
Бесплатный фрагмент - Нейросети для бизнеса и личного использования

Введение
Для частного пользователя нейросеть — это персональный инструмент расширения возможностей, приобретения новых знаний и навыков, ускорения процессов, связанных с информацией. В личном развитии нейросеть — это доступный в любое время репетитор, ментор, тренажер. Человеку, ежедневно работающему с большим объёмом информации, нейросеть поможет сэкономить много времени и качественно подготовиться к принятию решений в различных сферах. Нейросеть не заменяет эксперта, бизнес-коуча или психолога, а дополняет их. Навык работы с искусственным интеллектом (ИИ) включает три основных компонента: понимание возможностей, умение формулировать задачи так, чтобы получать наилучший результат (prompt engineering) и критическую оценку результатов.
Билл Гейтс, анализируя влияние ИИ на управление, отметил, что «ключевая роль ИИ — не в замене людей, а в усилении их продуктивности и возможностей принятия решений: компании, которые научатся строить управленческие процессы вокруг такого „копилота“, будут получать стратегическое преимущество в эффективности и инновациях» (на основе эссе Билла Гейтса «The Age of AI has begun» на Gates Notes и его версии на сайте World Economic Forum).
Освоив работу с ИИ на уровне, описанном в этой книге, читатель получает не просто новый инструмент, а устойчивое конкурентное преимущество в любой сфере, где имеет значение работа с информацией. Вы научитесь превращать нейросеть из «чата ради любопытства» в управляемого ассистента. Для специалиста это означает возможность брать на себя более сложные задачи, чем раньше, освобождая время от рутинного поиска и первичного анализа данных. Для человека, который только выстраивает карьеру, — шанс быстрее войти в новую профессиональную область, опираться на ИИ как на практический тренажёр профессиональных навыков и источник структурированной обратной связи.
Структура этой книги выстроена так, чтобы читатель не зависел от конкретных сервисов, а понимал фундаментальные принципы работы нейросетей и мог применять их к любым текущим и будущим инструментам. Разделы о генезисе ИИ, архитектурах, парадигмах обучения и мультимодальных системах формируют концептуальный каркас, который помогает осмысленно использовать как крупные языковые модели (LLM), так и специализированные решения для анализа данных, генерации контента или автоматизации процессов.
Такой подход соответствует лучшим практикам цифровой грамотности: сначала понимание устройства и ограничений технологии, затем — целенаправленное освоение прикладных сценариев.
Части, посвящённые промпт-инжинирингу, показывают, как перевести взаимодействие с ИИ из режима случайных попыток в управляемый процесс постановки задач и получения воспроизводимых результатов. Разбор основных типов промптов, шаблон «идеального запроса» и примеры для разных сфер — от психологического консультирования до анализа маркетинговых стратегий — позволяют выстроить собственную библиотеку рабочих сценариев. Это сочетает научно-популярное объяснение принципов с деловым фокусом на измеримой пользе: сокращении временных затрат, повышении качества решений и улучшении коммуникаций с клиентами, коллегами и аудиторией.
Практические главы о выборе моделей, локальном и облачном развёртывании, интеграции в бизнес-процессы, создании ИИ-ассистентов и интеграции с системами автоматизации отражают текущие тенденции «ИИ как копилота» в управлении и операционной деятельности. Они демонстрируют, как превратить нейросеть из отдельного сервиса в элемент личной и корпоративной архитектуры: от аналитики и маркетинга до разработки продуктов и поддержки клиентов. Раздел о правовых аспектах использования нейросетевых моделей в России и за рубежом дополняет эту картину.
Осваивая подходы, изложенные в книге, читатель получает не набор разрозненных приёмов, а целостную систему: от понимания устройства нейросетей и методического промпт-инжиниринга до построения собственных ИИ-агентов и юридически корректного и этически осмысленного использования моделей в реальных задачах. В результате нейросеть становится прозрачным, настраиваемым инструментом, усиливающим профессиональную компетентность и расширяющим возможности личного развития. В мире, где конкурируют уже не только продукты и компании, но и темпы обучения людей и организаций, такая комбинация научно-популярного понимания и практического делового применения ИИ превращает чтение этой книги в инвестицию в долгосрочное конкурентное преимущество читателя.
Именно этому — осознанному, профессиональному использованию ИИ в повседневной жизни, личном развитии, работе и бизнесе и посвящена эта книга.
