
Бесплатный фрагмент - Триангуляция в нейронной сети
Триангуляция в нейронной сети
Триангуляция в контексте нейронных сетей — это использование геометрического метода разбиения множества точек на треугольники для решения различных задач обработки данных, анализа структуры или построения связей между элементами сети.
Основные применения триангуляции в нейронных сетях
— Генерация связей между нейронами: Триангуляция Делоне используется для определения топологии связей между нейронами на основе пространственного расположения входных данных. Например, веса обратных связей между нейронами могут формироваться на основе расстояний между ними, вычисленных по триангуляционной сетке [1].
— Предобработка данных: Перед обучением нейронной сети точки данных могут быть триангулированы для выявления локальных структур и соседств, что позволяет учитывать геометрические взаимосвязи между объектами.
— Сегментация и построение поверхностей: В задачах 3D-моделирования и обработки облаков точек нейронные сети могут использовать триангуляцию для построения поверхностей и сеток, что важно для реконструкции объектов и анализа форм [2] [3].
Пример: Триангуляция Делоне в нейросетях
В одном из подходов, после построения триангуляции Делоне по входному набору точек, для каждого нейрона определяются его соседи по триангуляции. На основе расстояний до соседей вычисляется масштабирующая константа, а веса связей между нейронами устанавливаются с учетом этих расстояний и константы. Это позволяет учитывать локальную геометрию данных при формировании структуры сети [1].
Современные методы: Обучаемая триангуляция
В современных исследованиях, таких как PointTriNet, триангуляция интегрируется непосредственно в архитектуру нейронной сети как дифференцируемый слой. Здесь используются две сети: одна классифицирует, должен ли кандидат-треугольник войти в итоговую триангуляцию, а другая предлагает новые кандидаты. Такой подход позволяет автоматически строить оптимальные триангуляции для облаков точек в 3D-пространстве, что полезно для задач компьютерного зрения и 3D-реконструкции [2] [3].
Преимущества использования триангуляции
— Учет локальной геометрии данных
— Оптимизация структуры связей в нейронной сети
— Улучшение качества сегментации и моделирования сложных объектов
Вывод
Триангуляция в нейронных сетях — это инструмент, позволяющий эффективно моделировать и анализировать пространственные структуры данных, а также строить более информативные и адаптивные топологии связей между нейронами, что особенно актуально для задач, связанных с обработкой пространственных и геометрических данных [2] [1] [3].
⁂
Триангуляция Делоне в нейросетях
Триангуляция Делоне — это способ разбиения множества точек на плоскости (или в пространстве) на треугольники (или более высокоразмерные симплексы), при котором никакая точка из исходного множества не попадает внутрь описанной окружности (или сферы) любого треугольника (симплекса) [4] [5] [6]. Такой подход обеспечивает разбиение с максимально возможными минимальными углами, что позволяет избегать «тонких» и вырожденных треугольников [7] [5].
Применение в нейронных сетях
В нейросетях триангуляция Делоне используется для построения графовой структуры данных, где точки (например, элементы облака точек или векторы признаков) становятся вершинами графа, а рёбра определяются по результатам триангуляции. Это позволяет:
— Оптимально формировать локальные связи между элементами данных, что критично для задач, связанных с обработкой геометрической информации, 3D-моделированием и реконструкцией поверхностей [8] [9].
— Избегать вырожденных связей: благодаря свойствам Делоне, связи между точками не образуют «тонких» треугольников, что улучшает устойчивость и качество передачи информации в графовых нейронных сетях [7] [5] [9].
— Улучшать структуру графа: например, в современных графовых нейросетях (GNN) триангуляция Делоне используется для «перестройки» исходного графа, чтобы бороться с такими проблемами, как over-squashing (сжатие информации) и over-smoothing (усреднение признаков) [9].
Пример: DeepDT
В работе DeepDT предлагается использовать триангуляцию Делоне для построения графа из облака точек, после чего нейросеть учится классифицировать тетраэдры (в 3D) как принадлежащие или не принадлежащие поверхности объекта. Признаки точек агрегируются по структуре, заданной триангуляцией Делоне, что позволяет учитывать сложные пространственные взаимосвязи и повышает качество реконструкции поверхности [8].
