
Бесплатный фрагмент - Базы данных. Учебное пособие
Для студентов
«Сложная система, спроектированная наспех, никогда не работает, и исправить её, чтобы заставить работать, невозможно». Закон Мерфи
Введение
Любая информационная система сегодня в обязательном порядке включает в себя базу данных. Это может быть и база данных персонала и база данных контрагентов, товаров, услуг. Хотя большинство предприятий используют электронные таблицы, а не системы управления базами данных, но в ближайшем будущем все однозначно изменится. Использование электронных таблиц имеет свои неоспоримые преимущества в случае, если необходимо организовать небольшой массив данных и работать с ним приходится не часто. В случае же если «чистый» размер данных превосходит 100 Мб, то обработка таких массивов даже на современных ЭВМ с использованием электронных таблиц будет через мерно долгой.
СУБД эволюционируют вместе с данными. Сегодня OLAP кубы уже не являются ноу хау, а скорее превратились в обыденность, хотя еще 5 лет назад можно было по пальцам сосчитать предприятия использующие Oracle.
Отметим и все возрастающую роль распределенной обработки данных, поскольку когда возникают проблемы связанные с big data, даже хранение массивов в несколько десятков террабайт не представляется возможным на одной ЭВМ (исключая конечно специализированные системы хранения данных).
В данном пособии автор заостряет внимание на использовании СУБД Microsoft SQL Server и MySQL, поскольку первая используется во многих компаниях как стандарт дефакто, а вторая является свободно распространяемой и входит в комплект практически любого дистрибутива Unix-подобных операционных систем, дополнительно прекрасно интегрируется с PHP позволяя создавать платформы и приложения не только desktop но и web.
Все товарные знаки указанные в книге являются собственностью их правообладателей, а совпадения имен, названий, наименований и прочего — чистой случайностью.
Лекции
Лекция 1—3
База данных — это совокупность взаимосвязанных данных, находящихся под управлением системы управления базой данных (СУБД).
Система управления базой данных — совокупность языковых и программных средств, облегчающих для пользователей выполнение всех операций, связанных с организацией хранения данных, их корректировки и доступа к ним.
Этапы проектирования реляционной БД декомпозиционным методом
1) Разрабатывается универсальное отношение для БД (в универсальное отношение включаются все атрибуты, представляющие интерес для данного проектирования).
2) Определяются все функциональные зависимости между атрибутами данного отношения.
3) Определяется, находится ли отношение в нормальной форме Бойса — Кодда. Если да, то проектирование завершается, если нет, то осуществляется декомпозиция, т.е. разбиение отношения.
4) Шаги 2) и 3) повторяются для каждого нового отношения, полученного в результате декомпозиции. Проектирование завершается, когда все отношения будут находиться в НФБК.
Ключ — поле (атрибут), по которому можно однозначно определить каждую запись в таблице.
Функциональная зависимость — (А-> В) атрибут В функционально зависит от атрибута А если в любой момент времени каждому значению атрибута А соответствует одно значение атрибута В.
Атрибут В функционально полно зависит от атрибута А если В не зависит ни от какого подмножества А.
Нормализация — процесс построения оптимальной структуры таблиц и связи между ними.
Теория нормализации основана на том, что определенный набор таблиц обладает лучшими свойствами при включении, модификации и удалении данных, чем все остальные наборы таблиц, с помощью которых могут быть представлены те же данные.
Нормализованным отношением называют отношение, каждое поле которого содержит только атомарные значения. (пример про ФИО)
Определение первой нормальной формы (1НФ): отношение r находится в 1НФ, если каждый его элемент имеет и всегда будет иметь атомарное значение. (Это определение просто устанавливает тот факт, что любое нормализованное отношение находится в 1НФ.)
Определение второй нормальной формы (2НФ): отношение r находится во 2НФ, если оно находится в 1НФ и если каждый его атрибут, не являющийся основным атрибутом, функционально полно зависит от первичного ключа этого отношения.
Определение третьей нормальной формы (3НФ): отношение r находится в 3НФ, если оно является отношением во 2НФ и каждый его атрибут, не являющийся основным, не транзитивно зависит от первичного ключа этого отношения.
Транзитивная зависимость определяется следующим образом: если X -> Y и Y -> Z, то X -> Z (Z транзитивно зависит от X).
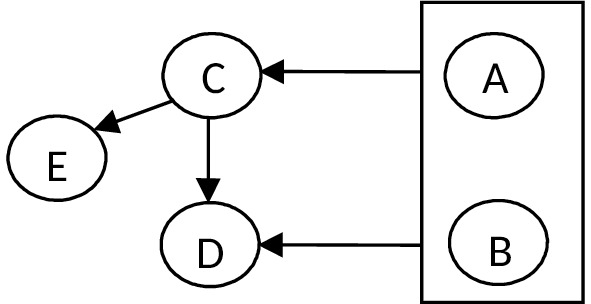
A, B -> C
A, B -> D
C -> D
C -> E
Первичный ключ: AB.
Отношение находится в 1НФ, поскольку все атрибуты имеют атомарные значения.
Отношение находится во 2НФ, т.к. все атрибуты функционально полно зависят от первичного ключа отношения.
Так как A, B -> C; C -> E, т. е. E транзитивно зависит от первичного ключа, значит отношение не находится в 3НФ.
Отношение находится в НФБК если каждый детерминант отношения является его возможным ключом.
Детерминант — это атрибут, от которого зависит другой атрибут.
Отношение r находится в 4НФ тогда и только тогда, когда при существовании многозначной зависимости в r атрибута Y от атрибута X, все остальные атрибуты r функционально зависят от Х.
Атрибут Х многозначно определяет атрибут Y, если с каждым значением x может использоваться значение y из фиксированного подмножества значений Y. Обозначается: X ↠ Y.
Избыточной функциональной зависимостью называют зависимость, заключающую в себе такую информацию, которая может быть получена на основе других зависимостей из числа использованных при проектировании БД.
Пусть r — отношение со схемой R,
w, x, y, z — подмножества R.
1-я аксиома вывода. Рефлексивность.
В r всегда имеет место Х -> Х
2-я аксиома вывода. Пополнение.
Если r удовлетворяет Х -> Y, то r удовлетворяет F-зависимости XZ -> Y
3-я аксиома вывода. Аддитивность (так же известна под названием — объединение).
Если отношение r удовлетворяет X -> Y и X -> Z, то r удовлетворяет F-зависимости Х -> YZ. (можно объединить правые части)
4-я аксиома вывода. Проективность.
Если отношение r удовлетворяет X -> YZ, то r удовлетворяет X -> Y и X -> Z.
(разбиваем совокупность)
5-я аксиома вывода. Транзитивность.
Х -> Y и Y -> Z влечет за собой X -> Z. (избыточная транзитивная зависимость может быть удалена)
6-я аксиома вывода. Псевдотранзитивность.
Если r удовлетворяет зависимостям X -> Y и YZ -> W, то r удовлетворяет XZ -> W.
Исходная диаграмма функциональных зависимостей:
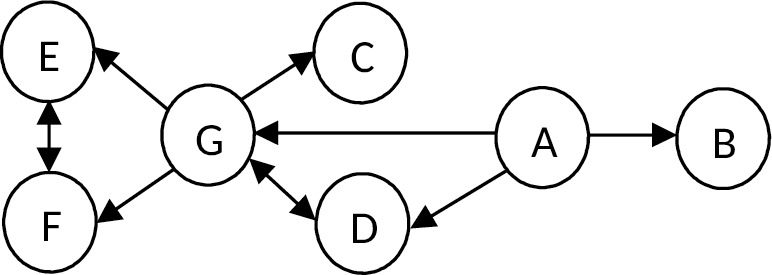
A -> B; A -> D; A -> G,
D -> G,
G -> D; G -> C; G -> F; G -> E,
E -> F,
F -> E
Удалим из исходного набора функциональных зависимостей все избыточные:
— т. к. A -> D, D -> G, то A -> G — исключим по аксиоме транзитивности
— т. к. G -> E, E -> F, то G -> F исключим по аксиоме транзитивности
— т. к. G -> E, G -> C, то по аксиоме аддитивности G -> E, C
— т. к. A -> B; A -> D, то по аксиоме аддитивности A -> D, B
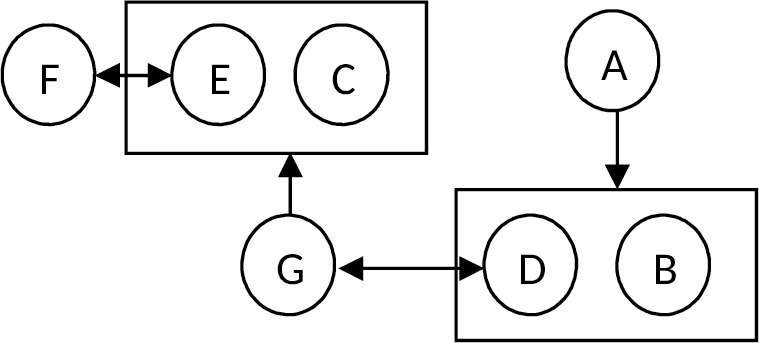
Окончательная диаграмма функциональных зависимостей:
Пример проектирования методом декомпозиции БД интернет-магазин.
