
Бесплатный фрагмент - Форензика
Методическое пособие для студентов
ВВЕДЕНИЕ
Форензика простыми словами, это сбор цифровых доказательств. Что можно понять под словосочетанием «цифровые доказательства». Под цифровыми доказательствами подразумевается наличие следов преступления на любых носителях информации, жесткие диски, смартфоны, планшеты, флешки, любые предметы где может храниться информация в электронном виде. Из самых не обычных это могут быть утюги, холодильники и прочая умная бытовая техника))
Существует несколько видов криминалистических экспертиз:
Аппаратно-компьютерная экспертиза;
Программно-компьютерная экспертиза;
Компьютерно-сетевая экспертиза;
Информационно-компьютерная экспертиза.
Перед специалистом в основном ставятся вопросы:
о наличии на объектах информации, которая относится к делу (в том числе, в неявном, удалённом, скрытом или зашифрованном виде);
о возможности использования исследуемых объектов для определённых целей (например, для доступа в сеть);
о действиях, совершённых с использованием объектов;
о свойствах программ, в частности, о принадлежности их к вредоносным;
об идентификации найденных электронных документов, софта, пользователей компьютера.
Еще есть понятие как экспресс анализ, то есть на месте быстро все проверяется и делается заключение. Например, вы сидите дома, взламываете сайт какого нибудь департамента, и тут в дверь позвонили, ты пошел открывать не выключив ноутбук, зашли полицейские, или люди из иных гос. структур, посмотрели ваш компьютер, и все, доказательство на лицо. По средствам экспресс анализа быстро выявят ваше причастие к взлому и заберут в другое место, менее приятнее чем ваш дом.
1 Общие сведения о логе веб-сервера
1.1 Как работает web server log file?
Когда пользователь вводит URL-адрес в браузер, тот сначала разбивает его на три компонента. Например:
https://your_site_address.com/example.html
В данном случае браузер понимает, что https — это протокол, your_site_address.com — название сервера, а example.html — имя файла.
Название сервера преобразуется в IP-адрес через сервер доменных имен. Затем HTTP-запрос GET отправляется на веб-сервер через соответствующий протокол для запрашиваемой страницы или файла, при этом HTML возвращается в браузер, а затем интерпретируется для форматирования видимой страницы на экране. Каждый из этих запросов записывается в log file веб-сервера.
Проще говоря, процесс выглядит так: посетитель совершает переход по странице, браузер передает его запрос серверу, на котором расположен веб-сайт. Сервер выдает запрошенную пользователем страницу в ответ. И после этого фиксирует все происходящее в log-файле.
Все, что вам нужно, чтобы проанализировать сканирование сайта поисковой системой, — экспортировать данные и отфильтровать запросы, сделанные роботом, например, Googlebot. С помощью браузера и диапазона IP это сделать удобнее.
Сам лог-файл представляет собой сырую информацию, сплошной текст. Но правильная обработка и анализ дают неограниченный источник информации.
1.2 Содержание и структура лог-файла
Структура журнала в конечном счете зависит от типа используемого сервера и конфигураций. Например, анализ логов Apache будет отличаться от анализа логов Nginx. Но есть несколько общих атрибутов, которые почти всегда содержатся в файле:
• IP-адрес запроса;
• дата и время;
• география;
• метод GET / POST;
• запрос к URL;
• код состояния HTTP;
• браузер.
Пример записи, включая приведенные выше данные:
111.11.111.111 — - [12 / Oct / 2018: 01: 02: 03 -0100] « GET / resources / whitepapers / retail-whitepaper / HTTP / 1.1 « 200“ -« „Opera / 1.0 (совместимый; Googlebot / 2.1; + http://www.google.com/bot.html)
Дополнительные атрибуты, которые иногда можно увидеть, включают:
• имя хоста;
• запрос / клиентский IP-адрес;
• загруженные байты;
• затраченное время.
Экспорт лог-файла на WordPress
Чтобы подобный файл появился и для сайта на платформе WordPress, необходимо включить функцию логирования. Для этого найдите в корневой папке сайта файл с названием wp-config.php. Скачайте файл на компьютер, чтобы получить доступ к редактированию.
Далее найдите строку: «That’s all, stop editing! Happy blogging». Перед ней добавьте новую строку кода:
define («WP_DEBUG», true);
Это переведет сайт в режим отладки, что включит отображение уведомлений об ошибках.
Теперь запустите запись ошибок в log-файл. Для этого сразу под предыдущей строкой кода добавьте новую:
define («WP_DEBUG_LOG», true);
Чтобы зайти в log-файл сайта на WordPress, нужно перейти в FTP или менеджер файлов. Далее в общей папке сайта откройте папку wp-content, в ней найдите файл с именем debug.
1.3 Анализаторы файлов журналов
По мере того, как все больше и больше компаний переходят в облако, аналитики журнала, анализ логов и инструменты управления журналами становятся все более востребованными.
Некоторые проверяют лог-файлы вручную. Веб-мастера экспортируют файл и анализируют его в программе Excel. В таком случае понадобится только сортировка и несколько формул, но данный подход — устаревший, и здесь рассматриваться не будет.
Использование специальных инструментов для анализа файлов журналов может облегчить обработку больших объемов информации.
Некоторые веб-мастера устанавливают анализатор логов на сам сервер. Способ удобен для проектов, расположенных на собственных серверах, — тогда логи будут сохранены неограниченное количество времени. А проекты, которые находятся на стороннем хостинге, будут поставлены в рамки — хранение максимум 1 месяц. Поэтому возникает необходимость производить ротацию и архивирование.
Screaming Frog Log File Analyzer
Для примера проведем анализ лог файлов через Screaming Frog Log File Analyzer.
Инструмент предоставляет доступ к бесплатной версии, ограничивая журнал событий одной тысячей строк. Для некрупного проекта этого объема хватит.
Скачайте и установите программу на компьютер, далее выгрузите лог-файлы или составьте список всех URL-адресов, которые присутствуют на веб-площадке. Экспорт файла описан выше.
Анализ логов онлайн покажет в таблице коды ответа страниц, даты последних переходов, контент, количество поисковых ботов и прочее.
Остальные анализаторы рассмотрим более кратко.
GoAccess предназначен для быстрого анализа данных. Его основная идея — быстро посмотреть логи сервера и проанализировать их в режиме реального времени без необходимости использования вашего браузера.
Splunk позволяет вам обрабатывать бесплатно до 500 МБ данных в день. Это отличный способ собирать, хранить, искать, сравнивать, анализировать журналы сайта.
Logmatic.io — инструмент анализа журналов, разработанный специально для улучшения работы программного обеспечения. Акцент делается на программные данные, куда входят и журналы. На данный момент инструмент платный.
Logstash — бесплатный инструмент с открытым исходным кодом для управления событиями и журналами. Его можно использовать для сбора журналов, их хранения и анализа.
Большинство ОС для web-серверов предоставляют возможность указать конкретные привилегии доступа для файлов, устройств и других вычислительных ресурсов на данном хосте. Следует понимать, что любая информация, к которой может быть осуществлен доступ из каталогов, принадлежащих web-серверу потенциально может стать доступной всем пользователям, имеющим доступ к публичному web-сайту. Обычно ПО web-сервера обеспечивает дополнительное управление доступом к файлам, устройствам и ресурсам. В случае, если разрешения доступа к ресурсам могут быть установлены как на уровне ОС, так и на уровне приложения web-сервера, важно, чтобы они были идентичны друг другу, в противном случае возможна ситуация, когда пользователям предоставлен либо очень большой, либо очень маленький доступ. Web-администраторы должны рассмотреть, какое конфигурирование доступа к хранимой в публичном web-сервере информации является наилучшим со следующих точек зрения:
• ограничение доступа ПО web-сервера к подмножеству вычислительных ресурсов средствами управления доступом ОС;
• ограничение доступа пользователей посредством дополнительного управления доступом, обеспечиваемым web-сервером, когда требуются более детальные уровни управления доступом.
Соответствующая установка управления доступом может помочь предотвратить раскрытие чувствительной информации, которая не предназначена для публичного распространения. Дополнительно управление доступом может быть использовано для ограничения использования ресурсов в случае DoS-атаки на публичный web-сайт.
Обычно файлами, доступ к которым должен контролироваться, являются следующие:
• ПО и конфигурационные файлы приложения.
• Файлы, непосредственно использующиеся механизмами безопасности: файлы хэшей паролей и другие файлы, используемые при аутентификации; файлы, которые содержат авторизационную информацию, используемую при управлении доступом; криптографический материал ключа, используемый в сервисах конфиденциальности, целостности и невозможности отказа.
• Логи сервера и файлы системного аудита.
• Системное ПО и его конфигурационные файлы.
1.4 Разграничение доступа для ПО web-сервера
Первый шаг в конфигурировании управления доступа состоит в гарантировании того, что web-сервер выполняется только от имени пользователя и группы, которые специально созданы для этого и имеют очень ограниченные права доступа. Таким образом, должны быть введены специальные идентификаторы пользователя и группы, используемые исключительно ПО web-сервера. Новый пользователь и новая группа должны быть уникальными и независимыми от всех остальных пользователей и групп. Это необходимо для реализации управления доступом, описанного далее. Хотя сервер может начинать выполняться как root (Unix) или system/administrator (Windows NT/2000/XP) для привязки к ТСР-порту 80 и/или 443 (используемому для предоставления НТТР и НТТРS-сервисов соответственно), не следует допускать, чтобы сервер продолжал выполняться на данном уровне доступа.