Алгоритмические детали
— Для построения триангуляции Делоне используются эффективные алгоритмы, такие как «разделяй и властвуй», инкрементальный подход с флипами рёбер и алгоритм Бойера–Уотсона [4] [6].
— В графовых нейросетях рёбра между вершинами определяются по результатам триангуляции, а не исходной топологии, что может существенно изменить характер распространения информации [9].
Кратко о преимуществах
— Максимизация минимального угла: избежание вырожденных треугольников [7] [5].
— Оптимальная локальная структура: эффективная агрегация информации между соседями [9].
— Гибкость: возможность применения в 2D, 3D и более высоких размерностях [4] [8].
Вывод:
Триангуляция Делоне в нейросетях — это инструмент для построения эффективных и устойчивых графовых структур, особенно актуальный для задач, связанных с геометрией, 3D-реконструкцией и обработкой облаков точек. Она позволяет формировать связи между элементами данных с учётом их пространственного расположения, что улучшает качество обучения и итоговых результатов моделей [8] [9].
⁂
Как триангуляция Делоне помогает избегать «тонких» треугольников в нейросетях
Триангуляция Делоне помогает избегать «тонких» (узких, вытянутых) треугольников благодаря своему основному геометрическому свойству: она максимизирует минимальный угол среди всех углов всех построенных треугольников [10] [11] [12]. Это означает, что в любой другой возможной триангуляции для того же набора точек самый маленький угол не будет больше, чем в триангуляции Делоне. Такой подход препятствует появлению треугольников с очень малыми углами, то есть «тонких» треугольников, которые могут негативно сказаться на точности и устойчивости вычислений в нейронных сетях, особенно при работе с геометрическими или графовыми структурами.
В нейросетях это свойство важно, потому что «тонкие» треугольники приводят к неравномерному распределению соседей и могут ухудшать агрегацию признаков между вершинами, а также увеличивать численные ошибки. Триангуляция Делоне, избегая таких треугольников, обеспечивает более равномерную и устойчивую структуру связей между узлами, что положительно сказывается на качестве передачи информации и обучении моделей [10] [11] [12].
⁂
Реализация осцилляторной хаотической нейронной сети с применением технологии NVIDIA CUDA для решения задач кластеризации
Осцилляторные хаотические нейронные сети (ОХНС) — это класс искусственных нейронных сетей, в которых динамика отдельных нейронов описывается осцилляторными (колебательными) и хаотическими процессами. Такие сети особенно эффективны для задач кластеризации, поскольку способны выявлять сложные структуры данных за счёт синхронизации и десинхронизации нейронов.
Особенности реализации на NVIDIA CUDA
— Параллелизация вычислений: CUDA позволяет эффективно распараллеливать вычисления, связанные с динамикой большого числа осцилляторов, что критично для моделирования хаотических нейронных сетей большого размера [13] [14] [15].
— Организация потоков: Для вычисления выходных значений нейронов и матрицы синхронизации используются различные схемы потоков (X-flow, Y-flow). Оптимальным признано использование числа потоков, не превышающего половину максимального количества потоков видеокарты, что обеспечивает минимальное время расчёта [13] [14].
— Буферизация и память: Для хранения матрицы синхронизации предложены различные варианты размещения данных в памяти с учётом размера сети, что позволяет эффективно использовать ресурсы видеокарты [13] [14].
— Анализ результатов: Синхронизация между нейронами анализируется с помощью неориентированных графов и систем непересекающихся множеств, что позволяет выделять кластеры в данных [13] [14].
Этапы решения задачи кластеризации
— Инициализация сети: Задание параметров осцилляторов и начальных условий.
— Параллельное моделирование динамики: На каждом временном шаге вычисляются состояния осцилляторов и их взаимодействия с помощью CUDA-ядер.
— Вычисление матрицы синхронизации: Определяются пары нейронов, находящихся в синхронизированном состоянии.
— Выделение кластеров: На основе анализа синхронизации формируются кластеры — группы нейронов, осциллирующих согласованно.
— Постобработка: Кластеры сопоставляются с исходными данными для интерпретации результатов.
