
Бесплатный фрагмент - Искусственный интеллект. Строки, контекст и волны на Паскале

«Обучение путем подачи хорошего примера часто — самый эффективный, а иногда — и единственно возможный метод.»
Никлаус Вирт, создатель языка Паскаль.
«Меня не интересует создание мощного компьютерного интеллекта. Мне вполне хватило бы самого посредственного — примерно как у президента Американской телефонной и телеграфной компании.»
Приписывается Алану Тьюрингу
Предисловие, которое рекомендуется прочитать
Учебные заведения России и мира продолжают обучать программированию на Паскале. И это происходит не из-за лени преподавателей к переизданию методических пособий по информатике. Такое обучение позволяет понять гибкую внутреннюю логику организации программ, ведь Паскаль обладает свойствами универсальности и широкими возможностями, при своей компактности и легкости понимания. С помощью этого языка программирования можно адаптировать, подготовить восприятие школьника или студента для самоорганизации и в других языковых средах.
Поэтому в этой книге автор изложил полезные и практичные аспекты накопленного многолетнего опыта, приемы и методы работы с неформализованными строковыми данными на Паскале; а также сведения о новой технологии, являющейся плодом этих практических изысканий. Модель описанной технологии искусственного интеллекта, в качестве исследовательского проекта также реализуется на этом языке. При этом, значительная часть приведенных алгоритмов и программных процедур публикуется впервые, что придает изданию особую ценность.
Почему эта книга актуальна?
Вся беда в том, что профессиональным приемам подробной, прикладной работы с данными строкового типа занимается очень ограниченное число специалистов. Отсюда вытекает явный недостаток практических пособий по данной тематике, и как следствие — неявный прикладной функционал в современных языковых компиляторах. Также этому есть и другое вполне логичное объяснение. Тема парсинга строковых данных много десятилетий являлась своего рода табу, дурным тоном программирования. Традиционно устоялся стереотип, что строковые переменные — это «рабы интерфейса» и баз данных, а неформализованные сведения — зло, с которым нужно бороться. Результат — налицо: отсутствие приличной школы: как учителей, разработчиков, так и их учеников. Отсутствие предложения за много десятилетий сформировало зеркальное отсутствие спроса. А затем появились и искусственные нейронные сети, которые худо-бедно начали с этими данными работать; но вот разработчикам от этого не стало легче. По существу, искусственные нейросети «подарили» программистам «черный ящик», действия которого бывают необъяснимы.
Этот пробел явно требует компенсации; тем более, очевидно невостребованной в современной парадигме когнитивных систем оказалась ниша символьного искусственного интеллекта.
В книге приводятся необычные, но достаточно простые решения по проекту интеллектуальной символьной диалоговой системы. Тем не менее, описанные подходы к ее реализации категорически отличаются от классического представления об объектно-ориентированном программировании, традиционных символьных экспертных систем и от современной методологии машинного обучения. Также весьма существенным моментом в этой работе является отказ от прямого использования символьных конструкций на естественном языке. Тем не менее, практические результаты показывают, что этот комплекс методик может решать задачи, по сей день считавшиеся серьезной проблемой.
Чем мы занимаемся?
«Мы» в данном случае — это небольшое сообщество единомышленников, не входящих в какое-либо формальное объединение, но захваченных идеей реализации искусственного интеллекта на базе технологии MSM.
Сверхзадачей исследований в данном направлении не являлось и не является создание сильного искусственного интеллекта в понимании современных физиков и инженеров; (такого, который будет многократно превосходить умственные способности людей). Для начала, следовало бы создать «средний» интеллект. Такой, каким обладает например, ваш сосед, Михаил Ефремович, учитель географии средних лет. Особо ничем не выдающийся, иногда не очень внимательный или рассеянный, иногда циничный, иногда смешной, но… понимающий. Способный сравнивать, оценивать, делать выводы, формулировать суждения. Решать повседневные задачи. Планировать, следовать определенным целям. И главное, способный действовать так, как этого требуют обстоятельства. Вы скажете, такие машины уже есть? Хорошо, если вы так считаете, не будем спорить. Но, автор считает, что нет.
Это учебник?
Книгу можно использовать как учебное пособие по разделу строковых данных на Паскале. Но было бы неверно воспринимать показанные решения, как нечто неоспоримое, — любая приведенная процедура может быть усовершенствована. Сама природа строк приближает нас к другой форме подхода к методикам реализации. Здесь, в этой новой реальности открывается то, что называется нечеткостью, субъективной оценкой и многогранностью связей элементов конструктора, который мы можем выстраивать.
Книга затронет и некоторые философские, психологические, лингвистические аспекты сущности человеческого восприятия. Но она не станет тешить человеческое самолюбие или рисовать утопические миры. На этом поле и без того работают слишком много мастеров слова, чтобы стать только очередным из них. Автору это неинтересно.
Гораздо интереснее работа, имеющая под собой практическое основание, а не метафорические рассуждения. «Практика есть критерий истины» — известное выражение, приписываемое Карлу Марксу, но авторство в данном случае не имеет значения.
Эта книга пробует осветить шаг за шагом движение в новом, малоизученном направлении работы с новой технологией. Страница за страницей практического освоения вы имеете шанс испытать чувства первооткрывателя, какие вероятно испытывал Левенгук, настраивающий первый оптический микроскоп. И пусть спустя сотни лет был построен и микроскоп электронный, но микроскоп конструкции Левенгука был самым важным, первым шагом в нужном направлении.
С другой стороны, кто-то мог бы и сказать «Да обернитесь вокруг: в нашем мире data science, блокчейна и искусственных нейросетей нет места для того, чтобы заниматься какими-то символами…» Но вещь, кажущаяся сегодня слишком простой или неочевидной может стать завтра тем самым электронным микроскопом. История знает массу таких примеров.
Например, концепция первого перцептрона, на основании которой родилось все изобилие современных искусственных нейросетей и машинного обучения более чем на 30 лет была подвергнута остракизму во время так называемой «Зимы искусственного интеллекта». И что бы сказали бывшие критики перцептрона теперь, когда каждая домохозяйка, школьник или пенсионер, имея некоторый интерес и немного свободного времени может настроить искусственную нейросеть и сортировать огурцы по 12 критериям в собственном гараже.
Можно освоить вещи и поинтереснее огурцов, например машинный перевод, зрение сквозь стены или толщи океанских вод… Но автор в данном случае равнодушен по отношению к искусственным нейросетям, к биг-дате или к попыткам создавать коннектоны. Безусловно, это в своем роде интересные, нужные и незаменимые вещи, представляющие немаловажный научный и коммерческий интерес. Плохая новость состоит в том, что все это имеет мало общего с настоящим интеллектом, который основан на процессе понимания смысла. Да, искусственные нейросети хорошо работают. Выписывают штрафы. Рисуют картины. Консультируют по ряду известных проблем. Играют в шахматы, Го или водят машины. Они это все умеют или будут уметь; и ваша сетка будет уметь гораздо лучше сортировать огурцы, чем человек, — с помощью нескольких строк кода, небольшой настройки переменных и нескольких тысяч примеров выборки. Это — сложная, но популярная и вполне осуществимая задача в рамках существующей парадигмы машинного обучения. Кроме того — уже изданы сотни прикладных учебных пособий по этой теме, существуют простые видеоинструкции по работе с кодом на Питоне и в свободном доступе находятся нужные приложения и наборы данных.
То, о чем говорит эта книга — трудно. Требует умственного труда, фиксации внимания, сосредоточенности. Эта книга — для тех, кто привык использовать критическое мышление, ставить все под сомнение, моделировать собственную реальность, а не идти вперед за общественным мнением.
Кого-то эта книга может развлечь, кого-то заставит задуматься или по-новому взглянуть на информационные технологии. Возможно — кто-то сделает интересный учебный проект, доклад, презентацию или реферат, за который может получить хорошую оценку. А кто-то, (и на это хочется надеяться), использует описанные методы, чтобы участвовать в приближении лучшего будущего с машинами, имеющими сознание. При этом, не будет иметь значения язык реализации, — все описанные методики могут быть переведены на любой язык программирования для достижения лучших показателей в скорости, адаптивности или коммерческой ценности.
Что здесь интересного?
Во-первых, эта книга является практическим руководством по работе со строковыми данными и может выполнять роль «решебника» для разного типа задач; во-вторых, она рассказывает о новой технологии, (в которую автор оказался замешан практически поневоле); и в-третьих — она затрагивает различные аспекты и неординарные подходы к проблеме сильного искусственного интеллекта.
При этом автор не станет говорить о чем-то невозможном. Любые части повествования будут относиться только к тем вещам, которые действительно существуют или к тем, которые могут быть созданы.
Вначале мы поговорим о представлении строковых данных на Паскале и о том, какие необычные процедуры и функции можно использовать, чтобы решать неординарные задачи, из разряда олимпиадных задач по информатике. Вероятно, эта часть особенно понравится школьникам и студентам, ведь здесь будет описано множество подпрограмм, имеющих прикладное применение.
Также мы вспомним о том, что такое альтернативная классификация данных в многомерном строчном множестве и каковы могут быть приемы работы с ними.
Далее, мы сосредоточимся на том, чтобы немного разобраться в действующих диалоговых интеллектуальных системах, постараемся понять их сильные и слабые места, разберем их «по винтикам» и порассуждаем, «как это работает?»
Во второй половине книги будут приведены новые методы работы с полисемией и контекстом, в чем нам поможет волна предложений, адаптированный толковый словарь и еще немного мозгового усердия.
И наконец, в завершении мы постараемся сконструировать систему, (пока только в теории, но со значительной степенью детализации) претендующую на звание «сильной логической машины». В частности, здесь мы поговорим о гештальт-цикличности, теориях физики мышления и связи логики, языка и интеллекта.
Кстати, в книге вы не увидите отсылки в приложения (чего так не любят многие читатели): все процедуры и функции описываются в разделе соответствующей тематики прямо по ходу повествования с приведением иллюстраций, показывающих, что происходит на экране компьютера.
О чем речь?
Это повествование является не столько логическим продолжением первой книги автора, сколько изложением «обратной стороны» практического программирования, комплекса приемов, демонстрирующих структуру программы обработки строковых данных «с нуля».
Книга «Искусственный интеллект: начала MSM», вышла в начале 2018 года. Она рассказывает об основах перспективной технологии в построении искусственного интеллекта — многомерном строчном (строковом) множестве (или «Multidimensional Strings Multiplicity», англ.). Простая программная среда, построенная на основе специфического классификатора всего за год с небольшим своего существования показала замечательные результаты, в связи с чем автор посчитал важным продолжить публикацию данных, а также методов и технологий, реализуемых в этом проекте.
В новой книге автор расскажет и о технологических приемах, использующихся в программной модели для решения наиболее сложных проблем «понимания» естественного языка. В первую очередь это касается вопросов полисемии и контекста, которые чаще всего, (а может быть и по привычке), считаются в ЭВМ непреодолимыми.
Что потребуется?
Все приведенные в качестве примера процедуры и функции реализованы на языке Pascal, а точнее, в бесплатном компиляторе TMT Pascal lite. Выбор автора оказался на стороне этого компилятора отнюдь не случаен. Это один из немногих компиляторов Паскаля, позволяющих использовать во внутренних процедурах и функциях входные и выходные массивы переменных строчного, логического и целочисленного типа. Кроме того, TMT Pascal известен, доступен и понятен настолько, что строить простые программные модели, обрабатывающие строковые массивы данных не доставит большого труда.
Споры об MSM
Технология MSM — вещь своенравная. Первые публикации о ней в сети в начале 2018 года были восприняты с подозрением, а иногда и с недоумением. Под сомнение ставилась как сама технология, так и квалификация автора, мол «Куда ты, блогер, сунулся в калашный ряд?» Но были среди критических замечаний и вполне корректные, достойные рассмотрения.
Особенно часто оппонентам автора вспоминался Курт Фридрих Гедель, австрийский математик и философ с его теорией о неполноте, а также интерпретация этой теории физиком и математиком Роджером Пенроузом в контексте принципиального различия между человеческим мозгом и компьютером. Мы не будем сильно беспокоить Геделя, поскольку систему MSM, едва ли можно назвать математически формальной.
