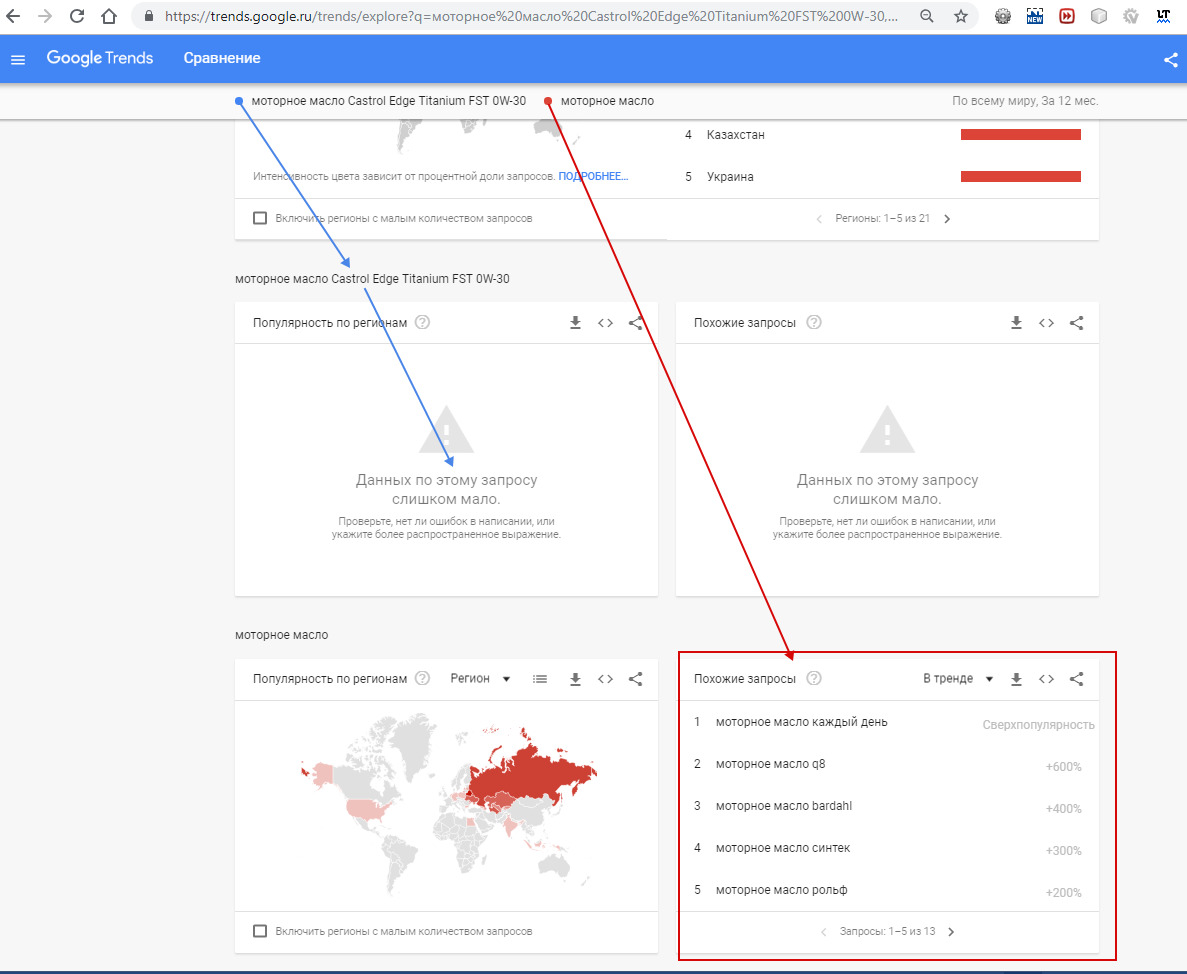
Потому что в trends.google.ru, (см. изображение ниже) синим видно, что нигде и никогда такой запрос не делают. Но видно (жёлтым), что просто «моторное масло Castrol Edge» люди ежедневно набирают по 50—100 раз в месяц.
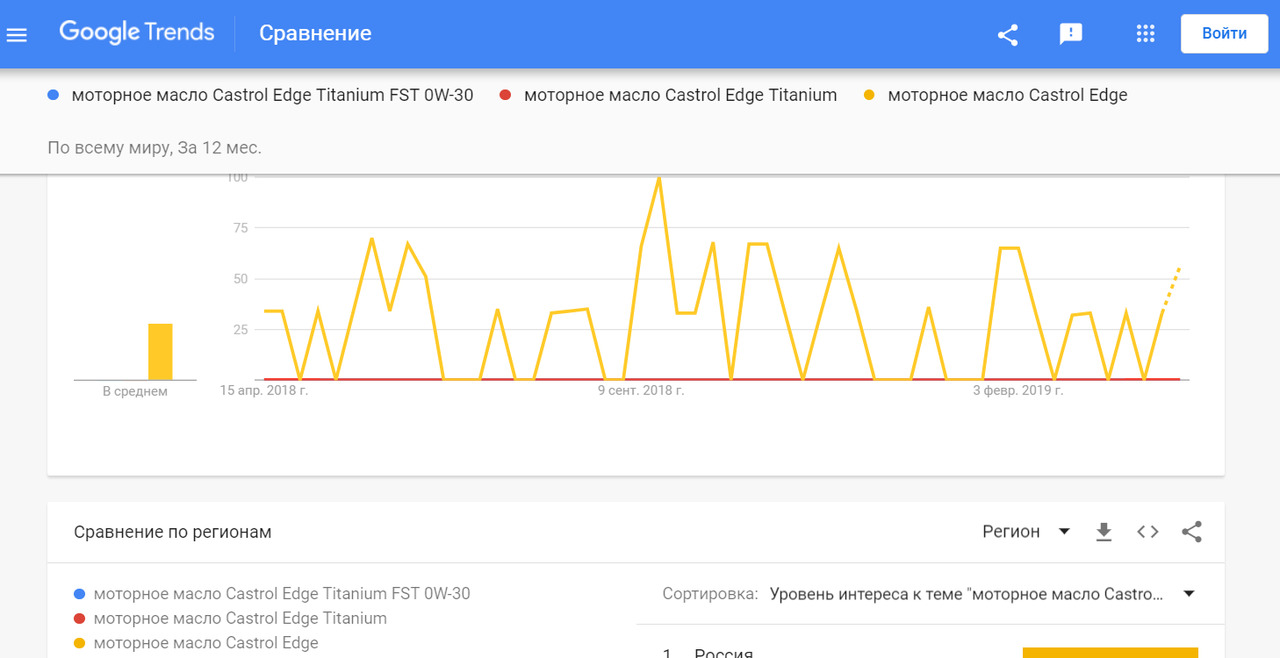
Поэтому, если требуются посетители из поисковика Гугл, то целесообразнее делать оптимизацию под запрос «моторное масло Castrol Edge».
Хотя по второму запросу конкуренция между страницами более чем в десять раз выше, целесообразнее оптимизировать страницу под этот запрос. Правда оптимизация именно под «моторное масло Castrol Edge» не такая уж простая задача, но не будем забегать вперёд.
Я люблю ловить рыбу, и люблю шоколад, но я никогда не буду ловить рыбу на шоколад, потому что рыба любит червяков, или что-то другое. Не знаю ни одного любителя шоколада, который бы пытался объяснить рыбе, что шоколад вкуснее. Каждый рыбак знает каких червяков, личинок, или др., в данный момент с удовольствием будет поглощать рыба, и подсовывает именно то, что сейчас хочет рыба.
Но почему-то заказчики сайтов считают, что они лучше знают, что нужно их посетителям.
И так, желательно проверять по каким фразам ищут товар, услугу, или др. потенциальные посетители в Google тренд, или подборе ключевых фраз. Причём желательно просматривать в том регионе, в котором желаете продавать, и в той поисковой системе, из которой желаете получать посетителей. Да Яндекс даёт более развёрнутые варианты подбора ключевых фраз, но в Google, люди могут набирать немного по-другому. Поэтому, если желаете высоко позиционироваться в двух поисковых системах, то объединяйте запросы.
(Google тренд не единственное место для подбора ключевых фраз. Для составителей контекстной рекламы Google предлагает расширенный вариант подбора ключевых фраз, которым и желательно пользоваться.)
Конечно, в каждой поисковой системе свои алгоритмы расчёта, и по-разному оценивается вес одних и тех же факторов, но подсчёт происходит по одним и тем же критериям, поэтому самый правильный вариант — делать грамотно и честно эту работу, и лидерство гарантировано.
Если продавец ещё не выбрал регион, где собирается продавать свою продукцию, то по следующему варианту скириншота можно просмотреть как в каких регионах делается этот запрос.
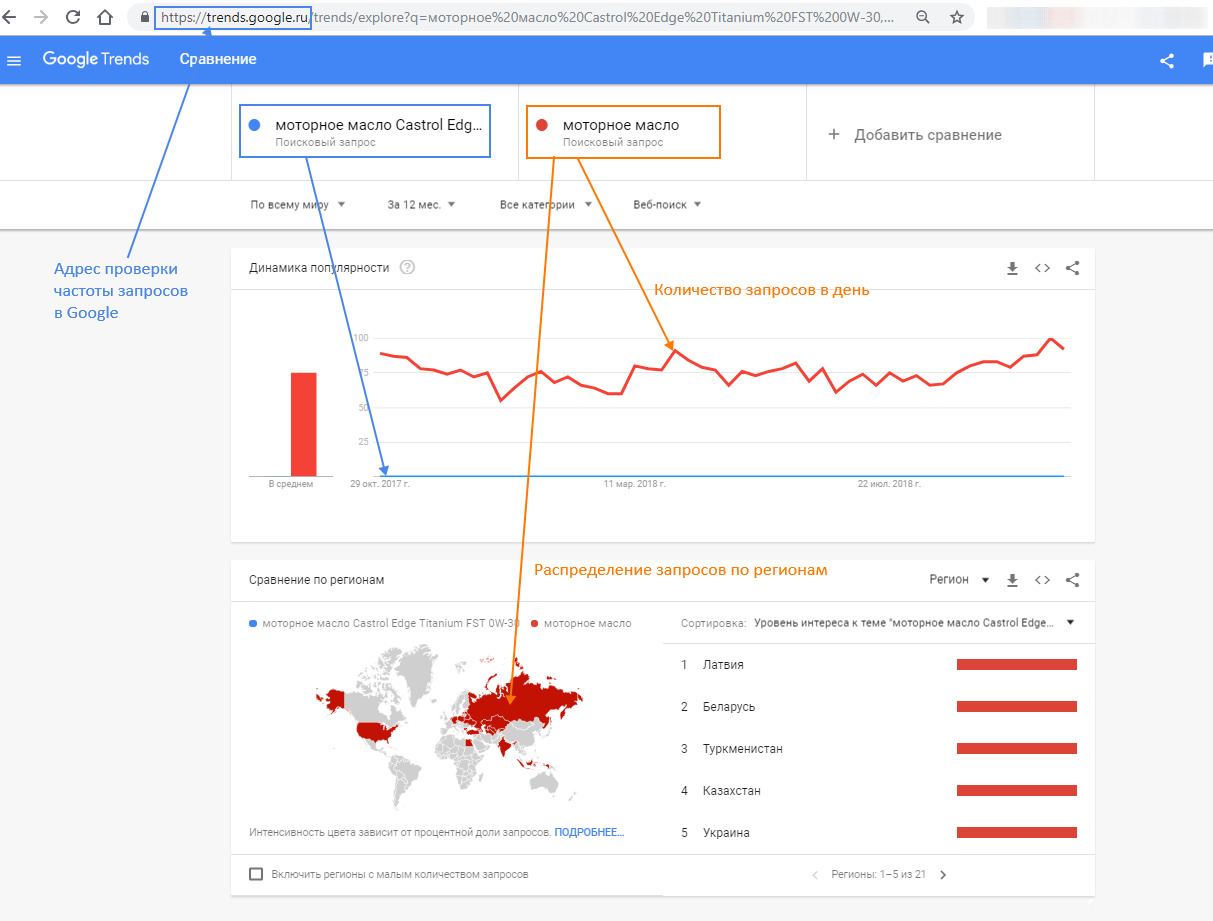
Далее Гугл предоставляет данные какие ещё дополнительно набирались с проверяемыми поисковыми фразами.
Как видно из скриншота «моторное масло Castrol Edge Titanium FST 0W-30», имеет мало запросов, и никаких дополнительных слов.
Но кроме запроса «моторное масло» пользователи набирали «моторное масло каждый день», «моторное масло q8», и ещё Google предлагает 11 вариантов.
Многие считают, что удобнее собирать ключевые слова по вариантам, которые предоставляет Яндекс Вордстат. И в этом — большой смысл, потому что расширение запросов Яндекс выдаёт многократно больше.
Минус же в том, что Яндексом и Google пользуются разные люди, и у них разные запросы, поэтому при использовании wordstat. yandex стоит учитывать возможно большой процент погрешности.
2 фактор. Чем популярнее запрос (ключевая фраза), тем выше рейтинг сайта
Если Google видит, что на сайте много страниц, которые отвечают на не популярные запросы, то и общий рейтинг сайта понижается. Поэтому настроив сайт на мало популярные запросы по этим запросам сайт выйдет в верхние ряды, потому что нет конкурентов. Но по популярным запросам ему будет пробиться труднее, или невозможно.
Формально все запросы по трактовке WordStat (ВордСтат) можно разделить на:
— высокочастотные — более 10 тысяч запросов в месяц, чаще всего это 1—2 слова;
— среднечастотные — от тысячи до 10 тысяч запросов в месяц, чаще всего это 2—4 слова;
— низкочастотные — от ста до тысячи запросов в месяц, чаще всего это 3—5 слова;
— микро низкочастотные — менее ста запросов в месяц, чаще всего это более 5 слов.
Здесь следует учитывать, регион, в котором продвигается сайт. Например, если онлайн торговля будет идти по всему миру, то вышеуказанные частота запросов — годятся. Но если сайт работает на небольшой город, то соответственно и запросов будет меньше во столько во сколько меньше город всего мира.
Нам часто приходится работать на небольшой регион, особенно это касается сферы обслуживания. Там обычно тысяча запросов за месяц — это шикарный запрос.
Для территориально ограниченного пространства (например, район небольшого города) мы пользуемся другой шкалой определения высокой частоты запроса, пропорционально уменьшая количество запросов в соответствии с количеством населения.
Google учитывает этот факт, подключил фильтр Геозависимых запросов.
Кстати сейчас Google уделяет особое внимание запросам с фразой: «… рядом со мной», или подобным.
3 фактор. Чем больше высоко ранжированный страниц сайта на высоко частотные запросы, тем выше рейтинг всего сайта
Это значит, что на одном сайте одна полезная для посетителей страница хорошо оптимизирована под конкретный запрос, а на другом сайте сотня таких страниц, то Google будет выше позиционировать страницу с сайта с большим количеством полезных страниц.
Например, если на вашем сайте одна страница, которая участвует в конкуренции по запросу «Ремонт телефонов», а у конкурента пол сотни разных страниц, на которых указаны и марки телефонов, то конкурент будет выше. Однако, если появится третья мастерская, которая на запрос «Ремонт телефонов», предоставит несколько сотен страниц с указанием не только марки телефона, но и модели, то такой сайт будет иметь больший вес.
4 фактор. Ключевая фраза в начале текста
Присутствие ключевой фразы в первой сотни слов на веб-странице увеличивает её рейтинг.
Чем ближе ключевая фраза к началу текста на странице, тем большую добавку к рейтингу получает она.
Читая далее эту книгу пытайтесь рассматривать, что это не требования Google, а рекомендации, которые делает Google на основании изучения сайтов, которые пользуются популярностью у посетителей.
Рассматривайте Google не с точки зрения карательного органа, а с точки зрения тренера, который выбирает игроков (веб-страницы) для своей команды (топ рейтинга по определённому поисковому запросу).
А все «карательные» меры к сайтам, и отдельным страницам — это усовершенствование отбора игроков в команду.
Читая эту книгу с этой точки зрения, вам будет намного понятнее, как Google составляет свой топ.
5 фактор. Геозависимость ключевой фразы
Например, «купить двухкомнатную квартиру в Подольске» — геозависимый запрос. Конкуренция по таким запросам не велика, и пробиться в верхние ряды — несложно.
Часто пользователи не указывают свою региональный привязку, тогда Google по умолчанию выбирает наиболее близко расположенные сайты компаний. Географическое расположение пользователя в этом случае Google определяет по IP-адресу, с которого был сделан запрос.
Примером таких запросов могут быть: «химчистка платьев», «ремонт компьютеров», «услуги приходящего бухгалтера», «доставка пиццы».
Очень хорошо, если при таких запросах указывается географическая привязка, например, «доставка пиццы по Риги», «купить квартиру на левобережье».
Для Google — это дополнительный положительный сигнал.
Запросы же типа «ремонт компьютеров своими руками», «продажа платьев из Италии», «самоучитель игры на гитаре» — не геозависимый запрос, потому как с таким запросом возможно обращаться из любой точки мира.
Но «Ближайшая кулинария», «Купить диван с доставкой», это чисто геозависимый запрос, и если у вас есть возможность удовлетворять запросы пользователей по таким фразам, то это делать значительно легче, чем влезть в конкурентную борьбу по более общим фразам.
6 фактор. Сезонность ключевой фразы
Сайтам продающих сезонные товары или услуги Google в сезон поднимает рейтинг, а в межсезонье — понижает.
Например, если пользователь летом напишет «модная обувь», то ему будут показываться сайты преимущественно с летней обувью. Если же этот же пользователь введёт этот запрос зимой, то ему будут показываться сайты с зимней обувью.
Поэтому полезно переписывать товар под сезонные запросы. Так увеличиваются шансы быть оценённым в Google.
Например, сезонные запросы «зимние сапоги», «заказать деда мороза». А одну и туже страницу с продажей цветов можно изменять под определенный праздник «цветы на 8-е марта», «цветы на день Валентина», «цветы к дню Победы», и т. д.
Примеры не сезонных товаров, рейтинг, которых не влияет на сезонность: «часы Tissot», «ноутбук asus», «свадебное платье».
Но стоит дописать, например, «часы Tissot в подарок на Новый год», но правильно составленный текст продажи часов на сайте попадёт в выдачу подарков на Новый год.
Ещё слабо распространены варианты объединения независимых и сезонных запросов.
Например, «Празднование 8 марта в нашем уютном кафе рядом со мной». Да такой запрос пользователи не делают, но умный Google понимает при подобных запросах, что человек ищет место, где отпраздновать 8 Марта, и ищет кафе поблизости от него.
Конечно, это теоретический пример, а на практике приходится проявлять креативность, и здесь есть только одно ограничение — ваша фантазия.
7 фактор. Каждый запрос пользователя относится к определённому типу
Google, когда своим искусственным интеллектом определяет, что имел ввиду пользователь, вводя в поисковое поле некоторую фразу, и перед выдачей первым делом определяет тип запроса. К примеру, если сайт настроен на продажу мультимедиа, а страница оптимизирована под запрос «смешное видео», то Google может отнести сайт к «смешное видео», и не показывать в выдаче по запросам о продаже.
Существует 5 типов запросов.
— Общие. Как правило это одно — два слова, например, кухня, письменный стол, и подобные. Не понятно, что человек ищет. Толи сериал «Кухня», толи рецепты кухни народов мира, толи мебель.
— Информационные. Так ищут информацию, например, «рецепт узбекского плова», «что такое астролябия».
— Навигационные запросы используют люди, которые что-то ищут, например, сайт, бренд, компанию, и подобное.
— Транзакционные, или коммерческие, т.е. человек желает что-то заказать, или купить. Это самые «вкусные» запросы с самой большой конкуренцией. Их прежде всего выдают слова: купить, заказать, магазин, каталог, и подобные. Например, если Вы желаете продавать кресла, то лучше оптимизировать сайт не под фразы: «красивые кресла», «лучшие кресла», а под «продажа кресел», «каталог кресел», «дешёвые кресла», «скидка на кресла», и подобные.
— Мультимедийные запросы имеют слова: «смотреть видео», «слушать музыку», и др.
Желательно ещё до создания сайта определить к какому типу запросов ваш ресурс будет относиться. Например, часто сайт по продаже размещает у себя массу информационных статей, и попадает в разряд информационных сайтов, и имеет в этом типе высокий ранг, в то время как страницы с товаром котируются хуже. Это допустимо если информационные страницы ищут потенциальных покупателей, чтобы потом взять координаты доводить до покупки. Так поступают бухгалтера, распространители косметики, или промышленного оборудования.
Кроме рассмотренной популярности и непопулярности ключевых слов, которые вводят пользователи, существует «конкуренция ключевых слов». Тот, кто давал контекстную рекламу в Google, очевидно, заметили, что дополнительно предлагаются и дополнительные ключевые фразы. Рядом с фразами — столбик, в котором написана популярность, или конкуренция этой фразы среди продавцов. Люди выбирают эти слова, но они не попадают в группу действующих фраз. Там написано, что эта ключевая фраза имеет мало запросов. Люди в недоумении. А секрета и нет — это недопонимание. Google своим столбиком говорит, что по этой фразе очень много желающих рекламироваться, но пользователи редко набирают такие фразы.
Т.е. существует два рейтинга.
Первый — это как часто пользователи задают ключевую фразу, или вопрос поисковику.
Второй — это сколько сайтов готовы ответить на этот вопрос, т.е. со сколькими сайтами придётся конкурировать за высокое место в выдаче.
Для оптимизатора же полезно знать какова конкуренция по каждой фразе, взятой для продвижения.
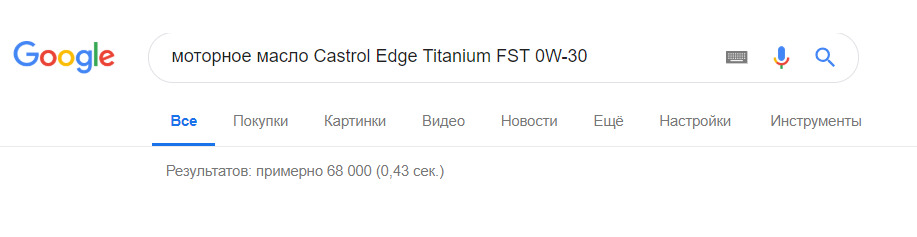
Вспомните пример «моторное масло Castrol Edge Titanium FST 0W-30».
Набираем в Google «моторное масло Castrol Edge Titanium FST 0W-30», и смотрим конкуренцию по этому слову т.е. сколько страниц по этому запросу нашёл поисковик.
В этом примере их всего 71.
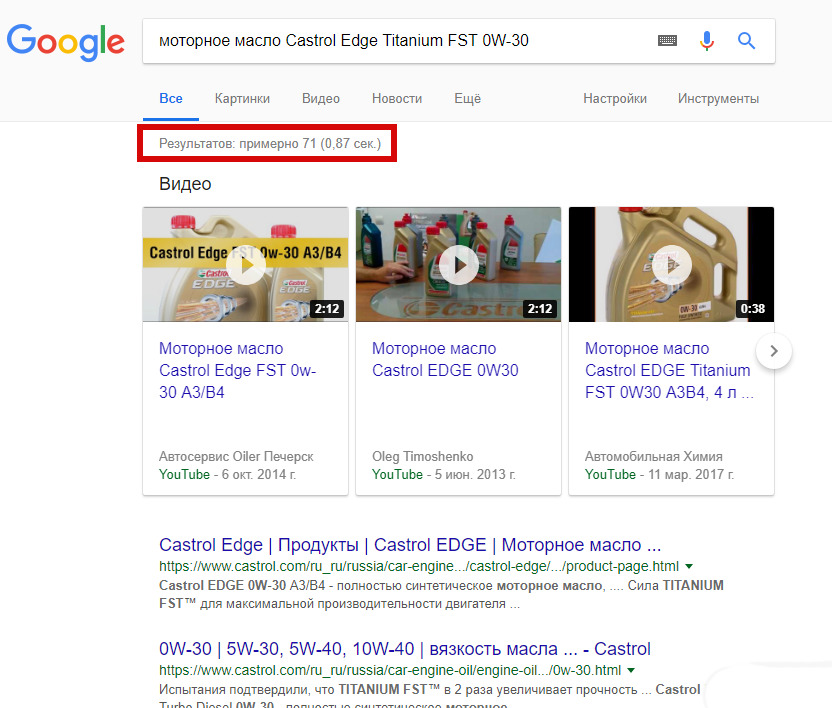
С такой конкуренцией и бороться не нужно, чтобы стать лидером, поэтому многие сеошники тупо выполняют свою работу, и получают отличный результат.
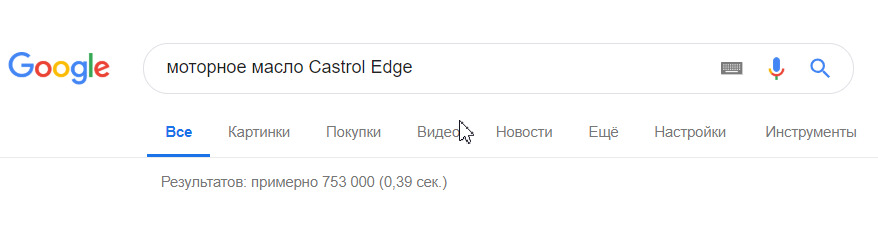
А вот другой запрос «моторное масло» уже имеет 9 150 000 страниц в конкуренции, и при таком запросе уже пробиться трудно.