Генезис искусственного интеллекта и нейросетей
«Как электричество 100 лет назад преобразило почти всё, сегодня я с трудом думаю об отрасли, которую искусственный интеллект не преобразит в ближайшие годы». Эндрю Ын (Andrew Ng) — один из ведущих мировых экспертов по искусственному интеллекту.

Современные нейросетевые модели являются результатом почти векового развития идей об искусственном интеллекте (ИИ) и машинном обучении — начиная с абстрактных логико-математических построений и заканчивая крупномасштабными индустриальными системами обработки данных.
Первые представления о нейросетях появились ещё в середине XX века, когда учёные попытались создать устройства, работа которых напоминала бы человеческий мозг. В 1943 году нейрофизиолог Уоррен Мак-Каллок и математик Уолтер Питтс предложили простую, но революционную идею — описать нейрон как математический элемент, который принимает сигналы, обрабатывает их и передаёт дальше. Эта модель показала, что сложное поведение можно объяснить комбинацией простых логических операций. Позднее Дональд Хебб сформулировал принцип обучения «нейроны, которые активируются вместе, усиливают связь», что заложило интуитивную основу для регулирования весов в нейросетях.
Спустя всего полтора десятилетия Фрэнк Розенблатт представил перцептрон — первую работающую нейросеть, способную «обучаться» на примерах и распознавать простые образы. Именно с перцептрона началась практическая история искусственных нейронных сетей и современных систем искусственного интеллекта.
В период с 1980 по 2000 год, к сожалению, исследования и вычислительные возможности того времени не позволяли развить идею нейросетей. Уже ближе к концу XX века исследователи добились значительного прогресса. Был разработан метод обратного распространения ошибки — способ, с помощью которого нейросеть «учится» на своих ошибках.
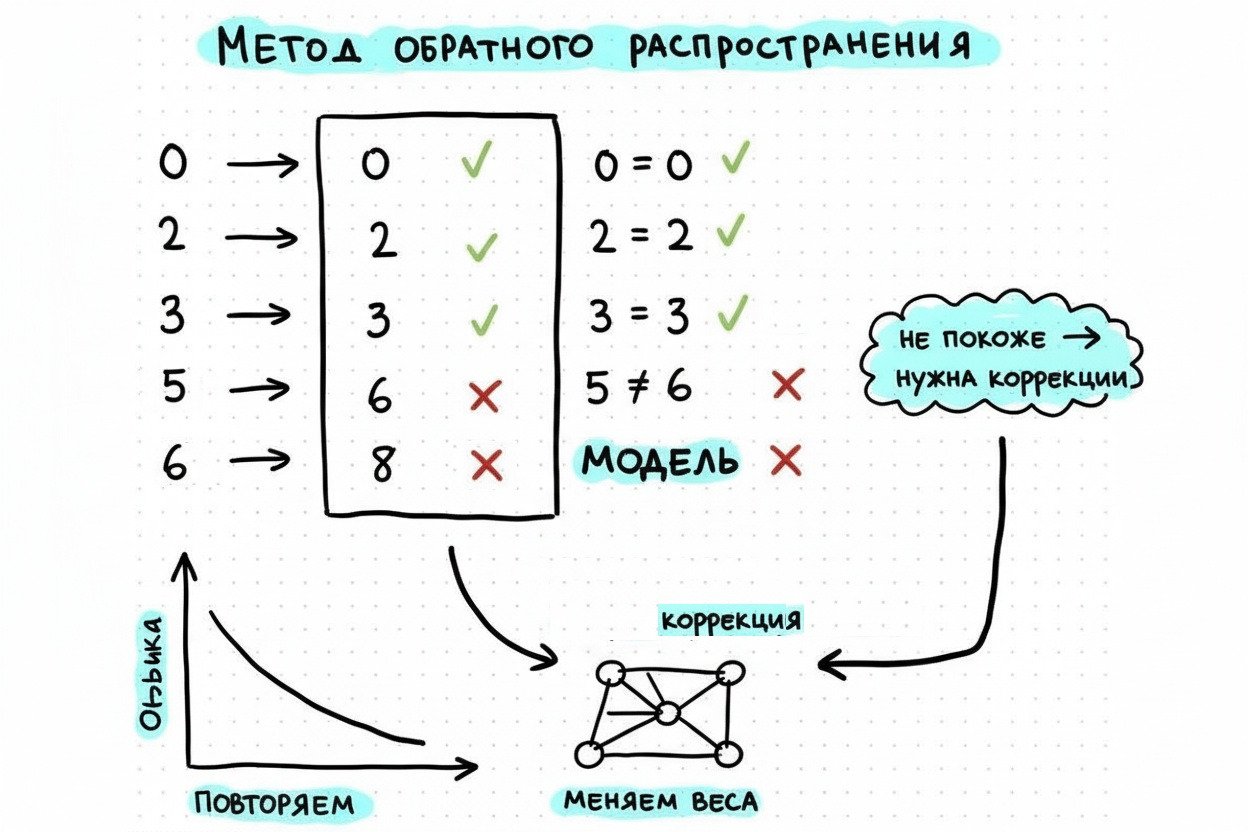
Когда сеть делает предсказание, например пытается определить тональность текста, она сравнивает свой ответ с правильным и вычисляет ошибку. Затем этот метод пошагово «прокручивает» ошибку в обратном направлении — от выходного слоя к входным. Каждый нейрон получает сигнал о том, как именно он повлиял на неправильный результат, и немного корректирует свои веса — численные параметры, отвечающие за важность связей.
Так повторяется многократно, пока сеть не научится давать максимально точные ответы. В упрощённом виде можно сказать: обратное распространение ошибки — это процесс самокоррекции нейросети, аналогичный тому, как человек учится на собственных ошибках, постепенно улучшая свои решения.
2000–2020: эпоха глубокого обучения и прорывов нейросетей
