
Бесплатный фрагмент - Вечный двигатель третьего рода
Неканонические размышления о бизнес-системах, или О чём стоит сначала подумать. Модели данных и бизнес-логика
От автора
«О чём задумался, детина? -»
Русская народная песня — «Вот мчится тройка почтовая»
«Таким образом, передо мной встала особая проблема — объяснить, чем же я, собственно, занимаюсь.»
Карлос Кастанеда — «Дар Орла»
Проблема передо мной встала тогда, когда я (не вполне серьёзно — ибо достаточно реально оценивал тогда и оцениваю сейчас свои способности к литературному творчеству как очень близкие к нулевым) пообещал своим дочкам изложить мои соображения по поводу того, чем же это я занимался во время своей деятельности на ниве IT.
Но слово — не воробей, и в конце концов совесть заставила заняться этим неким подобием инвентаризации своих соображений по поводу того, что же, как и исходя из чего я считал необходимым делать (хотя частенько реализовать это и не удавалось в силу, скажем так, различных иногда объективных, иногда субъективных, но всегда непреодолимых обстоятельств).Так что записанные мною размышления — это не пересказ обязательных к исполнению пунктов из учебников, а просто перечень тем и ситуаций, над которыми желательно предварительно хорошенько подумать, а не сразу кидаться ляпать по какой-либо из зазубреных схем нечто картонное по принципу — зато скорее будет, чем отчитываться.
НАЧАЛО
Что представляют собой IT-бизнес-системы. В общем виде это некий информационный скелет реального бизнес-процесса. Причём это не некое искусственное добавление типа карикатуры «Диспетчер, куда подавать груз?«на тему «автоматизации» из старого номера журнала «Крокодил». Нет смысла навешивать на грузчика рацию и телевизор, если он по-прежнему катит тачку. IT-бизнес-система должна быть частью автоматизированного бизнес-процесса, определяя его архитектуру, обеспечивая его функционирование, в том числе и управление. То есть, по аналогии с биологическими объектами, это совокупность скелета, кровеносной и нервной систем.
Однако лучше не тратить время на болтологию — оставим это тем, кто на этом зарабатывает себе на жизнь, организуя и проводя различные «школы», «семинары» и т.п., а заняться делом и подумать о «вариациях на тему»: как строятся бизнес-системы? Как это делать — хотя бы в первом приближении — оптимально?
Тема первая: Модели данных в бизнес-системах
По порядку. Первым делом — ибо любая бизнес-система оперирует данными — поразмышляем о структурах данных. И начнём, естественно, с конкретного примера, с варианта, кажущегося наиболее простым: простой-примитивной — на первый взгляд — библиотечной картотеки…
Размышление первое: БИБЛИОТЕКА
Нет, под библиотекой здесь будем иметь в виду не учреждение, расположенное в собственном либо арендованном здании, обременённое всевозможными расходами на персонал, коммунальные услуги и т. п., обслуживающее клиентов в читальных залах и посредством абонемента…
Займёмся только фондом библиотеки — книгохранилищем (как это называлось в доэлектронную эру) вкупе с каталогами (причём логистическая составляющая — сбор заявок, доставка литературы в залы, выдача/приёмка и т. п. — останется вне поля нашего внимания).
И представим всё это в виде структур данных.
…а представлять будем не в виде набора таблиц и относящихся к ним списков полей — а в виде диаграмм-графов, показывающих объекты и связи между ними. Атрибуты (поля), конечно же, упоминания не избегнут — но лишь те, которые призваны однозначно идентифицировать объект; и то — не в конкретно-обязательной форме, а только концептуально. Ибо это — универсальное представление, поддающееся реализации в любых терминах — хоть реляционных баз данных, хоть графовых… да вообще как угодно.
И будем безбожно путать термины «сущность» и «объект», «атрибут» и «поле», ибо в подобных рассуждениях это не принципиально: что таблица, что структура — всё едино.
Основные сущности
Начальный этап дизайна структур данных — определение сущностей, т. е., объектов, из которых состоит рассматриваемая система. В данном случае — библиотечный фонд.