Дополнительно следует использовать возможности ОС для ограничения доступа к файлам, доступным процессам web-сервера. Эти процессы должны иметь доступ только по чтению к тем файлам, которые необходимы для выполнения сервиса, и не должны иметь доступа к остальным файлам, таким как файлы лога сервера. Следует использовать управление доступом на уровне ОС для обеспечения следующего:
• процессы web-сервера должны быть сконфигурированы для выполнения от имени пользователя с очень ограниченным множеством привилегий (т.е. не выполняться как root, администратор или эквивалентные пользователи);
• к файлам содержимого web-сайтов процессы web-сервера должны иметь доступ по чтению, но не по записи;
• процессы web-сервера не должны иметь возможность записи в директории, в которых хранится публичное содержимое web-сайтов;
• только процессы, авторизованные как администратор web-сервера, могут писать в файлы web-содержимого;
• приложение web-сервера может писать в файлы логов web-сервера, но лог-файлы не могут читаться приложением web-сервера. Только процессы уровня root/system/administrator могут читать лог-файлы web-сервера;
• временные файлы, создаваемые приложением web-сервера, например, те, которые возникают при формировании динамических web-страниц, должны быть расположены в специальной и соответствующим образом защищенной поддиректории;
• доступ к любым временным файлам, созданным приложением web-сервера, ограничен процессами, которые создали эти файлы.
Также необходимо гарантировать, что приложение web-сервера не может хранить файлы вне специального подкаталога, выделенного для публичного web-содержимого. Это может быть задано посредством конфигурации в ПО сервера или может контролироваться ОС. Следует гарантировать, что к директориям и файлам вне специального поддерева директорий не может быть обращений, даже если пользователи знают имена этих файлов.
Для уменьшения воздействия основных типов DoS-атак нужно сконфигурировать web-сервер с ограниченным количеством ресурсов ОС, которые он может использовать. Чаще всего необходимо совершить следующие действия:
• инсталлировать содержимое web на отдельном жестком диске или логическом разделе от ОС и web-приложения;
• если допустимы загрузки (uploads) на web-сервер, установить ограничение на объем дискового пространства, которое выделяется для этой цели;
• если допустимы загрузки (uploads) на web-сервер, эти файлы не должны быть сразу же читаемы web-сервером и, тем самым, видимы пользователям по протоколу НТТР. Они должны быть читаемы web-сервером только после некоторого автоматизированного или ручного процесса просмотра. Это предотвращает от использования web-сервера для передачи пиратского ПО, инструментальных средств атак, порнографии и т.п.;
• гарантировать, что лог-файлы хранятся в соответствующем месте, в котором они не смогут исчерпать ресурсы файловой системы.
Эти действия в некоторой степени защитят от атак, которые попытаются заполнить файловую систему информацией, что может вызвать крах системы. Они могут также защитить против атак, которые пытаются заполнить RAM память ненужными процессами для замедления или краха системы, тем самым ограничив доступность сервиса. Информация в логах, созданных ОС, может помочь распознать такие атаки.
Дополнительно часто бывает необходимо сконфигурировать таймауты и другие способы управления для дальнейшего уменьшения влияния основных DoS-атак. Один из типов DoS-атаки состоит в том, чтобы одновременно устанавливать сетевые соединения сверх максимально допустимого, чтобы никакой новый законный пользователь не мог получить доступ. Когда таймауты установлены на сетевые соединения (время, после которого неактивное соединение сбрасывается) в минимально допустимое ограничение, существующие соединения будут завершаться по таймауту так быстро, как только возможно, создавая возможность устанавливать новые соединения законным пользователям. Данная мера только смягчает DoS-атаку, но не уничтожает ее.
Если максимальное число открытых соединений (или соединений, которые являются полуоткрытыми, — это означает, что первая часть ТСР-рукопожатия завершилась успешно) установить в наименьшее число, атакующий может легко израсходовать доступные соединения ложными запросами (часто называемыми SYN flood). Установка в максимум данного числа может смягчить эффект такой атаки, но ценой расходования дополнительных ресурсов. Заметим, что это является проблемой только тех web-серверов, которые не защищены firewall’ом, останавливающим SYN flood атаки. Большинство современных firewall’ов защищают web-сервер от SYN flood атаки, прерывая ее прежде, чем она достигнет web-сервера.
1.5 Управление доступом к директории содержимого web-сервера
Не следует использовать ссылки, aliases или shortcuts из дерева директории содержимого web на директории или файлы, расположенные где-то еще на хосте или сетевой файловой системе. Лучше всего запретить возможность ПО web-сервера следовать по ссылкам и aliases. Как указывалось раньше, лог-файлы и конфигурационные файлы web-сервера должны размещаться вне дерева директории, которое определено для публичного содержимого web.
Для ограничения доступа к дереву директории содержимого web требуется выполнить следующие шаги:
• выделить отдельный жесткий диск или логический раздел для web-содержимого и использовать поддиректории на данном жестком диске или логическом разделе исключительно для файлов содержимого web-сервера, включая графику, но исключая скрипты и другие программы;
• определить отдельную директорию исключительно для всех внешних по отношению к ПО web-сервера скриптов или программ, выполняющихся как часть содержимого web (например, CGI, ASP, PHP);
• запретить выполнение скриптов, которые не находятся под исключительным контролем административных аккаунтов. Данное действие выполняется созданием доступа и управлением им к отдельной директории, предназначенной для хранения авторизованных скриптов;
• запретить использование жестких и символических ссылок;
• определить матрицу доступа к содержимому web. Определить, какие папки и файлы внутри содержимого web-сервера имеют ограничения и какие являются доступными (и кому).
Большинство производителей ПО web-сервера предоставляют директивы или команды, которые позволяют web-администратору ограничить доступ пользователя к файлам содержимого web-сервера.
Например, ПО web-сервера Apache предоставляет директиву Limit, которая позволяет web-администратору указать, какие возможности доступа (такие как New, Delete, Connect, Head и Get) связаны с каждым файлом web-содержимого. Директива Require в Apache позволяет web-администратору ограничивать доступ к содержимому аутентифицированными пользователями или группами.
Многие директивы или команды могут быть перекрыты на уровне директории. Но при этом следует помнить, что удобство, состоящее в возможности делать локальные исключения из глобальной политики, может привести к появлению дыры в безопасности, появившейся в отдельной поддиректории, которая контролируется другим пользователем. Web-администратор должен запретить для поддиректорий возможность перекрывать директивы безопасности верхнего уровня, если это не является абсолютно необходимым.
В большинстве случаев подобные директивы web-сервера должны быть запрещены. НТТР определяет, что URL, заканчивающийся символом слеша, должен трактоваться как запрос на перечисление файлов в указанной директории. Web-сервер должен запрещать отвечать на такие запросы, даже если возможно публичное чтение всех файлов директории. Такие запросы часто указывают на попытку разместить информацию способами, отличными от тех, которые допускает web-администратор. Пользователи могут пытаться это делать, если у них возникают трудности в навигации по сайту или если ссылки в web-страницах обрываются. Нарушитель может пытаться это сделать, чтобы разместить информацию, скрытую интерфейсом сайта. Web-администраторы должны исследовать запросы данного типа, найденные в лог-файлах web-сервера.
На большинстве современных хостингов кроме FTP доступа к файловой системе предоставляется также SSH доступ (по-умолчанию или по запросу в тех поддержку). Умение веб-мастера работать с файлами сайта в терминале (в режиме командной строки) по SSH экономит ему массу времени. Операция, которая может занимать десятки минут по FTP, делается через командную строку за пару секунд. Кроме того, есть много операций, которые можно сделать только по SSH в режиме командной строки.
Веб-мастеру не обязательно осваивать весь инструментарий операционной системы Unix, для начала достаточно познакомиться с базовыми командами, а к ним добавить несколько полезных трюков при работе с командной строкой по SSH, чтобы быстро искать файлы, изменять их атрибуты, копировать, удалять и выполнять операции с текстовыми данными.
Я пропущу описание протокола и процесса подключения к аккаунту хостинга по SSH, в сети можно найти множество видео-уроков и статей по данной теме, скажу лишь что для подключения вам потребуется программа Putty (ОС Windows) / Терминал (Mac OS X) или аналогичные, и доступы к хостингу по SSH: хост, порт, логин и пароль (часто имя и пароль они совпадают с доступом в cPanel, ISPManager или аккаунтом панели управления хостингом).
Итак, что полезного можно делать в командной строке? Можно быстро выполнять поиск подстроки в текстовом файле, сортировку, фильтрацию текстовых данных. Например, для анализа журналов (логов) веб-сервера, чтобы выявить подозрительные запросы к сайту или понять, как взломали сайт.
Предположим, вы заметили подозрительную активность на сайте (стал медленно открываться, пропали доступы в админ-панель, с сайта рассылают спам и т.п.). Первое, что в этом случае нужно выполнить — это проверить файлы сайта на вредоносный код специализированными сканерами. Но пока сайт сканируется, можно провести экспресс-анализ логов веб-сервера с помощью команд find/grep, чтобы опеределить, не было ли обращений к каким-то подозрительным скриптам, попыток брутфорса (подбора пароля) или вызовов хакерских скриптов. Как это сделать? Об этом ниже.
Чтобы анализировать журналы (логи) веб-сервера нужно, чтобы эти логи были включены и доступны в пользовательской директории. Если по-умолчанию они отключены, необходимо их включить в панели управления хостингом и выставить, если есть такая настройка, максимально возможный период хранения (ротации). Если логов нет, но нужно выполнить анализ за последние несколько дней, их можно попробовать запросить в тех поддержке хостинга. На большинстве shared-хостингов логи можно найти в директории logs, которая расположена на один или два уровня выше директории public_html (www). Итак, будем считать, что логи на хостинге есть и путь до них известен.
Подключаемся по SSH и переходим в директорию с логами веб-сервера, которые на виртуальных хостингах хранятся обычно за последние 5—7 дней. Если вывести список файлов в директории, скорее всего там будет access_log за сегодняшний день, а также access_log.1.gz, access_log.2.gz,… — это архивированные логи за предыдущие дни.
Начать анализ лога можно с запросов, которые были выполнены методом POST:
grep «POST /’ access_log
или
cat access_log | grep «POST /»
Результат вывода можно сохранить в новый текстовый файл для дальнейшего анализа:
grep «POST /’ access_log> post_today. txt
Как сделать то же для лога, заархивированного gzip? Для этого есть команда zcat (аналогично cat, но распечатывает содержимое заархивированного файла).
zcat access_log.1.gz | grep «POST /’> post_today. txt
Для анализа подозрительной активности желательно использовать выборку по всем доступным логам. Поэтому далее в примерах будем использовать команду find, которая выполнит поиск всех файлов, а затем выполнит для каждого соответствующую команду (например, zcat).
