
Бесплатный фрагмент - Агрегация контента и его обработка
Сборник статей по архитектуре распределенных систем и программной инженерии

Термины и определения
В данной книге применяются следующие термины с соответствующими определениями:
Лемматизация (англ. lemmatization) — процесс приведения словоформы к ее словарной форме.
Партиционирование (англ. partitioning) — разделение больших таблиц (исходя из количества записей) в базе данных на маленькие.
Стемминг (англ. stemming) — процесс нахождения основы слова для заданного исходного слова.
Суммаризация (англ. summarization) — процесс выделения краткого содержимого из текста.
Токенизация (англ. tokenization) — процесс разделения текста на составляющие.
Naive Estimator — наивная оценка.
Twitter Topic Fuzzy Fingerprints — нечеткие отпечатки на основе тем сообщений в сети «Twitter».
Перечень сокращений и обозначений
В данной книге применяются следующие сокращения и обозначения:
БД — база данных.
API, АПИ (англ. Application Programming Interface) — аппаратно-программный интерфейс.
DNS (англ. Domain Name System) — система доменных имен.
FOAF (англ. Friend of a Friend) — спецификация для описания пользователя в социальных сетях.
HTML (англ. Hyper Text Markup Language) — язык гипертекстовой разметки.
JSON (англ. JavaScript Object Notation) — текстовый формат обмена данными, основанный на языке программирования JavaScript.
MNA (англ. Matrix-based News Analysis) — метод матричного анализа новостей.
MLE (англ. Maximum Likelihood Estimator) — подход оценки максимального правдоподобия.
MME (англ. Moment Matching Estimator) — метод определения вероятности изменения агрегированных данных.
NLP (англ. Natural Language Processing) — обработка естественного языка.
REST (англ. Representational State Transfer) — архитектурный стиль взаимодействия компонентов распределенного приложения в сети.
RSS (англ. Rich Site Summary) — обогащенная сводка сайта.
SVM (англ. Support Vector Machine) — метод опорных векторов.
TF-IDF (англ. Term Frequency — Inverse Document Frequency) — статистическая мера, используемая для оценки важности слова в контексте документа.
URL (англ. Uniform Resource Locator) — унифицированный указатель ресурса.
XML (англ. Extensible Markup Language) — расширяемый язык разметки.
YML (англ. Yandex Market Language) — стандарт передачи данных маркетплейса компании «Яндекс».
Предисловие
В этой книге представлены три мои статьи, объединенные одной темой: агрегация контента и его обработка. Данные статьи первоначально были опубликованы на английском языке в журнале из перечня ВАК «Программные системы и вычислительные методы» и использовались мной в дальнейшем в качестве основы при написании магистерской диссертации по программной инженерии на тему «Исследование методов построения архитектур агрегаторов информации в сети Интернет».
В текущий сборник вошел перевод этих статей, выполненный мной самим. К каждому из опубликованных переводов добавлена ссылка на оригинал, а также сохранена оригинальная аннотация на русском языке.
Статьи представлены в полном объеме, без сокращений. Кроме того, в приложении представлены архитектуры систем агрегации информации, дополняющие публикуемые статьи. Для того чтобы сделать иллюстрации читаемыми в черно-белой печати, мне пришлось в статье «Масштабируемая система агрегации, предназначенная для обработки 50 000 RSS-каналов» их переработать, заменив на черно-белые, без потери смысла.
Материал, представленный в данной книге, может быть полезен для студентов ИТ-специальностей, разработчиков ПО, ИТ-менеджеров, а также для широкого круга людей, интересующихся разработкой систем агрегации информации и построением сложных распределенных информационных систем.
Гибридная категориальная экспертная система для использования в агрегации контента
Перевод с английского
Ссылка на оригинальную статью: Kiryanov D. A. Hybrid categorical expert system for use in content aggregation // Software systems and computational methods. 2021. №4. С. 1—22. DOI: 10.7256/2454—0714.2021.4.37019
Аннотация
Предметом исследования является разработка архитектуры экспертной системы для распределенной системы агрегирования контента, основное предназначение которой — категоризация агрегированных данных.
Автор подробно рассматривает такие аспекты темы, как преимущества и недостатки экспертных систем, инструментарий разработки экспертных систем, классификация экспертных систем, а также рассматривает применение экспертных систем для решения проблем категоризации данных.
Особое внимание уделяется описанию архитектуры предложенной экспертной системы, которая состоит из компонента для фильтрации спама, компонента определения главной категории для каждого из типов обрабатываемого контента, а также компонентов для определения подкатегорий, один из которых основан на правилах доменной области, а другой компонент использует методы машинного обучения, дополняя первый. Основным выводом данного исследования является то, что экспертные системы возможно эффективно применять для решения проблем категоризации данных в системах агрегации контента.
Автором было выяснено, что гибридные решения, объединяющие подход, основанный на использовании базы знаний и правил с использованием нейронных сетей, помогают снизить стоимость экспертной системы. Новизна исследования заключается в предложенной архитектуре системы, которая является легко расширяемой и адаптируемой к нагрузкам за счет масштабирования существующих или добавления новых модулей.
Предложенный модуль определения спама основан на адаптировании поведенческого алгоритма определения спама в электронных письмах, предложенный модуль определения основных категорий контента использует два вида алгоритмов на основе нечетких отпечатков: Fuzzy Fingerprints и Twitter Topic Fuzzy Fingerprints, который изначально использовался для категоризации сообщений в социальной сети Twitter. Работа модулей, определяющих подкатегорию на основе ключевых слов, происходит во взаимодействии с базой данных — словарем (тезаурус). Последний классификатор использует алгоритм опорных векторов для конечного определения подкатегорий.
Ключевые слова: экспертная система, алгоритм нечетких отпечатков, агрегация контента, нейронная сеть, категоризация контента, инженерия знаний, метод опорных векторов, TF-IDF, CLIPS, идентификация спама.
Введение
Современная наука и промышленность немыслимы без использования компьютерных технологий. За последние 50 лет уровень информационного и интеллектуального обеспечения различных технологий чрезвычайно возрос [1]. Объем получаемой информации настолько велик, что человеку, даже специалисту, разобраться с ней очень сложно. Для его восприятия и обработки необходима особая интеллектуальная поддержка.
Поэтому экспертные системы и системы поддержки принятия решений находят свое применение в различных областях экономики, медицины и науки [2]. Экспертную систему можно определить как компьютерную систему, предназначенную для решения сложных задач путем эмуляции процесса принятия решений людьми-экспертами [3].
Экспертные системы возникли как значимый практический результат применения и развития искусственного интеллекта, т. е. совокупности научных дисциплин, изучающих методы решения задач интеллектуального (творческого) характера с использованием компьютеров [4]. Первые экспертные системы были разработаны в конце 60-х годов прошлого века и предназначались для создания искусственного сверхразума в некоторых предметных областях [5].