Основой MSM является иерархическая онтология, которая строится в соответствии с интуитивной, смысловой, неформализованной «нагрузкой» понятий, их синонимов, весов, отношений и правил. Иерархия имеет комплементарный код каждого элемента, не имеющий фиксированной числовой разрядности, который построен по принципу бесконечности и многомерности. В словарях, организованных по принципу MSM программная модель оперирует не конкретными словами, а их смысловым кодом, и действует на основе подбора правил, выбранных в соответствие с конкретными ситуациями. Также в логике MSM реализован механизм, который позволяет уйти от математической, компьютерной точности в сторону нечеткости, адаптивности к конкретным условиям. Этот механизм помогает определять близкие понятия, находить родство и различия слов-множеств на основании онтологических связей, фактически вшитых в код понятий, в противовес четкому математическому сходству формального написания слов на естественном языке.
В книге «Искусственный интеллект: начала MSM» приводился простой пример, когда эталонное знание «Кошачьи имеют красивую шерсть» автоматически порождает новые знания о том, что «У киски есть красивая шерстка» или «У льва есть прекрасная грива», и еще сотен подобных. Этот процесс совсем не похож на математичный. Первоначально введенные данные, формально, математически, совершенно отличаются от проверочных, и тем не менее программа находит их идентичными, поскольку связи объектов, вшитые в коде, и правила обработки позволяют это сделать.
Конечно же, подобный результат можно было бы получить и посредством обычного объектно-ориентированного программирования (ООП), однако относительно энергозатрат в данном случае MSM оказывается в безусловном выигрыше за счет комплементарности кода понятий и общей простоты организации системы. На следующем примере также видно принципиальное отличие в построении классификатора традиционной семантической сети (рис. 1) и MSM (рис. 2).
В отличие от традиционного решения семантической сети и вариантов объектного программирования, в которых сеть связей элементов описывается с помощью дополнительных описательных блоков, не обладающих комплементарными зависимостями, элементы в MSM входят в единую структуру, где каждый из них обладает «памятью предков», а кроме того «отягощен» свойствами и «отношениями». Эта структура обладает безграничной глубиной связей, «зашитой» в самом коде элементов. На рисунке — показан лишь микроскопический фрагмент, примерно 1/10 000 доли реального объема структуры, которая кодируется с помощью этих простых правил.
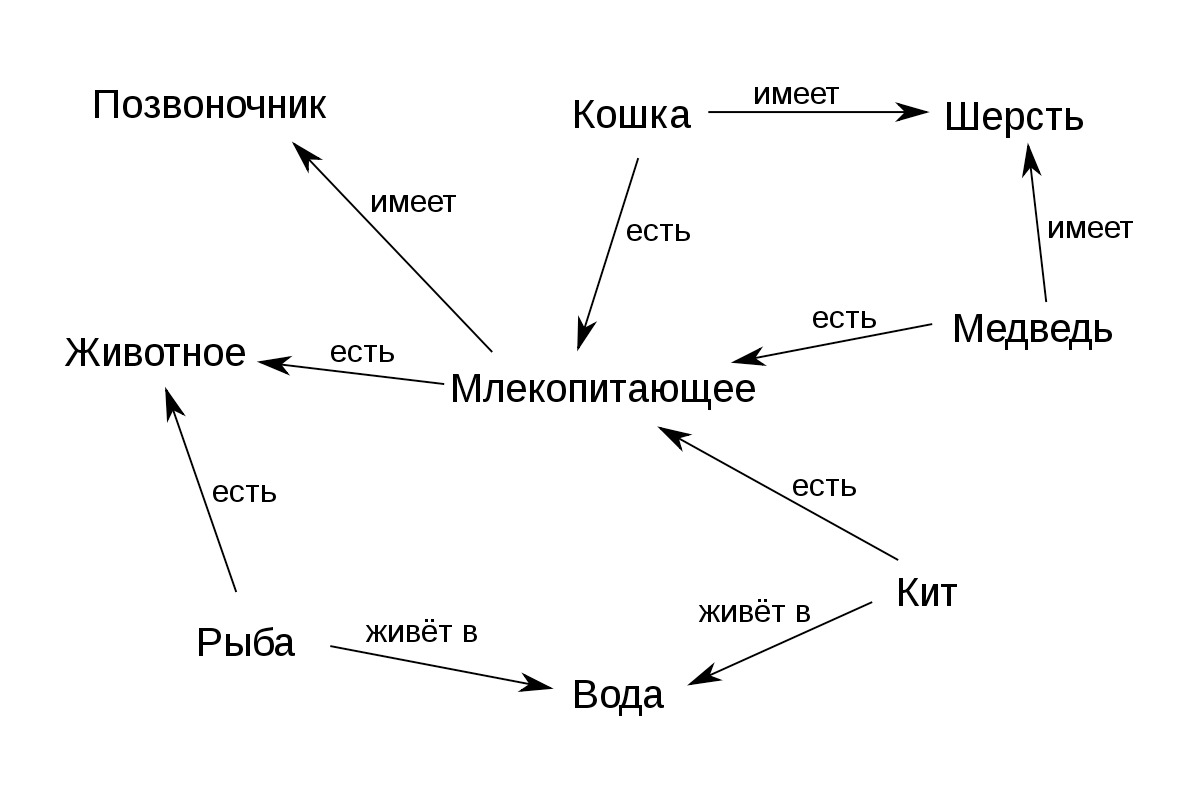
Кроме того, во взаимоотношениях элементов MSM играют немаловажную роль дополнительные словари зависимостей, весов и свойств, позволяющие с помощью минимальных средств строить сложные логические конструкции, обобщающиеся на целые классы значений.
Приведенный фрагмент классификатора занимает минимальный объем памяти, составляющий менее (!) 1 килобайта. За счет подобной реализации в перспективе можно достигнуть возможностей мощной логической машины, имеющей ничтожный объем в десятки или сотни мегабайт. Так приложение на основе MSM сможет работать даже в обычной бытовой технике вроде холодильника или микроволновки.
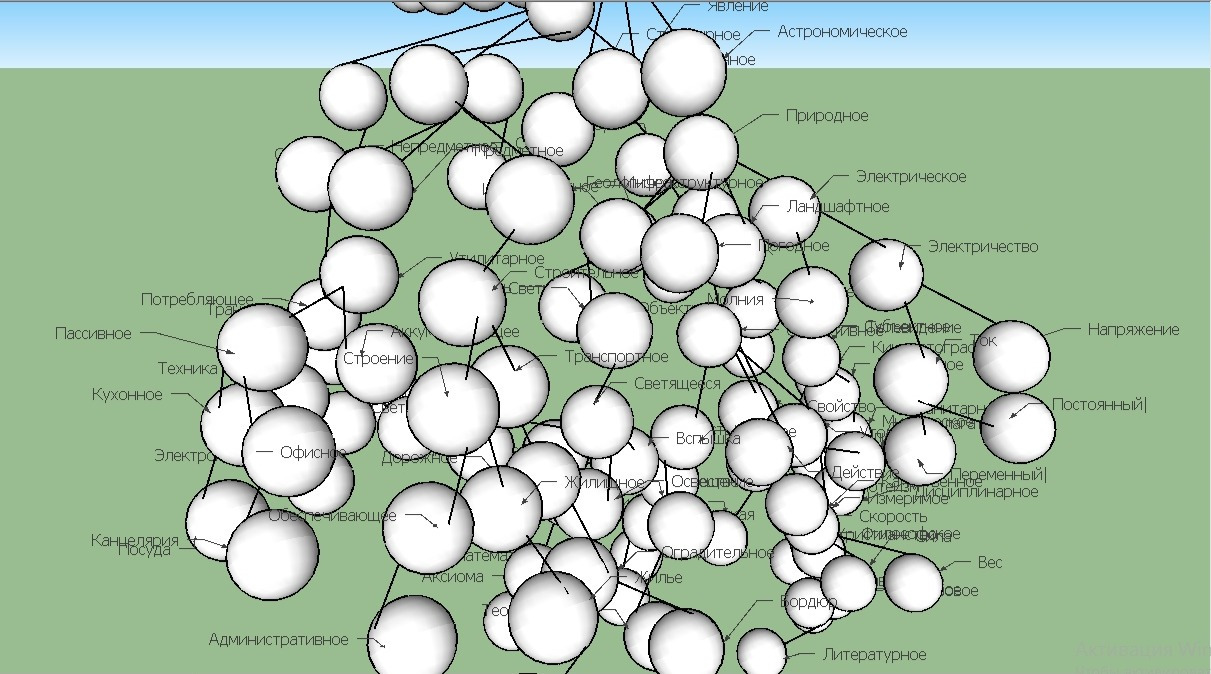
(Правда, насколько для потребителя может быть актуальна «понимающая» смысл языка микроволновая печь — это большой вопрос, но почему бы и нет?)
Но возвращаясь к теории Геделя, а точнее, к ее интерпретации, сам Роджер Пенроуз отчасти соглашается с вероятным сценарием построения сильного искусственного интеллекта: «Наше непонимание человеческого сознания говорит о наличие большого пробела в научных знаниях и этот пробел, возможно, находится там, где теории нужно выйти за пределы вычислительной системы».
Вот еще цитата из его книги «Тени разума»:
«В современной научной картине мира отсутствует один очень важный ингредиент. Этот недостающий ингредиент совершенно необходим, если мы намерены хоть сколько-нибудь успешно уместить центральные проблемы мыслительных процессов человека в рамки логически последовательного научного мировоззрения. Я утверждаю, что сам по себе этот ингредиент не находится за пределами, доступными науке, хотя в данном случае нам, несомненно, придется в некоторой степени расширить наш научный кругозор…»
Не является ли MSM тем самым недостающим звеном, пробелом в науке, выходящим за рамки математических вычислений? Ведь зависимости, образующиеся в этой технологии в большей степени функциональны только по причине организованных «вручную» связей, основанных на смысловой «нагрузке» языка, а также их отношений? Нематематические «вычисления» следуют контексту естественного языка, который выступает носителем смыслов, весов, свойств и отношений между элементами; и система MSM в достаточной степени удовлетворяет полноте отражения этих отношений.
Возвращаясь к рассуждениям в книге «Тени разума», можно сделать вывод, что Пенроуз в своем видении вычислительной модели опирается на математизм подхода к рассмотрению идеи воплощения искусственного интеллекта. Суть же метода MSM состоит в парсинге сходства и различия объектов и использовании правил обработки не только относительно конкретных элементов, но и в отношении классов объектов и фраз, предложений, составленных из классов моделей. Похожие процессы происходят и в искусственных нейросетях, которые также основаны на приципе поиска сходства и различий, однако диалоговые нейросети используют для своих операций слова, фразы и предложения естественного языка, тогда как MSM оперирует их смысловым кодом, заимствованным из понимания естественного языка.
Но другой вопрос состоит в том, является ли сам человек эталоном смысла и интеллекта? И возможно ли, анализируя смысловую нагрузку языка, достигнуть более высоких интеллектуальных результатов, чем у среднестатистического человека, как это видится многим нашим современникам?
Еще одна цитата Пенроуза в этом месте кажется весьма уместной: «Мы уверены, что являем собой апофеоз интеллекта в царстве животных, однако этот интеллект, по всей видимости, оказывается самым жалким образом не способен справиться с множеством проблем, которые продолжает ставить перед нами наше собственное общество».
Таким образом Пенроуз понимает, что человеческий интеллект несовершенен. И как вы помните, наша задача в конструировании MSM видится скорее в воссоздании модели человеческой логики в программной модели, нежели в создании сверхинтеллекта. Объективное человеческое несовершенство является частью человеческой сущности; в связи с чем рано или поздно нам не избежать его воплощения, частичного или полного в электронно-вычислительной машине.
Почему этот вывод становится нам очевидным? Напомню, что посыл реализации диалоговой модели на основе MSM состоит в том, что человеческое мышление и символьный язык по существу неотъемлемы, как утверждает, в частности, Ноам Хомски. И хотя этот тезис неоднозначен, но он хорошо аргументирован, ведь мышление без языка — это набор рефлективных зависимостей, бихевиористический подход, способный решать лишь узкий набор задач, отвечающих за реакцию на положительное подкрепление. Находить выход в лабиринте, избежать столкновения, выиграть в шахматы или Го, — это все замечательные примеры реализации статистических, а иначе говоря, математических методов в построении искусственного интеллекта. И даже те современные системы, которые направлены на работу с естественным языком (например, переводчики или боты-консультанты) по существу не оперируют смыслом языка, а производят лишь внешнюю, автоматную, формальную обработку статистических зависимостей того или иного написания слов. Однако они не «понимают» принципиальной разницы между кукурузой и кузнечиком, не могут сказать, кто быстрее или умнее, не различают позитивных и отрицательных факторов; а ведь эти вопросы по существу является сутью мышления.
В пользу этой точки зрения стоит привести несколько фрагментов из статьи «Ноам Хомский: где искусственный интеллект пошел не туда?»:
«… Ноам Хомский и его коллеги работали над тем, что впоследствии стало называться когнитивной наукой — открытие ментальных представлений и правил, которые лежат в основе наших познавательных и умственных способностей. Хомский и его коллеги опрокинули доминирующую в тот момент парадигму бихевиоризма, возглавляемую гарвардским психологом Б. Ф. Скиннером, в которой поведение животных было сведено к простому набору ассоциаций между действием и его следствием в виде поощрения или наказания.
…В мае 2011 года, в честь 150-летней годовщины Массачусетского технологического института, состоялся симпозиум «Brains, Minds and Machines» («Мозги, умы и машины»), на котором ведущие ученые-информатики, психологи и специалисты в области нейронаук собрались для обсуждения прошлого и будущего искусственного интеллекта и его связь с нейронауками. Подразумевалось, что собрание вдохновит всех междисциплинарным энтузиазмом по поводу возрождения того научного вопроса, из которого и выросла вся сфера искусственного интеллекта: Как работает разум? Как наш мозг создал наши когнитивные способности, и можно ли это когда-либо воплотить в машине?
Ноам Хомский, выступая на симпозиуме, не был преисполнен энтузиазма. Хомский раскритиковал сферу ИИ за принятие подхода, похожего на бихевиоризм, только в более современной, вычислительно- сложной форме. Хомский заявил, что опора на статистические техники для поиска закономерностей в больших объемах данных маловероятно даст нам объяснительные догадки, которых мы ждем от науки. Для Хомского новый ИИ — сфокусированный на использовании техник статистического обучения для лучшей обработки данных и выработки предсказаний на их основе — вряд ли даст нам общие выводы о природе разумных существ или о том, как устроено мышление. Эта критика вызвала подробный ответ Хомскому со стороны директора по исследованиям корпорации Google и известного исследователя в области ИИ, Питера Норвига, который защищал использование статистических моделей и спорил о том, что новые методы ИИ и само определение прогресса не так уж далеки от того, что происходит и в других науках. Хомский ответил, что статистический подход может иметь практическую ценность, например, для полезной поисковой системы, и он возможен при наличии быстрых компьютеров, способных обрабатывать большие объемы данных. Но с научной точки зрения, считает Хомский, данный подход неадекватен, или, говоря более жестко, поверхностен.
«Мы не научили компьютер понимать, что означает фраза „физик сэр Исаак Ньютон“, даже если мы можем построить поисковую систему, которая возвращает правдоподобные результаты пользователям, вводящим туда эту фразу…»
Еще раз уточним: задачей-минимумом нашего сегодняшнего исследования остается реализация диалоговой системы, близкой к человеческой модели мышления. И есть надежда, что технология MSM является принципиально новым подходом, способным дать нам новую пищу, иной способ исследования; вдохнуть новую жизнь в парадигму искусственного интеллекта как символьной системы, (но — не системы на естественном символьном языке).
Глава 1. Строковые процедуры и функции на практике
Подготовка к работе в TMT-Pascal
Все, что нам первоначально потребуется для работы — скачать и установить программу компилятора TMT-Pascal.
Это можно сделать бесплатно, например, отсюда: http://pascal.sources.ru/tmt/download.htm.
Здесь можно выбрать, например, версию TMT Pascal Lite v.3.90, которая подходит для реализации наших задач.
Далее, для работы с русским языком в DOS-приложениях, нам понадобится произвести некоторые предварительные настройки. На 32-битной Windows:
В Windows XP:
В командной строке меню «Пуск» набираем команду «Regedit». Далее, вносим изменения: HKEY_LOCAL_MACHINE -> SYSTEM -> CurrentControlSet -> Control -> KeyboardLayout
Здесь нужно изменить значение ключа 00000409 в папке DosKeybCodes на «ru».
Также, в файле autoexec. nt, расположенном в Windows\system32, надо добавить строку «lh %SystemRoot%\system32\kb16.com ru». После перезагрузки переключение раскладки клавиатуры в DOS-приложениях будет производиться комбинациями Ctrl+Left Shift (английская) и Ctrl+Right Shift (русская). Упомянутый метод нормально работает в том случае, если Language settings for the system в качестве Default стоит Cyrilic.
В Windows 7:
В файле Windows/sistem32/autoexec. nt вписать строки:
«lh %SystemRoot%system32dosx
lh %SystemRoot%system32kb16.com ru
set clipper=F80»
В файле Windows/sistem32/config. nt вписать:
«files=80; buffers=99».
В командной строке в меню «Пуск» через команду «rehgedit» редактируем реестр:
HKEY_LOCAL_MACHINE -> SYSTEM -> CurrentControlSet -> Control -> Keyboard Layout
DosKeybCodes изменить значение параметра 0000409 на ru
Раскладка будет переключаться сочетаниями клавиш:
русский — правые Shift+Alt; английский — левые Shift+Alt.
В Windows 10:
Не требует изменений в реестре. В файле Windows/sistem32/autoexec. nt добавляем строчку — "%SystemRoot%/system32/kb16 ru».
В случае если используется 64-разрядный Windows, требуется использование приложения-эмулятора для DOS-программ «DOS-box».
Строковые данные
Работе со строковыми данными всегда уделяют слишком мало внимания. Считается, что это нечто, само-собой разумеющееся и слишком понятное, чтобы делать на них акцент. В учебниках, самоучителях любой толщины и направленности нам сильно повезет, если им уделяется хотя бы 2 страницы.
Попробуем же восполнить известные пробелы, для чего начнем с самых азов работы со строками на Паскале.
Итак, строчные переменные и константы в Паскале описываются так же, как и любые другие, например строка S: String означает что переменная S будет хранить некий набор символов, строку (в количестве от 1 до 255).
Соответственно, декларация S: String [100] в блоке переменных обозначает, что переменная может хранить в себе последовательность элементов до 100 символов включительно. Декларировать количество символов может быть удобно, когда мы работаем с формализованными данными, например, с серией и номером документа с определенным числом символов. Но при этом следует учесть следующее: при попытке присвоения такой переменной более длинного ряда символов, не вошедшие символы будут «обрублены».
Например, описав переменную: S: String [8] следующая операция

