
Бесплатный фрагмент - Power Query: учебное руководство
От новичка до уверенного бизнес-пользователя
ВВЕДЕНИЕ
Предисловие
Вы держите в руках уникальную книгу.
В первую очередь она уникальна тем, что написана нашим соотечественником — экспертом по анализу данных, прогностической аналитике, Data Science и AI. Это одна из первых книг «отечественного производства», раскрывающая возможности использования ETL-инструментария Power Query.
Несомненно, книга привлечет внимание аналитиков и техническим специалистов. Но ее вторая уникальность в том, что она понятная и прикладная даже для обычных бизнес-пользователей.
Книга фокусируется на работе с пользовательскими интерфейсами (вкладки, кнопки, опции) — без погружения в язык М. И обычный бизнес-пользователь офисного приложения Excel сможет сразу использовать полученные знания на практике.
В-третьих, книга покрывает пользовательский функционал Power Query, которого достаточно для решения минимум 95% решаемых бизнес-пользователями задач в части подключения к разным источникам, преобразования, загрузки данных и обновления данных.
Но даже если Вы просто интересуетесь темой анализа данных — изложенный в книге материал будет полезен с точки зрения понимания «всей этой аналитической кухни».
Увлекательного Вам чтения!
От автора
Моя деятельность уже более 20 лет связана с анализом данных — от простых математических вычислений в Excel — до разработки моделей машинного обучения и применения методов прогностической аналитики. При этом я не ИТ специалист и не инженер — я управляю проектами преобразований крупных организаций, меняю их бизнес- и операционные модели.
Но без качественного анализа данных невозможно провести ни один трансформационный проект — и неважно касается он организации, общества и т. д. Поэтому все проекты начинаются со сбора и анализа данных, поиска зависимостей и закономерностей, моделирования и прогнозирования.
Поэтому неважно какую должность Вы занимаете и какой род Вашей деятельности: в современном мире в любой профессии Вы ежедневно сталкиваетесь с цифрами и данными как минимум на уровне подготовки регулярной отчетности.
Обратите внимание на свою работу и присутствие в ней работы с данными. Скорее всего Вы лично или Ваши подчиненные запрашиваете или выгружаете данные из разных систем, сводите в одну таблицу, обрабатываете и «чистите» их, проводите необходимые вычисления, пытаетесь обобщить, провести нужные вычисления, визуализировать и т.д.. А потом еще добиваетесь вывода этого всего на уровень регулярной отчетности с регулярным (еженедельным, ежемесячным или ежеквартальным) обновлением…
И делаете это скорее всего в самых популярных инструментах работы с данными в корпоративном мире — офисном приложении Microsoft Excel или «набирающей обороты» программе Power BI.
Но чтобы начать обработку, анализ и визуализацию данных в Excel или Power BI — сначала предстоит долгий и мучительный путь выгрузки данных из корпоративных систем, баз данных, приложений и т. д. В корпорациях это зачастую требует вовлечения ИТ-специалистов или аналитиков, умеющих писать запросы на SQL. А потом еще и регулярно просить их обновить данные (или «приделать где-нибудь кнопку, которая будет выгружать обновленный отчет»).
Но все начало меняться с 2010 года, когда к Excel вышла надстройка Power Query. На сегодня она уже является полноценным ETL-инструментом: это мощная технология подключения к источникам, извлечения из них данных, преобразования в массивы и очистки для дальнейшего анализа.
Благодаря Power Query Вы даже на уровне простого бизнес-пользователя сможете без привлечения ИТ-специалистов и аналитиков:
— подключиться к источникам данных (в виде файлов и баз данных различных систем);
— настроить шаги преобразования и чистки данных;
— регулярно или по необходимости обновлять все свои таблицы, отчеты и дашборды нажатием одной клавиши мыши.
И эта книга — это Ваша возможность попробовать «на вкус и ощупь» ETL-инструмент Power Query, который позволяет загружать данные в Excel, Power BI и Analysis Services.
Естественно, вместить все в одну книгу невозможно. Но в ней отобраны самые необходимые знания для полноценной работы с Power Query и в Excel, и Power BI.
Для демонстрации ключевых возможностей программ отобраны понятные даже новичку примеры. А чтобы книга была прикладного характера — к важнейшим главам прилагаются ЛИСТЫ ПРАКТИКИ, по которым читатели могут отрабатывать основные моменты работы Power Query в Excel и Power BI.
Если после прочтения книги Вам захочется увидеть, как Power-надстройки к Excel и программа Power BI работают «вживую» с загруженными с помощью Power Query данными, а также своими руками выполнить практические упражнения — регистрируйтесь на онлайн курсы на платформе STEPIK или UDEMY:
· Power BI — от новичка до уверенного бизнес-пользователя
· Excel Power Query и Pivot: с 0 до бизнес-пользователя
Даже если Вы просто взяли полистать эту книгу любопытства ради, но работа с данными совершенно не из области Вашего интереса — то книга все-равно попала в Ваши руки не зря. Наверняка у Вас есть знакомые, которым она будет полезной — поделитесь с ними информацией об этой книге.
Увлекательного Вам чтения!
Структура книги
Книга нацелена на освоение основных функционалов ETL-инструмента Power Query
Но в самом вначале книги я сначала расскажу о способах организации данных в виде таблиц, понятии массивов данных, переменных и объектах\наблюдениях, типах данных — в общем о том, с чем доведется работать в любой аналитической программе. Именно с массивами работают даже продвинутые инструменты прогностической аналитики (типа SPSS, Statistica, JASP и т.д.). Если Вы не новичок и все это прекрасно знаете — можете пропустить это раздел.
Потом мы подготовим рабочее пространство (необходимые инструменты), познакомимся с тем, что собой представляет «экосистема Power» (частью которой является Power Query) в целом и предназначение ее компонентов. И отдельно скажу о том, как это все работает вместе Если Вам это все также известно — можете смело пропускать.
После знакомства с предназначением и общей логикой работы компонентов мы более детально рассмотрим ETL-инструментарий Power Query, используемый для автоматизации процесса подключения к источникам, извлечения из них нужных данных, их чистки и преобразования — и загрузки в Excel и Power BI для анализа и визуализации, а также обновления данных нажатием одной кнопки.
В принципе вот такой достаточно простой, но интересный путь ждет готового последовать по нему читателя.
Как работать с книгой
Я слышу — и забываю,
Я вижу — и вспоминаю,
Я делаю — и понимаю.
Приписывают Конфуцию
Каждый раздел книги раздел устроен так, чтобы Вы не только ориентировались в наборе функционалов Power Query, а и легко соотносили их с решаемыми задачами в части загрузки и преобразования данных.
Тем бизнес-пользователям, кто хочет всерьез освоить работу в Power Query, а не просто прочесть «еще одну умную книгу» — настоятельно рекомендую сразу же после каждого практического раздела отрабатывать ЛИСТЫ ПРАКТИКИ.
Для этого у Вас «под рукой» должны быть:
— как минимум MS Excel с надстройкой Power Query, а в идеале программа Power BI Desktop (распространяемая в открытом доступе официальная программа Microsoft) — и по ходу работы с книгой Вы организуете себе такую рабочую среду;
— массивы данных в виде пары таблиц в Excel из Вашей профессиональной деятельности (или просто скачанные из сети интернет, или искусственно созданные Вами данные средствами Excel);
— любознательность и настойчивость в конвертировании прочитанного в прикладные знания.
Имея это, Вы сможете делать все то, о чем будет идти речь в книге собственными руками на практике. Ведь сама книга построена еще и как самоучитель — в ней описаны последовательные шаги работы и применения Power Query.
МАССИВ ДАННЫХ
Что такое массив
Как Вы уже знаете, для работы требуется структурированный в виде таблицы массив. Видов таблиц укрупнено есть два:
1) Сведенные таблицы. Используется для отчетности и визуализаций в программах MS Office. Пример на рис.1:
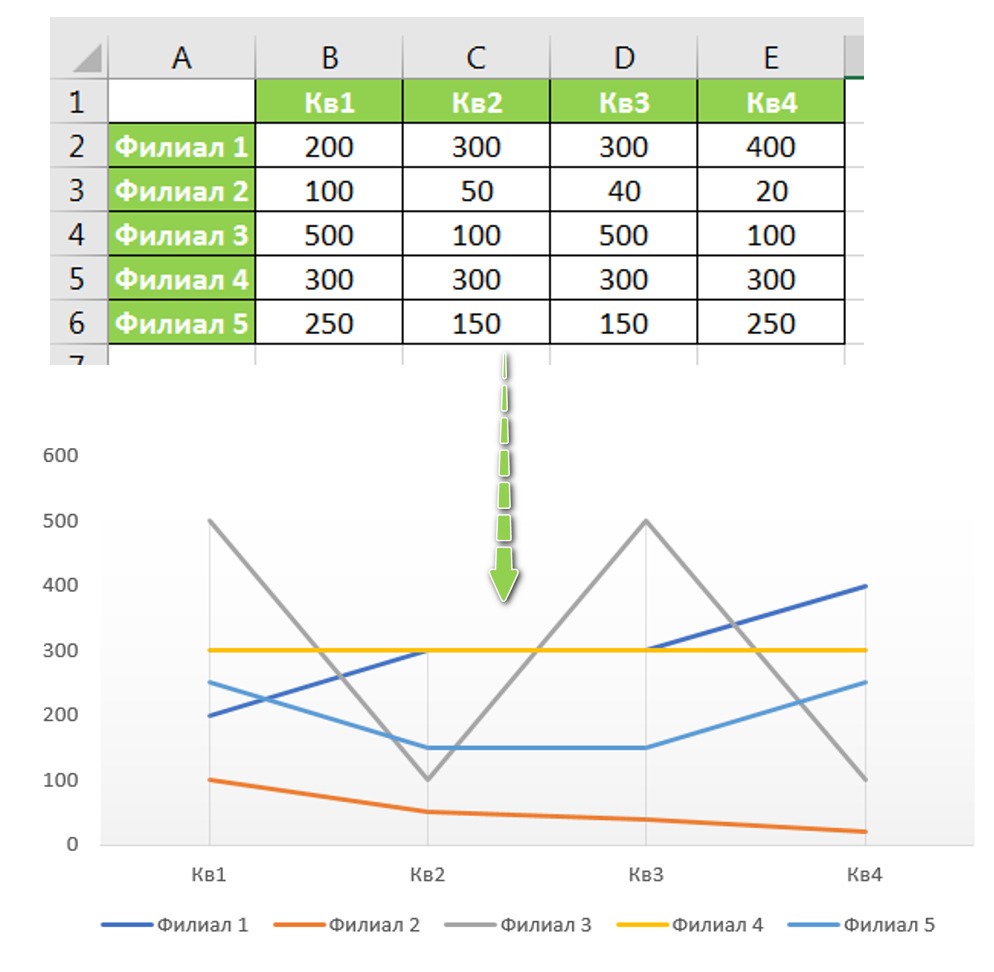
Наглядно выглядит — но это худший вариант для обработки и анализа данных. Это, по сути, уже обработанные (сведенные, агрегированные в разных разрезах) данные. Тем не менее в бизнесе циркулируют такие данные — и Вам буде доводиться работать и с такими таблицам.
Особенно когда данные существуют только в печатном виде без исходного массива или Вам их в телефонном режиме «надиктовал» коллега\руководитель\партнер.
2) Второй вариант: массив данных. Массивом для нас является «плоская» двумерная таблица (не сведенный отчет). В такой таблице:
— по строкам идут случаи\объекты\наблюдения для нашего анализа (компания, отдел, дата замера, человек, клиент, товар и т.д.),
— по столбцам\колонкам — параметры\признаки (называются «переменные») со значениями для случаев, объектов или процессов (ФИО, название компании, ID клиента, скорость, деньги, город или страна, отдел, род войск, зарплата, пол, частота курения и т. д.).
Если взять пример той же сведенной таблицы — то в виде массива она будет выглядеть так (рис.2):

Новичков в анализе данных (тех, кто просто до этого видел готовые отчеты) такой вид таблицы может «вогнать в ступор»: на предыдущем рисунке была нормальная понятная таблица, в которой можно было разобраться и что-то понять — а это что такое?