В самом общем виде — в библиотеке хранится что-то где-то, содержащее какую-то информацию…
В самом конкретном — в комнатах стоят шкафы или стеллажи, на полках — книги, которые содержат произведения (одно или много; или же — часть) каких-либо авторов… Это — случай классической библиотеки. Более современный случай — в фонде имеется информация, хранимая в электронном (оцифрованном) виде, в виде файлов. Файлы могут находиться как на носителях типа дискет (а что? вдруг ещё остались где-нибудь), магнитных лент (это вообще раритеты), компакт-дисков (CD, DVD, BD и т. п.), а также на накопителях (т. н. жёстких дисках) серверов. Носители будут храниться как и книги, на полках (либо в ящиках) шкафов, сервера будут расположены в комнатах — так что принципиальных отличий здесь не видно.
Сделаем первый шаг.
Назовём основные сущности:
— хранимая единица информации — Unity
— местоположение хранения этой единицы — Placeholder
— содержание хранимой единицы информации — Content
Связаны они следующим образом:
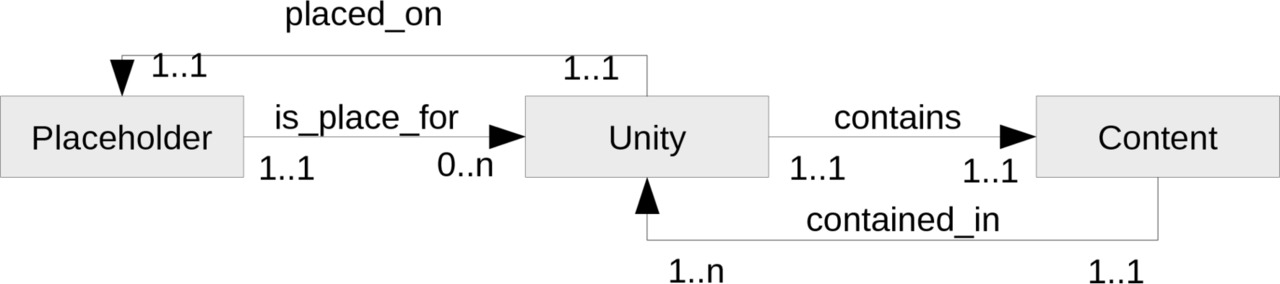
Что видно из этой диаграммы?
— В месте хранения Placeholder может находиться несколько хранимых единиц Unity, но может не быть и ни одной. Это показано связью (relation) is_place_for.
— Каждая хранимая единица Unity обязательно находится в одном (и не более! это вроде само собой понятно) месте хранения Placeholder (показано связью placed_on).
— Каждая хранимая единица Unity обязательно — поскольку речь идёт об информации — имеет вполне определённое содержание Content. Причём — только одно. Связь contains.
— Напротив, содержание Content вполне может относиться к нескольким (одной и более) хранимым единицам Unity (связь contained_in). Пример — несколько экземпляров одной книги.
Это — самое общее представление. Будем рассматривать эти сущности более детально, и в том же порядке, в котором они были декларированы: Unity, затем Placeholder, ну и напоследок Content. Возможно (то есть, практически наверняка), что-то ещё добавится по пути, в процессе.
Естественно, для каждой сущности будет описан и минимальный набор обязательных — придающих ей уникальную значимость — атрибутов.
Да, вот что ещё здесь обязательно надо упомянуть: все имена сущностей (объектов) и их атрибутов (полей), а также связей между объектами — вымышленные, взятые исключительно для примера. Всякое совпадение с реальными именами чисто случайное…
И — о, Гринпис, где твой ледокол! — при рисовании схем и написании текста ни одно животное не пострадало.
Хранимая единица информации (Unity)
Итак, для начала — хранимая единица информации Unity. Очевидно, она должна описывать предметы, которые хранятся в фонде, учитываются как отдельные единицы и могут выдаваться абонентам. Что может храниться в библиотеке?
— Книги,
— журналы,
— газеты,
— рукописи,
— ксерокопии,
— микрофильмы,
— микрофиши,
— магнитные, оптические и прочие современные нам носители,
— и т. д., и т. п. — в общем, всё, что только может содержать информацию.
Здесь надо немного остановиться. Вопрос касается файлов.
С одной стороны, файл — отдельная законченная единица информации. С другой стороны, в одном файле может содержаться несколько независимых единиц информации — например, оцифрованных книг, репродукций и т. п. И с третьей стороны — один хранимый экземпляр носителя информации (например, компакт-диск) может содержать несколько файлов. Кстати, этот компакт-диск может быть не самостоятельным — а приложением к какой-либо книге…
Остановка получается недолгая, ибо решение очевидно и просто: каждая единица информации (Unity) может быть в то же время и собранием (Collection) подобных единиц.