даст в результате S=«Мама мыл» и соответственно, потерю оставшихся символов.
Также, если в одной процедуре входные или выходные переменные отличались по своему числу символов от переменных в другой процедуре или функции, компилятор вернет ошибку и укажет на разность типов переменных. В таком случае нам потребуется, чтобы число декларированных в переменных символов совпадало и не превышало 255. Если последнее условие представляет затруднения, но представляет крайнюю необходимость, помогут методы обработки длинных строк.
Длинные строки
В Паскале возможна работа с длинными строками, длина которых определяется не числовым значением первого байта строки, а замыкающим символом «#0». Ограничение в них определяется лишь объемом оперативной памяти или ее схемой адресации. Максимально возможная строка в таком случае ограничена числом в 65 535 символов; еще такие строки называют ASCIIZ-строками.
Для создания длинных строк, перед описанием программы следует включить директиву расширенных значений компилятора {X+}; так же следует включить и модуль Strings.
Сама строка описывается типом Pchar, который является символьным указателем и отвечает за хранение массива символов Char.
На следующем примере показан вывод строки из массива 600 символов. Здесь LongS — длинная строка, S-массив символов. В данном случае массив S поочередно заполняется символами A и B в зависимости от нечетности (Odd=true) или четности значений счетчика цикла i.

Далее, производится операция присвоения значений массива S переменной LongS и ее последний символ помечается символом завершения строки «#0».
Кроме того, мы можем и напрямую работать с массивами символов Char, как со строками.
В модуле Strings описываются следующие операторы для обработки ASCIIZ-строк, но мы перечислим кратко основные из них, поскольку в обычной практике они нам не потребуются:
StrCopy (S1,S2): Pchar; — Копирует строку S2 в строку S1, возвращая указатель на S1.
StrLen (S1): Integer; — Возвращает длину строки.
StrCat (S1, S2): Pchar; — Объединяет строки S1 и S2, возвращая указатель на начало строки.
StrECopy (S1, S2): Pchar; — так же объединяет строки S1 и S2, но возвращает указатель на конец строки.
StrComp (S1, S2): Integer; — Сравнивает две строки и возвращает код 0 если строки равны, положительное значение если S1> S2 и отрицательное значение если S1 меньше S2.
StrlComp (S1,S2: Pchar; L: Word): Pchar; — так же сравнивает строки, но не более числа символов, указанного в L.
StrEnd (S): Pchar — Возвращает указатель на конец строки.
StrLCat (S1, S2: Pchar; L: Word): Pchar; — функция копирует строку S2 в конец строки S1 с учетом ограничения на количество символов L.
Пример работы с массивом символов S, как с длинными строками:

В данном случае, мы присваиваем массиву значение функцией StrCopy, а затем измеряем его длину с помощью StrLen и выводим на экран.
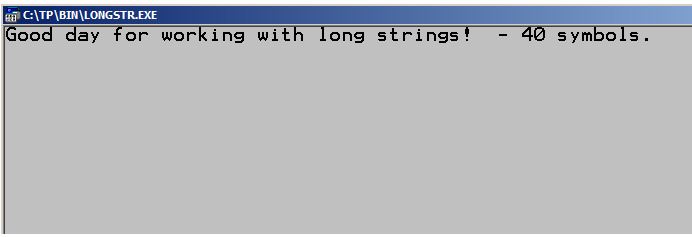
Из недостатков работы с длинными строками выделяются:
— относительно долгие операции конкатенации (объединения двух строк) и получения числового значения их длины;
— отсутствие контроля за концом строки, (что может вызывать потери данных и критические ошибки);
— невозможность использовать символ завершающего байта (#0) в качестве элемента строки;
— громоздкость синтаксиса.
По этим причинам и ввиду особой специфики работы, — большее внимание мы уделим операциям с обычными строками.
Функция поиска
Одной из базовых функций работы с переменными строкового типа является функция поиска подстроки в строке POS (S,S2), указывающая на числовую позицию первого символа подстроки.
Например, в случае

n — должна быть переменной целочисленного типа (Integer, Word или Longint) и в данном случае получит значение 6 — позицию подстроки «мыла» в строке.
Функция Pos достаточно хороша во многих случаях, однако особенностью строчных данных может быть и такой случай, когда подстрока встречается в строке несколько раз. В таком случае функция Pos вернет первое попадание в подстроку.
Например, следующее выражение

вернет значение 2, хотя символ «а» встречается здесь несколько раз и верными могли быть также значения 4, 9 и 12.
Копирование
Если нам требуется получить фрагмент текста, являющегося частью строки, можно использовать функцию Copy (S,N1,N2); Здесь N1 определяет, с какого символа будет производиться копирование, а N2 — число копируемых символов.
Например, действие