Но на самом деле это более удобное структурирование таблицы — из нее легко получать те самые сведенные отчеты в разных разрезах (как в виде сводных таблиц, так и диаграмм). И более того — такая таблица сможет ВЗАИМОДЕЙСТВОВАТЬ с другими таблицами путем установления с ними связей по общим переменным-идентификаторам («ключам»).
Если на этом этапе Вы еще не смогли понять важность именно такого структурирования данных — то просто пока поверьте.
А из этой главы вынесите то, что данные должны быть внесены в упорядоченную таблицу — и Вам до начала ввода данных надо эту таблицу уже представить в собственной голове. И моя рекомендация: всегда старайтесь получить массив — где по строкам указаны случаи\объекты (сотрудники, клиенты, предприятия, товары и т.д.), а по столбцам — переменные (их признаки или характеристики). Причем Power Query имеет встроенный механизм преобразования сведенных отчетов в массивы — но об этом поговорим позже.
Итак, надеюсь Вы уловили разницу между массивом данных и сведенным отчетом. И запомнили, что на выходе из Power Query должен получиться вычищенный и готовый к анализу массив данных, в котором по строкам идут объекты\наблюдения, а по столбцам — переменных\характеристики со своими значениями для каждого объекта.
Объекты (строки) в массиве
Итак, в массиве у нас по строкам идут объекты нашего анализа (еще их называют случаи или наблюдения). Это то, что мы анализируем и по чему собираем информацию. Это могут быть:
· люди
· клиенты
· посетители
· товары
· предприятия
· подразделения
· магазины
· дата замера \ получения показателя
· и т. д.
Например, если мы собираем информацию по продажам в городах — то объектами будут города.
Если по магазинам — то объектами будут магазины.
Если нас интересуют продажи по конкретным отделам в магазине — то это будут отделы.
А если интерес представляют продажи по конкретным продавцам-консультантам — то это будут ФИО конкретных продавцов-консультантов. Причем в массиве у каждого из них может присутствовать признак отдела и магазина, а также города, в котором магазин находится — и мы сможем при необходимости агрегировать\обобщить информацию о продажах и в разрезе магазина, и в разрезе отдела, и в разрезе городов.
Т.е., если Вас интересуют показатели магазинов (магазины — это объекты Вашего анализа), но Вы можете получить данные на более детализированном уровне (на уровне объектов в виде продавцов-консультантов) — то используйте максимально возможный детализированный уровень сбора информации, но содержащий нужные Вам признаки (в данном случае магазин, в котором продавец-консультант осуществлял продажу).
Это все сказано к тому, что наиболее желательно заполучить массив на максимально детализированном уровне объектов с необходимым набором признаков (переменных) для его укрупнения (обобщения, агрегации) в случае необходимости. Но об уровне детализации массива мы поговорим еще в отдельной главе.
Переменные (столбцы\колонки) в массиве
В отличии от Excel, работающего с каждой конкретной ячейкой, Power-надстройки и Power BI работают со столбцами целиком — т.е. с переменными.
Если у Вас случаи\объекты анализа — конкретные люди. То, например, цвет глаз у каждого человека будет свой. И цвет глаз — это переменная. А карие, голубые, зеленые и т. д. — это значения этой переменной у конкретного объекта.
Т.о., каждый случай\объект имеет своих характеристики, т.е., может принимать свое значение той или иной переменной.
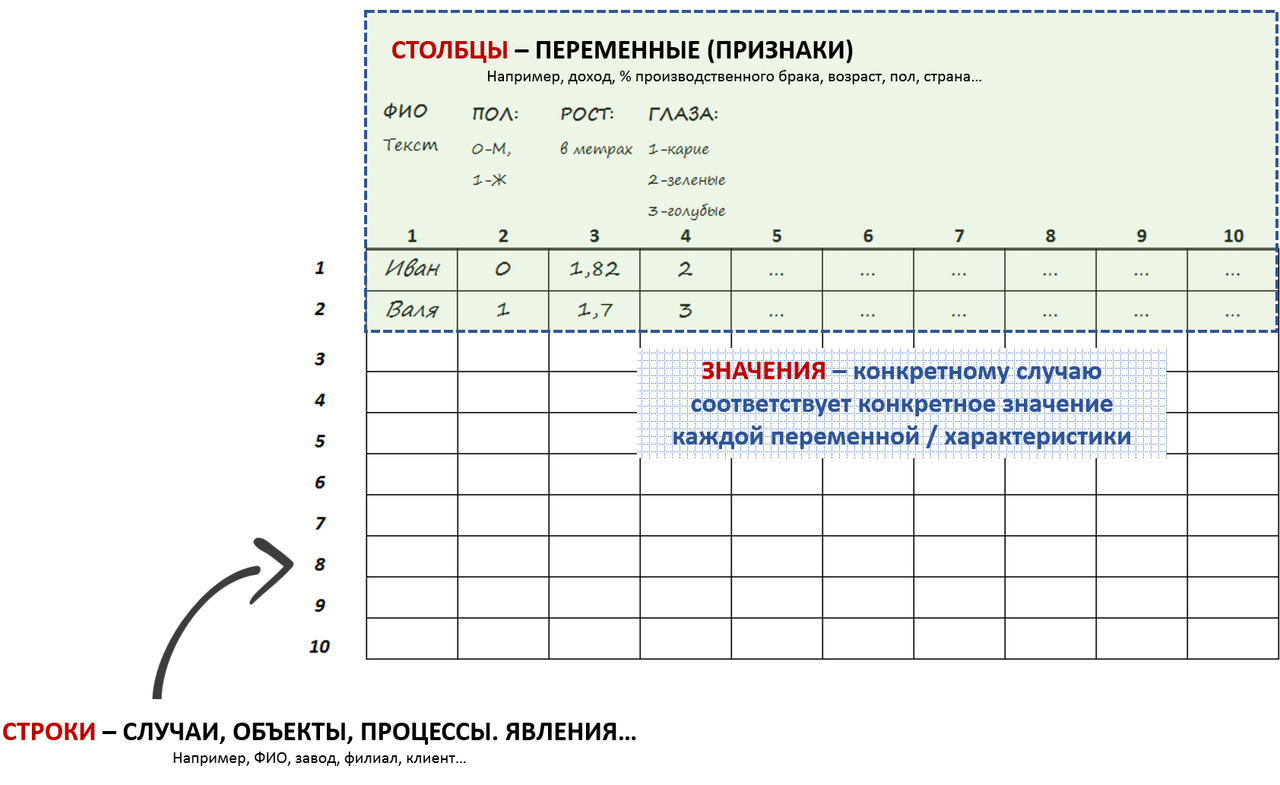
Например, рост Вали = 1,7 метра, а Ивана 1,82. У Вали глаза голубые, у Ивана — зеленые. Валя — женщина, а Иван — мужчина. Валя живет в Омске, Иван — в Москве. Месячный доход Вали — 80.000 руб, а Ивана — 200.000 руб. Вадя ездит на отдых за границу редко — раз в несколько лет, Иван часто — несколько раз в год.
Валя и Ваня — это наши объекты/случаи/наблюдения.
Рост, цвет глаз, доход, место проживания… — характеристики\признаки или переменные. См. рис. 3:

Вместо Вали и Ивана могут быть предприятия, товары. А в качестве переменных — доходы, объем производства и численность персонала для предприятий, или цена и количество проданных единиц товара.
В общем, по столбцам в массиве идут переменные, которые характеризуют наши объекты — и именно с переменными ведется работа в Power-надстройках и Power BI.
И каждая переменная принимает свое значение для конкретного объекта\наблюдения (рис.4), которые могут быть разными не только с т.з. самого значения переменной (например, голубой или зеленый цвет глаз), а и с т.з. шкал измерения переменных.
А какие бывают типы шкал для записи переменных — разберем в следующей главе.
Шкалы для измерения переменных
Обратим внимание, что каждая переменная (колонка\столбец) имеет свое значение для того или иного случая\объекта.
И значения переменных варьируются и отличаются от случая к случаю, от объекта к объекту. К примеру, цвет глаз может быть синим или зеленым; рост 1,7 и 1,82; пол — мужской или женский; доход 80.000 или 200.000 и т. д.
Т.е., каждое значение по конкретной взятой переменной соответствует его замеру у конкретного объекта.
Но также Вы наверняка заметили, что переменные могут быть измерены в разных шкалах.
Например, переменная «Пол» — измеряется по двоичной (бинарной) шкале: мужчина или женщина. Но могло бы быть записано и 0 и 1 или 1 и 0 — причем без разницы какому бы полу соответствовало бы значение 0, а какому 1.
А переменная «Доход», выраженная в рублях, может принимать большое количество разных значений — до копеек.
А вот переменная «Частота поездок за границу» уже не является такой точной как доход, но несет понимание порядка\частоты\интенсивности — часто-редко. Т.е., могут быть и шкалы просто несущие понимания нарастающего\убывающего порядка: часто-редко; много-мало; высоко-низко (например, частота курения, уровень дохода (низкий-средний-высокий), использования интернета, воинские звания).
Шкалы имеют разную информативность. К примеру, если доход записан в рублях до копеек — то мы можем более точно сказать, насколько различается зарплата одного и второго человека. А если зарплата записана как «низкая-средняя-высокая» — то мы можем судить о различиях в зарплате только относительно.
От того, какая шкала используется зависит также и то, как ее можно обработать, какие показатели по ней получить. К примеру, среднее из городов Вы не получите. И если присвоите городам цифровые значений (типа Омск = 1, Самара = 2 и т.д.) — то среднее значение из их цифровых кодов будет бессмысленным.
От типа шкалы зависит какие методы анализа к ней можно применять.
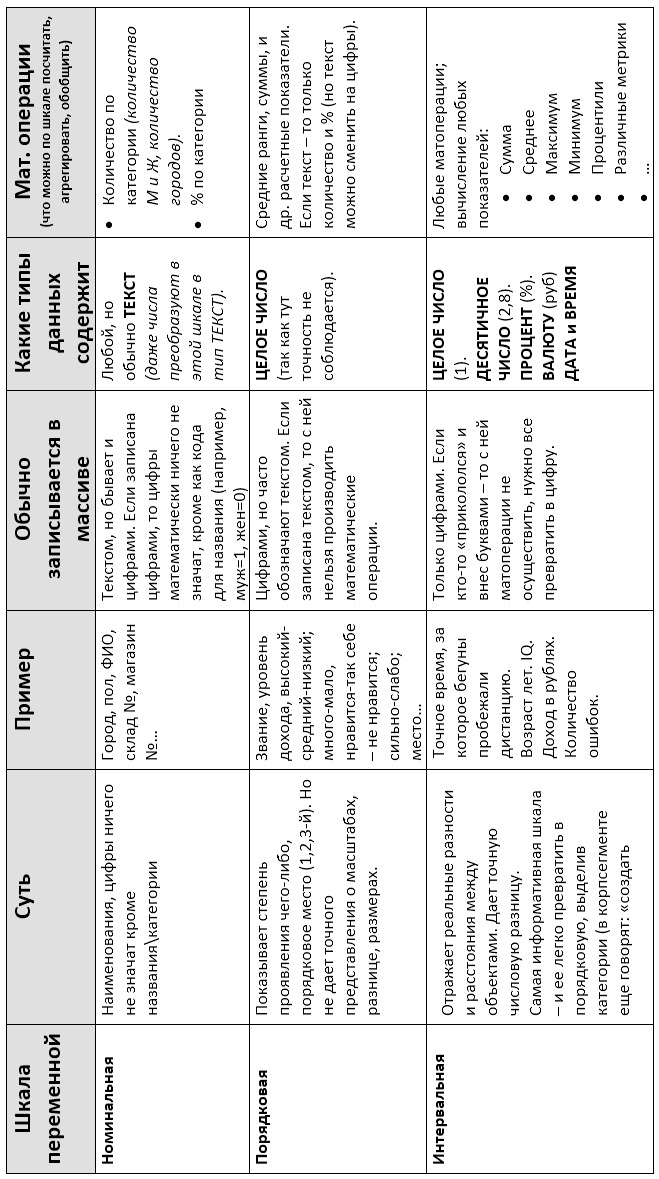
Статисты придумали разные шкалы, но их в целом можно объединить в три основных вида (рис.5), которые я приведу в порядке возрастания информативности и расскажу, что с ними можно делать.