В начале своего развития экспертные системы реализовывались с использованием специализированных языков программирования, таких как Lisp и Prolog [6]. Некоторые из подобных систем активно используются и сегодня. Примером такой системы является DENDRAL [7], целью которой является создание органических молекулярных графов нециклических изомеров (написана на Lisp). Еще одним хорошим примером является PROSPECTOR II [8], который успешно использовался при поиске месторождений полезных ископаемых.
Существует множество типов и реализаций экспертных систем. Например, в статье [9] рассматриваются и классифицируются экспертные системы по двум категориям: системы, основанные на правилах, и системы, основанные на знаниях, с их приложениями для различных исследований и проблемных областей.
Цель этой статьи — представить экспертную систему, являющуюся частью распределенной системы агрегации контента и помогающую категоризировать агрегированный контент. Процесс категоризации зачастую усложняется необходимостью обработки огромного объема данных, что необходимо для повышения релевантности результатов поиска. Для выбора в пользу наиболее подходящего архитектурного решения в рамках данной задачи потребовалось провести исследование преимуществ и недостатков экспертных систем, а также инструментов их разработки.
Эта статья структурирована следующим образом. В главе 1 представлен обзор преимуществ экспертных систем. Глава 2 содержит основные недостатки экспертных систем. В главе 3 описана архитектура экспертной системы в ее общем представлении. Классификация экспертных систем представлена в главе 4. В главе 5 представлен обзор инструментов создания экспертных систем. Примеры экспертных систем, выполняющих задачи категоризации, перечислены в главе 6. В главе 7 объясняется архитектура предлагаемой системы. Наконец, выводы приведены в главе 8.
1. Преимущества экспертных систем
В современном понимании экспертная система — это разновидность искусственного интеллекта (ИИ), т. е. совокупность программ, выполняющих функции человека-эксперта при решении задач из конкретной предметной области [10, с. 203]. И одно из важнейших отличий экспертных систем от других систем с искусственным интеллектом заключается в том, что экспертная система моделирует механизм мышления человека применительно к решению задач в данной проблемной области, а не бизнес-логику.
Экспертная система, помимо выполнения вычислительных операций, формирует определенные соображения и выводы на основе имеющихся у нее знаний (этот компонент обычно называют базой знаний). Кроме того, экспертные системы отличаются от других систем с применением ИИ тем, что используют эвристические и приближенные методы решения задач [1].
Одним из главных преимуществ экспертных систем является производительность. В основном подобные системы обрабатывают данные объектов реального мира, а такие операции обычно требуют значительного человеческого опыта, т. е. экспертизы. Хорошо спроектированные экспертные системы находят решение за разумное время, которое как минимум не хуже того, с которым ту же задачу может решить специалист в данной предметной области. Это означает, что экспертные системы продуктивны и их мощь выражается посредством качественного понимания областей задач [11, с. 74].
Экспертные системы легко анализируют все аспекты проблемы, что часто приводит к выбору лучшей альтернативы. Такие системы оказываются чрезвычайно эффективными, когда базы знаний огромны, поскольку, однажды занесенные, эти знания сохраняются навсегда. С другой стороны, эксперт — это в первую очередь человек, который имеет ограниченную базу знаний. К тому же всегда существует риск потери экспертных знаний из-за ухода эксперта из компании.
В исследовании [12] отмечается весьма положительное влияние экспертных систем на совершенствование контрольного аудита в электронных системах бухгалтерского учета, что проявлялось в упрощении процесса разделения работ и обязанностей. Кроме того, подчеркивается влияние экспертных систем на улучшение управления доступом к подобным системам за счет увеличения вероятности правильной обработки и удостоверения подлинности входных данных. Кроме того, был отмечен положительный эффект от внедрения экспертных систем с точки зрения повышения уровня безопасности и защиты данных, а также улучшения контроля над системной документацией, разработкой и обслуживанием.
Подводя итог преимуществам использования экспертных систем, среди них можно выделить следующие [11, с. 80—81]:
1. повышенная доступность и надежность: доступ к экспертным знаниям возможен с любого компьютера, и система всегда своевременно дает ответы на поставленные вопросы;
2. множественная экспертиза: несколько экспертных систем могут быть запущены одновременно для решения проблемы и получения более высокого уровня знаний, чем у эксперта-человека;
3. объяснение: экспертные системы всегда описывают, как была решена проблема;
4. быстрый ответ: экспертные системы работают быстро и способны решить проблему в режиме реального времени;
5. снижение стоимости: стоимость экспертизы для каждого пользователя значительно снижается.
2. Недостатки экспертных систем
Даже лучшие существующие экспертные системы имеют определенные ограничения по сравнению с человеком, являющимся экспертом в своей предметной области. Например, из-за своей сложности большинство экспертных систем плохо подходят для использования конечным пользователем и для работы с ними необходима высокая квалификация.
Еще одной проблемой при использовании экспертных систем является представление экспертных знаний в форме, понятной системе. Известно также, что приобретение знаний может быть очень дорогим и трудоемким, если проводить его правильно [13, с. 79].
Время, необходимое для составления базы знаний, варьируется от случая к случаю, но может легко составлять от 50 до 100 человеко-недель. Также стоит отметить, что подготовительный этап, включающий первоначальную настройку, технико-экономическое обоснование (ТЭО) и выбор программной оболочки, может занять дополнительно от 15 до 25 человеко-недель [14, с. 165—166].
Дополнительно стоит отметить, что экспертные системы не обладают механизмом самообучения и неприменимы в областях с широкой тематикой. Их использование ограничено такими предметными областями, в которых эксперт может принять решение за время от нескольких минут до нескольких часов. Кроме того, в тех областях, где эксперты могут отсутствовать, использование экспертных систем оказывается невозможным [6].
Также известно, что системы, основанные на знаниях, неэффективны, когда речь идет о строгом анализе, когда количество решений зависит от тысяч различных возможностей и множества переменных, которые меняются со временем. Экспертная система знает алгоритм обработки знаний, но не алгоритм решения задачи, в отличие от традиционных прикладных приложений. Это означает, что алгоритм обработки знаний может привести к непредвиденному результату [6].
Еще одним недостатком является то, что часть знаний в экспертных системах (обычно менее 10 процентов) ускользает от стандартных схем представления и требует специальных исправлений. Такие исправления создают риск аудита и угрозу безопасности, поскольку они дают возможность скрыть знания, которые могут привести к необычному или дисфункциональному поведению [15, с. 9].
В исследовании [16] рассматриваются этические характеристики экспертной системы, такие как отсутствие интеллекта, похожего на человеческий; отсутствие эмоций; случайная предвзятость и отсутствие ценностей. Также было показано, что выбранные характеристики экспертной системы негативно влияют на степень этики в организационной среде.
Доказательства эффективности экспертных систем в медицине неоднозначны. Хотя в некоторых исследованиях отмечалось, что экспертные системы улучшили работу поставщиков медицинских услуг и лечение пациентов, результаты других исследований были менее оптимистичны в отношении их воздействия, требуя дополнительных доказательств для демонстрации экономической эффективности систем подобного вида [13, с. 92]. Например, экспертные системы оказались плохо применимы для плановых медицинских консультаций, где они могут использоваться только как дополнительное средство помощи для врачей, предоставляя им необходимые для постановки диагноза данные о пациентах [17].