присвоит переменной S значение «мыла». Если мы изменим числовые значения, например, на «11, 4» — в переменной S окажется слово «раму»; при «1, 4» — это будет «Мама»; а при «6, 2» в переменной окажется слово «мы».
Также, одним из ключевых элементов работы с фрагментами текста является функция Length (S), позволяющая определять длину строки, чтобы не выходить за ее рамки.
Например,

присвоит переменной n значение 14 — число символов, содержащихся в строке.
Рассмотрим и возможности построения более сложных конструкций с символами.
Предположим, переменной S присвоено значение «Мама мыла раму»; но нам известно только, что в ней находится три слова (длина которых неизвестна) и необходимо получить первое слово из этой строки, отправив его в переменную S2. Это действие мы можем выполнить так:

— ведь мы помним, что функция Pos находит первое совпадение подстроки, а в начале строки пробела у нас нет. Так в S2 попадет слово «Мама».
Если же нам требуется скопировать текст, следующий за первым пробелом, эта процедура будет выглядеть несколько сложнее:

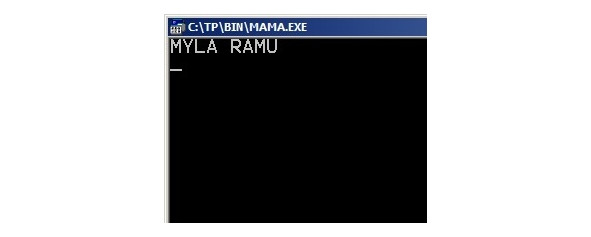
Здесь, в качестве позиции для отсчета мы берем место нахождения в строке первого пробела и копируем следующие за ним символы за минусом числа символов, следующих до пробела включительно. Проверить верность этой формулы можно в следующей программе:
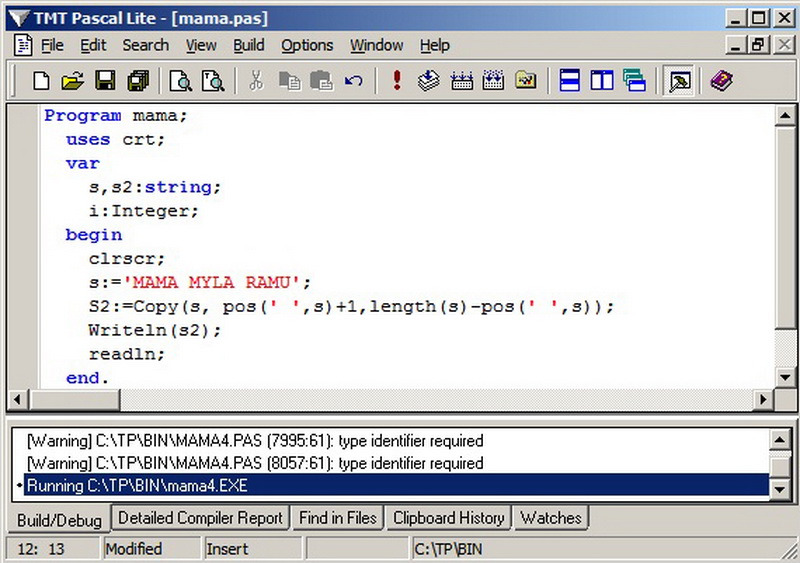
Результат — можно увидеть на экране:
Также, предположим, что нам необходимо скопировать последнее слово из строки. В данном случае, поскольку функция «Pos» нам не поможет, придется воспользоваться циклом, чтобы «вручную» установить место нахождения последнего пробела.
Контролировать конкретный символ строки можно, используя числовое значение индекса символа в строке, при этом числовой индекс указывается в квадратных скобках S [n].
Так, в упомянутой строке S [1] =«М», S [2] =«а», s [3] =«м» и т. д. Зная общее число символов с помощью функции length (S) мы можем перебором достигнуть нужного нам символа в цикле и после произвести нужную операцию. В следующей программе мы получаем последнее слово, благодаря перебору символов с «хвоста», уменьшая значение, полученное из длины строки оператором Dec (i). Так же, на всякий случай мы уточняем условие выхода из цикла в случае, если пробел так и не будет достигнут (i <1).
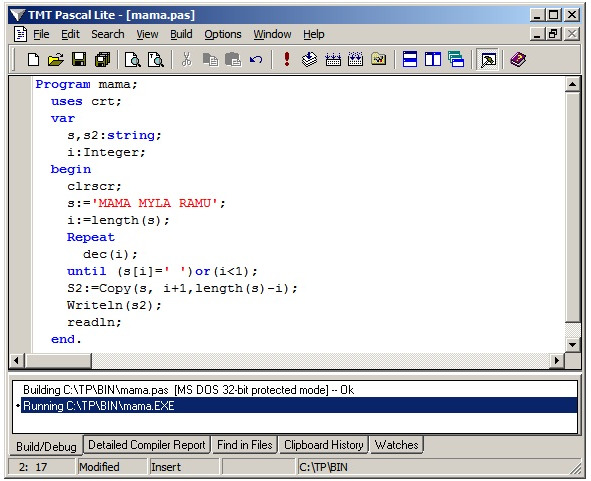
Результат удовлетворяет ожиданиям.

Почему же в примерах мы использовали английскую транскрипцию? Очень просто, — поскольку по умолчанию в компиляторе TMT Pascal используется кодировка Win, и та же программа с русским предложением внутри даст непонятный итог:
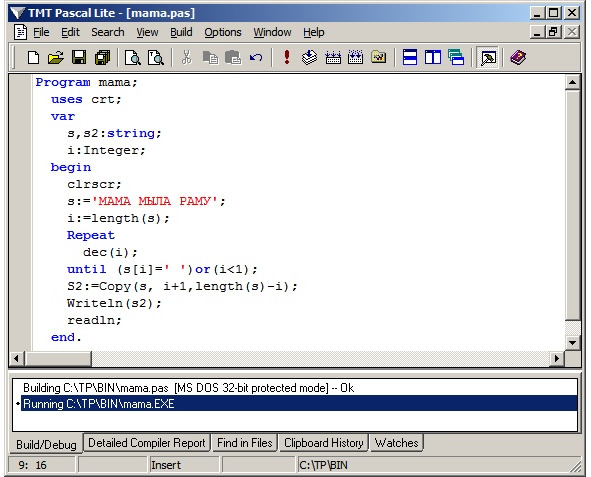
Так он будет выглядеть, несмотря на то, что формальных ошибок мы не допускали:

И это ничто иное как слово «раму», не переведенное в Dos-кодировку.
Похожий, «никакой» результат мы получим, если, например, напишем символы «а» в строке в английской раскладке, а предложение — на русском; тогда функция Pos из поиска вернет значение отсутствия символа (0), хотя визуально нам кажется, что никакого различия в написании нет.
Эти проблемы открывают целый пласт операционных задач, связанных с кодировками.
Кодировки
Ввод данных в стандартном окне программы DOS осуществляется в кодировке DOS ASCII. Также и данные, которые в нем отображаются, имеют кодировку DOS.
В случае, если нам требуется обрабатывать данные из какого-либо внешнего источника, например из приложения «Блокнот», скорее всего, потребуется перекодирование из Win-кодировки. «Скорее всего» поскольку символы цифр, пробелов, пунктуации и английских букв имеют одинаковые адресные значения как в кодировке Win, так и в DOS; но символы дополнительных языков, например кириллицы, имеют различные значения в различных кодировках. Между тем если и вывод и ввод осуществляется в фоновом режиме, и как исходные данные так и обрабатываемые находятся в одной кодировке, перекодирование из одной кодировки в другую также может и не потребоваться. (Например, в случае, когда мы принимаем в обработку данные, записанные в кодировке Win, и записываем их часть в другой файл, имеющий ту же кодировку Win).
Для разбора кодировки символов нам понадобится следующая пара функций:
CHR (x) — указывает на символ с числом X из символьной таблицы (это можно сделать и служебным обозначением «#x», например K:=#32, — в данном случае, значение k будет равно пробелу, символу с кодом «32» в соответствии с таблицей символов ASCII).
ORD (k) — возвращает код символа K из символьной таблицы.
Здесь, K имеет тип Char (символ). Операции с символами схожи с операциями со строковым типом, например к переменной строчного типа мы можем добавить символ:
S:=S+K;
Здесь, если содержимое S=«Мама мыла раму», а K=«c», мы получим значение S=«Мама мыла рамуc»;
Значения таблицы символов по величине равны одному байту, следовательно, они могут принимать численные значения в диапазоне от 0 до 255.
Чтобы вывести стандартную таблицу символов, нам понадобится следующая программа:
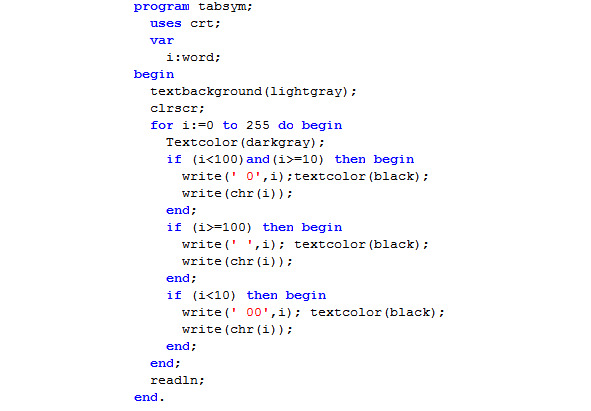
Мы несколько усложнили ее для того, чтобы получить ровную таблицу: здесь мы выделили код символа другим цветом, и добавили символы: «0» к двузначным и «00» однозначным числам.
Так мы выводим значения таблицы символов ASCII в DOS-кодировке, кроме управляющих символов с кодами «11» («vertical tab»/ «вертикальная табуляция»), «12» («form feed»/ «смена страницы») и «13» («Enter»). Также был «испорчен» управляющий символ «8», равнозначный команде удаления предыдущего символа с клавишей «Backspace».
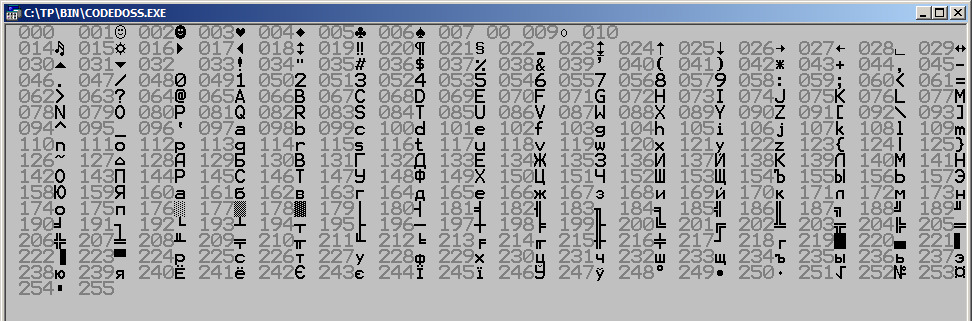
Здесь, символы с кодами до 32 являются служебными.
Кстати, из управляющих символов в будущем нам могут понадобиться:
«Тab» — #9
«Enter» — #13
и возможно, «Esc» — #27.
Несмотря на то, что они не имеют явного представления в виде конкретного обозначения, но они так же записываются в тексте, как и все остальные. То есть, взглянув на строку мы не увидим что там есть символ с кодом «13» («Enter»), но при обработке этой строки последним символом может оказаться символ с кодом «13». Это особенно важно понимать при обработке предварительно сохраненных файлов.
Что в этой таблице является очевидным: мы можем выделить значения чисел от 0 до 9 (коды 48—57); ряд символов пунктуации и специальных знаков (коды 33—47); английские прописные (большие) буквы от A до Z (коды 65—90); английские строчные (маленькие) буквы от a до z (коды 97—122); русские прописные (большие) буквы от А до Я (коды 128—159); русские строчные (маленькие) буквы от а до я (коды 160—175, 224—239) отдельно буквы Ё (240) и ё (241); и элементы псевдографики (коды 176—223).
Для простоты восприятия на рисунке ниже представлена нумерация кодов клавиш стандартной клавиатуры «QWERTY».
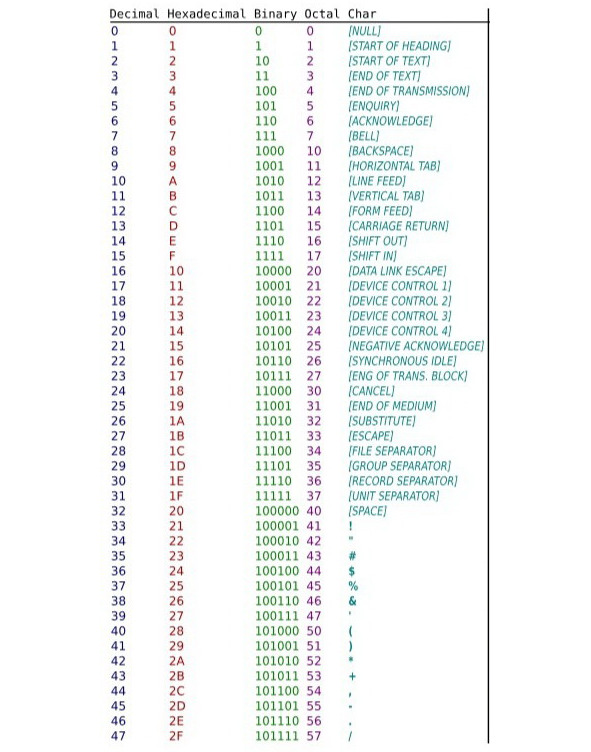
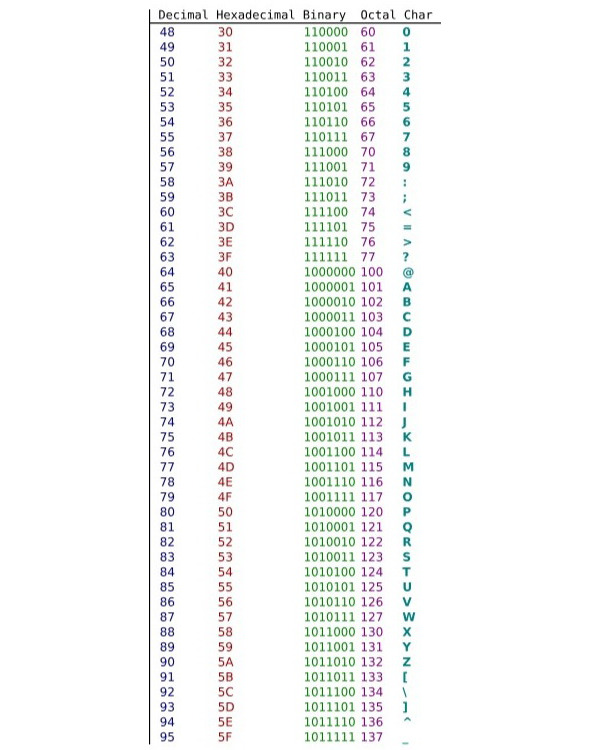
На следующем рисунке приведена базовая кодировка ASCII в двоичном, восьмеричном и символьном коде без использования дополнительных языков.
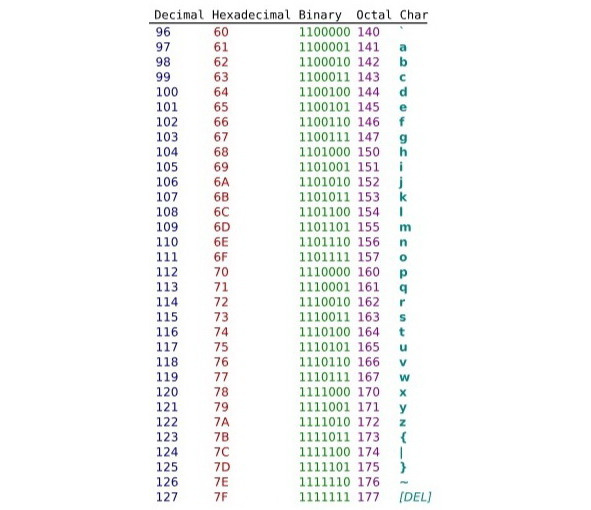
Справка:
ASCII (англ. American standard code for information interchange), — название таблицы кодировки, в которой распространённым печатным и непечатным символам сопоставлены числовые коды. Таблица была разработана и стандартизована в США, в 1963 году.
Так или иначе, если в программе нужно использовать какой-то символ, например для условия выхода из цикла, уточнить его нам поможет простая программа:
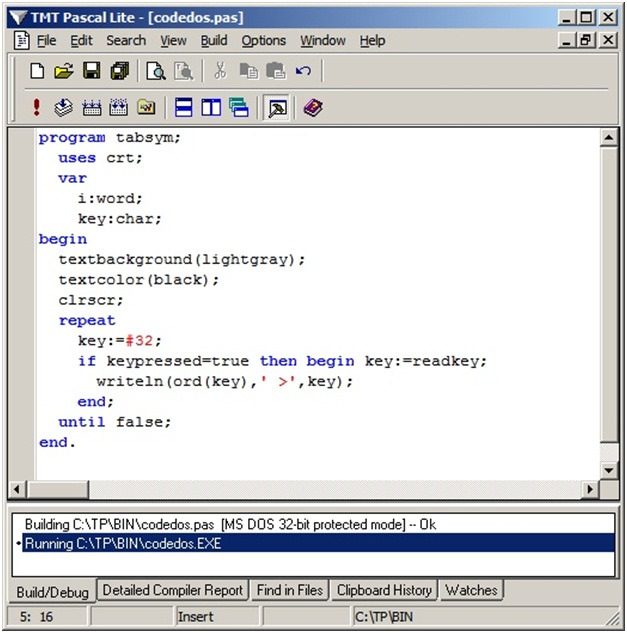
Здесь, Key — переменная символьного типа Char отвечает за нажатие клавиш и последующий вывод кода символа на экран.
Строка «If keypressed=true» — «Если нажата клавиша», то переменной «key» присваивается символ нажатой клавиши «readkey». Затем, мы выводим на экран значение символа в таблице (функция ord) и сам символ (key).
Пример ее использования:

Итак, мы разобрались с таблицей символов.
Теперь поговорим о перекодировке.
Как уже упоминалось, Win-кодировка текстового файла отличается от DOS-кодировки, но она необходима для получения данных из открытых источников и удобства представления данных.
Нормализация строк
Для перекодировки строки текста из кодировки Win в DOS нам потребуется следующая процедура DecodeToDOS:
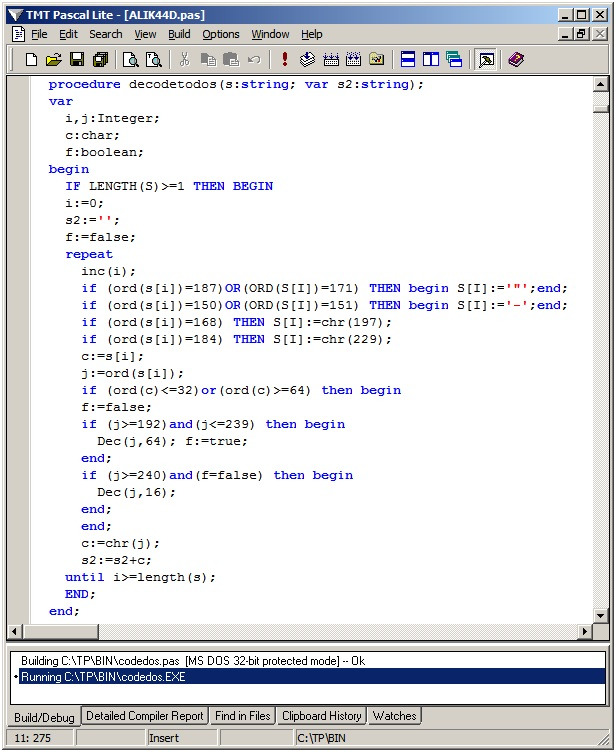
Соответственно, обратно из кодировки DOS мы можем «перегнать» текст в кодировку Win (например, для записи в файл).
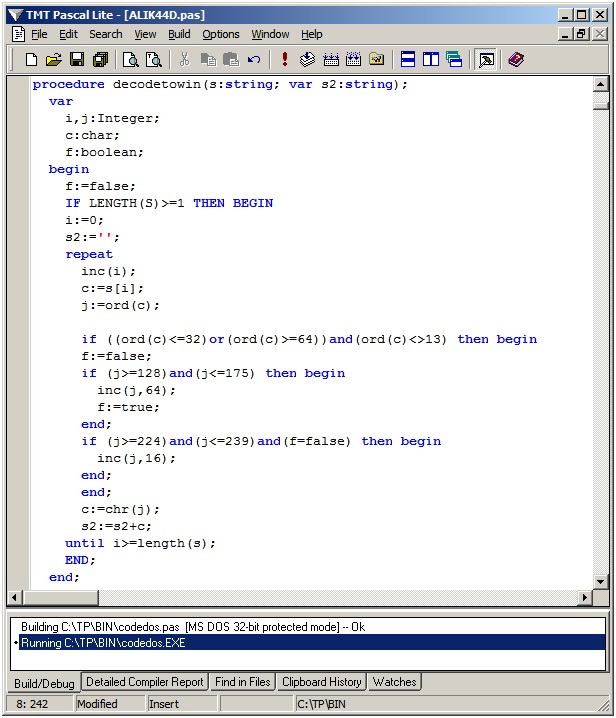
Также, нам может потребоваться перекодирование не строки (из Win в DOS), а отдельного символа, в этом случае мы используем процедуру DecodeToDOSC:
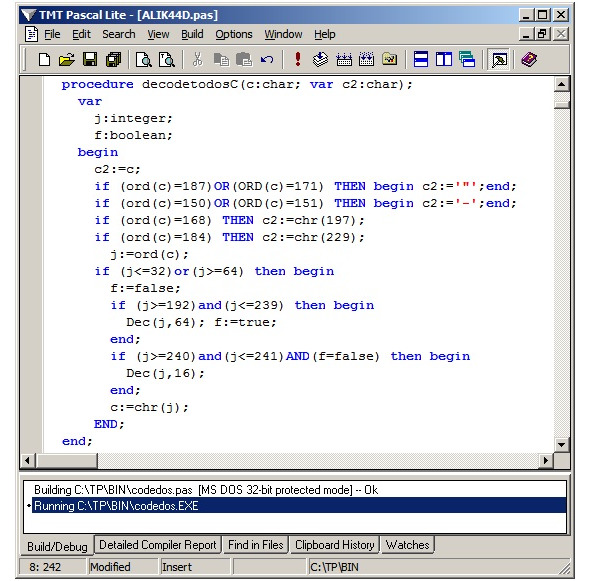
В программах использующих перекодировку символов мы использовали простой принцип преобразования, обращаясь к числовым значениям переменных.
Далее, говоря об обработке строковых данных нам регулярно будет требоваться процедура замены подстроки в строке, как приведенная ниже InsInString:
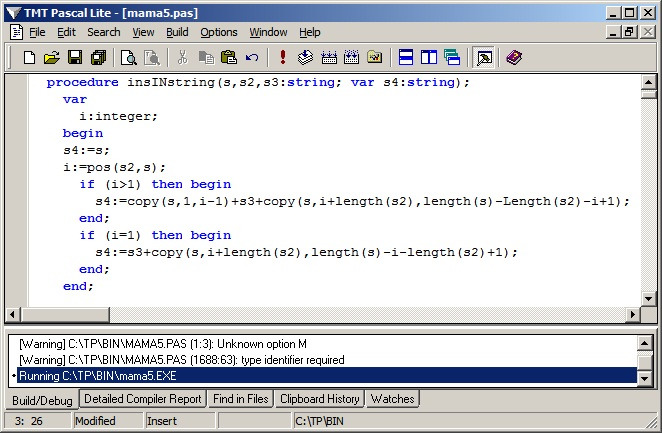
Как она работает. Переменная i получает позицию нахождения подстроки S2 в строке S. Если при этом позиция находится не на первом символе, в строку результата S4 копируется фрагмент строки до указанной позиции (фрагмент Copy (S,1,i-1), к нему прибавляется «слово» -замена S3, и оставшийся фрагмент текста за минусом уже полученного фрагмента с учетом стоявшего ранее на этом месте слова (фрагмент Copy (s,i+length (s2),length (s) -length (s2) -i+1)).
В операции замены первого слова есть небольшое различие — первым сразу становится подстрока замены S3.
Предположим, в строке «Мама мыла раму» нам необходимо заменить слово «раму» на «окно».
Замена производится в одно действие:

В данном случае переменная s2 получит измененную строку «Мама мыла окно». А в случае, если искомая подстрока не будет найдена, переменная S4 вернет в программу исходную строку S.
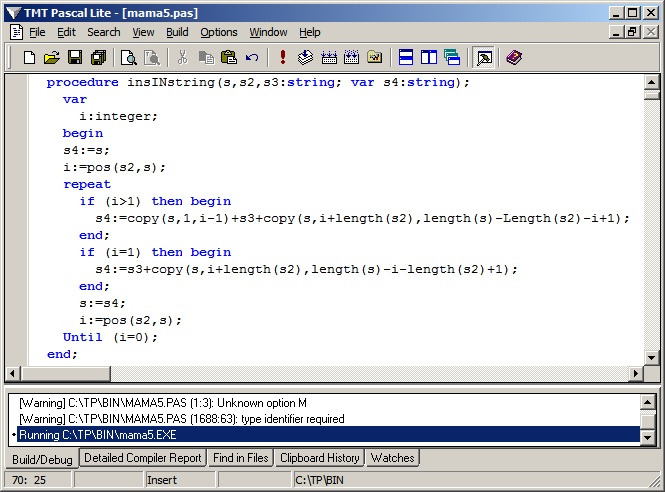
Но здесь необходимо учесть один момент. В случае, когда в текстовой строке встречается несколько раз одно и то же заменяемое слово, (например, слово «быть» в строке «быть или не быть»), процедуру следует повторить. Поскольку нам неизвестно, сколько раз во фразе может встретиться слово (или символ, или группа символов), один, три раза или 100 раз, мы можем усовершенствовать процедуру для того, чтобы она заменяла их все до тех пор, пока искомой подстроки в строке не останется. Здесь можно применить цикл Repeat с условием выхода.
Видоизменим процедуру InsInString, добавив цикл.
Еще одним необходимым элементом нормализации текста является его преобразование из строчного написания в заглавное для удобства последующего оперирования.
То есть наша строка «Мама мыла раму» после обработки должна выглядеть как «МАМА МЫЛА РАМУ», где все буквы являются прописными, большими.
Приведенная ниже процедура Getups преобразует строку таким образом, что все символы, написанные строчными буквами становятся прописными, а все прочие символы — копирует в той же позиции. Для этого процедура, которая работает со строкой использует другую процедуру, (Getup), которая производит ту же операцию, но на уровне 1 символа.
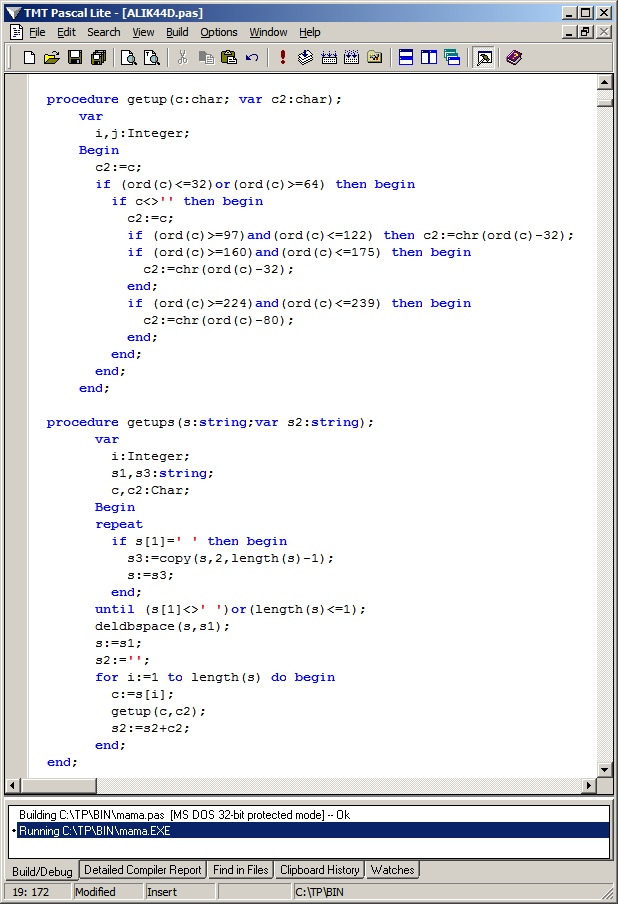
Ознакомившись с ними вы можете сделать вывод о принципе их работы. Чтобы не заменять все буквы по одной, процедура GetUp работает с диапазонами кодировок символов, меняя их нужным образом. В данном случае это уже упомянутые диапазоны кодировки DOS: английские строчные буквы от a до z (коды 97—122) и русские строчные буквы от а до я (коды 160—175, 224—239). Определив «попадание» в строчную кодировку мы уже знаем, в какую «сторону» и на какое число следует изменить код, вычесть или прибавить. В частности, для изменения английских строчных символов из кода символа вычитается число 32; а в русских, — до буквы «п» также вычитается 32, с буквы «р» — вычитается 80.
Поскольку процедура Getups изначально готовилась как процедура нормализации, по своему опыту в ней сразу использовались и дополнительные подготовительные элементы как вложенная процедура Deldbspace — удаления двойных и тройных пробелов, а также пробелов, стоящих перед началом и в конце строки:
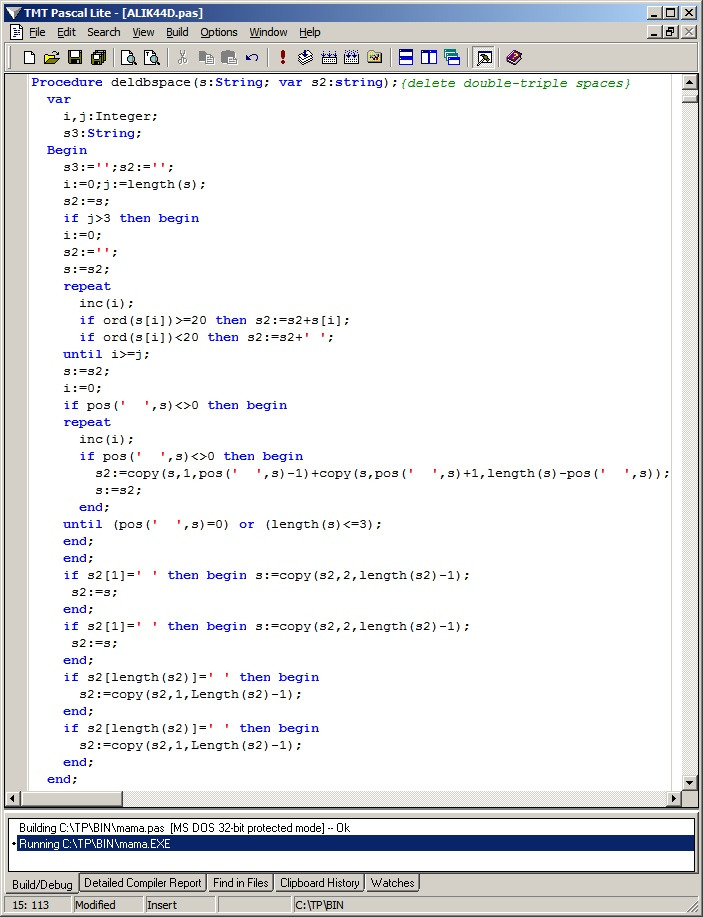
Теперь постараемся подытожить то, что мы получили.
С помощью описанных процедур мы можем нормализовать текст, используя буквально несколько операторов.
Вернемся к нашей проблеме с кодировкой, но теперь будем во всеоружии:
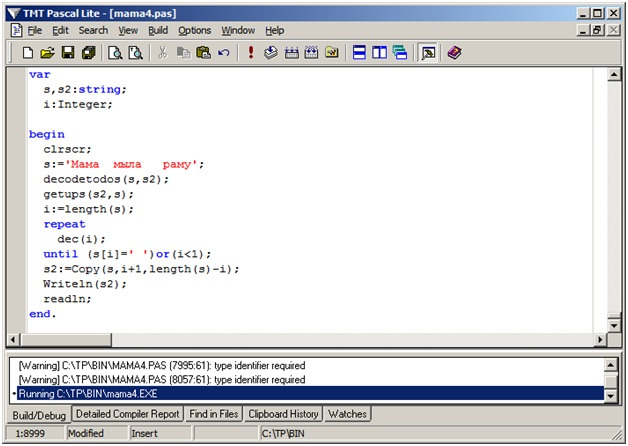
Здесь исходная строка написана в кодировке Win и содержит лишние пробелы. Мы перекодируем ее в кодировку DOS, с помощью процедуры Decodetodos, переводим в верхний регистр (и убираем лишние пробелы) с помощью процедуры Getups, и получаем последнее слово строки «раму».
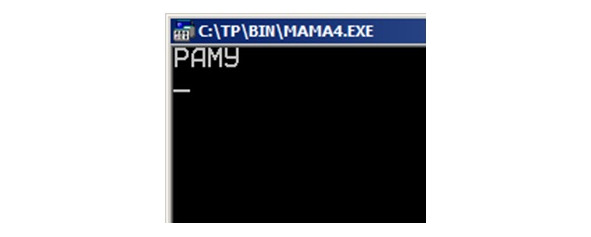
Следует упомянуть еще о нескольких базовых процедурах работы со строками в Паскале.
Преобразования строк
Str (N, S); — преобразует число N в строку S.
Иногда это требуется для операций над числовыми данными, например, для преобразования даты и времени в наборы символов строкового типа. Дело в том, что в Паскале мы не можем смешивать данные разных типов, и для этого требуется привести их к одному типу.
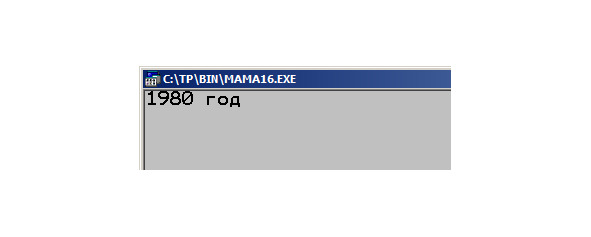
Для наглядности, рассмотрим процедуру, которая генерирует строку информации о завтрашней дате в читаемом формате. Результат должен выглядеть, допустим, так: «1 марта 2019 года». Все что у нас есть, это информация о дате сегодняшней, полученной посредством оператора GetDate. Эта информация кажется банальной, но в ней мы должны учесть в случае необходимости, содержит ли текущий месяц 30 или 31 день. Также стоит знать, является ли год високосным, если сегодня 28 февраля; стало быть завтрашний день может быть как первым днем календарной весны, так и 29 февраля. Как осуществить этот выбор?
Оператор Str здесь используется дважды в конце: для преобразования числа года и дня и последующей их конкатенации (иначе говоря, объединения) в одной строке.