Номинальная — например, пол, город, страна, семейное положение, политическая партия, ФИО кандидата в президенты. По сути, это шкала наименований и классификаций. С ней бессмысленно проводить какие-либо математические операции. Цифры в ней ничего не значат, или как говорят ученые не имеют эмпирического значения. Если, например, мы поставим 1 Уфе, а 2 — Самаре, это не означает, что Уфа на ступеньку ниже Самары. Мы можем даже поменять цифры между городами — это ничего не изменит.
Т.е., эта шкала всего лишь определяет принадлежность наблюдения \ случая \ объекта к какой-то группе\категории и позволяет классифицировать объекты. Тут мы можем посчитать только количество объектов в группе\категории. Например, количество или % мужчин и женщин. Или количество людей из разных стран. Или количество тех или иных профессий.
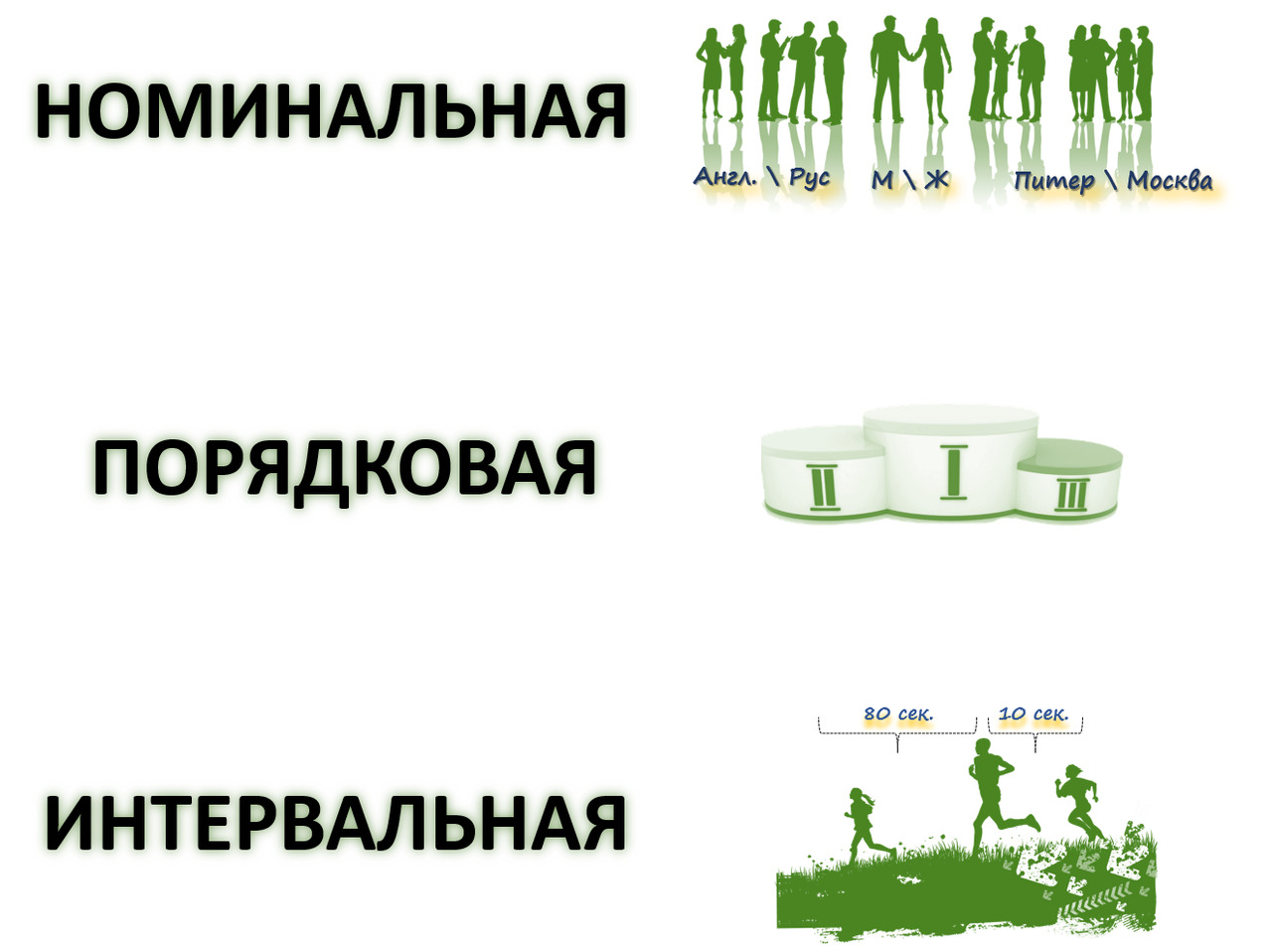
Второй тип шкал — порядковая или ранговая (еще ее называют «ординальная» от англ. order — порядок). Например, воинское звание, или место в организационной иерархии, или уровень образования. В эту шкалу закладывается некая степень проявления какого-то свойства между объектами, но непонятна ни его точность, ни расстояния между ними. Генерал выше полковника. Работа может быть интересна, безразлична или неинтересна. Занявший I место по бегу быстрее того, кто занял II и III (хотя разница в их абсолютном результате могла составлять между первым и вторым 5 секунд, а с третьим — более 2 минут).
Эту шкалу, как и номинальную, используют для классификации объектов и подсчета количества или %. Но по ней можно применять и ряд методов статистического анализа и поиска закономерностей — например, попробовать найти взаимосвязь между частотой использования мата и воинским званием.
Третий тип — интервальные шкалы (количественные или метрические). Если предыдущая порядковая шкала несла только информацию о порядке (рангах, порядке, месте) данных, то количественная — это числа, реально отражающие размерности, разности и расстояния между объектами.
Например, точное время за которое бегуны пробежали дистанцию. Возраст лет. IQ. Уровень лояльности или мотивации сотрудника. Доход.
С этими шкалами можно осуществлять любые виды анализа и вычисления. Более того, их можно легко превращать в порядковые, объединяя диапазоны значений. Например, доход можно разбить на 4 диапазона — низкий, средний, выше среднего и высокий.
Оговорюсь, что количественные (метрические) шкалы могут выглядеть по-разному:
— есть с отрицательными значениями (например, температура в градусах; прибыль; баланс на кредитке);
— есть с абсолютным нулем (например, возраст);
— есть те, которые в принципе не начинаются с нуля (например, IQ).
В разговорах аналитиков или в литературе их могут именовать по-разному (например, интервальная, шкала масштаба или шкала отношений с абсолютным нулем…) — но, по сути, все они с точки зрения использования методов аналитического инструментария одинаковы.
Вот такие три основные шкалы (номинальная, порядковая и интервальная) представления переменных. И неважно в какой программе Вы будете работать (Excel, Power BI или инструментах прогностической аналитики типа SPSS, JASP, SAS, Statistica…) — Вы всегда будете иметь дело с этими шкалами.
Типы данных
Вы уже знаете какие бывают шкалы для переменных. Но многие после знакомства с этими типами шкал немного теряются — а ведь есть %, есть тексты, есть даты и время, есть целые и дробные числа… Как оно все вписывается в эти шкалы?
Все это — является типами данных, которые присваиваются значениям переменных.
И типы данных бывают крупно 4 категорий:
· Числовые: целое число (например, пассажировместимость автобуса меряется в целых числах; экипаж танка — в целых числах); десятичное число (например, 19,3 см); валюта (например, 100$); проценты (50%).
· Дата и время (01.01.2001; 12:05)
· Текстовые
· Логический (ИСТИНА \ ЛОЖЬ)
Типы данных критически важны для вычислений и применения к ним функций\формул. Например, если Вы присвоите ТЕКСТОВЫЙ тип, то с ним нельзя будет производить математические операции — даже если внести данные по такой переменной в виде цифр.
Присваивать правильные типы данных для вычислений крайне важно и для Power Query, и для Power BI, и для Power Pivot. Как это сделать технически — мы будем проходить в практических разделах по работе с программами. Технически процедура не сложная, но для себя Вы должны понимать какой тип данных у Вас содержат ячейки со значениями по каждой переменной.
Требования к записи значений в массиве
Итак, Вы уже знаете:
— что нужно работать с упорядоченными в форме массива данных таблицами,
— что в массивах по строкам записываются объекты, а по столбцам переменные\признаки — и каждая переменная для каждого конкретного объекта имеет свое значение,
— о трех типах шкал измерения переменных — а также типах данных, которые могут быть присвоены значениям переменных.
А в этой главе еще поговорим о том, как записываются значения по каждой переменной (колонке\столбцу) в массиве.
Сами столбцы должны быть названы именами\названиями переменных.
В базах данных и специализированных программах (к примеру, Power BI) названия столбцов — это отдельная сущность. А вот относительно Excel — то в нем имена\названия переменных вносятся просто в 1-ю строку таблицы.
И по этим переменным\столбцам четко напротив каждого случая\объекта (например, Вали и Ивана) записаны соответствующие им значения переменных — см. рис.6 на примере Excel.
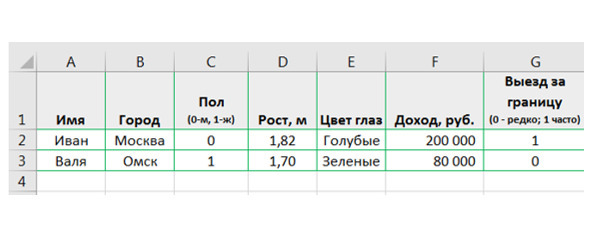
Два важнейшие момента по внесению значений переменных в массив отражены на рис.7:

1) Значение каждой переменной по каждому объекту\случаю записывается в отдельную ячейку. Запрещено объединять ячейки и записывать несколько разных переменных в одной ячейке!
2) Одинаковые значения в ячейках конкретного столбца (переменной) должны быть записаны одинаково. Никакого разного написания: если рост в метрах, то не пишем по одному случаю\объекту корректно 1,7, по-другому 170 уже в сантиметрах, а по третьему вообще словами «метр семьсят». Или допустим если мужской пол закодировали значением 1 — то будьте добры везде писать 1, а не в одном случае М, во втором 1, а в третьем М1 — а потом и значение «мужской» где-нибудь по ходу «втулить».
В противном случае у Вас в массиве буду в лучшем случае ошибки (значение Error, если тип данных для столбца числовой, а в ячейке этого столбца попадется текст) — но их можно быстро почистить. Ну а в худшем случае — Вы не заметите некорректных значений (например, когда 1,7 и 170 являются числовыми) и примите их в обработку и анализ.
Поэтому отсутствие записей в виде нескольких значений в одной ячейке и единообразная запись значений переменных — крайне важны для корректной обработки и анализа данных.
Уровень детализации массива
В завершение раздела о массивах рассмотрим такой важный момент как уровень его детализации (или как еще говорят «гранулярности»). И сразу в привязке к вопросу наличия в массиве переменной с уникальными (неповторяющимися) значениями.
Многие начинающие аналитики полагают, что именно объект анализа задает уровень детализации массива. И эти объекты анализа (то, что идет по строкам) в массиве должны быть представлены в уникальном виде (каждое значение, к примеру ФИО или город, встречается 1 раз).
И во многих случаях так и есть. Например, Вы опрашивает покупателей (рис. 8):
(1) и каждый покупатель является объектом (записывается в строке) и является уникальным значением,
(2) его демографические характеристики (пол, возраст, соцстатус и т.д.) и задаваемые вопросы являются переменными (записываются в столбцы),
(3) а признаки и ответы — помещаются в значения (построчно записываются в соответствующих столбцах).