Как определить попытки взлома или поиска уязвимых скриптов?
Например, можно найти все обращения к несуществующим скриптам. php во всех доступных логах.
grep ’php HTTP.* 404» access_log
find. -name «*.gz’ -exec zcat {} \; | grep ’php HTTP.* 404»
(вместо -exec можно использовать xarg для вызова zcat.)
Еще можно поискать все неуспешные обращения к скриптам php (к которым был закрыт доступ).
find. -name «*.gz’ -exec zcat {} \; | grep ’php HTTP.* 403»
Здесь мы ищем запросы, в которых встречается расширение php и статус 403.
Далее посмотрим по всем доступным логам число успешных обращений к скриптам, отсортируем их по числу обращений и выведем ТОП-50 самых популярных. Выборку сделаем в три шага: сначала выполним поиск по access_log, затем по всем access_log.*.gz, выведем результаты в файл, а затем используем его для сортировки.
find. -name «*.gz’ -exec zcat {} \; | grep ’php HTTP.* 200»> php. txt
grep ’php HTTP.* 200» access_log>> php. txt
cut -d «"» -f2 php. txt | cut -d ' ' -f2 | cut -d»?» -f1 | sort | uniq -c | sort -n | tail -50
Для сайта на Wordpress результат может выглядеть так:
(примеры для Wordpress приведены исключительно для иллюстрации, в действительности описанный подход и команды не ограничиваются данной CMS. Приведенные команды можно использовать для анализа журналов веб-сервера сайтов, работающих на любых php фреймворках и системах управления (CMS), а также просто на php скриптах.)
1 /wp-admin/edit.php
1 /wp-admin/index.php
1 /wp-admin/update-core.php
1 /wp-admin/upload.php
2 /wp-admin/users.php
3 /wp-admin/plugins.php
4 /wp-includes/x3dhbbjdu.php
4 /wp-admin/profile.php
4 /wp-admin/widgets.php
38 /wp-admin/async-upload.php
58 /wp-admin/post-new.php
1635 /wp-admin/admin-ajax.php
6732 /xmlrpc.php
14652 /wp-login.php
Из результата видно, что к файлу wp-login.php было более 14000 обращений, что ненормально. Судя по всему на сайт была (или еще идет) брутфорс атака с попыткой подобрать доступ к панели администратора.
Большое число обращений к xmlrpc.php также может свидетельствовать о подозрительной активности. Например, через сайт могут атаковать (DDOS’ить) другие Wordpress сайты при наличие XML RPC Pingback Vulnerability.
Еще в списке подозрительными выглядят успешные обращения к /wp-includes/x3dhbbjdu.php, так как такого файла в стандартном Wordpress быть не может. При анализе он оказался хакерским шеллом.
Таким образом буквально за несколько секунд можно можно получить статистику по обращениям к скриптами, определить аномалии и даже найти часть хакерских скриптов без сканирования сайта.
Теперь давайте посмотрим, не было ли попыток взлома сайта. Например, поиска уязвимых скриптов или обращения к хакерским шеллам. Найдем все запросы к файлам с расширением. php со статусом 404 Not Found:
find. -name «*.gz’ -exec zcat {} \; | grep ’php HTTP.* 404»> php_404.txt
grep ’php HTTP.* 404» access_log>> php_404.txt
cut -d «"» -f2 php_404.txt | cut -d ' ' -f2 | cut -d»?» -f1 | sort | uniq -c | sort -n | tail -50
На этот раз результат может быть таким:
1 /info.php
1 /license.php
1 /media/market.php
1 /setup.php
1 /shell.php
1 /wp-admin/license.php
1 /wp-content/218.php
1 /wp-content/lib.php
1 /wp-content/plugins/dzs-videogallery/ajax.php
1 /wp-content/plugins/formcraft/file-upload/server/php/upload.php
1 /wp-content/plugins/inboundio-marketing/admin/partials/csv_uploader.php
1 /wp-content/plugins/reflex-gallery/admin/scripts/FileUploader/php.php
1 /wp-content/plugins/revslider/temp/update_extract/revslider/configs.php
1/wp-content/plugins/ultimate-product-catalogue/product-sheets/wp-links-ompt.php
1/wp-content/plugins/wp-symposium/server/php/fjlCFrorWUFEWB.php
1 /wp-content/plugins/wpshop/includes/ajax.php
1 /wp-content/setup.php
1 /wp-content/src.php
1 /wp-content/themes/NativeChurch/download/download.php
1 /wp-content/topnews/license.php
1 /wp-content/uploads/license.php
1 /wp-content/uploads/shwso.php
1 /wp-content/uploads/wp-admin-cache.php
1 /wp-content/uploads/wp-cache.php
1 /wp-content/uploads/wp-cmd.php
1 /wp-content/uploads/wp_config.php
1 /wp-content/wp-admin.php
1 /wp-update.php
1 /wso2.php
2 /wp-content/plugins/dzs-zoomsounds/ajax.php
2 /wp-content/plugins/hello.php
2 /wp-content/plugins/simple-ads-manager/sam-ajax-admin.php
3 /wp-content/plugins/dzs-zoomsounds/admin/upload.php
4 /2010/wp-login.php
4 /2011/wp-login.php
4 /2012/wp-login.php
4 /wp-content/plugins/wp-symposium/server/php/index.php
Как видим из результата, подобные обращения были. Кто-то «на удачу» пытался обратиться к хакерскому шеллу в каталоге предположительно уязвимого компонента Revolution Slider /wp-content/plugins/revslider/temp/update_extract/revslider/configs.php и к WSO Shell в корне сайта и к ряду других хакерских и уязвимых скриптов. К счастью, безуспешно.
C помощью тех же find / cat / zcat / grep можно получить список IP адресов, с которых эти запросы выполнялись, дату и время обращения. Но практической пользы в этом мало.
Больше пользы от выборки всех успешных POST запросов, так как это часто помогает найти хакерские скрипты.
find. -name «*.gz’ -exec zcat {} \; | grep «POST /.* 200»> post. txt
grep «POST /.* 200» access_log>> post. txt
cut -d «"» -f2 post. txt | cut -d ' ' -f2 | cut -d»?» -f1 | sort | uniq -c | sort -n | tail -50
Результат может выглядеть следующим образом:
2 /contacts/
3 /wp-includes/x3dhbbjdu.php
7 /
8 /wp-admin/admin.php
38 /wp-admin/async-upload.php
394 /wp-cron.php
1626 /wp-admin/admin-ajax.php
1680 /wp-login.php/
6731 /xmlrpc.php
9042 /wp-login.php
Здесь видно много обращений к wp-login.php и xmlrpc.php, а также 3 успешных POST запроса к скрипту /wp-includes/x3dhbbjdu.php, которого не должно быть в Wordpress, то есть скорее всего это хакерский шелл.
Иногда полезно посмотреть выборку всех 403 Forbidden запросов, выполненных методом POST:
find. -name «*.gz’ -exec zcat {} \; | grep «POST /.* 403»> post_403.txt
grep «POST /.* 403» access_log>> post_403.txt
cut -d «"» -f2 post_403.txt | cut -d ' ' -f2 | cut -d»?» -f1 | sort | uniq -c | sort -n | tail -50
В нашем случае это выглядело так. Не очень много, хотя это могли быть попытки эксплуатации XML RPC Pingback:
8 /xmlrpc.php
Наконец, можно выбрать TOP-50 популярных запросов к сайту за сегодня:
cut -d «"» -f2 access_log | cut -d ' ' -f2 | cut -d»?» -f1 | sort | uniq -c | sort -n | tail -50
Получаем:
6 /wp-admin/images/wordpress-logo.svg
6 /wp-admin/plugins.php
7 /wp-admin/post-new.php
8 /wp-admin/async-upload.php
9 /sitemap. xml
10 /wp-admin/users.php
13 /feed/
13 /wp-admin/
20 /wp-admin/post.php
22 /wp-admin/load-styles.php
38 /favicon. ico
52 /wp-admin/load-scripts.php
58 /wp-cron.php
71 /wp-admin/admin.php
330 /wp-admin/admin-ajax.php
1198 /
2447 /wp-login.php
Статистика обращений к /wp-login.php в access_log подтверждает, что брутфорс атака на сайт еще идет (кто-то пытается подобрать пароль), поэтому следует ограничить доступ к wp-admin по IP или с помощью серверной аутентификации, а если на сайте Wordpress нет регистрации пользователей, то можно ограничить доступ и к wp-login.php.
Таким образом без каких-либо специализированных приложений и дополнительных инструментальных средств можно быстро выполнить анализ логов веб-сервера, найти подозрительные запросы и их параметры (IP адрес, User Agent, Referer, дату/время). Все что для этого нужно — подключение по SSH и базовые навыки работы с командной строкой.
2 Лог антивирусной программы
Начинаем мы с того, что запускаем программу FTK Imager.
Журналы программы
Kaspersky Security записывает информацию о своей работе (например, сообщения об ошибках программы или предупреждения) в журнал событий Windows и в журналы событий Kaspersky Security.
О журнале событий Windows
В журнал событий Windows записывается информация о работе Kaspersky Security, на основании которой администратор Kaspersky Security или специалист по информационной безопасности могут контролировать работу программы.
События, связанные с работой Kaspersky Security, регистрируются в журнале событий Windows источником KSCM8 (службой Kaspersky Security). Базовые события, связанные с работой программы, имеют фиксированные коды событий. Вы можете использовать код события для поиска и фильтрации событий в журнале.
О журналах событий Kaspersky Security
Журналы событий Kaspersky Security представляют собой файлы формата TXT, которые хранятся локально в папке <Папка установки программы> \logs. Вы можете задать для хранения журналов другую папку.