Начало XXI века стало переломным моментом в истории искусственного интеллекта. В нулевые годы на рынке появились мощные графические процессоры (GPU), изначально предназначенные для обработки компьютерной графики. Однако именно они позволили учёным обучать нейросети быстрее и на гораздо больших объёмах данных. Параллельно человечество вступило в эпоху «больших данных»: интернет, социальные сети и цифровые архивы начали производить терабайты информации, пригодной для анализа. На этом фоне возродился интерес к идее обучающихся нейросетей, но теперь на новом уровне.
Так возникло глубокое обучение (deep learning) — направление, основанное на использовании многослойных нейронных сетей, способных самостоятельно выделять важные признаки из данных. Хотя сам термин активно вошёл в обиход лишь в 2010-е годы, именно тогда начались первые настоящие успехи: алгоритмы стали уверенно обгонять человека в распознавании изображений, переводе текста и анализе речи.
Джеффри Хинтон не случайно назвал глубокое обучение «вторым дыханием» нейросетей, подчёркивая, что идеи 1980-х годов получили практическую реализуемость только при доступе к массивным датасетам и мощным вычислительным кластерам. Именно этот синтез привёл к появлению систем, способных распознавать изображения на уровне или выше человека, переводить тексты в реальном времени и генерировать содержательные тексты и изображения.
Глубокое обучение превратилось в универсальный подход к обучению представлений данных, позволяющим использовать нейросети не как узкий инструмент, а как общий метод моделирования сложных структур в изображениях, тексте, речи и других областях. Это хорошо согласуется с формулировкой Яна ЛеКуна и соавторов: «глубокое обучение позволяет вычислительным моделям, состоящим из нескольких последовательных слоёв обработки, обучаться представлениям данных на нескольких уровнях абстракции». [LeCun Y., Bengio Y., Hinton G. Deep learning / Nature. 2015]
Эти достижения привлекли внимание ведущих IT-корпораций и инвесторов, что вызвало бурный рост интереса к искусственному интеллекту по всему миру. Возникла новая инженерная экосистема — библиотеки, фреймворки и облачные сервисы, которые сделали нейросети доступными не только исследователям, но и компаниям, преподавателям и энтузиастам.
2020-е: возрождение ИИ и феномен ChatGPT
Настоящую революцию в восприятии искусственного интеллекта произвела языковая модель GPT-3 (Generative Pretrained Transformer 3), созданная компанией OpenAI в 2020 году. Эта модель обучалась на колоссальном объёме текстов и показала, что машина может не просто обрабатывать язык, а создавать осмысленные тексты, вести диалог и даже рассуждать в ограниченных формах.