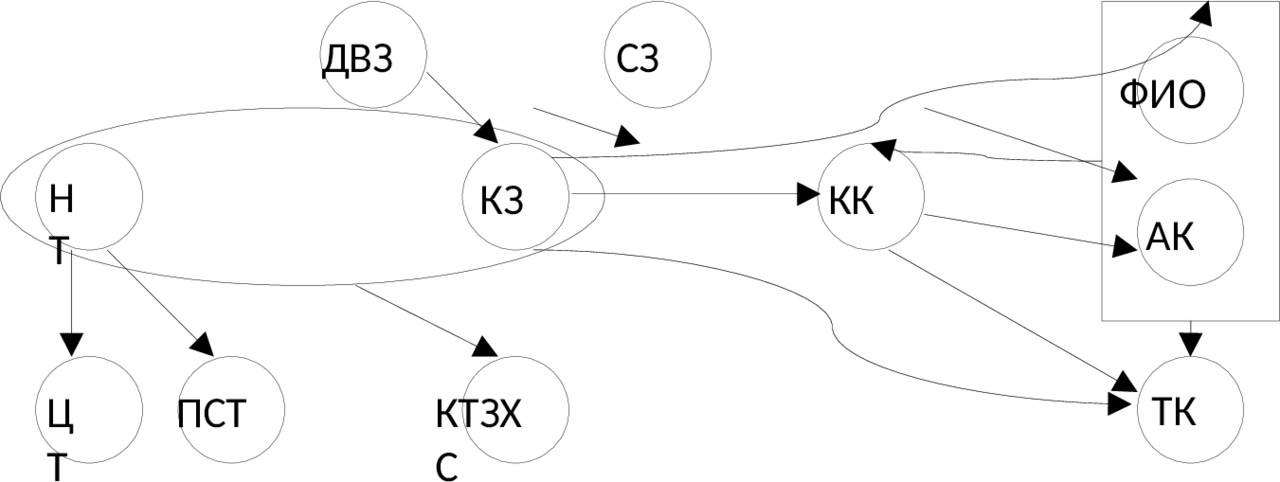
Уточнив вопрос о том какую информацию следует хранить в базе данных, определим все атрибуты, представляющие интерес для проектируемой базы данных. Это: для каждого товара его код, название, цена, процентная скидка; ФИО, адрес, телефон каждого клиента; для каждого заказа его код, сумма, дата выполнения и количество товара для каждого заказанного названия.
Применим для всех атрибутов краткие обозначения:
Название товара — НТ
Цена товара — ЦТ
Процентная скидка на товар — ПСТ
Код клиента — КК
ФИО клиента — ФИО
Адрес клиента — АК
Телефон клиента — ТК
Код заказа — КЗ
Сумма заказа — СЗ
Дата выполнения заказа — ДВЗ
Количество товара для каждого заказанного названия — КТЗ.
Универсальное отношение будет иметь вид: r (НТ, ЦТ, ПСТ, КК, ФИО, АК, ТК, КЗ, СЗ, ДВЗ, КТЗ).
Определив все функциональные зависимости, имеющиеся между атрибутами универсального отношения, построим диаграмму функциональных зависимостей (см. рис. 1.1).
Удалим из исходного набора функциональных зависимостей все избыточные:
— КЗ → КК и КК → ТК, т. е. КЗ → ТК также можно удалить по аксиоме транзитивности.
— КК → ФИО и КК → АК по аксиоме аддитивности заменим на КК → ФИО, АК.
— ФИО, АК → КК и КК → ТК, т. е. ФИО, АК → ТК является избыточной зависимостью по аксиоме транзитивности и ее можно удалить.
— КЗ → КК и КК → ФИО, АК, т. е. КЗ → ФИО, АК также можно удалить по аксиоме транзитивности.
— НТ → ЦТ, НТ → ПСТ, НТ → НС по аксиоме аддитивности заменим на НТ → ЦТ, ПСТ.
— КЗ → СЗ, КЗ → ДВЗ, КЗ → КК по аксиоме аддитивности заменим на КЗ → СЗ, ДВЗ, КК.
— КК → ФИО, АК и КК → ТК по аксиоме аддитивности заменим на КК → ФИО, АК, ТК.
Окончательно диаграмма функциональных зависимостей примет вид, показанный на рис. 1.2.
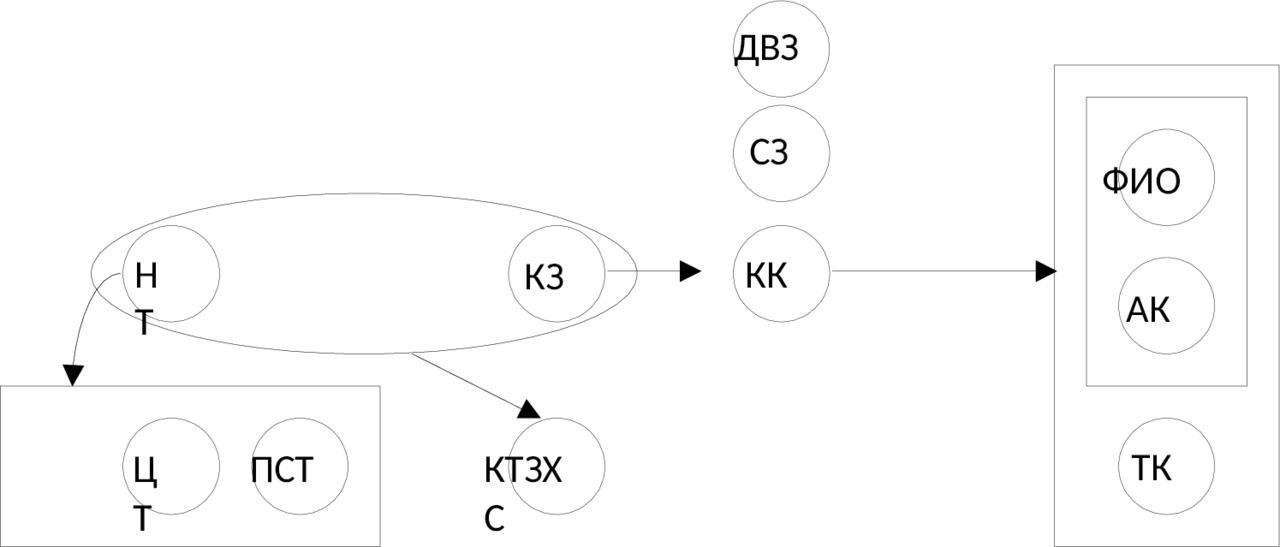
Выполним преобразование исходного отношения в набор НФБК — отношений:
1)
r1 (НТ, ЦТ, ПСТ, КК, ФИО, АК, ТК, КЗ, СЗ, ДВЗ, КТЗ).
Отношение r1 не находится в НФБК (есть зависимости от частей ключа (НТ → ЦТ, ПСТ); детерминанты НТ, КЗ, КК, (ФИО, АК) не являются возможными ключами) и поэтому разбивается далее.
2) Для проведения проекции по правилу цепочки выберем F-зависимость НТ → ЦТ, ПСТ. Получим следующие отношения:
r2 (НТ, ЦТ, ПСТ);
r3 (НТ, КК, ФИО, АК, ТК, КЗ, СЗ, ДВЗ, КТЗ).
Отношение r2 находится в НФБК (его детерминант (НТ) является возможным ключом) и не нуждается больше в декомпозиции. Отношение r3 не находится в НФБК (есть зависимости от частей ключа (КЗ → СЗ, ДВЗ, КК); детерминанты КЗ, КК, (ФИО, АК) не являются возможными ключами) и поэтому разбивается далее.
3) Для проведения второй проекции также по правилу цепочки выберем F-зависимость КК → ФИО, АК, ТК. Получим следующие отношения:
r4 (КК, ФИО, АК, ТК);
r5 (НТ, КК, КЗ, СЗ, ДВЗ, КТЗ).
Отношение r4 находится в НФБК (его детерминанты (КК, (ФИО, АК)) являются возможными ключами) и не нуждается больше в декомпозиции. Отношение r5 не находится в НФБК (есть зависимости от частей ключа (КЗ → СЗ, ДВЗ, КК); детерминант КЗ не является возможным ключом) и поэтому разбивается далее.
4) Для проведения третьей проекции по правилу цепочки выберем F-зависимость КЗ → СЗ, ДВЗ, КК.
r6 (КЗ, СЗ, ДВЗ, КК).
Отношение r6 находится в НФБК (его детерминант (КЗ) является возможным ключом) и не нуждается больше в декомпозиции.
r7 (НТ, КЗ, КТЗ).
Отношение r7 находится в НФБК (его детерминант (НТ, КЗ) является возможным ключом) и не нуждается больше в декомпозиции.
Преобразование исходного отношения в набор НФБК — отношений завершено.
Таким образом, получили следующий набор отношений:
r2 (НТ, ЦТ, ПСТ);
r4 (КК, ФИО, АК, ТК);
r6 (КЗ, СЗ, ДВЗ, КК);
r7 (НТ, КЗ, КТЗ).
Выполним проверку полученного набора отношений:
1) Проверим отношения на наличие дублирующихся функциональных зависимостей. Для этого составим списки F-зависимостей для каждого отношения.
F-зависимости в отношении r2:
НТ → ЦТ, ПСТ.
F-зависимости в отношении r4:
КК → ФИО, АК, ТК;
ФИО, АК → КК;
ФИО, АК → ТК.
F-зависимости в отношении r6:
КЗ → СЗ, ДВЗ, КК.
F-зависимости в отношении r7:
НТ, КЗ → КТЗ.
Таким образом, в полученном наборе отношений нет F-зависимости, которая появлялась бы более чем в одном отношении. Полученный набор F-зависимостей не совпадает с набором минимального покрытия и может быть получен из него с помощью аксиомы аддитивности (в отношении r4 объединим F-зависимости ФИО, АК → КК и ФИО, АК → ТК).
2) Осуществим проверку набора отношений на наличие избыточных. В полученном наборе отношений нет отношения, все атрибуты которого находились бы в одном другом отношении набора или могли быть найдены в отношении, получаемом с помощью операции соединения любых других отношений проектного набора.
3) Рассмотрим отношения с практической точки зрения. Все полученные отношения разумны с практической точки зрения: в отношении r2 регистрируются данные о товарах, в отношении r4 хранятся данные о клиентах, отношение r6 отвечает за учет полученных товаров, в отношение r7 записывается информация о количестве каждого товара в заказе.
Проектирование базы данных методом «сущность-связь»
При проектировании базы данных методом «сущность — связь» необходимо выполнить следующие действия:
— Уточнить, какая именно информация о предметной области будет храниться в проектируемой базе данных. Выделить в предметной области объекты и их свойства. Зафиксировать связи между объектами и их свойствами и связи между объектами разных классов. Построить ER — модель.
— Осуществить переход от инфологической модели предметной области к даталогической модели базы данных.
— Выявить, в какой нормальной форме находятся полученные отношения (отобразить функциональные зависимости между атрибутами каждого отношения).
Выделяют три этапа проектирования БД:
— инфологическое моделирование
— даталогическое моделирование
— физическая реализация
1) На первом этапе создается инфологическая модель предметной области.
Предметная область — это часть реального мира, представляющего интерес для данного проектирования.
Инфологической моделью предметной области называют описание предметной области, выполненное с использованием специальных языковых средств, и независящее от используемых в дальнейшем программных и технических средств.
2) На основе инфологической модели строится даталогическая модель.