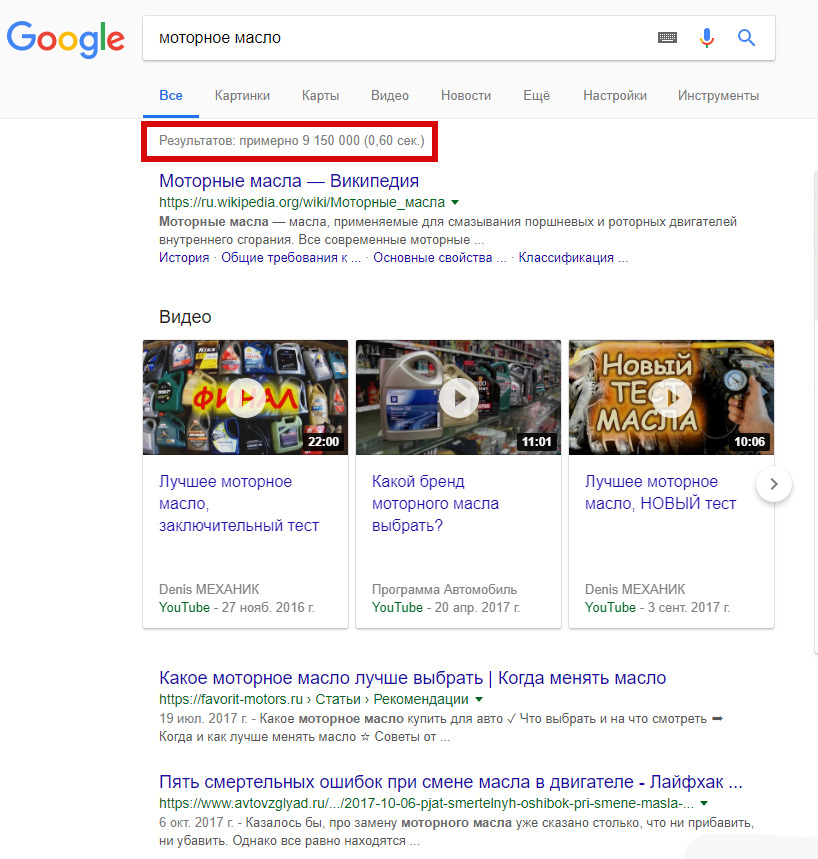
Но если читали о типах запросах внимательны, то применительно к последнему запросу — это общий запрос. Не понятно, что человек ищет.
Толи он ищет информацию об этом масле, толи желает купить, толи ещё что-то.
Но на запрос «купить моторное масло в Москве» набирается 788 000 страниц, т.е. в 10 раз меньше, а значит вывести страницу сайта в лидеры будет намного проще. Кроме этого, это геозависимый запрос, и целевой запрос. Тот, кто пишет в строке поиска «купить моторное масло в Москве» уже настроен покупать масло в своём регионе.
С моторными маслами — это пример, на котором рассмотрели, как из многотысячных ключевых фраз для сайта выбирать наиболее подходящие.
Главная ошибка, не понимание, или желание идти по лёгкому пути молодых сеошников в том, что они не учитывают степень конкуренции.
Здесь, следует соблюдать баланс, чтобы ключевая фраза была средне и низкочастотной, а конкуренция по этой фразе была минимальной. Обычно стараются, чтобы конкуренция страниц по всей России не превышала миллиона. Если же конкуренция страниц несколько миллионов, то следует задуматься о целесообразности оптимизации по этой фразе.
Единственно что может помочь пробиться в верхние ряды — это геозависимые запросы, и то только в том случае, если конкуренты к ним не подготовлены.
Но если конкуренция меньше тысячи, то такую фразу лучше забыть, потому как конкуренты не дураки, и уже имеют опыт. В большинстве случаем конкуренты уже давно съели, переварили и отнесли в туалет эту идею, как непригодную. А их опытом нужно пользоваться. Только не слишком умные люди думают, что они самые умные.
Теперь о подборе слов.
Для многих wordstat. yandex, или trends. google единственные источники ключевых фраз. Существуют и специализированные программы по подбору слов. Не буду их перечислять, любой без труда найдёт их используя поисковик Google, если наберёт, например, «онлайн подбор ключевых слов», или «программа подбора ключевых слов». Из большого списка можно выбрать для себя понравившуюся.
Одна проблема в этом методе — много не подходящих фраз. Такие программы гребут всё из различных доступных источников, и так подобранные фразы возможно никогда не искались в Google.
Другой путь и более продуктивный — воспользоваться опытом конкурентов. Лично моя практика показывает, что практически всё, что придумывает новичок прежде было опробовано корифеем-конкурентами, и не получив желаемого отклик было отвергнуто. Лучше брать сайты из верхней части выдачи, и применять их ключевые фразы.
Составляете список ключевых фраз, по которым желаете, чтобы находили ваш сайт. Вводите их в поисковике, открываете первую десятку сайтов по этим запросам, затем открывайте код сайтов и берете слова из тега keywords. Так не будет десятков тысяч ключевых фраз, но будут проверенные.
Для примера набираем в Google «моторное масло», далее открываем первый десяток сайтов. На странице сайта кликаем правой кнопкой мыши, и в раскрытом меню выбираем пункт «Просмотр кода страницы».
Видим такой код, в котором нас интересует сейчас то что отмечено красным прямоугольником.
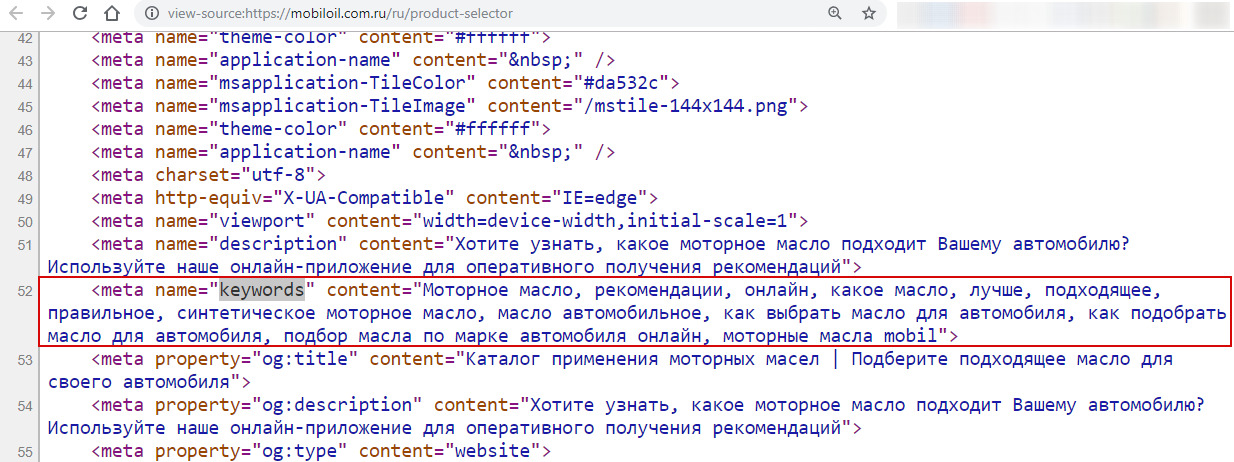
Из тега keywords копируем все слова:
Моторное масло, рекомендации, онлайн, какое масло, лучше, подходящее, правильное, синтетическое моторное масло, масло автомобильное, … Удаляем ненужное, типа: лучше, подходящее, правильное…
И заносим в свой список. Так проделываем со всем десятком открытых сайтов. Объединяем эти списки, и оставляем именно то, что точно соответствует будущему сайту.
После чего проделываем такую работу по всем ключевым фразам, по которым желаете, чтобы находили ваш сайт. Желаете расширить список — берите другие слова из списка, вводите в строке поиска Google, и продолжаете сбор.
Конечно, в списке будут и не нужные фразы, но в любом случае список ключевых слов будет намного чище.
Причём, чем выше конкуренция в нише, тем более качественные будут фразы.
Если тег keywords пуст, то можно скопировать текст и вставив его в сео-анализатор текста посмотреть под какие фразы писался текст. Так вы сразу набираете ключевые фраза, и смотрите как делают лидеры в этой нише.
И ещё не забывайте о подсказках, которые высвечиваются при наборе запроса.
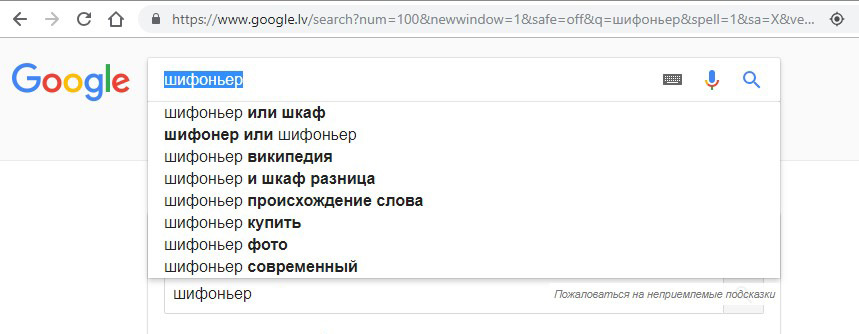
Этот список наиболее часто набираемых фраз пользователями.
И как дополнение, в самом низу этой же страницы поиска есть раздел: «Вместе с этим часто ищут»

8 фактор. Количество ключевых фраз на странице
Если на веб-странице Google находит несколько ключевых фраз, по которым можно показывать в выдаче страницу, он воспринимает такую страницу более ценной, и она может дать Google внутренний признак качества. Чем более популярные запросы, тем это больший дополнительный признак качества страницы.
Это относится к длинным текстам, более 2—3 тысяч слов. Например, странице автор статьи описывает ответы на запросы: «ремонт мобильных телефонов», «замена стекла на телефоне», «замена экрана телефона», «замена батареи на телефоне», т. д. в 5—7 тысяч слов. Причём о замене стекла на телефоне, замене экрана телефона, замена батареи на телефоне, т. д. он рассказывает в 300 и более словах.
Тогда по каждой позиции замены сайт будет высоко ранжироваться (при других положительных факторах) по этим ключевым словам, кроме общей фразы «ремонт мобильных телефонов». Однако если на веб-странице идёт простое перечисление видов ремонта, и общий объем статьи в несколько сотен слов, а ещё хуже несколько десятков слов, то рассчитывать, что такая статья будет иметь высокий ранг не стоит.
Если же на каждый вид ремонта отведена отдельная страница из нескольких предложений, то это пустая трата времени и ресурсов. Такой набор страниц никогда не будет высоко ранжироваться.
Кроме этого, Google фрагменты хорошего текста, по своему алгоритму ставит в нулевую позицию, в так называемый информационный блок: избранные, рекомендуемые фрагменты и др. Конечно, если ответ удовлетворяет условиям требуемых для попадания в этот блок. Но об этом в специальных факторах см. ниже.
Попасть в голосовой поиск — ещё одно лакомое место для сайта. Об этом также подробно читайте в соответствующим факторе.
9 фактор. Спам в мета тегах
Набивать ключевыми словами или числами мета теги в попытке манипулировать рейтингом сайта в результатах поиска Google — плохая идея, которой ещё пользуются начинающие SEO-специалисты и хозяева сайтов.
Хотя на тег ключевых слов «keywords» утверждает Google, что не обращает внимание, но наша практика показывает, что только заполнение этого тега увеличивает рейтинг страниц. Мы всегда заполняем тег ключевых слов хотя бы для того, чтобы знать под какую фразу, или фразы оптимизируется страница сайта.
Заполнение тега описания страницы «description» ключевыми словами или фразами часто звучит неестественно, например:
«Мы продаём нестандартные сигарные хьюмидоры. Наши нестандартные сигарные хьюмидоры изготовлены вручную. Если вы думаете о покупке нестандартного хьюмидора для сигар, пожалуйста, свяжитесь с нашими специалистами по хьюмидору для сигар по адресу…»
По словам Google это звучит не естественно, что может привести к удару по рейтингу.
С другой стороны, мета тег «description» составленный в соответствии с рекомендациями Google показывается в сниппете поисковой выдаче — это своего рода рекламный текст, читая, который пользователь решает переходить на сайт, или нет. Выше приведённый пример с многократным повторением фразы «нестандартные сигарные хьюмидоры» вряд ли кого-то побудит перейти на сайт.
Тоже самое относится и к тегу «title», который является описанием страницы, и который выводится в сниппете, как заголовок. Если «description» не удовлетворяет алгоритмам Google, то поисковик возьмёт фрагмент текста из текста этой веб-страницы, но спамные заголовки Google берет без изменения и вставляет его заголовком в сниппет. Поэтому заголовку страницы следует уделять особое внимание.
В этом факторе говорится только о спаме в мета тегах.
Рекомендации Google по составлению этих и других мета тегов смотрите в соответствующих факторах и сигналах.
LSI КЛЮЧЕВЫЕ СЛОВА
Если прежде было достаточно разбросать ключевые слова по тексту, засунуть в заголовки, и описание чего было достаточно для высокого позиционирования, то теперь другая эра, LSI ключевых слов.
Когда человек набирает в поиске «двуспальная кровать», то Google понимает, что ищется мебель.
Этому помогает LSI — латентно семантический индекс.
Чтобы не входить в научные термины и определения поясню на примере.
Google получил запрос «мебель для спальни». Google понимает, что человек хочет посмотреть какая мебель имеется для спальни. А это кровать, тумбочки, шифоньер, какие-то светильники, и многое другое.
Откуда Google это знает?
Алгоритмы Google набрали соответствующие фразы из уже высоко позиционируемых сайтов, и знает, что «мебель для спальни» имеет сопутствующие слова, которые раскрывают тему.
10 фактор. Сопутствующие слова
Google проанализировал десятки или сотни миллионов страниц, которые пользуются популярностью у посетителей, и выявил слова, которые чаще всего встречаются с искомыми словам, которые были дополнительными. Для вновь создаваемых страниц желательно, чтобы эти дополнительные слова входили во вновь индексируемые страницы для их высокого ранжирования.
Чем больше таких слов, тем лучше раскрыта тема, и как подтверждение — время, затраченное пользователем на странице.
Запрос «Горячее оцинкование металла». Здесь должны быть слова: завод, ванна, цинк, … Чем больше сопутствующих слов в тексте, тем лучше раскрыта тема. Так заложено в интеллекте алгоритмов.
И так по каждой имеющейся в интернете теме.
Как же искать сопутствующие слова?
Для этого много сервисов, предоставляют эту услугу, например, Google Keyword Planner. Другой вариант в Google поиске искать, например, генератор LSI ключевых слов.
Также полезно просматривать результаты поиска по ключевой фразе. В ответах на запросы поиска Google показывает какие LSI ключевые слова он считает подходящими.
Например, по фразе «мебель для кухни» получается набор сопутствующих слов.
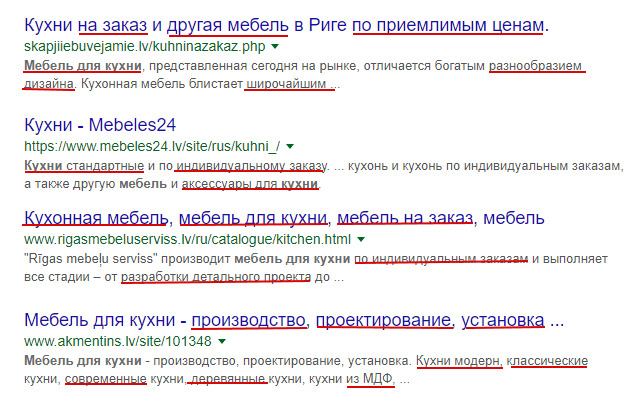
Но непревзойдённый результат по подбору LSI ключевых слов может дать специалист в этой области. Никакая машина, никакой генератор не способен выдать столько сопутствующих слов по теме сколько выдаст специалист, эксперт в этой теме.
Google, конечно же уже знает сопутствующие слова из других веб-страниц, и для него уже мало что новое попадает в индекс.
11 фактор. Попадание в проблему
Google уделяет особое внимание другой группе сопутствующих слов. Это слова, которые помогают лучше понять проблему, с которой пользователь обращается к поисковику. Соответственно и на страницах сайта поисковик должен увидеть слова из соответствующей группы проблем.
Точное попадание ответа на проблему пользователя — увеличение веса веб-страницы на заданный пользователем вопрос.
Например, если вопрос к поисковику, и соответственно ответ на веб-странице содержат слова: «Цены, Стоимость, Сколько, Как нанять, Риски, Выгоды, Плюсы и минусы, Против, Проблемы» и подобные, то Google понимает, что — это исследования, связанные с покупкой, и в этом случае подбирается страница, на которой продаётся товар, описываются плюсы и минусы этого товара, какие выгоды получит покупатель. Чем больше ответов, тем лучше.
С желанием получить помощь, связанную с покупкой, будут используемы слова:
«Помогите, Оценка, Отзывы, Рейтинги» и подобные.
Если пользователь ищет информацию о продукции:
«Приборы, Программного обеспечения, Товары, Системы» и подобные.
Если пользователь ищет информацию, связанную с обслуживанием, то он употребляет слова:
«Сервисы, Решения, Технология, Дизайнер, Монтажник, Строитель, Создатель, Разработчик, Поставщик, Консультант, Повышение квалификации, Хранить, Лечение, Терапия» и подобные.
Правда к словосочетаниям «Быстрый кредит», «Срочный заём», также, как и к словам «Казино», «Порно» и подобным у Google большое недоверие, если такие это молодые сайты, и не сыскали большого авторитета у пользователей. Google для сайтов с такими фразами запустил специальный фильтр пессимизации, о котором я писал в первой части (36 фильтров Google). И если поисковик находит оптимизированные страницы под эти ключевые фразы, то возможно попадание в черный список Google.
12 фактор. Слова синонимы
Прежде чтобы показывать поисковику, что страница релевантная запросу пользователя нужно было на 100 слов написать до 7 раз заветное слово, которое называлось ключевиком.
Например, в тексте о кредите, где пятьсот слов нужно было повторить слово кредит до 35 раз. Такой текст не выглядит естественно, поэтому как требуется словесное разнообразие. А это разнообразие дают синонимы. Например, на слово «кредит» словарь синонимов предлагает: ссуда, заём, деньги, платёж, ипотека, дебет, и др.
Грамотное использование синонимов делают текст более точным, а поисковику помогают лучше понять смысл написанного.
13 фактор. Окружение блоков
Также как в спальне или на кухне должна быть своя специфическая мебель, по которой определяется что это за помещение, так же и на сайте, и на страницах сайта должна быть своя «обстановка».
Также как по обстановке в помещении можно судить о комфортабельности помещения, так и Google определяет по наличию модулей на сайте определяет качество и ценность страницы.
Примерами могут служить на определенных сайтах конвертеры валют, калькуляторы процентных ставок, голосование, комментарии, оценки, и многое другое.
Если сайт — блог, то для блога должны быть следующие модули: возможность написать комментарий, ответить на комментарий, поставить оценку за статью, комментарий, и другое.
Если — интернет-магазин, то обязательно должна быть корзина, условия оплаты, доставки, отзывы о товаре, естественно изображение и описание товара, и многое другое.
Обо всем, что считает Google должно быть на сайте и страницах каждый может сам посмотреть, открыв первый десяток сайтов из ТОП 10, чтобы увидеть, что имеется на этих сайтах.
Если желаете быть в выдаче по определенному запросу первым, то сделайте также как у лидера, и ещё немного лучше. Это не гарантия занять первое место, потому как в расчёт берётся множество факторов, но без этого можно дать 100%-ю гарантию, что высокое место в рейтинге не светит.
14 фактор. Ключевые слова LSI в заголовке и описании
Если прежде было достаточно напихать ключевых слов в заголовок веб-страницы, в заголовок текста в описание страницы, а также повторить эту ключевую фразу в описании картинки, то теперь это может рассматриваться Google как переизбыток одной ключевой фразы.
Google рекомендует использовать вместо одной ключевой фразы её LSI словами. Например, если статься посвящена мобильным телефонам, то желательно использовать весь набор LSI слов, т.е. мобильник, телефон, смартфон, гаджет, устройство, и т. п.
Google различает слова с несколькими потенциальными значениями. Это может также выступать в качестве сигнала релевантности.
СИГНАЛЫ НА УРОВНЕ КЛЮЧЕВЫХ СЛОВ
Как правило, если компания занимается созданием контента для своего веб-сайта — это стандартный контент-маркетинг: статьи хорошо написаны, но на самом деле никого не вдохновляют на действия. Но это даже не самая большая проблема; реальная проблема заключается в том, что в заголовках статей отсутствуют коммерчески ценные ключевые слова, что делает статьи бесполезными для SEO.
Проще говоря, Google решает, должна ли ваша статья отображаться для заданного поискового запроса, в зависимости от того, имеет ли эта статья поисковый термин в заголовке; так что если вы публикуете статьи с умными заголовками, но без поисковых терминов, вы получите нулевое посещение из Интернета!
Давайте посмотрим на пример. Компания специализируется на тепловых продуктах — маленьких устройствах во всем, которые обеспечивают оптимальную температуру. Недавно они опубликовали статью в блоге под следующим названием: «Терморегулирование помогает нашей жизни».
Суть статьи заключается в том, что OEM-производителям необходимо более тщательно продумывать компоненты управления температурным режимом, поскольку они играют важную роль в качестве продукта.
Тем не менее, статья никогда не будет получать трафик от Google, потому что её название не содержит коммерчески полезного ключевого слова, которое потенциальный клиент будет искать.
Чтобы определить, как будет выглядеть такое ключевое слово, нам нужно начать с знания нашей целевой аудитории. Давайте предположим, что это «Специалисты по частичной закупке у производителей оборудования». По сути, люди, отвечающие за приобретение деталей, которые OEM использует для создания своих продуктов.
Теперь, что такой человек будет вводить в Google? В этом случае, если они ищут детали управления температурой, это может быть хорошим началом: «детали управления температурой».
Это только моя догадка, но у меня есть простой способ увидеть, что люди на самом деле ищут: функция авто заполнения Google. По сути, введя любое слово или фразу в поле поиска на Google.com, я получаю список предложений, которые приходят непосредственно от Google. Поэтому, если я перейду к окну поиска и введу «терморегулирование з», а затем подожду, пока не появятся «запчасти».
Авто заполнение научило меня, что люди обычно не ищут «детали»; они ищут «продукты». И если я продолжу исследовать и использую Планировщик ключевых слов Adwords, который предлагает ключевые слова, основанные на вводимом вами исходном ключевом слове, я узнаю, что большую часть времени они просто ищут конкретный продукт управления температурой, такой как калорифер или радиатор.
Но давайте вернёмся к нашему первоначальному предположению и допустим, что кто-то ищет продукты для управления температурным режимом в целом — они хотят найти нового дистрибьютора. Они, вероятно, собираются напечатать «дистрибьютор продуктов управления температурным режимом».
Проверяя этот термин в функции автозаполнения Google, я вижу, что этот термин используют люди.
Теперь давайте вернёмся к нашему приятному, но неэффективному названию «Управление температурным режимом — наша жизнь». Можем ли мы изменить его так, чтобы оно включало ценное ключевое слово, которое привлекло бы человека, отвечающего за закупку продуктов для управления температурным режимом у OEM-производителя?
«Отличный продукт начинается с правильного дистрибьютора продукции для терморегулирования». Конечно, такой заголовок не совсем будет хорошо работать, потому как ключевую фразу лучше размещать вначале текста, но об этом более подробно смотрите далее. Сейчас мы рассматриваем только принцип.
Но вернёмся к заголовку. В то время как первоначальное название было посвящено тому, как мир вращается на основе продуктов для управления температурным режимом, и это название больше касается того, как продукты работают в основном за счёт качественных компонентов для управления тепловым режимом, суть осталась та же.
Новый заголовок не слишком сильно теряет читаемость по сравнению со старым и гораздо более коммерчески полезен. Иными словами, этот заголовок может стоить сотни тысяч евро в виде новых продаж терм продукции, ориентированных на SEO, в следующем году, а первый — ничего не стоит потому как не может ранжироваться высоко.
Идеальное название статьи всегда будет представлять собой смесь читабельности и богатства ключевых слов. Мой заголовок интересен с точки зрения поисковых запросов, Google оценит это, и отправит клиентов.
Это основной процесс создания отличного заголовка статьи. Но здесь есть нюанс, который вы могли бы уловить, а можете и не заметить. И это концепция транзакционных ключевых слов.
Транзакционные ключевые слова — то, что заставляет контент превращаться в доход.
Напомню, что транзакционные запросы набирают пользователи, желающие купить конкретную продукцию или воспользоваться услугой.
Транзакционное ключевое слово является частью ключевой фразы, которая указывает, что пользователь потенциально заинтересован в трате денег. В приведённом выше примере, где нашим целевым ключевым словом является «дистрибьютор продуктов для терморегулирования», первая фраза — «терморегулирование» — просто корень. Это тема фразы. Это не ценная часть.
Ценная часть, которая указывает на то, что искатель хочет купить, — в двух последних словах: «продукты» и «дистрибьютор».
Подумайте об этом так: если кто-то вводит «управление температурой» в Google, мы уверены, что они хотят что-то купить? Или они могут искать фразу, чтобы понять, что это такое? Я думаю, вы согласитесь, что это неоднозначно. Но если кто-то печатает «продукты для терморегулирования», мы можем согласиться с тем, что он скорее покупатель. И если кто-то наберёт «дистрибьютора продуктов для терморегулирования», мы можем быть почти уверены, что они ищут компанию, у которой можно купить продукты для терморегулирования. Однако следует учитывать, что по мнению Google 10—25% такие запросы делают конкуренты, которые ищут дополнительную информацию для своих целей.
Таким образом, по шкале от «Не коммерчески ценно» до «Очень коммерчески ценно» фраза «продукты для терморегулирования» — 7/10. Человек вероятный покупатель. А фраза «дистрибьютор продуктов для терморегулирования» — 10/10. Это то 100% попадание.
Несмотря на возможность того, что человек, который его набрал, является конкурентом (или скромным генеральным директором маркетинговой компании, занимающей ведущие позиции), они почти наверняка являются потенциальными клиентами. Вот почему мы нацелены на это.
Я хочу сказать, что есть определенные слова, которые носят транзакционный характер. В этом случае «части» — это одно, а «дистрибьютор» — другое. В каждой отрасли существуют различные транзакционные ключевые слова: ключевые слова, на которые вы действительно хотите ориентироваться, потому что именно они вводят в Google настоящие покупатели. Это низко висящий фрукт, который как лифт поднимает ваш контент в поиске.