Практическая значимость
Реализация ОХНС на GPU позволяет:
— Существенно ускорить обработку больших объёмов данных за счёт массового параллелизма [13] [14] [15].
— Эффективно решать задачи кластеризации, особенно в случаях сложных, нелинейных и разнородных данных, где классические методы могут быть неэффективны [16].
— Применять различные алгоритмические и структурные решения для оптимизации работы сети и использования памяти GPU [13] [14].
Вывод:
Реализация осцилляторной хаотической нейронной сети с использованием технологии NVIDIA CUDA обеспечивает высокую производительность и эффективность при решении задач кластеризации, особенно для сложных и больших наборов данных. Такой подход сочетает преимущества хаотических динамик для выявления сложных структур и параллельных вычислений для ускорения обработки [13] [14] [15] [16].
⁂
Анализ метода осцилляторной хаотической нейронной сети с использованием CUDA для решения проекционных задач
Суть метода
Метод основан на использовании осцилляторной хаотической нейронной сети (ОХНС), реализованной с применением технологии NVIDIA CUDA для ускорения вычислений. ОХНС — это однослойная, рекуррентная, полносвязная сеть, где динамика нейронов описывается логистическим отображением, а результат кластеризации выявляется по синхронизации выходных сигналов нейронов во времени. Для повышения производительности и возможности применения к большим данным сеть реализуется на GPU с использованием CUDA [17] [18] [19] [20].
Алгоритм работы с учетом проекционных задач
— Подготовка данных и проекционные преобразования
— Входные данные представляют собой множество точек, которые могут быть заранее спроецированы в нужное пространство (например, при решении задачи понижения размерности или поиска кластеров в проекциях).
— Построение триангуляции Делоне
— Для определения топологии связей между нейронами используется триангуляция Делоне. Она позволяет выявить локальные соседства между точками в проекции, что особенно важно для корректного учета геометрических отношений в проекционном пространстве. Масштабирующая константа для весов связей также вычисляется на основе триангуляции [17].
— Формирование весовой матрицы
— Весовые коэффициенты между нейронами рассчитываются по формуле с учетом евклидовых расстояний между точками (нейронами) и масштабирующей константы, полученной из триангуляции. Это обеспечивает чувствительность сети к пространственным отношениям между точками в проекции.
— Параллельное моделирование динамики сети
— Вычисления динамики нейронов (их выходных значений на каждом шаге) и анализ синхронизации между ними реализуются на GPU с помощью CUDA. Используются разные схемы организации потоков (X- и Y-потоки) для оптимизации работы в зависимости от размера сети и возможностей видеокарты. Это позволяет эффективно обрабатывать большие проекционные задачи [17] [18] [19] [20].
— Анализ синхронизации и выделение кластеров
— После завершения итераций анализируется матрица синхронизации между нейронами. С помощью методов теории графов (поиск компонент связности) или системы непересекающихся множеств выделяются кластеры синхронизированных нейронов, что соответствует группам точек в проекционном пространстве.
Преимущества метода для проекционных задач
— Учет локальной геометрии: Использование триангуляции Делоне обеспечивает корректное выявление локальных соседств в проекциях, что критично для сложных многомерных данных.
— Высокая производительность: Реализация на CUDA позволяет значительно ускорить обработку больших массивов данных, что важно для проекционных задач с большим числом точек.
— Гибкость: Метод не требует априорной информации о числе кластеров и может применяться к данным любой размерности (при условии корректной проекции и построения триангуляции).
— Устойчивость к шуму: Хаотическая динамика и анализ синхронизации делают метод устойчивым к выбросам и сложным структурам в данных.
Ограничения и особенности
— Вычислительная сложность: Несмотря на ускорение с помощью GPU, для очень больших сетей (десятки тысяч нейронов) требуется значительный объем памяти и продуманная буферизация.
— Ограничения триангуляции: Алгоритмы триангуляции (например, quickhull) могут быть ограничены размерностью данных и требуют предварительной обработки на CPU.
— Пороговые параметры: Для выделения кластеров требуется настройка порогов синхронизации, что может влиять на результаты в зависимости от структуры проекционных данных.