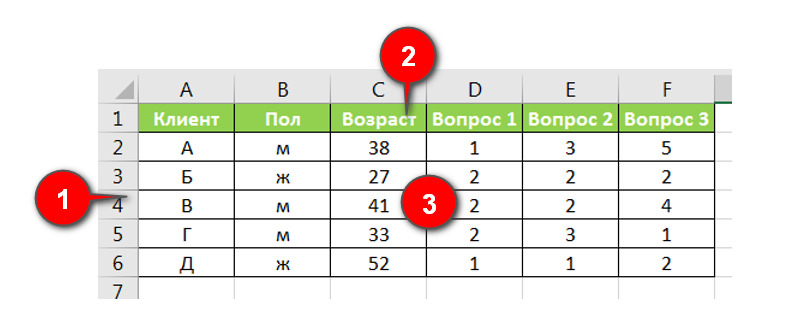
И тогда уровень детализации — уровень объекта Вашего исследования. И ФИО каждого покупателя встречается в уникальном виде.
Но в реальности так будет не всегда.
Давайте вернемся к примеру, который я рассматривал в главе об объектах анализа — пример с магазинами, в которых работают продавцы.
Допустим, объектом анализа являются магазины. И Ваш массив достаточно чтобы выглядел как на рис.9 слева (А).
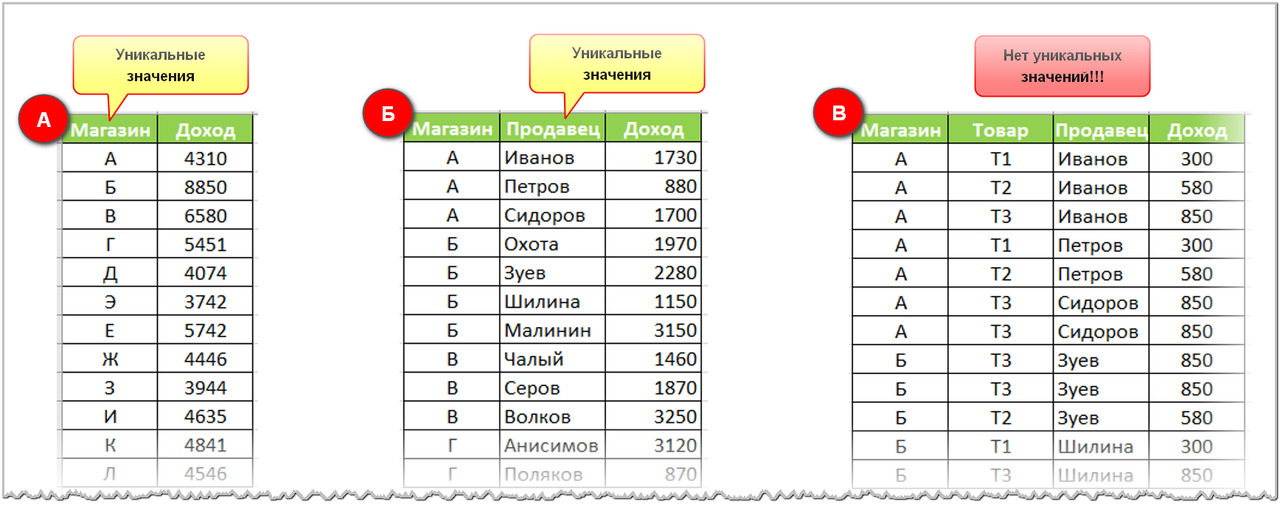
Но если у Вас есть возможность получить массив по продавцам — он будет выглядеть как на рис.9 посредине (Б). И из него также можно получить информацию по магазинам (в нем есть переменная «Магазин»). И заметьте — продавцы в уникальном виде, а каждый магазин повторяется столько раз, сколько продавцов в нем работает.
А если есть возможность достать еще продажи конкретного товара — то тогда массив будет выглядеть так как на рис.9 справа (В). И в нем также есть информация по магазинам. При этом ни одна переменная не содержит уникальных значений! И магазины, и товары, и ФИО продавцов повторяются много раз. Конечно, в этот массив наверняка можно дозагрузить переменную-идентификатор с уникальными значениями — код каждой конкретной транзакции (если он, конечно, где-то хранится в базе). Но можно работать и с такими массивами, не содержащими уникальных идентификаторов.
И это все на рис.9 — по сути один массив разной гранулярности (детализации). Такой детализированный массив Вы всегда можете укрупнить \ обобщить. Т.е., Ваш рабочий массив данных может быть на более глубоком уровне детализации, чем интересующие Вас объекты анализа. Если мощности систем позволяют, то загрузите массив на максимально детализированном уровне: но с необходимым набором признаков\переменных (в нашем примере «Магазин») для его укрупнения (обобщения, агрегации) до объектов анализа.
А по поводу наличия в массиве переменной с уникальными значениями. Хорошо, когда она есть. Но на практике в массиве не всегда может быть переменная, содержащая уникальные значения.
На этом о детализации массивов пока все.
Заключение
Итак, в этом разделе мы поговорили о структурированных в табличном виде массивах данных, которые годятся для работы с Power-надстройками и программой Power BI.
По строкам в массиве записываются объекты\случаи\наблюдения нашего анализа, а по столбцам — их переменные\признаки. В ячейках на пересечении идут значения переменных в построчной привязке к каждому объекту.
К записи значений в массив есть 2 важные требования:
1) каждое значение записывается в отдельной ячейке — недопустимо вносить несколько значений в одну ячейку (и в частности, запрещено объединять ячейки, как это привыкли делать многие пользователи Excel).
2) Одни и те же значения должны быть записаны одинаково.
И именно в таком виде должны быть организованы данные для анализа. И основное предназначение надстройки Power Query — это как раз помочь преобразовать имеющиеся данные в пригодный для анализа массив данных.
Также Вы поняли, что важно думать о гранулярности (уровнях детализации) таблиц-массивов — и всегда стараться (если позволяют технические средства и доступность такой информации) получить максимально детализированный массив данных. Причем при повышении уровня гранулярности не всегда в массиве будет какая-то одна переменная с уникальным набором значений.
Кроме того, в части работы со значениями мы познакомились с 3 типами шкал для измерения переменных и их информативностью, а также понятием типов данных, которые важны для вычислений и агрегации данных.
В завершение по теме шкал и типов данных дам тезисную таблицу на рис.10 — она может быть хорошим подспорьем для новичков при работе с данными.
РАБОЧАЯ СРЕДА: готовим инструмент для работы
Об инструментарии: суть и предназначение
Прежде, чем говорить о Power Query, давайте сначала поймем, что это за «зверьки» Power Query, Power Pivot и Power BI из «зоопарка» программ Microsoft.
Вы сами видите, что мир очень быстро меняется. И те изменения в отраслях, бизнесах, покупательских предпочтениях, поведении клиентов и т.д., на которые ранее уходило более полувека — сейчас могут происходить минимум трижды за десятилетие.
Поэтому движущийся в ногу со временем бизнес все меньше опирается только на чьи-то мнения и предположения, основанные на чьем-то прошлом опыте — менеджерам нужны свежие данные для понимания реальности и принятия верных решений.
И ежедневно менеджеры и аналитики получают самые разнообразные данные:
· прямо в интерфейсах разных программ
· выгрузки из баз данных
· Табличные отчеты
· Текстовые сообщения
· е-мейлы на почту
· Excel-файлы
· диаграммы в Power Point
· печатные материалы
· и т.д..
Все эти данные в разном виде, разных форматах, в разных системах и базах. И зачастую требуется потратить массу времени чтобы просто собрать их воедино — а потом еще больше времени чтобы их регулярно обновлять.
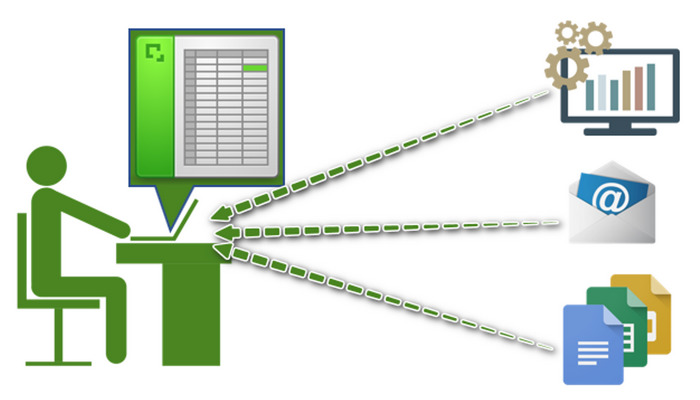
А самым ходовым приложением для работы с данными в корпоративном мире безусловно является Excel — и все менеджеры пытаются свести сыплющиеся на них данные в этот самый Excel — и уже в нем что-то анализировать.
Выглядит это все примерно как на рис.11.
И вот дабы автоматизировать процесс ручной выгрузки, переделывания таблиц к требуемому виду массива, копирования/вставки и обновления вручную данных из разных систем — к Excel создана надстройка Power Query.
Power Query помогает подключить к источникам данных (систем, отчеты в файлах, базы данных), преобразовать эти разнообразные данные в нормальный массив для анализа — и загрузить в Excel. Причем после первой такой загрузки данных Power Query «запоминает» источники данных и шаги приведения массива в порядок — и далее позволяет обновлять этот массив на регулярной основе простым нажатием кнопки ОБНОВИТЬ.
И массив из Power Query загружается в последние версии Excel в виде объекта «Таблица» (которую пользователи именуют «Умной таблицей», получаемой при выделении диапазона данных и нажатия комбинации CTRL+T) или в виде именованного диапазона для более ранних версий Excel.
Но всем известно ограничение Excel — чуть более миллиона строк… А если у нас 10 или 100 млн. строк? А если данные сгружены в виде нескольких таблиц? Тогда в построении сводных таблиц и диаграмм из множества таблиц помогает следующая надстройка — Power Pivot. Эта надстройка позволяет построить модели данных (связать таблицы) и при необходимости дополнить нашу модель новыми переменными, вычисленными на языке DAX — и по ним вывести сводные таблицы и диаграммы.
А если простых сводных таблиц и диаграмм мало — то можно создать некий интерактивный отчет в надстройке Power View: по сути создать лист-слайд с интерактивными диаграммами. Но надстройка Power View уже практически не используется — Microsoft настоятельно рекомендует использовать сразу программу Power BI, которая является «сборником» этих трех надстроек семейства Power с улучшенным функционалом.
Итого, у эффективно работающего с данными профессионала формируется среда для работы с немного большим набором инструментов, чем обычный Excel (рис.12).
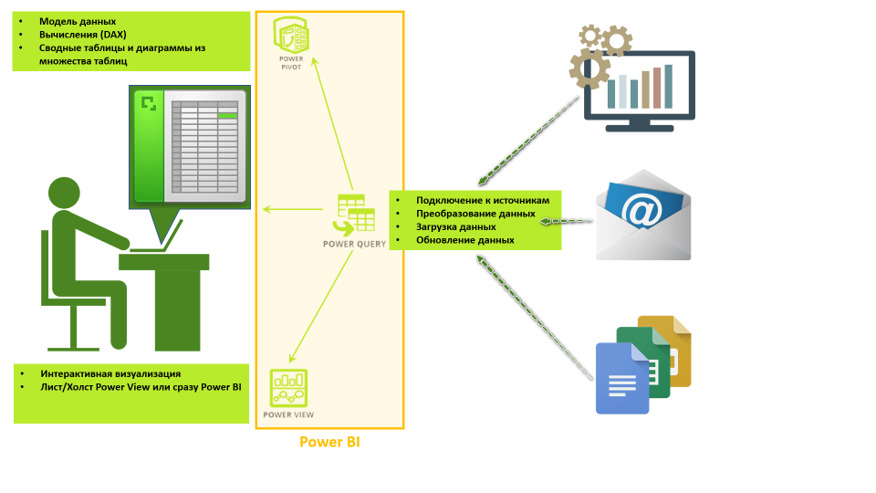
При этом многие полагают, что Power BI заменяет Excel — но это ошибочное мнение. Excel был и остается средой для работы на уровне частных данных и конкретных ячеек, а также включает в себя иных набор специализированных функций и надстроек для анализа данных (ПОИСК РЕШЕНИЯ, ЧТО-ЕСЛИ, АНАЛИЗ ДАННЫХ, ЛИСТ ПРОГНОЗА и т.д.), которые недоступны в Power BI. Т.е., Power BI — это заменитель только 3 Power-надстроек (Query, Pivot, View), но не самой программы Excel.