Если вы Stubhub (компания по обмену и перепродаже билетов), транзакционное ключевое слово будет «билеты». Вы не хотите, чтобы люди печатали «Бет Харт», потому что по этому запросу пользователи могут искать её биографию, или посмотреть где у неё гастроли, или просто хотят послушать её песни. Но вы начинаете интересоваться, если они пишут на концерт «Бет Харт. «Концерт» является достаточно транзакционным. Но только частичным, потому как пользователь может только послушать или посмотреть её какой-либо концерт. Однако вам действительно интересно, если они вводят «билеты на концерт Бет Харт». Слово «Билеты» невероятно транзакционное слово.
Если вы лечебный центр алкогольной реабилитации, транзакционным ключевым словом будет «лечение». Другое слово — «центр». Третье — это «программа». Вас не волнуют люди, которые пишут «алкоголь». Вы начинаете беспокоиться, когда они вводят слово «реабилитация алкоголя» (поскольку «реабилитация» часто подразумевает программу лечения). Вы очень интересуетесь, когда они вводят «лечение от алкогольной зависимости» или вам очень интересно, когда они вводят «программу реабилитации от алкоголя».
Я уверен, что вы уже поняли смысл. Есть корневые ключевые слова, которые устанавливают тему поиска, и есть транзакционные ключевые слова различной силы, которые указывают на интерес к покупке. Ниже приведен список транзакционных ключевых слов со всего спектра. Вы заметите, что первые 2 столбца являются «сложными» транзакционными ключевыми словами, то есть они очень близки к моменту покупки. Те, что в столбцах справа — превосходные ключевые слова, связанные со справкой и исследованиями, — немного дальше от момента покупки, но все же достаточно близко, чтобы Google считал их транзакционными.
СВЯЗАННОЕ С ОБСЛУЖИВАНИЕМ:
· Компания;
· Фирма;
· Сервисы;
· Решения;
· Технология;
· Дизайнер;
· Монтажник;
· Строитель;
· Создатель;
· Разработчик;
· Поставщик;
· Консультант;
· повышение квалификации;
· хранить;
· лечение;
· терапия.
ОТ ПРОДУКЦИИ:
· Приборы;
· программного обеспечения;
· товары;
· системы.
ПРЕВОСХОДНАЯ СТЕПЕНЬ:
· Обычай;
· Лучший;
· Топ;
· Редкий;
· Помощь, связанная с;
· Помогите;
· Отзывы;
· Рейтинги.
ИССЛЕДОВАНИЯ, СВЯЗАННЫЕ С:
· Цены;
· Стоимость;
· Сколько;
· Как нанять;
· Риски;
· Выгоды;
· Плюсы и минусы;
· Против;
· Проблемы.
Надеюсь, что вы найдёте этот список полезным.
КАЧЕСТВО КОНТЕНТА. Общее
Как уже писал в книге «36 фильтров Google» полезный и качественный контент для Google разные понятия.
Качественный контент — это когда Google
· не находит орфографических и синтаксических ошибок в тексте;
· текст отформатирован так, что хорошо просматривается его структура;
· контрастность цветов на сайте;
· вёрстка сайта отвечает требованиям спецификации W3C;
· другие факторы, описанные ниже.
Сюда ещё можно добавить, что излагаемые факты должны соответствовать действительности. Например, если на веб-страницы будет написано, что Вторая мировая война была в 18 веке в то время, как на миллионе других сайтов говорится, что это война 20-го века, то такая веб-страница, а с ней и весь сайт будет занимать в результатах поиска более чем миллионное место.
15 фактор. Ошибки в написании текста
Чтобы Google посчитал контент качественным разработчики сайта, или хозяин должен проверить сайт на наличие орфографических и синтаксических ошибок. Это те только требование поисковых систем, но и пользователю будет читать более приятно, и такой текст вызывает большее доверие.
Если прежде в качестве ключевых фраз SEO-шники набивали и слова с опечатками, и умышленно делали ошибки в тексте, чтобы по запросам с опечатками быть первыми, то теперь Google в поиске предлагает заменить слова с орфографическими ошибками на правильное написание. Хозяину желательно самому убедиться, что текст без ошибок. Обязательно нужно это сделать, если у конкурентов по поиску текст написан грамотно.
Правда я не раз видел, особенно в социальных сетях, как профессиональные журналисты, чтобы быть ближе к своей молодёжной аудитории, чтобы сходить за своего употребляют сленг, пишут слова не в соответствии с грамматикой, а так как говорит аудитория. Самый распространённый пример слово «Сейчас», писать с ошибкой, как говорят в обычной речи — «щяс».
Как видите на скриншоте Google понял, что я хочу узнать какая сейчас погода, и любезно предложил исправить мою ошибку.
Но Google прощает только своим пользователям. К хозяевам сайтов он относится более строго.
Конечно, одного исправления ошибок в тексте, чтобы существенно продвинуться в рейтинге — не достаточно, но это должен быть первым шагом на пути продвижения сайта.
Хотя моими орфографическими и синтаксическими ошибками пестрят мои тексты, на данный момент это мало, или совсем не влияет на рейтинг. Но это не значит, что и в ближайшем будущем на вашем языке этот фактор не получит более весомое значение в рейтинге, хотя бы потому, что это один из ключевых факторов авторитетности сайта.
16 фактор. Не читаемый текст
Google не анализирует дизайн сайта, но «видит» сочетание цвета фона и цвета шрифта. По его представлению цвет фона и текста должны быть контрастными, и легко читаемыми.
Сейчас только ленивый не знает, что Google видит текст, написанный цветом или очень близким к цвету фона, и существенно пессимизирует такие сайты.
Другой приём уже из области вёрстки. Программный код позволяет большой текст поместить в некоторый <div>, который как бы вывести на сайт, но указать этому диву координаты за пределами видимой части веб-страницы. Пользователь не видит какой текст спрятан на веб-страницы, она кажется аккуратной, а на самом деле на ней может таиться несколько сеошных текстов, которые должны продвигать сайт.
Google считает такие манипуляции серьёзным нарушением, и пессимизирует, задвигает такие сайты в невидимую пользователем часть поиска.
Кстати, ни один Google фильтр не удаляет сайт из индекса, а только существенно или очень существенно понижает рейтинг сайтам, которые нарушают его правила.
Только при ручной проверке сайта специалистом, после получения жалобы сайт может быть исключён из индекса. Об этом более подробно читайте в моей книге «36 фильтров Google».
17 фактор. Структура текста на веб-страницы
Вспомните, как вам тяжело читать длинные посты и сообщения в социальных сетях. Наверняка вы сталкивались и с длинными текстами на сайте, например, вот с такими.
Согласитесь, что читать такой текст трудно, и вряд ли его кто-то осилит, если излагаемая в нем информация не представляет особого интереса для читателя.
Поэтому разбивать текст на логические блоки — это не прихоть Google, а желание пользователя.
Google считает, что пользователя нужно уважать, и оформлять контент, чтобы читающему было максимально удобно. Потому должны быть заголовки и подзаголовки, текст разложен по хорошо просматриваемым абзацам, есть и списки, и выделения в тексте, и картинки или видео, наглядно поясняющее написанное. Более подробно об оформлении текста читайте в главе «Тексты».
Этот фактор рассматривает структуру сайта комплексно, т.е. чем больше элементов форматирования применено на странице, тем лучше. И форматирование не должно быть в ущерб содержанию, а помогать наглядно воспринимать веб-страницу: во всем нужна мера.
В Google Руководстве об этом ничего не сказано, но уверен, что пользователю будет трудно воспринимать текст с использованием различного начертания, размера и цвета шрифта. Учитывая, что Google ратует за лёгкость восприятия, то если ещё и не ввёл понижения рейтинга за чрезмерную пестроту, то это будет сделано.
18 фактор. Ошибки в вёрстки сайта
Лично мне не раз приходилось сталкиваться с тем, что исправление ошибок в коде или вёрстке сайта в соответствии со спецификацией W3C, и дальнейшей проверки качества кода веб-страниц приводило к существенному повышению рейтинга этих веб-страниц.
Ошибки HTML или валидация W3C. Ошибки в написании HTML кода или небрежное кодирование могут быть признаком сайта низкого качества. Несмотря на противоречивость, многие в SEO считают, что даже включение в код HTML таких тегов как <font> Текст </font> с атрибутами size, color, face и др. отрицательно влияют на ранг веб-страницы.
Хорошо закодированная страница используется как сигнал качества.
Поэтому после проверки контента на ошибки желательно проверить сайт на соответствие спецификации W3C.
19 фактор. Микроразметка
Микроразметка на веб-страницах увеличивает сниппетры, что делают его более заметными в поисковой выдаче.
Джон Мюллер из Google сказал, что «со временем, я думаю, что [структурированная разметка] тоже может войти в рейтинг».
Пока нет никаких доказательств того, что микроразметка или микроданные напрямую влияют на рейтинг в поисковых системах. Но микроданные влияют авторитет сайта.
Однако, по статистики процент кликов по расширенному сниппету может увеличиваться до 30%.
Гугл же имеет статистику по каждому запросу, и знает сколько раз переходили на какой сайт.
Ниже приведена таблица, взятая из открытых источников, которая показывает сколько было переходов на сайт за тысячу показов.
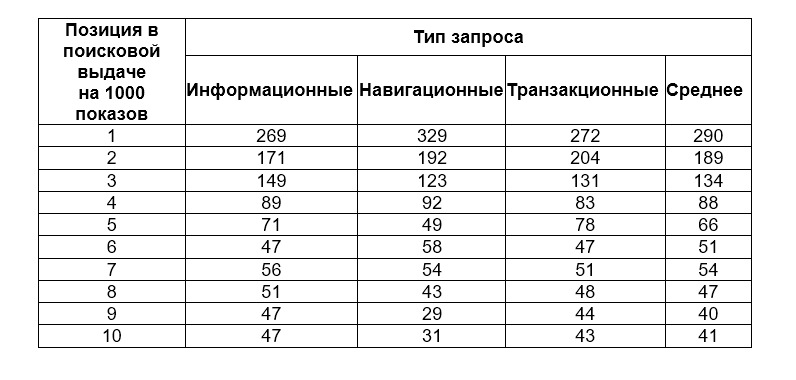
А теперь представьте Google поставил сайт на 7 месте при 54 переходах на тысячу показов. При добавлении расширенного сниппета и увеличении кликабельности на 25% добавляется 14 дополнительных показа, т.е. — 68. Что соответствует пятому месту. Так благодаря структурированной разметки сайт может подниматься в рейтинге.
Конечно, приведённый пример — виртуальный, а расчёт далёк от реального расчёта. Но моя цель — показать, как косвенно расширенный сниппет поднимает рейтинг сайту.
Как делать структурированную разметку подробно и полно смотрите на сайте Schema.org.
Ниже пример, на котором показано, достаточно небольших знаний HTML, чтобы сделать правильную разметку.
<div itemscope itemtype = "http://schema.org/Offer">
<span itemprop = «name»> Blend-O-Matic </ span>
<span itemprop = «price»> $ 19,95 </ span>
<div itemprop = «reviews» itemscope itemtype = "http://schema.org/AggregateRating">
<img src = "four-stars.jpg» />
<meta itemprop = «ratingValue» content = «4» />
<meta itemprop = «bestRating» content = «5» />
На основе <span itemprop = «ratingCount»> 25 </ span> пользовательских рейтингов
</ div>
</ div>
Эта разметка говорит поисковику, что вы желаете, чтобы отмеченный фрагмент кода был отражен в сниппите при поисковой выдаче. Проверить на ошибки, и получить подсказки от Google по мультиразметки можно по адресу: https://search.google.com/structured-data/testing-tool/.
Вот только Google ещё не всегда, или по своему секретному алгоритму, или другой необъявленной причине не показывает это расширение на некоторых категориях сайтов.
Но это не значит, что так будет всегда. Google совершенствуется каждый день.
Что такое схемы структурированных данных?
Наряду с форматами структурированных данных, схемы структурированных данных работают как своего рода словарь, определяя термины для типов вещей (например, «Персона», «Событие», «Организация»), а также для свойств и отношений (например, «имя», «worksFor»). Поддерживая это разделение между форматом и схемой, пользователи различных форматов могут использовать в своих интересах одни и те же широко используемые схемы.
Данные — словарный запас.
Проект Google «Data Vocabulary» стал важной вехой в разработке структурированных данных в интернете, поскольку он привёл к сотрудничеству нескольких поисковыми системами для создания schema.org.
Однако в настоящее время этот проект сильно устарел и, как правило, предпочтительнее использовать более широко распространённый словарь из Schema.org. Таким образом, разметка data-vocabulary.org перестанет соответствовать критериям и улучшениям результатов поиска Google.
Обратите внимание, что это единственное последствие этого изменения. Страницы, использующие схему словаря данных, останутся действительными для всех других целей.
Для того, чтобы иметь право на богатые функции результатов Google, рекомендуется преобразовать структурированные данные data-vocabulary.org в schema.org.
Например, вот как вы можете изменить словарь данных на schema.org
Data-vocabulary.org
Schema.org
Вы можете протестировать любой фрагмент кода в режиме реального времени с помощью Rich Results Test, вставив его в окно поиска. Если требуется более глубокое изучение этого вопроса ознакомьтесь с сообществом Google для веб-мастеров.
20 фактор. Голосовой поиск
То, что оптимизированный голосовой поиск влияет на результаты поиска в выдаче напрямую Google не заявлял. Однако исследование Mindmeld показало, что 75% сайтов из Топ3 присутствуют в голосовом поиске. И 95% входят в Топ10.
Уже ни для кого не секрет, что поисковик, во всяком случае на английском языке не подбирает тексты, по ключевым словам, а пытается понять, на какой вопрос желает получить ответ пользователь, и ранжирует сайты по наиболее подходящему ответу, конечно же в своём понимании, по своим алгоритмам.
В наши дни поисковики учатся мыслить с точки зрения понимания вопроса, понять не что он написал формально, а, что хочет пользователь узнать. Конечно, это также зависит от множества факторов, помимо ключевых слов и темы вопроса.
Ранжирование ответов может включать в себя просмотр предыдущих поисковых запросов конкретного пользователя или шаблонов поисков, чтобы определить цель его поиска и предоставить более точные результаты.
Сдвиг в сторону семантического поиска совпадает с движением к лучшему пониманию намерений пользователя и предоставлению контента, отвечающего этим потребностям.
По мере того, как Google усиливает свою способность справляться с семантикой, он переходит к использованию большего количества разговорных терминов.
Поиск таким способом в прошлом, показал бы документы, которые содержат слова из запроса, но они не обязательно были теми, которые лучше всего отвечали на эти вопросы.
Рост разговорного и семантического поиска увеличил количество длинных ключевых слов, используемых при поиске.
Ключевые слова с коротким хвостом уже уменьшились в важности, и разговорный поиск неизбежно уменьшит их количество ещё больше.
Обнаружение и затем ответ на эти разговорные фразы и вопросы, которые люди задают о продуктах, услугах или бренде, в целом очень важно, но потенциально важно для успеха и в голосовом поиске.
Они часто вне конкурентной борьбы, что делает их более лёгкими для ранжирования, а это означает, что сайт может появляться чаще, что является довольно простым способом начать создавать значительную видимость и посещаемость. Ведь чем на большее количество вопросов отвечает сайт, тем он ценнее для поисковика, а, следовательно, и имеет больший авторитет, т.е. ранг.
Может показаться что это не самый лучший конвертирующий трафик в мире, но это не так. Такими ответами идет работа над вершиной воронки, что многие бренды игнорируют.
Рекомендуемые фрагменты — нулевая позиция.
Избранные фрагменты, также известные как нулевая позиция, представляют собой результаты поиска, которые отображаются в верхней части SERP и содержат ответы на вопросы пользователей, без необходимости открывать страницу сайта.
Google извлекает информацию со страницы один результат для запроса и ссылается на источник.
Отвечая на вопросы голосового поиска, Google Assistant как правило считывает избранные фрагменты (хотя может использовать и другие результаты).
Фактически, недавнее исследование доктора Питера Дж. Мейерса показало, что 87% ответов голосового поиска происходят из избранных фрагментов.
Многие из этих полей предоставляют информацию общего достояния, например, сколько миллиметров в трёх дюймах, на которые Google отвечает с помощью мгновенных ответов.
Повторюсь, что, получив ответ на свой вопрос, пользователь, как правило не переходит на сайт, но для Google, показывающий такие ответы с сайта, вес сайта возрастает.
Однако Избранные фрагменты извлекаются с любого веб-сайта на первой странице результатов. Более того, Google даёт кредит доверия брендам как в обычном, так и в голосовом поиске.
Если сайт уже продвинулся до первой страницы результатов поиска, вам нужно лишь внести небольшие изменения, а не полностью пересматривать свою стратегию SEO.
Избранные фрагменты помогают людям идти, учиться, покупать или делать что-то. Выполните исследование ключевых слов длинного хвоста, чтобы найти эти вопросы и ответить на них в своем контенте.
Сделайте свой контент лёгким для чтения и понимания Google, поместив вопрос в теги заголовка, а затем коротко ответьте на него.
Табличная и маркированная информация также отличные форматы для избранных фрагментов.
Статистика запросов показывает, что всё больше и больше делается запросов с мобильных устройств, пользуются голосовым поиском.
Так что оптимизируйте сайты сейчас, и это беспроигрышный вариант, если он станет ведущим методом поиска в будущем.
21 фактор. Тошнота
Тошнота — частота использования какого-либо слова в тексте к общему количеству слов в тексте.
Общепризнано, что для благозвучного воспроизведения текста, и лёгкого его восприятия частота каждого слова в тексте не должна превышать 5—7%. Это значит, что на каждые сто слов одно и тоже слово может употребляться не более семи раз.
Наш мозг устроен так, то, что более часто повторяющиеся слова мы воспринимаем как наиболее значимые. Именно поэтому и рассказчик, и в напечатанном тексте суть, основная мысль, ключевые фразы часто повторяются в разговоре или тексте.
Поисковый робот не понимает суть написанного на страницы, он просто подсчитывает количество повторения каждого слова и фраз, и суть, ценность определяет по наибольшему количеству повторений.
Например, вы желаете оптимизировать текст, посвящённый шампуню под сезонный запрос «летний шампунь». Этот шампунь отлично противодействует ультрафиолетовым лучам, и вы в тексте из ста слов повторили фразу «ультрафиолетовые лучи» 8 раз. Но в этом же тексте фразу «летний шампунь» употребили 6 раз. Поисковик по тексту поймёт, что статья посвящена в первую очередь «ультрафиолетовым лучам», а не «летнему шампуню».
Как может показаться начинающему, что по желаемой фразе всё нормально, но поисковик воспринимает, что статья оптимизирована не под сезонный запрос, а под «ультрафиолетовые лучи», причём статья имеет повышенную тошноту, а значит требуется понижение её веса.
Использование синонимов в тексте снижает тошноту. В нашем примере фразу «ультрафиолетовые лучи» следует разнообразить фразами «вредное излучение», и подобными вариантами.
Вычислять величину тошноты в тексте достаточно сложный процесс, поэтому лучше проверять её количество на онлайн SEO оптимизаторах текстов.
Не забывайте, что нормальная человеческая речь без подсчётов укладывается в норму, поэтому статья, написанная специалистом в своей теме и с любовью, всегда уложится в норму даже если автор не имеет понятия о тошноте. Проверено.
Как вычислить плотность ключевых слов?
Существует несколько различных вариантов формул для определения плотности ключевых слов на любой странице. Какой пользуется Google пользователям не известно, поэтому для понимания привожу самую популярную из них.
Плотность = (Nkr / (Tkn — (Nkr x (Nwp-1)))) x 100
· Плотность = плотность вашего ключевого слова или фразы.
· Nkr = сколько раз вы повторяли конкретную ключевую фразу.
· Nwp = количество слов в ключевой фразе.
· Tkn = полные количество слов в анализируемом тексте
Оценка плотности ключевого слова для страницы, по существу, рассчитана с учетом того, сколько раз повторяется конкретная ключевая фраза в документе, количество слов в этой ключевой фразе и общее количество слов в анализируемом тексте.
Естественно предположить, что важно попытаться определить этот заветный процент для достижения высокого рейтинга в Google.
Вопрос в том, какова оптимальная плотность ключевых слов? это 3% или 0,3% или 13%?
Если вы посмотрите онлайн — вы найдете много противоречивого МНЕНИЯ на идеальную плотность ключевых слов, и все это звучит очень научно.
Поэтому по большинству мнений можно принят 3-5-7%.
Вместо того, чтобы смотреть на плотность ключевых слов, лучше сосредоточиться только на их присутствии. Убедитесь, что вы указали ключевые слова (ключевые фразы), которые используете, в теге заголовка страницы, мета-описании и в части содержимого.
Не добавляйте лишние ключевые слова, чтобы получить магию 3,22% или 7,08% (или другой процент, на который стремитесь получить), но заставляйте текст выглядеть естественным.
Если вы дадите кому-то прочитать текст, и тот отметит, что текст хорошо читается, и сможет рассказать, о чем в тексте идёт речь, то с текстом всё в порядке. — Wiep Knoll.
А вот что говорит Google о плотности ключевых слов в качестве ранжирующего сигнала.
Джон Мюллер из Google заявил в 2014 году. —
«В общем, плотность ключевых слов — это то, на чем я бы не сосредоточился. Поисковые системы отчасти отошли от измерения плотности ключевых слов.»
До этого, в 2011 году, Мэтт Каттс официально заявил, что идеальная плотность ключевых слов является заблуждением.
«Это не совсем так… Продолжайте повторять вещи снова и снова, тогда вы рискуете попасть в „заполнение ключевыми словами“».
В Руководстве Google для веб-мастеров говорится:
«Ключевое слово Фарш…. приводит к негативному восприятию пользователя и может нанести вред рейтингу вашего сайта».
Полезно знать, что об этом говорят опытные маркетологи:
Что SEO думает о плотности ключевых слов в качестве ранжирующего сигнала?
Аарон Уолл из SEOBOOK назвал плотность ключевых слов: «переоценённой концепцией».
Джим Бойкин отметил: «Использование соотношения ключевых слов к общему тексту на странице не является хорошим показателем для SEO».
Билл Славски сказал, увидев очень мало упоминаний о плотности ключевых слов в патентах поисковых систем в течение многих лет: «Я всегда считал, что плотность ключевых слов более вероятна, чем факт».
Рэнд Фишкин из MOZ сказал, что:
«ПРАВДА — это просто то, что современные поисковые системы никогда не использовали плотность ключевых слов».
Д-р Эдель Гарсиа один из немногих учёных по поиску информации, который перешёл в SEO ещё в 2005 году ясно дал понять, что «Коэффициент плотности ключевых слов ничего не говорит нам о:
1. Относительное РАССТОЯНИЕ между ключевыми словами в документах.
2. где в документе встречаются термины (РАСПРЕДЕЛЕНИЕ).
3. Частота совместного цитирования между терминами (CO-OCCURRENCE).
4. основная тема, ТЕМА и под темы (тематические вопросы) документов.
Гарсия утверждает, что это будет означать, что «плотность ключевых слов не входит в качество контента».
В своей статье «Плотность бессмысленных слов» Гарсия подытожил:
«допущение, что значения плотности ключевых слов могут быть приняты для оценки весов терминов или что эти значения могут быть использованы в целях оптимизации, равнозначно плотности ключевых слов без учёта смысла.»
Лучшие оптимизаторы уже давно утверждают, что оптимальной плотности ключевых слов НЕТ, пока Google не подтвердил это.
22 фактор. Заспамленность текста
Заспамленность или употребление Стоп-слов или шумовых слов понижают рейтинг страницы.
Поисковики считают эти слова не информативными, а поэтому их пропускают.
Стоп слова делят на общие и зависимые.
К общим стоп-словам относят: частицы, союзы предлоги, местоимения, причастия, междометия.
К зависимым стоп-словам относят слова поисковой фразы. Например, Фёдор Михайлович Достоевский. Здесь для поиска достаточно написать Достоевский, и поисковик поймёт, что желает пользователь. Слова же Фёдор Михайлович будут зависимыми стоп-словами.
Стоп-слова в тексте.
Обойтись без этих слов в тексте невозможно, поэтому поисковики определяют водянистость текста выраженное в процентах.
Водянистость текста = (количество стоп слов: общее количество слов) х 100%.
· До 15% — считается естественное содержание воды в тексте.
· От 15% до 30% — повышенное содержание воды.
· От 30% недопустимо высокое содержание воды в тексте.
Чем больше водянистости, тем больше поисковики уменьшают ранг страницы.
Google не раскрывает те слова и фразы, которые он использует при ранжировании. Одна из возможных причин этого, то, что список постоянно пополняется и уточняется.
К этому фактору понижения рейтинга, думаю, что начинают относиться пустые и затёртые фразы, которые уже бесят пользователей типа: «индивидуальный подход к каждому клиенту», «мы молодая, быстроразвивающаяся компания» и т. д.
23, 24 факторы. Индекс Фога и формула Флеша. Лёгкость чтения
У многих современных людей развито клиповое мышление. Это значит, что люди не способны воспринимать большие объёмы информации, и клиповый формат для них наиболее приемлем.
Это относится и к восприятию текста. Фрагменты текста, или предложения размером в СМС — именно то, что способен полноценно воспринимать среднестатистическому человеку.
Это значит нужно писать короткими, простыми словами и фразами с количеством символов в предложении до 160 печатных знаков. Идеально если в предложении не более 6—7 слов, а слова состоят из 6—7 букв. Западные исследования показали, что среднестатистический молодой человек или девушка при прочтении сложносочинённого или сложноподчинённого предложения, в котором более 10—12 забывают о том, что говорилось вначале.
Это и не мудрено, ведь человек, открывая страницу не приходит из пустоты. У него масса других забот и проблем, которые, кроме заданной поисковику, нужно решить. У него может болеть зуб, он может неудобно сидеть, ждать начальника для получения вливания. На все свои проблемы отвлекается человек, когда просматривает веб-страницу, и чем ниже образование посетителя, тем сложнее ему воспринимать информацию.