Подробность ведения журналов событий программы зависит от установленных параметров детализации журналов.
Kaspersky Security ведет журналы событий по следующему алгоритму:
• Программа записывает информацию в конец самого нового журнала.
• Когда размер журнала достигает 100 МБ, программа архивирует его и создает новый журнал.
• По умолчанию программа хранит файлы журналов в течение 14 дней с момента внесения последнего изменения в журнал, а затем удаляет их. Вы можете установить другой срок хранения журналов.
Для каждого Сервера безопасности создаются отдельные журналы независимо от варианта развертывания программы.
В папке с журналами программы и в папке с данными программы (<Папка установки программы> \data) могут содержаться конфиденциальные данные. Программа не обеспечивает защиту от несанкционированного доступа к данным в этих папках. Вам необходимо предпринять собственные меры по защите данных в этих папках от несанкционированного доступа.
SpIDer Guard G3 файловый монитор для современных ОС Windows пришедший на замену SpIDer Guard® для старых 32 битных ОС Windows.
1. spiderg3.sys — бут-драйвер, мини-фильтр файловой системы работающий на 32- и 64 -битных ОС;
2. запускается одним из первых на начальном этапе загрузки ОС;
3. отслеживает и запоминает активность (запуск процессов, загрузку модулей, файловые манипуляции…) всех процессов с самого начала загрузки ОС;
4. блокирует доступ к файлам по запросу клиента.
Настройки SpIDer Guard G3
Все настройки SpIDer Guard G3 хранятся в реестре, в ключе
HKEY_LOCAL_MACHINE\SOFTWARE\Doctor Web\Scanning Engine\SpIDer Guard\Settings
и при изменении влияют на всю систему.
Основные настройки
Core/LicensePath= [каталог]
параметр позволяет указать каталог в котором находится лицензионный ключ. Обычно это каталог установки антивируса.
Core/LicenseFile= [путь]
параметр позоляет указать для SpIDerG3, конкретный лицензионный ключ. Параметр устарел и не используется, заменен на Core/LicensePath.
Core/Watcher/Disable=dword:0/1
включает/отключает использование SE второй копии своего процесса (сторожевого пса). Вторая копия при запуске подключается к основному процессу SE как отладчик и контролирует его работу. При активном сторожевом псе, невозможно подключиться к SE отладчиком и перехватить на себя управление.
Core/Limit/Engines=dword: [кол-во движков:0]
параметр позволяет ограничивать для спайдера кол-во используемых антивирусных движков.
Core/Limit/Cores=dword: [кол-во ядер:0]
параметр позволяет ограничивать для спайдера кол-во используемых ядер процессора, на многоядерных системах. при 0-значении кол-во используемых ядер расчитывается исходя из конфигурации железа или ОС.
Core/Limit/BgScan=dword: [кол-во потоков:0]
параметр позволяет ограничивать кол-во потоков используемых для фонового сканирования (BG).
Настройки действий
Scan/Action/Infected=dword: [действие]
Scan/Action/Incurable=dword: [действие]
Scan/Action/Suspicious=dword: [действие]
Scan/Action/Archive=dword: [действие]
Scan/Action/Mail=dword: [действие]
Scan/Action/Container=dword: [действие]
Scan/Action/Dialer=dword: [действие]
Scan/Action/Adware=dword: [действие]
Scan/Action/Riskware=dword: [действие]
Scan/Action/Hacktool=dword: [действие]
Scan/Action/Joke=dword: [действие]
позволяет настроить выполняемые действия для различных видов угроз.
Возможные действия: 0 — информировать, 1 — лечить, 2 — в карантин, 4 — удалить, 8 — игнорировать.
Настройки логирования
Log/File= [путь]
параметр задает полный путь к лог-файлу спайдера.
Log/Buffered=dword:0/1
влючает/откючает буфферизированный вывод (когда строки в лог пишутся не сразу, а сначала накапливаются в памяти) в лог.
Log/Verbose=dword:1/0
включает/отключает детализированный вывод в лог.
Log/Debugging=dword:0/1
включает/выключает отладочный вывод в лог.
Log/SizeInKB=dword: [размер в кб]
параметр задает допустимый размер файла лога. при указании -1 лог не лимитирован. При указании — 0 лог не ведется.
Log/Show/Archiver=dword:1/0
включает/отключает вывод в лог информацию о архивах и их содержимом.
Log/Show/Packer=dword:1/0
включает/отключает вывод в лог информацию о упаковщиках и их содержимом.
Log/Show/OK=dword:1/0
включает/отключает вывод в лог информацию о чистых проверенных файлах.
Log/Show/Milliseconds=dword:0/1
включает/отключает вывод в лог милисекунд.
Log/Show/Skipped=dword:0/1
включает/отключает вывод в лог информацию о исключенных из проверки файлов.
Настройки проверки объектов
Scan/Heuristic=dword:1/0
включает/отключает использование эвристики при проверки файлов движком. Отключать не рекомендуется.
Scan/Check/Archive=dword:0/1
включает/отключает проверку архивов в спайдере. Крайне не рекомендуется включать данную опцию.
Scan/Check/Container=dword:1/0
включает/отключает проверку инсталляторов (кроме BINARES контейнеров) в спайдере.
Scan/Check/Mail=dword:0/1
включает/отключает проверку почтовых файлов и баз в спайдере. Крайне не рекомендуется включать данную опцию.
Scan/Check/Processes=dword:1/0
включает/отключает проверку запускаемых процессов и модулей спайдером. Отлкючать не рекомендуется.
Scan/Check/Removable=dword:1/0
включает/отключает проверку на чтение и запись файлов на сменных носителях спайдером. Отключать не рекомендуется.
Запускаемые процессы и модули на сменных носителеях проверяются независимо от состояния опции.
Scan/Check/Network=dword:0/1
включает/отключает проверку на чтение файлов с сетевых дисков и ресурсов спайдером.
Запускаемые процессы и модули на сетевых дисках и ресурсах проверяются независимо от состояния опции.
Настройки карантина
Quarantine/EnableBackup=dword:1/0
параметр включает/отключает создание в карантине резервной копии файла, при любой манипуляции с файлом (изменение/удаление). Отключать не рекомендуется.
Quarantine/MaximumSize=dword: [размер]
задает максимальный размер карантина для использования спайдером, в процентах от размера диска. По умолчанию 10%.
Quarantine/StoragePeriod=dword: [период]
задает период, указывающий как долго хранить файлы в карантине. По умолчанию 30 дней.
Лимиты на проверку
Данный набор параметр предназначен для возможной оптимизации проверки. Любые изменения данных параметров приводят к ослаблению безопасности. Без крайней необходимости менять их не стоит.
Scan/Misc/Maximum/Time=dword: [число]
данный параметр позволяет ограничивать максимальное время на проверку одного файла спайдером. Параметр задается в миллисекундах. При 0-значении лимита на время проверки нет.
Scan/Misc/Maximum/PackingLevel=dword: [число]
позволяет установить лимит на кол-во итераций распаковки упаковщиков, файла движком. По умолчанию 1000 итераций.
Scan/Misc/Archive/Maximum/Level=dword: [число]
позволяет установить лимит на кол-во уровней распаковки архива, файла движком. По умолчанию 16 уровней.
Scan/Misc/Archive/Maximum/Size=dword: [размер]
данный параметр позволяет ограничивать максимальный размер проверяемого архива спайдером. Параметр задается в Кб.
Scan/Misc/CureLimit=dword: [число]
параметр позволяет установить лимит на кол-во итераций лечения файла. По умолчанию используется значение от самого SE и равное 500.
Управление ресурсами системы
Scan/Resource/High=dword: [число]
позволяет задать процент доступных ресурсов для высокоприоритетного сканирования (запуск процессов, загрузка модулей). По умолчанию 0.
Scan/Resource/Normal=dword: [число]
позволяет задать процент доступных ресурсов для обычного сканирования (проверка файлов). По умолчанию 0.
Scan/Resource/Low=dword: [число]
позволяет задать процент доступных ресурсов для низкоприоритетного сканирования (фоновая проверка, рескан после обновления баз). По умолчанию 100.
Значения данных параметров задаются от 0 до 100.
0 — используются все доступные ресурсы системы, 100 — работает только при простое системы.
Дополнительные параметры проверки
Scan/Processes/OnCreate=dword:1/0
при значении 1, проверка процессов происходит в момент создания процесса или в момент загрузки модуля в процес, сам процесс заблокирован в момент проверки. При 0-значении запускаемые процессы и загрузка модулей не блокируется спайдером, и их проверка осуществялется в фоновом режиме. По молчанию 1 и менять не рекомендуется, т. к. Снижает безопасность.
Rescan/ResultSet=dword:1/0
включает/отключает пересканирование файлов всех загруженных процессов и модулей, при обновлении баз спайдером.
Scan/Block/Autorun=dword:1/0
включает/отключает блокировку файлов autorun.inf в корне дисков сменных носителей.
Scan/Files/BeforeAccess=dword:0/1
включает/отключает параноидальный режим проверки в спайдере. При включенной опции любое обращение к файлу будет заблокировано и проверено спайдером. Не рекомендуется включать, т.к. существенно увеличивает назгрузку на систему.
Исключения файлов и процессов
Данные разделы реестра служат для добавления различных типов исключений в спайдере.
Параметры имеют вид:
0= [строка]
1= [строка]
…
n= [строка]
[HKEY_LOCAL_MACHINE\SOFTWARE\Doctor Web\Scanning Engine\SpIDer Guard\Settings\Exclude/Files]
в данный раздел добавляются файлы и маски которые следует исключить из проверки спайдером.
[HKEY_LOCAL_MACHINE\SOFTWARE\Doctor Web\Scanning Engine\SpIDer Guard\Settings\Exclude/Paths]
в данный раздел добавляются пути которые следует исключить из проверки спайдером.