Практическая эффективность
Экспериментальные результаты показывают, что реализация ОХНС на CUDA обеспечивает ускорение вычислений в 6–8 раз по сравнению с оптимизированными CPU-реализациями, а для больших сетей — до 68 раз. Таким образом, метод является эффективным инструментом для решения проекционных задач кластеризации, особенно при работе с большими и сложными данными [17] [18] [19] [20].
Вывод:
Метод осцилляторной хаотической нейронной сети с аппаратным ускорением на CUDA и использованием триангуляции Делоне хорошо подходит для решения проекционных задач кластеризации. Он учитывает пространственные отношения между точками в проекциях, эффективно выделяет кластеры и масштабируется на большие объемы данных за счет параллельных вычислений [17] [18] [19] [20].
⁂
Основная литература и статьи по теме осцилляторных хаотических нейронных сетей и их реализации на NVIDIA CUDA для кластеризации
Классические и обзорные статьи
— Angelini L. et al. «Clustering Data by Inhomogeneous Chaotic Map Lattices.» Physical Review Letters, 2000, no. 85, pp. 78–102.
— Оригинальная работа, в которой впервые предложена модель осцилляторной хаотической нейронной сети (ОХНС) для задач кластеризации данных [21] [22].
— Бендерская Е. Н., Толстов А. А. «Реализация осцилляторной хаотической нейронной сети с применением технологии NVIDIA CUDA для решения задач кластеризации.» Информационно-управляющие системы, №4, 2014, с. 94–101.
— Подробное описание алгоритмов, архитектурных решений и результатов аппаратной реализации ОХНС на GPU с использованием CUDA. В статье приведены результаты тестирования, рекомендации по оптимизации и анализ эффективности метода [21] [23] [22] [24].
— Benderskaya E. N., Zhukova S. V. «Oscillatory Neural Networks with Chaotic Dynamics for Cluster Analysis Problems.» Нейрокомпьютеры: разработка, применение, 2011, №7, с. 74–86.
— Рассматриваются теоретические основы и практические аспекты применения хаотических осцилляторных нейронных сетей для кластеризации [21].
— Benderskaya E. N., Zhukova S. V. «Nonlinear Approaches to Automatic Elicitation of Distributed Oscillatory Clusters in Adaptive Self-Organized System.» In: Distributed Computing and Artificial Intelligence (DCAI — 2012), Advances in Intelligent and Soft Computing, vol. 151, Springer, 2012, pp. 733–741.
— Описаны нелинейные методы самоорганизации кластеров на основе осцилляторных сетей [21].
Аппаратные и программные аспекты
— Benderskaya E. N., Tolstov A. A. «Trends of Hardware Implementation of Neural Networks.» Научно-технические ведомости СПбГПУ. Информатика. Телекоммуникации. Управление, 2013, №3 (174), с. 9–18.
— Обзор тенденций и проблем аппаратной реализации нейросетей, включая ОХНС [21].
— Benderskaya E. N. «Perspective and Problems of Parallel Computing Based on Non-Linear Dynamic Elements.» Суперкомпьютеры, 2013, №1 (13), с. 40–43.
— Анализ проблем параллельных вычислений с использованием нелинейных динамических элементов [21].
— Liang L. «Parallel Implementation of Hopfield Neural Networks on GPU.» 2011.
— Описывает параллельные реализации нейронных сетей на GPU, что релевантно для ОХНС [21].
— NVidia C Best Practices Guide. Design Guide. DG-05603-001_v5.5. July 2013.
— Практическое руководство по эффективному использованию CUDA для вычислений на GPU [21].
Новейшие исследования и аппаратные реализации
— SPbPU EL — Хаотический осциллятор для нейронных сетей. 2023.
— Диссертационная работа по разработке и моделированию аппаратной реализации хаотической осцилляторной нейронной сети для задач кластеризации, включая программные инструменты и тестирование на реальных данных [25].
— Hardware Implementation of Differential Oscillatory Neural Networks (DONNs) with VO₂-based Devices. Frontiers in Neuroscience, 2021.
— Современные аппаратные решения на базе новых материалов и мемристоров для построения осцилляторных нейросетей, анализ устойчивости и синхронизации [26].
Дополнительные источники
— Ultsch A. «Clustering with SOM: U*C.» Proc. Workshop on Self-Organizing Maps, Paris, France, 2005, pp. 75–82.