(Посмотрите на выдачу в Google, на нулевую позицию (в большинстве эта выдача голосового поиска), там ответы как молния на заданный вопрос. Краткость и точность изложения становится всё более востребованной.)
Уверен, что у русского человека проблем не меньше, чем у западного, а поэтому нижеописанные формулы справедливы и для русских.
Гугл для определения читаемости текста пользуется индексом Фога и формулой Флеша.
Суть индекса и формулы — просты. Чем меньше слов в предложении, и чем короче слова, тем текст более читаемый, а значит такие статьи получают и больший рейтинг.
Поисковые системы прекрасно понимают направленность сайта.
Для научного, информационного или сайта-магазина язык подачи информации различен.
Если сайт, к примеру, новостной, то там не должно быть длинных и сложных предложений. Должно быть больше действия, глаголов и минимум превосходной степени.
Если же это литературный сайт, то предложения могут быть длиннее, для простора творческих фантазий. Конечно, если сайт рассчитан на то, чтобы человек просто расслаблялся на нем.
Для интернет-магазина Google считает, что текст должен быть информационным, больше существительных и глаголов, меньше воды.
Сайт, рассчитанный на подростков, должен иметь простые, короткие слова и предложения, чтобы подросток мог без напряжения понять суть.
Сайт же, рассчитанный на научных работников, должен соответствовать их уровню образования. Если сайт для профессорского состава будет написан школьным языком, то профессора не оценят этот примитивизм, а Google понизит оценку за качество сайта.
Сайт должен соответствовать уровню подготовки читателя, на которого сайт и рассчитан. Именно для этих целей и следует проверять сайт на индекс Фога и формулой Флеша.
Подробнее о методах расчёта.
Образовательный индексе Флеша-Кинсайда показывает, каким уровнем образования должен обладать читатель проверяемого документа. Подсчёт показателя делается на основе вычисления среднего числа слогов в слове и слов в предложении. Значение показателя варьируется от 0 до 20.
· От 0 до 10 означают число классов школы, оконченных читателем.
· От 11 до 15 — соответствуют курсам высшего учебного заведения.
· Больше 15 относятся к сложным научным текстам.
Рекомендуемый диапазон значений этого показателя: от 8 до 10 для среднестатистического покупателя.
Индекс удобочитаемости (Flesch Reading Ease) — мера определения сложности восприятия текста читателем. Он вычисляется на основе нескольких параметров: длины предложений, слов, удельного количества наиболее частотных (или редких) слов и т. д.
Уровень удобочитаемости
90–100 — очень высокий — это выпускник вуза.
80–90 — высокий — студент вуза.
70–80 — выше среднего образования 10–12 классов.
60–70 — средний — 8–9 классов.
50–60 — ниже среднего — 7 классов.
30–50 — низкий 6 классов.
0–30 — очень низкий — 5 классов.
Google не показывает какими формулами он пользуется для определения соответствия текста уровню подготовки, но в своих руководствах рекомендует при написании текстов учитывать уровень образованности пользователя, и писать на языке читателя.
25 фактор. Орфография и грамматика
Google никогда не говорил, что орфография и грамматика напрямую влияют на результаты ранжирования сайтов в поиске. Но это означает лишь, что они не запускают проверку орфографии по всему Интернету.
Однако, можно прочитать в Руководстве по поисковой оптимизации:
«…следует избегать:
· Грамматических и орфографических ошибок в тексте.
· Запутанных формулировок и некачественного контента…»
С другой стороны, алгоритм Google Panda проверяет качество контента, и это не секрет, что качество грамматики влияет на авторитет, а значит и на рейтинг страницы.
Google заявляет, что он просматривает орфографию и грамматику, включая «естественный» язык т.е. в Google помечается куча несвязанных слов, собранных в случайном порядке, а это говорит о том, что текст не авторитетный, и снижается рейтинг веб страницы.
Плохая орфография и грамматика также отрицательно влияет на пользовательские факторы, потому как люди не любят читать тексты с ошибками. Снижается и доверие к сайту с ошибками.
Кроме этого, MOZ исследуя сайты заметил, что сайты, занимающие более высокие места содержат меньше ошибок, чем те, которые ниже.
Легко понять, что Google при прочих равных показателях позиционирует более грамотный текст выше безграмотного.
Орфография и грамматика учитывается и в комментариях, или обсуждениях темы. Но этом случае Google считает, что тема вызвала интерес, идёт обсуждение, а это значит, что тема интересная для пользователей, и поэтому веб-страницы, которая вызвала повышенный интерес добавляется вес. Поисковик уделяет большое внимание поведенческим факторам.
Маркетологи давно заметили, что люди лучше покупают у своих, тех кто близок им по духу, кто говорит на их языке. Но сленг, местный диалект поисковик не учитывает. Кроме этого, молодёжь в силу безграмотности или бунтарства пишет некоторые слова с ошибками, например, слово «сейчас» пишут «щяс» или более короткий вариант: «щя».
Вот и получилась для продавцов товара дилемма: писать грамотно, качественно, или писать на языке потенциальных покупателей.
26 фактор. Количество страниц на сайте
Количество страниц на сайте зависит от вида бизнеса. Веб-сайты получают наибольший рейтинг за уникальный, качественный контент, который регулярно обновляется.
Если бизнес ориентирован на небольшой город, то скорее всего потребуется десяток веб страниц. Если создаете интернет-магазин, который будет продавать товары по всему миру, то потребуется создавать тысячи страниц. Пока сайт уделяет основное внимание пользовательским потребностям, сайт получает прирост в рейтинге.
Создание страниц только ради SEO уменьшит пользовательский интерфейс, а значит и рейтинг сайта.
И наоборот — отсутствие достаточного количества страниц может отрицательно сказываться на рейтинге сайта. Если посетители на сайте не могут найти интересующую его информацию, сайт практически бесполезен для них, и такие сайты наказываются.
Поэтому нужно тщательно подумать структуре сайта, установить цели, которые он должен выполнять, и создать количество страниц, которые имеют смысл для бизнеса.
Каждый бизнес отличается от других, каждый бизнес-сайт будет отличаться от других.
Google проанализировал миллионы сайтов (по поведенческим факторам) по разным видам бизнесов, и вывел, какие страницы и в каком объёме пользователи считают наиболее полезными.
Для этого необходимо перед созданием веб сайта посмотреть результаты выдачи в интересующем направлении бизнеса, и просматривая ТОП 10 выявить те виды страниц, которые имеются у конкурентов.
Из всего многообразия бизнес-сайтов можно выделить 10 основных страниц, которые Google считает желательными для любого сайта.
Эти 10 стандартных веб-страниц являются хорошей отправной точкой для высокого ранжирования сайта:
1. Главная,
2. О нас,
3. Сервисы,
4. Товары / Услуги,
5. Часто задаваемые вопросы,
6. Отзывы,
7. Контакты,
8. Политика конфиденциальности,
9. Блог / Новости,
10. Портфолио.
Естественно, эти страницы не гарант высокого ранжирования веб-сайта, но без отсутствия какой-либо из них резко снижает вероятность попадания сайта в ТОП 10.
Вообще бытует мнение, что сайт, имеющий менее двух-трёх сотен страниц поисковики, не считают серьёзными. Хотя практика показывает, что бывают и чудеса, когда одностаничники (лэндинги) занимали высокие позиции, обходя объёмные сайты.
Это лишний раз говорит о том, что ни один фактор не является решающим. Здесь собираются большие и маленькие капельки, и все они вместе определяют вес сайта.
В случае с одностаничниками же в высоко конкурентных нишах мне не известны случаи, когда, случайно попавший в топ сайт удерживался там долго. Я вполне допускаю, что эта некоторая недоработка фильтров, которая при обнаружении исправляется.
27 фактор. Низкий рейтинг страниц
Если на сайте набирается много страниц, которые имеют низкий рейтинг, то эти страницы снижают и общий рейтинг всего сайта, а соответственно и рейтинг страниц, которые прежде имели более высокий рейтинг.
Исследуйте причины, по которым страницы не имеющие ценности для посетителя, и делайте их лучше, или удаляйте их.
Исключением могут быть микро низкочастотные запросы, в основном это геозависимые, или с использованием специфических терминов. Такие страницы, если удовлетворяют пользовательский интерес, но не уменьшают рейтинг сайта.
Например, маленькое кафе, которое приглашает посетителей своего района города со своими экзотическими пирожными попробовать их уникальный продукт.
КОЛИЧЕСТВО ПРЕДОСТАВЛЯЕМЫХ УДОБСТВ
Обратите внимание, что эти факторы — это плод кропотливой работы Google.
Это не то, что Google поковырялся у себя в носу утречком, а в обед объявил, то он будет резать сайты, которые не предоставляют те или иные услуги.
Эти факторы — исследования Google веб-страниц миллионов сайтов, которые просматривают пользователи, и решают доверять ли этому сайту или нет.
Чем больше и подробнее учтены ниже перечисленные факторы, тем больше доверия к сайту получает посетитель, тем выше становится рейтинг этого сайта.
28 фактор. Количество услуг или товара в интернет-магазине
Авторитетность сайта зависит от количества услуг, которые предоставляет компания. Например, если одно бюро переводов делает переводы на трёх языках, а другое — на двадцати, то более авторитетным Google считает то которое работает с большим числом языков.
Тоже самое и с количеством товаров, чем больше видов товара в магазине, тем больше рейтинг сайта.
Только за счёт увеличения других показателей интернет-магазину с десятком товаров получить более высокий рейтинг в Google, чем магазин, в котором продаётся несколько тысяч подобных товаров.
Практика же показывает, что увеличение других показателей, например, покупка ссылок с высоко ранжируемых сайтов стоит серьёзных дополнительных финансовых вложений, которыми мелкие продавцы не обладают. Но крупные продавцы обычно уже позаботились, и по остальным показателям позаботились об увеличении веса своих страниц.
Мы не берёмся за продвижение в первые ряды мелких сайтов в нишах с большой конкуренцией, где плотно обосновались даже местные гиганты продаж.
Дополнительно читайте фактор «Стандарт YMYL».
29 фактор. Цена
Если на сайте продаётся товар или услуга, то должна быть цена. Это нужно рассматривать как LSI-термин. Величина цены — один из главнейших показателей, влияющих на рейтинг. При ранжировании сайтов. Если на одном сайте цена указана, к примеру 100€, а на другом 200€, при прочих равных условиях, то Google ранжирует выше тот сайт, на котором более низкая цена.
Трудно представить какие другие факторы, и насколько должны быть более весомыми, чтобы товар, или услуга с более высокой ценой ранжировался выше, чем с более низкой.
Единственно, что может предложить продавец — это ряд дополнительных услуг, которые входят в цену. Например, бесплатная доставка, бесплатное обслуживание, и др.
Если же у конкурентов заранее известно, что цена будет всегда ниже, при прочих равных условиях, то не стоит рассчитывать, что сайт с более высокими ценами займёт более высокое положение при выдаче.
К сожалению, многие сеошники обещают чудо, а заказчики живут по словам Пушкина:
«Ах, обмануть меня не трудно!.. Я сам обманываться рад!»
30 фактор. Количество способов оплаты
Только продвинутые пользователи интернет имеют массу различных платёжных карточек. Обычные же покупатели в интернете имеют один способ оплаты, хотя бы потому что солидные продавцы предлагают позаботились о том, чтобы покупатель без труда со своей единственной карточкой мог совершить интернет-платёж.
Представьте себе два магазина, продающие один и тот же товар по одной цене. Первый магазин имеет способ оплаты с имеющейся у покупателя карточки, а второй требует первоначально положить деньги на счёт некоторой платёжной системы, чтобы потом оплатить покупку. Первый продавец предлагает оплатить покупку в два клика, а второй через дополнительную регистрацию, и дополнительное перечисление денег. Какой вариант выберет покупатель?
Как для покупателей, так и для Google имеет большое значение разнообразие способов оплаты, ведущее к украшению платежа. Чем больше выбор вариантов оплаты, тем проще потребителю выбрать наиболее приемлемый для себя. Чем больше способов оплаты, тем более авторитетным считается продавец.
Поисковик ценит этот фактор, и увеличивают рейтинг сайта, который предоставляет много вариантов оплаты, и принимает деньги с любых платёжных систем и интернет-банков.
31 фактор. Количество способов доставки
Покупателю желательно выбрать кто и когда привезёт ему товар. Чем больше вариантов получить товар, тем больше считается удобств предоставляется покупателю, тем больше увеличивается вес сайта.
Кроме облегчения покупателю получение товара, для Google — это дополнительный сигнал, что продавец серьёзный, потратил дополнительные средства и время, чтобы организовать различные способы доставки. Количество вариантов способов доставки увеличивает авторитет сайта.
Если видите, что конкуренты предлагают различные варианты доставки, то и вам нужно позаботится об этом.
32 фактор. Количество мест, где можно получить товар
По количеству мест, в которых покупатель может забрать товар, Google оценивает авторитетность продавца. Чем больше мест у компании, в которых пользователь может получить товар, тем крупнее продавец, тем он более авторитетнее.
Для увеличения рейтинга в Google имеет значение наличие компании в Google My Business, и в кругах.
Дополнительным положительным фактором является то, что адреса компании и её филиалов на сайте совпадают с адресами при регистрации в Google My Business и кругах.
Хорошие сайты по мнению Google достойны показываться в специальных блоках пользователям, которые находятся неподалеку от места зарегистрированном в Google My Business.
33 фактор. Обратная связь и их количество
Значение имеет наличие формы обратной связи, т.е. чтобы посетитель сайта мог задать вопрос прямо на сайте.
Возможность позвонить с сайта прямо со своего смартфона, никуда не переключаясь, также увеличивает вес веб-ресурса. Ещё лучше, когда на сайте имеется несколько телефонов для звонков по разным вопросам. И опять-таки эти же телефоны должны быть прописаны в Google My Business.
И немного забегая вперёд. Когда регистрируется домен сайта компании положительным фактором влияющие на рейтинг сайта является один и тот же номер телефона на сайте и при регистрации.
Это подчёркивает тот факт, что компания работает честно, и ей нечего скрывать. Так тоже добавляется ещё одна капелька к увеличению авторитетности сайта.
Google понимает, что если компания очень большая, то заниматься регистрацией домена может один человек, а обслуживать клиентов — другой, поэтому в этой ситуации не происходит уменьшение рейтинга.
И так, чем больше вариантов связи предлагается посетителю, тем больший вес имеет веб-сайт в Google. И посетителю этот факт внушает большее доверие.
ТЕГИ ВЕБ-СТРАНИЦЫ
Мета теги: сигналы и фантомы
Что такое мета теги?
Мета-теги используются Google и другими поисковыми системами не совсем очевидными способами.
«Мета-теги — отличный способ для веб-мастеров предоставлять поисковым системам информацию о своих сайтах. Они могут использоваться для предоставления информации всем типам клиентов, и каждая система обрабатывает только те мета теги, которые они понимают, и игнорирует остальные. (Они) добавляются в <head> раздел вашей HTML-страницы». GOOGLE.
Помогают ли метатеги SEO?
Высокий рейтинг в Google имеет гораздо большее отношение к актуальности и репутации высококачественного контента, удовлетворённости пользователей и популярности в Интернете, чем простая оптимизация мета-тегов.
По моему опыту, большинство мета-тегов не оказывают значительного влияния на то, где страница находится в Google, положительным образом.
При правильном использовании мета теги могут по-прежнему быть полезными в ряде областей за пределами ранжирования страниц в прямом воздействии, например, для повышения рейтинга кликов в поисковой выдаче. Злоупотребляйте ими, и вы можете получить воздействие карательных алгоритмов, определяющих качество Google.
Каковы наиболее важные мета-теги для SEO?
Для целей этого остановлюсь на трёх мета тегах, которые больше всего влияют на ранг страниц:
· мета-описание (необязательно, возможно, импортируется и иногда используется Google);
· мета-роботы (необязательно, используется Google);
· мета ключевые слова (необязательно, но иногда увеличивают вес в Google).
Использует ли Google то, что находится в мета тегах для ранжирования страниц?
Некоторые поисковые системы когда-то искали скрытые HTML-теги, подобные этим, чтобы упорядочить страницы на страницах результатов поисковых систем, но большинство поисковых систем эволюционировали после этого, и, безусловно, Google это сделал.
Google официально заявляет, что не использует некоторые метаданные при ранжировании страницы (в позитивном ключе), и тесты на протяжении многих лет, безусловно, подтверждали это.
Короче говоря, Google не использует информацию в мета теге ключевых слов или мета теге описания для фактического ранжирования страниц, но использует текст мета-описания для создания фрагментов поиска.
«Дело не в том, что изменение ваших описаний, их удлинение, укорачивание или подстройка ключевых слов повлияют на рейтинг вашего сайта». Джон Мюллер 2017.
Что делают мета-теги в SEO?
Метаданные могут помочь описать любую страницу в более удобном машиночитаемом формате, более подходящем для поисковых систем, но они, скорее всего, будут рассылаться спамом и поэтому в конечном счёте будут ограничены сами по себе, когда дело доходит до ранжирования документов в Интернете.
Более вероятно, что Google будет искать злоупотребления в таких тегах и наказывать их каким-то образом, а не вознаграждать.
Google может использовать метаданные, среди многих других сигналов, для классификации страниц или отображать информацию о странице в поисковой выдаче, хотя в естественных результатах, видно их влияние, где его можно обнаружить, когда оно вообще используется.
Я ищу дубликаты шаблонного текста в мета описаниях, так как они часто являются признаком некачественных страниц. Я делаю это, потому что Google говорит, что им не нравится эта практика — и в их рекомендациях говорится не делать этого.
Возможно, Google смотрит на то, насколько уникально ваше мета описание относительно других страниц вашего сайта.
Предполагается, что страницы «стоят сами по себе» — возможно, алгоритмы проверяют, что они это делают, и вы не используете некачественные методы для их создания.
Я создал инструменты, которые могут идентифицировать страницы дверного проёма, например, путём анализа мета-тегов — так что Google, безусловно, сможет сделать ещё больше.
«[Мета теги] могут влиять на то, как пользователи видят ваш сайт в результатах поиска, и на самом деле переходят на ваш сайт.» Джон Мюллер 2017.
Контролируют ли мета-теги мой поисковый фрагмент в Google?
Иногда, да, по крайней мере, в случае Мета-описания, но не всегда, и это зависит от многих факторов.
Google выберет свой собственный предпочтительный фрагмент поиска для поисковой выдачи для целей отображения, основываясь на элементах, на которые все еще может повлиять тот, кто создал страницу (и сайт) — и то, что Google знает о странице.
ПРИМЕЧАНИЕ: фрагменты SERP «основаны на запросе пользователя».
Имейте в виду, что нет никакой гарантии, что Google будет использовать мета-описание страницы в качестве фрагмента поиска. Текст, представленный во фрагменте поиска Google, является запросным и зависит от запроса.
«Имейте в виду, что мы корректируем описание на основе запроса пользователя. Поэтому, если вы делаете запрос на сайте и видите это в результатах поиска для своего сайта, это не обязательно то, что обычный пользователь будет видеть, когда он также увидит поиск». Джон Мюллер, Google 2017
Meta Description SEO — лучшие практики
Джон Мюллер в 2017 году сообщил:
«Мы экспериментировали с показом более длинных описаний в результатах поиска, и я считаю, что это то, что видят все больше и больше людей. Что касается описаний, которые мы показываем, мы пытаемся сосредоточиться на мета-описании, которое вы предоставляете на своих страницах, но если нам понадобится дополнительная информация или больше контекста, основанного на запросе пользователя, возможно, тогда мы также сможем использовать некоторые части страницы. По сути, с чисто технической точки зрения эти описания не ранжируются. Таким образом изменение ваших описаний, их удлинение, укорачивание или подстройка ключевых слов повлияют на рейтинг вашего сайта».
Мета-тег описания все еще важен как с точки зрения человека, так и с точки зрения поисковой системы, если он используется разумно и правильно.
«Однако это может повлиять на то, как пользователи видят ваш сайт в результатах поиска, и на самом деле они переходят на ваш сайт. Так что это один из аспектов, о котором следует помнить». Джон Мюллер 2017.
Пример кода:
<meta name = «Description» content = «Я бы не стал тратить 2 минуты на оптимизацию мета-тегов ключевых слов для Google, но Google советует нам обратить внимание на мета-описания.» />
Если ваша страница носит информационный характер, вы можете сделать её релевантной ценному запросу, на котором вы сосредоточены, но написать её для людей, а не только для поисковых систем. Если ключевая фраза, для которой вы оптимизируете страницу, найдена в мета-описании, вы обычно можете зависеть от мета-описания, отображаемого в списках Google.
Если ключевое слово в поисковом запросе не присутствует на странице, скорее всего, ваше мета-описание не выйдет в сниппет.
Хотя мета-описания должны быть уникальными — будьте осмысленными, когда вручную пишете уникальный текст мета-описания, который не появляется на странице — или вы просто даёте не связанный текст, и не получаете никакой реальной выгоды от ранжирования.
Google смотрит на описание, но есть спор, использует ли он тег описания для ранжирования страниц. Думаю, что они могут использовать на каком-то уровне это описание, или для конкретных тестов, или для определенных типов страниц.
Из многих тестирований заметно, что это очень слабый сигнал в информационной поисковой выдаче — и это очень зависит от запроса. Во многих наблюдениях Google, конечно, индексирует мета-описание для отображения фрагмента, но не столько для ранжирования страниц, сколько для показа пользователям, которые, глядя на эти описания, решают переходить на предлагаемую веб-страницу или нет.
И всё же, очень важно иметь уникальные теги заголовков и уникальные мета описания на каждой странице вашего сайта.
Я не генерирую описания автоматически на небольших сайтах — обычно пиши мета-описание, используя естественный язык, либо вообще пропустить это тег.
Сколько символов будет отображаться в Google как часть мета-описания во фрагменте SERP?
«Наши фрагменты в Google стали немного длиннее… не расширяйте свои мета-теги описания. Это более динамичный процесс.» Дэнни Салливан, Google декабрь 2017
С декабря 2017 года Google начал отображать фрагменты SERP (страницы результатов поиска), содержащие более 300 символов. С тех пор хорошим практическим правилом было то, что вы можете (если хотите) создавать мета-описания длиной до 300 символов, если хотите, чтобы все сообщение появлялось на странице поиска Google.
Google к 2020 году внёс изменения (об этом читайте далее в факторах ранжирования), поэтому я бы не стал тратить на количество печатных знаков в описании много времени. Тем более, что Google не считает количество символов, а отводит определенное количество пикселей под описание. Об этот также читайте далее.
Нужно делать длинное мета-описание или краткое мета-описание для страниц?
Если у вас очень короткие мета описания, Google отметит это в консоли поиска. С очень коротким мета-описанием вы рискуете потерять желаемое позиционирование в некоторых поисковой выдаче.
С очень длинными мета-описаниями вы рискуете, что Google обрежет тщательно созданные сообщения, которые вы помещаете в этот мета тег.
Google также часто меняет количество символов, отображаемых в поисковой выдаче на разных устройствах, и никогда не гарантируется, что они все равно будут использовать ваше мета-описание.
Джона Мюллера в своём видео выступлении ответил на вопрос:
«Вы бы порекомендовали расширить Мета-описание? Чтобы соответствовать новым ограничениям Google для фрагментов поиска.»
«Мы всегда экспериментировали со ссылкой на фрагмент, и иногда мы показываем больше, иногда мы показываем меньше, и это то, что я думаю, иногда немного сложнее, но я бы порекомендовал делать запросы, которые вы видите в поисковой консоли, где люди на самом деле ищут и пробуют их, а затем видят, как выглядят ваши страницы с помощью фрагмента, и если вы согласны с тем, как они выглядят, то хорошо, если вы предпочитаете иметь что-то другое, то это то, что вы можете изменить Мета-описание, так что это не тот случай, когда я бы сказал, что каждый должен сделать длинное описание, мы показываем разные фрагменты в зависимости от запроса.» Джон Мюллер, 2017.
По вопросу оптимизации мета описаний он уточнил:
«Вы как бы должны сбалансировать своё время и подумать, действительно ли стоит пройтись по сотне тысяч страниц и написать новое описание, или мне просто хотелось бы помнить об этом, когда я создаю новые страницы, и не беспокоиться об этом» много об этом ограничении в сто шестьдесят символов или о чем-то, что было раньше, потому что я думаю, особенно когда мы делаем такие изменения, они имеют тенденцию немного двигаться назад и вперёд, пока мы не найдём правильный баланс.» Джон Мюллер, 2017.
Что Google говорит о мета-описаниях?
Гугл говорит, что вы можете программно-автоматически генерировать уникальные мета-описания на основе содержимого страницы.
Следуйте примеру Google:
<META NAME = «Описание» CONTENT = «Автор: Дж. К. Роулинг, Иллюстратор: Мэри ГрандПре, Категория: Книги, Цена: $ 17,99, Длина: 784 страницы»>
…И их совет, зачем это делать:
«Никакого дублирования, больше информации, и все чётко помечено и разделено. Никакой реальной дополнительной работы не требуется для создания чего-то такого качества: цена и длина являются единственными новыми данными, и они уже отображаются на сайте.» GOOGLE.
Google также говорит:
«Программно генерировать описания для некоторых сайтов, таких как новостные СМИ, создание точного и уникального описания для каждой страницы легко: поскольку каждая статья написана от руки, требуется также минимум усилий, чтобы добавить описание, состоящее из одного предложения.
«Для больших сайтов, управляемых базой данных, таких как агрегаторы продуктов, рукописные описания более сложны. В последнем случае, однако, программная генерация описаний может быть уместной и поощряется — просто убедитесь, что ваши описания не являются «спамом». Хорошие описания понятны человеку и разнообразны, как мы говорили в первом пункте выше. Специфичные для страницы данные, которые мы упоминали во втором пункте, являются хорошим кандидатом для программной генерации.
Используйте качественные описания.