В ноябре 2022 года появился ChatGPT — интерфейс, сделавший эту технологию доступной каждому. Всего за два месяца аудитория сервиса превысила сто миллионов пользователей — рекордный результат в истории интернета. Даже сами разработчики признавались, что не ожидали такого взрывного эффекта. С этого момента искусственный интеллект перестал быть уделом специалистов: он стал частью повседневной жизни — вошёл в образование, бизнес, журналистику и творчество.
Вслед за OpenAI крупные корпорации запустили собственные проекты, основанные на GPT-подобных архитектурах. Одновременно появилось множество платформ, облегчающих использование нейросетей без технической подготовки: от инструментов для генерации изображений до систем написания кода, анализа и визуального представления данных. Параллельно менялось и понимание социального и экономического значения ИИ. Эндрю Ын сравнил искусственный интеллект по масштабам влияния с электричеством, указывая, что в долгосрочной перспективе «почти любая отрасль будет преобразована ИИ».
Современная Российская Федерация уверенно входит в число мировых лидеров по развитию искусственного интеллекта, где ключевую роль играют крупные технологические компании, инвестирующие миллиарды рублей в ИИ-инфраструктуру, языковые модели и облачные сервисы.
Сбер лидирует на российском рынке ИИ, по оценкам исследовательских агентств, входит в число крупнейших игроков, контролируя существенную долю выручки отрасли, и инвестируя более 100 млрд рублей в год в развитие языковых моделей (например, GigaChat), мультимодальных систем (таких как Kandinsky) и корпоративных платформ. По данным Brand Finance Global 500 (2021), Сбер вошёл в тройку сильнейших брендов мира по силе (BSI 92,0/100, рейтинг AAA+), обогнав многие европейские банки. Сбер координирует национальные ИИ-проекты, интегрируя их в свою экосистему — от платформ обработки данных до голосовых ассистентов «Салют».
Яндекс занимает ключевые позиции по выручке от ИИ-решений (порядка 500 млрд рублей в 2025 году, рост почти на 50% год к году), лидируя в разработке рассуждающих моделей, таких как Алиса AI и YandexGPT, интегрированных в Поиск, облачные сервисы и автономный транспорт. Компания также развивает системы для бизнеса, включая платформы класса AI Studio.