— Сравнительный анализ методов кластеризации, включая самоорганизующиеся карты [21].
— Sørensen H. H. B. «High-Performance Matrix-Vector Multiplication on the GPU.» Proc. of Euro-Par 2011 Workshops. Lecture Notes in Computer Science, vol. 7155, Springer, 2012, pp. 377–386.
— Описывает эффективные методы вычисления на GPU, применимые для реализации нейросетей [21].
Примечание:
Подробные описания и алгоритмы реализации осцилляторных хаотических нейронных сетей на CUDA, а также анализ производительности и рекомендации по оптимизации можно найти в статье Бендерской Е. Н. и Толстовой А. А., доступной в открытом доступе [21] [23] [22] [24].
⁂
Литература и статьи по проекционным методам в нейросетях
1. Проекционные нейронные сети и нейронные сети с обучением проекций
— Sujith Ravi. «ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections.»
— Описан новый архитектурный подход, в котором компактные нейронные сети обучаются с помощью проекционных операций (random projections, locality sensitive hashing). Метод позволяет значительно уменьшить размер и вычислительную сложность моделей при сохранении высокой точности, что особенно актуально для мобильных и встроенных устройств [27] [28].
— Sujith Ravi. «Efficient On-Device Models using Neural Projections.»
— Proceedings of the 36th International Conference on Machine Learning, PMLR 97:5370—5379, 2019
— В статье подробно рассматриваются методы построения компактных нейросетей с помощью проекций, их обучение и экспериментальные результаты на задачах визуальной и текстовой классификации [28].
2. Проекционные методы для снижения размерности и обучения представлений
— Обзор по обучению представлений (representation learning) и методам понижения размерности
— Яндекс Образование: Обучение представлений
— Рассматриваются методы снижения размерности, такие как SVD, autoencoder, PCA, и их связь с нейросетями. Описывается, как современные нейросети автоматически строят эффективные проекционные представления данных для последующего решения целевых задач [29].
— Обзор автокодировщиков для проекций и снижения размерности
— Habr: Обзор применений автокодировщиков
— Статья объясняет, как автокодировщики (autoencoders) используются для построения проекций и снижения размерности, а также для предобучения глубоких сетей. Приведены примеры визуализации проекций документов с помощью автокодировщика и LSA [30].
3. Классические источники по архитектурам и обучению нейросетей
— Учебник: «Искусственные нейронные сети и их приложения»
— В учебнике подробно рассматриваются многослойные персептроны, embedding-слои, рекуррентные и LSTM-сети, а также методы векторизации и проекций признакового пространства для различных задач анализа данных [31].
4. Применение проекционных методов в компьютерном зрении и глубоком обучении
— Rajaligappa Shanmugamani. «Deep Learning for Computer Vision.»
— Книга содержит современные методы обработки изображений с помощью сверточных сетей, включая техники предобработки, снижения размерности и построения признаковых проекций для повышения эффективности и точности моделей [32].