«Наконец, убедитесь, что ваши описания… качественные описательные. Качество мета-описаний легко ослабить, поскольку они не видны непосредственно в пользовательском интерфейсе для посетителей вашего сайта. Но мета-описания могут отображаться в результатах поиска Google — если описание достаточно высокого качества. Небольшая дополнительная работа над вашими мета-описаниями может иметь большое значение для показа соответствующего фрагмента в результатах поиска. Это может улучшить качество и количество вашего пользовательского трафика». Google.
Это значит, что если вы сделали завлекающий на сайт описание, то пользователи будут кликать на сниппет, с этим описанием. Тем самым Google будет видеть по пользовательским факторам (см. ниже) что ваш контент привлекает внимание, и будет повышать рейтинг страницы по этому запросу пользователя.
Получается, что привлекательное описание мало влияет как таковое на рейтинг, но оказывает большое влияние через пользовательские факторы.
Так же хорошее мета-описание влияет на качество страницы. Об этом более подробно читайте в соответствующих факторах.
Можно ли контролировать, какое сообщение появляется во фрагменте поиска Google?
В настоящее время Google официально заявляет, что они склонны игнорировать спам-мета-теги описания, например:
«Поскольку мета-описания обычно видны только поисковым системам и другому программному обеспечению, веб-мастера иногда забывают о них, оставляя их совершенно пустыми. Также по той же причине часто используется одно и то же мета-описание на нескольких (а иногда и на многих) страницах. С другой стороны, это также относительно часто, что описание полностью не по теме, низкого качества или откровенного спама. Эти проблемы бросают тень на опыт поиска наших пользователей, поэтому мы предпочитаем игнорировать такие мета описания.» Google.
В то время как поисковые системы имеют гораздо лучшие способы классификации спама, все же стоит помнить, что поисковые системы всегда в поисках манипуляций, которые идут далеко. Bing публично заявил, что они обращаются к метаданным для выявления признаков манипулирования (уверен, что и Google фиксирует этот сигнал), поэтому вы должны понимать, что, вероятно, существует определенная степень риска, связанная с оптимизацией метаданных.
В большинстве органических результатов, на которые я смотрел, размещение ключевого слова в описании не приведёт к тому, что страница низкого качества окажется на 1-м месте, и вы не окажетесь на 50 местах в конкурентной нише, поэтому зачем оптимизировать для поисковой системы, если вы можете оптимизировать её для человек?
Уверен, что это гораздо более ценно, особенно если вы уже в тренде поиска, то есть на первой странице своего ключевого слова.
Аргумент, который необходимо сделать, — сосредоточьтесь на пользователей в информационных списках в Google, если вы хотите получить сотрудничество от Google.
Мета-тег описания важен на каком-то уровне в Google, Yandex, Yahoo и Bing, а также в любом другом листинге поисковика, и вы можете использовать его несколькими способами, но ориентируйтесь на пользователя, оставляйте этот тег информативным и актуальным.
Я часто опускаю мета описания на страницах, и в основном, когда страница ориентирована на текст более 2000 слов с оптимизацией на несколько ключевых фраз, потому что думаю, что моё время лучше сосредоточить на более важных проблемах на сайте, или когда я ещё не могу выбрать одну, главную ключевую фразу. Я часто захожу на страницы, чтобы создать более качественные описания, и часто полагаюсь на автоматическое создание уникальных, информационных мета-описаний, которые одобряет Google.
«Для более крупных сайтов, управляемых базой данных, таких как агрегаторы продуктов, рукописные описания могут быть невозможны. Однако в последнем случае программная генерация описаний может быть уместной и поощряется.» Google.
Если у Google есть причина, он урезает ваше мета-описание для отображения.
Это самый интересный пример, который Google даёт сайтам электронной коммерции:
«Включите чётко обозначенные факты в описание. Мета-описание не обязательно должно быть в формате предложения; это также отличное место для включения структурированных данных о странице. Например, в новостях или публикациях в блоге может быть указан автор, дата публикации или дополнительная информация. Это может дать потенциальным посетителям очень актуальную информацию, которая в противном случае может не отображаться во фрагменте. Точно так же на страницах продукта могут быть ключевые биты информации — цена, возраст, производитель — разбросанные по всей странице. Хорошее мета-описание может объединить все эти данные. Например, следующее мета-описание содержит подробную информацию о книге.»
<meta name = «Description» content = «Автор: А. Н. Автор, Иллюстратор: P. Picture, Категория: Книги, Цена: $ 17.99, объем: 784 стр.>
Могу ли я заставить мое мета-описание использоваться Google?
Трудно заставить Google сделать что-либо с какой-либо надёжностью.
Это возможно, но, чтобы получить, например, мета-описание для ключевого слова, вам обычно нужна фраза ключевого слова в мета-описании. Обратите внимание, что если ключевое слово в мета-описании в первую очередь заключается в том, что оно является дубликатом элемента заголовка страницы, то, в соответствии с рекомендациями Google — это не идеально — и, возможно, даже ненужное дублирование.
Например,
Заголовок страница: «Изготовляем и доставляем пиццу»
И мета-описание: «Изготовляем и доставляем пиццу по всему городу…»
Представьте такой сниппет на страницы поиска. Посетитель вместо того, чтобы под заголовком получить дополнительную информацию, например, какие виды пицц изготовляются, видит повторяющийся текст.
Я обращаю очень пристальное внимание на то, что Google говорит в эти дни, особенно после обновления качества Google в мае 2015 года и других обновлений качества сайта, таких как Google Panda, которые Google может использовать для ранжирования вашего сайта.
То, что на мета-описание может повлиять то, на что можно повлиять, не означает, что вам следует это делать, если он дублирует текст в элементе title. Этот совет прямо от Google.
«Генерирование заголовков и описаний страниц (или фрагментов) Google полностью автоматизировано и учитывает как содержание страницы, так и ссылки на неё, появляющиеся в Интернете. Цель фрагмента и заголовка состоит в том, чтобы наилучшим образом представить и описать каждый результат и объяснить, как он соотносится с запросом пользователя.» Google.
В течение последних нескольких лет можно было полагаться на тег заголовка страницы (который не является мета тегом и фактически называется элементом заголовка страницы) для предоставления «заголовка» поискового фрагмента в Google и мета-описания (если ключевое слово, фраза присутствовала) часто предоставлял описание фрагмента страницы, что облегчало создание сообщения в списках Google.
Google радикально изменил способ создания фрагментов страницы, чтобы улучшить взаимодействие с пользователем и улучшить работу поисковой системы.
Есть ещё много вещей, которые вы можете сделать, чтобы «привлечь внимание» к своему фрагменту (сниппету) страницы, но будьте осторожны, используя «звёздочки» или другие специальные символы — если вы «торчите», как больной большой палец — это не совсем то, что намеревается Google. Оставьте свой призыв к действию в тексте — не полагайтесь на глюки.
Думаю, что в долгосрочной перспективе Google хотел бы, чтобы любая гарантированная «манипуляция» поисковым сообщением в поисковой выдаче была преимуществом его платной схемы AdWords, а не её естественных результатов. Он не хочет, чтобы SEO делал это … … не за пределами разметки Schema.org.
Google больше не требует информации в различных тегах для ранжирования или отображения страниц, все больше полагаясь на новые сигналы для ранжирования и отображения страниц в поисковой выдаче.
Мета-описание SEO-тесты и наблюдения
Хотя я обычно фокусируюсь в основном на пользователях при создании мета-описаний, я потратил много времени на то, чтобы делать наблюдения, делать заметки и нечасто проверять, была ли возможность, когда дело доходит до всего, что связано с SEO, включая элементы страницы, и включая метаданные, и в том числе мета-описание.
Каждой странице нужно мета-описание?
Google говорит:
«Убедитесь, что каждая страница на вашем сайте имеет мета-описание». Google.
Хорошее мета-описание может быть еще одним сигналом качественной страницы.
Можно ли занимать высокие места без мета-описания?
Да. Google, как правило, может извлечь соответствующий фрагмент из страницы, которую вы можете затем вернуться и оптимизировать для рейтинга кликов, если вы думаете о лучшем сообщении, которое вы хотите отобразить в поисковой выдаче для этой страницы.
ПРИМЕЧАНИЕ. Google советует вам использовать мета-описание на страницах, а не пропускать его.
Использует ли Google мета-описание при ранжировании страницы?
Многие люди используют в тестах тарабарские слова. Я всегда использовал уникальные фразы, которые появляются только в скрытых элементах — и у меня много страниц повсюду. Меня интересует только то, что я вижу и что на самом деле помогает ранжированию страниц в поисковой выдаче.
· Google игнорирует мета-описание, когда ключевое слово также отсутствует на странице — какие подсказки предлагает Google игнорирует мета-описание при возврате основного результата поиска пользователю.
· Google по- прежнему читает мета-описание и использует его во фрагментах, если вы используете определенные операторы — если вы хотите, чтобы мета-описание отображалось как фрагмент, поместите в него ключевое слово (и это ключевое слово также должно быть на странице).
Метая Ключевые слова SEO лучшие практики
«Но, если вы смотрите на мета теги ключевых слов, мы на самом деле не используем их вообще.» Мэтт Каттс, Google, 2009.
Google очень хорошо понимает мета-ключевые слова (или мета-теги ключевых слов) — они не используют их:
Пример использования кода
<meta name = «Keywords» content = «SEO, поисковая оптимизация, оптимизация» />.
(Однако, как говорил ранее, в 2019 году одному моему клиенту было достаточно на веб-страницу вставить ключевые слова, и этого было достаточно, чтобы его сайт существенно поднялся в поиске.)
«Вы правы в том, что мы обычно игнорируем содержимое мета тега „ключевые слова“. Как и в случае с другими возможными мета тегами, не стесняйтесь размещать его на своих страницах, если вы можете использовать его для других целей — это не будет штрафоваться». Джон Мюллер, Google.
Роботы Метатег SEO Лучшие практики SEO
Пример кода:
<meta name = «robots» content = «index, nofollow» />
Я мог бы использовать вышеуказанный мета тег, чтобы сказать Google индексировать страницу, но не переходить по каким-либо ссылкам на странице, если по какой-то причине я не хотел, чтобы страница отображалась в результатах поиска Google, но я хочу, чтобы Google следовал по ссылкам на этой странице.
«По умолчанию Googlebot будет индексировать страницу и переходить по ссылкам на неё. Так что нет необходимости отмечать страницы значениями содержимого INDEX или FOLLOW.» Google.
Существуют различные инструкции, которые вы можете использовать в своём мета теге роботов, но помните, что Google по умолчанию будет индексировать и переходить по ссылкам, поэтому вам не нужно включать это в качестве команды — вы можете полностью исключить метаданные роботов — и, вероятно, следует если у вас нет подсказки.
«Робот Google понимает любую комбинацию строчных и прописных букв.» Google.
Допустимыми значениями атрибута «CONTENT» для мета тега роботов являются: «INDEX», «NOINDEX», «FOLLOW», «NOFOLLOW». Довольно понятно.
Примеры:
· META NAME = «ROBOTS» CONTENT = «NOINDEX, FOLLOW»
· META NAME = «ROBOTS» CONTENT = «INDEX, NOFOLLOW»
· META NAME = «ROBOTS» CONTENT = «NOINDEX, NOFOLLOW»
· META NAME = «ROBOTS» CONTENT = «NOARCHIVE»
· META NAME = «GOOGLEBOT» CONTENT = «NOSNIPPET»
Google понимает следующее и интерпретирует следующие значения метатегов роботов:
· NOINDEX — предотвращает включение страницы в индекс.
· NOFOLLOW — запрещает роботу Google переходить по любым ссылкам на странице. (Обратите внимание, что это отличается от атрибута NOFOLLOW уровня ссылки, который не позволяет Googlebot переходить по отдельной ссылке.)
· NOARCHIVE — предотвращает доступ к кэшированной копии этой страницы в результатах поиска.
· NOSNIPPET — предотвращает появление описания под страницей в результатах поиска, а также предотвращает кеширование страницы.
· NONE — эквивалент «NOINDEX, NOFOLLOW».
На уровне страницы — это мощно. Когда я оптимизирую страницу для Google, я обычно сосредотачиваюсь на содержании страницы (MC) и опыте пользователя, и меня обычно интересуют следующие элементы страницы:
· Элемент заголовка — Важно — Уникальный.
· Мета-описание (необязательно, но желательно в большинстве случаев) — уникально.
· Роботы (опционально) — будьте осторожны.
Эти теги находятся в разделе [HEAD] на странице [HTML] и представляют собой единственные теги для Google, на которые действительно обращают внимание. Почти все остальное, что вы можете вставить в [HEAD] вашего HTML-документа, не значительно, и, возможно, даже бессмысленно.
Google прямо говорит в своих рекомендациях:
«Google будет игнорировать мета-теги, которые он не знает». Рекомендации Google для веб-мастеров, 2018
Как Google относится к «noindex, follow» в метатеге роботов на страницах
Это ошибочное мнение в сообществе SEO, что Google обрабатывает это, как некоторые могут подумать:
«Так что с noindex это довольно сложно. Что, я думаю, является чем-то вроде заблуждения в целом, так как сообщество SEO в этом «с noindex и follow», мы по-прежнему видим случай, когда мы видим noindex, и на первом этапе мы говорим: «Хорошо, вы не хотите, чтобы эта страница отображалась в результаты поиска. Мы по-прежнему будем хранить его в нашем индексе, просто не будем его показывать, и тогда мы сможем перейти по этим ссылкам.
Но если мы увидим там noindex дольше, чем мы думаем, эта страница действительно не хочет использоваться в поиске, поэтому мы полностью удалим ее. И тогда мы все равно не будем переходить по ссылкам. Таким образом, noindex и follow по сути аналогичны noindex, nofollow. Там нет большой разницы в долгосрочной перспективе». Джон Мюллер, Google.
И
«noindex, follow» «по сути то же самое, что и» «noindex, nofollow» Джон Мюллер, Google.
А также
«если бы кто-то связал эту страницу, а у вас было установлено значение noindex, как если бы они ссылались в никуда», Джон Мюллер, Google 2018.
Использует ли Google метатег ODP Robots?
Мета-тег Open Directory Data теперь устарел!
Google использовал данные из ODP для создания фрагментов, хотя вы можете сказать Google не использовать эти данные, используя мета-теги, и я обычно использовал этот тег тоже.
<meta name = «robots» content = «NOODP» />
Чтобы специально запретить Google использовать эту информацию для описания страницы, используйте следующее:
<meta name = «googlebot» content = «NOODP»/>
Если вы используете метатег robots для других директив, вы можете объединить их.
<meta name = «googlebot» content = «NOODP, nofollow» />
Google больше не следует этому мета тегу.
«С закрытым DMOZ (ODP) мы перестали полагаться на его данные, и, таким образом, директива NOODP уже не используется».
Использует ли Google мета-теги Geo для ранжирования страниц?
Нет: Google не использует мета-теги Geo для ранжирования страниц.
«Мы вообще не используем гео мета теги для поиска, вероятно, никогда не используем. Используйте hreflang + обычный геотаргетинг». Джон Мюллер, Google, 2017.
Использует ли Google мета-теги Googlebot для ранжирования страниц?
Да:
<meta name = «googlebot» content = «…,…»>
Эти мета-теги определяют, как поисковые системы сканируют и индексируют страницу. Мета-тег «роботы» определяет правила, применимые ко всем поисковым системам, а мета-тег «googlebot» определяет правила, применимые только к Google. Google понимает следующие значения (при указании нескольких значений разделяйте их запятой):
· noindex: предотвращает индексацию страницы.
· nofollow: не переходите по ссылкам с этой страницы при поиске новых страниц для сканирования.
· nosnippet: не показывать фрагмент этой страницы при отображении его в результатах поиска.
· noarchive: не отображать ссылку «Кэширование» для этой страницы в результатах поиска.
· unavailable_after: [date]: удалить эту страницу из результатов поиска после указанной даты и времени.
Правило по умолчанию «index, follow» — оно используется, если вы полностью пропустите этот тег или если вы указали content = «all».
Как примечание, теперь вы также можете указать эту информацию в заголовке ваших страниц, используя HTTP-директиву «X-Robots-Tag».
Это особенно полезно, если вы хотите настроить сканирование и индексирование не-HTML-файлов, таких как PDF-файлы, изображения или другие виды документов.
Использует ли Google метатег «notranslate»?
Да:
<meta name = «google» content = «notranslate»>
«Когда мы понимаем, что содержание страницы не на том языке, который пользователь, вероятно, захочет прочитать, мы часто предоставляем ссылку в результатах поиска на автоматический перевод вашей страницы. В целом, это дает вам возможность предоставить свой уникальный и привлекательный контент гораздо большей группе пользователей.
Однако могут быть ситуации, когда это нежелательно. Используя этот метатег, вы можете указать, что не хотите, чтобы Google предоставил ссылку на перевод для этой страницы. Этот метатег, как правило, не влияет на рейтинг страницы для какого-либо конкретного языка.»
Дополнительную информацию можно найти в «FAQ по Google Translate».
Что означает «проверить» метатег контроля?
Это специальный метатег Google Search Console для подтверждения права собственности на ваш сайт в Google. Обратите внимание, что «метатег verify-v1» является исключением, он чувствителен к регистру»:
<meta name = «verify-v1 ″ content =«… ”> «Этот метатег для инструментов Google для веб-мастеров используется на странице верхнего уровня вашего сайта, чтобы подтвердить право собственности на сайт в инструментах для веб-мастеров (в качестве альтернативы вы можете загрузить HTML-файл для этого).
Значение содержания, которое вы вводите в этот тег, предоставляется вам в вашем аккаунте инструментов для веб-мастеров. Обратите внимание, что, хотя содержимое этого метатега (включая верхний и нижний регистр) должно точно соответствовать предоставленному вам, не имеет значения, измените ли вы тег с XHTML на HTML или формат тега соответствует формату твоя страница.» Google.
Консоль поиска Google AKA Инструменты для веб-мастеров
Google также будет искать метаданные при подключении вашего сайта к Инструментам Google для веб-мастеров. Если вам когда-либо понадобится использовать этот метод проверки, его легко применить к HEAD.
Использует ли Google мета теги http-эквивалент = «Тип контента»?
<meta http-equ = «Content-Type» content = «…; charset =…»>
«Этот мета тег определяет тип содержимого и набор символов страницы. При использовании этого мета тега убедитесь, что значение атрибута содержимого заключено в кавычки; в противном случае атрибут charset может быть интерпретирован неправильно. Если вы решите использовать этот мета тег, само собой разумеется, что вы должны убедиться, что ваш контент действительно находится в указанном наборе символов». Google.
<meta http-эквивалента = «refresh» content = «…; url =…»>
«этот мета тег отправляет пользователя на новый URL через определенное время, иногда используемый как простая форма перенаправления. Этот вид перенаправления поддерживается не всеми браузерами и может сбить пользователя с толку. Если вам нужно изменить URL-адрес страницы, как это показано в результатах поиска, мы рекомендуем вместо этого использовать перенаправление на сервер 301. Кроме того, в «Методиках и сбоях W3C для Руководства по обеспечению доступности веб-материалов 2.0» он указан как устаревший.
Нужен ли Google код метаданных в нижнем или верхнем регистре?
Google может читать оба:
(X) HTML и использование заглавных букв Google может читать мета теги как в HTML, так и в стиле XHTML (независимо от кода, используемого на странице).
Кроме того, прописные или строчные буквы обычно не важны в мета тегах — мы одинаково относимся к <TITLE> и <title>. Мета тег «verify-v1» является исключением, он чувствителен к регистру.
Использует ли Google метатег Revisit-After?
Нет:
«Иногда веб-мастерам не обязательно включать «revisit-after», чтобы стимулировать график сканирования поисковыми системами, однако этот мета тег в значительной степени игнорируется.
Если вы хотите предоставить поисковым системам информацию об изменениях на ваших страницах, используйте и отправьте карту сайта XML. В этом файле вы можете указать дату последнего изменения и частоту изменения URL-адресов на вашем сайте». Google.
Как насчёт мета тегов заголовка страницы?
Элемент заголовка страницы не является мета тегом, хотя часто на него ссылаются.
Заголовки страниц не классифицируются как мета теги. Они правильно понимаются как элементы заголовка страницы.
В соответствии с передовой практикой в заголовках страниц должно быть не более 1–12 слов (при наличии ключевой фразы-фокуса), однако, обратите внимание, для удобства использования, вероятно, лучше иметь самые названия.
Google использует ключевые слова и ключевые фразы в элементе «Заголовок страницы» при оценке страницы и часто, но не всегда, в качестве заголовка фрагмента поиска страницы в поисковой выдаче. Google нравится заголовки в пределах этого и гарантировать, что важные ключевые слова находятся в пределах первых 8 слов или около 60 букв.
Как написать эффективные мета теги?
Об этом подробно читайте в факторах, а здесь — общие положения.
Вы по-прежнему можете проявлять творческий подход, думая о некоторых тегах, таких как мета-описание, но мета-теги лучше всего использовать, когда они точно описывает страницу, о которой идёт речь, и помогают Google быстро получить информацию о вашей странице.
Если вы помогаете Google обслуживать, особенно информационные запросы, а также помогаете быстро получить доступ к данным, Google — ваш друг, помощник, и большинство мастеров по-прежнему могут извлечь выгоду из этих отношений.
При правильном использовании мета-описания традиционно помогает сформировать чрезвычайно важный «крючок» вашей рекламы в бесплатных поисковой выдаче.
Ваши теги должны быть точными, релевантными и описательными. Будьте осторожны, сосредотачивая их все без необходимости на одном ключевом слове, но не думайте о «мета тегах», пока вы не подумали о том, что такое «тема» и «концепция» страницы, его «цель» и конечный «пользовательский опыт».
Удовлетворение всех является ключом к созданию репутации в Google и в социальных сетях. Если вы оптимизируете для Google, не думайте о странице или статье, думайте «тема» и ваш «информационный центр». В будущем Google стремится вернуть богатые, информативные редакционные страницы в многих органических результатах — эта тенденция очевидна уже сейчас в некоторых нишах.
Все основные поисковые системы рекомендуют разумное использование метаданных, и, если вы пишете полезные описательные теги, маловероятно, что какая-либо основная поисковая система накажет правильное использование — по крайней мере, когда не используются некачественные ярлыки.
Большинство поисковых систем используют или использовали метаинформацию для классификации документа, но только потому, что поисковая система «использует» теги мета-описания, например, не означает, что они используют её как прямой сигнал положительного ранжирования, где Ваша страница занимает место в поисковой выдаче.
Вы познакомились с сигналами, которые в некотором случае оказались фантомными. Теперь приступим к рассмотрению факторов, которые учитывает Google.
ФАКТОРЫ ВЕБ-СТРАНИЦЫ
34 фактор. Тег заголовка веб страницы
Тег заголовка показывает название страницы сайта. Заголовок на скриншоте отмечен красным прямоугольником.
Тег заголовка веб страницы предназначен для краткого и точного описания содержания страницы. Для многих пользователей он не имеет никакого значения, в обозревателе.
Его используют поисковые системы в результатах поиска в качестве заголовка.
Пример кода написания заголовка.
<HEAD>
<title> Пример заголовка </ title>
</ HEAD>
Оптимальный формат
Ключевое слово — LSI ключевое слово | Фирменное наименование:
товара / услуги — товара и инструменты | Мир товара
Google обычно берет первые 50—60 печатных знака.
Число не точное, потому что на самом деле поисковик под хранение заголовка отводит 600 пикселей на любом языке. Но начертание букв имеет разное количество пикселей. Например, Буквы «г» и «М».
Поэтому лучше быть кратким, и не вылизать из 50 печатных знаков. Если заголовок будет длиннее, то поисковик его обрезает, и важная информация после 50-й буквы не будет учтена поисковиком.
Заголовок страницы не желательно писать заглавными буквами, потому как заглавные буквы «съедают» больше пикселей, чем прописные. Однако — это хороший прием, выделиться из общей массы заголовков, написанных строчными буквами. Смотрите как написали свои заголовки ваши конкуренты по выдачи, и оформляйте заголовок отличительно от них.
Кроме как в веб браузере и на страницах результатов поиска заголовок отображается и социальных сетях.
Так социальные сети используют тег заголовка, чтобы определить, что показывать, когда пользователь делится страницей.
В некоторых социальных сетях, включая Facebook и Twitter есть свои собственные мета теги, которые позволяют писать заготовки, отличающиеся от оригинальных заголовков на странице. Специально прописанный заголовок для Facebook и Twitter на странице может привлекать большее внимание читателей социальных сетей, но не добавляет веса страницы сайта.
За длинные заголовки поисковик не штрафует, но обрезает их. Проблемы могут возникнуть, когда заголовок набивается ключевыми фразами.
Например, «Купить платье, лучшие платья, дешёвые платья, платья на продажу!»
Ценность страницы повышается если она имеет уникальный заголовок.
Для информационного сайта заголовок — это ключевая фраза и далее дополнительные сведения, вытекающие из текста.
Для большого интернет-магазина, где однотипный товар, Google рекомендует писать заголовки в следующем формате.
[Наименование продукта] — [Категория продукта] | [Название бренда]
Google отрицательно относится к названиям страниц, подставляемых по умолчанию, например, «Главная», или «Новая страница». Легко представить, как и пользователи будут реагировать, когда в результатах поиска увидят: «Страница продукта» или «Без названия». Именно поэтому на первой страницы результатов поиска не попадают страницы с такими названиями.
Как известно при просматривании страниц поиска пользователь не прочитывает весь текст, предлагаемый поисковиком, а обращает внимание на первые два слова заголовка, и если видит, что эти слова хотя бы созвучны с его словами, которые набрал в строке поиска, то обращает внимание на остальной заголовок и текст под ним. Поэтому Google рекомендует начинать описание страницы с ключевой фразы, или созвучной с ней.
По исследованиям Moz чем ближе ключевая фраза к началу заголовка, тем чаще люди кликают на него.
Один из примеров, на котором показано как это работает. Этот пример характеризует и корректность написания заголовков.