Даталогическая модель является моделью логического уровня и представляет собой отображение логических связей между элементами данных безотносительно к их содержанию и среде хранения. Описание логической структуры БД на языке СУБД называется схемой.
3) Третий этап проектирования состоит в привязке ДЛМ к среде хранения с помощью модели данных физического уровня (физической модели). Описание физической структуры БД называется схемой хранения.
Компоненты ИЛМ:
— описание объектов и связей между ними (ER — модель);
— описание информационных потребностей пользователей;
— алгоритмические связи показателей;
— лингвистические отношения;
— ограничения целостности.
В предметной области в результате ее анализа выделяют классы объектов. Классом объектов называют совокупность объектов, обладающих одинаковым набором свойств. Каждый объект в информационной системе представляется своим идентификатором, а каждый класс объектов представляется именем класса. Каждый объект обладает определенным набором свойств.
Связь между объектом и характеризующим его свойством изображается в виде линии. Связь может быть единичной или множественной.
Если объект обладает только одним значением какого-то свойства, то такое свойство называют единичными. Если для свойства возможно существование одновременно нескольких значений у одного объекта, то такие свойства называют множественными.
Свойства, значения которых не могут изменяться с течением времени (например, Дата рождения), называются статическими и обозначаются буквой S. Свойства, значения которых могут изменяться со временем (например, Фамилия, Адрес, Телефон), называются динамическими и обозначаются буквой D.
Свойство, которое может отсутствовать у некоторых объектов одного класса (например, свойство Ученая степень, не все объекты класса Сотрудники могут обладать указанным свойством), называют условными и изображают пунктирной линией.
Существует понятие составного свойства (примеры таких свойств: Адрес, состоящий из «улицы», «дома», «квартиры»; Дата рождения, состоящая из «числа», «месяца», «года»). Для его обозначения используют квадрат.
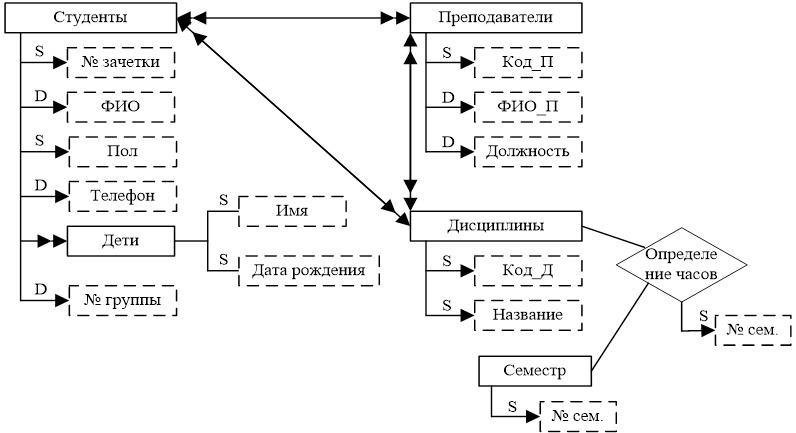
В инфологической модели фиксируются не только связи между объектом и его свойствами, но и связи между объектами разных классов.
Различают связи типа:
— один к одному (1:1);
— один ко многим (1:М);
— многие к одному (М:1);
— многие ко многим (М:М).
Объект называют простым, если он рассматривается как неделимый. Сложный объект представляет собой объединение других объектов, простых или сложных, также отображаемых в информационной системе. Понятия простой и сложный являются относительными. Сложные объекты подразделяют на составные, обобщенные и агрегированные.
Составной объект соответствует отображению связи «целое — часть». Примеры таких объектов: класс — ученики, группа — студенты и т. п. (связь между составным и составляющими его объектами отображается отношением 1:М)
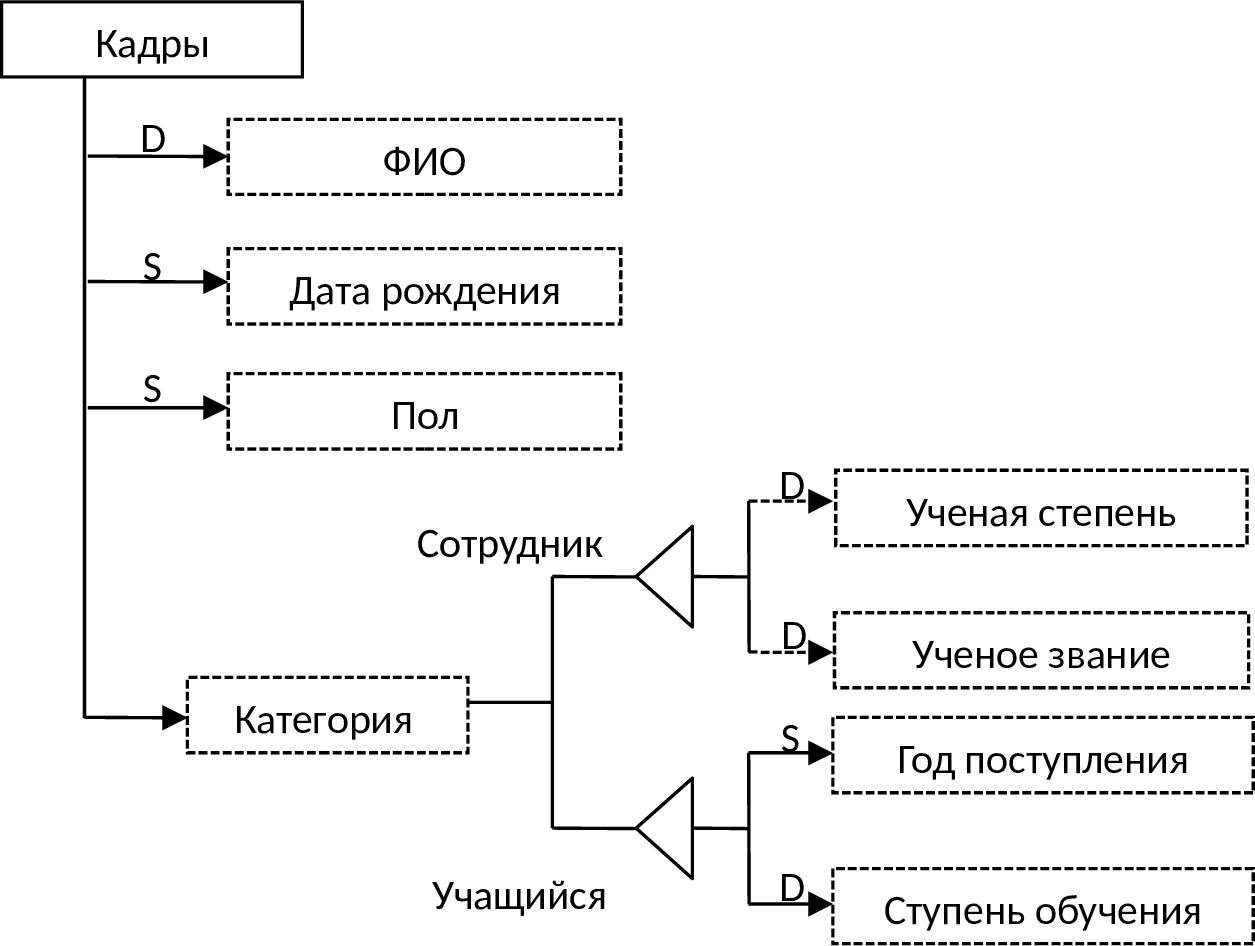
Обобщенный объект отражает наличие связи «род — вид» между объектами предметной области. Например, объекты Студент, Школьник, Аспирант образуют обобщенный объект Учащиеся. Объекты, составляющие обобщенный объект, называются его категориями. Как «родовой» объект, так и «видовые» объекты могут обладать определенным набором свойств. Причем «видовые» объекты обладают всеми теми свойствами, которыми обладает «родовой» объект, плюс свойствами, присущими только объектам этого вида.
Определение родо-видовых связей означает классификацию объектов предметной области по тем или иным признакам. Подклассы могут выделяться в ИЛМ в явном виде (см. рис. 3.5).