[HKEY_LOCAL_MACHINE\SOFTWARE\Doctor Web\Scanning Engine\SpIDer Guard\Settings\Exclude/Processes]
данный раздел наиболее опасен, но позволяет задействовать мощную возможность спайдера. Здесь можно задать список файлов процессов для которых спайдер будет игнорировать любую активность данного процесса. Очень действенное средство для избавления от конфликтов.
Например, зададим:
0=c:\windows\system32\notepad. exe
Теперь, любые манипуляции с файлами, процессом запущенным из c:\windows\system32\notepad. exe будут игнорироваться спайдером и не попадать на проверку.
Исключения на размер проверяемых объектов
Scan/AlwaysCheck/Limit/OLEEXPL=dword: [размер:0]
Scan/AlwaysCheck/Limit/PPT=dword: [размер:0]
Scan/AlwaysCheck/Limit/VISIO=dword: [размер:0]
Scan/AlwaysCheck/Limit/RTF=dword: [размер:0]
Scan/AlwaysCheck/Limit/HTML=dword: [размер:0]
Scan/AlwaysCheck/Limit/CHM=dword:: [размер:1024]
Scan/AlwaysCheck/Limit/EMBEDOBJ=dword:: [размер:0]
Scan/AlwaysCheck/Limit/HTMLVBA=dword: [размер:0]
Scan/AlwaysCheck/Limit/MSGVBA=dword: [размер:0]
Scan/AlwaysCheck/Limit/BINARYRES=dword: [размер:0]
Scan/AlwaysCheck/Limit/DOC1C=dword: [размер:0]
Scan/AlwaysCheck/Limit/PDF=dword:: [размер:0]
Scan/AlwaysCheck/Limit/AUTOIT=dword: [размер:0]
Данный набор опции позволяет тонко настроить ограничения на проверку различных типов файлов, что гораздо безопаснее чем исключения по имени или маске. Размер задается в КБ.
3 Системные исключения
Exclude/SystemFiles=dword:1/0 — включает/отключает игнорирование проверки специальных системных путей и файлов, согласно рекомендации Microsoft. Набор строк и файлов зависит от версии ОС, типа ОС (рабочая станция, сервер, контролер домена…). Включение данной опции позволяет избавится от возможных конфликтов и снижения производительности на высокопроизводительных серверах и контролерах домена.
Exclude/PrefetcherDB=dword:0/1 — позволяет исключить из проверки файлы базы данных префетчера, это база данных создается системой, и служит для ускорения повторного запуска приложений Включение данной опции в некоторых случаях может повысить производительность системы.
Exclude/SearchDB=dword:0/1 — позволяет исключить из проверки файлы базы данных службы индексирования. Это служебная служба для индексирования файлов на дисках. Включение данной опции может повысить производительность системы при условии что в ОС включено индексирование файлов.
Лог веб-сервера счетчики
Теоретически существует два основных метода подсчета статистики: использование анализатора логов и применение счетчика посещений.
Каждый из названных методов имеет свои плюсы и минусы, однако в большинстве случаев более просты в применении и подходят для широкого круга пользователей именно счетчики, а лог-анализаторы, как правило, сложны в настройке (требуется специальная подготовка конфигурационных файлов), а потому в большей степени ориентированы на профессионалов. Хотя при желании можно отыскать и простые в применении анализаторы логов (правда, все подобные решения оказываются платными и чаще всего достаточно дорогими), и не совсем банальные в использовании счетчики.
При этом ни один из методов не обеспечивает полной достоверности статистических данных, и на практике показания счетчиков и лог-анализаторов могут различаться в десятки раз. Оптимальным решением является комбинация обоих методов сбора информации, поскольку только в этом случае возможно получить наиболее близкие к реальности данные.
Анализаторами логов называют программы, которые сами не занимаются сбором статистики, но умеют анализировать серверные логи (то есть данные обо всех обращениях к серверу, записанные им в лог-файлы). Теоретически лог-файлы можно просматривать и вручную через текстовый редактор, но это достаточно трудоемко, а при большом (в сотни и тысячи) числе посетителей и вообще невозможно.
Гораздо удобнее использовать анализаторы логов, преобразующие данные в понятные отчеты. Поскольку web-сервер фиксирует все обращения к сайту, то формируемые на их основе отчеты обеспечивают самую полную статистику о посетителях и могут рассказать очень много. Так, с помощью отчетов анализаторов можно узнать не только общее количество хитов и хостов, но и выяснить, по каким ссылкам приходили на сайт посетители, на каких именно страницах они были, какие файлы загрузили, сколько времени провели, с каких страниц ушли, смогли ли вообще загрузить нужные им страницы и т. д. Серверные логи также позволяют учитывать число заходов с поисковиков, вести статистику поисковых запросов, определять маршруты перемещения пользователей по сайту, вести статистику рефереров и отслеживать деятельность поисковых роботов и т. д. Иными словами, приведенная в отчетах лог-анализаторов статистика отличается максимально возможной полнотой (последнее, правда, относится лишь к профессиональным решениям) и позволяет проанализировать работу проекта и выявить имеющиеся проблемы.
В то же время в подавляющем большинстве случаев хостеры в целях минимизации размера лог-файлов не включают на серверах возможность фиксации cookies — в итоге точно идентифицировать посетителей по серверным логам удается далеко не всегда, ведь зачастую руководствоваться приходиться только IP-адресами. А один IP-адрес в действительности не может ассоциироваться с одним и тем же пользователем — у части пользователей адреса динамические, при работе через прокси-сервер множество пользователей получают одинаковый IP-адрес, часть пользователей применяет софт для сокрытия своих IP-адресов и т. д. Все это означает, что на базе серверных логов нельзя получить статистику, важную для электронной коммерции, например отчеты по продажам.
В отличие от анализаторов, счетчики посещений собирают данные для анализа самостоятельно, правда для этого требуется разместить на страницах исследуемого сайта специальный код, по которому при обращении к странице (когда наряду с содержимым сайта загружается еще и внешний элемент — чаще всего картинка) записываются данные о посетителе. Счетчики ведут общую статистику посещаемости с детальным распределением по времени, фиксируют хосты и хиты, выявляют уникальных посетителей (с подробной информацией о каждом из них — IP-адрес, браузер, ОС, новый/старый и др.) вкупе с количеством посещенных ими страниц и временем пребывания на каждой из них. Кроме того, счетчики фиксируют рефереров, нередко могут запоминать данные о путях перемещения посетителя по сайту, начиная с точки захода на сайт и заканчивая точкой выхода, могут определять информацию о цветности, разрешении экрана, языке браузера и пр.
Вместе с тем собранную счетчиками статистику нельзя признать полной, ведь они не могут подсчитать трафик, не предоставят данные о загрузке пользователем файлов, флэш-объектов, картинок, активизации ссылок и форм и, как правило, не умеют отслеживать поисковых роботов и т. д. Да и назвать точной статистику от счетчиков нельзя по многим причинам. Счетчики берут данные из cookies, получение информации из которых может блокироваться в браузере. Они управляются скриптами, поддержку которых в браузере несложно отключить. Пользователь может работать с несколькими браузерами, что еще больше запутывает ситуацию. Кроме того, при медленной связи некоторые картинки (в том числе и картинки счетчиков) могут просто не успевать загрузиться, ведь пользователь, увидев требуемую информацию, никогда не станет ждать окончания загрузки страницы, а перейдет дальше по нужной ссылке. И наконец, многие из тех, кто использует dial-up, просто отключают загрузку картинок в браузере, так что картинка счетчика потенциально не может загрузиться, а следовательно, скрипт не сработает и пользователь останется неучтенным. Так что погрешность собираемых счетчиками данных внушительна и, как считают многие специалисты в данной сфере, может составлять до 30%.
Счетчики бывают внешними и внутренними. Первые реализованы как веб-сервисы и управляются с удаленного сервера, на которых и хранится вся собираемая информация. Данный тип статистики широко распространен и прельщает многих пользователей относительной бесплатностью (на самом деле никакой благотворительности тут нет, так как на сайте размещается картинка с логотипом соответствующего сервиса, по сути представляющая собой его рекламу) и простотой использования. Внешние счетчики не обеспечивают получение статистики в режиме реального времени (они выдают ее с некоторым опозданием) и не умеют отслеживать роботов. Кроме того, собираемая ими информация хранится на внешнем сервере, а это небезопасно. Для бесплатных счетчиков можно назвать еще ряд минусов. Во-первых, никто не гарантирует бесперебойной работы счетчика (или хотя бы uptime в 99%) и высокой скорости загрузки сайта со счетчиком. Во-вторых, на сайт придется устанавливать видимые картинки счетчика с логотипом соответствующего веб-сервиса, которые, как правило, совсем не вписываются в дизайн сайта. В-третьих, не всегда есть возможность получить услугу анонимно, то есть без регистрации в различных рейтингах и каталогах.
Внутренние счетчики (или внутренние системы статистики) управляются с собственного сервера и представлены отдельными модулями, которые устанавливаются со стороны клиента либо интегрируются в систему управления сайтом. Они обеспечивают доступ к статистике в режиме реального времени и гарантируют конфиденциальность информации. Разработчики сайтов для установки подобных счетчиков пишут требуемые модули самостоятельно либо прибегают к независимым коммерческим решениям, которые в большинстве своем обеспечивают получение очень широкого спектра статистической информации, важной как для администраторов сайтов, так и для маркетологов.
4 Лабораторный практикум
4.1 Лабораторная работа №1. Исследование мультимедийного трафика
Задание
В программе WireSharkвыполнить:
1. Восстановить аудиопоток переданный через протокол SIR
2. Восстановить видеопоток.
Перечень необходимых инструментов
Wireshark — это достаточно известный инструмент для захвата и анализа сетевого трафика, фактически стандарт как для образования, так и для траблшутинга.
Wireshark работает с подавляющим большинством известных протоколов, имеет понятный и логичный графический интерфейс на основе GTK+ и мощнейшую систему фильтров.