Основы работы искусственных нейросетей
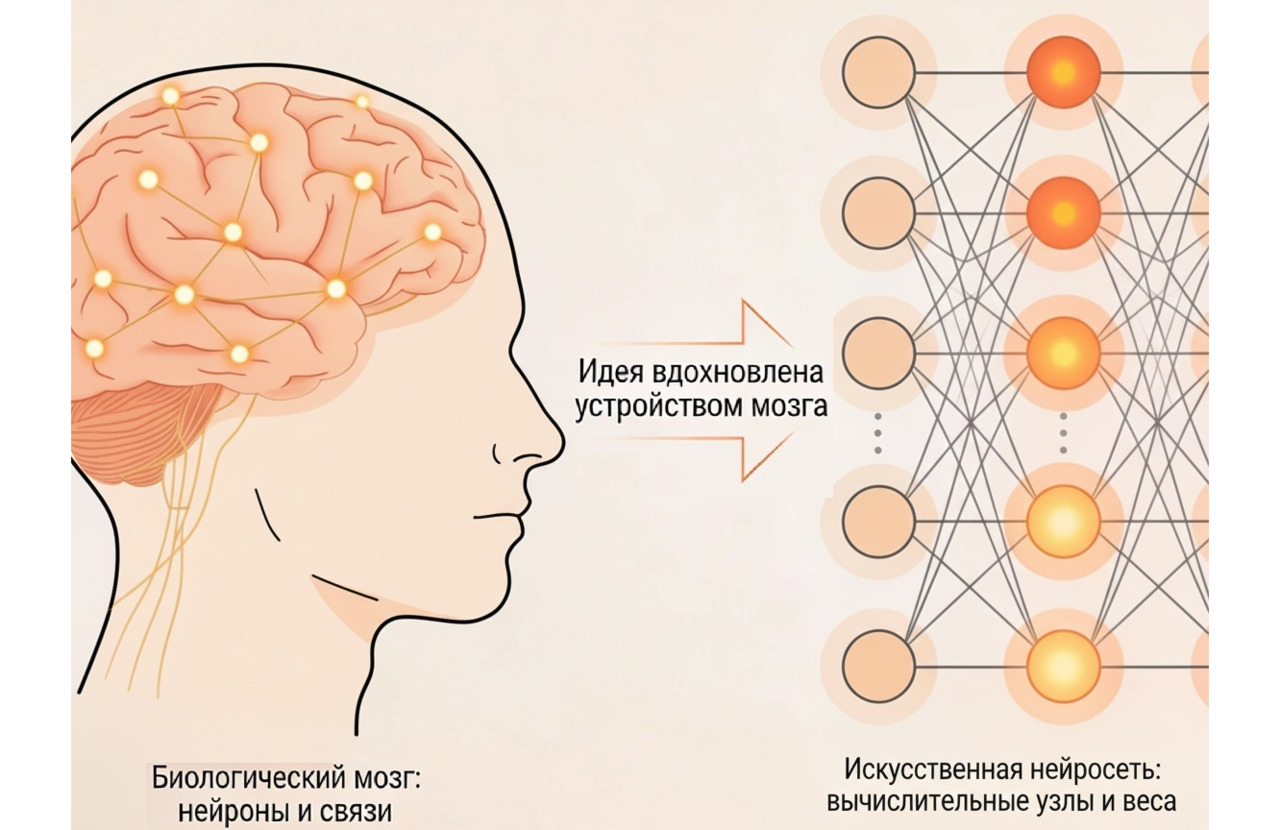
Искусственные нейронные сети (ИНС) представляют собой семейство моделей, которые используют множество простых, но массово взаимодействующих вычислительных элементов для аппроксимации сложных зависимостей в данных. Концептуально они вдохновлены устройством биологического мозга, но по своей природе являются строго математическими объектами, оперирующими векторами, матрицами и функциями активации. Нейросети состоят из множества искусственных нейронов, связанных между собой и формирующих слои, которые преобразуют входные данные, выявляя скрытые закономерности и зависимости, позволяющие системе «учиться» на примерах и самостоятельно находить решения сложных задач — от распознавания речи и изображений до анализа текстов, прогнозирования и творчества. В отличие от традиционных алгоритмов с жёстко заданными правилами, нейросети формируют внутренние представления (features) на основе примеров, что делает их особенно полезными в задачах, где явные правила сформулировать трудно или невозможно.
Основные элементы нейросети: от нейрона до архитектуры
Нейрон, веса и функция активации
Базовая единица ИНС — искусственный нейрон — получает на вход набор чисел, вычисляет взвешенную сумму и пропускает результат через функцию активации, которая «решает», насколько сильным будет отклик. Весами называются параметры, управляющие тем, какие входы для модели значимее; именно они меняются в процессе обучения.
Реалистичный пример: отзывы о спектаклях. Для нейрона, отвечающего за «позитивность», слова «прекрасный», «сильная игра», «рекомендую» получают высокие положительные веса, а слова «скучно», «затянуто» — веса, усиливающие сигнал «негативности». Функция активации (например, ReLU) отсеивает слабые сигналы и усиливает значимые, что помогает модели не «реагировать» на случайный шум.
Нейроны объединяются в слои:
• входной слой принимает данные (векторизованный текст, признаки изображения и т. д.);
• несколько скрытых слоёв последовательно извлекают более абстрактные признаки;
• выходной слой формирует итоговое решение — класс текста, вероятности эмоциональных меток, предсказанное число.