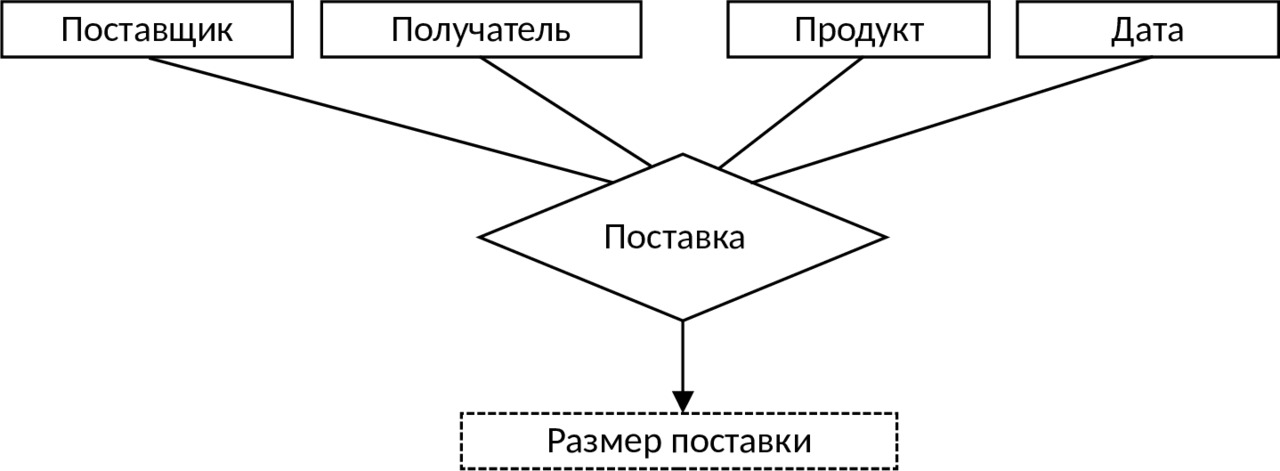
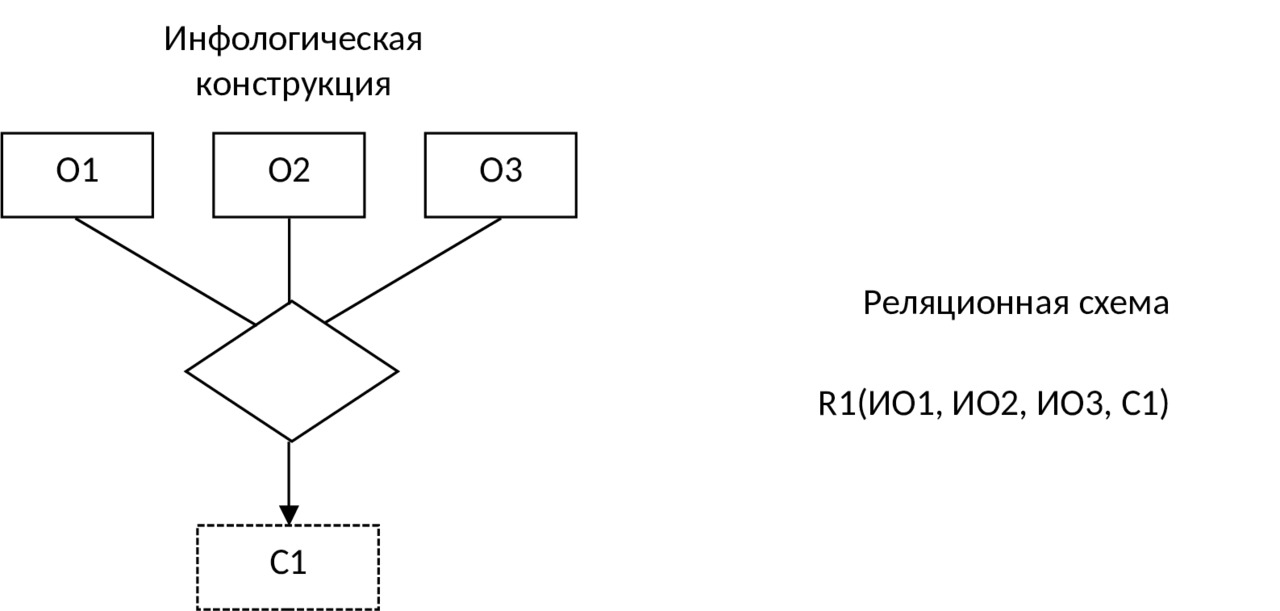
Агрегированный объект соответствует обычно какому-либо процессу, в который оказываются «вовлеченными» другие объекты. Например, агрегированный объект Поставка (см. рис. 3.6) объединяет в себе объекты Поставщик, Получатель, Продукт и Дата. Для отображения агрегированного объекта в схеме использован ромб. Агрегированный объект может, так же как и простой объект, иметь характеризующие его свойства.
Правила, по которым строится даталогическая модель:
1) Для каждого простого объекта и его единичных свойств строится таблица, атрибутами которой являются идентификатор объекта и реквизиты, соответствующие каждому из единичных свойств:

2) Если у объекта имеются множественные свойства, то каждому из них ставится в соответствие отдельная таблица:
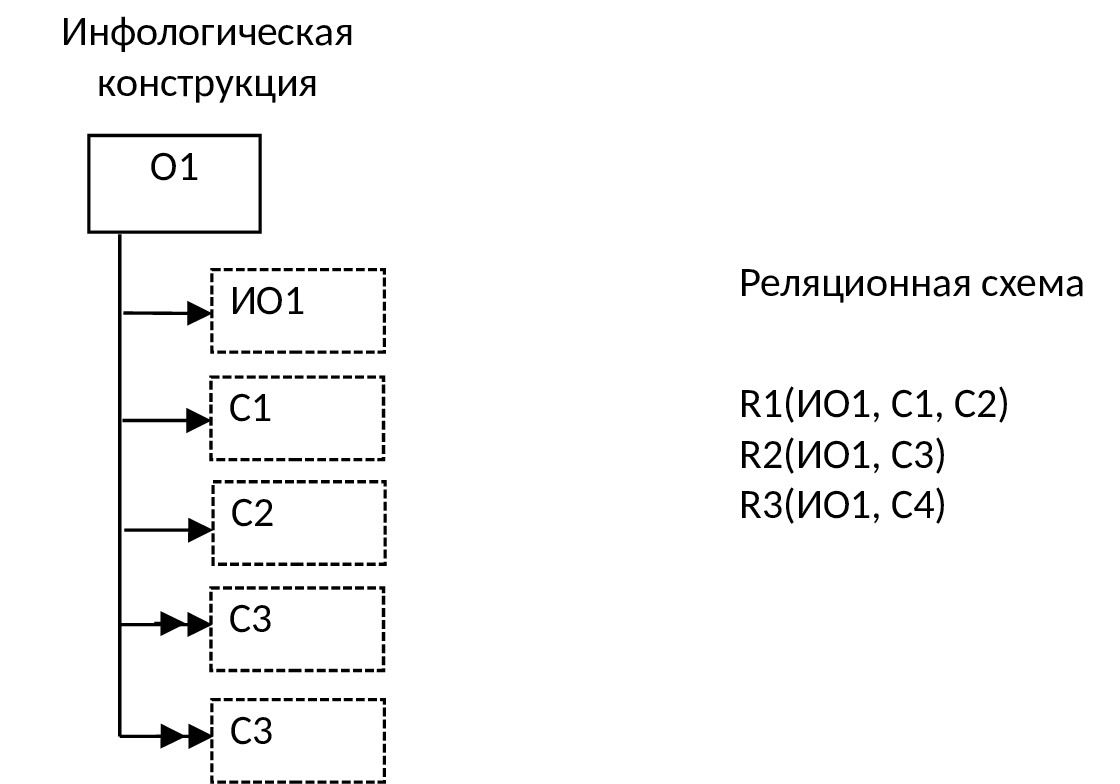
3) Если между объектом и его свойством имеется условная связь, то при отображении в реляционную модель возможны следующие варианты:
— если многие из объектов обладают рассматриваемым свойством, то его можно хранить в БД так же, как и обычное свойство;
— если только незначительное число объектов обладает указанным свойством, то при использовании предыдущего решения для многих записей в таблице значение соответствующего поля будет пустым. Для устранения этого недостатка выделяют отдельную таблицу, которая будет включать в себя идентификатор объекта и атрибут, соответствующий рассматриваемому свойству.
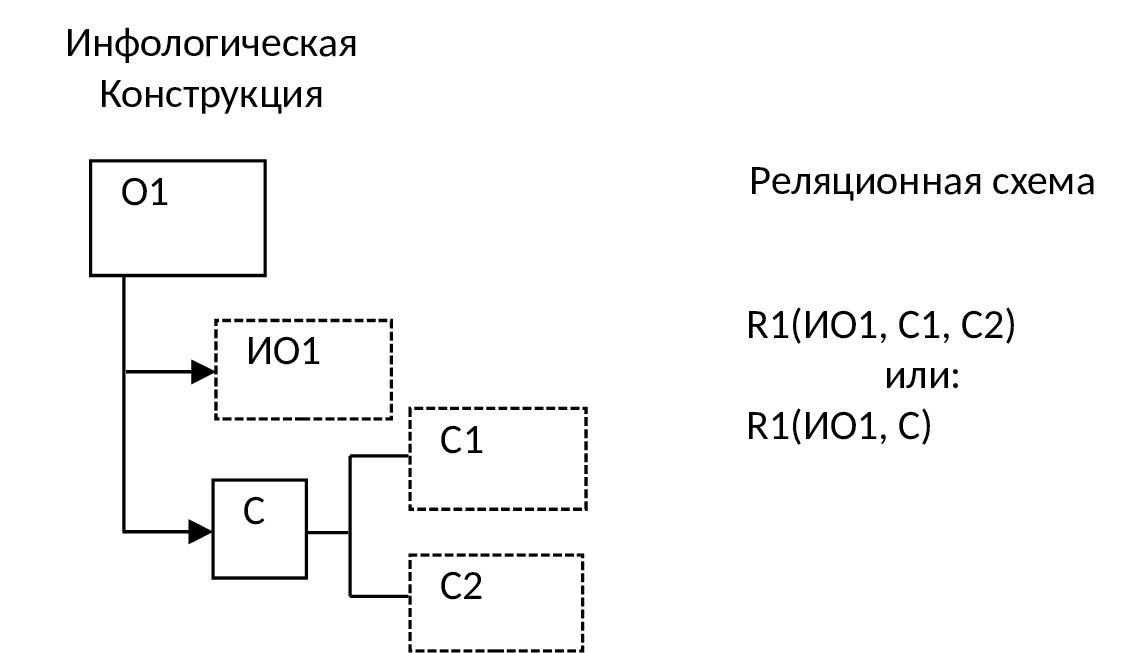
4) Если у объекта имеется составное свойство:
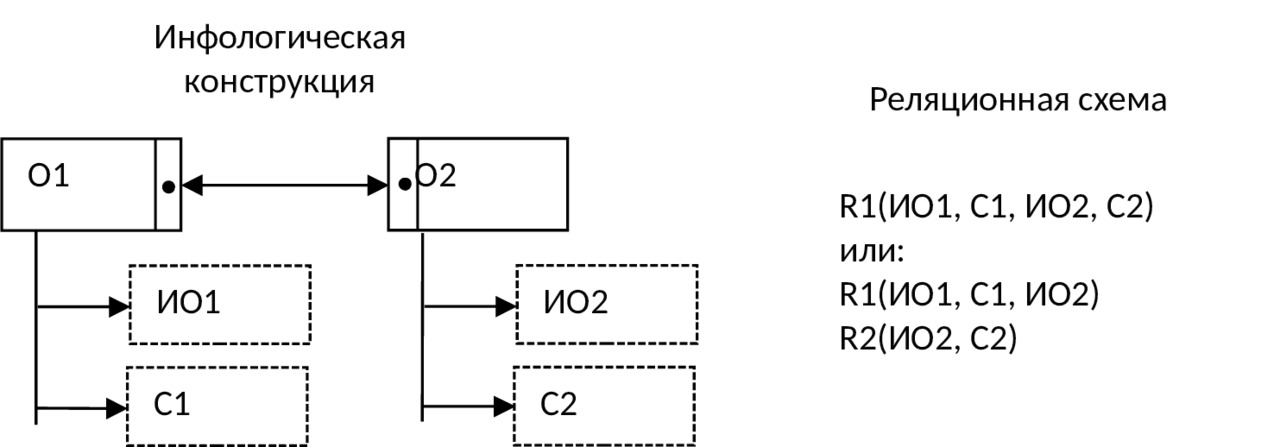
5) Если связь между объектами 1:1 и классы принадлежности обоих объектов являются обязательными, то для отображения данных объектов и связи между ними:
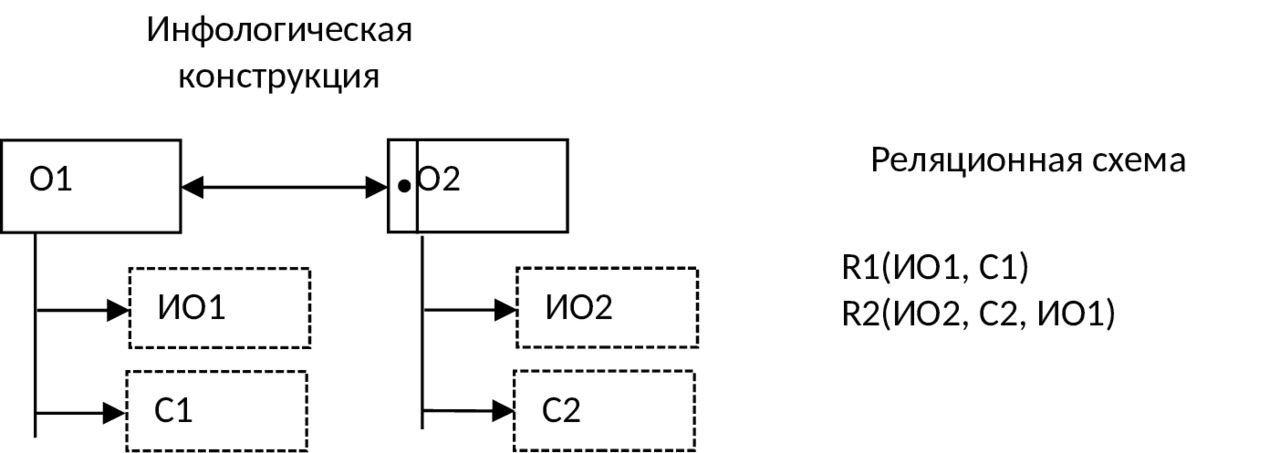
6) Если связь между объектами 1:1 и класс принадлежности одного объекта является обязательным, а другого — необязательным, то для каждого из этих объектов используют отдельные таблицы, а идентификатор объекта, для которого класс принадлежности является необязательным, добавляется в таблицу, соответствующую тому объекту, для которого класс принадлежности обязательный:
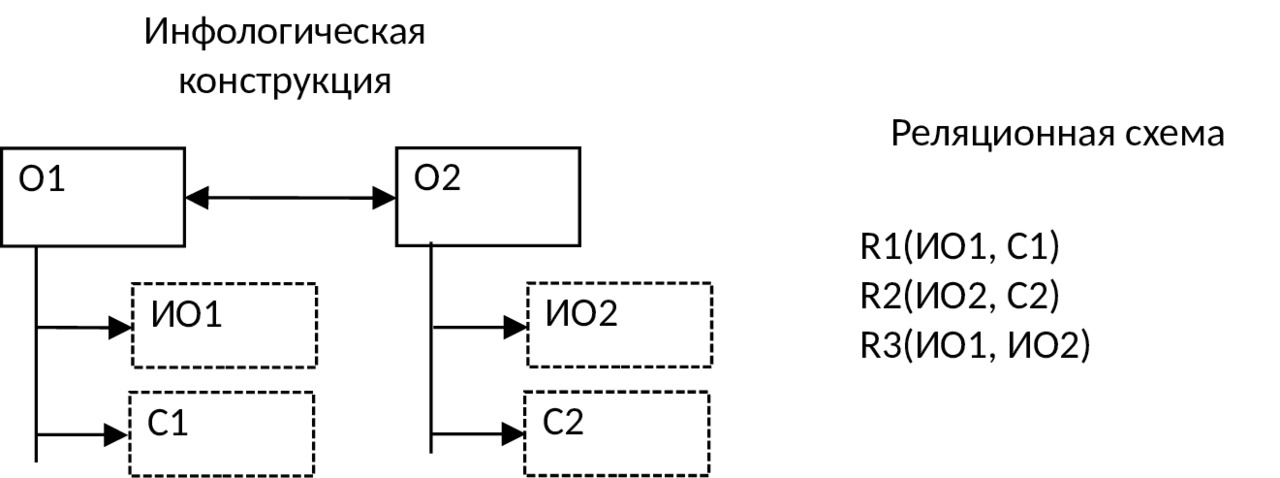
7) Если связь между объектами 1:1 и класс принадлежности каждого объекта является необязательным, то следует использовать три таблицы: по одной для каждого объекта и одно для отображения связи между ними:
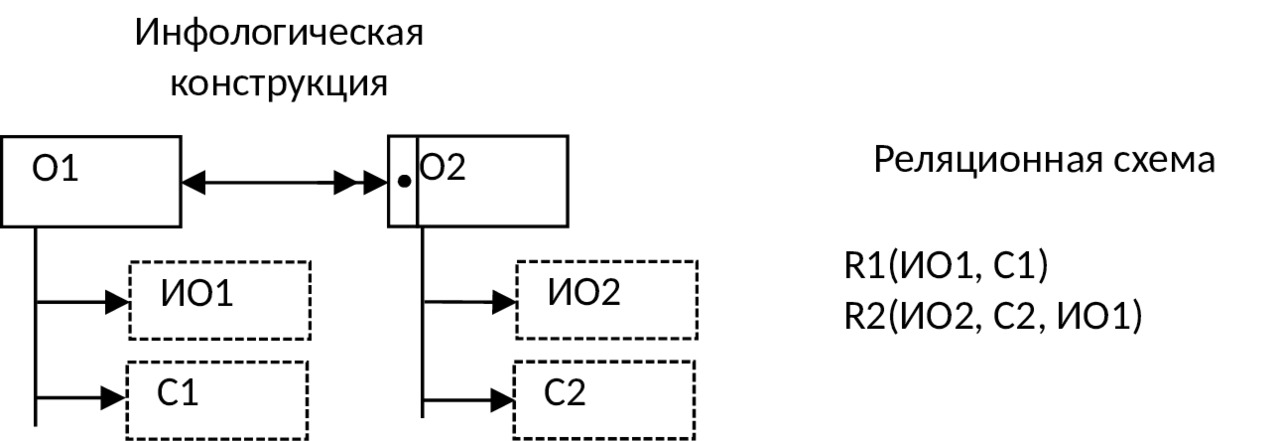
8) Если между объектами предметной области имеется связь 1:М и класс принадлежности n — связного объекта является обязательным, то используют две таблицы: по одной для каждого объекта, и в таблицу, соответствующую n — связному объекту, добавляется идентификатор 1 — связного объекта:
9) Если между объектами предметной области имеется связь 1:М и класс принадлежности n — связного объекта является необязательным, то создают три таблицы: по одной для каждого объекта и одну для отображения связи между ними:
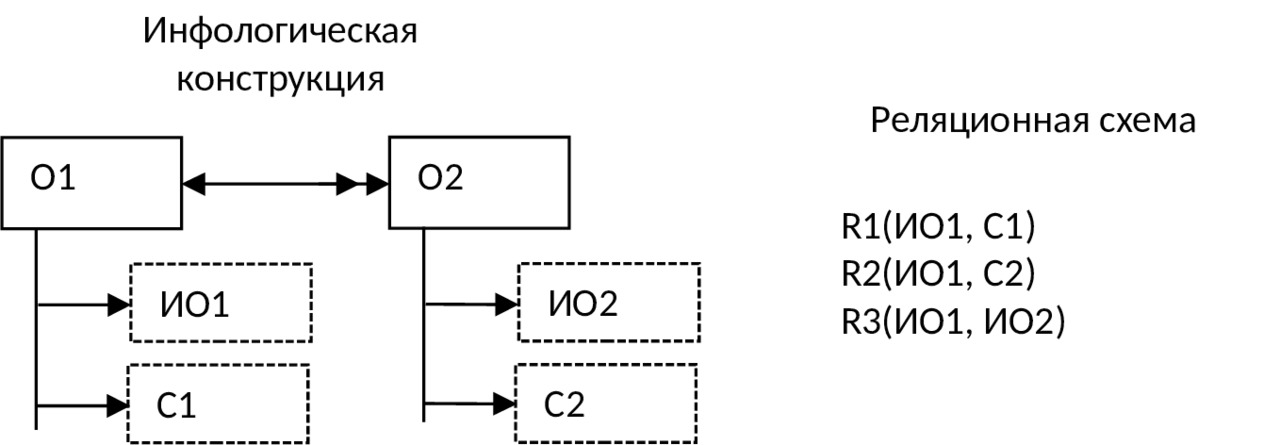
10) Если между объектами предметной области имеется связь М:М, то для хранения такой информации потребуется три таблицы: по одной для каждого объекта и одна для отображения связи между ними (классы принадлежности могут быть: оба — обязательными, оба — необязательными, один — обязательный, другой — необязательный):
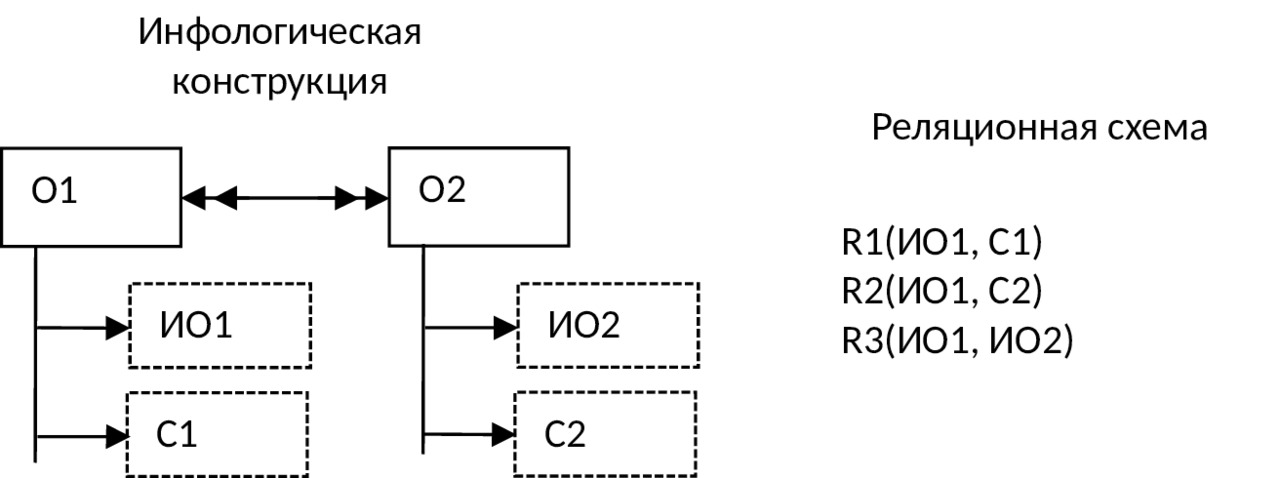
11) Агрегированному объекту, имеющему место в предметной области, в ДЛМ ставится в соответствие одна таблица, атрибутами которой являются идентификаторы всех объектов, «задействованных» в данном агрегированном объекте, а также реквизиты, соответствующие свойствам этого объекта:
Модели представления данных
Иерархическая модель
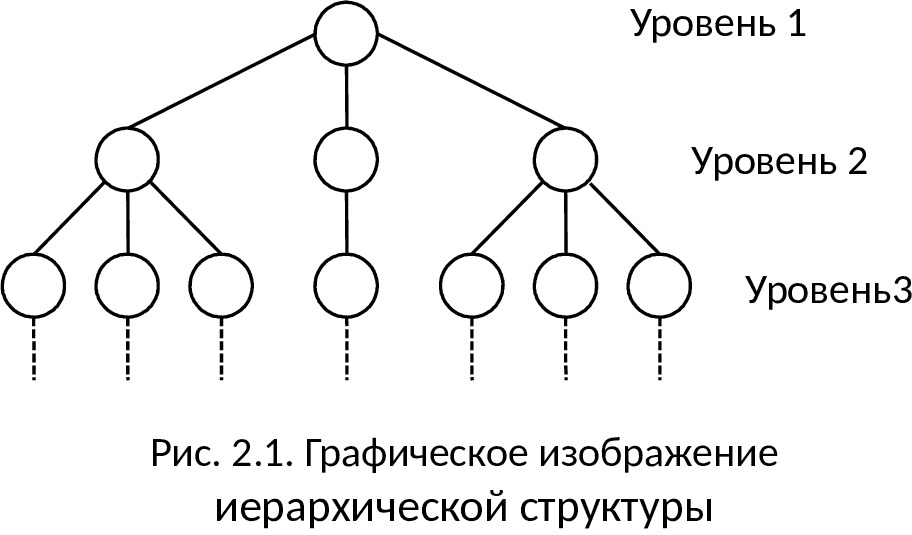
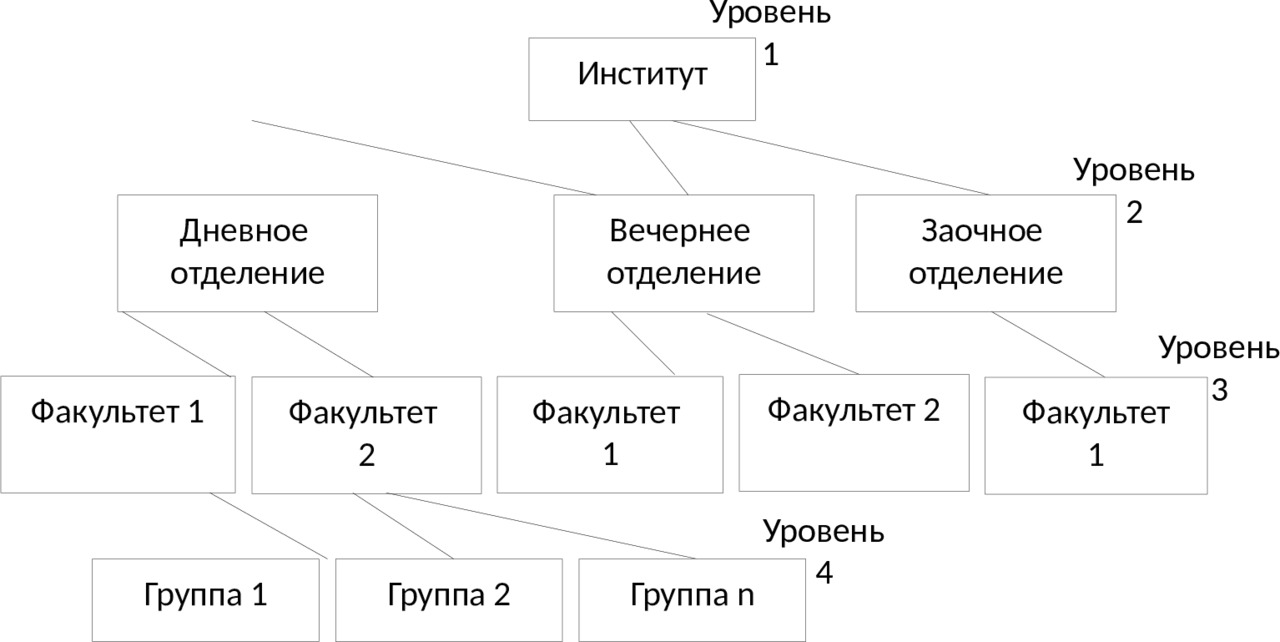
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Графическим способом представления иерархической структуры является дерево (см. рис. 2.1).