Работает это все вместе так (рис.13):
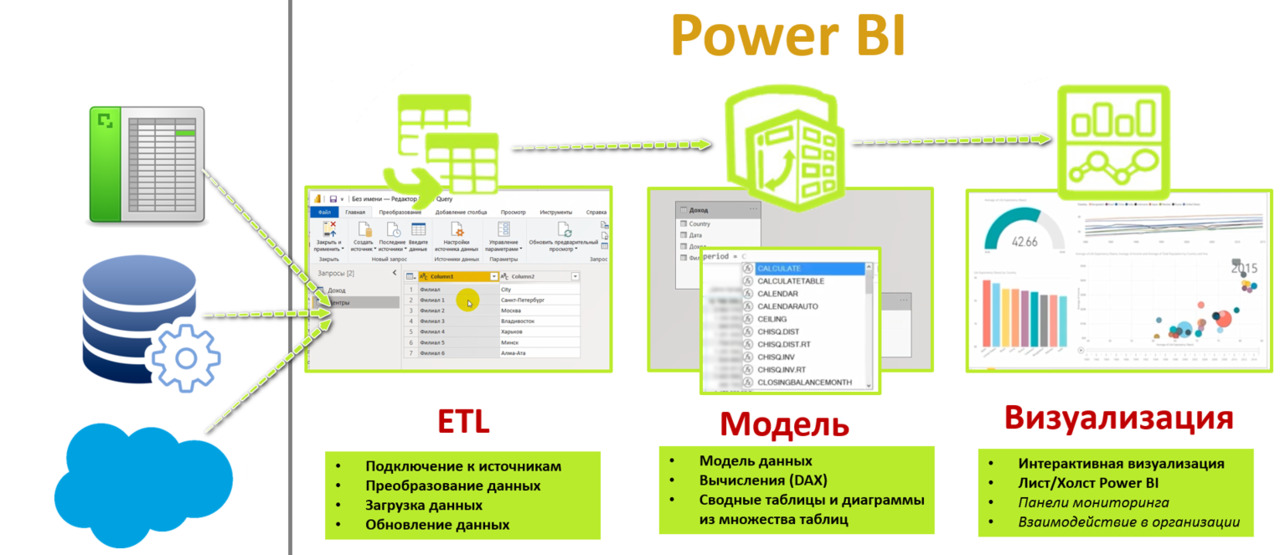
1. С помощью Power Query как ETL-инструментария (Exctract, Transform, Load — Извлечение, Преобразование, Загрузка) Вы подключаетесь к источникам данных и загружаете из них данные, преобразовав в структурированные массивы данных;
2. Загруженные таблицы объединяете в модель данных, используя Power Pivot. При необходимости расширяете\ насыщаете\ обогащаете модель новыми переменными путем вычислений на DAX. И можете извлекать из данных знания через сводные таблицы и диаграммы.
3. Визуализируете данные в Power BI на холсте в виде различных визуальных элементов (таблицы, всевозможные диаграммы, карточки, карты, датчики и т.д).
В этом разделе Ваша задача будет следуя инструкциям в следующих главах организовать себе рабочую среду для работы с Power Query в Excel и Power BI.
Проверить/подключить надстройку Power Query в Excel
По итогу данной главы Вы убедитесь, что у Вас в Excel подключена надстройка Power Query, которая необходима для работы с этой книгой.
Если Вы знаете, что в Вашем Excel есть Power Query — то можете эту главу пропустить.
Откройте Excel и в зависимости от Вашей версии выполните требуемое.
Excel 2016 и выше — перейдите на ленте во вкладку ДАННЫЕ и убедитесь в наличии кнопок подключения к источникам данных. Для 2016 версии должны быть видны вот эти секции/группы кнопок (в частности, секция «Скачать & Преобразовать» — рис.14):
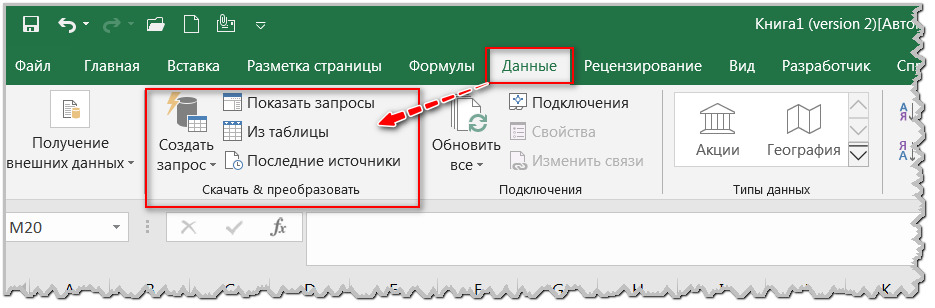
Для 2019 версии будут вот эти кнопки (в частности, секция «Получить и преобразовать данные» — рис.15):

Excel 2013 или 2010 — посмотрите на ленте наличие вот такой вкладки POWER QUERY (рис.16):
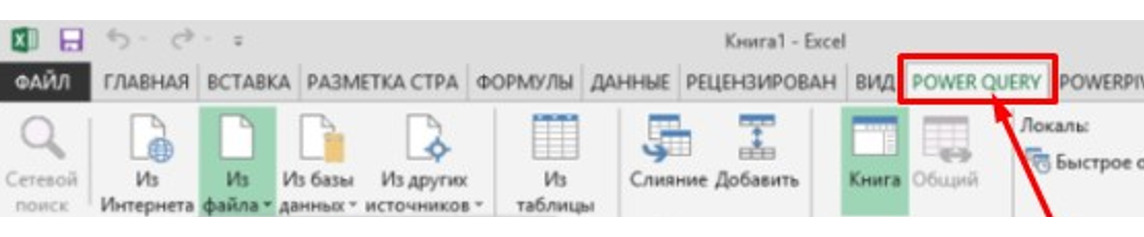
Если ЕСТЬ — все ОК, надстройка подключена.
Если НЕТ — то перейдите на официальный сайт Microsoft по этой ссылке https://www.microsoft.com/ru-RU/download/details.aspx?id=39379, скачайте надстройку. После скачивания необходимо закрыть Excel файлы и запустить скачанный файл-установщик, следуя шагам установки. После завершения установки надстройки запустите Excel и убедитесь, что на ленте появилась новая вкладка POWER QUERY.
Установить Power BI
По итогу данной главы Вы установите бесплатное приложение Power BI Desktop на Ваш ПК.
Скачайте программу на официальном сайте Microsoft https://powerbi.microsoft.com/ru-ru/downloads/
Запустите установку и следуя шагам программы установите ее.
Запустите Power BI Desktop и убедитесь, что программа без проблем открывается на Вашем ПК (инсталляция/установка прошла успешно).
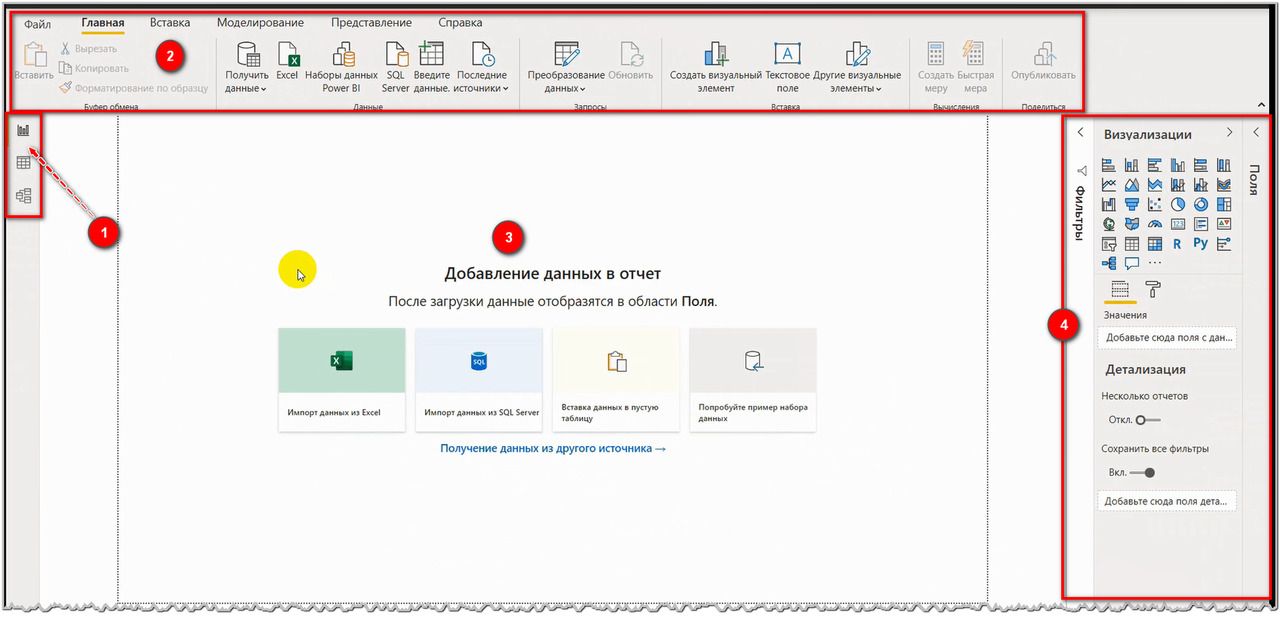
Бегло познакомьтесь с интерфейсом программы (не надо «с лету» пытаться сразу понять как это работает): походите по закладкам слева (1) и на каждой посмотрите ленту вверху (2), рабочую область посредине экрана (3) и область параметров справа (4) — рис. 17.
Как это все работает вместе
Суть и предназначение надстроек и Power BI мы разобрали в первой главе этого раздела — и даже рассмотрели общую логику их совместной работы. А теперь в завершение этого раздела и прежде чем Вы начнете работу одним из компонентов Power Query — более детально еще раз посмотрим как это все работает вместе.
Общая схема работы всей «экосистемы Power» показана на рис. 18:
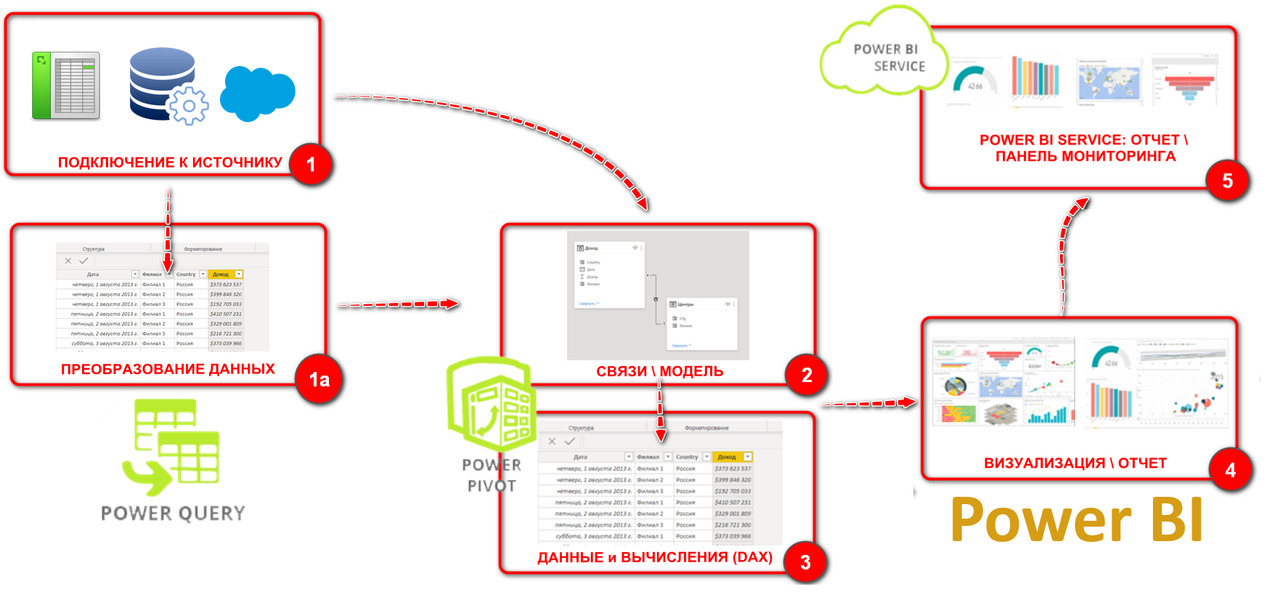
(1) С помощью Power Query, который мы рассмотрим в этой книге, Вы подключаетесь к источникам данных — и загружаете из них структурированную в виде массива таблицу. Таблица из каждого источника сгружается в виде объекта ТАБЛИЦА как в Power BI, так и на отдельный лист в последних версиях Excel (в виде «умной таблицы»).