Краткий список ключевых публикаций:
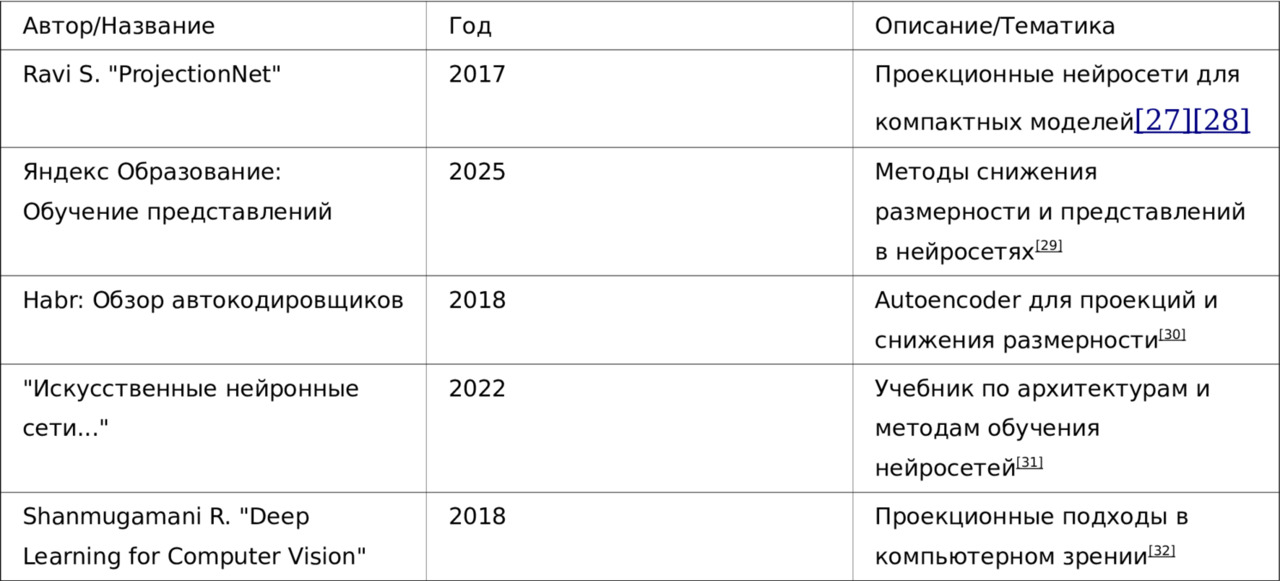
Эти источники охватывают теорию и практику проекционных методов в нейросетях, включая современные архитектуры, методы снижения размерности, обучение представлений и компактные модели для устройств с ограниченными ресурсами.
⁂
Какие статьи подробно описывают применение CUDA для осцилляторных нейросетей
Наиболее подробное и практически ориентированное описание применения технологии NVIDIA CUDA для реализации осцилляторных хаотических нейронных сетей содержится в следующих публикациях:
1. Бендерская Е. Н., Толстова А. А. «Реализация осцилляторной хаотической нейронной сети с применением технологии NVIDIA CUDA для решения задач кластеризации»
Информационно-управляющие системы, №4, 2014, с. 94–101.
— В статье подробно рассматриваются:
— архитектура осцилляторной хаотической нейронной сети (ОХНС),
— особенности параллельной реализации на GPU с использованием CUDA,
— алгоритмы вычисления выходных значений нейронов с разными паттернами доступа к памяти,
— варианты организации вычислений (X-flow, Y-flow, поток на нейрон),
— оптимизация хранения матрицы синхронизаций и буферизации,
— анализ производительности и рекомендации по выбору схемы параллелизма в зависимости от размера сети и возможностей GPU.
— Приводятся результаты тестирования и сравнения с CPU, а также практические рекомендации для реализации ОХНС на современных видеокартах NVIDIA [33] [34] [35] [36].
2. Benderskaya E. N., Tolstov A. A. «Hardware Implementation of a Chaotic Oscillatory Neural Network by NVidia CUDA Technology»
Information and Control Systems, 2014, No. 4, pp. 94–101.
— Англоязычная версия вышеуказанной статьи, доступная в открытом доступе, содержит подробное описание алгоритмов, архитектурных решений и результатов тестирования, а также ссылки на исходный код реализации [34] [35].
Дополнительные статьи, упомянутые в библиографии:
— Benderskaya E. N., Zhukova S. V. «Oscillatory Neural Networks with Chaotic Dynamics for Cluster Analysis Problems.»
— Нейрокомпьютеры: разработка, применение, 2011, №7, с. 74–86.
— Описывает теоретические основы и практические аспекты применения хаотических осцилляторных сетей для кластеризации.
— Benderskaya E. N., Zhukova S. V. «Nonlinear Approaches to Automatic Elicitation of Distributed Oscillatory Clusters in Adaptive Self-Organized System.»
— Distributed Computing and Artificial Intelligence (DCAI — 2012), Advances in Intelligent and Soft Computing, vol. 151, Springer, 2012, pp. 733–741.
— Рассматривает методы самоорганизации кластеров на основе осцилляторных сетей.