Дерево представляет собой иерархию элементов, называемых узлами. Под элементами понимается совокупность атрибутов, описывающих объекты. В модели имеется корневой узел (корень дерева), который находится на самом верхнем уровне и не имеет узлов, стоящих выше него. У одного дерева может быть только один корень. Остальные узлы, называемые порожденными, связаны между собой следующим образом: каждый узел имеет только один исходный, находящийся на более высоком уровне, и любое число (один, два или более, либо ни одного) подчиненных узлов на следующем уровне.
Примером простого иерархического представления может служить административная структура высшего учебного заведения: институт — отделение — факультет — студенческая группа (см. рис. 2.2).
К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения операций над данными.
Недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями.
На иерархической модели данных основано сравнительно ограниченное количество СУБД, в числе которых можно назвать зарубежные системы IMS, PC/Focus, Team-Up и Data Edge, а также отечественные системы Ока, ИНЭС и МИРИС.
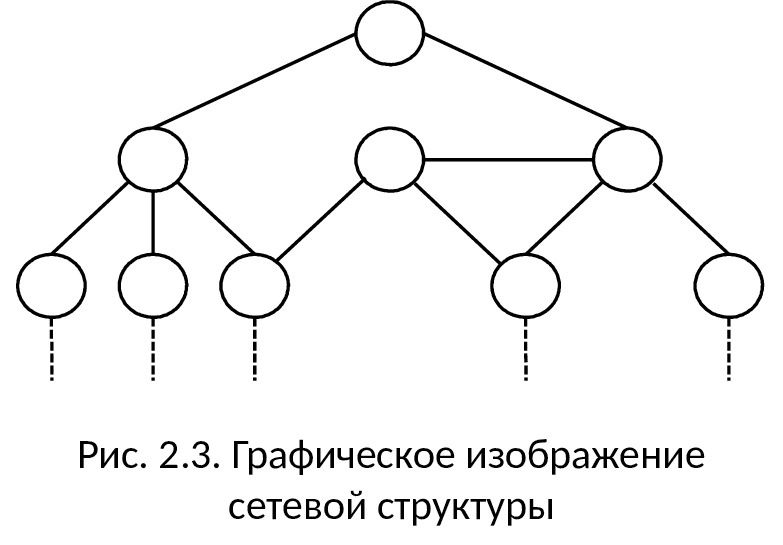
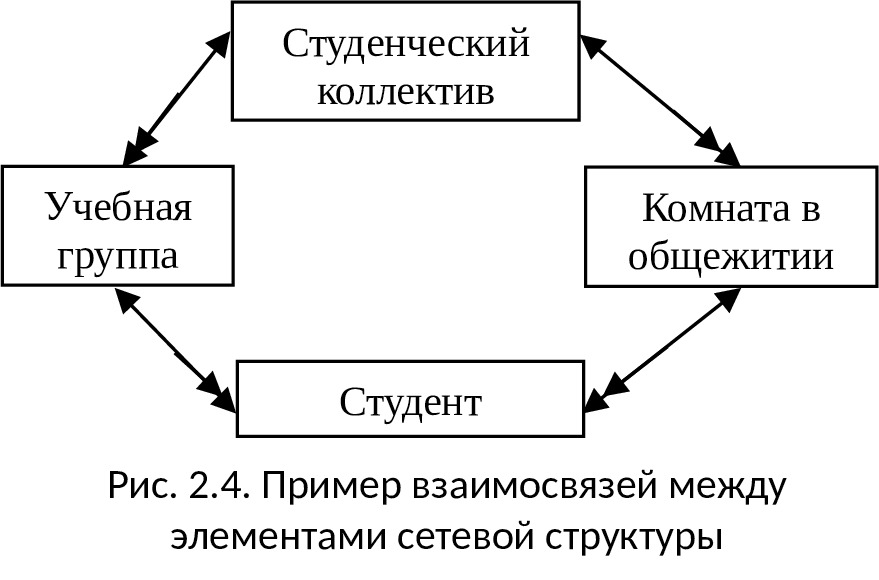
Сетевая модель данных
Отличие сетевой структуры от иерархической заключается в том, что каждый элемент в сетевой структуре может быть связан с любым другим элементом (см. рис. 2.3). Пример простой сетевой структуры показан на рис. 2.4.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности.
Недостатком сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе.
Наиболее известными сетевыми СУБД являются IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
Реляционная модель данных
Реляционная модель данных была предложена Е. Ф. Коддом.
Реляционная база данных представляет собой хранилище данных, организованных в виде двумерных таблиц (см. рис. 2.5). Любая таблица реляционной базы данных состоит из строк (называемых также записями) и столбцов (называемых также полями).
Строки таблицы содержат сведения о представленных в ней фактах (или документах, или людях, одним словом, — об однотипных объектах). На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных.
Данные в таблицах удовлетворяют следующим принципам:
1. Каждое значение, содержащееся на пересечении строки и столбца, должно быть атомарным.