Вернёмся к теме — Unity.
Каждый экземпляр этой сущности должен представлять собой сочетание атрибутов, уникальным образом характеризующих хранимую единицу информации. На сами же отдельные атрибуты требование уникальности значений может распространяться не всегда. Если атрибут должен иметь уникальное значение, то оно обычно автоматически генерируется программным способом при создании экземпляра сущности (например, в случае целочисленных величин или весовых значений символов логично применить автоинкремент). Если значение атрибута может быть не уникальным, то возможны случаи:
— значение атрибута абсолютно произвольно (так называемый «мануальный ввод»), либо
— значение атрибута должно быть задано из определённого списка значений (выбор из справочника).
В первом случае атрибут должен быть членом структуры объекта (сущности). Во втором же логичнее создать отдельный список возможных значений атрибутов (или же в качестве справочника может выступить список любых других — в том числе и той же самой — сущностей) и устанавливать связь между ним и основным объектом. В конкретных имплементациях такая связь со справочником может устанавливаться либо посредством кросс-структуры (таблицы перекрёстных ссылок), либо прямой ссылкой на запись справочника — но не будем этим заморачиваться, ибо сие суть не принципиально, а исключительно по обстоятельствам.
Отметим, что и уникальные атрибуты могут выбираться из справочников — например, при наличии неких доменных ограничений. В этом случае необходим дополнительный контроль единственности выбора… но, как говорится — любой каприз за ваши ресурсы.
Итак:

Разберём по позициям. На первый раз — подробно.
Unity::id
Уникальный идентификатор, который будет использоваться для организации связей с другими структурами данных библиотеки. Требования к нему:
— лёгкость автоматического генерирования уникальных значений,
— достаточный (для конкретной информационной системы — в нашем случае это библиотека) диапазон возможных значений,
— минимальный физический размер поля.
Третий пункт в современном дизайне баз данных как-то особенно не подчёркивается, однако — при всём уважении к постоянно возрастающему быстродействию вычислительной техники, не стоит заниматься наплевательским расходованием её ресурсов — поиск в двоичном дереве в итоге тем быстрее, чем короче ключевое поле.
Всем необходимым условиям вполне (на мой взгляд; можете не соглашаться) удовлетворяет тип integer (unsigned integer — если оперировать терминами языков программирования типа C/C++): при длине поля в четыре байта диапазон значений составляет от 0 до 4 294 967 295 (0xffffffff в шестнадцатеричном представлении). К примеру, для типа numeric, представляющего собой фактически вариант формата char, потребовалось бы поле длиной в десять байт. Уникальность значений легко обеспечивается автоинкрементом (большинство современных реляционных баз данных обеспечивают это на стороне сервера БД — достаточно задать полю соответствующее свойство). Для быстрого поиска идентификатора в таблице по этому полю должен существовать индекс.
И, естественно, поле идентификатора должно быть заполнено всегда.
Unity::code
Уникальный библиотечный код — своего рода инвентарный номер, присваиваемый хранимой единице (книге, журналу и т. п.) при поступлении в фонд библиотеки.
Условный формат string подразумевает возможность наличия в коде не только цифр, но также букв и спецсимволов. Код может состоять из нескольких частей, несущих в себе, например, классификационную информацию, информацию о месте хранения и т. д. Всё это специфично для каждой конкретной библиотеки — поэтому конкретный размер поля не предлагается. В принципе, если это целесообразно, то вместо одного поля (атрибута) может быть несколько — по числу обязательных частей; полный код в таком случае собирается из этих полей по соответствующему правилу.
Естественно, код должен быть уникальным. Однако, учитывая специфику предлагаемой модели данных, а именно: то, что единица информации может быть одновременно собранием (коллекцией) единиц, — это поле может оставаться незаполненным. Может и вообще отсутствовать — если система учёта в конкретной библиотеке такого кода не предусматривает.
Для возможности быстрого поиска, сортировки и группировок по коду — индексация.
Unity::name
Имя хранимой единицы. Название книги, рукописи, имя файла и т. п. Также — в случае сборников-коллекций — наименование собрания сочинений, серии книг («Миры Клиффорда Саймака», например, или «Мир приключений»), журнала (элементы коллекции — отдельные номера) и т. д.