Кроссплатформенный, работает в таких ОС как Linux, Solaris, FreeBSD, NetBSD, OpenBSD, Mac OS X, и, естественно, Windows. Распространяется под лицензией GNU GPL v2. Доступен бесплатно на сайте официальном сайте wireshark.org.
Установка в системе Windows проста, жмем далее, далее, далее.
Зачем вообще нужны анализаторы пакетов?
Для того чтобы проводить исследования сетевых приложений и протоколов, а также, чтобы находить проблемы в работе сети, и, что важно, выяснять причины этих проблем.
Вполне очевидно, что для того чтобы максимально эффективно использовать снифферы или анализаторы трафика, необходимы хотя бы общие знания и понимания работы сетей и сетевых протоколов.
Так же во многих странах использование сниффера без явного на то разрешения приравнивается к преступлению.
SIP (Session Initiation Protocol — протокол установления сеанса), разработанный одним из отделений IETF — MMUSIC (Multiparty Multimedia Session Control). Описывается в спецификации RFC 2543 и RFC 3261.
SIP — это протокол прикладного уровня модели OSI, описывающий способы и правила установления интернет-сессий для обмена мультимедийной информацией, такой как: звук, голос, видеоряд, графика и др. Для соединения обычно используется порт 5060 или 5061. В качестве транспортных протоколов SIP поддерживает: UDP, TCP, SCTP, TLS. Протокол SIP широко применяется в офисной IP-телефонии, видео и аудио-конференциях, онлайн играх и др.
Протокол SIP имеет клиент-серверную модель. Основными функциональными элементами являются:
Абонентский терминал. Устройство, с помощью которого абонент управляет установлением и завершением звонков. Может быть реализован как аппаратно (SIP-телефон), так и программно (Софтфон).
Прокси-сервер. Устройство, которое принимает и обрабатывает запросы от терминалов, выполняя соответствующие этим запросам действия. Прокси-сервер состоит из клиентской и серверной частей, поэтому может принимать вызовы, инициировать запросы и возвращать ответы.
Сервер переадресации. Устройство, хранящее записи о текущем местоположении всех имеющихся в сети терминалах и прокси-серверах. Сервер переадресации не управляет вызовами и не генерирует собственные запросы.
Сервер определения местоположения пользователей. Представляет собой базу данных адресной информации. Необходим для обеспечения персональной мобильности пользователей.
Важные преимущества
Так как группа MMUSIC разрабатывала протокол SIP с учётом недостатков предшествующего ему H.323, то SIP обзавелся следующими достоинствами:
Простота
Так как SIP унаследовал текстовый формат сообщений от HTTP, то в случае если одному терминалу при установлении соединения неизвестна какая-либо возможность, известная другому, то данный факт попросту игнорируется. Если же такая ситуация возникнет с протоколом H.323, то это приведет к сбою соединения, т.к H.323 имеет бинарный формат сообщений и все возможности протокола описаны в соответствующей документации.
Масштабируемость
В случае расширения сети, при использовании протокола SIP, существует возможность добавления дополнительного числа пользователей.
Мобильность
Благодаря гибкой архитектуре протокола SIP, пропадает необходимость заново регистрировать пользователей, в случае смены ими своего местоположения.
Расширяемость
При появлении новый услуг существует возможность дополнят протокол SIP новыми функциями.
Взаимодействие с другими протоколами сигнализации
Имеется возможность использования протокола SIP с протоколами сигнализации сетей ТфОП, такими как DSS-1 и ОКС7.
Типы Запросов
Для организации простейшего вызова в протоколе SIP, предусмотрено 6 типов информационных запросов:
INVITE — Инициирует вызов от одного терминала к другому. Содержит описание поддерживаемых сервисов (которые могут быть использованы инициатором сеанса), а также виды сервисов, которые желает передавать инициатор;
ACK — Подтверждение установления соединения адресатом. Содержит окончательные параметры сеанса связи, выбранные для установления сеанса связи;
Cancel — Отмена ранее переданных неактуальных запросов;
BYE — Запрос на завершение соединения;
Register — Идентификация местоположения пользователя;
OPTIONS — Запрос на информацию о функциональных возможностях терминала, обычно посылается до фактического начала обмена сообщениями INVITE, ACK;
SIP — ОТВЕТЫ
Определено 6 типов ответов, которым прокси-сервер описывает состояние соединения, например: подтверждение установления соединения, передача запрошенной информации, сведения о неисправностях др.
1ХХ — Информационные ответы; показывают, что запрос находится в стадии обработки. Наиболее распространённые ответы данного типа — 100 Trying, 180 Ringing, 183 Session Progress.
2ХХ — Финальные ответы, означающие, что запрос был успешно обработан. В настоящее время в данном типе определены только два ответа — 200 OK и 202 Accepted (прим. 202 кода нет в RFC 3261).
3ХХ — Финальные ответы, информирующие оборудование вызывающего пользователя о новом местоположении вызываемого пользователя, например, ответ 302 Moved Temporary.
4ХХ — Финальные ответы, информирующие об отклонении или ошибке при обработке или выполнении запроса, например, 403 Forbidden или классический для протокола HTTP ответ 404 Not Found. Другие примеры: 406 Not Acceptable — неприемлемый (по содержанию) запрос, 486 Busy Here — абонент занят или 487 Request Terminated — вызывающий пользователь разорвал соединение не дожидаясь ответа (отмена запроса).
5ХХ — Финальные ответы, информирующие о том, что запрос не может быть обработан из-за отказа сервера, 500 Server Internal Error.
6ХХ — Финальные ответы, информирующие о том, что соединение с вызываемым пользователем установить невозможно, например, ответ 603 Decline означает, что вызываемый пользователь отклонил входящий вызов.
Протокол SIP определяет 3 основных сценария установления соединения: с участием прокси-сервера, с участием сервера переадресации и непосредственно между пользователями. Сценарии отличаются по тому, как осуществляется поиск и приглашение вызываемого пользователя.
Подробное знакомство с WireShark
Даже поверхностное знание программы Wireshark и её фильтров на порядок сэкономит время при устранении проблем сетевого или прикладного уровня. Wireshark полезен для многих задач в работе сетевого инженера, специалиста по безопасности или системного администратора. Вот несколько примеров использования:
• Устранение неполадок сетевого подключения
• Визуальное отображение потери пакетов
• Анализ ретрансляции TCP
• График по пакетам с большой задержкой ответа
• Исследование сессий прикладного уровня (даже при шифровании с помощью SSL/TLS, см. ниже)
• Полный просмотр HTTP-сессий, включая все заголовки и данные для запросов и ответов
• Просмотр сеансов Telnet, просмотр паролей, введённых команд и ответов
• Просмотр трафика SMTP и POP3, чтение писем
• Устранение неполадок DHCP с данными на уровне пакетов
• Изучение трансляций широковещательного DHCP
• Второй шаг обмена DHCP (DHCP Offer) с адресом и параметрами
• Клиентский запрос по предложенному адресу
• Ack от сервера, подтверждающего запрос
• Извлечение файлов из сессий HTTP
• Экспорт объектов из HTTP, таких как JavaScript, изображения или даже исполняемые файлы
• Извлечение файлов из сессий SMB (Аналогично опции экспорта HTTP, но извлечение файлов, передаваемых по SMB, протоколу общего доступа к файлам в Windows)
• Обнаружение и проверка вредоносных программ
• Обнаружение аномального поведения, которое может указывать на вредоносное ПО
• Поиск необычных доменов или конечных IP
• Графики ввода-вывода для обнаружения постоянных соединений (маячков) с управляющими серверами
• Отфильтровка «нормальных» данных и выявление необычных
• Извлечение больших DNS-ответов и прочих аномалий, которые могут указывать на вредоносное ПО
• Проверка сканирования портов и других типов сканирования на уязвимости
• Понимание, какой сетевой трафик поступает от сканеров
• Анализ процедур по проверке уязвимостей, чтобы различать ложноположительные и ложноотрицательные срабатывания
Эти примеры — только вершина айсберга.
Установка Wireshark
Wireshark работает на различных операционных системах и его несложно установить. Упомянем только Ubuntu Linux, Centos и Windows.
Установка на Ubuntu или Debian
• #apt-get update
• #apt-get install wireshark tshark
Установка на Fedora или CentOS
• #yum install wireshark-gnome
Установка на Windows
На официальной странице загрузки лежит исполняемый файл для установки. Довольно просто ставится и драйвер захвата пакетов, с помощью которого сетевая карта переходит в «неразборчивый» режим (promiscuous mode позволяет принимать все пакеты независимо от того, кому они адресованы).
Начало работы с фильтрами
С первым перехватом вы увидите в интерфейсе Wireshark стандартный шаблон и подробности о пакете.
Как только захватили сессию HTTP, остановите запись и поиграйте с основными фильтрами и настройками Analyze | Follow | HTTP Stream.
Названия фильтров говорят сами за себя. Просто вводите соответствующие выражения в строку фильтра (или в командную строку, если используете tshark). Основное преимущество фильтров — в удалении шума (трафик, который нам не интерестен). Можно фильтровать трафик по MAC-адресу, IP-адресу, подсети или протоколу. Самый простой фильтр — ввести http, так что будет отображаться только трафик HTTP (порт tcp 80).
Примеры фильтров по IP-адресам
• ip.addr == 192.168.0.5
• !(ip.addr == 192.168.0.0/24)
Примеры фильтров по протоколу
• tcp
• udp
• tcp. port == 80 || udp. port == 80
• http
• not arp and not (udp. port == 53)
Попробуйте сделать комбинацию фильтров, которая показывает весь исходящий трафик, кроме HTTP и HTTPS, который направляется за пределы локальной сети. Это хороший способ обнаружить программное обеспечение (даже вредоносное), которое взаимодействует с интернетом по необычным протоколам.
Практическая часть
Выполним перехват протокола SIP используя сниффер «Wireshark»
Протокол SIP определяет 3 основных сценария установления соединения: с участием прокси-сервера, с участием сервера переадресации и непосредственно между пользователями. Сценарии отличаются по тому, как осуществляется поиск и приглашение вызываемого пользователя.