Ссылки на публикации:
— PDF-версия основной статьи (русский и английский текст) [33] [34] [35]
— Статья на сайте журнала [34] [35]
— Краткое описание и выводы на CyberLeninka [36]
Вывод:
Для глубокого изучения реализации осцилляторных нейросетей на CUDA рекомендуется ознакомиться с работой Бендерской и Толстовой (2014), где приведены все необходимые алгоритмы, схемы оптимизации и результаты тестирования на реальных GPU [33] [34] [35] [36].
⁂
ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections
ProjectionNet — это архитектура для обучения компактных нейронных сетей, оптимизированных для выполнения на устройствах с ограниченными вычислительными ресурсами (например, мобильные телефоны, умные часы, IoT), при этом обеспечивается высокая точность и минимальный объем памяти [37] [38] [39] [40].
Ключевые идеи и архитектура
— Совместное обучение двух сетей:
— ProjectionNet использует совместную оптимизацию двух моделей:
— Полноценная (trainer) нейронная сеть — может быть любой современной архитектурой (feed-forward, LSTM, CNN и др.), обучаемой на стандартных данных.
— Проекционная (projection) сеть — компактная сеть, которая использует случайные проекции (например, locality-sensitive hashing, LSH), чтобы преобразовывать входные данные или промежуточные представления в компактные бинарные векторы.
— Обучение с «наставничеством»:
— Обе сети обучаются одновременно с помощью backpropagation, где проекционная сеть учится воспроизводить поведение большой сети, аналогично подходам «аппрентисшип-обучения» (apprenticeship learning). После обучения для инференса используется только компактная проекционная сеть [37] [38] [39] [40].
— Проекции и бинаризация:
— Проекционная сеть применяет параметризованные случайные проекции для получения битовых представлений скрытых слоев. Это позволяет существенно уменьшить число параметров и объем памяти, необходимый для хранения модели, а также ускорить вычисления за счет простых операций в битовом пространстве [38] [39] [40].
Преимущества и особенности
— Минимальный объем памяти:
— Модели ProjectionNet могут быть на порядок меньше по размеру, чем исходные сети, что позволяет запускать их на устройствах с ограниченными ресурсами без потери качества [37] [38] [39].
— Гибкость и масштабируемость:
— Проекционная сеть может быть обучена с нуля или «учиться» у уже обученной большой сети. Размер и сложность проекционной сети настраиваются под конкретную задачу или устройство [39] [41].
— Универсальность:
— Подход применим к различным типам задач — от визуального распознавания до обработки текста и речи. Эксперименты показывают, что ProjectionNet сохраняет высокую точность при значительном сокращении размера модели [38] [39] [40].
— Применение в реальных продуктах:
— ProjectionNet используется для создания полностью on-device моделей, например, для Smart Reply на Android-устройствах, где важны приватность и скорость работы [42].
Технические детали
— Проекционные функции:
— Используются модифицированные версии LSH для формирования битовых векторов скрытых слоев. Можно комбинировать с другими операциями (например, свертками) для гибкости архитектуры [39] [43].
— Обучение:
— Совместная оптимизация обеих сетей происходит end-to-end, что позволяет проекционной сети эффективно перенимать знания от большой сети [37] [38] [39].
— Экспериментальные результаты:
— ProjectionNet показывает значительное уменьшение размера моделей (до 100 раз) при сохранении конкурентной точности на задачах классификации изображений и текста [39] [40].
Основные публикации
— Sujith Ravi. «ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections.» arXiv:1708.00630 (2017) [37] [40].
— Sujith Ravi. «Efficient On-Device Models using Neural Projections.» Proceedings of ICML 2019 [39] [43] [41].
Вывод:
ProjectionNet — это современный подход к созданию компактных и быстрых нейронных сетей для выполнения на устройствах с ограниченными ресурсами. Он основан на совместном обучении большой и проекционной сети, где последняя использует случайные проекции и битовые представления для существенного сокращения размера модели без значительных потерь в точности [37] [38] [39] [40].
⁂
Найди литературу на данную тему
Для изучения темы ProjectionNet и применения нейронных проекций для построения эффективных компактных моделей, оптимизированных для работы на устройствах с ограниченными ресурсами, рекомендуется следующая ключевая литература:
Основная статья
— Sujith Ravi. «ProjectionNet: Learning Efficient On-Device Deep Networks Using Neural Projections.»