Резюмируя недостатки использования экспертных систем [11, с. 81], выделим следующие:
1. экспертные системы обладают поверхностными знаниями, и простая задача потенциально может оказаться дорогостоящей в вычислительном отношении;
2. экспертные системы требуют ввода данных от инженеров по знаниям, сбор данных очень сложен;
3. экспертная система может выбрать наиболее неподходящий метод решения той или иной задачи;
4. проблемы этики использования любых форм ИИ в настоящее время очень актуальны;
5. это закрытый мир со специфическими знаниями, в котором нет глубокого восприятия понятий и их взаимосвязей до тех пор, пока их не предоставит эксперт.
3. Архитектура экспертной системы в общем представлении
В общем виде экспертная система включает в себя следующие компоненты: базу знаний, механизм логического вывода, подсистему объяснений, подсистему приобретения знаний и интерфейс пользователя. Общая архитектура экспертной системы представлена на рисунке 1 [11, с. 75].
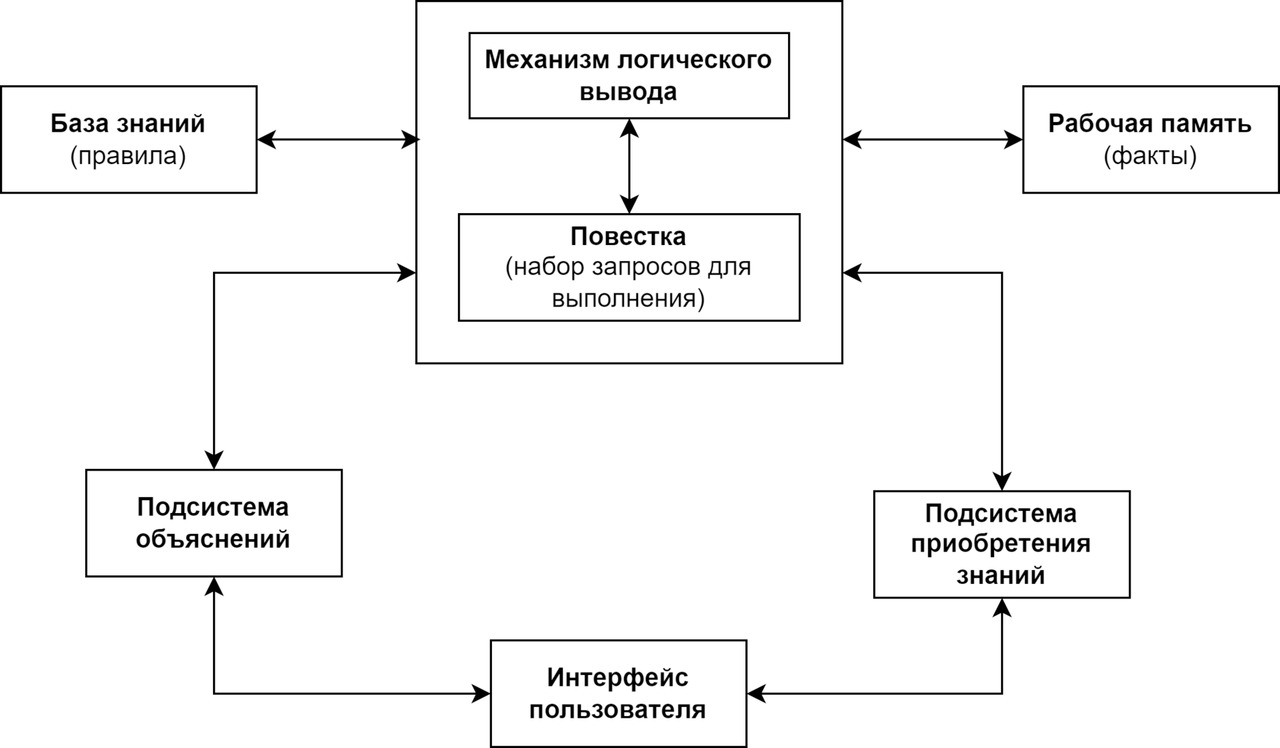
Высокоуровневую архитектуру экспертной системы, показанную на рисунке 1, можно объяснить следующим образом [11, с. 75—76]:
1. В базе знаний хранятся факты для обработки. Это информация о предметной области, введенная экспертами.
2. Механизм логического вывода — это интерпретатор правил, он обрабатывает текущую повестку, состоящую из списка запросов для выполнения.
3. Подсистема объяснений — это механизм, который объясняет пользователю рассуждения экспертной системы при решении задачи.
4. Подсистема приобретения знаний используется для получения информации от пользователя в автоматическом режиме. На данном этапе используются различные методы описания входных данных, такие как описание процессов функционирования, опросы и результаты научных наблюдений.
5. Интерфейс пользователя переводит правила из внутреннего представления в понятный пользователю вид.
4. Классификация экспертных систем
Экспертные системы принято разделять на четыре класса по принципу их работы, включая экспертные системы на основе правил, фреймов, нечеткой логики и нейронных сетей [10, с. 203].
4.1. Экспертные системы, основанные на правилах
Системы, основанные на правилах, преобразуют знания человека-эксперта в формат, подходящий для использования в автоматизированной системе с использованием набора утверждений, т. е. фактов, и набора правил, воплощающих эти знания [18, 19]. Правила задаются в форме ЕСЛИ — ТО. Подобные экспертные системы очень популярны в медицине [20—27]. В исследовании [28] описан унифицированный фреймворк для построения подобных экспертных систем, в котором формализуются операции генерации, упрощения и представления правил.
4.2. Экспертные системы, основанные на фреймах
Фреймовые экспертные системы [29—32] функционируют на основе так называемых фреймов, представляющих собой развитую структуру данных, содержащую концептуальную информацию: именование понятия, возможные значения каждого из атрибутов, а также информацию о процедурах для обработки целевых задач. Фреймовые системы могут решать более сложные задачи по сравнению с экспертными системами, основанными на правилах [10, с. 203—204], и часто комбинируются с последними, образуя, таким образом, мощную систему для решения сложных задач [33].
4.3. Экспертные системы на основе нечеткой логики
Экспертные системы на основе нечеткой логики [34—40] построены на основе теории нечетких множеств, которая используется в процессе принятия решений. Такие системы обладают высокой надежностью и способны выполнять предварительные и эвристические рассуждения [10, с. 204].
Цель экспертных систем на основе нечеткой логики — предоставить простой способ работы в среде с высоким уровнем неопределенности. Если допускается, что сделанные экспертной системой выводы не будут точными, и при этом принимается в расчет определенная погрешность, то в таких случаях использование нечеткой логики может быть очень эффективным [41].
4.4. Экспертные системы на основе нейронных сетей
Экспертные системы на основе нейросетей, как следует из названия, используют нейронные сети для построения базы правил на основе примеров, приведенных человеком-экспертом. Экспертная система на основе нейронной сети со временем увеличивает знания, представленные в ее связях, обучаясь на примерах [42].