На рисунке 1 можно увидеть список пользователей SIP, результат перехвата декодируем в RTP, далее можно прослушать разговор (рисунок 2).
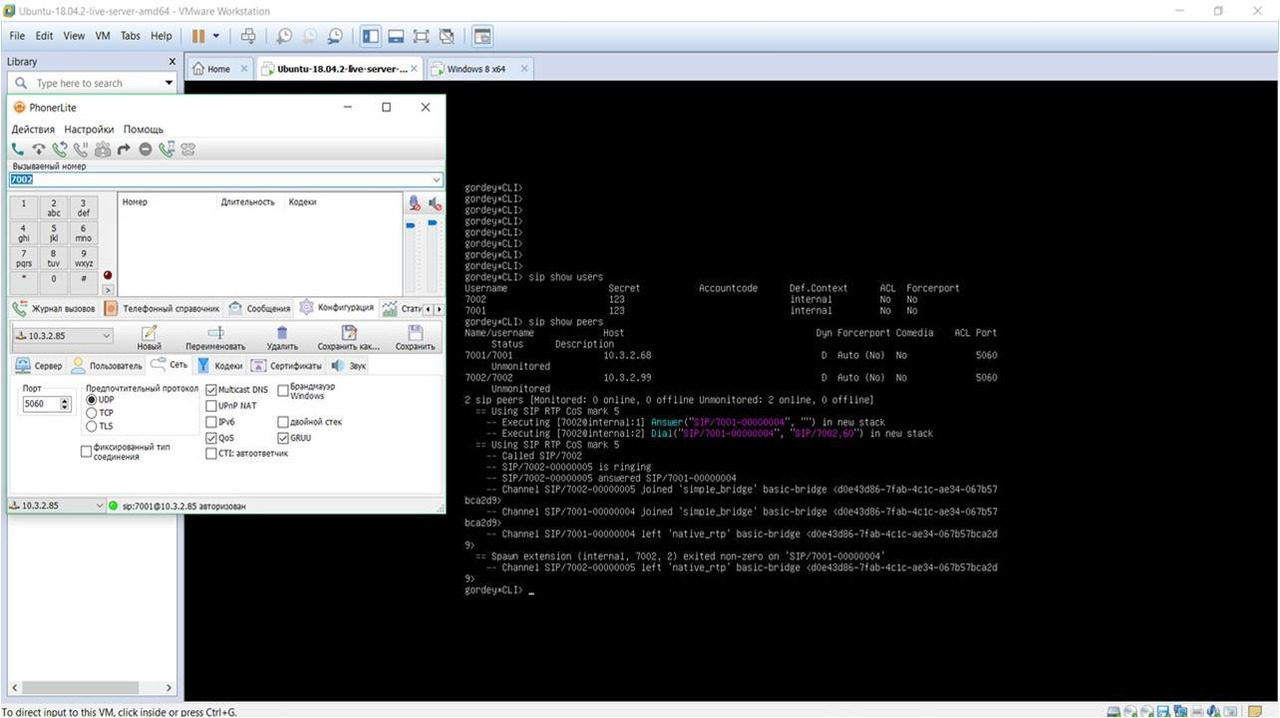
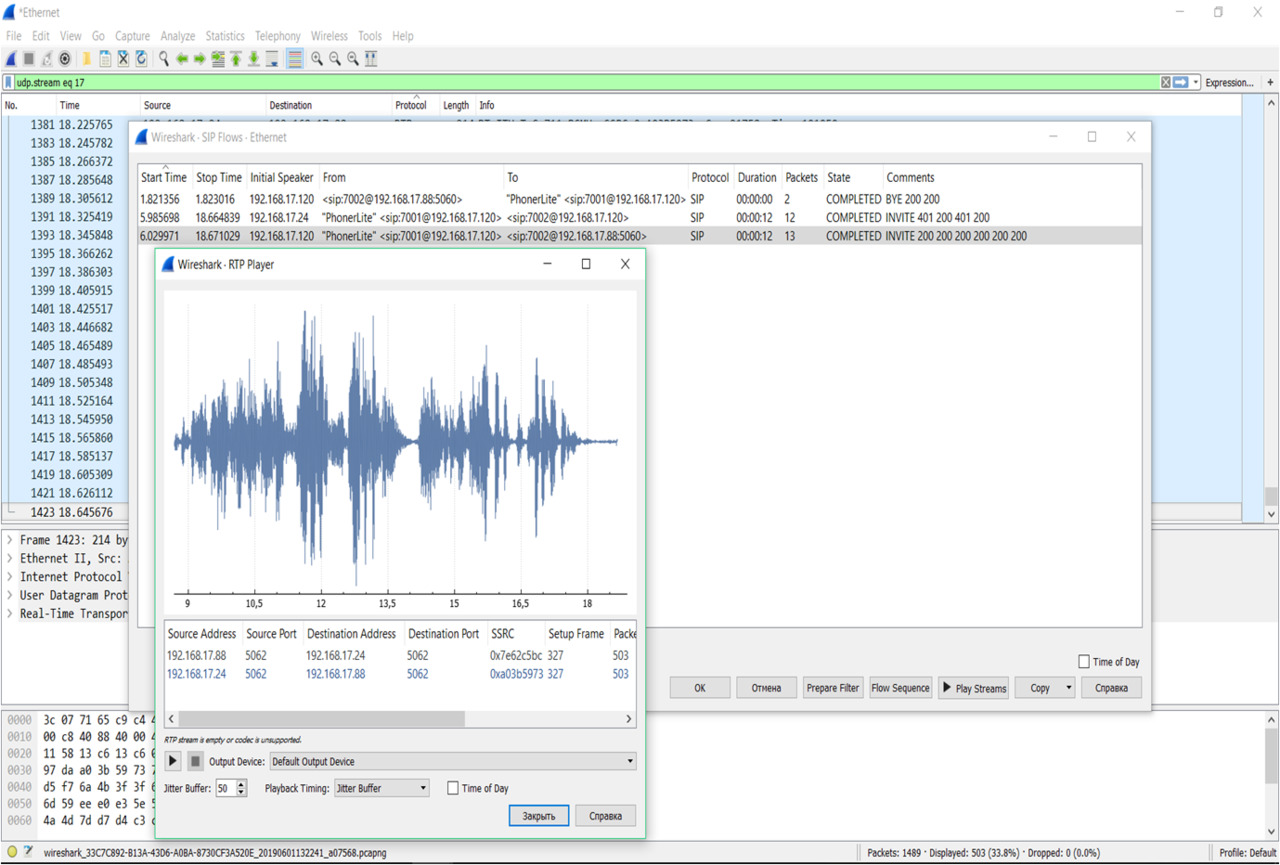
Рисунок 2 — Результат перехвата
4.2 Лабораторная работа №2. Исследование данных передаваемых через протокол TCP
Задание
В программе Wiresharkвыполнить:
Восстановить информацию переданную по протоколу FTP;
Восстановить информацию переданную по протоколу SMB2;
Восстановить информацию переданную по протоколу HTTP;
Восстановить информацию переданную по протоколу SMPT;
Восстановить информацию переданную по протоколу POP3;
Восстановить информацию переданную по протоколу DNS;
Восстановить информацию переданную по протоколу NNTP;
Восстановить информацию переданную по протоколу telnet;
Восстановить информацию переданную по протоколу LDAP;
Восстановить информацию переданную по протоколу HTTPS.
Выполнение работы
Эхо-запрос ping — утилита для проверки целостности и качества соединений в сетях на основе TCP/IP, а также обиходное наименование самого запроса. Название происходит от английского названия звука импульса, издаваемого сонаром.
Соберем лабораторный стенд, нам понадобится 2 компьютера, hubс выходом в интернет. Компьютеры должны быть связаны меж собой через hub. Назовем первый компьютер «PC-1»с ipадресом (192.168.1.10/24) и дадим второму компьютеры название соответственно «PC-2»cipадресом (192.168.1.12/24). Затем передадим echo-запрос с «PC-1»на «PC-2», IP-адрес «PC-2» можно увидеть на рисунке 3, выполнение pingпредставлено на рисунке 4.