Значение поля может быть (и чаще всего так оно и есть) не уникальным, однако — в отличие от библиотечного кода — оно должно быть обязательно. Насчёт длины поля (поле, естественно, должно быть произвольно-символьным) чёткие рекомендации давать трудно… приведу пример названия одного широко известного произведения (которое вполне может встречаться в виде отдельной книги): «Жизнь, необыкновенные и удивительные приключения Робинзона Крузо, моряка из Йорка, прожившего 28 лет в полном одиночестве на необитаемом острове у берегов Америки близ устьев реки Ориноко, куда он был выброшен кораблекрушением, во время которого весь экипаж корабля кроме него погиб, с изложением его неожиданного освобождения пиратами; написанные им самим». В этом плане проще с именами файлов: операционные системы налагают конкретные ограничения на их длину (Unix — 255, Windows — 257, Mac OS X — 256 символов соответственно). В зависимости от конкретной задачи — т. е., планируемого основного содержания библиотеки и платформы реализации — string может быть реализован, например, как TEXT, CHAR (n) либо VARCHAR (n), где n — длина поля.
Индексация по этому полю желательна как для возможности сортировки по алфавиту, так и для структурного поиска (по вхождению слов). Частный пример реализации второго случая — использование DB2 Text Extender.
Unity::path
Местоположение хранимой единицы. Как и в случае библиотечного кода, формат данного поля представлен чисто условно. В реальной системе это должен быть либо конкретный адрес, где находится книга (либо другой хранимый объект) — комната, шкаф/стеллаж, полка/ячейка, — и тогда рациональней использовать набор из нескольких полей (атрибутов), либо путь к файлу — тогда, как и для поля name, будут действовать зависящие от платформы реализации ограничения на длину. Но и в этом случае — поскольку полный путь включает сетевое имя сервера (или сетевого диска; или локального диска — если сервер один) и иерархию каталогов — удобнее всё же будет использовать набор полей.
Естественно, требование уникальности неприменимо к местоположению/пути в любом случае: как на одной полке может стоять много книг, так и в одном каталоге может находиться множество файлов.
Если сущность определяется как Collection — то единого пути может не быть (подшивка Chemical Abstracts за несколько десятков лет ну никак не вместится на одну полку), и атрибут (или набор атрибутов) будет не заполнен. Но это — только для Collection, все единичные Unity — в том числе и входящие в различные Collection — должны где-то находиться, и path у них должен быть заполнен (см., впрочем, *)).
Совершенно закономерен здесь вопрос (если следить за процессом рассуждений внимательно — а не по принципу «в одно ухо вошло — из другого… м-м-м…») о правомерности существования этого самого атрибута: зачем он здесь, если местоположение хранимой единицы достаточным образом описывается связью placed_on к объекту Placeholder?
Атрибут Unity::path является производным (образно говоря, суммой по некоторым — конкретным для каждой имплементации — правилам) от полной иерархии связанных по placed_on объектов Placeholder, а именно атрибутов Placeholder::path. Содержимое его, соответственно, меняется синхронно изменениям в иерархии связанных объектов Placeholder (как это будет реализовано — на уровне базы данных, или же на уровне приложения — целиком на совести имплементатора).
Возможно, это некое нарушение «стройности изложения», но подобные — явно необходимые — случаи денормализации всё же лучше предусматривать заранее, чтобы по возможности избегать множественных итераций при дизайне структур данных.
*)
Поскольку информация о местоположении хранимой единицы может либо содержаться в атрибуте Unity::path, либо быть закодирована в поле Unity::code, то для случая обязательного наличия информации о местоположении Unity должно существовать и быть заполнено хотя бы одно из этих полей.
Коллекции (Collection)
Добавим теперь «второе лицо» сущности Unity — способность представлять собой объект Collection. Сделать это можно разными способами — в зависимости от конкретной концепции организации коллекций.