Слои и глубина модели
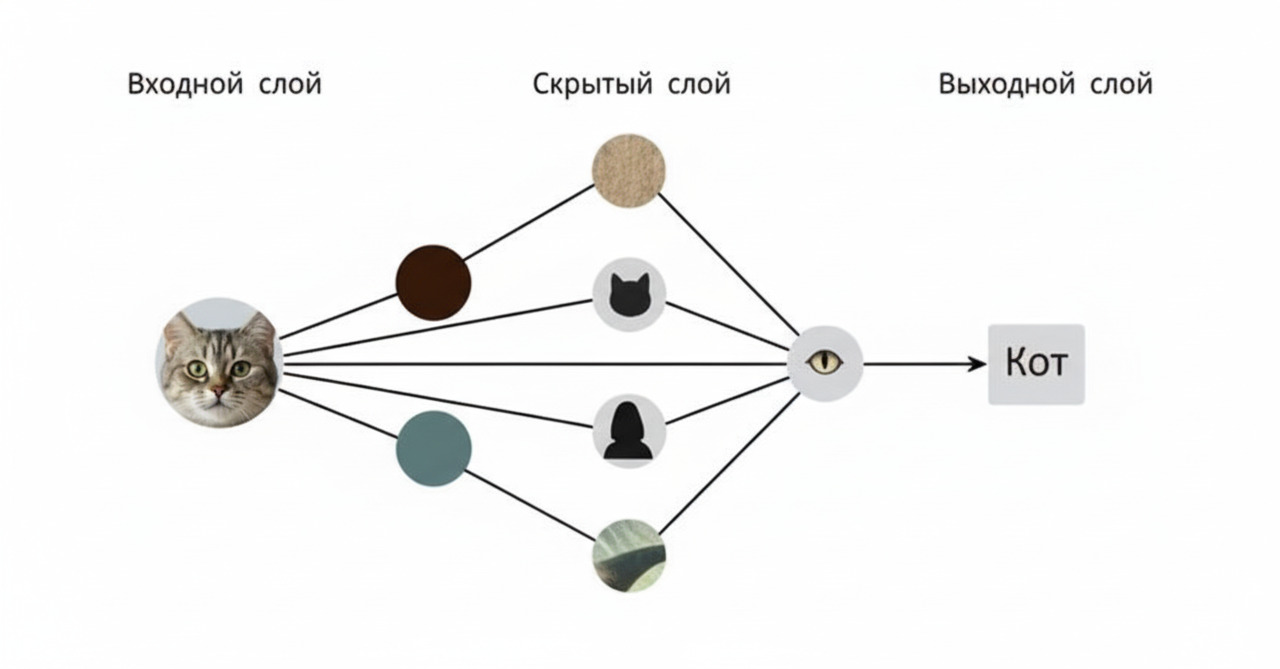
Глубокими называют сети с множеством скрытых слоёв; именно они позволяют моделировать сложные, многослойные зависимости, например переход от букв к словам, от слов к высказываниям, от высказываний к «темам» или дискурсам. Для гуманитария важно, что на разных уровнях модель «видит» разные аспекты текста: от локальной статистики до глобальных сюжетных или стилевых паттернов.
Архитектура как «каркас» исследования
Архитектура нейросети — это способ организации слоёв и связей между ними. Выбор архитектуры определяет, какой тип структуры данных учитывает модель: последовательность (текст во времени), двумерную структуру (изображение), сеть связей (социальный граф, сеть персонажей) и т. д.
Простые многослойные перцептроны достаточны для задач, где данные уже сведены к вектору признаков, например при базовой тематической классификации.
• Свёрточные сети хорошо работают с изображениями и рукописными текстами;
• рекуррентные и трансформер-архитектуры — с последовательностями слов;
• графовые сети — с отношениями между объектами (люди, персонажи, организации).
Для гуманитарного проекта архитектура — это не техническая деталь, а методологический выбор: что именно считается «структурой» данных и какие связи между элементами важны для анализа.
Создание и обучение нейросетевых моделей
В прикладном машинном обучении можно выделить два базовых подхода к построению нейросетевых моделей.
1. Полная разработка модели «с нуля»
В этом случае исследователь самостоятельно проектирует архитектуру (выбирает тип слоёв, размерность, механизм внимания и т. д.) и обучает модель на собственных данных, начиная со случайно инициализированных весов. Такой подход:
• даёт максимальный контроль над архитектурой и целевой функцией;
• позволяет лучше адаптировать модель под специфику предметной области (например, медицинские изображения, промышленный поток данных, редкий язык);
• потенциально обеспечивает наивысший «потолок» качества, если объём и качество данных достаточны.
Однако обучение с нуля требует больших вычислительных ресурсов, значительных объёмов размеченных данных и времени на экспериментирование. Поэтому этот путь оправдан главным образом в крупных исследовательских проектах и инфраструктурных компаниях.
2. Использование уже готовой (предобученной) модели
На практике всё чаще применяют второй подход: берут уже обученную «фундаментальную» модель (foundation model) и адаптируют её под конкретную задачу. Здесь возможно несколько вариантов:
• fine-tuning — дообучение модели на новых данных, близких к целевой задаче, с частичным или полным обновлением весов;
• instruct-tuning — обучение модели следовать текстовым инструкциям пользователя;
• adapter-подходы и LoRA-тюнинг — добавление небольших дополнительных слоёв или модулей без изменения всех исходных весов.