2. Значения данных в одном и том же столбце должны принадлежать к одному и тому же типу, доступному для использования в данной СУБД.
3. Каждая запись в таблице уникальна, то есть в таблице не существует двух записей с полностью совпадающим набором значений ее полей.
4. Каждое поле имеет уникальное имя.
5. Последовательность полей в таблице несущественна.
6. Последовательность записей в таблице несущественна.
Поле или комбинацию полей, значения которых однозначно идентифицируют каждую запись таблицы, называют возможным ключом (или просто ключом).
Если таблица имеет более одного возможного ключа, тогда один ключ выделяют в качестве первичного. Первичный ключ любой таблицы обязан содержать уникальные непустые значения для каждой строки.
Поле, указывающее на запись в другой таблице, связанную с данной записью, называется внешним ключом.
Подобное взаимоотношение между таблицами называется связью. Связь между двумя таблицами устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой.
Группа связанных таблиц называется схемой базы данных. Информация о таблицах, их полях, первичных и внешних ключах, а также иных объектах базы данных, называется метаданными.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной ее широкого использования.
К основным недостаткам реляционной модели относятся отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются: DB2, Paradox, FoxPro, Access, Clarion, Ingres, Oracle.
К отечественным СУБД реляционного типа относятся системы ПАЛЬМА и HyTech.
Постреляционная модель
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Постреляционная модель представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных. Модель допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
На рис. 2.6 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Из рисунка видно, что по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не потребуется выполнять операцию соединения данных из двух таблиц.
а) Накладные Накладные-товары
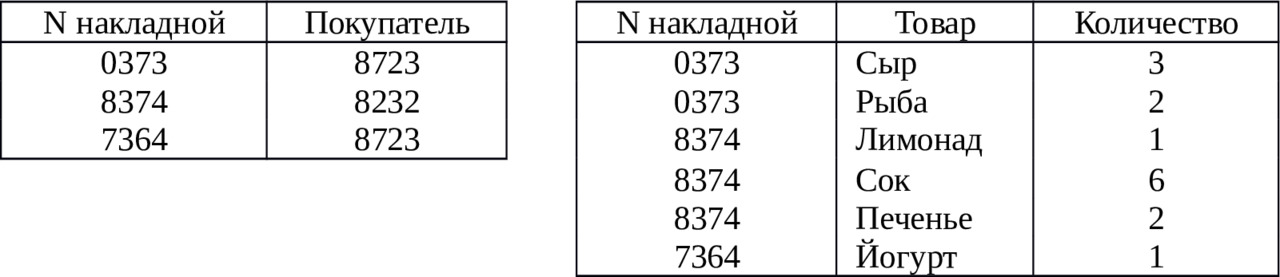
б) Накладные
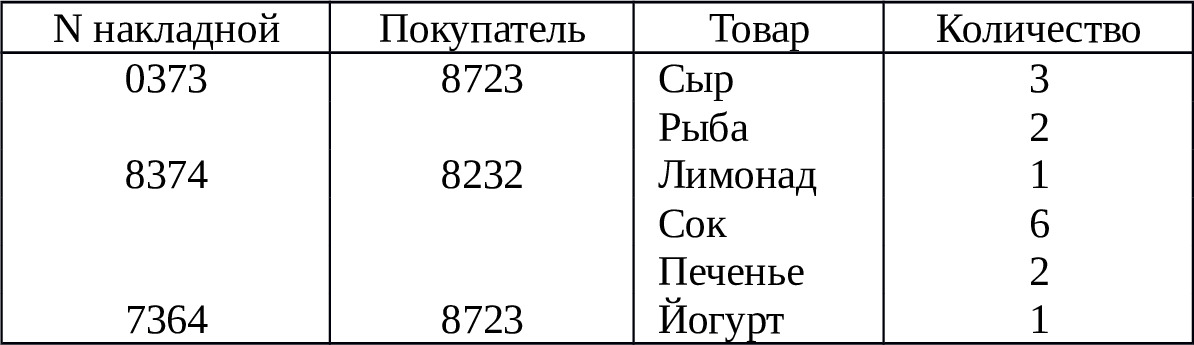
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД соответствующих механизмов.
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
Рассмотренная постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
Многомерная модель
Многомерный подход к представлению данных появился практически одновременно с реляционным, но интерес к многомерным СУБД стал приобретать массовый характер с середины 90-х годов. Толчком послужила в 1993 году статья Э. Кодда. В ней были сформулированы 12 основных требований к системам класса OLAP (OnLine Analytical Processing — оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных.
В развитии концепций информационных систем можно выделить следующие два направления:
— системы оперативной (транзакционной) обработки;
— системы аналитической обработки (системы поддержки принятия решений).
Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД.
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость.
Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь, управляющий, руководитель.
Историчность данных предполагает обеспечение высокого уровня статичности собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Для иллюстрации на рис. 2.7 приведены реляционное (а) и многомерное (б) представления одних и тех же данных об объемах продаж автомобилей.
Основные понятия многомерных моделей данных: измерение и ячейка.
Измерение — это множество однотипных данных, образующих одну из граней гиперкуба. В многомерной модели измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба.
Ячейка — это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам).

В примере на рис. 2.7 б каждое значение ячейки Объем продаж однозначно определяется комбинацией временного измерения.
В существующих многомерных СУБД используются две основных схемы организации данных: гиперкубическая и поликубическая.
В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером системы, поддерживающей поликубический вариант БД, является сервер Oracle Express Server.
В случае гиперкубической схемы предполагается, что все ячейки определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов в БД, все они имеют одинаковую размерность и совпадающие измерения.
Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем.
Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примерами систем, поддерживающими многомерные модели данных, является Essbase, Media Multi-matrix, Oracle Express Server, Cache. Существуют программные продукты, например Media/MR, позволяющие одновременно работать с многомерными и с реляционными БД.
Объектно-ориентированная модель
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Стандартизированная объектно-ориентированная модель описана в рекомендациях стандарта ODMG-93 (Object Database Management Group — группа управления объектно-ориентированными базами данных).
Рассмотрим упрощенную модель объектно-ориентированной БД. Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом или типом, конструируемым пользователем (определяется как class). Значение свойства типа class есть объект, являющийся экземпляром соответствующего класса. Каждый объект-экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект-экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связную иерархию объектов. Пример логической структуры объектно-ориентированной БД библиотечного дела приведен на рис. 2.9. Здесь объект типа Библиотека является родительским для объектов-экземпляров классов Абонент, Каталог и Выдача. Различные объекты типа Книга могут иметь одного или разных родителей. Объекты типа Книга, имеющие одного и того же родителя, должны различаться, по крайней мере, инвентарным номером (уникален для каждого экземпляра книги), но имеют одинаковые значения свойств isbn, удк, название и автор.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное различие между ними состоит в методах манипулирования данными.
Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма.
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа Каталог добавить свойство, задающее телефон автора книги и имеющее название телефон, то мы получим одноименные свойства у объектов Абонент и Каталог. Смысл такого свойства будет определяться тем объектом, в который оно инкапсулировано.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа Книга, являющимся потомками объекта типа Каталог, можно приписать свойства объекта-родителя: isbn, удк, название и автор. Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство типа abs. Так, определение абстрактных свойств билет и номер в объекте Библиотека приводит к наследованию этих свойств всеми дочерними объектами Абонент, Книга и Выдача. Не случайно, поэтому значения свойства билет классов Абонент и Выдача, показанных на рис. 2.9, являются одинаковыми — 00015.
Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к рассматриваемому примеру полиморфизм означает, что объекты класса Книга, имеющие разных родителей из класса Каталог, могут иметь разный набор свойств. Следовательно, программы работы с объектами класса Книга могут содержать полиморфный код.
Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД.
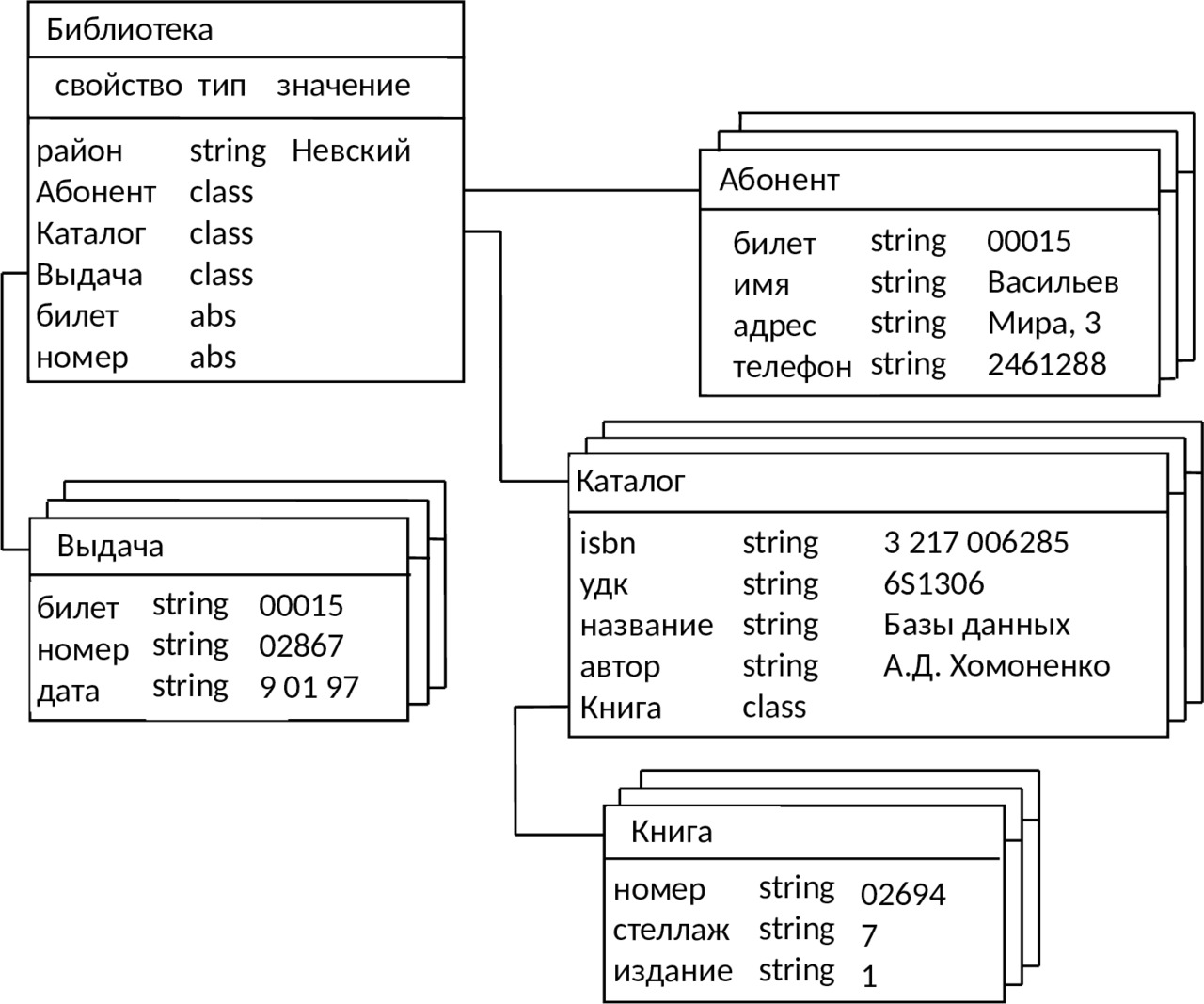
Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
К объектно-ориентированным СУБД относятся POET, Jasmine, Versant, O2, ODB-Jupiter, Iris, Orion, Postgres.