Для простоты и наглядности просто представим ситуацию в виде графа:
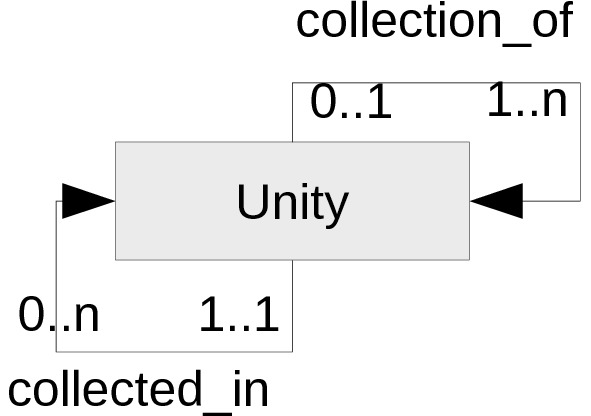
То есть, каждая единица может быть (либо не быть) коллекцией ненулевого числа отдельных хранимых единиц (связь collection_of), а каждая хранимая единица заведомо существует и может входить (либо не входить) в различное число коллекций (показано связью collected_in).
Например, роман «Война и мир» Льва Николаевича Толстого (бумажная книга без приложений в виде компакт-диска с аудио-версией или ролевой игрой по сюжету) коллекцией сам не является, но в принципе может являться частью коллекции «Сочинения Л. Н. Толстого» (если какое-либо издательство выпустило такую серию). Но: если коллекцией является некое «Собрание сочинений Л.Н.Толстого в… томах», то элементом такой коллекции будет не конкретное произведение, а «Том номер такой-то». А какие произведения будут в этом томе — уже дело содержания. В общем, хозяин — барин, но принцип понятен.
Оговорка насчёт «бумажной книги без приложений» весьма существенна: книга по какой-либо проблеме программирования, к которой прилагается диск с примерами, в данной схеме — уже коллекция.
Каких-то дополнительных специфических атрибутов — по сравнению с «базовой» Unity — Collection не предполагает. Однако появляется некоторая поведенческая специфика:
— экземпляр Unity не может быть Collection для самого себя;
— удалён может быть только тот экземпляр Unity, который ни для кого более не является Collection.
То есть:
— связь collected_in объекта Unity не может указывать на самого себя;
— у удаляемого экземпляра Unity не должно быть связей collection_of.
Коллекции являются не некоей исключительной прерогативой хранимых единиц библиотечного фонда, а общим концептуальным конструктивным элементом структур данных, позволяющим организовывать иерархию объектов, и будут встречаться и в дальнейшем. Поэтому рассуждения о них и были выделены в отдельный пункт.
Имплементационно-специфичным моментом здесь является реализация связей (в случае Unity — collected_in и collection_of; далее встретятся и другие). В частности, в реляционных базах данных для этого могут быть использованы таблицы перекрёстных ссылок, позволяющие организовывать связи типа «многие ко многим» (many-to-many). Надо только не забывать регулировать взаимоотношения связанных объектов в базе при действиях над ними (On Update, On Delete) правилами — CASCADE, RESTRICT… — и всё получится.
Местоположение хранения (Placeholder)
Смешно, но понимание необходимости регистрации местоположения хранимой единицы — а этот атрибут уж никак не специфичен для библиотечного фонда, он обязателен для любого каталога — никак не найдёт своей дороги в массы. Пример: аптека в Минске (столица «незалежнай Беларусі»). Проверив по компьютерной базе (!) наличие запрошенного препарата, аптекарша долго роется наобум в ящиках стоящего у неё за спиной шкафа; утомившись, звонит своей напарнице-сменщице: «А где у нас …?» Сразу понимаешь, что эту аптечную систему не разрабатывали специалисты, а «распрацовывалi адукаваныя тутэйшыя фахоўцы»… но таков уж уровень Gebiet’а Ost.
А что касается места хранения единиц информации, то здесь очевидно наличие многоярусной иерархии.