(1а) Если таблица в источнике не соответствует требованиям массива (или даже просто содержит лишние, или требующие изменений данные, или требует дополнительных данных) — Вы c помощью того же Power Query преобразуете ее в нужный вид.
(2) Потом создаете модель данных в Power Pivot. Модель — это набор взаимосвязанных таблиц с переменными. Причем даже одна таблица считается моделью. Если загружено несколько таблиц — то их можно по общим переменным-идентификаторам (ключам) объединить связями для создания сводных таблиц и диаграмм по переменным из множества разных таблиц.
(3) При необходимости Вы можете расширить Вашу модель, насытив\обогатив ее новыми таблицами, столбцами\переменными и мерами. Вычисления всех этих новых вещей производятся на языке DAX (язык не сложный и очень похож на функции\формулы в Excel).
(4) После загрузки из источников таблиц, их связи в модель с вычислением при необходимости новых элементов — данные визуализируются в виде построения сводных таблиц и диаграмм в Power Pivot или же сразу строятся более продвинутые сводные визуализации в Power BI. Причем модель из Power Pivot Excel можно легко импортировать в Power BI — и построить необходимые визуализации в нем.
(5) Этот шаг возможен только из Power BI — публикация построенных отчетов в облачное приложение Power BI Service, с последующей настройкой панелей мониторинга\ дашбордов. Также из облачной службы Power BI Service можно предоставлять доступ и распространять панели мониторинга внутри Вашей организации чтобы поделиться результатами своего аналитического труда и организовать совместную работу c результатами анализа.
В этой книге мы рассмотрим из всего процесса только этапы 1 и 1а, где задействован Power Query.
Заключение
В этом разделе Вы сделали 2 важнейшие вещи для успешной работы с Power-надстройками и Power BI:
1. Поняли предназначение и познакомились с общей схемой работы «экосистемы Power» вместе.
2. Проверили\установили Power Query в Excel, а также установили официальную программу Power BI.
Теперь в следующих разделах книги мы пройдемся от начала до конца по основным шагам работы с надстройкой Power Query в Excel и Power BI:
— подключения к источникам и извлечения из них данных,
— их преобразования и очистки;
— с последующей загрузкой в Excel и Power BI;
— и обновлением данных при необходимости нажатием одной кнопки ОБНОВИТЬ.
И всем читателям настоятельно рекомендовано отрабатывать описанные функционалы на практике — для этого по итогам каждой главы или комплексно после нескольких глав Вам будет предложена схема практической отработки навыка в виде ЛИСТА ПРАКТИКИ.
POWER QUERY как ETL-инструментарий
Роль Power Query как ETL-инструментария
Первое, что необходимо сделать до того, как начать анализ данных — это собрать их в виде массива на листе в Excel, в надстройке Power Pivot или программе Power BI.
Таблицы с данные хранятся обычно в базах данных, системах, других файлах (Excel, PDF, JSON…) и т. д. И «по-старинке» обычные пользователи Excel:
— открывают имеющиеся у них файлы с данными, проверяют и обновляют при необходимости;
— пишут запрос в ИТ на выгрузку нужных данных из систем и баз,
— копируют все собранные данные в один Excel-файл,
— при необходимости «стягивают» в единую таблицу функцией\формулой ВПР (VLOOKUP),
— а потом по этой единой таблице строят сводные таблицы и диаграммы.
И при каждом последующем обновлении данных для актуализации отчетов это все повторяется заново. Т.е, данные вроде бы как и все есть, и понятно где они находятся и как их собрать — но собрать их воедино «еще то удовольствие» и тем более довольно трудозатратное.
Но существует возможность подключиться к источникам и загрузить данные в виде массива в Excel или Power BI напрямую. Более того, «записать» шаги преобразования таблицы из источника в нужный нам вид (удалить лишние столбцы, добавить недостающие, почистить лишние строки и ошибки…) — и обновлять данные из источников простым нажатием кнопки ОБНОВИТЬ.
Эта возможность существует благодаря ETL-инструменту Power Query.
ETL — это аббревиатура англ. Extract, Transform, Load — Извлечение, Преобразование и Загрузка данных.
Таким образом, работа начинается с подключения к источнику данных и загрузки таблиц с помощью Power Query.
Именно Power Query автоматизирует подключение, загрузку и обновление данных из источников, «запоминая» и сами источники, и шаги, которые необходимо проделать с таблицами в этих источниках — чтобы в итоге «сгрузить» Вам в Excel, Power Pivot или Power BI данные в виде нормального массива.
И при необходимости обновления данных (скажем через неделю, месяц, квартал, год…) Вам не нужно снова выбирать и указывать источники, не нужно заново повторять шаги по приведению данных в источнике в вид нормального массива — Вам достаточно только нажать кнопку ОБНОВИТЬ и Power Query сделает это за Вас.
Т.е., схематически обособленная роль этого компонента\надстройки отдельно изображена на рис.19:
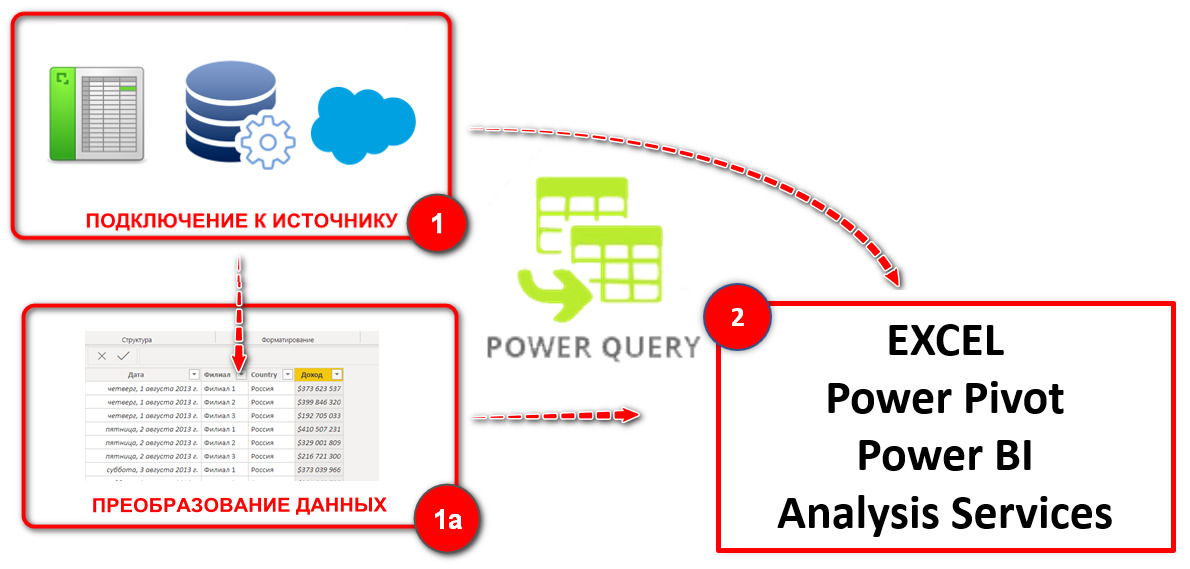
(1) Подключиться к источнику и «запомнить» его.
(1а) При необходимости преобразовать таблицу в источнике к необходимому виду — и «запомнить» примененные шаги преобразований.
(2) Сгрузить таблицы-массивы в Excel (или сразу и в модель данных Power Pivot для последних версий Excel) или в Power BI — и далее обновлять их простым нажатием кнопки ОБНОВИТЬ (имея уже «в памяти» и все источники, к которым нужно подключиться, и все примененные к таблице шаги для ее преобразования к нужному виду).
И вот в этом разделе книги мы в целом познакомимся с работой ETL-инструмента Power Query в части подключения к источникам, преобразованию и обновлению данных. А в следующих разделах — детально разберем возможности и функционалы в части преобразования данных в редакторе Power Query.
Источники данных
Из прошлой главы Вы уже поняли, что источник — это файл, база данных или система\сервис, где хранится статичная или постоянно обновляемая таблица с данными, которую нам нужно загрузить для анализа и визуализации.
Если в источнике находится сведенный отчет, а не массив — его можно в Power Query преобразовать в массив, но эту возможность мы рассмотрим ближе к концу книги.
Power Query имеет множество встроенных коннекторов (соединителей) к различным системам и базам данных — и Вы можете сразу же подключится к ним и получать из них актуальные данные.
В данной главе мы рассмотрим к каким источникам умеет подключаться Power Query на момент написания книги. А в следующей главе — как подключаться к источникам и загружать данные.
В Excel Power Query может подсоединяться к условно пяти большим группам\категориям источников (рис. 20):
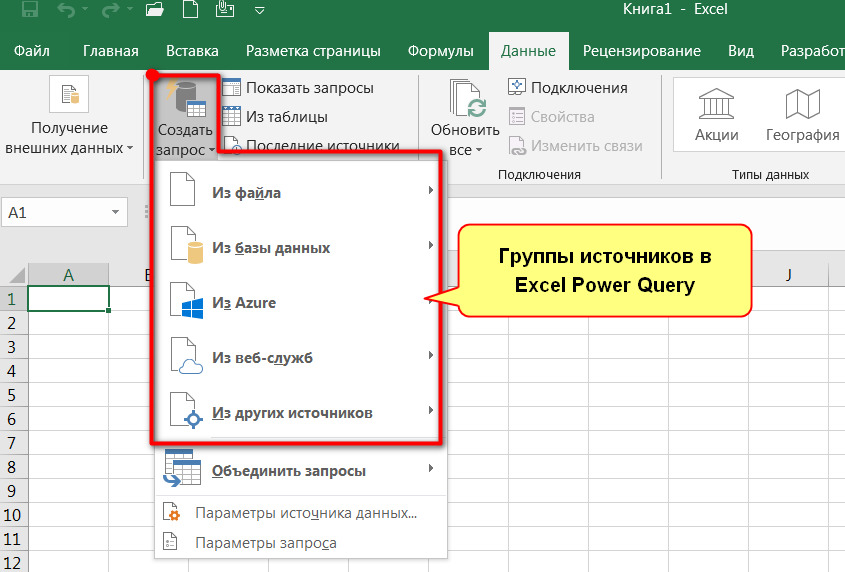
· Файлы (Excel\CSV, JSON, XML, Текст)
· Базы данных (Access, SQL, MySQL, Oracle, IBM, Teradata…)
· MS Azure (SQL, HDFS, BLOB, табличного DWH)
· Веб-службы (Salesforce, Dynamics 365, SharePoint…)
· Другое (сайты, ODATA, AD, MS Exchange, пустые запросы…)
Но Power Query в Excel более ограничен в части подключения к источникам, чем специализированная программа Power BI Desktop. И ограничен как по группам\категориям, так и по наполнению категорий — даже в категории «Файлы» в Power BI можно подключать допустим еще и PDF.