Что происходит? В качестве выходной переменной процедуры мы указали единственную переменную S, в которую будет необходимо отправить результат — строку с датой. Далее, внутренними переменными мы описали Year (год), Month (месяц), Day (день) и Day_of_week (день недели); а также их строковые версии: Years, Months, Days. (Поскольку день недели в данном случае нам не интересен, мы не будем заниматься его описанием и преобразованием).
Первоначально, получив из операционной системы информацию о дате в формате чисел «GetDate (year, month, day, day_of_week)», мы прибавляем к числовому значению дня единицу «Inc (day)», и смотрим, что из этого получится.
В операторе сравнения с перечислением «Case» мы выбираем варианты сценариев. В месяце однозначно не может быть 32 дня, поэтому сталкиваясь с этим числом, мы присваиваем переменной дня единицу и увеличиваем значение месяца на единицу. Но если на дворе был декабрь? Мы помним об этом, и если это так (числовое значение месяца «Month» превратилось в 13), то прибавляем к году единицу «Inc (year)», если сегодня 31 декабря.
Но как мы помним — 31-ый день бывает не в каждом месяце; поэтому мы включаем в исключения и 31-ые числа ноября, сентября, июня и апреля, — если таковые получились, то значение месяца «Month» так же увеличиваем на единицу, а значению дня «Day» присваиваем 1.
Число 30 невозможно даже после крайне редкого дня «29 февраля», поэтому мы предусматриваем и его в виде исключения.
И наконец, 29 февраля бывает не в каждом месяце. Поэтому если мы встречаем такой вариант, нам необходимо уточнить, является ли год високосным или нет.
Точное определение високосного года звучит так:
«Год високосный, если он делится на четыре без остатка, но если он делится на 100 без остатка, это не високосный год. Однако, если он делится без остатка на 400, это високосный год.»
То есть, в данном случае, если мы видим попадание в одно из условий, когда год не делится на 4 без остатка, либо когда делится на 100, но не делится на 400, то считаем этот год обычным и следующим днем считается 1 марта.
Затем мы присваиваем в очередном блоке сравнений case значение месяцев в нужном нам склонении: «января», «февраля» и так далее. И наконец, в результате преобразований числовых данных в строковые, получаем итоговый, нужный результат.
Теперь мы рассмотрим обратную процедуру Val (S, N, R), где происходит преобразование S — строки, в N — число, с сообщении об ошибке (или ее отсутствие) в R.
Ниже приведен фрагмент программы в которой число, записанное в строковой переменной S преобразуется в N. Результат операции R при этом сообщит нам, есть ли в преобразовании ошибка (код R <> 0) или ошибка отсутствует (R=0).

Теперь мы рассмотрим процедуру для преобразования фрагмента текста с использованием дополнительной информации. Предположим, мы имеем текст статьи, который необходимо дополнить некоторыми строковыми данными. В статье может встретиться употребление информации о процентах, которое мы должны расширить, например, «95%» заменить на фразу «почти все (95%)». Также при встрече дробного процентного показателя, процедура должна округлить его, например «19,2%» употребить «менее пятой части (19%)». Вариативность такого «очеловечивания» процентных показателей может быть достаточно широкой (в приведенном примере, до 24 вариантов).
Что нам потребуется для упрощения этой задачи. Во-первых, это функция определения символов цифр Trycifra.

Во-вторых, это уже описанная ранее процедура InsInString. И в-третьих, это файл, «DictPer. txt», который необходимо сохранить в рабочем каталоге программы (по умолчанию это C:/TP/BIN). Он будет содержать числовые диапазоны значений и их описания (кодировка Win). Приведем его содержимое полностью:
«0
3
незначительный процент
3
5
менее двадцатой части
5
8
чуть более двадцатой части
8
10
менее десятой части
10
15
более чем десятая часть
15
16
менее шестой части
16
19
менее пятой части
19
21
пятая часть
21
25
больше пятой части
25
25
четверть
26
27
более чем четверть
27
30
почти третья часть
30
40
более чем третья часть
40
50
менее половины
50
58
более половины
59
65
около двух третей
65
75
почти три четверти
75
77
три четверти
77
80
почти четыре пятых
80
82
четыре пятых
82
92
подавляющее большинство
92
100
почти все
100
100
все
100
10000000
более 100%»
Теперь приступим к сборке и рассмотрим происходящее подробнее.
В процедуре нам потребовалось много строковых переменных для текущих операций (S-S8), две переменные для хранения диапазона (N2 и N3), одна — для текущего показателя (N типа Real), одна — символьного типа (C), одна переменная для связи файла (F типа Text), и две — логического типа (Boolean) для контроля над текущим состоянием операции (b и tryfalse).

На вход в процедуру мы имеем строку S, к обработке которой приступаем в случае нахождения в ней символа «%». В цикле меняется значение текущего символа S [i], и если мы встречаем обычные буквы или иные символы, то устанавливаем текущее значение tryfalse=true.
Если же нам встречается число или символы дроби, то мы храним его в переменной S3, поскольку оно может оказаться, а может и не оказаться процентом. Логический указатель числа («нужного» символа) устанавливаем на B=true, и отменяем значение «ненужного» символа TryFalse=false. Также мы дублируем это значение в переменной S8.
Встретив символ процента, цикл завершается. Мы преобразуем значение строковой переменной S3 в число N. Результат преобразования j мы игнорируем, поскольку контролировали код символов и уверены в числовом содержимом переменной. Поэтому используем в дальнейшем j как хранилище для округленного значения N (Round (N)).
Затем мы открываем файл словаря значений DictPer. txt, читаем его по 3 строки сразу, причем первые два «читаем» как числа (N2 и N3) с которыми сравниваем текущее число значения j. Если число j попадает в промежуток между указанными числами, нами используется символьное выражение из файла s6, которое мы не забываем переводить в кодировку DOS (процедура decodetodos).
Теперь протестируем готовую процедуру в следующей программе.
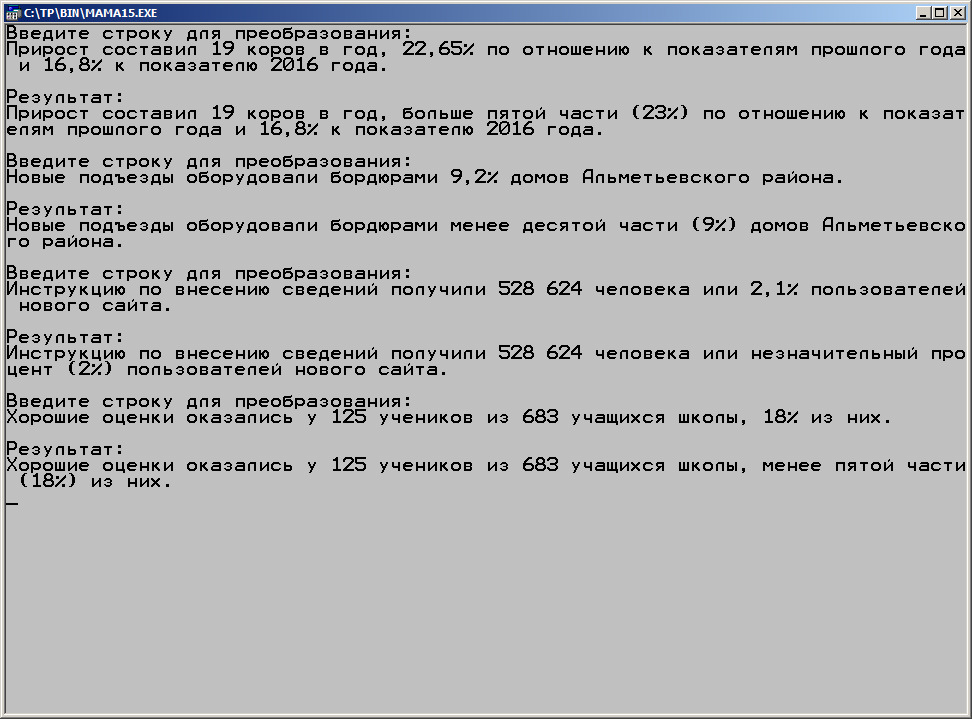
По такому принципу можно обрабатывать большие массивы текста, добиваясь, к примеру, увеличения его уникальности.
Сложное сравнение
Предположим что нам необходимо выбрать из десятка слов два, наиболее похожих. Но что, если все они разные и простое сравнение не работает? Если самыми похожими окажутся, например, «ковровая» и «ковровый»? «Хлебный» и «хлебо-булочный»? «Эволюция» и «конституция»? В данных случаях поможет функция сложного сравнения сходства.
Для начала поговорим о стратегии алгоритма. Мы могли бы здесь посчитать простое количество попаданий букв одной строки в другую, однако это исключает вероятность оценки сходства суффиксов и окончаний слов, как в последнем нашем примере с «эволюцией» и «конституцией». Судите сами.
эволюция
конституция
Если мы начнем перебирать индексы букв этих слов с «головы», сравнивать их последовательно [1, 2, 3, 4, 5…], то ни одного раза не получим совпадения:
э <> к, в <> о, о <> н, л <> c, ю <> т, ц <> и, и <> т, я <> у, «» <> ц, «» <> и, «» <> я.
Это плохо, поскольку для любого адекватного человека понятно, что слова похожи окончанием « -ция».
Очевидно, что алгоритм должен быть несколько сложнее простого последовательного перебора индекса для таких случаев.
Для решения этой проблемы, нам требуется провести комплексное сравнение. Мы будем сравнивать не конкретные позиции, а нахождение фрагментов одного слова в другом слове, меняя размер этих фрагментов от минимального к максимальному. То есть, сначала мы будем искать наличие букв по одной (э, в, о, л…); затем буквенных пар (эв, во, ол, лю, юц…); затем буквенных троек (эво, вол, олю, люц, юци, ция); четверок (эвол, волю, олюц, люци, юция); пятерок (эволю, волюц, олюци, люция); шестерок (эволюц, волюци, олюция); семерок (эволюци и волюция); и максимума — слова целиком (эволюция). Причем, чем больший фрагмент определяется попаданием, тем большее количество баллов мы должны присвоить за это попадание. Кроме того, нам следует учесть и разницу в длине строк.
Кстати, в данном случае, нам не принципиально соблюдение некой константы в виде получения процента, нам важен результат, который может быть выражен некоторым абстрактным числом баллов за количество попаданий и сравним его с другими результатами.
Программное решение этой процедуры может быть следующим.

Что происходит: первоначально, мы присваиваем переменной оценки сравнения (P) исходный балл (10 000), и оцениваем разность длины строк, за что также присваиваем различный размер «шага» оценки (step). В зависимости от величины разницы длины слов (L и L2) мы вычитаем эту разницу из первоначальной оценки (P). Затем происходит процесс приведения обоих слов к одинаковым условиям, — мы считаем их равными по длине, но если одно слово оказывается короче другого, то к нему присоединяется дополнительное число пустых символов-пробелов (S4).
Далее, происходит процесс сравнения с использованием циклов, описанный выше. И в завершении, мы вычитаем исходное количество баллов из полученной оценки.
В результате работы процедуры мы получаем оценку сходства слов «эволюция» и «конституция» в 908 баллов. Если же в качестве первого слова выступит «рыба», или «аргумент», оценка снизится до 0 баллов. Слово же «конституционный» поднимет оценку до 8 880. Конечно, это абстрактное число, однако в рамках столь же абстрактных координат оно дает стабильные сравнительные показатели сходства слов на естественном языке.
Но к сожалению, применять данную процедуру к крупным фрагментам текста проблематично: разделители в виде пробелов в двух строках могут неоправданно повышать показатели сходства. Мы могли бы конечно взять и заменить их на какие-либо другие символы, но никто не гарантирует, что и эти символы не встретятся в тексте. Кроме того, сравнение множества больших фрагментов текста будет сильно замедлять программу и повышает вероятность «зависаний». Ввиду этого, самым адекватным решением может быть специализация процедуры на сравнение одиночных слов.
Теперь следует определиться, что делать в таком случае с предложениями. Для начала попробуем пилить их на слова и выводить в форме массива из отдельных слов. В таком виде обработка больших фрагментов текста значительно упрощается.
А чем разделяются слова в предложениях? Правильно, пробелами и пунктуацией. Мы приготовим универсальную процедуру, которая будет «распиливать» любое предложение на набор слов и складывать их в массив для вывода. Стратегия здесь довольно простая, — идти вдоль индекса предложения и используя маркер разделения (пробел) отделять очередное слово. При этом, мы не станем сохранять пунктуацию, — ведь она «создает шум»: в данном случае — это словарные конструкции, которых нет. Ведь фактически для программы слова «корова» и «корова,» будут двумя разными словами, разными наборами символов. Это нас не устраивает. Поэтому, помня о том, что нам еще следует обработать пунктуацию, выделим исключительно все слова в предложении. Так может выглядеть эта процедура:

В процедуре Justbreak происходит обработка предложения, поступившего в переменную S в двух циклах Repeat. В ней, индекс слова будет контролировать переменная j, а индекс последовательного символа в предложении — переменная i. Первый цикл присваивает новое значение счетчику индекса слова командой inc (j). Условием выхода из цикла, сохраняющего слово, будет символ пробела, запятой, двоеточия, точки или превышение индекса i длины строки предложения. Внутри этого цикла мы добавляем очередной символ к текущему слову, если он соответствует условиям — не равен знаку пунктуации или пробелу. Кто-то может возмутиться, ведь процедура разбивает некоторые составные слова, вроде «кто-то», «как-то», «как-нибудь» и т. д. Но в данном случае мы все же отделим «мух от котлет» — выделим составные конструкции как слова по отдельности, но запомним, в какой конструкции пунктуации они находились.
Модель пунктуации
Перейдем к процедуре сохранения пунктуации. Конечно же, она нам очень пригодится. Она очень проста.