Книга стоит на полке, полка принадлежит стеллажу, стеллаж расположен в комнате, комната имеет положение в здании (этаж + номер), у здания есть конкретный адрес: номер, улица, город, страна…
Для описания такой иерархии вполне подходит вышеописанный принцип Collection — применимо к сущности Placeholder:
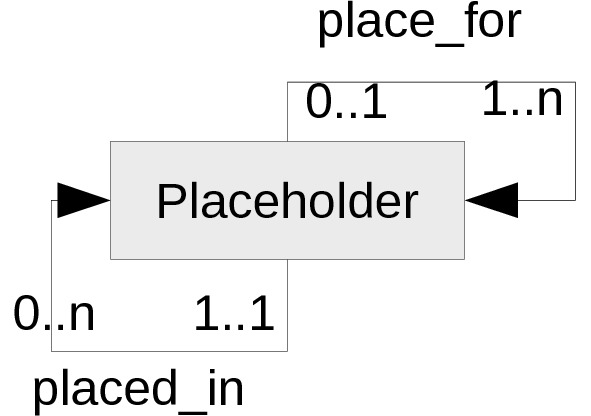
Что значит:
— любое место хранения может содержать в себе некоторое количество объектов — мест хранения; а может и не содержать ни одного, т. е. являться конечным (пример первого случая: шкаф, в нём — полки; пример второго — либо полки, на которых стоят книги, либо же — шкаф без полок, а книги навалены в нём в кучу… и такое случается…); связь — place_for;
— само по себе место хранение существует всегда (а как же!), а вот располагаться в высшем по иерархии объекте ему может быть не обязательно — если оно самое старшее по иерархии, т. н. корневое (связь — placed_in).
Естественно, иерархия мест хранения вверх должна быть ограничена — иначе можно добраться и до астрономических категорий. В рамках нашей модели вполне достаточно ограничиться сверху номером корпуса библиотеки, а уж в качестве конкретизирующего элемента (это может понадобиться — к примеру, при поиске какой-либо информации по нескольким библиотечным фондам) привлекать более полные адресные данные самой библиотеки.
Однако об адресах попозже, пока же перейдём к атрибутам.

Посмотрим, кто здесь есть кто — и что совпадает, а что не совпадает с Unity.
Placeholder::id
Уникальный идентификатор, служащий тем же целям, что и оный у Unity, и с теми же требованиями к себе — ничего нового не добавить.
Placeholder::code
Инвентарный код места хранения. Может, в принципе, содержать в себе информацию и о расположении данного объекта в общей иерархии — либо только в ближайшем, старшем по иерархии, месте хранения. К примеру, для корпуса библиотеки: «1» — номер корпуса (иерархически выше конкретный адрес библиотеки, но это уже совсем другая история). Или «2» — номер этажа в корпусе (вариант: «1—2» — корпус 1, этаж второй; это, кстати, очередной пример возможной денормализации).
Может состоять из нескольких полей — если вдруг так было удобней программистам, или же так предусмотрено системами учёта.
Может — в зависимости от установленного порядка (или беспорядка — это уж как назвать) в библиотеке — вообще отсутствовать. Тогда либо поле name, либо path должны будут содержать значения типа «Второй стеллаж слева от входа», или — для компьютера — «Мой компьютер 1» (найдёте, типа, в свойствах — если сумеете отыскать, где он стоит, этот компьютер)…
На вполне законных основаниях code может отсутствовать, конечно, для дисков и каталогов/подкаталогов в случае хранимых файлов. Тогда соответственные имена будут либо в name, либо в path — это уж с какой ноги встанет дизайнер данных, и то, и другое вполне корректно.
Placeholder::name
Может содержать, например, наименования — в т. ч. условные — зданий («Главный корпус», «Книгохранилище», «Абонемент»). Вряд ли целесообразно (хотя формально верно) записывать туда что-то вроде «Полка стеллажа».
Зато в случае хранения файлов вполне логично здесь (или в path) увидеть «SERVER001», «D:» или «Scientific\».
Placeholder::path
Вполне можно ожидать здесь номер этажа в здании, комнаты на этаже, шкафа/стеллажа в комнате, полки в шкафу/стеллаже (сверху или снизу счёт — это уж как в данной библиотеке заведено).
Для хранимых файлов — имя сервера, диска, каталога (в зависимости от иерархического положения объекта).
*)
Как видно из вышеописанного, хотя бы одно из полей — code, name или path — у объекта Placeholder должно быть заполнено. Какое и как (и вообще — сколько полей/атрибутов необходимо для какой категории информации) — дело конкретной имплементации.
Содержание хранимой единицы (Content)
Перейдём к содержанию хранимой единицы — сущности Content. Что может быть информацией, находящейся в Unity? Некое произведение — одно либо несколько. Романы в книге, статьи в журнале, картины в альбоме, файлы на диске… вариантов много, имя им — легион. Общее же у них всех то, что содержание — это список произведений.
Таким образом выясняется, что граф взаимосвязей объектов Unity, Placeholder и Content — равно как и список основных сущностей — должен быть дополнен сущностью произведение (Opus). Он связан с сущностью Content следующим образом:
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.