Перечислять все что есть в Power BI не будем (реально много!). Просто для примера сравните наполнение категории «Веб-службы» в Excel (слева, всего 6 опций) и Power BI (справа, много опций — и еще полоса прокрутки вниз указана стрелкой) на рис.21:
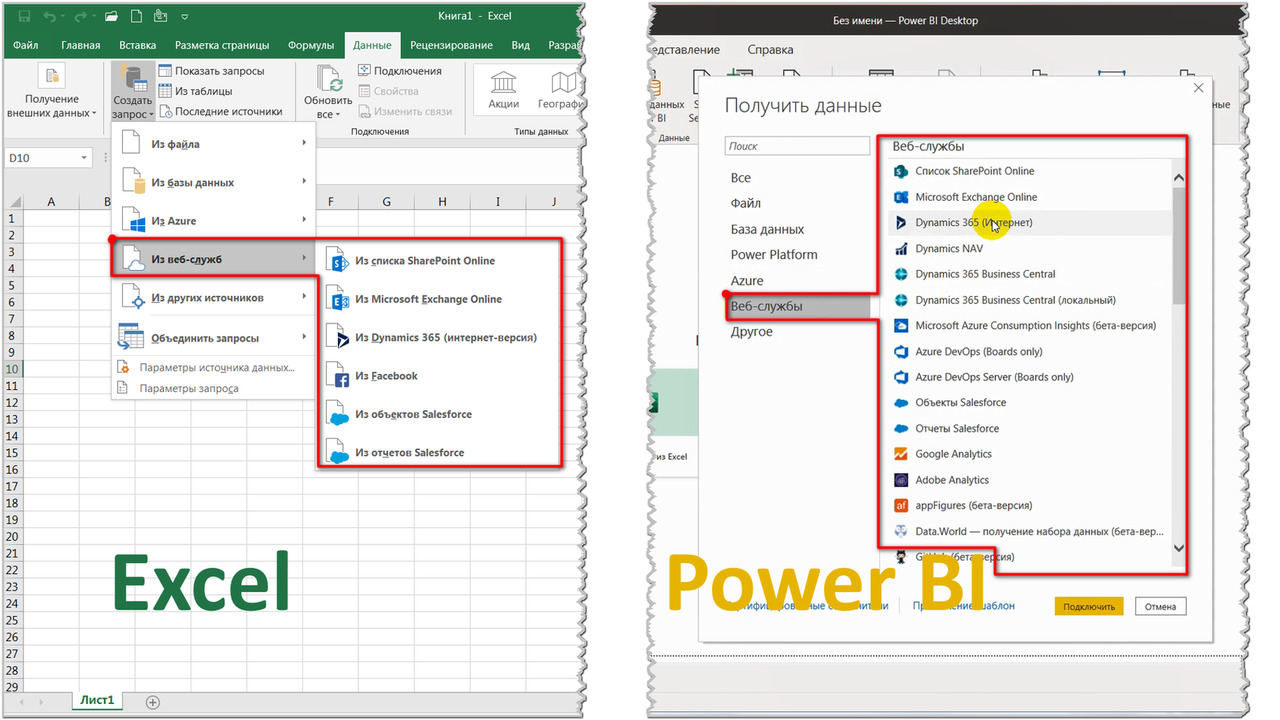
То же самое по количеству будет и в базах данных, и в других группах\категориях: в Power BI Desktop будет намного больше коннекторов к разным источникам. И количество возможных источников в Power BI постоянно активно пополняется.
Итак, в данной главе Вы должны вынести то, что есть различные источники данных, к которым можно подключаться с помощью Power Query. Ну и то, что в Power BI Desktop арсенал коннекторов (соединителей) с источниками на порядок обширнее и постоянно пополняется.
Подключение к источникам и загрузка данных
Вы теперь знаете, что Power Query имеет огромный арсенал коннекторов (соединителей) к источникам данных. В этой главе рассмотрим, как подключаться к источникам и загружать данные в Excel и Power BI.
Для подключения источника и в Excel, и Power BI на ленте нужно нажать кнопку ПОЛУЧИТЬ ДАННЫЕ (или СОЗДАТЬ ЗАПРОС в Excel 2016): только в Excel она находится на вкладке ДАННЫЕ, а в Power BI — на вкладке ГЛАВНАЯ (рис.22- см. красные пути).
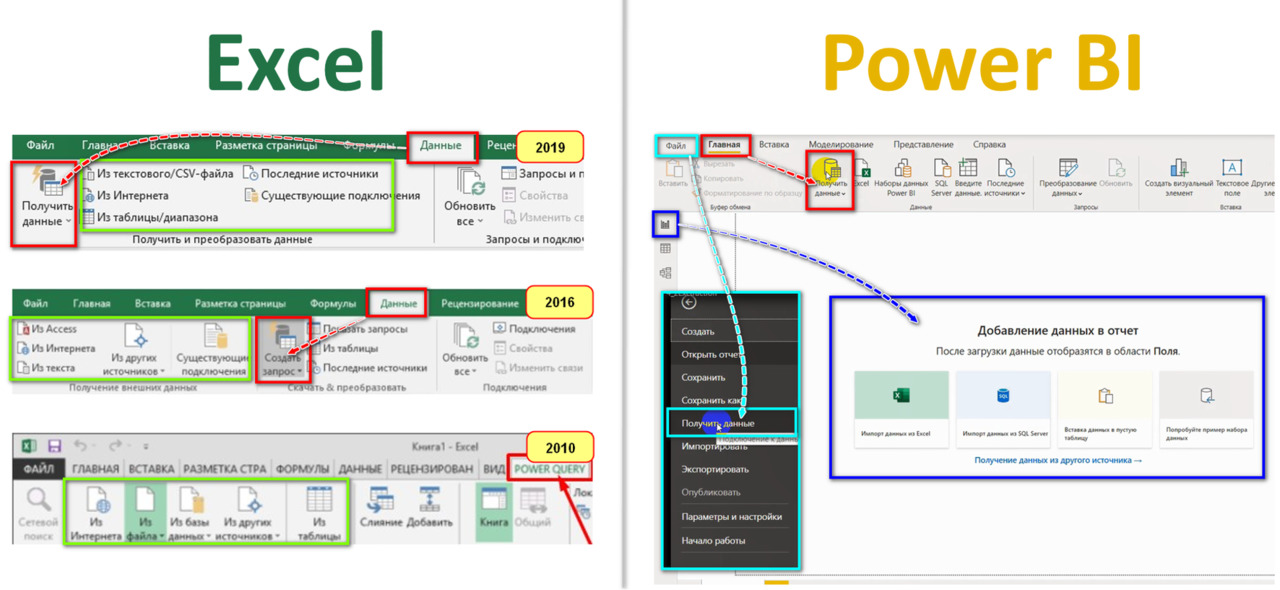
В более старых версиях Excel вместо отдельной кнопки есть набор кнопок начинающихся «Из…» на вкладке POWER QUERY — эти кнопки на рис. 22 обведены зеленой рамкой во всех версиях.
Ну и как видно на рис.22, в Power BI подключение дополнительно также можно вызвать:
· Прямо из холста\слайда в представлении\закладке ОТЧЕТ как только программа загрузилась еще пустая без данных (при загрузке первых данных эти кнопки исчезнут) — синий путь.
· А можно в меню ФАЙЛ, выбрав пункт «Получить данные» — фиолетовый путь.
При нажатии кнопки ПОЛУЧИТЬ ДАННЫЕ программа попросит указать источник, к которому Вы хотите подключиться (рис. 23).
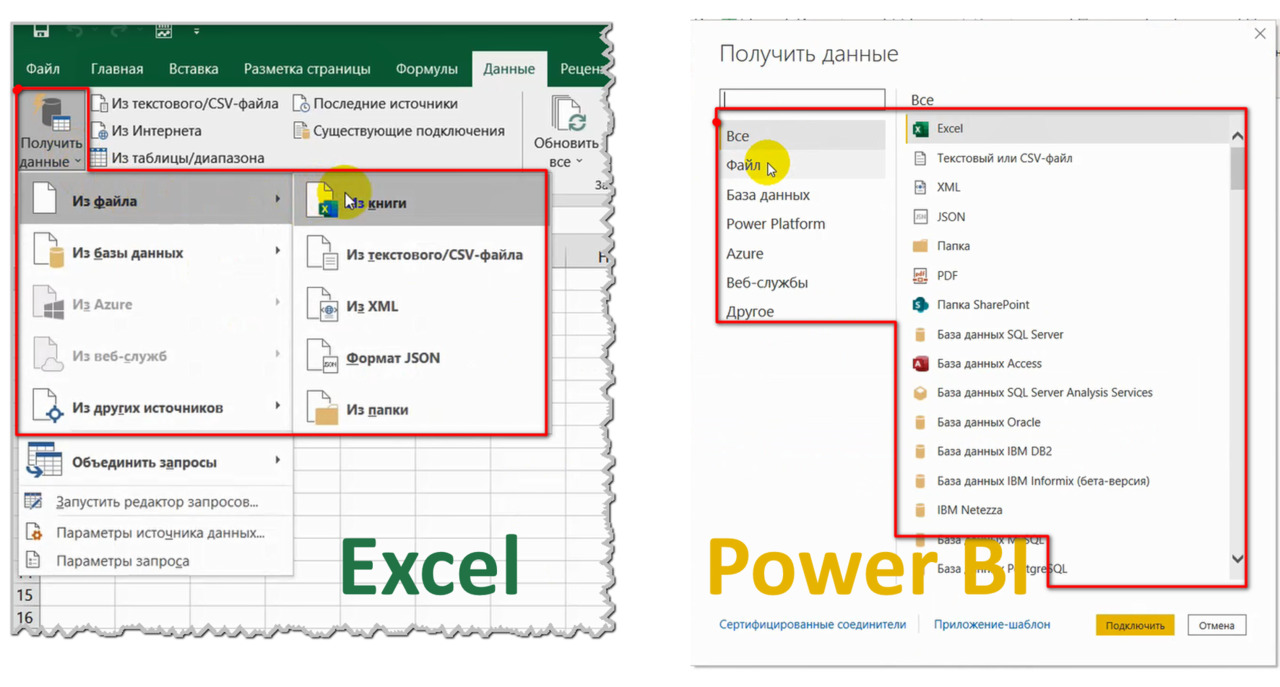
Далее Вы просто указываете путь к источнику. Общая логика подключения к источникам одинакова, но каждый источник имеет свои особенности. Например:
— если выбрать в качестве источника файл (Excel, PDF, XML, JSON и т.д.) — то откроется стандартное окно указания пути к файлу на ПК;
— если выбрать сайт из интернета — то нужно буде указать URL-адрес (ссылку);
— если выбрать базу данных — то нужно будет указать сервер, имя базы и пароль\авторизация;
— если выбрать OData — то кроме авторизации еще может понадобиться ключ учетной записи Marketplace…
Также будьте готовы к тому, что при подключении к конкретному источнику понадобится обновление или установка дополнительных компонентов конкретно на Вашем ПК. К примеру, даже для импорта из PDF понадобится. NET Framework 4.5 или выше. Но Power Query сам Вам об этом скажет и переадресует на страницу с требованиями для подключений к источникам (рис.24):
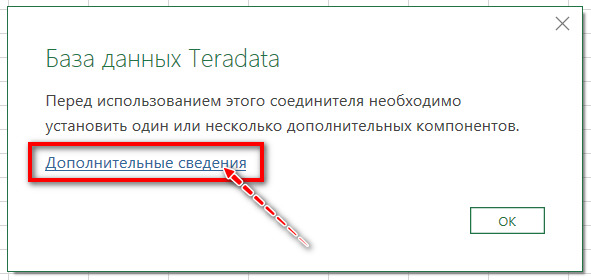
На этой официальной странице Microsoft находится как список требований к каждому соединителю, так и инструкция как ими пользоваться — кому интересны специфические источники, можно посмотреть детали по этой ссылке: Импорт данных из внешних источников (Power Query)
После того, как Вы выбрали источник (при необходимости установив недостающие на Вашем ПК компоненты и авторизировавшись в источнике) начинается самая важная часть: Вам открывается окно НАВИГАТОР.