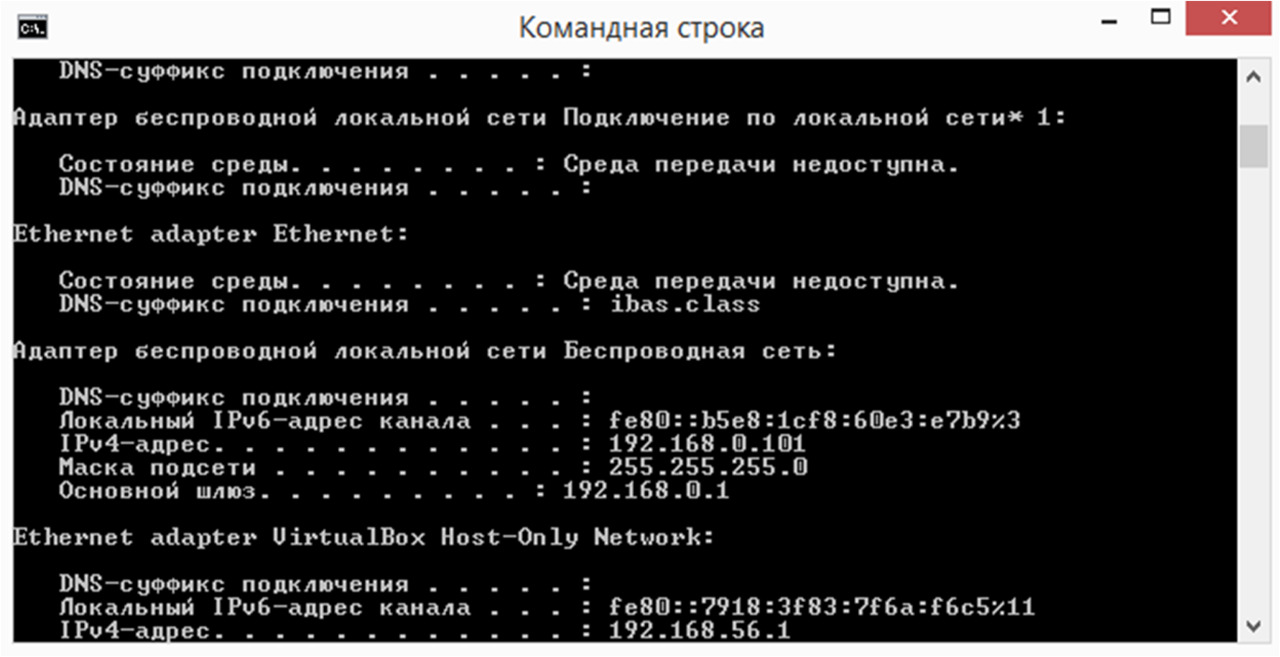
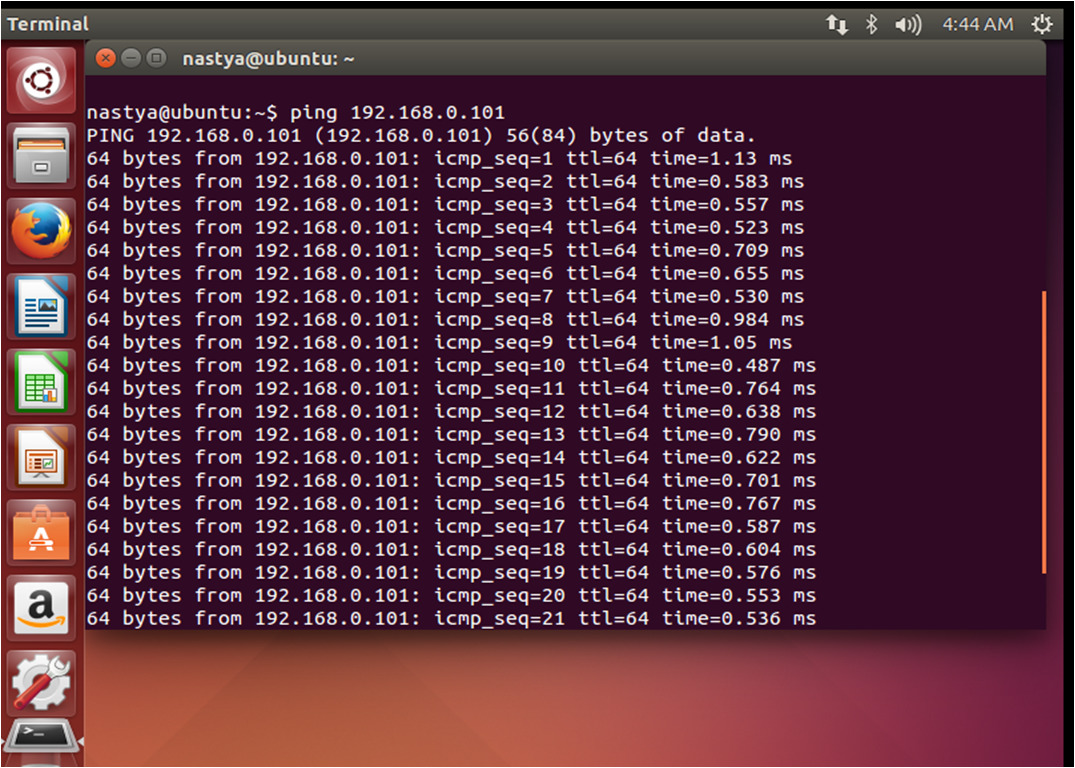
Далее во время передачи echo-запроса выполнимперехват трафикана «Attacker» (атакующий пк т. е. PC-2) используя сниффер «Wireshark» — программа-анализатор трафика для компьютерных сетей Ethernet и некоторых других. Результат перехвата представлен на рисунке 5.
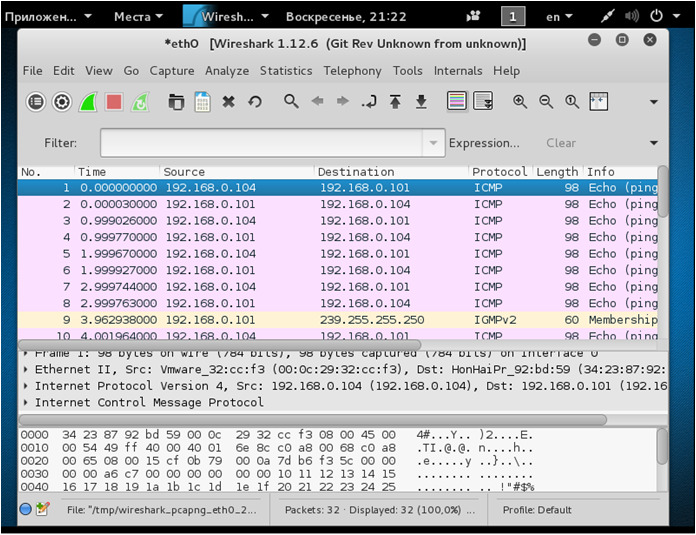
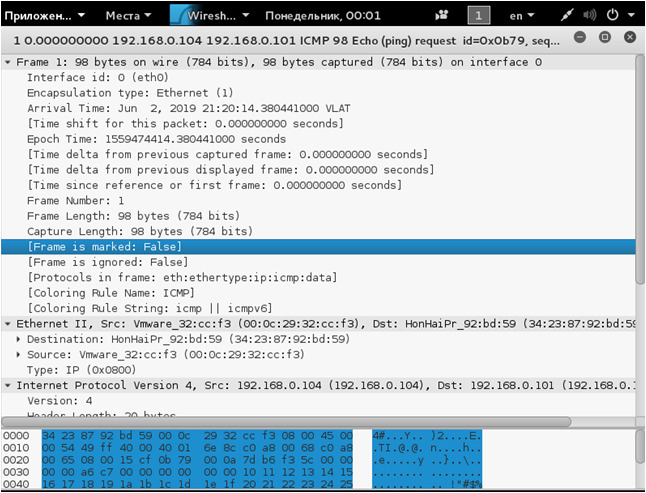
На рисунке видно, что ping проходил между ПК с адресами: 192.168.0.104 и 192.168.0.101, атакующий ПК перехватил ICMPпакеты. Нажмем два раза на интересующий нас пакет, после чего можно увидеть информацию об интересующем нас пакете (рисунок 6).
Далее осуществим передачу файлов». txt», «.png»,». rar» по протоколу «SMB» с «PC-1» на «PC-2».
SMB — это протокол, основанный на технологии клиент-сервер, который предоставляет клиентским приложениям простой способ для чтения и записи файлов, а также запроса служб у серверных программ в различных типах сетевого окружения. Серверы предоставляют файловые системы и другие ресурсы (принтеры, почтовые сегменты, именованные каналы и т. д.) для общего доступа в сети. Клиентские компьютеры могут иметь у себя свои носители информации, но также имеют доступ к ресурсам, предоставленным сервером для общего пользования.
Клиенты соединяются с сервером, используя протоколы TCP/IP (а, точнее, NetBIOS через TCP/IP), NetBEUI или IPX/SPX. После того, как соединение установлено, клиенты могут посылать команды серверу (эти команды называются SMB-команды или SMBs), который даёт им доступ к ресурсам, позволяет открывать, читать файлы, писать в файлы и вообще выполнять весь перечень действий, которые можно выполнять с файловой системой. Однако в случае использования SMB эти действия совершаются через сеть.
Основные элементы структуры заголовка SMB:
• Command — команда протокола.
• RCLS — код класса ошибки.
• ERR — код ошибки.
• Tree ID (TID) — идентификатор соединения с сетевым ресурсом.
• Process ID (PID) — идентификатор клиентского процесса фактического соединения.
• User ID (UID) — идентификатор пользователя; используется сервером для проверки прав доступа пользователя.
•Multiplex ID (MID) — идентификатор группы пользователя; используется сервером для проверки прав доступа группы пользователя.
• WCT — количество параметров, следующих за заголовком.
• BCC — количество байт данных, следующих за параметрами
TCP/IP — сетевая модель передачи данных, представленных в цифровом виде. Модель описывает способ передачи данных от источника информации к получателю. В модели предполагается прохождение информации через четыре уровня, каждый из которых описывается правилом.
Пользовательская команда mail, пользовательские команды обработки сообщений (MH) и команда сервера sendmail могут применять TCP/IP для передачи сообщений между системами, а основные сетевые утилиты (BNU) могут применять TCP/IP для передачи файлов и команд между системами.
Для получения информации о состоянии локального или удаленного хоста и сети, к которой он подключен, в TCP/IP предусмотрены определенные команды.
Finger или f показывает информацию о текущих пользователях заданного хоста. Эта информация включает: идентификатор пользователя, его полное имя, имя терминала, дату и время входа в систему.
Хост преобразует имя хоста в его IP-адрес или наоборот.
ping помогает определить состояние сети или хоста. Чаще всего эта команда применяется для проверки работоспособности сети или хоста.
rwho показывает список пользователей, которые в настоящий момент работают на хостах локальной сети. В списке указывается имя пользователя, имя хоста, а также дата и время входа в систему.
whois определяет принадлежность псевдонима или ИД пользователя. Эта команда применяется только в тех локальных сетях, которые подключены к сети Internet.
Основные элементы структуры заголовка SMB:
• Command — команда протокола.
• RCLS — код класса ошибки.
• ERR — код ошибки.
• Tree ID (TID) –идентификатор соединения с сетевым ресурсом.
• Process ID (PID) — идентификатор клиентского процесса фактического соединения.
• User ID (UID) — идентификатор пользователя; используется сервером для проверки прав доступа пользователя.
• Multiplex ID (MID) — идентификатор группы пользователя; используется сервером для проверки прав доступа группы пользователя.
• WCT — количество параметров, следующих за заголовком.
• BCC — количество байт данных, следующих за параметрами.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.