Вариант 1. «Подарочные карты и сертификаты E-Gift».
Вариант 2. «Купить подарочный сертификат E-Gift для друга».
В первом варианте 85% пользователей смогли предсказать, что им предлагается.
Во втором варианте, чтобы понять, что предлагается, потребовалось прочитать весь заголовок. Практика показывает то, что первое слово купить в заголовке страницы отпугивает тех, кто в своём запросе не набрал это слова.
Поэтому избегайте при построении заголовков конструкций типа
Название фирмы | категория продукта — подкатегория продукта — Название продукта.
Так снижается уникальность заголовка. Если же заголовок длинный, то его уникальная часть будет обрезана, не сохранена, а поэтому полностью пропадёт уникальность заголовка.
Если же продаёте брендовый продукт, то все-таки его название лучше помещать в конце заголовка. Но если потребитель более ориентирован на бренд, то в этом случае это правило можно не соблюдать. Бывают случаи, когда Google сам добавляет в заголовок название бренда. Поэтому обращайте внимание на то, как отображается заголовок в результатах поиска.
Помните, что заголовок в результатах поиска — это первое знакомство с компанией и продуктом, это первое впечатление, которое оставляете у потенциального посетителя. Первое же впечатление должно быть наиболее позитивным и содержать точное сообщение.
Если заголовок по мнению Google — плохой, то поисковик берет на себя право подставлять свой заголовок.
Это возникает по нескольким причинам, и является понижающим фактором веса страницы, поэтому заголовки нужно переписать в следующих случаях.
· Когда заголовок чрезмерно оптимизирован. Вспомните пример: «Купить платье, лучшие платья, дешёвые платья, платья на продажу!».
· Заголовок страницы не соответствует её содержанию. Для примера вспомните фактор тошноты, подразумевается оптимизация под одну фразу, а по тексту чаще употреблялась другая фраза.
Если на странице используются мета теги для Facebook или Twitter, Google может брать заголовок из этих тегов. Это и не плохо и не хорошо, но в этом случае следует подумать на сколько такой заголовок соответствует введённому пользователем запросу.
35 фактор. Ключевая фраза в заголовке — первая
Согласно исследованиям, MOZ заголовки, которые начинаются с ключевой фразы лучше позиционируются в Google, чем заголовки, в которых ключевая фраза стоит в конце.
Например, ключевая фраза «Царские монеты»
Вариант 1. «Царские монеты купить на аукционе Dils».
Вариант 2. «Купить на аукционе Dils царские монеты».
Для Google, как и для пользователей первый вариант предпочтительнее. Этот фактор показывает, что Google проводит исследования поведенческого фактора, и свои наработки включает в свои фильтры ранжирования.
Бывший Гуглер, Андре Вейхер, который работал в команде Google Search Quality заявил:
«Не размещайте более 2 коммерческих ключевых слов в своих заголовках, иначе Google не одобрит их».
36 фактор. Повторяющиеся заголовке страницы
Также, как и повторения одних фраз с маленькими изменениями на разных веб-страницах отрицательно влияет на вес страниц. Одна и та же фраза на всех титлах (заголовки страницы) ещё больше уменьшают ранг. Я уже не говорю о
Самая распространённая ошибка менять в заголовке страницы только ключевые слова.
Например,
· Замена экрана на телефоне за один час, в нашей сети ремонтных мастерских…
· Замена кнопки Home на телефоне за один час, в нашей сети ремонтных мастерских…
· Замена батареи на телефоне за один час, в нашей сети ремонтных мастерских…
Фактически, Search Console предупреждает, если у вас их слишком много таких описаний страниц. До лучше писать однотипно, как это делают программы автоматической подстановки мета тегов, чем оставлять этот тег пустым. Но лучше если взялись, то сделать правильно.
37 фактор. Тег описания веб страницы
Ещё в сентябре 2009 года неоднократно звучали заявления, что ни мета описания, ни мета-ключевые слова не являются факторами для ранжирования в поиске Google Но эти теги существенно влияют на поведенческие факторы, которым Google уделяет всё большее значения.
Поэтому рассмотрим описание страницы подробно.
Тег описания страницы, или description — это служебный тег, предназначенный для поисковиков.
Этот тег не виден на веб странице, он находится в верхней части страницы в разделе <HEAD> кода.
Формат тега описания страницы имеет вид:
<meta name=«description» content=«Краткое описание страницы.» />
В поисковых системах он выглядит как показано на скриншоте.
Этот тег после заголовка — второй контакт пользователя с предложением. Это своего рода анонс, реклама, которая должна заинтересовать пользователя и побудить желание перейти на сайт.
Поэтому от его качества описания зависит будет посещение страницы или нет.
Поэтому превосходный тег описания страницы (description), по которому осуществляются переходы на сайт существенно добавляет вес страницы, потому что учитывается как поведенческий фактор.
Дэнни Салливана (аналитик и журналист, который работает на Google) в 14 мая 2018 года в Твиттере (@dannysullivan) опубликовал твит, о том, что сейчас фиксированной длины у дескрипшена нет. То есть описание страницы всегда генерируется на основе массы переменных (запроса пользователя, его локации, устройства и т.п.)
И тем не менее хорошо написанное описание страницы учитывается поисковиками.
Поэтому справедливы следующие правила написания этого тега.
1. Описание страницы должно быть не более 160 символов.
2. В описании можно использовать только буквенно-цифровые символы. Если Google видит кавычки и другие символы, то он игнорирует эти описания.
3. Google покажет тег описания, если в теге описания, запросом пользователя и содержимым страницы существует достаточно сильное совпадение с содержанием. Если хотите, чтобы Google показывал тег описания, включите в него ключевые слова этой страницы. Если эти слова будут совпадать с запросом пользователя, то они будут выделены жирным шрифтом.
4. Ложные обещания — увеличат посещаемость, но посетители будут быстро покидать страницу, а по этому поведенческому фактору Google уменьшит рейтинг страницы, и она уйдёт с первого листа поиска.
5. Описание должно быть обзором страницы.
6. Посетитель ищет или информацию, или желает купить. В описании нужно отразить, что это информационная или страница, на которой можно купить.
7. Описание будет более доходчиво если написано простым языком, на котором говорит пользователь.
8. Описание страницы плохо воспринимается если оно дублирует заголовок. Если описание раскрывает смысл заголовка, то процент кликабельности многократно возрастает.
9. Уникальное торговое предложение (УТП) в описании выделяет предложение из общей массы. Например, если предлагаете бесплатную консультацию, или тест драйв, то укажите это в конце описания.
10. Только уникальное описание страницы воспринимается поисковиком положительно.
11. Описание страницы следует делать на том языке, на котором текст страницы.
12. Относитесь к мета-описанию, как к рекламе вашей веб-страницы: сделайте его максимально привлекательным насколько это возможно.
Иногда лучше не писать дескрипшен.
1. Когда сленговая страница.
2. Если страница настраивается на большое количество ключевых фраз. В этом случае лучше, чтобы поисковик сам выбрал описание, в соответствии с запросом пользователя тот фрагмент текста, который наиболее подходит запросу.
Если у вас, например, страница ориентирована на весьма популярный запрос «ремонт мобильных телефонов», и чтобы превзойти конкурентов, вы сделали отличный лонгрид (большое количество текста), в котором описали по пунктам, которые являются ключевыми фразами:
· Замена сенсорного стекла;
· Замена / ремонт экрана;
· Восстановление разъёмов;
· Замена камеры;
· Замена батареи;
· И т. д.
В этом случае лучше не писать описание страницы. Google сам подберёт нужное описание из вашего текста, и как правило он берет часть первого абзаца, после заголовка, которая соответствует ключевой фразе.
Хорошо, когда этот заголовок написан в теге <h2>. Именно поэтому, когда много ключевых фраз на странице писать первый абзац после заголовка <h2> из расчёта того, что он попадёт в сниппет. А длинна этого абзаца желательно, чтобы до 160 символов, чтобы весь текст абзаца вошёл в сниппет.
Однако Google сам определяет брать описание из мета тега, или сгенерировать описание страницы самостоятельно.
Поэтому желательно писать тег описания в соответствии с рекомендациями Google. Но в любом случае на моей практике не было такого, что поисковик игнорировал хорошее описание, и генерировал своё.
Третьим замечательным тегом в <HEAD>, является тег keywords, в котором записываются ключевые слова. Но об этом теге читайте в ключевых словах этой книги.
38 фактор. Повторяющиеся дескрипшены
Также, как и повторения одного текста с небольшими изменениями на разных веб-страницах отрицательно влияет на вес страниц, также мало отличающиеся дескрипшены уменьшают ранг.
Самая распространённая ошибка менять в дескрипшенах только ключевые слова.
Например,
· Замена экрана на телефоне за один час, в нашей сети ремонтных мастерских…
· Замена кнопки Home на телефоне за один час, в нашей сети ремонтных мастерских…
· Замена батареи на телефоне за один час, в нашей сети ремонтных мастерских…
Фактически, Search Console предупреждает, если у вас их слишком много таких описаний страниц. До лучше писать однотипно, как это делают программы автоматической подстановки мета тегов, чем оставлять этот тег пустым. Но лучше если взялись, то сделать правильно.
39 фактор. Повторяющиеся текст в описании и дескрипшенах
Если текст в названии страницы и в её описании идентичен, то это ещё один отрицательный фактор, который понижает вес веб-страницы.
Этим страдают интернет-магазины, особенно небольшие. Например, они создают карточки товаров на один товар, но разной расцветки, а в дескрипшенах ленятся прописать цвет товара. Другой пример, турагентство предлагает отдых в различных отелях Турции, но на всех веб-страницах дескрипшенах указывает один и тот же общий текст. Этим страдают и блогеры, когда разных страницах одной темы не замолачиваются с описанием.
Более мягкий вариант, когда, например ремонтная мастерская по ремонту мобильных телефонов в одном и том же меняет только название товара.
«Ремонт телефоны Blackview всех моделей с любыми поломками. Вернёт полный функционал вашему гаджету за цену, которая порадует вас», и
«Ремонт телефоны Caterpilla всех моделей с любыми поломками. Вернёт полный функционал вашему гаджету за цену, которая порадует вас».
Чем больше уникальность описания, тем больше веса получает веб-страница.
Но не забывайте, что это всего лишь один из более 300 факторов ранжирования.
40 фактор. Фразы, понижающие рейтинг
Чего нельзя писать в Мета тегах.
Google отрицательно относится если в тегах ключевых слов, описаниях заголовка и страницы употребляются
· сленговые фразы, если текст рассчитан не на специализированную группу;
· не нормативная лексика в любой форме;
· пропаганда насилия, наркотиков, детская порнография, и
· подобные направления, противоречащие общепринятому законодательству.
Кроме этого, запрещена реклама некоторой легальной продукции, которые можно отнести к полу запретным, например, табака и алкоголя.
Если поисковик замечает эти полу запретные слова на страницах сайта, то сайт выпадает из общего поиска. Это значит, что сайт будет участвовать в поиске по своей тематики, но не даже шикарные страницы о вреде этого продукта не будут участвовать в поиске.
Поэтому табачному или алкогольному магазину нет смысла пытаться продвигаться в поисковике по запросам о вреде этих продуктов. Сайты, которые попали в список полу запрещённых продуктов изначально накладывается понижающий коэффициент, и применяется термин не рекомендуемые продукты.
41 фактор. Гипнотические мета теги
Заголовки и описания страниц, которые имеют повышенное воздействие на подсознание с применением гипнотического или манипуляционного текста в поисковике считаются плохими, потому что большинство слов и их сочетания обладающих повышенным воздействием на подсознание, не являются информативными, и занесены в стоп-слова.
В результате такие фразы Google воспринимает как содержащие высокую водянистость, и игнорируются.
Тоже самое происходит и с текстами.
ТЕКСТЫ
42 фактор. Уникальность текстов
Если статьи для сайта берутся с другого сайта, который Google уже проиндексировал, то статья не учитывается. Иногда возникает ситуация, когда размещается статья на непопулярном сайте, её сдирают, и размещают на популярном сайте, и Google, первой проиндексировал копию с популярного сайта воспринимает её как оригинал. И в этой ситуации никто никому ничего не докажет.
Понимая это, поисковики предложили каждый свой вариант закрепления авторских прав за автором статьи. И в Google и в Yandex предложили свои варианты закрепления авторских прав.
Yandex создал специальную форму, в которую заносится статья, и сразу после регистрации можно размещать статью на сайте. Более подробно об этом читайте в справке Yandex.
Google на момент написания этих строк продолжает продвигать свои круги для бизнеса, поэтому и внёс закрепление авторских прав через свои круги в Google+ для бизнеса.
Это достаточно трудоёмкий процесс, его описывать не буду, поэтому как Google, возможно в скором времени упростит этот процесс.
Если в Google, в ответах на запросы пользователей, Ваша статья с закреплёнными авторскими правами появляется в выдаче, то может появиться и Ваша фотография, имя и фамилия, как автора по утверждению Google. Но в предыдущем предложении ключевое слово «может».
Последние и подробные инструкции по закреплению авторских прав в конкретной поисковой системе найдёте в интернете, потому что всё меняется быстро.
Теперь о рерайтинге. Обычно берут с других сайтов одну или несколько статей, и делают перестановку и/или объединение абзацев, перестановку слов, замену слов синонимами. Все эти изменения Google замечает, и такой текст не считается оригинальным, а поэтому не добавляет вес страницы с высоким процентом заимствования. Различные источники указывают различный процент, начиная с которого Google не индексирует страницы, но думаю, что тот, кто желает быть на вершине рейтинга не будут пачкаться такими статьями.
Чем больше процент совпадения с используемыми статьями, тем больше вычитается из рейтинга у страницы.
Хороший рерайтинг это когда набирается несколько статей, и копирайтет пересказывает всё своими словами.
Трудно сказать, как в Google работает алгоритм проверки уникальности, но уверен, что на портале advego работает подобный алгоритм. На этом сайте любой может проверить текст на уникальность.
По большому счету авторская статья будет только та, в которой впервые излагаются факты, и делаются свои умозаключения. Именно таким статьям Google присваивает наивысший рейтинг.
За оригинальностью текста следит фильтр Duplicate Content.
Подобные фильтры в Google защищают топ поисковой выдачи от не уникального, а попросту ворованного или копированного контента. Duplicate Content допускает к ранжированию тексты с уникальностью более 80%. Все что ниже — не берется во внимание.
Об этом фильтре подробнее смотрите в «36 фильтров Google»
43 фактор. Длинна текста
Одним из факторов качества оригинального текста для Google является длинна текста. По проведённым исследованиям Moz было установлено, что длинные тексты позиционируются выше коротких.
Если считать, что в русском языке средняя длинна слова 6—7 букв, то текст должен быть в пределах 15 тысяч печатных знаков. В любом случае лучше писать статьи более 10 тыс. печатных знаков.
Но это не значит, что, написав статью в 2,5 тысячи слов, статья гарантировано попадёт на первое место. Вероятно, Google ведёт подсчёт длинны текста без воды, и стоп-слов.
Какие же слова Google занёс в черный список — их коммерческая тайна, поэтому, чтобы проводились исследований в этом направлении, мне не известно.
В любом случае длинный текст — это фактор, который позволяет утверждать, что статья наиболее полно раскрывает тему, но это не говорит о том, что и ключевые и LSI слова расставлены грамотно и в нужном количестве.
Как вычислить оптимальную длину текста?
Длинна текста может существенно отличаться на разных тематиках сайтов. Подсказать же минимальную длину статьи помогут конкуренты. Для этого заходим в Google, с поле поиска вводим ключевую фразу, по которой желаем написать статью, и открываем первый десяток сайтов, исключая контекстную рекламу.
Копируем статью, заносим её на полюбившийся сервер проверки уникальности, и смотрим количество слов первого десятка сайтов по выбранной ключевой фразе. Складываем все десять результатов, и делим на 10.
Ваша статья должна быть на 10—25% больше полученного результата.
Повторюсь, что это не гарантия стать первым в выдаче. Хоть длина текста очень большая капля, добавляющая к весу веб-страницы, но не единственная. Следует учитывать всё выше и ниже написанное.
Вы обязательно заметите, что на первых местах находятся сайты с не слишком длинными статьями, но это значит, что у них лучшие другие показатели.
44 фактор. Структура документа
Хорошо структурированный текст — это хороший показатель качества контента, а значит и добавка весу страницы.
В HTML более чем достаточно средств структурировать и форматировать текст.
Подзаголовки H2, H3, H4, H5, H6
Правильное использование элементов заголовка H2, H3, H4, H5, H6
«Шесть элементов заголовка от H1 до H6 обозначают заголовки разделов. Хотя порядок и появление заголовков не ограничены HTML DTD, документы не должны пропускать уровни (например, от H1 до H3), так как преобразование таких документов в другие представления часто проблематично.» W3C.
Подзаголовки не так важны при ранжировании сайтов, но существенно добавляют вес страницы, если выполняют два требование.
1. Показывают наглядно структуру документа.
2. Используют LSI терминологию.
По рекомендациям Google каждая статья должна иметь четко читаемую структуру текста.
Например,
<Н1> Лучшие Марки Автомобилей из Европы (и их технические характеристики) </Н1>
<Н2> Немецкие автомобили </Н2>
<Н3> BMW </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> Volkswagen </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> Mercedes-Benz </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> Audi </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> Porsche </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> … </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н2> Английские автомобили </Н2>
<Н3> Land Rover </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> Aston Martin </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> Rolls-Royce, </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> … </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н2> … </Н2>
<Н3> … </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
<Н3> … </Н3>
<p> Текст об этой марки машин …. </p>
<p> …. </p>
Такая структура построения текста приветствуется Google в любом документе, и это повышает ранг веб страницы, будь то консультации, реклама товаров, услуги, или рассказ о каких-то событиях.
Чтобы было более понятно кратко напомню построение, которое предложил ещё Аристотель, и пока более мудрой структуры никому не удалось придумать.
Если человек желает о чем-то поведать, то он высказывает тезис, или предмет доказательства, или предмет его рассказа. Если нет предмета доказательства, то все согласны с этим тезисом, и это уже не тезис, а всем известный факт. Если факт всем известен, то все всё знают, и нечего доказывать, и говорить тут не о чем, а тем более писать.
Например, если в нашем выше рассмотренном примере было написано «Автомобили из Европы», то не понятно, что этим хотел сказать автор. Но написав «Лучшие Марки Автомобилей из Европы (и их технические характеристики)», человек понимает, что речь пойдёт о перечислении марок автомобилей, производимых в Европе, и будут даны их характеристики. Хороший тезис, с этим уже можно и поспорить, или узнать что-то новое.
Тезис должен быть подкреплён аргументами. В приведённом примере аргументами являются заголовки Н2 и Н3. А аргументы должны быть раскрыты последующим текстом для каждой марки.
Общепризнанное построение структуры выполняет ещё одну задачу — употребление LSI терминов Каждый подзаголовок (тексты в тегах Н2 — Н3) — это и есть LSI термин. По количеству этих терминов (и качеству) Google определяет на сколько полно раскрыт текст.
Чем больше в тексте синонимов у основной ключевой фразе, чем больше сопутствующих слов этой фразе, тем больше вес веб страницы.
Списки
Для улучшения структуризации и визуальной навигации по тексту используют нумерованные и маркированные списки.
Нумерованный список применяется, когда передаётся последовательность действий, например,
1. Набрал воды в чайник.
2. Поставил на подставку.
3. Включил чайник;
4. Ждёшь пока закипит вода…
Нумерованный список допустимо применять, когда нужно показать точное или последовательное количество фактов.
Маркированной список применяется, когда не важна последовательность, при более повествовательном характере изложения.
Для Google это дополнительный фактор того, что текст хорошо структурирован. И пользователю по таким метка проще ориентироваться в тексте.
45 фактор. Начертания шрифтов
Google обрабатывает теги <b> <strong> и теги <em> и <i> одинаково с точки зрения ранжирования и индексирования страниц.
Мэтт Каттс сказал, что нет никакой разницы в том, как Google относится к тегу <strong> и <b>, когда дело доходит до ранжирования, подсчёта очков или других факторов поиска.
Нет официального подтверждения того, что Google использует эти теги в качестве факторов ранжирования. Нет и опровержения.
Поэтому было много спекуляций на эту тему: некоторые оптимизаторы советуют использовать теги выделения, другие говорят, что это бессмысленно.
Однако в Стандартах W3C определяющих открытую веб-платформу сказано, что тег <strong> и <em> были задуманы для выделения ключевых фраз, как помощь поисковикам. А теги <b> и <i> оставлены как дизайнерские выделения текста.
Визуально же текст в теге <strong> ничем не отличается от текста в теге <b>. Аналогично и <em> и <i> визуально ничем не отличается.
Мне не трудно при написании текстов применять выделения по правилам W3C, а как вам, решайте сами.
Даже если на данный момент Google не учитывает выделение жирным или курсивом, это не значит, что и в дальнейшем будет так.
С одной стороны, теги <strong> и <em> могут помогать поисковикам определяться с ключевыми и LSI словами на веб-страницы, а с другой стороны использование этих тегов делает текст более лёгким для восприятия, и могут улучшить вес веб-страницы за счёт качества контента.
Многие веб-мастера тегами <strong> и <em> выполняют дизайнерские выделения вместо использования тегов <b> и <i>.
Если поисковики следуют Стандартам W3C, то такое выделение вводит в заблуждение системы определения ключевых фраз, а значит такое выделение снижает рейтинг страницы.
В своём последнем исследовании, посвящённом факторам рейтинга поисковой системы, MOZ.com попросил 120 ведущих мировых маркетологов по поиску оценить, насколько важно, по их мнению, использование жирных и курсивных ключевых слов. Их ответ был 2,8 из 10 (1 значение «Нет значения» для 10 означает «Очень важно»).
По какой-то причине, однако, SEOmoz «On-Page Grader обращает внимание на теги <B> и <STRONG> при определении того, насколько оптимизирована веб-страница, тоже неизвестно.
В любом случае, уверен, что если сейчас Google ещё не учитывает <B> и <STRONG>, и другие подобные теги, то вскоре — этот фактор будет учтен, потому как по написанию кодинга виден профессионализм, а значит и авторитет сайта.
46 фактор. Правильный кодинг
В любом случае существует спецификация W3C, которую каждый разработчик должен соблюдать.
Всякие же от неё отступления считаются ошибками, а большое количество ошибок или плохой кодинг может быть знаком плохого качества контента, что фиксирует Google.
Подумайте о своих пользователях и о том, как они изучают контент. Обычно посетители «сканируют» ваш контент. Таким образом, желательно использовать теги жирный, курсивный и подчёркивание для стилизации контента, чтобы сделать текст более легко воспринимаемым.
Люди склонны сканировать веб-страницы, а не читать каждое слово. Жирные ключевые слова и ключевые фразы могут не влиять на рейтинг страницы, но это определенно поможет читаемости и потреблению контента более глубоко понять суть написанного.
Путём моделирования наиболее релевантных фраз и ключевых слов с жирным и курсивом теги, вы помогаете пользователю быстрее понимать контент, что улучшает визуальное восприятие, а как показывает практика даже уменьшит показатель отказов от просмотра страницы.
А это значит, что хорошо структурированный, и визуально оформленный текст, увеличивает время просмотра, увеличивает рейтинг страницы по пользовательскому фактору.
47 фактор. Цитата
Одним из трёх важнейших факторов, влияющих на ранжирование сайта в ответах на запросы пользователей в Google, являются ссылки. Поисковик учитывает вес не только входящих, но и исходящих ссылок.
Google считает, что если в контенте есть цитаты со ссылками на авторитетные источники, из которых взяты фрагменты текста, то материал серьёзно придуман, хорошо подготовлен и является авторитетным.
Тег <q> в HTML указывает, что текст внутри этого тега является короткой цитатой. Желательно указать источник цитаты, для этого используется атрибут cite.
<q cite="http://example.com/citata/"> Здесь размещается короткий текст, процитированный с другого сайта </q>
Тег <blockquote> предназначен для выделения длинных цитат внутри документа. Текст, обозначенный этим тегом, традиционно отображается как выровненный блок с отступами слева и справа (примерно по 40 пикселов), а также с отбивкой сверху и снизу.
Формат записи, который добавляет вес веб-страницы.
<blockquote cite="http://example.com/citata/">.
Здесь размещается длинный текст, процитированный с другого сайта </blockquote>.
Кроме этого, цитата характеризует веб страницу как содержащую качественный контент, конечно, если ссылка на авторитетный сайт в глазах Google. Соответственно добавляется и авторитет сайту.
48 фактор. Таблицы
Для Google таблицы — это первичный сигнал, что текст хорошо структурирован, и не более.
Пока Google видит, что от сайта посетители получают пользу, у него нет никаких претензий к структуризации страницы.
Когда пользователи находят сайт непривлекательным и бесполезным, они уходят.
Google фиксирует (это показатель отказов), когда пользователи возвращаются на страницу результатов поиска после посещения сайта и выбирает для просмотра другой сайт.
Если поисковик видит, что пользователь получил ответ на свой вопрос на сайте, где нет таблиц, то на первом сайте пусть будут хоть золотые таблицы, он никогда не обойдёт тот сайт, который даёт исчерпывающий ответ.
Так рейтинг сайта падает и таблицы перестают быть сигналом хорошей структуры веб-сайта.
Наличие таблицы на сайте слабый сигнал, который говорит о возможно хорошей структуре сайта.
Если же таблица на сайте широкая по горизонтали, и при просмотре страницы с такой таблицей требуется горизонтальная полоса прокрутки, то при поиске в Google на мобильном устройстве такие страницы выпадают из поиска, хотя хорошо позиционируются для стационарных компьютеров.
Удобный просмотр веб-страницы на мобильном устройстве один из важных факторов при ранжировании сайтов.
Также Google не любит длинные по вертикали таблицы, которые имеют более 6 строк, и выходят за пределы экрана мобильных устройств.
Поэтому, если не желаете терять клиентов с мобильными устройствами, то не используйте большие таблицы на страницах сайта. Но таблицы полностью обозримые на мобильном экране, увеличивают авторитет веб-страницы.