Этот путь существенно снижает порог входа: можно использовать уже «насыщенную» знаниями модель и донастроить её на относительно небольшом корпусе данных. Такой подход доминирует в прикладных проектах, где важны скорость внедрения и экономия ресурсов
Основные парадигмы обучения нейросетей: от примеров к обобщению
Основные парадигмы обучения нейросетей: от примеров к обобщению
Эксперт в области нейросетевых технологий Эндрю Ын часто подчёркивает, что «улучшение качества данных зачастую даёт больший прирост точности, чем усложнение модели»
[Andrew Ng, интервью и колонка о data centric AI в Forbes: Andrew Ng Launches A Campaign For Data-Centric AI, 2021].
С точки зрения организации данных и обратной связи выделяют три классических типа обучения нейросетей:
1. Обучение с учителем (supervised learning)
В этой схеме для каждого объекта есть не только входные данные, но и правильный ответ (метка класса, числовое значение, целевая последовательность). Модель учится строить отображение «вход → выход», минимизируя разницу между своими предсказаниями и эталонными значениями. Примеры:
• классификация изображений (распознавание объектов на фотографиях);
• предсказание стоимости, вероятности события, тональности текста;
• машинный перевод с параллельным корпусом.
Обучение с учителем даёт высокую предсказательную точность, но требует трудоёмкой разметки данных.
2. Обучение без учителя (unsupervised learning)
Здесь модель работает с неразмеченными данными: для объектов нет заранее заданных «правильных ответов». Цель — выявить скрытую структуру данных:
• сгруппировать похожие объекты в кластеры (например, сегментация клиентов по поведению);
• обнаружить аномалии (выбросы, подозрительные транзакции);
• извлечь компактные представления, в которых сложные объекты кодируются векторами фиксированной длины.
Обучение без учителя особенно важно там, где разметка отсутствует или слишком дорога, но необходимо понять, какие типы данных вообще существуют и как они связаны между собой.
Пример: социолог загружает в модель тысячи комментариев под новостями, не помечая их темами. Сеть выявляет кластеры, в которых доминируют, например, разговоры об экономике, науке, культуре. Далее исследователь интерпретирует эти кластеры, сопоставляя машинную категоризацию с дискурсивными рамками, принятыми в его дисциплине.
3. Обучение с подкреплением (reinforcement learning)
В этой парадигме модель рассматривается как агент, который взаимодействует со средой, выбирает действия и получает отложенную обратную связь в виде «наград» или «штрафов». Цель — выработать стратегию (политику), максимизирующую суммарную награду во времени.
Классические области применения:
• обучение игровых стратегий (шахматы, компьютерные игры);
• управление роботами и автономным транспортом;
• оптимизация сложных процессов и систем (логистика, управление ресурсами).
Обучение с подкреплением позволяет моделировать последовательное принятие решений в динамической среде, но требует аккуратного проектирования среды, функции «награды» и механизмов безопасности.
Обучение нейронной сети обычно формулируется как задача оптимизации: необходимо подобрать параметры (веса и смещения), минимизирующие функцию потерь, измеряющую расхождение между предсказаниями модели и целевыми значениями. На практике это реализуется с помощью градиентных методов и обратного распространения ошибки, которые последовательно обновляют параметры, проходя по данным многократно (эпохи обучения) и постепенно снижая среднюю ошибку. Важнейшая задача — не только добиться точности на обучающем наборе, но и обеспечить способность модели обобщать знания на новые, ранее не виденные примеры, что требует контроля переобучения и тщательной подготовки данных.
Архитектуры: от простых моделей к трансформерам
Мультимодальные системы
умеют одновременно работать с текстами, изображениями, звуком и видео: одна и та же модель может, например, прочитать исторический документ, проанализировать его иллюстрации и сгенерировать аудио комментарий для музейного аудиогида. Для гуманитарных наук это означает переход от изолированного текстоцентричного анализа к комплексной работе с культурными артефактами разных форматов. Например, ChatGPT — это мультимодальная модель, которая архитектурно объединяет в себе несколько нейросетевых компонентов.
Открытые и полуоткрытые модели
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.