Здесь мы берем исходное предложение и (на всякий случай) предварительно исправляем наиболее распространенные ошибки: наличие пробела перед символами пунктуации, с помощью ранее описанной процедуры insinstring. Далее поработаем с элементами массива signs, в котором будем хранить символы пунктуации на время обработки.
Здесь мы начинаем «путешествие» по индексу входного предложения, отмечая каждое слово символом пробела или символом пунктуации, если он есть. Кроме того, мы выделяем весь полученный блок служебными символами «^».
В результате, на строку «Антошка — плохой, нехороший.» мы получим следующую картинку пунктуации « ^-,.^». Что же, теперь мы можем рассматривать любое предложение как набор «чистых» слов и модель пунктуации, к нему прилагающуюся.
Теперь вновь вернемся к задаче, в которой требовалось выделить и обнаружить пару наиболее схожих слов в предложении.
Мы можем использовать следующий алгоритм:
1. Разбить слова в предложении на массив с помощью процедуры justbreak с числом элементов j.
2. Сравним каждое слово массива с каждым и если полученное значение является максимальным, то сохраним его, как ответ. Для этого нам потребуется два цикла и правило, по которому одно и то же слово мы не будем сравнивать с самим собой.
Используя этот нехитрый метод, мы можем получить своего рода игру, в которой программа будет искать слова, близкие по написанию и выбирать их, как на следующем примере:
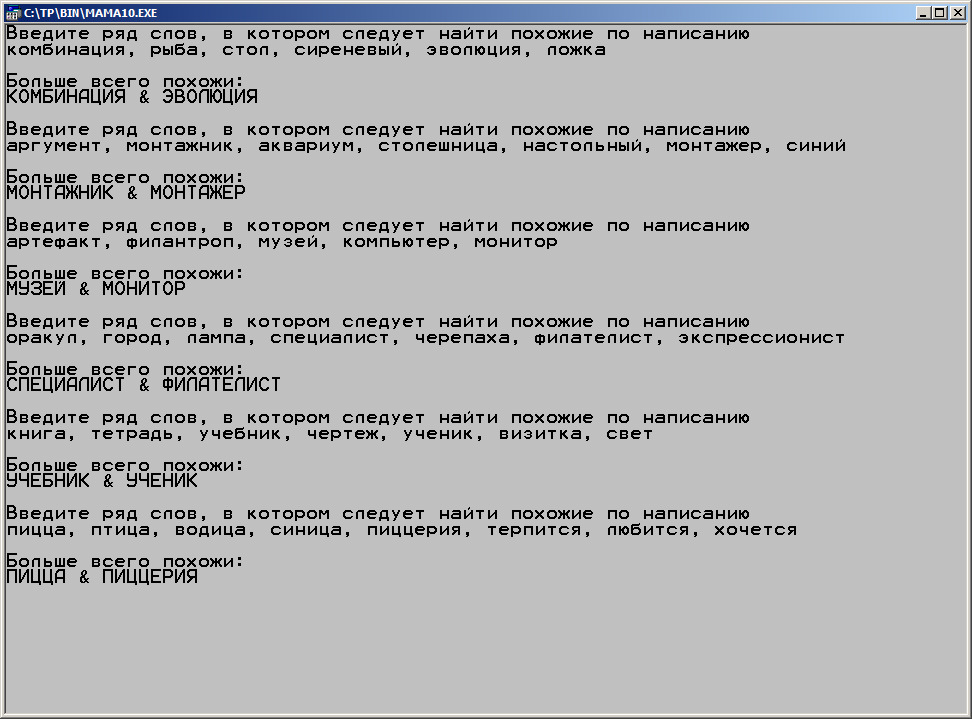
Как видно, программа действует, отсекая символы пунктуации и преобразуя ряд слов из одной строковой переменной в массив слов, а также приводит каждое слово в верхний регистр. Теперь рассмотрим программу, которая осуществляет эти действия.

Итак, что мы здесь видим. В первую очередь, это набор строковых переменных (s, s2, s3), которые нужны для обмена данными между процедурами нормализации (decodetodos, getups) и ввода строки пользователем. Также, здесь используются переменные для работы циклов (i и n), для индексирования конца массива sm (j), для определения максимума (max) и текущего состояния баллов (ball). Кроме того — переменные для хранения лучших позиций двух слов (max1) и (max2) в массиве (sm). Массив требуется нам в качестве выходной переменной для использования в описанной выше процедуре justbreak, поэтому мы не производим иных действий с его элементами (по очистке, заполнению пустыми символами и др.), поскольку эти действия уже прописаны в самой процедуре justbreak.
Весь алгоритм кроме исходных функций очистки мы поместили в цикл Repeat с отсутствием условия выхода (Until false) для того, чтобы вопросы и ответы повторялись при желании пользователя бесконечно.
После нормализации (декодирования) приветственной фразы «Введите ряд слов, в котором следует найти похожие по написанию» и выведении ее на экран, от пользователя получается строка S, в которой он написал ряд слов. Эту строку мы разбиваем процедурой justbreak на массив слов sm с известным числом элементов j, после чего в двух циклах последовательно сравниваем (с помощью percentcheck2) различные элементы массива друг с другом, если речь не идет об одном и том же элементе (i <> n). Если текущий максимум Max оказывается ниже текущей оценки Ball, мы передаем число Ball в Max, и запоминаем позиции I и N, сохраняя их в переменные max1 и max2 соответственно. После окончания циклов сравнения мы выводим результат из массива sm с индексами max1 и max2 и ждем следующее задание.
Эта игра может быть усовершенствована. Например, в роли задающего вопрос и генерирующего слова мы можем поставить программу, а человек будет их угадывать. Но для этого нам уже потребуется работа со словарями, чем мы и займемся позже.
Шаблоны поиска
Еще одну интересную функцию можно считать очень полезной при обработке строковых данных. Она незаменима для анализа, а точнее, парсинга по значительным объемам текста.
Предположим, перед нами — достаточно монотонный текст, состоящий из букв, пунктуации и пробелов. Это может быть html -страница текста, полная рекламы, модулей и ссылок; но небольшая часть этого текста носит важный для нас смысл. Мы хотели бы разметить этот фрагмент текста какими-либо жесткими правилами, однако это невозможно. На начало нужного фрагмента в тексте указывают лишь косвенные признаки, — например, наличие даты, времени публикации и имени автора в следующем формате: «12.08.2018 01:20, АНАТОЛИЙ ИВАНОВ». Строка перед ним — содержит только название статьи, а после и до него — ряды случайных символов.
Эти данные — всегда разные, но формат их записи всегда один. Как нам прочитать их в случайном месте текста?
В этом случае мы используем технологию шаблона. Под шаблоном здесь понимается последовательное использование какого-либо ряда символов (точек, букв, чисел, дефисов и т.п.), которое заранее может быть известно, однако его расположение в строке может быть различным: этот ряд символов может находиться где угодно.
В чем состоит идея:
1. «Прочитать» строку текста, размечая встреченные группы символов одной из нескольких меток. Например, все буквы русского алфавита мы можем пометить «0», пунктуацию — «1», числа — «2», английские буквы — «3», символьные команды и псевдографику «4» и «5», а пробелы — «6». (Согласно этой схеме, упомянутый выше шаблон без имени автора мы могли бы записать как последовательность «22122122226221221»).
2. В «клоне» строки, размеченной полученным кодом мы находим искомый шаблон.
3. Поскольку длина клонированной строки и исходной не отличается, указание на позицию шаблона укажет на позицию первого нужного нам символа в исходной строке и общее количество символов.

Как видно, функция довольно проста, но здесь были использованы некоторые жизненные «лайфхаки». Поскольку бывает довольно сложно проконтролировать всю палитру диапазонов таблицы символов, здесь введена дополнительная переменная логического типа «plus», которая содержит информацию, об использовании очередного символа из строки в шаблоне. Если мы пропустили какой-то символ (if plus=false) после проверки всех полезных для нас вариантов, тогда мы добавляем символ кода «5» в S3 (там может оказаться псевдографика, командные символы и т.п.). В таком случае длина строки, содержащая код шаблона S3 не будет отличаться от исходной S. Также, для того, чтобы каждый раз не проверять код текущего символа из исходника S, мы присвоили его значение переменной j, что ускоряет время исполнения.
По окончании кодирования строки, мы выполняем поиск подстроки SS в полученной строке S3, и копируем фрагмент из реальной строки S с позиции строки полученного шаблона S3 и с длиной подстроки шаблона SS. Фрагмент «S2:=copy (s, pos (ss, s3), length (ss));»
Проверим корректность процедуры:

И вот результат:
Функция шаблона с различными модификациями незаменима для парсинга неформализованных данных. К примеру, она подходит для поиска даты рождения, номеров телефонов, домашних адресов, номеров документов, временных периодов трудового стажа и других сведений из текстовых файлов резюме, которые впоследствии могут быть внесены в стандартную форму и нужным образом исправлены.
Но предположим, что пользователь написал дату рождения с лишним пробелом. Например так, 02.12. 1962. Как можно предположить подобную ситуацию и исправить ее автоматически?
Конечно же, во-первых, нам следует убедиться, что имелась ввиду именно дата рождения а не период работы или дата составления резюме. На это могут указывать сопутствующие данные: фрагменты слов в строке с «род», «рожд», «г.р» или «д.р». Убедившись, мы используем ту же функцию shablon, но с некоторой модификацией, которая может получать числовую информацию, игнорируя степень разреженности между числовыми символами.
Так, функция clearshablon в случае необходимости игнорирует наличие или отсутствие в строке дополнительных пробелов, благодаря нескольким операторам, добавленным в функцию shablon и пользуясь описанной выше процедурой insinstring.

В итоге, при обработке строки «02.12. 1962» с использованием шаблона, не включающего пробел 2212212222 функция сlearshablon вернет результат «02.12.1962» без лишнего пробела, благодаря синхронным усилиям процедуры insinstring, устранившим все пробелы из строк как в коде-шаблоне, так и в исходной строке.
Разреженный текст
К разреженному тексту разработчики обычно относятся скептически; мол, явление это редкое и тратить усилия на то, чтобы его распознавать — бессмысленно. Но если исходить из анализа данных современных резюме, рефератов и сочинений, окажется, что почти в каждом двадцатом из них встречаются одна-две строки разреженного текста. Неужели строку типа «И в а н о в И в а н И в а н о в и ч» придется упустить? Быть может вы никогда не столкнетесь с разреженным текстом, но сам по себе вопрос весьма интересен.
Посмотрим, как эту проблему можно решить средствами Паскаля.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.