49 фактор. Тег заголовка текста Н1
Заголовки текста — это первое (возможно после картинки), что видит посетитель, открывая страницу сайта. Именно по заголовку пользователь определяет получит ли он ответ на тат запрос, с которым он обратился к поисковику, и стоит ли утруждать себя просмотром этой страницы.
Пример кода заголовка текста:
<H1> Главный заголовок текста </H1>
Google как прежде, так и в 2018 году при подсчёте рейтинга страницы сайта уделяет большое внимание заголовку, написанному в теге Н1.
«Тег заголовка H1 второй по значимости после тега описания страницы.»
Мэтт Каттс, Google.
Это и понятно. Человек желает сразу видеть, что открытая им страница отвечает на заданный им вопрос, т.е. в заголовке Н1 видеть фразу, заданную им в поиске.
Тег заголовка текста Н1.
По данным Moz: «80% результатов поиска в первой странице в Google используют H1».
Как же правильно составлять идеальный заголовок H1?
1. Хотя постоянно идёт спор между оптимизаторами сколько заголовков Н1 может быть в тексте (ведь допускается сколько угодно), но по тем же данным Moz наивысшие места в ответах на запросы пользователей занимают страницы, у которых один заголовок Н1. Если поисковики на странице находят несколько H1, то логический приоритет семантического тега H1 размывается, поисковик не понимает какой ключевой фразе отдавать приоритет, и каждой ключевой фразе отдаётся половина, или треть всего веса, в зависимости от того сколько заголовков было написано.
2. Тег заголовка текста H1 должен описывать тему страницы.
a. Тег H1 должен быть созвучен с заголовком страницы, и желательно не быть его копией. Наличие ключевой фразы в начале заголовка, и далее использование LSI терминов, раскрывающие смысл статьи. Если не используется ключевое слово, то как Google узнает, о чем идёт речь, и как правильно проиндексирует веб страницу?
b. Тег H1 должен дать представление о том, что пользователю предлагается прочитать. Написанию «вкусных» заголовков посвящено много статей в интернете, и это отдельная тема. Однако, «вкусный» заголовок для пользователей и поисковиков иногда отличаются, потому как пользователя завлекают интригой, а для высокого ранжирования требуется чёткое изложение фактов.
3. Считается, что длинна заголовка от 20 до 70 символов наиболее благоприятная для восприятия. Установлено, что среднестатистический человек легко воспринимает своей «оперативной» памятью не более 5—7 слов, максимум 10. Когда человек дочитает заголовок до десятого слова, он забывает первые слова. Именно поэтому многие и не читают длинные заголовки, а сканируют только первые два слова.
Но не стоит на этом зацикливаться, это не так важно, как прежде. Однако при более коротком заголовке теряется ценное пространство, заполнив которое можно получить дополнительный вес. Длинный же заголовок хуже воспринимается пользователем, и для поисковиков размывается его ценность. Поэтому при написании заголовков следует учитывать эту дилемму.
4. Заголовок страницы должен быть самым важным визуальным элементом на странице. Он должен быть крупным по размеру, и мощным по смыслу. Заголовок — это семантический тег, а не дизайнерский изыск, поэтому обращайте внимание, чтобы он был легко читаемым.
5. Используя алгоритм RankBrain, Google научился понимать, что хочет получить пользователь. Если понимание вопроса, и понимание автора текста совпадают, что он хочет донести до пользователя, совпадут, то страница появится в результатах ответов на запрос пользователя. Пользователь в результатах поиска видит страницы, которые отвечают на его вопрос, и переходит по указанным ссылкам. Когда пишется статья нужно спросить у себя: «чего хочет пользователь, когда открывают мою статью? Каковы его намерения?».
Текст в теге Н1 должен удовлетворять этому намерению. Задача заголовка текста — начать удовлетворять намерения пользователя. Когда человек в поисковой системе набирает некоторый набор слов — он формулирует своё намерение.
50 фактор. Теги заголовка текста Н2-Н6
Теги заголовков Н2-Н6 менее значимые, их наличие указывает на то, что текст возможно хорошо структурирован. Содержащиеся в них ключевые фразы — сигнал, что именно под эту фразу оптимизирована страница. Но с этими тегами, как и с таблицами — дополнительный нюанс привлечения внимания, а для поисковиков — дополнительное время, проведённое на сайте.
Дополнительное внимание следует уделить тегу Н2. Его применяют в качестве заголовков в виде вопроса при микро-разметки, чтобы попасть на нулевую выдачу. Обычно в тег Н2 помечают вопросы голосового поиска. О мультиразметки и голосовом поиске читайте в соответствующих факторах.
51 фактор. TF-IDF — частота слов в тексте
TF-IDF — это как часто каждое слово появляется в документе. Google считает, чем чаще анализируемое слово появляется в тексте, тем выше вероятность того, что эта страница об этом.
Но Google использует более сложную версию TF-IDF.
TF-IDF (сокращение от «термин частота — обратная частота документа») используется для измерения важности данного ключевого слова на странице. В отличие от плотности ключевых слов, он не просто показывает, сколько раз термин используется на странице; он также анализирует большой набор страниц и пытается определить, насколько важно то или иное ключевое слово.
Скажем, в ремонте автомобилей термин «ремонт шин», вероятно, важнее, чем «ремонт двигателя с турбонаддувом» — просто потому, что у каждого автомобиля есть шины, и только у небольшого количества автомобилей есть турбодвигатели. Из-за этого термин «ремонт шин» будет использоваться в большем наборе страниц, которые говорят о ремонте автомобилей.
Исследуя статистику ключевых слов большого числа ваших конкурентов, формула TF-IDF покажет вам:
1) Какие ключевые слова являются наиболее важными и актуальными для вашей темы;
2) Какие из них используются на вашей странице должным образом (насколько поисковые системы ожидают их появления, поскольку известно, что Google использует TF-IDF при индексации);
3) Какие термины на вашей странице используются слишком много или слишком мало.
Учитывая, что Google не берет во внимание те ключи, которые указаны на веб странице, может оказаться, что в тексте он возьмёт другие ключевые фразы, и будет ранжировать по ним.
Например, создана страница, и как бы оптимизирована под фразу «ремонт компьютеров». Внесла «ремонт компьютеров» с плотностью 5%, но в тексте повторила фразу «наша компания» гораздо больше раз. Такой вариант Google посчитает текст переспамленным по фразе «наша компания». И это грозит тем, что веб страница вылетает из ТОПа.
Другая сторона вопроса — это запросы, с которыми Google сталкивается впервые, и на них нет уже заготовленных ответов, а таких примерно 25%. Подбирать же ответ по наибольшему наличию введённых пользователем слов — заведомо выдавать мусор. Не известно как оптимизирована веб-страница, ведь Google не анализировал её в этом разрезе. Поэтому поисковик начал работать с введёнными пользователем словами, пытаясь понять суть вопроса, на который нужно дать ответ.
Термин «ключевые слова» уже утратил своё смысловое значение с вводом алгоритма RankBrain как составная часть фильтра Колибри (Hummingbird) в 2015 году. Google, по введённым словам, пытается понять суть вопроса, чтобы подобрать наиболее подходящий ответ.
Вот как Грег Коррадо описал RankBrain в то время:
«RankBrain использует искусственный интеллект для встраивания огромного количества письменного языка в математические объекты — так называемые векторы — которые компьютер может понять. Если RankBrain видит слово или фразу, с которыми он не знаком, машина может догадаться, какие слова или Фразы могут иметь аналогичное значение и соответствующим образом фильтровать результат, что делает его более эффективным при обработке поисковых запросов, которых раньше не было».
RankBrain использует так называемые «сущности», которые представляют собой конкретные объекты, о которых Google знает некоторые факты, такие как люди, места и вещи. С помощью математического алгоритма он затем делит объекты на более конкретные векторы слов, которые приводят к определенной поисковой выдачи. Естественно, сходные векторы слов приводят к сходной поисковой выдачи.
Самое лучшее — это то, что Google уже собрал много информации о них и может сразу же найти самые точные результаты поиска по вашему запросу. Однако, когда RankBrain встречает неизвестный запрос, он ищет вектор, который наиболее похож на исходный запрос, и возвращает результаты именно для него.
Теперь, когда RankBrain направлен на подключение поисковиков к наиболее релевантным возможным результатам, поисковая цель стала приоритетом. Вот почему RankBrain отдает предпочтение только тем страницам, которые действительно соответствуют его миропониманию, требованиям — отвечают на вопросы поисковиков, и предоставляют исчерпывающую информацию по теме, указанной в запросе.
Таким образом, сегодняшняя эффективная оптимизация контента невозможна без понимания смысла поискового запроса и проведения исследования ключевых фраз для конкретных целей.
Ещё одна вещь, которая изменила грамотный подход к SEO, — это смещение акцента на оптимизацию контента с ключевых слов на темы запросов пользователями. Я думаю, что для большинства SEO-специалистов неудивительно, что концепция «одно ключевое слово — одна страница» действительно мертва. Это означает, что в эпоху RankBrain всё, к чему вы должны стремиться, — это всесторонность — вы не сможете получить высокий рейтинг, создав многочисленные страницы, которые охватывают различные варианты ключевых слов.
Google теперь даёт больший вес тем страницам, которые способны ответить на большее количество вопросов.
Что мы знаем наверняка о алгоритмах Google, так это то, что они никогда не останутся неизменными надолго. И шансы чрезвычайно высоки, что Google будет (если не уже) настраивать и улучшать RankBrain.
Более того, RankBrain постоянно учится и меняется, поэтому единственное, что нужно делать, это нацелить контент на людей, сделать его актуальным для поисковых целей, а также сделать его диалоговым и современным.
Более подробно о RankBrain читайте в «36 фильтров Google».
52 фактор. Естественный язык
По сути, единственная рекомендация по оптимизации RankBrain, которую мы получили до сих пор, пришла от Гэри Иллиеса, аналитика веб-мастеров Google, который сказал, что:
«Оптимизация для RankBrain на самом деле очень проста, и это то, о чем мы, вероятно, говорим уже 15 лет, — и мы рекомендуем — писать на естественном языке. Попробуйте написать контент, который звучит по-человечески. Если вы пытаетесь писать, как машина, то RankBrain просто запутается и, вероятно, просто оттолкнёт вас назад в результатах поиска.
Но если у вас есть контент на сайте, попробуйте зачитать некоторые из ваших статей или что бы вы ни написали, и спросите людей, звучит ли это естественно, как они привыкли слышать. Если это звучит разговорно, если это звучит как естественный язык, который мы использовали бы в вашей повседневной жизни, то, конечно, вы оптимизированы для RankBrain. Если это не так, то вы не оптимизированы.»
Из своего опыта хочу добавить, что профессиональный сленг показывает профессионализм, и увеличивает рейтинг страницы, а с уличным сленгом пока ещё происходит обратное.
Кроме этого тексты, написанные продавцом товара или услуги, который досконально знает свой предмет и в последствии подправленный мастером рекламного слова, позиционируются выше, чем тексты, написанные девушкой-копирайтером за копейки.
53 фактор. Избранные фрагменты
«Когда пользователь задаёт вопрос в Поиске Google, мы можем отобразить результат поиска в специальном блоке фрагментов в верхней части страницы результатов поиска. Этот блок фрагментов содержит сводку ответа, извлечённую из веб-страницы, а также ссылку на страницу, заголовок страницы и URL-адрес». Google 2018.
Google показывает избранные фрагменты, отвечающие на вопросы пользователя из нескольких источников. Это позволяет быстро выбрать сайт, где пользователь мог получить наиболее полный ответ на свой вопрос.
В русской же части интернета избранные фрагменты ещё слабо представлены, поэтому кто первым в своей тематике подготовит эти фрагменты, тот займёт место.
В исследовании, проведённом SEMrush и Ghergich & Co., было проанализировано 6,9 миллиона избранных фрагментов. Кроме того, они дополнительно проанализировали 80 миллионов ключевых слов.
Цель состояла в том, чтобы разбить процентные доли отобранных фрагментов по группам ключевых слов.
О силе ключевых слов.
Когда один из исследователей — A. J. Ghergich удалял знаки вопроса, предлоги и сравнивал их большим набором данных, только 7% общих ключевых слов содержат фрагменты. Небольшие исследования показывают более высокие цифры, но 80 миллионов ключевых слов — это самое большое исследование, которое проводилось на момент написания книги.
Исследование показало, что 41% вопросов содержат фрагменты. Ключевые слова сравнения и предлог также с большей вероятностью показывают избранные фрагменты.
Вопросы показывают увеличение доли ключевых слов с выбранными фрагментами на 480%.
Основным исключением из общего правила являются фразы, начинающиеся словом «как».
Напоминаю, что эти данные из англоязычного интернета. Возможно, в русском сегменте что-то изменится. Но повторюсь, что эта тема на русском языке ещё не изучена.
Проведённый анализ сравнительных ключевых слов немного сложен. На первый взгляд кажется, что они хорошо подходят для отрывков из абзацев. Но это потому, что у Google не так много хорошо структурированных сравнительных таблиц.
A. J. Ghergich утверждает, что он успешно форматировал сравнения цен в таблицы и зарабатывал избранные фрагменты. Содержание не изменилось — только то, как мы представили данные. Ключевые слова для определения цены — это тип ключевых слов в конце цикла покупки, которые имеют высокую конверсию.
Это работает и в русском интернете.
Если вы пытаетесь ранжироваться по вопросам, выберите фрагмент абзаца. Если вы пытаетесь ранжироваться по предлогам, используйте список. Сравнение цен хорошо работает в таблицах.
Теперь у вас есть данные о том, какой тип рекомендуемого фрагмента оптимизировать. Давайте посмотрим, как оптимизировать ваш контент для избранных фрагментов.
Как хорошее практическое правило, копирайтерам создавать абзацы в диапазоне от 40 до 60 слов. Вы должны быть краткими и избегать гигантских стен текста. Если желаете попасть в избранный фрагмент пишите, как пишите СМС.
Вы должны использовать более длинные списки, когда это возможно, поэтому Google вынужден урезать результаты. Вы должны дать пользователю причину перейти на ваш сайт. Если имеет смысл использовать только короткий список, попробуйте использовать достаточно слов для каждого элемента, чтобы Google обрезал каждый элемент списка.
Тем не менее, имейте в виду, что лучше для пользователя. Иногда это короткий, прямой список пунктов, и это нормально.
Как и списки, вы должны создавать таблицы, которые Google будет обрезать (смотрите на изображении выше). Сосредоточьтесь на ключевых словах конца цикла покупки, таких как цена.
Применяйте пейзажные изображения. Ghergich пишет, что они обнаружили, что наиболее распространённое соотношение сторон для показанных фрагментов изображений составляет 4: 3.
Размер медиа-изображения в пикселях составлял 600 х 425.
Пейзажные изображения также выглядят менее точечно, когда Google уменьшает их.
54 фактор. Что такое рекомендуемый фрагмент?
Концентратор избранных фрагментов — это внутренний URL-адрес, который заработал 10 или более популярных фрагментов Google для одной страницы.
Однако при исследовании были обнаружены отдельные страницы, зарабатывающие 200—300 избранных фрагментов для одного внутреннего URL.
Использование стоковой фотографии в верхней части вашей статьи отрицательный сигнал.
Такие изображения никогда не должны были ставиться в первую очередь. Не зацикливайтесь на подсчёте, а сосредотачивайтесь на предоставлении наглядных пособий в вашем контенте, чтобы заработать очки.
Думайте об авторитетных доменах относительно вашей ниши. Нужно очень постараться малым предприятиям, для зарабатывания показов в избранном фрагменте, чтобы считаться актуальным авторитетом в сравнении с конкурентами.
89% популярных URL-адресов фрагментов имеют социальную активность. Это не означает, что социальные акции приравниваются к более высокому рейтингу или получению фрагментов. Это означает, что контент, который мы видим на этих позициях, показывает сильные сигналы вовлечения пользователей.
A. J. Ghergich просмотрел все 3800 URL-адресов через API Google Speed Page. Оценки скорости сайта были хорошими, но показатели дружелюбия к мобильности и удобства использования оказались на низком уровне.
Средний показатель для мобильных устройств составляет 95/100. Средний балл юзабилити составляет 96/100. Для такого большого списка получение такого высокого среднего балла требует внимания.
Я не верю, что точный счёт имеет значение в конце. Важно то, что мобильные пользователи имеют хорошие результаты на веб-сайтах, попавших в избранный фрагмент. Пользователи должны иметь возможность быстро получать ответы и легко перемещаться по сайту.
95,77% списков избранных фрагментов используют списки. Не один список, а множество упорядоченных и неупорядоченных списков на URL.
Пример показателей веб-ресурса связанного со здравьем, который получил около сотни избранных фрагментов:
· Высокая вовлеченность пользователей: 750 социальных акций;
· Мобильный: 99/100;
· Протокол HTTPS: используется;
· Использование СМИ: 12 изображений, связанных со здоровьем;
· Количество слов: 2100 слов в тексте;
· Применение заголовков: 12 тегов h1 — h6;
· Краткое содержание: Средняя длина абзаца составляет 42 слова;
· Использует списки: 7 упорядоченных или неупорядоченных списков;
· Ссылок на приведённые факты 48 ссылок на внешние факты.
Ввиду того что во время прочтения книги исследуемая страница возможно будет удалена или изменена, поэтому смотрите её скриншот на момент публикации её фрагментов в Приложении Скриншот А.
Веб-страница с заголовком «Отследите потерянный iPhone и найдите его с помощью iCloud» получила тоже около сотни избранные фрагментов.
· Высокая активность пользователей: 7 000 в социальных сетях;
· Мобильный: 98/100;
· Протокол HTTPS: используется;
· Использование СМИ: 15 iPhone связанных изображений;
· Количество слов: 2 078 слов;
· Заголовки: 16 тегов h1 — h6;
· Краткое содержание: Средняя длина абзаца составляет 34 слова;
· Использует списки: 6 упорядоченных или неупорядоченных списков;
· Факты цитирования: 6 внешних ссылок.
Смотрите скриншот этой веб страницы на момент публикации её фрагментов в Приложении Скриншот Б.
Привожу эти примеры, чтобы читатель мог увидеть какой объем предстоит провести, чтобы войти в избранный фрагмент, и получить большой авторитет веб-страницы со стороны Google.
Следует заметить, что корреляция не является причинно-следственной связью. Я не рассматриваю избранные центры фрагментов как черный ящик, в котором хранятся секреты получения избранных фрагментов. Я просто указываю на некоторые общие темы, которые, на мой взгляд, поучительны для создателей контента.
Некоторые выводы имеют смысл с точки зрения поисковой системы.
Давайте рассмотрим несколько вещей, которые Google должен делать при отправке пользователям определенного контента.
1. Предоставьте краткие ответы:
· Средний абзац составляет 42 слова;
· Списки отлично подходят для мобильных устройств.
2. Используйте надёжные источники:
· Сильные внешние ссылки;
· Сильная социальная активность.
3. Установить полный охват темы:
· До 50 ссылок на внешние источники;
· Длинна текста более 2000 слов.
4. Фокус на безопасный просмотр: HTTPS.
5. Обеспечить отличное взаимодействие с пользователем на разных устройствах:
· Высокие мобильные дружеские оценки;
· Высокие показатели мобильности.
Благодаря SEMrush у нас есть данные о том, какой тип рекомендуемого фрагмента оптимизировать. Вы знаете, точную длину, которую вы должны использовать для каждого типа фрагмента. У вас также есть представление о центрах фрагментов функций и о том, почему Google доверяет их содержанию.
Итак, Google выбирает контент Избранные фрагменты на основе сочетания длины контента, форматирования, наличие ссылок на авторитетов и использования HTTPS.
Используйте это исследование, чтобы повторно оптимизировать ваш лучший старый контент, который входит в топ-10, но в котором отсутствуют избранные фрагменты.
Дайте поисковым системам ответы, которые им нужны. Используйте сжатые форматы, сфокусируйтесь на опыте мобильных пользователей, и вы получите долгосрочное вознаграждение.
Как получить избранные фрагменты в Google?
Несмотря на всю запутанность, задержку по времени, переписывание ключевых слов, ручную оценку и смещение выбора, которые Google проходит, чтобы сопоставить страницы с запросами по ключевым словам, вам все равно нужно оптимизировать страницу, чтобы занять определенную нишу, и если вы сделаете это разумно, вы откроете богатство длиннохвостого трафика с течением времени (многие из которых бесполезны, как всегда, но то, что RankBrain может очистить со временем).
Замечания:
· В будущем Google собирается производить больше таких прямых ответов или блоков ответов (они движутся в этом направлении с 2005 года).
· Сосредоточение на их срабатывании позволит вашим создателям контента создавать именно те страницы, которые Google хочет ранжировать. Руководства «КАК» и «ЧТО ТАКОЕ» — ИДЕАЛЬНО и ОЧЕНЬ ЛУЧШИЙ тип контента для этого упражнения.
· Google вознаграждает эти статьи и поисковая система вероятно, будет продолжать это делать в будущем.
· Google Knowledge Graph предлагает ещё одну интересную возможность — и указывает на следующий этап в органическом поиске.
· Google производит эти ЯЩИКИ ОТВЕТА, которые могут продвигать страницу из любой точки на первой странице Google до номера 0.
· Все подробные стратегии содержания на вашем сайте должны быть сосредоточены на этом новом аспекте оптимизации Google. Бонус в том, что вы физически создаёте контент, который Google очень хорошо оценивает, даже не принимая во внимание рамки знаний.
· По сути, вы кормите Google лёгкими ответами, чтобы демонстрировать свою страницу. Все это очень хорошо сочетается с органическим линкбилдингом. Чем больше ответов вы разблокируете, тем больше у вас шансов занять место номер ноль ДЛЯ БОЛЬШЕ И БОЛЬШЕ УСЛОВИЙ — и, как следствие, — все больше и больше людей видят ваш утилитарный контент, и в результате вы получаете социальные ссылки и ссылки, если люди заботятся об этом. все об этом.
· Вы можете поделиться расширенным фрагментом (или блоком ответов Google, как их впервые называли SEO). Иногда вы представлены, а иногда это URL-адрес конкурента. Все, что вы можете сделать в этом случае, это продолжать улучшать страницу, пока вы не вытесните своего конкурента.
Мы уже знаем, что Google любит «советы» и «как», а также расширенные часто задаваемые вопросы, но эта система ANSWER BOX Графа знаний предоставляет реальную возможность и, безусловно, является тем, на что должна быть ориентирована любая контентная стратегия, чтобы максимизировать воздействие вашего бизнеса на органический поиск.
К сожалению, это обоюдоострый меч, если вы втягиваетесь в долгосрочную перспективу. В конце концов, Google ищет простые ответы, поэтому, в конечном итоге, может не потребоваться отправлять посетителей на вашу страницу.
Справедливости ради, на данный момент эти расширенные фрагменты Google выглядят в комплекте со ссылкой на вашу страницу и могут оказать положительное влияние на трафик на страницу. Так — на данный момент — это возможность воспользоваться.
55 фактор. Контент, скрытый за вкладками
«Google не может ранжировать страницу для контента в разделах, скрытых за вкладками, потому что Google знает, что пользователи не видят контент, спрятанный в закладках, потому что он не виден по умолчанию».
Специалист отдела качества поиска Google Джон Мюллер.
Это значит, что для уменьшения длинны страницы установленные вкладки, аккордеоны, и подобные красивые элементы, которые нужно кликнуть, чтобы посмотреть содержание не индексируется.
Google не может ранжировать такой скрытый контент в этих разделах. Google считает, что если пользователь сделал запрос, то должен сразу увидеть ответ, не догадываясь, что нужно открыть ещё и соответствующую вкладку.
Вес страницы в этом случае не уменьшается, но следует учитывать, что скрытый текст может быть только дополнительным, и объём текста не учитываются.
Прежде Amazon использовал много вкладок, но теперь они, выводят большую часть контента непосредственно на странице, заставляя пользователя прокручивать и прокручивать, чтобы увидеть содержимое.
В своих справочных документах Google использует клик для расширения, но только для просмотра вопросов. Нажав на сам вопрос, пользователь попадаете на новую страницу с указанным ответом, а не остаётся на той же страницы с ответом под вопросом.
Задумайтесь — требует ли красота этих жертв?
Не забывайте, если человек попадает на ваш сайт из поисковика, то он задал конкретный вопрос, на который хочет получить ответ. У него масса других вопросов, которыми забита голова. Но вот человек попал на ваш сайт и хочет получить ответ на свой вопрос.
Ему не интересны ваши сюрпризы типа найди ответ на этой, страницы, угадай за какой вкладкой спрятан ответ. Именно поэтому Google не учитывает скрытые тексты. Больше того, чем быстрее посетитель увидит ответ на свой вопрос, зайдя на страницу, тем ценнее страница.
56 фактор. Фред
Эксперты команды MOZ, изучив более 700 сайтов, пострадавших от этого обновления, заметили, что 95% из них сайтов имеют две общие черты.
Все сайты кажутся ориентированными на контент, будь то форматы блогов или другой контент, такой как сайты, и все они довольно сильно занимаются размещением рекламы на страницах своих сайтов.
На самом деле, похоже, что многие (не все, но многие) из них были созданы с единственной целью получения дохода от AdSense или других рекламных компаний, и не обязательно принося пользу пользователю.
На сайтах, которые попадают под этот фильтр, также наблюдается падение органического трафика Google на 50% и выше сразу же.
А в некоторых случаях падение трафика доходит до 90% за ночь.
Я должен заметить, что Google официально не подтвердил эти теории или даже что было обновление.
Барри Шварц пишет, что после проверки более 100 различных сайтов:
«Это обновление предназначено для сайтов с низким качеством контента, но приносят доход больший, чем помощь своим пользователям.