Подход на основе нейронных сетей может быть применен в том случае, когда трудно определить, является ли база знаний правильной, последовательной или неполной. Это также применимо в ситуациях, когда трудно получить соответствующий требованиям поставленной задачи набор правил от экспертов-людей [43].
Несмотря на то что нейронные сети изначально не были предназначены для создания экспертных систем [42], этот подход активно используется в настоящее время в связи с бурным развитием алгоритмов машинного обучения [10, с. 204].
При построении экспертных систем с использованием нейросетевого подхода могут использоваться различные алгоритмы и типы нейронных сетей. Например, в статье [44] показано, как алгоритм прямого распространения ошибки (feedforward backpropagation) [45] можно использовать для прогнозирования температуры корпуса печи. В работе [46] описана экспертная система видеонаблюдения на основе рекуррентной нейронной сети (RNN) [47] и сети долгой краткосрочной памяти (LSTM) [48]. В исследовании [49] была предложена экспертная система на основе нейронной сети обобщенной регрессии (GRNN) [50] для диагностики заболевания, вызванного вирусом гепатита В.
5. Инструментарий для создания экспертных систем
Разработка экспертных систем — очень сложная задача, требующая инженеров по знаниям, которые переводят экспертные знания на язык экспертной системы. Для ускорения процесса разработки часто используется специализированное программное обеспечение. В этом разделе представлен краткий обзор некоторых оболочек и языков программирования, которые используются для создания экспертных систем.
5.1. Exsys Corvid
Exsys Corvid [51] уже много лет является одной из самых популярных коммерческих оболочек и активно используется до сих пор. Он включает в себя инструменты для программной отладки и тестирования, а также редактирования и модификации знаний и данных. Система логического вывода (Corvid Inference Engine), написанная на Java, позволяет решать сложные задачи с использованием правил ЕСЛИ — ТО.
Экспертные системы автоматизации знаний на основе Exsys Corvid нашли свое широкое применение в самых разных областях, таких как медицина, техническое обслуживание, управление человеческими ресурсами, госсектор, энергетика и т. д. [52]. Использование Exsys Corvid в качестве инструмента разработки для реализации экспертных систем описано в статьях [53—56].
5.2. CLIPS
CLIPS [57] — хорошо известный программный инструмент для построения экспертных систем на основе правил. Он написан на языке программирования C и использует прямую цепочку логического вывода (forward chaining). В настоящее время CLIPS активно используется в многочисленных современных проектах, таких как разработка экспертной системы для выбора тоннелепроходческой машины [58], прототипирование экспертных систем на основе правил [59], а также в реализации цифрового фитнес-тренера [60].
5.3. Java Expert System Shell (JESS)
Java Expert System Shell (JESS) — это еще одна популярная оболочка для создания экспертных систем. Данная оболочка является интерпретатором языка программирования Jess и может использоваться в консольных и графических приложениях. С архитектурной точки зрения система JESS основана на продукционной модели представления знаний (production system) и выполняет программы, основанные на правилах [61].
JESS успешно использовалась во многих проектах, включая интерактивную голосовую систему [62], обнаружение семантических веб-сервисов [63], анализ рисков безопасности [64], создание виртуальной лабораторной платформы [65], и многих других проектах.
5.4. Kappa PC
Kappa PC [66, 67] представляет собой оболочку, объединяющую критически важные технологии, необходимые для быстрой разработки недорогих и высокопроизводительных экспертных систем. Позволяет писать приложения с использованием графического пользовательского интерфейса и генерирует стандартный программный код ANSI C. Компоненты предметной области представлены как объекты и могут описывать объекты реального мира, такие как автомобили, или нематериальные понятия, такие как собственность, и эти объекты могут быть расширены с помощью методов [66].
Применение программного обеспечения Kappa PC можно найти во многих проектах, таких как экспертная система для проектирования коммерческих автобусов [68] или консультативная система, помогающая повысить эффективность транспортной системы [69].
5.5. Prolog
Prolog [70—72] — язык логического программирования, который очень популярен в программировании искусственного интеллекта и часто используется для разработки экспертных систем. Основными особенностями Prolog являются механизм сопоставления с образцом (pattern matching), поддержка поиска с возвратом (backtracking), а также возможность древовидного структурирования данных.
5.6. Flex
Flex — это набор инструментов для разработки экспертных систем на основе языка программирования Prolog. Поддерживает рассуждения на основе фреймов с наследованием, программирование на основе правил и процедуры, управляемые данными, полностью интегрированные в среду логического программирования [73, с. 9]. Существует множество экспертных систем, построенных с использованием этой оболочки, например: экспертная система выбора площадки для тепловых электростанций [74] и экспертная система для интерпретации результатов микроматрицы аллергенов [75].
5.7. Gensym G2
G2 — мощная экспертная система для операций в реальном времени, предоставляемая Gensym Corporation. G2 может обрабатывать десятки тысяч правил в секунду, поддерживает рассуждения как в пределах установленных временных рамок, так и рассуждения по умолчанию; определение правил на естественном языке и планирование приоритетов задач [76].
G2 используется в таких проектах, как, например, динамическое моделирование угольной шахты [77] и реализация концептуальной основы моделирования биофармацевтического завода [78], где требуются высокая производительность и надежность.
5.8. Lisp
Lisp, помимо Prolog, — это еще один популярный язык программирования для создания экспертных систем, который сегодня активно используется в таких проектах, как экспертная система диагностики и лечения диабета [79], а также во многих других.
5.9. VisiRule
VisiRule [81] — популярный инструмент визуального моделирования, предназначенный для построения надежных моделей принятия решений. VisiRule не требует навыков программирования и генерирует код Flex и Prolog на основе визуальных моделей. Пример работы VisiRule можно найти в исследовании [81], описывающем создание экспертной системы принятия решений на основе правил.
Как было показано выше, существует множество оболочек и языков программирования, которые можно использовать для построения экспертных систем. К сожалению, многие инструменты в настоящее время не поддерживаются. Технический отчет [82] содержит подробный обзор многих из них.
6. Задачи категоризации и классификации с использованием экспертных систем
Экспертные системы могут использоваться для решения проблемы категоризации, т. е. они могут определять некоторые объекты или последствия неопределенных знаний посредством иерархической категоризации. База знаний таких категориальных систем состоит из таксономического набора вербальных категорий, а их целью является определение категории входного объекта на основе имеющихся фактов [83].
Поскольку категориальное знание состоит только из логических связей между фактами и не подвергается сомнению, его можно выразить в виде правил ЕСЛИ — ТО. Категориальные экспертные системы также требуют механизма логического вывода для решения конкретной проблемы. Механизм логического вывода может использовать методы как обратной (backward chaining), так и прямой (forward chaining) цепочки рассуждений и, кроме того, включать модули объяснения и разрешения конфликтов [84, с. 25—30].
Текущие исследования показывают, что при разработке модулей классификации в подобных экспертных системах в качестве альтернативы подходу, основанному на правилах, широкое применение находят нейронные сети. Экспертные системы очень часто применяются для решения задач классификации и категоризации данных, и в этом разделе содержится описание некоторых из них.