— Полный текст статьи (arXiv:1708.00630v2, PDF) [44]
— В работе описана архитектура ProjectionNet — совместное обучение большой (trainer) и компактной (projection) нейронной сети, где последняя использует случайные проекции и битовые представления для существенного уменьшения размера модели. Подробно рассмотрены алгоритмы обучения, применение locality-sensitive hashing (LSH) для проекций, экспериментальные результаты на задачах классификации изображений (MNIST, CIFAR-100) и текста, а также анализ компромисса между размером модели и точностью.
Краткое описание статьи
— Введение в проблему: сложности применения больших нейросетей на мобильных и IoT-устройствах из-за ограничений по памяти, вычислениям и приватности.
— Предложенное решение: совместное обучение двух сетей, где компактная projection-сеть учится воспроизводить поведение большой сети с помощью случайных проекций и бинаризации скрытых слоёв.
— Технические детали: использование LSH для формирования битовых векторов, совместная оптимизация с помощью backpropagation, возможность настройки размера и сложности модели.
— Эксперименты: значительное уменьшение размера модели (до 100 раз и более) при сохранении высокой точности на ряде задач.
— Практическая значимость: ProjectionNet позволяет реализовывать эффективные, быстрые и приватные on-device модели для задач компьютерного зрения и обработки текста.
Рекомендуется ознакомиться с оригинальной статьёй для получения полного представления о теории, реализации и практических результатах ProjectionNet [44].
⁂
Locality-Sensitive Hashing (LSH): Краткое описание и применение
Locality-sensitive hashing (LSH) — это вероятностный метод понижения размерности и ускорения поиска похожих (similar) объектов в высокоразмерных пространствах, широко используемый для задач приближённого поиска ближайших соседей (Approximate Nearest Neighbor, ANN) [45] [46] [47].
Основная идея
В отличие от традиционных хеш-функций, которые стремятся равномерно распределять объекты по корзинам (buckets), LSH специально подбирает семейство хеш-функций так, чтобы схожие объекты с высокой вероятностью попадали в одну и ту же корзину, а далекие — в разные [45] [46]. Это позволяет быстро находить кандидатов на совпадение без необходимости полного перебора всех пар объектов.
Как работает LSH
— Выбор семейства хеш-функций: Для каждого типа метрики (например, евклидова, косинусная, Жаккара) существуют свои семейства LSH-функций. Например, для косинусного сходства используются случайные проекции [48] [49].
— Генерация нескольких хеш-таблиц: Для повышения точности используется несколько независимых хеш-таблиц, каждая из которых строится на основе случайного набора хеш-функций [46].
— Хеширование объектов: Каждый объект многократно хешируется, формируя битовые подписи (signature). Похожие объекты с большой вероятностью будут иметь совпадающие подписи хотя бы в одной таблице.
— Поиск кандидатов: Для поиска ближайших соседей достаточно сравнить только объекты, попавшие в те же корзины, что и запрос, что резко снижает число сравнений [49] [45].
Математическая формализация
Семейство хеш-функций называется locality-sensitive, если для выбранной метрики выполняются условия:
— Для похожих объектов вероятность попасть в одну корзину высока.
— Для непохожих — вероятность низка [49] [45].
Применение
— Поиск ближайших соседей в больших и высокоразмерных данных (изображения, тексты, аудио, векторы признаков) [50] [49] [51] [52].
— Дедупликация и поиск дубликатов (например, веб-страниц, документов, аудиофайлов) [52].
— Аудио- и видео-фингерпринтинг (например, Shazam) [51].
— Рекомендательные системы, биоинформатика, кластеризация и др. [47] [53].
Пример использования в нейронных сетях
В архитектуре ProjectionNet LSH применяется для проецирования входных данных или скрытых представлений в компактные битовые векторы. Это позволяет строить сверхкомпактные модели, которые можно эффективно запускать на устройствах с ограниченными ресурсами [48]. В ProjectionNet LSH-матрица фиксируется до обучения, и проекции вычисляются как знаки скалярных произведений между входным вектором и случайными векторами из LSH-семейства, что гарантирует, что схожие объекты будут иметь схожие битовые подписи [48].
Ключевые преимущества LSH
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.