Подавляющее большинство URL-адресов, которыми я поделился, показывают веб-сайты одного типа. Контент-сайт, часто в формате блога, но не всегда, с контентом по различным темам, который выглядит написанным для целей ранжирования, а затем содержит рекламные и / или партнёрские ссылки, разбросанные по всей статье. Многие из этих сайтов не являются отраслевыми экспертными сайтами, а скорее имеют контент по широкому кругу тем, которые не добавляют столько ценности, сколько уже написали другие сайты в этой отрасли.
Во многих случаях контент оборачивается вокруг рекламы, где зачастую объявления немного сложно отличить от контента. В других случаях рекламы становится меньше или вообще нет, а скорее выручка за счёт партнёрских моделей, потенциальных клиентов или других возможностей.»
Из этого следует, что создание сайтов с контентом низкого качества, цель которых получение денег от рекламы, не предоставляя полезной информации посетителям невозможно оптимизировать так, чтобы в поисковой выдаче Google.
57 фактор. Автоматически сгенерированный контент
Контент «автоматически сгенерированный» — это контент, созданный программным способом. В тех случаях, когда он предназначен для манипулирования поисковым рейтингом и не помогает пользователям, Google может предпринять отрицательные воздействия с таким контентом. Автоматически сгенерированный контент включает:
· Текст, который не имеет смысла для читателя, но может содержать ключевые слова для поиска.
· Текст переведён с помощью автоматизированного инструмента без проверки человеком без редактуры и корректуры.
· Текст генерируется с помощью автоматизированных процессов, таких как цепочки Маркова (последовательность случайных событий с конечным или счётным числом исходов, характеризующаяся тем свойством, что, говоря нестрого, при фиксированном настоящем будущее независимо от прошлого).
· Текст, созданный с использованием автоматических методов синонимизации или перестановки слов в предложении.
· Текст, сгенерированный из очищающей ленты Atom / RSS или результатов поиска.
· Сшивание или комбинирование контента с разных веб-страниц без добавления достаточного значения.
Google ненавидит авто сгенерированный контент. Если они подозревают, что ваш сайт откачивает контент с других сайтов, это может привести к штрафу или деиндексированию.
58 фактор. Копии частей контента на разных страницах сайта
«Содержимое, которое копируется, но немного отличается от оригинала — отрицательный фактор. Этот тип копирования затрудняет поиск точного соответствия исходного источника. Иногда меняются только несколько слов или меняются целые предложения, или делается модификация «найти и заменять», где одно слово заменяется другим во всем тексте. Эти типы изменений намеренно выполняются, чтобы затруднить поиск исходного источника контента. Мы называем этот контент «скопированным с минимальными изменениями, и как правило не учитываем его при ранжировании».
Руководство по оценке качества поиска Google Март 2017.
Часто на сайтах услуг, которые оказываются в разных городах, создаются страницы с одним и тем же текстом, но меняется только название города.
Повторяющийся контент — это отрицательный фактор для всего сайта. Когда поисковые системы сканируют много URL-адресов с одинаковым (или очень похожим) контентом, это может вызвать ряд проблем с SEO.
1. Пользователи должны пробираться через слишком много дублированного контента, поэтому могут пропустить часть уникального контента.
2. Крупномасштабное дублирование может привести к снижению ранга всего сайта, т.к. один вес страницы будет распределяться на все копии. Например, ремонт смартфонов оказываются в пяти районах города. Создано пять страниц контента, в которых меняется только название района. С точки зрения геозависимости очень здорово, потому что пользователь, набрав «ремонт смартфона в промышленном районе» попадает на страницу, оптимизированную под этот район. Но страниц с мало изменённым текстом — пять, поэтому вес каждой страницы составляет пятую часть.
3. Увеличивает время ранжирования всего сайта за счёт того, что будут индексироваться копии, а не информативные веб страницы. Интернет-магазины часто для увеличения количества товаров делают для каждого размера и / или цвета отдельные страницы. Так ранжируются карточки одного и того же товара в то время, как другой товар ждёт своей очереди.
4. Но даже если контент имеет рейтинг, поисковые системы могут выбрать неправильный URL как «оригинал». Использование canonicalization помогает контролировать дублированный контент.
59 фактор. Дубли или копии страниц на сайте
Дубли или копии — это одна и та же страница сайта, которая открывается по нескольким разным адресам.
Копии страниц чаще всего возникают, когда:
· Движок системы управления содержимым сайта (CMS) автоматически генерирует дубликаты страниц.
Например, http://site.net/press-centre/cat/view/identifier/novosti/ http://site.net/press-centre/novosti/.
· Для Google одна и та же страница, например,
http://site.net/press-centre/novosti/ — со слешем в конце http://site.net/press-centre/novosti — без слеша в конце считается, как 2 разные страницы, т.е. дубли.
· Один и тот же товар представлен в нескольких категориях. Например, костюм может быть в категории костюмы, в категории бренды, и в категории распродажа.
Например, http://site.net/category-1/product-1/ http://site.net/category-2/product-1/ http://site.net/rasprodaza/product-1/.
· При изменении структуры сайта, когда уже существующим страницам присваиваются новые адреса, но при этом сохраняются их дубли со старыми адресами.
Например,http://site.net/catalog/product http://site.net/catalog/podcategory/product.
· Это происходит, когда каждому пользователю, посещающему веб-сайт, назначается другой идентификатор сеанса, который хранится в URL-адресе.
· Версия для печати содержимого также может вызывать повторяющиеся проблемы с содержимым, когда индексируются несколько версий страниц.
· Если сайт имеет отдельные версии на «www.site.com» и «site.com» (с префиксом «www» и без него), и один и тот же контент живёт в обеих версиях. Так создаются дубликаты каждой из этих страниц. То же самое относится к сайтам, которые поддерживают версии как в http: //, так и в https: //. Если обе версии страницы являются живыми и видимыми для поисковых систем — это проблема с дублированием контента. И как говорилось раньше, вес таких страниц делится на количество страниц.
Устранение проблемы с повторяющихся контентом сводится к одной идее: указать, какой из дубликатов является «правильным».
Всякий раз, когда контент на сайте можно найти по нескольким URL-адресам, он должен быть канонизирован для поисковых систем.
(Канонический тег («rel canonical») — это способ сообщить поисковым системам, что конкретный URL-адрес представляет собой главную копию страницы.)
На данный момент используют один из трёх основных способов избавиться от индексирования дублей страниц.
· использование 301 перенаправления на правильный URL,
· rel = canonical атрибут
· или использование инструмента обработки параметров в Google Search Console.
301 перенаправление.
Во многих случаях лучшим способом борьбы с дублирующим контентом является настройка 301 перенаправления с «дублированной» страницы на исходную страницу контента.
Когда несколько страниц с потенциалом для ранжирования хорошо объединены в одну страницу, они не только перестают конкурировать друг с другом; они также создают более сильную релевантность и популярность сигнала для поисковика в целом. Это положительно повлияет на способность «правильной» страницы хорошо ранжироваться.
Атрибут rel = «canonical».
Другим вариантом для борьбы с копиями контента является использование атрибута rel = canonical. Это говорит поисковым системам, что данная страница должна рассматриваться как копия указанного URL-адреса, а все ссылки, метрики контента и «рейтинг мощности», которые поисковые системы применяют к этой странице, должны быть направлены на указанный адрес URL.
Атрибут rel = «canonical» является частью HTML-страницы, заносится в HEAD страницы, и выглядит следующим образом:
Общий формат:
<head>
…[другой код, который должен быть в HTML-заголовке веб-страницы]…
<link href = «АДРЕС (URL) ОРИГИНАЛЬНОЙ СТРАНИЦЫ» rel = «canonical» />
…[другой код, который может быть в HTML-заголовке веб-страницы]…
</ HEAD>
Например, для текущей страницы указать ее каноническую ссылку <link rel=«canonical» href="http://site.com/canonical-link.html"/>.
Атрибут rel = ‘’canonical’’ должен быть добавлен в HTML-заголовок каждой повторяющейся версии страницы, а часть «АДРЕС (URL) ОРИГИНАЛЬНОЙ СТРАНИЦЫ» выше заменена ссылкой на исходную (каноническую) страницу.
Атрибут передает примерно одинаковое количество веса ссылки в качестве перенаправления 301, и, поскольку он реализован на уровне страницы (вместо сервера), более легок в исполнении.
Мета-роботы Noindex.
Один метатег, который может быть особенно полезен при работе с дублями контента, — это meta robots, когда он используется со значениями «noindex, follow».
Обычно называемый Meta Noindex, Followи технически известный как content = «noindex, follow», этот тег мета-роботов добавляется в HTML-заголовок каждой отдельной страницы, который должен быть исключен из индекса поисковой системы.
Общий формат:
<head>
…[другой код, который должен быть в HTML-заголовке веб-страницы]…
<meta name = «robots» content = «noindex, follow»>
…[другой код, который должен быть в HTML-заголовке веб-страницы]…
</ HEAD>
Тег meta robots позволяет поисковым системам сканировать ссылки на странице, но не позволяет им включать эти ссылки в свои индексы. Важно, чтобы дубли страниц все равно сканировалась, хотя говорите Google не индексировать ее, потому что Google явно предостерегает от ограничения доступа к общему доступу к дублированию контента на вашем веб-сайте.
Поисковые системы желают видеть все на случай, если вы сделали ошибку в своем коде.
Использование мета-роботов является особенно хорошим решением для разрешения проблемы с дублями страниц.
Предпочтительная обработка доменов и параметров в Google Search Console.
Консоль Google Search Console позволяет указать предпочтительный домен сайта (например, http://yoursite.com вместо http://www.yoursite.com) и указать, должен ли Googlebot сканировать различные параметры URL-адреса по-разному, т.е. обрабатывать параметры.
В зависимости от структуры URL-адреса и причины возникновения проблемы с дублями страниц, можно настроить или предпочитаемый домен, или обработку параметров (или оба!).
Основным недостатком использования обработки параметров в качестве основного метода работы с копиями страниц является то, что эти изменения, работают только в Google.
Любые правила, введенные с помощью Google Search Console, не повлияют на то, как Яндекса, так и других поисковых систем, которые сканируют сайт. Придется использовать инструменты для других поисковых систем в дополнение к настройке параметров в Search Console.
Файл robots. txt.
В файле robots. txt сообщается поисковым ботам, какие страницы или файлы не стоит сканировать.
Для этого используют директиву «Disallow». Она запрещает заходить на ненужные страницы.
Заметьте, если страница указана в robots. txt с директивой Disallow, это не значит, что страница не будет проиндексирована, и не попадёт в выдачу.
Это может произойти, потому что
· страница была проиндексирована ранее,
· на неё есть внутренние
· или внешние ссылки.
Инструкции robots. txt носят рекомендательный характер для поисковых ботов. Поэтому этот метод не гарантирует удаление дублей из списка ранжированных страниц.
Всегда тег rel = canonical гарантирует, что версия вашего сайта получит дополнительный кредит доверия как «оригинальный» фрагмент контента.
Дополнительные методы для работы с дублирующим контентом.
1. Если веб-мастер определяет, что каноническая версия домена — www.example.com/, то все внутренние ссылки должны идти по адресу
http: // www. example.com/example, а не http: // example.com/page
(обратите внимание на отсутствие www).
2. При копировании фрагмента контента убедитесь, что страница с копированной частью добавляет ссылку на исходный контент, а не вариант URL.
3. Чтобы добавить дополнительную защиту от копирования контента, уменьшающего SEO- вес для контента, разумно добавить ссылку на rel-canonical для ссылок на существующие страницы. Это канонический атрибут, указывающий на URL-адрес, на котором он уже включён, и это значит, что это препятствует воровству контента.
После того как устранили дублирующий контент необходимо проверить сайт ещё раз. Только так можно убедиться в эффективности проведённых действий.
Анализ сайта на дубли желательно проводить регулярно. Только так можно вовремя определить и устранить ошибки, чтобы поддерживать высокий рейтинг сайта.
Дополнительно читайте о дублях страниц в ФИЛЬТРЕ PANDA, в первой части книги «36 фильтров Google».
ИЗОБРАЖЕНИЯ
60 фактор. Уникальность изображения
На сайте изображения должны быть уникальными, также, как и тексты. Если картинка взята с другого сайта, то такие изображения не учитываются.
Даже если у вас интернет-магазин, который продаёт брендовые вещи, и на нем вы размещаете фотографии производителя, то для поисковиков — это не аргумент качества сайта, а фактор того, чтобы не учитывать это изображение.
Только уникальные изображения добавляют вес страницы.
61 фактор. Дубли изображения
Также, как и текст поисковик учитывает только на одной страницы, которую проиндексировал первой, так и изображение увеличивает вес только один раз.
Повороты, обрезание, зеркальные отражения, применение различных фильтров Google распознает. Так что такие манипуляции с изображениями не проходят.
62 фактор. Количество пикселов и килобайт
Изображения менее 160 пикселов — это 40х40 пикс. Google относит к дизайнерскому оформлению сайтов и не учитывает. Поэтому миниатюры изображений должны быть более чем 50х50 пикселов, если желаете, чтобы поисковик учёл эту картинку. Это замечание актуально для интернет-магазинов, которые размещают несколько мелких изображений товара под одним большим, потому что Google считает мелкие картинки частью дизайна.
Google считает, что несколько изображения товара лучше его представляют, чем одна картинка.
Поисковик считает, что большие изображения более полезны пользователю, но следует учитывать, что чем больше картинка, тем требуется больше времени для её загрузки. Если же страница сайта грузится долго, то это существенный фактор понижения веса сайта.
Сейчас фотоаппараты позволяют делать фотографии более 10 МБ, и количеством пикселей более чем 5000х3000. Такие фотографии не допустимы для интернет-страниц.
Поэтому первое, что нужно сделать — это уменьшить размер фотографии до размера экрана пользователя. Если Ваш потенциальный пользователь будет смотреть Ваш сайт на компьютере или ноутбуке, то, делайте фотографии не больше разрешения его монитора. Если де сайт нацелен на пользователей смартфонов, то уменьшайте фотографии под экран смартфона.
Для смартфонов не стоит размещать фотографий больше трёх. По исследованиям маркетологов большее количество — утомляет.
И последнее — фотографии не должны превышать 200 КБ, а желательно чтобы они были меньше 100 КБ. В любом случае соблюдайте правило: «Минимальный размер при сохранении допустимого качества.»
63 фактор. Количество изображений на странице
Хорошая статья с одним изображением получает больший вес, чем эта же статья без изображения. Google считает, что изображение — хороший сигнал того, что страница качественная.
Однако второе, третье и т. д. изображения слабо увеличивают вес страницы, но снижают скорость загрузки страницы, а чем медленнее скорость загрузки, тем больше уменьшается рейтинг сайта.
Много изображений, значит дольше пользователь остаётся на странице, рассматривая их. Это увеличивает рейтинг страницы, но увеличение скорости загрузки снижает этот же рейтинг. Точных расчётов, возможно ещё и у Google нет, но это не значит, что его и не будет. Поэтому лучше не заморачиваться на этих параметрах, а делать просто хорошо. В конечном счёте Google учится выбирать лучшее.
64 фактор. Название файла изображения
Очень часто на веб страницах можно увидеть картинки с такими названиями «e1495475889821.jpg».
Google не приветствует такие названия. Google считает, что название файла изображения должно соответствовать изображению. Поэтому файл с картинкой следует называть по изображаемому объекту латиницей, и желательно с употреблением ключевых слов.
Например, «divan.jpg».
Если требуется написать несколько слов, то нужно писать их через дефис или нижнее подчёркивание: «сhjornyj-divan.jpg», или «сhjornyj_divan.jpg» хуже без разделения «сhjornyjdivan.jpg». Цифры допускаются если указывается количество объектов на изображении. Заглавные буквы — не допустимы. Можно использовать только маленькие буквы без пробелов Недопустимы символы и спецсимволы.
Кроме этого, Google отмечает, что путь к изображению тоже должен быть человеку понятным, например, таким «img/divany/сhjornyj_divan.jpg».
65 фактор. Атрибут ALT
Текст alt, по существу, отображается, когда изображения отключены в большинстве браузеров, поэтому мы считаем его частью текста на странице.
Джон Мюллер, Google 2017.
«Поскольку робот Googlebot не видит изображения напрямую, мы обычно концентрируемся на информации, предоставленной в атрибуте «alt».
SEROUNDTABLE, 2017.
Атрибут ALT — значимый, как теги заголовка и описания веб страницы.
Формат записи:
<IMG src = "file-name.gif» alt = «Здесь размечается alt-текст»>
Также, как и теги заголовка и описания страницы этот текст должен быть уникальным, описывать суть демонстрируемого, и иметь ключевую фразу как можно ближе к началу.
Например, если вы разместили статью о том, как ваш щенок любит играть с теннисным мячом, оптимизировали статью под фразу «мой щенок», и разместили фотографию, где он изображён играющимся, то уместно такое описание.
alt = «Мой щенок Кеша — большой любитель играть на спортивной площадке с теннисными мячами.»
Если у вас несколько изображений, то разнообразие описаний изображения увеличивает вес страницы.
Чем больше — тем лучше, но не забывайте — чем больше фотографий, тем дольше грузится страница.
Если изображение является частью дизайна сайта, то Google рекомендует всё равно писывать атрибут alt, и оставлять его пустым вот так alt = «».
Этим вы сообщаете поисковику, что это изображение относится к дизайну сайта.
Если же у Вас нет подписей к изображениям на веб странице, то Google считает, что у Вас нет иллюстрации рассказываемого в статье, нет дополнительной информации, только красивый дизайн, который больше по объему имеющейся информации. А такие страницы — теряют в весе.
Ещё хуже, когда атрибут «alt» отсутствует в теге img.
Какова же допустима длинна текста в атрибуте alt?
По проведённым исследованиям в англоязычном Google было получено, что поисковик считывает до 16 слов текста из этого атрибута. Делайте этот атрибут уникальным и содержательным, потому как Google считает его немаловажной частью текста.
Если желаете иметь достоверную картину факторов, влияющих на ранжирование, вы должны проводить эксперименты на своём собственном сайте для проверки любых заявлений, которые читаете в Интернете по двум причинам.
1. Можете натолкнуться на утверждения неумелых пересказчиков, которые недопоняли авторитетов, или вообще сами, что-то придумали.
2. Google — постоянно совершенствует свой поисковый алгоритм, а поэтому многое, что работало некоторое время назад, становится бесполезным.
3. Google — если, что-то написал в своём руководстве, то это он может только указал на перспективу развития.
4. То, что Google ввёл на английском языке ещё может быть не включено в поиск на русском и других языках.
66 фактор. Атрибут TITLE
Атрибут «title» в теге img для пользователя отображается в виде всплывающей подсказки.
Многие сеошники считают, что необходимо его вписывать и заполнять ключевыми словами.
Очевидно, они руководствуются фразой:
«Не стесняйтесь дополнять атрибут „alt“ „title“ и другими атрибутами, если они предоставляют ценность вашим пользователям!»
SEROUNDTABLE, 2017.
Но ценностью для посетителя будет не набор ключевых или LSI слов, при подводе мышки на изображение, а информация, которую получит пользователь при клике.
Вернёмся, к примеру, о щенке, где писали
alt = «Мой щенок Кеша — большой любитель играть на спортивной площадке с теннисными мячами.»
По мнению Google более логично написать, что произойдёт при клине. Например, в качестве атрибута для ссылки
Title= «Кликните, и посмотрите на увеличенное изображение в высоком разрешении».
Итак, атрибут «title» следует ставить, когда изображение указывает на навигационное действие, такое как «переход к следующему экрану» или «возврат к началу страницы». В этом случае изображение должно сопровождаться пояснительным текстом, который указывает, что пользователю предлагается сделать.
67 фактор. Формат изображения
С некоторого времени при определении скорости загрузки веб-ресурса на developers.google.com пользователи могут видеть такое сообщение:
Google для уменьшения скорости загрузки предлагает отказаться от форматов JPG и PNG, и пере конвертировать все изображения на новые форматы: JPEG 2000, JPEG XR и WebP.
Формат JPEG 2000 (JP2)
был создан комитетом Объединённой группы фотографических экспертов в 2000 году. Он предлагает некоторые преимущества в точности изображения по сравнению со стандартным JPEG.
Но по данным caniuse.com этот формат поддерживает только Safari и iOS Safari, т.е. более поздние разработки продукции компании Apple.
Формат изображений JPEG XR
от Joint Photographic Experts Group, имеет лучшее сжатие чем jpg. Поддерживает сжатие без потерь, альфа-канал и 48-битный глубокий цвета.
Но, как видите он практически не поддерживается современными обозревателями.
Формат изображения WebP,
От компании Google поддерживает сжатие с потерями и без потерь, а также анимацию и альфа-прозрачность.
Поддерживается практически всеми современными обозревателями, за исключением продуктов Apple.
Поэтому, если желаете, чтобы на Safari ваши картинки не были видны, то можете смело использовать этот формат.
Можно использовать тег picture:
<picture>
<source type=«image/webp» srcset=«path/to/image. webp»>
<source type=«image/jp2» srcset="path/to/image.jp2»>
<source type=«image/jxr» srcset=«path/to/image. jxr»>
<img src="path/to/image.jpg»>
</picture>
Но тег picture не поддерживают старые обозреватели, поэтому нужен будет js:
Достаточно просто подключить и всё:
<script async=true src=/path/to/picturefill. js> </script>
<script async=true src=/path/to/jxr. js> </script>
<script async=true src=/path/to/jp2.js> </script>
Однако если вы не желаете здорово заморачиваться, на старые обозреватели, то можно использовать такой формат записи:
<picture>
<source srcset=«my_image. webp» type=«image/webp»>
<img src="my_image.jpg» alt=«Моё изображение»>
</picture>
Менее трудозатратный вариант.
Для Google и поддерживающих WebP обозревателей будет выводится my_image. webp, а для Safari будет показываться изображение my_image.jpg.
Т.е. картинки с jpg оставляем как есть, а с помощью утилит, которые вы без труда найдёте в интернете конвертируем jpg в WebP.
Преобразование картинок в WebP не только уменьшает скорость загрузки, но и показывает поисковику, что страница качественная.
68 фактор. Результаты изображения
Блок изображения Google иногда появляются в обычных, органических результатах поиска.
Многие SEO-эксперты утверждают, что появление в этом блоке увеличивает рейтинг сайта.
Другой пользы от появления в этом блоке, маловероятно, потому что людей, ищущих картинки, вряд ли интересуют покупки и тексты.
ВИДЕО
69 фактор. Видео
Здесь мы не будем рассматривать места, где размещать видео, как подбирать ключевые слова и писать заголовки и описания. Все это делается на видео-хостинге, где хранится видео.
Здесь рассмотрим только отношение Google к видео размещённого на странице веб-сайта, и как лучше сделать, чтобы увеличить вес страницы.
Видео на странице — это прежде всего разнообразие контента на станице, что уже является положительным сигналом. Это и увеличение времени просмотра страницы, что является ещё одним сигналом для поисковика качества содержания страницы.
Третьим положительным фактором является то, что видеофайл берётся с другого сайта, а это уже внешняя ссылка.
К сожалению, Google при индексировании берет со страницы только одно видео. Если же на странице размещено несколько видео, то поисковик проиндексирует только первое.
Время от времени вижу сайты, где видео скрыто в закладках, или находится в конце страницы, и чтобы его увидеть нужно выполнить некоторые действия. Поисковые сканеры также будут уходить, не индексируя скрытое видео.
Это, естественно, приводит к низким показателям, потому как пользователи не добираются до видео, и уходят, не промотав до видео, а Google считает, что видео не интересно, и этот факт идёт в минус весу страницы.
Бывает так, что вместо видео размещается картинка, при клике на которую в сплывающем окне открывается видео. Такой вариант размещения говорит поисковику, что видео нет на этой странице.
Чтобы видео дало максимальный прирост к рейтингу его делают центром внимания на веб-странице.
Так же, как и для картинок справедливо то, что одно видео нельзя вставлять «для лучшей видимости» на несколько страниц одного сайта. Так создаётся конкуренция на веб-сайте для каждого экземпляра видео, которое вы опубликовали.
Подумайте об этом с точки зрения, когда кто-то ищет, например, советы и приёмы веб-дизайна в Google. Поисковик на этот запрос подобрал несколько ваших замечательных страниц, и алгоритм должен решить, какую страницу отображать в результатах поиска первой. Если видеоролик размещён на трёх различных веб-страницах, то шансы появиться в результатах поиска будут разделены на 3, между этими страницами.
Однако, если ролик опубликован на одной странице, и на этой же странице собраны все мнения, комментарии и впечатления, тогда у страницы будет больше шансов появиться в результатах поиска первой.
70 фактор. Уникальность Видео
Также, как и текст, и изображения на сайте должны быть уникальными, так и видеоролик должен быть уникальным.
Единственное отличие от другого контента — видеоролик не обязательно должен быть размещён на сайте. Например, он может быть размещён на канале Youtube, а на сайте устанавливается ссылка на видео.
71 фактор. Транскрипты Видео
Это полное текстовое представление контента, содержащегося в видео. Метаданные и видео теги не содержат столько информации о содержании видео в поисковых системах, сколько транскрипции. Поисковые роботы сканируют текст и используют его для индексирования. Таким образом, видео-транскрипция помогает поисковым системам лучше понять содержание видео и улучшить его рейтинг. Как создавать такой файл, уверен любой найдёт в интернете.
Существует и другой приём поднятия рейтинга с размещённым видео на странице сайта. Разместить краткое описание того, что показывается на видео рядом. И в конце дописать: «Более подробно об этом смотрите видео». Так для поисковика — это дополнительный контент, а посетителю — дополнительное привлечение внимание к видео.
72 фактор. Файл sitemap для видео
Создайте файл sitemap для видео.
Видео элементы обеспечивают поисковые системы метаданными о видео контенте на веб-сайте и являются расширением существующей карты сайта.
Можно использовать карту сайта, чтобы сообщать поисковым системам о категории, названии, описании, длине и целевой аудитории для каждого видео, которое вставляются на сайт. В дополнение к этому можно использовать sitemap, чтобы дать поисковым системам больше информации видео, например, URL-адрес страницы, на которой размещено видео, дату срока действия, ограничения и платформу.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.