6.1. Категориальная экспертная система Jurassic
Jurassic [85] является хорошо известным примером категориальной экспертной системы. Ее база знаний состоит из 423 правил, которые представлены в виде ориентированного ациклического графа с глубиной, равной пяти.
В Jurassic используется подход [86] представления объектов не в виде наборов признаков, а в виде списков, что позволяет включать в одно объектное представление копии одного и того же объекта, различающиеся своим положением в списке. Система выполняет категоризацию с использованием нейронной дедуктивной системы. В случае неопределенных знаний сходство определяется на основе общих признаков.
6.2. Экспертная система для классификации множественного интеллекта учащихся
В работе [87] представлена экспертная система, которая классифицирует способности студентов в одной из трех областей: инженерия, менеджмент и естественные науки. Архитектура системы включает в себя пользовательский интерфейс, механизм логического вывода, базу знаний, базу данных студентов и базу данных, содержащую ответы студентов на вопросы, которые используются для определения наиболее подходящего курса для каждого студента.
База знаний системы содержит предустановленные правила, которые необходимо корректировать в процессе работы. Система определяет предпочтительный курс для учащегося на основе весов, рассчитанных с помощью специальных функций, определенных для каждого типа интеллекта для каждого класса.
6.3. Экспертная система классификации трещин дорожного покрытия
В исследовании [88] рассматривается мультиагентная экспертная система автоматического обнаружения признаков разрушения дорожного покрытия. В качестве компонента, выполняющего задачу классификации, в ней используется экспертная система, работающая при помощи нейронной сети. Данная система является гибридной [89] и имеет довольно сложную архитектуру, состоящую из трех подсистем, и помимо экспертной системы использует различные технологии, такие как нечеткая логика [90], обработка изображений, методы мягких вычислений (soft computing) и т. д.
6.4. Экспертная система классификации скачков напряжения
В работе [91] представлена экспертная система классификации скачков напряжения в энергосистеме. Экспертная система обрабатывает четыре класса событий, которые могут быть вызваны неисправностями трансформатора или индукционного двигателя, а также скачкообразными изменениями напряжения. Задача классификации основана на характеристиках данных событий, связанных с временным снижением напряжения. База знаний системы содержит признаки, однозначно характеризующие события в наборе правил.
6.5. Экспертная система классификации твитов
Экспертные системы часто используются в задаче классификации контента. Например, в исследовании [92] представлена MISNIS — экспертная система, которая автоматически классифицирует твиты по набору интересующих тем. Система использует метод Twitter Topic Fuzzy Fingerprints [93] и сравнивает нечеткие отпечатки отдельного текста с отпечатками потенциального автора. Чтобы определить, относится ли твит к определенной теме, система создает отпечаток темы и отпечаток трендовых тем.
6.6. Экспертная система категоризации многоязычных документов
Проект GENIE, описанный в статье [94], представляет собой многоязычную экспертную систему категоризации текста на основе правил, которая состоит из пяти этапов: предварительная обработка, классификация на основе атрибутов, статистическая классификация, географическая классификация и онтологическая классификация.
Процесс категоризации начинается с этапа предварительной обработки, который включает в себя лемматизацию [95], распознавание именованных сущностей (named entity recognition, NER) [96] и извлечение ключевых слов [97]. Затем выполняется классификация на основе атрибутов, основанная на тезаурусе (thesaurus), то есть списке слов и наборе их отношений. Следующим этапом является статистическая классификация, где методы машинного обучения используются для поиска закономерностей, соответствующих статистической информации, и получения меток, соответствующих общим темам документа.
После система применяет географический классификатор для определения возможных географических ссылок, включенных в текст. Географический классификатор использует специальный компонент — географический справочник (gazetteer) [98], который представляет систематизированную информацию о местах и географических названиях.
На конечном этапе осуществляется онтологическая классификация с использованием лексической базы данных, которая содержит наборы синонимов и семантических отношений между ними.
Подобный подход к построению архитектуры модуля классификации используется в проекте Hypatia [99] — экспертной системе, разработанной для отделов канцелярии и делопроизводства и обеспечивающей категоризацию, семантический поиск, обобщение, извлечение знаний, агрегацию и многие другие функции в области анализа текстовых документов.
7. Предлагаемая система
7.1. Архитектура системы
Предлагаемая экспертная система категоризации рассматривается как часть высоконагруженной распределенной системы агрегации контента, агрегирующей текстовые данные различных типов, таких как новости, блоги, объявления о работе, информация о компании (включая отзывы о работе), события (встречи, конференции, выставки и т. д.), и отображает его в удобном для пользователя виде.
Поскольку основной целью этой системы является предоставление релевантного ответа на пользовательский запрос, решение проблемы категоризации агрегированного контента очень актуально. Задача усложняется огромным объемом данных, что подразумевает необходимость обеспечения высокой производительности и масштабируемости работы системы категоризации.
Каждый из агрегированных документов обладает набором свойств, таких как заголовок, дата создания, URL, тип, краткое описание и т. д. Эти свойства используются механизмом на основе правил для категоризации данных в том случае, когда данные, полученные на этапе нейросетевой обработки, недостаточны для принятия конечного решения.
Высокоуровневая архитектура предлагаемой системы показана на рисунке 2.