Лекция 4
БЕЗОПАСНОСТЬ БАЗ ДАННЫХ
В контексте обсуждения баз данных часто совместно используются термины безопасность и целостность, хотя на самом деле, это совершенно разные понятия. Термин безопасность относится к защите данных от несанкционированного доступа, изменения или разрушения данных, целостность — к точности или истинности данных. По-другому их можно описать следующим образом:
— Под безопасностью подразумевается, что пользователям разрешается выполнять некоторые действия.
— Под целостностью подразумевается, что эти действия выполняются корректно.
В современных СУБД поддерживается один из двух широко распространенных подходов к вопросу обеспечения безопасности данных, а именно избирательный подход или обязательный подход, либо оба подхода. В обоих подходах единицей данных или объектом данных, для которых должна быть создана система безопасности, может быть как вся база данных целиком или какой-либо набор отношений, так и некоторое значение данных для заданного атрибута внутри некоторого кортежа в определенном отношении. Эти подходы отличаются следующими свойствами:
— В случае избирательного управления некий пользователь обладает различными правами (привилегиями или полномочиями) при работе с объектами. Более того, разные пользователи обычно обладают и разными правами доступа к одному и тому же объекту. Поэтому избирательные схемы характеризуются значительной гибкостью.
— В случае обязательного управления, наоборот, каждому объекту данных присваивается некоторый классификационный уровень, а каждый пользователь обладает некоторым уровнем допуска. Таким образом, при таком подходе доступом к определенному объекту данных обладают только пользователи с соответствующим уровнем допуска. Поэтому обязательные схемы достаточно жестки и статичны.
Обязательное управление доступом
Требования к обязательному управлению доступом изложены в двух важных публикациях министерства обороны США (Стандарт Правительства США «Trusted Computer System Evaluation Criteria, DOD standard 5200.28 — STD, December, 1985», описывающий защищенные архитектуры информационных систем и определяющий уровни защиты от A1 (наивысшего) до D (минимального)), которые неформально называются «оранжевой книгой» и «розовой книгой». В «оранжевой книге» перечислен набор требований к безопасности для некой «надежной вычислительной базы», а в «розовой книге» дается интерпретация этих требований для систем управления базами данных.
В этих документах определяется четыре класса безопасности — D, C, B и A. Говорят, что класс D обеспечивает минимальную защиту (данный класс предназначен для систем, признанных неудовлетворительными), класс С — избирательную защиту, класс В — обязательную, а класс А — проверенную защиту.
Избирательная защита. Класс С делится на два подкласса — С1 и С2 (где подкласс С1 менее безопасен, чем подкласс С2), которые поддерживают избирательное управление доступом в том смысле, что управление доступом осуществляется по усмотрению владельца данных.
Согласно требованиям класса С1 необходимо разделение данных и пользователя, т.е. наряду с поддержкой концепции взаимного доступа к данным здесь возможно также организовать раздельное использование данных пользователями.
Согласно требованиям класса С2 необходимо дополнительно организовать учет на основе процедур входа в систему, аудита и изоляции ресурсов.
Обязательная защита. Класс В содержит требования к методам обязательного управления доступом и делится на три подкласса — В1, В2 и В3 (где В1 является наименее, а В3 — наиболее безопасным подклассом).
Согласно требованиям класса В1 необходимо обеспечить «отмеченную защиту» (это значит, что каждый объект данных должен содержать отметку о его уровне классификации, например: секретно, для служебного пользования и т.д.), а также неформальное сообщение о действующей стратегии безопасности.
Согласно требованиям класса В2 необходимо дополнительно обеспечить формальное утверждение о действующей стратегии безопасности, а также обнаружить и исключить плохо защищенные каналы передачи информации.
Согласно требованиям класса В3 необходимо дополнительно обеспечить поддержку аудита и восстановления данных, а также назначение администратора режима безопасности.
Проверенная защита. Класс А является наиболее безопасным и согласно его требованиям необходимо математическое доказательство того, что данный метод обеспечения безопасности совместим и адекватен заданной стратегии безопасности.
Коммерческие СУБД обычно обеспечивают избирательное управление на уровне класса С2. СУБД, в которых поддерживаются методы обязательной защиты, называют системами с многоуровневой защитой.
Согласно статистике, защите периметра сети уделяется втрое больше внимания, чем защите от внутренних возможных нарушений.
Кроме того, если вернуться к случаям взлома БД и провести простой расчет, то он покажет несостоятельность попыток свалить всю вину за происшедшее на хакеров. Разделив объем украденных данных на типовую скорость канала доступа в Интернет, мы получим, что даже при максимальной загруженности канала на передачу данных должно было бы уйти до нескольких месяцев. Логично предположить, что такой канал утечки данных был бы обнаружен даже самой невнимательной службой безопасности.
И если перед нами стоит задача обеспечить безопасность корпоративной СУБД, давайте озадачимся простым вопросом: кто в компании вообще пользуется базой данных и имеет к ней доступ?
Существует три большие группы пользователей СУБД, которых условно можно назвать операторами; аналитиками; администраторами.
Под операторами в предложенной классификации мы понимаем в основном тех, кто либо заполняет базу данных (вводят туда вручную информацию о клиентах, товарах и т. п.), либо выполняют задачи, связанные с обработкой информации: кладовщики, отмечающие перемещение товара, продавцы, выписывающие счета и т. п.
Под аналитиками мы понимаем тех, ради кого, собственно, создается эта база данных: логистики, маркетологи, финансовые аналитики и прочие. Эти люди по роду своей работы получают обширнейшие отчеты по собранной информации.
Термин «администратор» говорит сам за себя. Эта категория людей может только в общих чертах представлять, что хранится и обрабатывается в хранилище данных. Но они решают ряд важнейших задач, связанных с жизнеобеспечением системы, ее отказоустойчивости.
Но различные роли по отношению к обрабатываемой информации — не единственный критерий. Указанные группы различаются еще и по способу взаимодействия с СУБД.
Операторы чаще всего работают с информацией через различные приложения. Безопасность и разграничение доступа к информации тут реализованы очень хорошо, проработаны и реализованы методы защиты. Производители СУБД, говоря о возможностях своих систем, акцентируют внимание именно на такие способы защиты. Доступ к терминалам/компьютерам, с которых ведется работа, разграничение полномочий внутри приложения, разграничение полномочий в самой СУБД — все это выполнено на высоком техническом уровне. Честно внедрив все эти механизмы защиты, специалисты по безопасности чувствуют успокоение и удовлетворение.
Но беда в том, что основные проблемы с безопасностью приходятся на две оставшиеся категории пользователей.
Проблема с аналитиками заключается в том, что они работают с СУБД на уровне ядра. Они должны иметь возможность задавать и получать всевозможные выборки информации из всех хранящихся там таблиц. Включая и запросы общего типа «select * *».
С администраторами дело обстоит не намного лучше. Начиная с того, что в крупных информационных системах их число сопоставимо с числом аналитиков. И хотя абсолютно полными правами на СУБД наделены лишь два-три человека, администраторы, решающие узкие проблемы (например, резервное копирование данных), все равно имеют доступ ко всей информации, хранящейся в СУБД.
Между аналитиками и администраторами на первый взгляд нет никакой разницы: и те и другие имеют доступ ко всей обрабатываемой информации. Но все же отличие между этими группами есть, и состоит оно в том, что аналитики работают с данными, используя некие стандартные механизмы и интерфейсы СУБД, а администраторы могут получить непосредственный доступ к информации, например на физическом уровне, выполнив лишний раз ту же операцию по резервному копированию данных.
Какие еще защитные механизмы можно задействовать, чтобы решить проблему безопасности данных?
В принципе, в любой СУБД есть встроенные возможности по разграничению и ограничению доступа на уровне привилегий пользователей. Но возможность эта существует только чисто теоретически. Кто хоть раз имел дело с администрированием большой СУБД в большой организации, хорошо знает, что на уровне групп пользователей что-либо разграничить слишком сложно, ибо даже, помимо многообразия организационных ролей и профилей доступа, в дело вмешиваются проблемы обеспечения индивидуального доступа, который вписать в рамки ролей практически невозможно.
Но и это еще не все. Очень часто обработка данных ведется не самим пользователем, а созданным и запущенным в СУБД скриптом. Так, например, поступают для формирования типовых или периодических отчетов. В этом случае скрипт запускается не от имени пользователя, а от имени системной учетной записи, что серьезно затрудняет понимание того, что же на самом деле происходит в базе данных. Притом сам скрипт может содержать практически любые команды, включая пресловутое «select * *». В ходе работы скрипт может сформировать новый массив данных, в том числе и дублирующий все основные таблицы. В итоге пользователь получит возможность работать с этим набором данных и таким образом обходить установленные нами средства аудита.
Попытка использовать для разграничения доступа криптографию также обречена на провал: это долго, ресурсоемко и опасно с точки зрения повреждения данных и их последующего восстановления. К тому же возникают проблемы с обработкой информации, ибо индексироваться по зашифрованным полям бесполезно. А самое главное, что некоторым администраторам все равно придется дать «ключи от всех замков».
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.