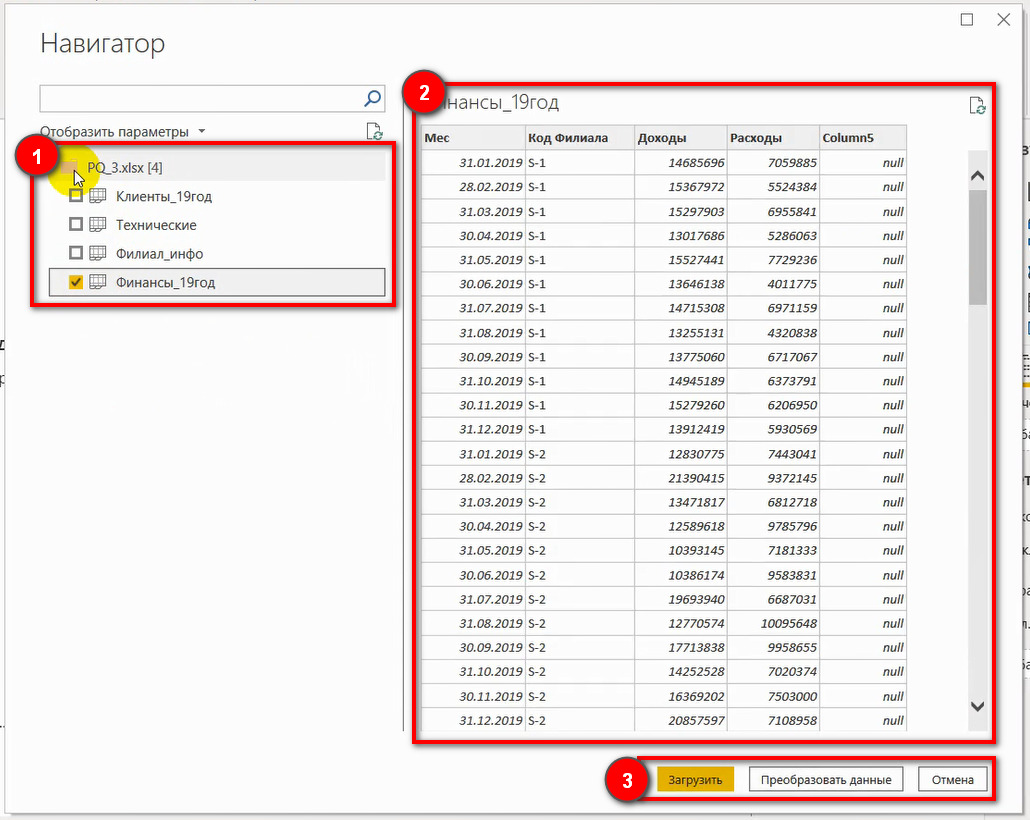
В окне НАВИГАТОР (рис.25) есть:
(1) список содержащихся в источнике таблиц, в котором Вы можете отметить птичками\флажками нужные для загрузки,
(2) область предварительного просмотра таблиц,
(3) кнопки ЗАГРУЗИТЬ и ПРЕОБРАЗОВАТЬ ДАННЫЕ.
Power Query считывает таблицы с объектов-таблиц и листов. Например:
— если источник Excel-файл (книга) — то каждый отдельный лист с данными будет восприниматься как таблица-массив. Соответсвенно, если у Вас на одном листе несколько таблиц — каждую из них должна быть выделить в источнике в виде объекта ТАБЛИЦА комбинацией CTRL+T — иначе Power Query ее не будет «видеть» как отдельную таблицу, а будет воспринимать лист цельным массивом данных.
— если источник база данных — то считываются объекты ТАБЛИЦА.
— если источник сайт (веб-страница) — то считываются объекты таблицы в языке разметки гипертекста…
И в НАВИГАТОРЕ Вы:
— отмечаете в списке нужные Вам для работы таблицы (на момент написания книги в НАВИГАТОРЕ Excel чтобы выбрать несколько таблиц необходимо сначала сверху над списком таблиц поставить флажок «Несколько элементов»);
— просматриваете таблицы их в области предварительного просмотра — и принимаете решение загружать их «как есть» или требуются изменения\преобразования каких-то таблиц;
— и жмете соответствующую кнопку: ЗАГРУЗИТЬ (если преобразований не требуется: таблица выглядит нормальным массивом данных) или ПРЕОБРАЗОВАТЬ ДАННЫЕ (если в таком виде Вас таблица не устраивает — в ней нужно что-то удалить, добавить, изменить…).
По нажатию кнопки ЗАГРУЗИТЬ:
— в Excel на отдельно листе в виде «умной таблицы» (объект ТАБЛИЦА) или именованного диапазона (более ранние версии Excel) загрузится массив из источника, а слева будет панель запросов (рис.26):
Причем если Вы загружали несколько таблиц — то все они в Excel будут загружены на разные листы.
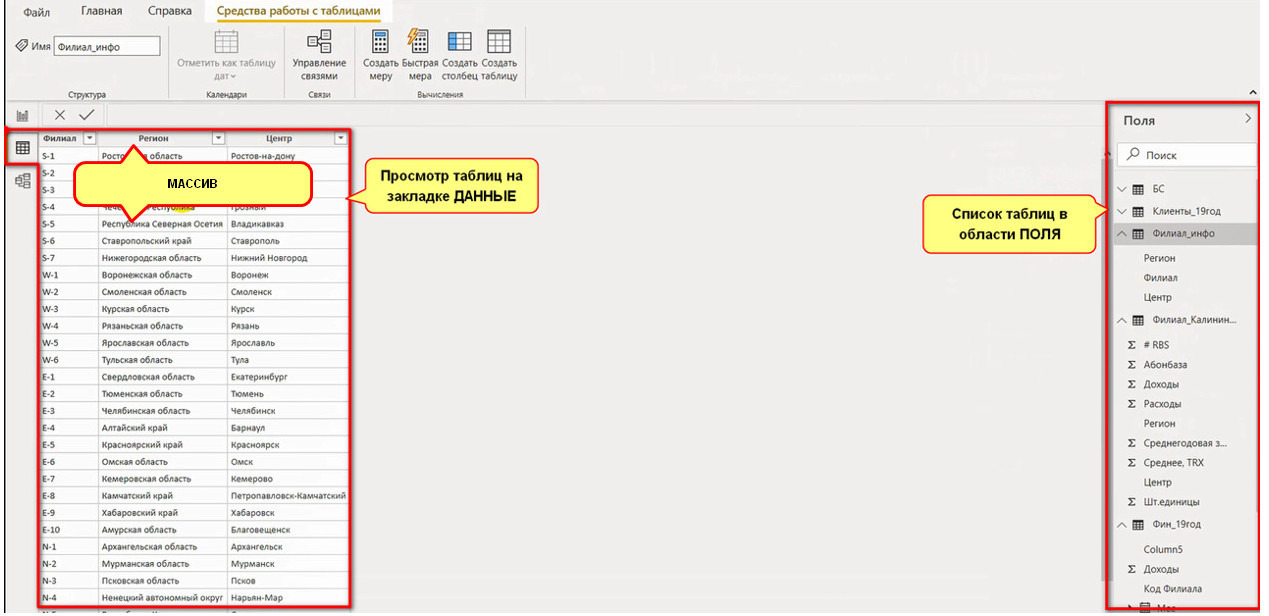
— в Power BI же Вам загрузит таблицы во всех представлениях\закладках в области ПОЛЯ справа, а просмотреть их можно будет в виде таблиц на закладке ДАННЫЕ — рис.27:
В общем, по нажатию кнопки ЗАГРУЗИТЬ таблицы загрузятся в Excel или Power BI — ту программу, в которой Вы указывали подключение источников.
По нажатию кнопки ПРЕОБРАЗОВАТЬ ДАННЫЕ Вы попадете в редактор Power Query (рис.28):
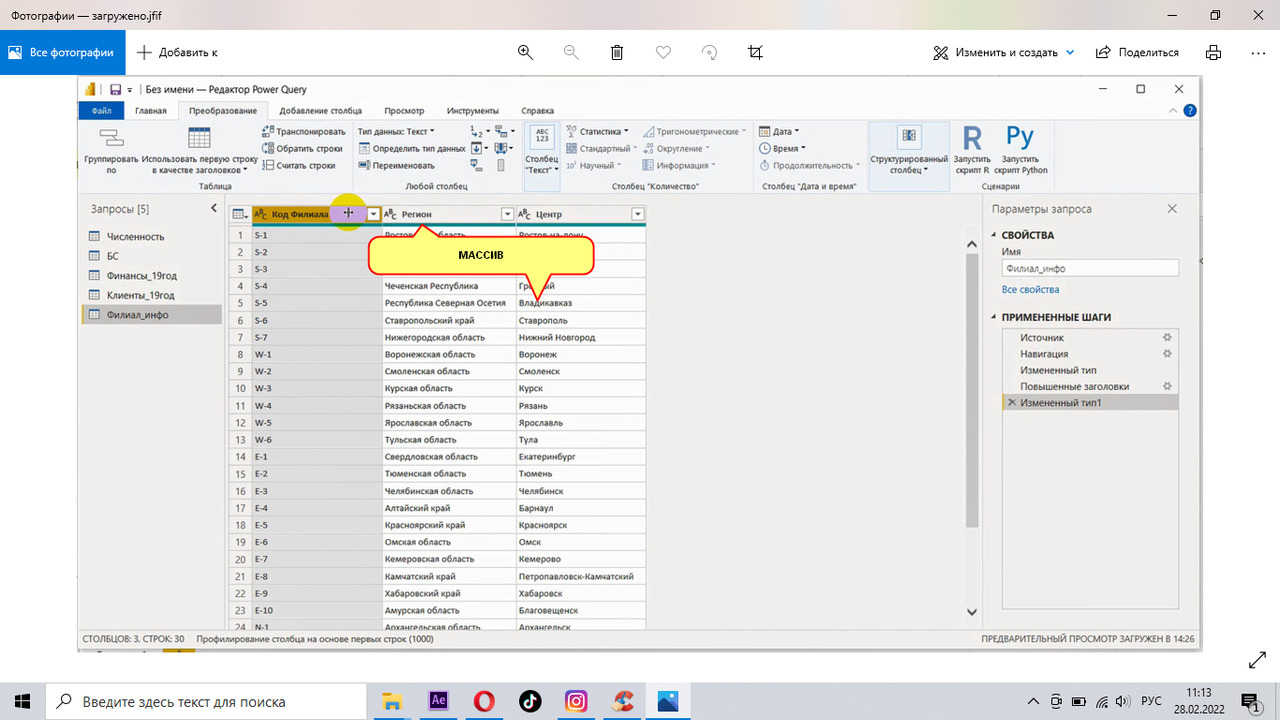
В этом редактор можно сделать различные преобразования в таблице из источника для приведения ее к пригодному для анализа виду массива данных. Но интерфейс редактора и все возможности преобразований мы пошагово изучим в отдельных главах данного раздела.
Итого, в этой главе мы узнали как подключиться к источникам данных и выбрать в них нужные нам таблицы с данными — после чего решить, что нам нужно:
— ЗАГРУЗИТЬ таблицу (если преобразований не требуется: таблица выглядит нормальным массивом данных) — и нам загрузит таблицу в Excel или Power BI;
— ПРЕОБРАЗОВАТЬ ДАННЫЕ в таблице (если в исходном виде Вас таблица не устраивает — в ней нужно что-то удалить, добавить, изменить…) — и тогда мы попадем в редактор Power Query, где сможем сделать необходимые преобразования данных.
Лист практики №1: подключение источников и загрузка данных
Для практического освоения читателем изучаемых функций рекомендуется пробовать их делать своими собственными руками. Для этого по ходу книги будут встречаться такие ЛИСТЫ ПРАКТИКИ. Пошагово выполняйте указанные в них действия для закрепления прочитанного материала.
Подключение источников и загрузку данных рекомендуется попробовать сделать на примере источника в виде Excel-файла, поскольку:
— Excel-файлы есть у любого пользователя этой программы (или могут быть легко и быстро сделаны «с нуля»),
— подключение Excel не потребует установления на ПК никаких дополнительных компонент.
1. Возьмите любой Excel-файл из Вашей профессиональной деятельности, структурированный в виде массива данных. Сохраните этот файл отдельно где-то у себя на ПК под названием Source.
Если у Вас нет своего Excel-файла — искусственно создайте и сохраните на ПК Excel-файл, содержащий, к примеру, три столбца\переменные:
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.