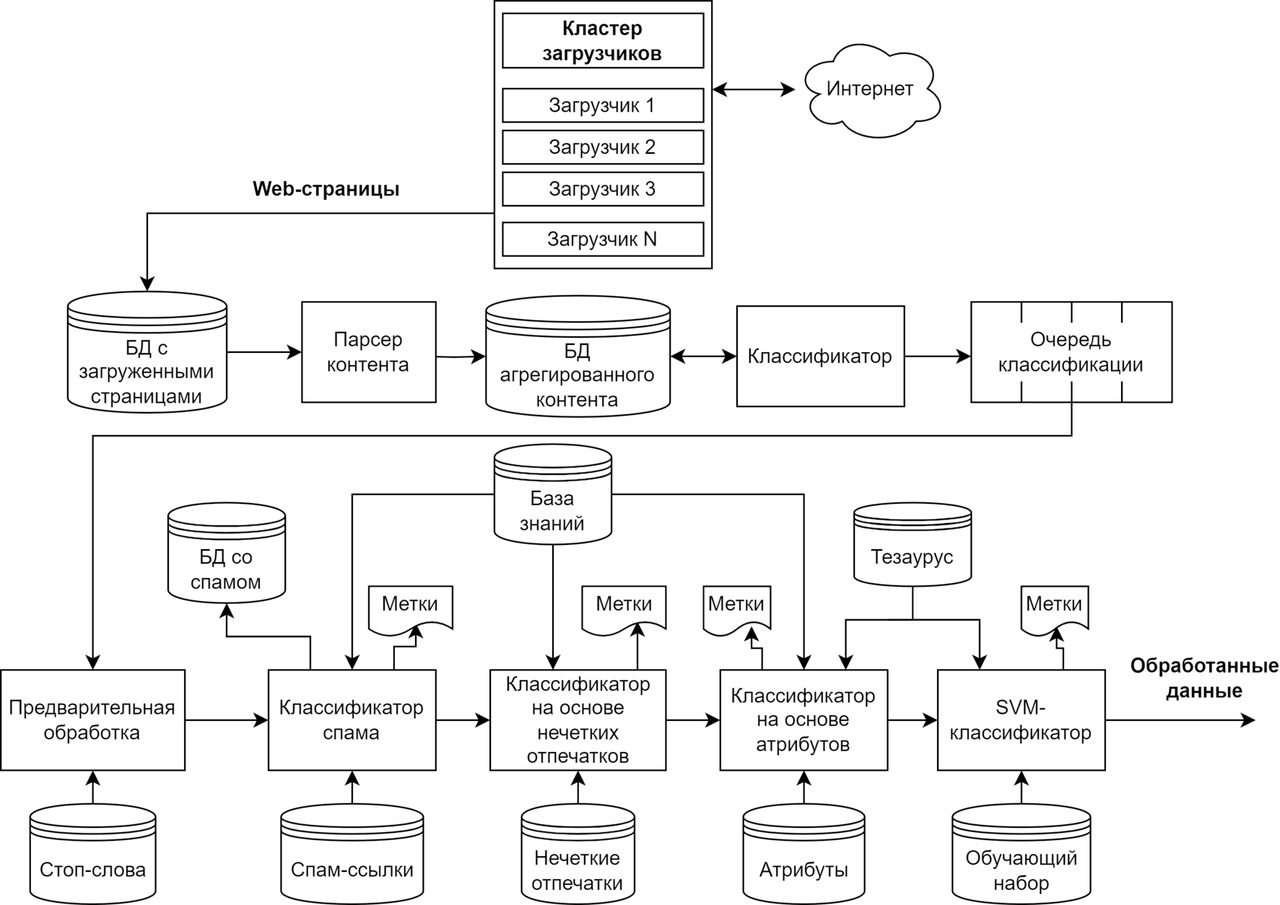
Система, показанная на рисунке 2, состоит из кластера загрузчиков контента [100], т. е. веб-краулеров, модуля парсинга контента, модуля классификации, модуля предварительной обработки, классификатора спама, классификатора на основе нечетких отпечатков, классификатора на основе атрибутов и SVM-классификатора.
В системе также имеется тезаурус — база данных со списком слов на разных языках, которые используются в категоризации данных. На каждом этапе система пытается получить метки, соответствующие категориям обрабатываемого контента.
Всю представленную систему можно разделить на две части: первая часть — поиск информации, вторая — ее последующая обработка и категоризация. Эти части будут описаны ниже, уделяя больше внимания части категоризации, поскольку технология агрегирования контента не является основной темой данного исследования.
7.2. Получение информации
Загрузчики контента отвечают за постоянное наполнение системы данными: они отправляют сотни запросов к источникам в Интернете и сохраняют веб-страницы в базу данных хранилища контента.
Парсер контента — это распределенный набор сервисов-парсеров, которые получают на вход агрегированные данные и извлекают из них структурированную информацию в соответствии с бизнес-правилами. Полученные в результате обработанные данные затем сохраняются в БД агрегированного контента. Так же, как и БД с загруженными страницами, БД агрегированного контента является реляционной базой данных (PostgreSQL [101]). В системе повсеместно используется master-slave репликация для обеспечения отказоустойчивости и стабильной работы.
Классификатор извлекает обработанные данные из БД агрегированного контента и добавляет их для последующей обработки в очередь классификации (RabbitMq [102]). Очередь сообщений в данном случае используется для масштабирования нагрузки, т. к. объем обрабатываемой информации очень велик.
7.3. Предварительная обработка
Модуль предварительной обработки автоматически извлекает HTML-данные из очереди сообщений, поступивших на классификацию, и производит дальнейшую предварительную обработку, цель которой — облегчение дальнейшей работы механизма категоризации.
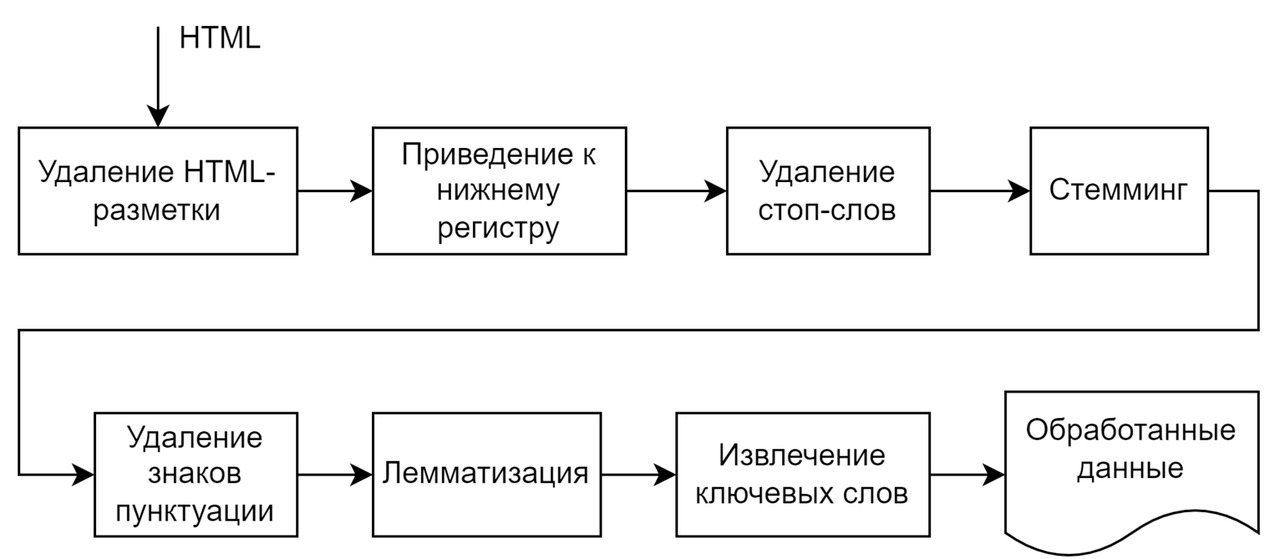
Архитектура модуля предварительной обработки показана на рисунке 3.
Как следует из рисунка 3, архитектура модуля предварительной обработки состоит из отдельных приложений, выполняющих удаление HTML-разметки, приведение к нижнему регистру, удаление стоп-слов, стемминг [103], удаление знаков пунктуации, лемматизацию, а также извлечение ключевых слов с использованием алгоритма TF-IDF [104].
7.4. Классификатор спама
Рассматриваемая система агрегирования контента должна иметь эффективный механизм обнаружения спама и нежелательного контента. Проблема состоит в том, что спам может содержаться в различных типах контента и принимать многочисленные формы: от скрытой рекламы до незаконного контента в статьях, агрегированных комментариях и отзывах. Идентификация и классификация спама является актуальной научно-технической проблемой, которая решается разнообразными способами, включая применение экспертных систем на основе правил, а также систем, базисом которых являются алгоритмы машинного обучения.
Например, в исследовании [105] описан фреймворк для гетерогенного обучения на основе cost-based методов, которые применяются для обнаружения спама в сообщениях Twitter и представляют собой сочетание работы экспертов и алгоритмов машинного обучения, отвечающих за фильтрацию спама в сообщениях.
В статье [106] спам-сообщения были идентифицированы с помощью ИИ на основе алгоритмов глубокого обучения. Исследователи применили шесть моделей обучения и обнаружили, что XGBoost [107] имеет лучшую производительность среди моделей машинного обучения при определении спама.
Классификатор спама, входящий в состав предлагаемой системы, основан на поведенческом методе, описанном в [108], который совмещает подход, основанный на правилах, с нейросетевой обработкой. Данный метод использовался авторами указанного исследования для решения задач обнаружения спама в электронных письмах. Архитектура предлагаемого классификатора спама показана на рисунке 4.
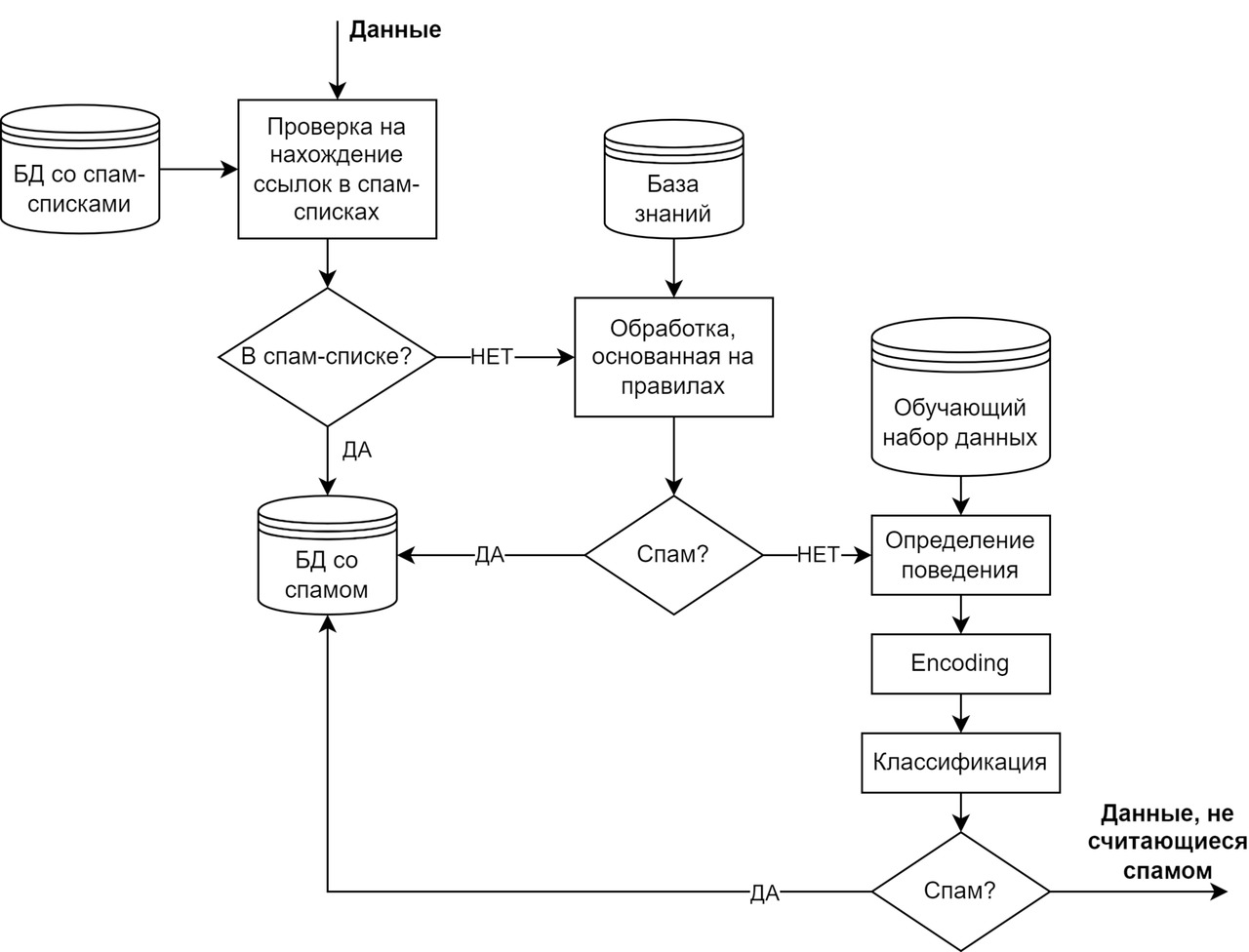
Классификатор спама работает следующим образом: при поступлении новой партии агрегированного контента запускается анализ входного текста на предмет наличия внешних ссылок, занесенных в спам-список. При обнаружении совпадений на этом этапе данные считаются спамом и сохраняются в БД со спамом.
Следующим шагом является обработка на основе правил, в которой используются знания предметной области из базы знаний. Если данные определяются как спам, то они снова сохраняются в БД со спамом.
Для выявления спам-поведения предполагается формировать новости, комментарии, блоги и другой агрегированный контент в соответствии с их ключевыми словами, тегами, датой создания, информацией об авторе, внешними ссылками, описаниями изображений и т. п. и представлять эти данные в векторной форме с последующей нейросетевой обработкой, как описано в статье [108].
7.5. Классификатор на основе алгоритма нечетких отпечатков
Весь агрегированный контент должен иметь основные категории, соответствующие общему содержанию смысла. Кроме того, есть более конкретные подкатегории. Например, для категории «Спорт» возможны подкатегории «Хоккей» или «Футбол».
Для этого используется классификатор на основе алгоритма нечетких отпечатков (Fuzzy fingerprints classifier), определяющий основные категории для каждого типа агрегированного контента. Для таких типов контента, как статьи и блоги, которые содержат большое количество текстовых данных, этот модуль применяет алгоритм нечетких отпечатков [109]. В случае комментариев и обзоров, которые менее многословны, используется алгоритм Twitter Topic Fuzzy Fingerprints [93].
Для определения основной категории анализируемого контента создается его отпечаток на основе наборов обучающих данных, содержащих объекты с известной категорией. Созданные отпечатки сохраняются в базу данных PostgreSQL.
Если классификатор получает неоднозначные результаты, в действие вступает механизм, основанный на правилах, который использует логику предметной области, связанную со свойствами анализируемого документа.
7.6. Классификация на основе атрибутов и SVM-классификация
Идея использования классификатора на основе атрибутов была заимствована из конструкции экспертной системы GENIE [94]. Это основанный на правилах процесс, который находит подкатегории обработанных документов в соответствии с их свойствами и на основе основной категории, найденной на предыдущем этапе с помощью классификатора нечетких отпечатков.
На последнем этапе обработки данных используется SVM-классификатор, реализованный на основе метода опорных векторов (support vector machine, SVM) [110, 111]. SVM-классификатор ищет совпадения для извлечения подкатегорий, которые могли быть пропущены классификатором на основе атрибутов.
8. Заключение
Проблема классификации и категоризации контента очень актуальна при реализации систем агрегации контента, обрабатывающих огромные объемы данных. По этой причине была представлена архитектура экспертной системы, которая классифицирует и категоризирует агрегированный контент, используя комбинацию нейронных сетей и подхода, основанного на правилах.
Для поиска архитектурного решения, подходящего для текущей предметной области, было проведено исследование преимуществ и недостатков экспертных систем. Было выявлено, что экспертные системы могут быть очень дорогими в разработке и обслуживании, а сбор данных часто требует ресурсов и времени.
С другой стороны, экспертные системы отличаются своим быстродействием и могут решать проблемы в режиме реального времени. Предлагаемая архитектура представляет собой гибридное решение, использующее подход, основанный на правилах, который нивелирует ошибки, допускаемые нейронной сетью. Ожидается, что предложенный подход окажется более эффективным, чем обычное использование подхода, основанного на правилах, т. к. при помощи него может быть распознано значительно большее количество закономерностей.
В архитектуру предлагаемой системы входит модуль классификации спама, который использует комбинацию подхода, основанного на правилах, и нейронной сети для обнаружения спама в агрегированном контенте. В состав системы также входит классификатор на основе нечетких отпечатков, который определяет основные категории для каждого типа агрегированных данных, а для коррекции результатов классификации и категоризации используется подход на основе правил. Классификатор на основе атрибутов определяет подкатегории обрабатываемого контента, а SVM-классификатор используется для улучшения результатов на последнем этапе обработки. Предлагаемая система отличается модифицируемостью, благодаря чему в ее состав можно легко добавлять дополнительные компоненты.
В данной статье также представлен обзор инструментов разработки экспертных систем. Показано, что существует множество доступных фреймворков и языков программирования, которые используются при разработке систем подобного рода. Выбором автора в данном случае является CLIPS: портативное, расширяемое, хорошо документированное общедоступное программное обеспечение.
Библиография
1. Басманов С. Н., Басманова А. А. Обзор эволюции экспертных систем в медицине с точки зрения соответствия основным признакам // Перспективы развития информационных технологий. 2014. №21.
2. Посвалюк Н. Э., Погорелов С. А. Разработка экспертной системы для определения предиктивных рисков заболеваний // Региональные проблемы. 2018. №4.
3. S. N. Islam. Expert System Shell for Developing Multi Crop Expert Systems // AFITA/WCCA 2018 Conference. 2018.
4. Макаров О. Ю., Репников В. Д., Турецкий А. В. Применение экспертной системы для анализа результатов моделирования радиоэлектронных средств на механические воздействия // Вестник ВГТУ. 2013. №6–3.
5. G. V. Komlev, A. S. Mitrofanova. Expert systems // Тенденции развития науки и образования. 2019.
6. Држевецкий Юрий Алексеевич, Затылкин Александр Валентинович, Юрков Николай Кондратьевич Экспертные системы как Прикладная область искусственного интеллекта // НиКа. 2011.
7. Bruce G Buchanan, E. A. Feigenbaum, J. Lederberg. Heuristic DENDRAL: A program for generating explanatory hypotheses in organic chemistry // Machine learning and heuristic data. 1968.
8. R. B. McCammon. PROSPECTOR II — an expert system for mineral deposit models // International Journal of Rock Mechanics and Mining Sciences & Geomechanics Abstracts. 1996. №6.
9. Haider Khalaf Jabbar, Rafiqul Zaman Khan. Development of Expert Systems Methodologies and Applications // International Journal of Information Technology & Management Information System (IJITMIS). 2015. №6 (2).
10. Limao Zhang, Yue Pan, Xianguo Wu, Mirosław J. Skibniewski. Artificial Intelligence in Construction Engineering and Management / Springer. 2021.-263 p.
11. Rajesh Singh, Anita Gehlot, Mahesh Kumar Prajapat, Bhupendra Singh. Artificial Intelligence in Agriculture / CRC Press. 2021.-176 p.
12. Abdel-Rahman kh. El-Dalabeeh, Mohammed Said AlZughoul. The Impact of Expert Systems on Enhancing the General Controls over the Computerized Accounting Information Systems // International Journal of Academic Research in Accounting, Finance and Management Sciences. 2019. №9 (4).
13. Lei Xing, Maryellen L. Giger, James K. Min. Artificial Intelligence in Medicine: Technical Basis and Clinical Applications / Academic Press. 2020.
14. J.C. van Dijk, P. Williams. Expert Systems in Auditing / Palgrave Macmillan, London. 1990. — 192 pp.
15. Daniel O’Leary. Audit and Security Issues with Expert Systems / Amer Inst of Certified Public. 1992.-29 p.
16. Y. Kilani, E. Haikal. Exploitation of expert system in identifying organizational ethics through controlling decision making process // Management Science Letters. 2020. №10 (7).
17. Antoine Richard, Brice Mayag, François Talbot, Alexis Tsoukias, Yves Meinard. What does it mean to provide decision support to a responsible and competent expert?: The case of diagnostic decision support systems // EURO Journal on Decision Processes. 2020. №8.
18. Alvine Boaye Belle, Timothy C. Lethbridge, Miguel Garzón, Opeyemi O. Adesina. Design and implementation of distributed expert systems: On a control strategy to manage the execution flow of rule activation // Expert Systems with Applications. 2018. №96.
19. C. Grosan, A. Abraham. Rule-Based Expert Systems. In intelligent Systems. // Springer. 2011. №17.
20. M. M. Syiam. A neural network expert system for diagnosing eye diseases // Proceedings of the tenth conference on artificial intelligence for applications, IEEE. 1994.
21. Fu Zetian, Xu Feng, Zhou Yun, Zhang XiaoShuan. Pig-vet: a web-based expert system for pig disease diagnosis // Expert Systems with Applications. 2005. №29 (1).
22. P. S. K. Patra, D. P. Sahu, I. Mandal. An expert system for diagnosis of human diseases // International Journal of Computer Applications. 2010.
23. R. Borgohain, S. Sanyal. Rule Based Expert System for Diagnosis of Neuromuscular Disorders. // International Journal of Advance Networking and Applications. 2012.
24. Rung-Ching Chen, Yun-Hou Huang, Cho-Tsan Bau, Shyi-Ming Chen. A recommendation system based on domain ontology and SWRL for anti-diabetic drugs selection // Expert Systems with Applications. 2012. №4 (39).
25. H. Alder, B.A. Michel, C. Marx, G. Tamborrini, T. Langenegger, P. Bruehlmann, J. Steurer and L.M. Wildi. Computer-based diagnostic expert systems in rheumatology: Where do we stand in 2014? // International journal of rheumatology. 2014.
26. V. Rawte, B. Roy. Thyroid Disease Diagnosis using Ontology based Expert System // International Journal of Engineering Research and Technology. 2015. №4 (6).
27. A. M. Karim, F. V. Çelebi, A. S. Mohammed. Lecture Notes on Software Engineering // Software development for blood disease expert system. 2016. №4 (3).
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.